Activation Functions in Neural Networks

Overview
Activation functions play a vital role in Neural Networks. An activation function is a mathematical function that makes the Neural Network special. Without activation functions, a Neural Network wouldn't perform better than a Regression model. The activation function introduces non-linearity into the model.
What is the Activation Function?
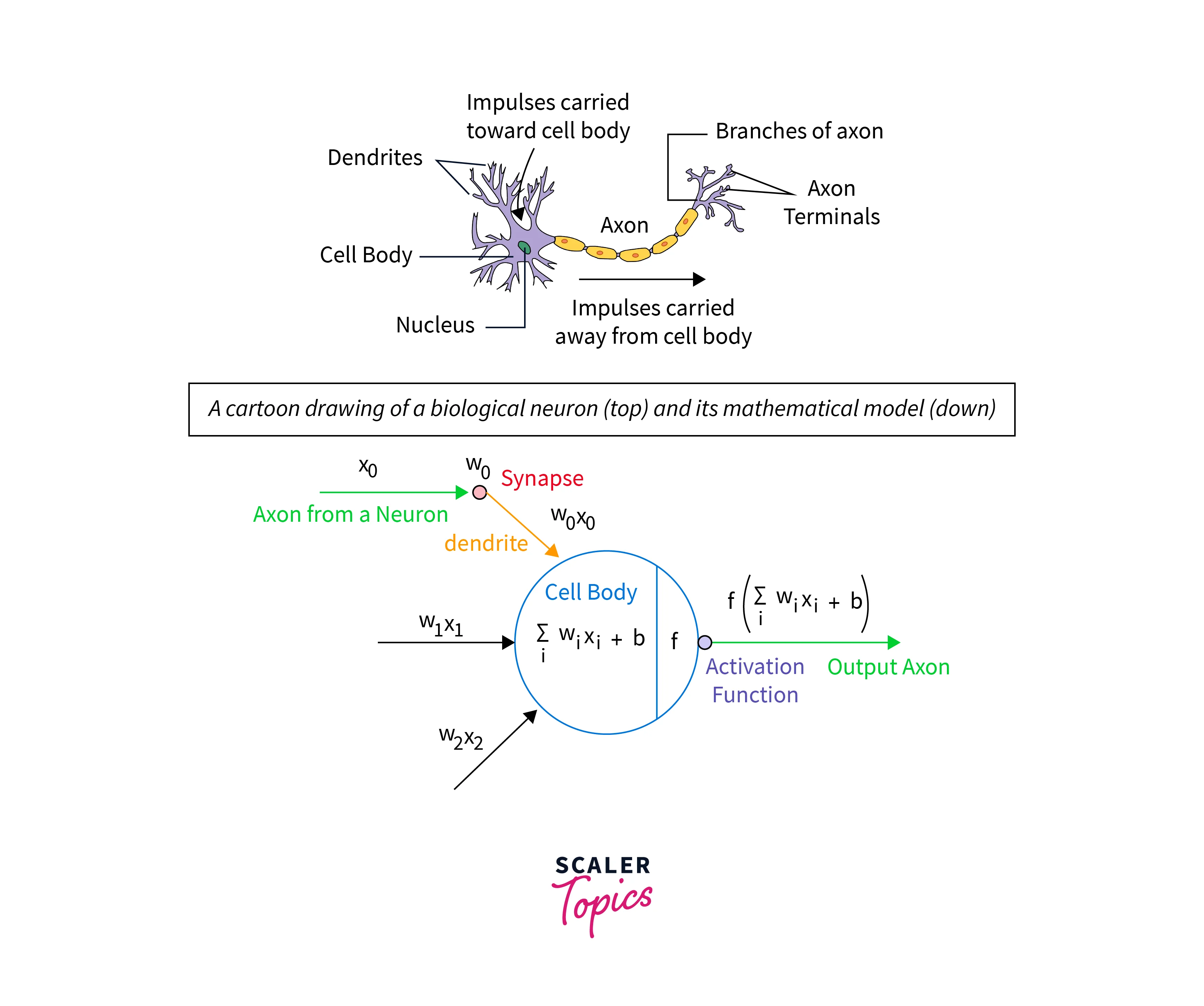
A Neural Network is modeled after the Neurons in the brain. The brain receives a surplus of information, but not everything is useful or required, so the brain filters out information and only takes in the required information. Activation functions are the gates of a Neural network, allowing only useful information to pass through.
