
Machine learning algorithms are the fundamental tools used in the fields of artificial intelligence and data science that allow computers to learn from data and make deft predictions or judgments. Crafting your own machine learning algorithm, often referred to as building a machine learning model, is a fundamental skill for any aspiring data scientist or AI enthusiast.
By breaking the process down into manageable steps and giving you a structured approach to writing your own machine learning algorithms, this step-by-step guide will enable you to start your journey towards becoming an AI master.
If you’re looking for a structured and comprehensive learning experience, consider exploring Scaler’s Machine Learning Course. It provides a deep dive into algorithm development, equipping you with the knowledge and skills to create your own ML models and solve real-world problems.
Understanding the Basics of Machine Learning
Machine learning is a fascinating field that enables systems to learn from data and make predictions or decisions without explicit programming. This branch of artificial intelligence (AI) has completely transformed a wide range of sectors, including banking, healthcare, entertainment, and transportation.
Types of Machine Learning

Machine learning algorithms fall into three main categories:
1. Supervised Learning:
- Algorithms learn from labeled data, where each input has a corresponding output. Predicting the outcome for fresh, untainted data is the aim.
- Common examples include spam filtering, image classification, and predicting house prices.
2. Unsupervised Learning:
- Unlabeled data is explored by algorithms to find hidden patterns or groupings.
- Common examples include customer segmentation, anomaly detection, and recommendation systems.
3. Reinforcement Learning:
- An agent learns to make sequential decisions in an environment to maximize a reward.
- It is similar to a character in a video game learning to play by making mistakes and earning rewards for clever moves.
- Used in robotics, game playing, and resource management.
Why Learning to Write an Algorithm is Crucial
The core of the field is writing models or machine learning algorithms. It allows you to tailor solutions to specific problems, optimize performance, and gain a deeper understanding of how machine learning works. Although pre-built libraries are helpful, developing your own algorithms gives you more flexibility and allows you to take on challenging tasks.
Prerequisites for Writing a Machine Learning Algorithm
Prior to starting the fascinating process of writing machine learning algorithms, make sure you have the skills and knowledge required. While the learning curve can be steep, a strong foundation in certain areas will pave the way for success.
Programming Languages:
- Python or R: Proficiency in at least one of these languages is crucial. R is superior in statistical computing and data visualization, but Python is a popular choice due to its ease of use and abundance of libraries.
Mathematical Foundations:
- Linear Algebra: Understanding vectors, matrices, and matrix operations is essential for working with data and understanding many machine learning algorithms.
- Calculus: Understanding optimization strategies used in model training requires an understanding of fundamental calculus concepts like derivatives and integrals.
- Statistics: A solid grasp of statistical concepts, including probability distributions, hypothesis testing, and regression analysis, is crucial for interpreting data and evaluating model performance.
Understanding of Machine Learning Libraries:
Having knowledge of well-known machine learning libraries can greatly expedite your development process.
- Scikit-learn: This versatile Python library offers a wide range of machine-learning algorithms and tools for preprocessing, model selection, and evaluation.
- TensorFlow: This powerful framework is ideal for building and training complex neural networks, particularly for deep learning tasks.
- Other libraries: Depending on your chosen language and specialization, explore other relevant libraries, such as Keras for neural networks, PyTorch for deep learning research, or Caret for machine learning in R.
Guide to Write a Machine Learning Algorithm
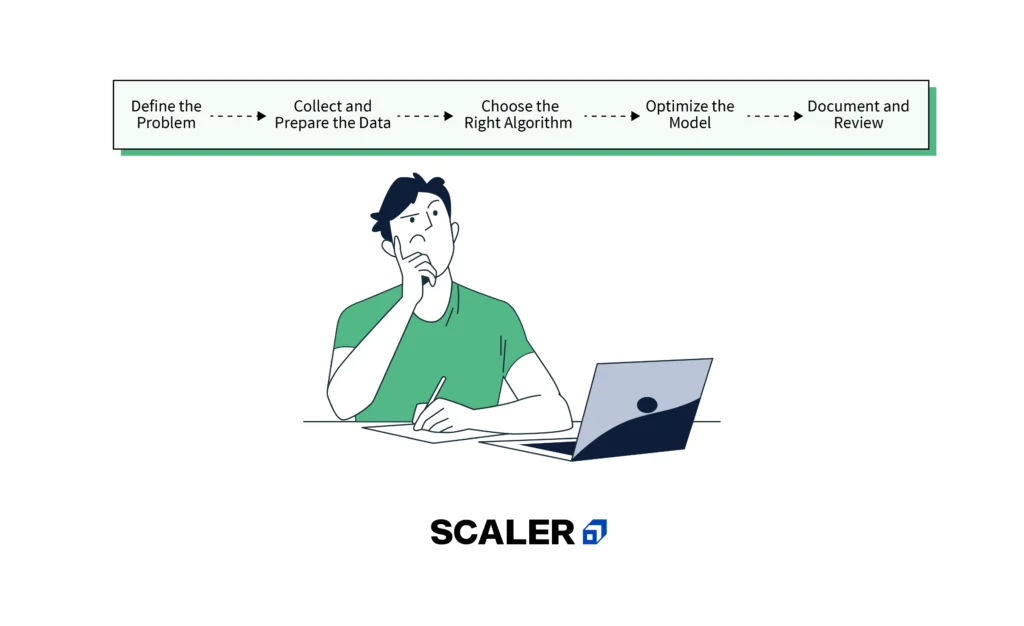
The process of turning unprocessed data into a model that can make predictions or decisions is known as machine learning. Let’s break down this process into actionable steps:
Step 1: Define the Problem
- Understand the problem at hand and its context.
- Determine the intended result or forecast that you would like the algorithm to fulfill.
- Convert the issue into a machine learning task, like clustering, regression, or classification.
Step 2: Collect and Prepare the Data
- Data Collection Techniques: Gather relevant data from various sources, including databases, APIs, sensors, or web scraping. Make sure the data is accurate and pertinent to the issue.
- Data Cleaning and Preprocessing: Clean the data by handling missing values, removing outliers, and transforming it into a suitable format for your chosen algorithm.
Step 3: Choose the Right Algorithm
- Overview of Common Algorithms: Learn about different algorithms such as neural networks (for complex pattern recognition), decision trees (for decision rules), and linear regression (for continuous value prediction).
- Criteria for Selecting the Algorithm: Consider factors like the type of problem, data size, interpretability requirements, and computational resources when choosing an algorithm.
Step 4: Split the Data
- Training Set vs. Test Set: Separate your data into two sets: a test set, which is used to assess the model’s performance on unseen data, and a training set, which is used to train the model.
- Cross-Validation Techniques: Employ techniques like k-fold cross-validation to further assess model generalization and prevent overfitting.
Step 5: Train the Model
- Training Process: Feed the prepared data into your chosen algorithm, allowing it to learn patterns and relationships within the data.
- Tuning Hyperparameters: Change the hyperparameters, which regulate the learning process, to maximize the model’s performance.
Step 6: Evaluate the Model
- Model Evaluation Metrics: Assess the model’s performance using appropriate metrics like accuracy, precision, recall, F1 score (for classification), or mean squared error and R-squared (for regression).
Step 7: Optimize the Model
- Model Optimization Techniques: Use techniques such as feature engineering, hyperparameter tuning, or ensemble methods (combining multiple models) to further enhance the model’s performance.
Step 8: Deploy the Model
- Model Deployment Options: Deploy your model into a production environment, either on-premises or in the cloud, to make predictions or decisions on new data.
- Monitoring and Maintenance: To guarantee the model’s accuracy and applicability, keep a close eye on its performance and retrain it with fresh data as necessary.
Step 9: Document and Review
- Importance of Documentation: Document your code, data preprocessing steps, model architecture, and evaluation results to ensure reproducibility and facilitate collaboration.
- Code Reviews and Collaboration: To find areas for improvement and guarantee code quality, conduct code reviews and solicit input from mentors or peers.
These steps can help you create machine-learning algorithms that solve real-world issues and spur innovation. You can also iterate on your models continuously.
Example: Implementing a Basic Machine Learning Algorithm
Let us take a look at a basic example of using the well-known Scikit-learn library to implement a linear regression algorithm in Python.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# Step 1: Define the Problem
# Let's say we want to predict house prices based on their features (size, number of bedrooms, etc.)
# Step 2: Collect and Prepare the Data
# Load the dataset (assuming you have a CSV file named "housing_data.csv")
df = pd.read_csv("housing_data.csv")
# Select features (X) and target variable (y)
X = df[["size", "num_bedrooms"]] # Adjust features as needed
y = df["price"]
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Step 3: Choose the Algorithm
# We'll use Linear Regression for this example
model = LinearRegression()
# Step 4: Train the Model
model.fit(X_train, y_train)
# Step 5: Evaluate the Model
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
# Step 6: Optimize the Model (Optional)
# You can experiment with different hyperparameters or feature engineering techniques to improve performance
# Step 7: Deploy the Model (Optional)
# Once you're satisfied with the model's performance, you can deploy it into a production environment
# Step 8: Document and Review
# Document your code, data preprocessing steps, and model evaluation resultsExplanation of Each Step:
- import pandas as pd: Imports the Pandas library for data manipulation.