The weighted sum of inputs and biases are fed to the Activation function, which returns if the Neuron is to be activated or not. Consider a Feed Forward Network
X = (input*weight) + bias
The Activation Function is applied to the sum of the weighted inputs.
Why do We Need an Activation Function?
How would the Network perform if there was no Activation function? First, it would work as another Linear Regression model. Let's take a look at the following example. First, let's consider a simple 3-layer network.
Output if the input layer
Where f is a linear function
We can see that the output is a Linear equation and cannot perform well with non-linear data. Applying the Activation function enables the Network to perform much better. This is another form of Linear Regression.
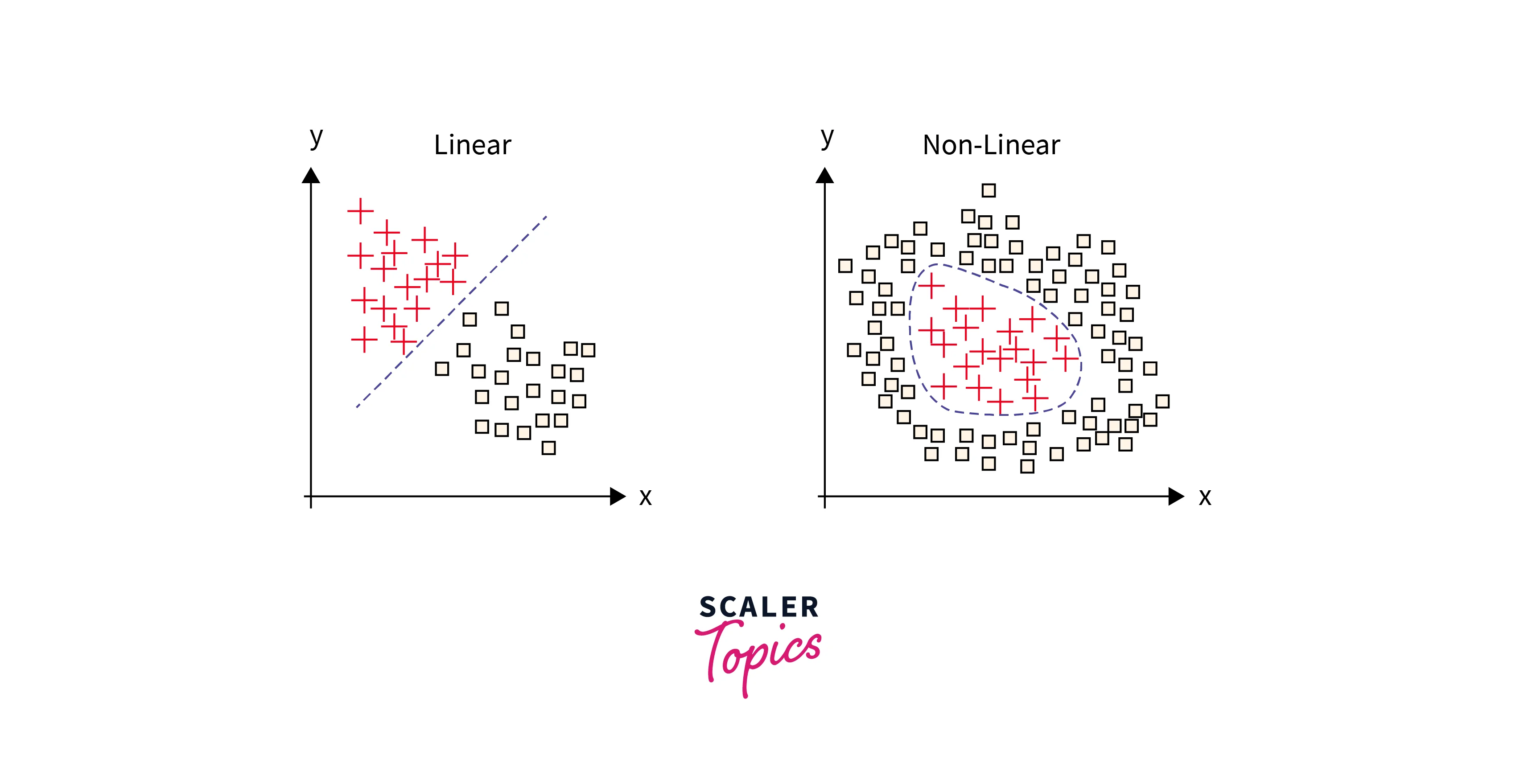
Why Use Non-Linear Activation Functions?