- from sklearn.model_selection import train_test_split: Imports the function to split data into training and testing sets.
- from sklearn.linear_model import LinearRegression: Imports the Linear Regression algorithm.
- from sklearn.metrics import mean_squared_error: Imports the metric for evaluating the model.
- df = pd.read_csv(“housing_data.csv”): Loads the dataset from a CSV file.
- X = df[[“size”, “num_bedrooms”]]: Selects the features for the model.
- y = df[“price”]: Selects the target variable (house price).
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42): Splits the data into 80% training and 20% testing sets.
- model = LinearRegression(): Creates a Linear Regression model object.
- model.fit(X_train, y_train): Trains the model on the training data.
- y_pred = model.predict(X_test): Uses the trained model to make predictions on the test data.
- mse = mean_squared_error(y_test, y_pred): Calculates the Mean Squared Error to evaluate the model’s performance.
- print(“Mean Squared Error:”, mse): Prints the evaluation metric.
This condensed example shows the fundamental procedures needed to put a machine learning algorithm into practice. Remember, real-world projects often involve more complex data preprocessing, feature engineering, and model optimization techniques. Nonetheless, this example offers a foundation for comprehending the fundamental procedure for creating and assessing Python machine-learning models.
Elevate Your Career with Machine Learning
Unlock the potential of AI and build intelligent systems with Scaler’s Machine Learning Course. Gain hands-on experience and expert knowledge to excel in this rapidly growing field. Enroll today to start your journey!
Common Challenges and How to Overcome Them
There are a number of obstacles to overcome when writing machine learning algorithms, even with a well-organized guide. Let’s explore some of the common hurdles and effective strategies to overcome them:
1. Data Quality Issues
- Missing Values: Missing data can hinder model performance. Take care of them by dropping rows or columns if necessary, employing more advanced methods like KNN imputation, or imputing using mean, median, and mode.
- Outliers: Outliers can skew your model’s learning. Identify them using visualization or statistical methods and handle them by removing, transforming, or capping them.
- Inconsistent Data Types: Ensure data consistency by converting columns to appropriate types (e.g., strings to numeric for calculations).
- Imbalanced Datasets: In classification tasks, imbalanced datasets (where one class has significantly more samples than others) can lead to biased models. To address this, apply methods such as undersampling, oversampling, or synthetic data generation.
2. Overfitting and Underfitting
- Overfitting: This occurs when the model learns the training data too well, capturing noise and failing to generalize to new data. Avoid overfitting by employing strategies such as:
- Regularization: Adding penalty terms to the loss function to discourage complex models.
- Cross-Validation: Evaluating the model on multiple folds of the data to assess its generalization ability.
- Early Stopping: Stopping training early when the model’s performance on a validation set starts to degrade.
- Underfitting: This happens when the model is too simple to capture the underlying patterns in the data. Address underfitting by:
- Increasing Model Complexity: Consider incorporating more features or utilizing a more intricate algorithm.
- Feature Engineering: Create new features or transform existing ones to capture more information.
3. Model Interpretability
- Black-Box Models: Intricate models, such as deep neural networks, can be challenging to comprehend, making it more difficult to comprehend how predictions are made.
- Techniques for Interpretability: Use techniques like LIME (Local Interpretable Model-agnostic Explanations) or SHAP (SHapley Additive exPlanations) to gain insights into feature importance and how the model makes decisions.
- Choose Simpler Models: If interpretability is crucial, opt for simpler models like linear regression or decision trees, which are inherently easier to understand.
Tools and Resources for Writing Machine Learning Algorithms
When writing machine learning algorithms, having the appropriate tools and resources at your disposal is essential for a seamless and effective experience. Here are some essential components to aid your development process:
Recommended IDEs
- Jupyter Notebook: This open-source web application is a favourite among data scientists for its interactive environment. It is perfect for documentation and experimentation because it lets you put code, graphics, and explanatory text in one document.
- PyCharm: This powerful IDE from JetBrains offers a comprehensive suite of tools for Python development, including code completion, debugging, and version control integration. Thanks to its clever features, you can greatly increase productivity and optimize your workflow.
Libraries and Frameworks
- Scikit-learn: This versatile machine-learning library provides a user-friendly interface for a wide array of algorithms, making it a great choice for both beginners and experienced practitioners.
- TensorFlow: If you’re delving into deep learning, TensorFlow’s flexibility and scalability make it a top contender. It is perfect for training and constructing intricate neural networks.
- Keras: A high-level neural network application programming interface, Keras makes neural network definition and training easier, which makes it an excellent option for quick prototyping and experimentation.