In real-life data, we see non-linear data samples. Adding an activation function ensures that we consider the non-linearity in the data. Furthermore, adding the activation function turns the neurons on and off for different inputs, which further helps the Neural network learn about the input and its corresponding output.
It helps the deep learning model perform well in complex tasks.
Why is Derivative/Differentiation Used?
A couple of parameters decide if the Activation function is good. First, the Activation function must be differentiable and monotonic and should converge quickly.
During Backpropagation, the derivative is calculated to train the model. So the activation function that is chosen should be differentiable.
Differentiate:
Change in the y-axis w.r.t. change in the x-axis. It is also known as slope.
Monotonic:
A function that is either entirely non-increasing or non-decreasing.
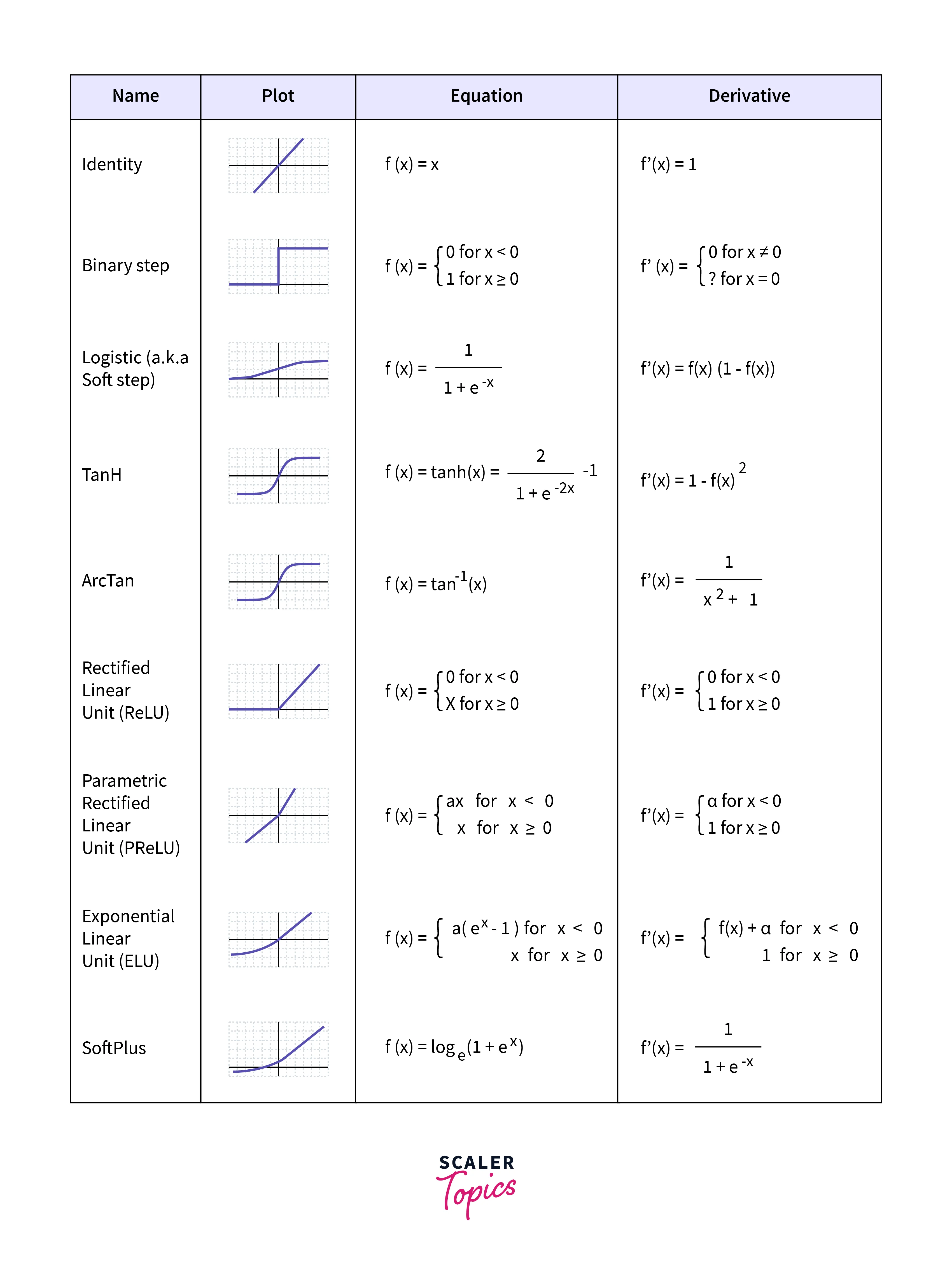
Variants of Activation Function
There are two types of Activation functions:
1. Linear Activation Functions
2. Non-linear Activation Functions
Linear Activation Function
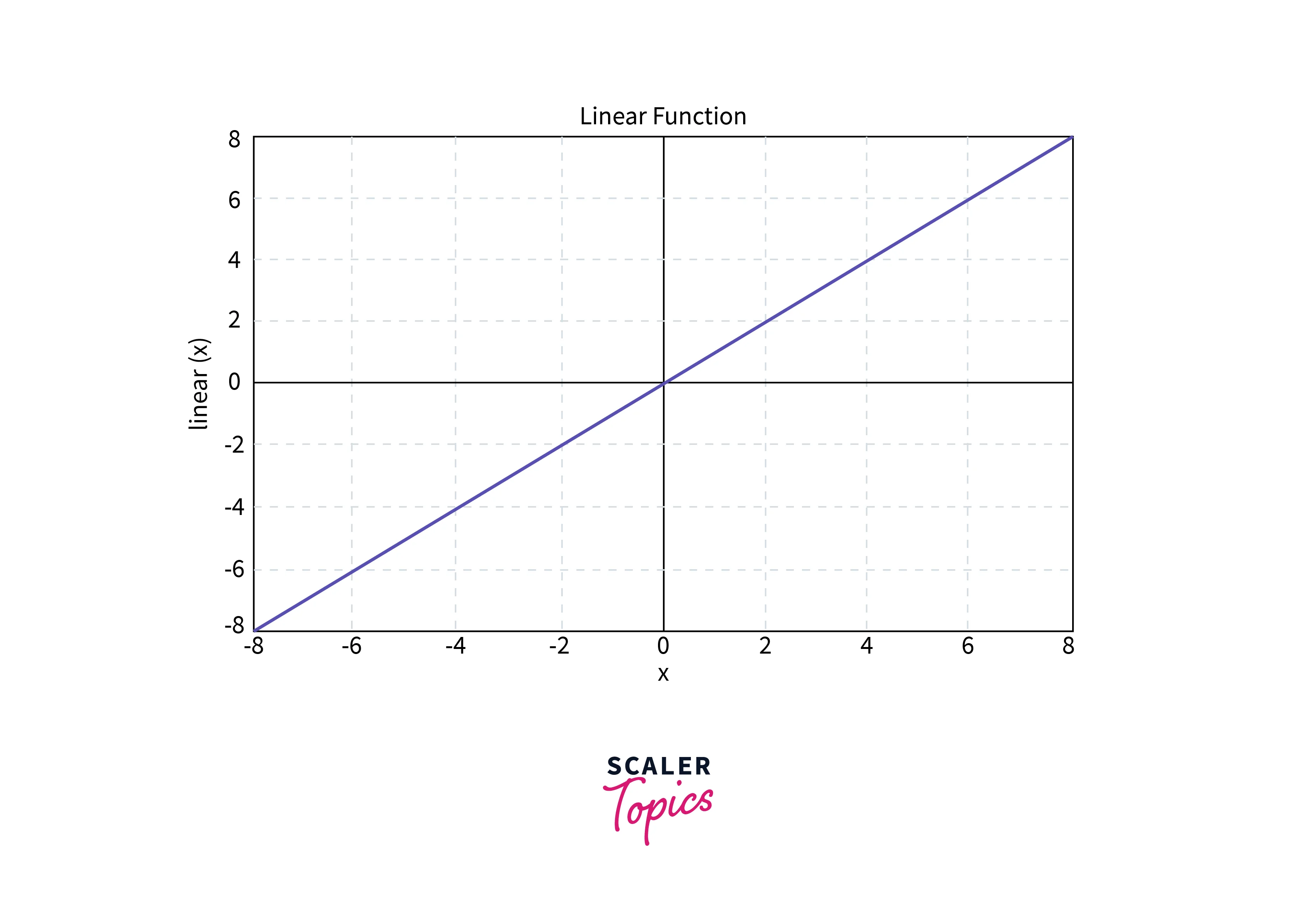
Looking at it, we can see that the Function is a straight line passing through the origin. The values are not confined and can take any integer values from -inf to +inf
Equation:
Using Linear Activation Functions alone in the Neural Network won't perform well as they do not handle the usual data fed into the model, which has complex parameters.
Non-Linear Activation:
Non-Linear Activation functions enable the model to better fit the data with more parameters and complexities.
1. Sigmoid or Logistic Activation Function
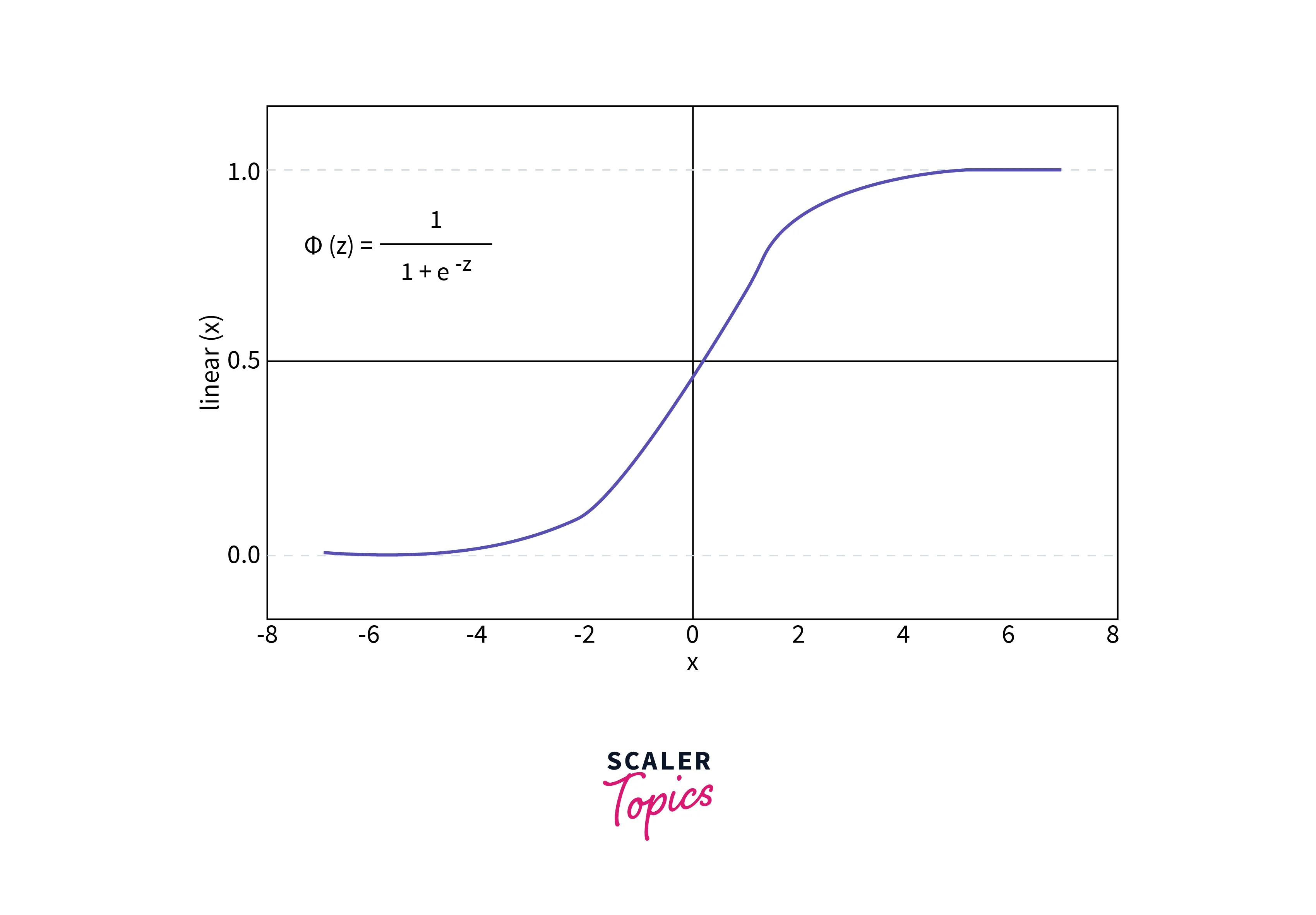
The sigmoid activation function takes input values between - and + and outputs values in the range (0,1). This is very useful, especially in the output layer, where a probability value is required.
This function is both Differentiable and Monotonic.
2. Tanh or hyperbolic tangent Activation Function

Tanh Activation is similar to Sigmoid but outputs values in the range [-1,1]. This offers an advantage to Tank compared to Sigmoid. A Zero input is now mapped near 0rather than0.5` in Sigmoid.
The function is differentiable.
The function is monotonic, while its derivative is not monotonic.