Online Resources and Courses
The internet offers a wealth of resources to guide your machine learning journey:
- Online Tutorials and Courses: Many courses on machine learning and related subjects are available on platforms like edX, Udacity, and Coursera.
- Blogs and Forums: Engage with online communities and forums to learn from others, ask questions, and stay updated on industry trends.
- Documentation and Tutorials: Refer to the official documentation for your chosen libraries and frameworks to understand their functionalities and best practices.
Scaler’s Machine Learning Course
For a structured and comprehensive learning experience, consider Scaler’s Machine Learning Course. This program provides:
- A comprehensive discussion of machine learning methods and algorithms.
- Hands-on projects to apply your knowledge in real-world scenarios.
- Mentorship and guidance from industry experts.
- Career support to help you land your dream job in machine learning.
Best Practices for Writing Machine Learning Algorithms
Developing machine learning algorithms is not just writing code; it is also about implementing best practices that guarantee efficiency, maintainability, and teamwork. Let’s explore some essential strategies to elevate your code quality and enhance your development workflow:
Code Modularity and Reusability:
- Break down your code into smaller, modular functions or classes. This encourages reusability across various projects and improves the organization and readability of your code.
- Encapsulate data and logic within classes or modules to achieve better code organization and separation of concerns.
- Use meaningful variable and function names that accurately reflect their purpose.
Version Control with Git:
- Track changes to your code with Git, which makes it easier to collaborate and lets you go back to earlier iterations when necessary.
- Create descriptive commit messages that clearly explain the changes made in each commit.
- Try out new features and bug fixes using branches instead of the main codebase.
Peer Review and Testing:
- Seek feedback from peers or mentors through code reviews to identify potential improvements, bugs, or performance bottlenecks.
- Create unit tests to make sure your code is correct and that updates do not affect already-existing features.
- Utilize testing frameworks to automate the testing process and catch errors early in the development cycle.
Additional Best Practices
- Documentation: Document your code thoroughly, explaining the purpose of functions, algorithms, and data structures. This facilitates future maintenance and updates and improves the readability of your code for other people.
- Error Handling: Implement robust error handling mechanisms to gracefully handle unexpected situations and prevent your code from crashing.
- Performance Optimization: Create a profile of your code to find areas where it is performing poorly and optimize important passages for speed and efficiency.
- Keep it Simple: Strive for simplicity and clarity in your code. Avoid unnecessary complexity and prioritize readability.
Following these recommendations will help you write machine learning code that is easier to extend, debug, and collaborate on. It will also be cleaner, more effective, and maintainable. Remember, writing good code is an ongoing process of learning and improvement, so embrace feedback, experiment with different approaches, and strive for excellence in your coding endeavours.
Conclusion

Although creating your own machine learning algorithms can seem overwhelming, it can be a rewarding and manageable task if you follow a methodical, structured approach. By understanding the problem, preparing your data meticulously, choosing the right algorithm, and diligently evaluating and optimizing your model, you can create powerful solutions that harness the potential of artificial intelligence.
Don’t hesitate to embark on this exciting journey. Start small, experiment with different algorithms, and embrace the learning process. Your ability to create your own machine-learning models will improve with practice and confidence.
If you’re seeking a comprehensive learning experience to deepen your understanding and accelerate your progress, consider enrolling in a machine learning course or workshop. These well-organized courses provide you with professional coaching, practical assignments, and a welcoming learning environment to help you become an algorithm development expert and explore the creative possibilities of artificial intelligence.
FAQs
How do I start writing a machine learning algorithm from scratch?
Start by clearly defining the problem you want to solve and gathering relevant data. Choose a suitable algorithm based on the task, then implement it using a programming language like Python or R. Train your model, evaluate its performance, and iterate to optimize it.
What are the most common mistakes when writing ML algorithms?
Common mistakes include inadequate data preprocessing, overfitting or underfitting the model, neglecting feature engineering, using inappropriate evaluation metrics, and overlooking the importance of documentation and code review.
How important is coding in writing a machine learning algorithm?
Coding is essential for implementing machine learning algorithms. Proficiency in languages like Python or R, along with knowledge of relevant libraries, is crucial for translating your algorithm into functional code.
Can I write an ML algorithm without a strong math background?
While a solid understanding of math, especially linear algebra, calculus, and statistics, is beneficial, you can start with a basic understanding and gradually build your knowledge as you learn. Many libraries abstract away some of the complex math, allowing you to focus on implementation and experimentation.
What tools are essential for writing a machine learning algorithm?
IDEs like Jupyter Notebook or PyCharm facilitate code development and experimentation. Libraries like Scikit-learn, TensorFlow, and Keras provide essential functions and algorithms for building models. Additionally, tools for data visualization, version control (Git), and collaboration are important for a smooth workflow.