3.ReLU Activation
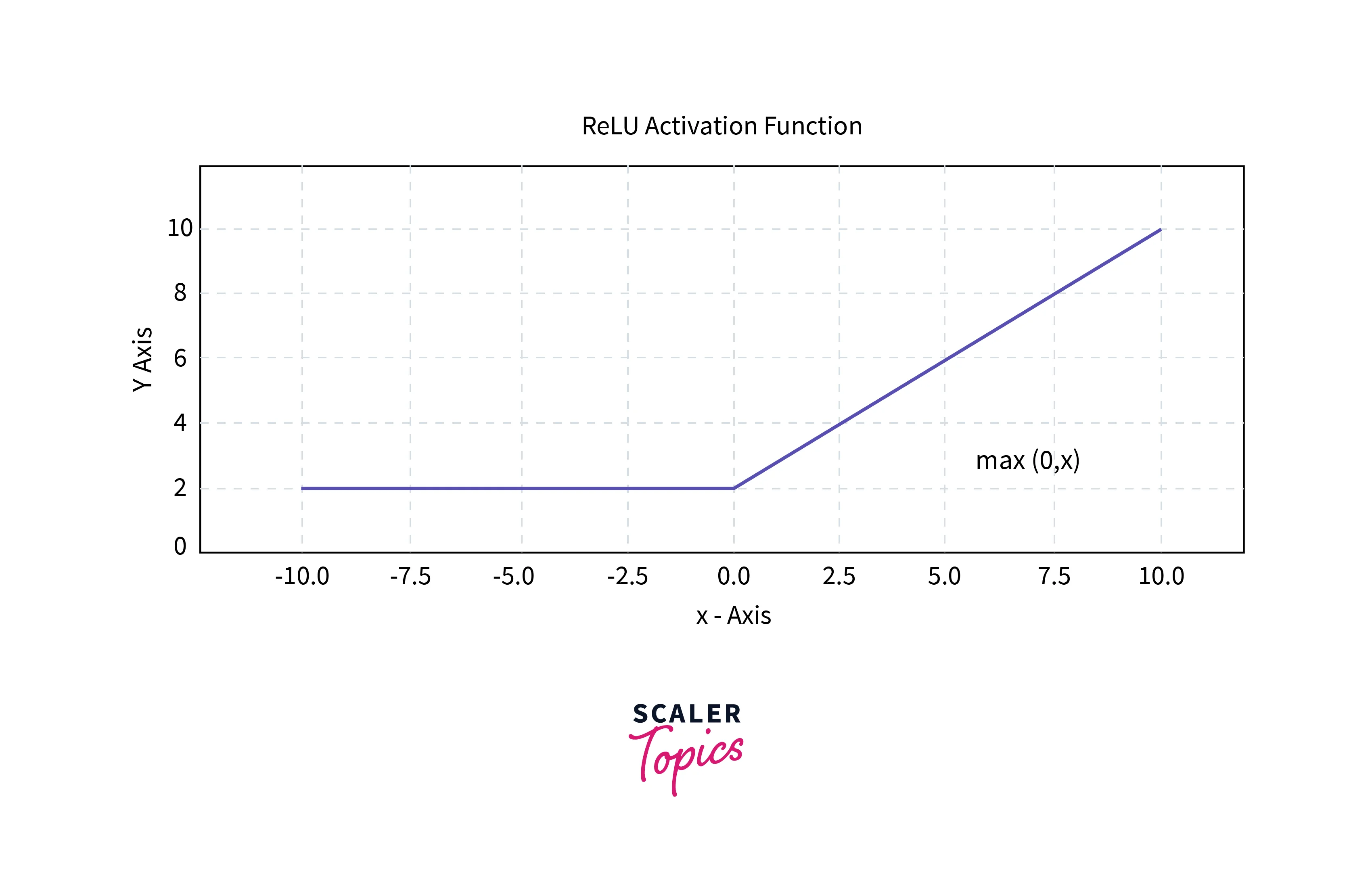
ReLU, or Rectified Linear Unit, has become the most commonly used Non-linear Activation Function. This function returns 0 for input<0 and Linear for input>0. The output ranges from [0,+ve inf].
This helps with a major problem of Sigmoid and Tanh, the Vanishing Gradient problem. In short, the Vanishing Gradient arises because of the restricted output range of Sigmoid and Tanh. So during training, the gradient value becomes smaller and smaller as the values are lesser than 1. This is overcome in ReLU since the Linear part has no output limits.
But it comes with its limitation. The Negative half of ReLU returns 0 for all negative values. This causes the Negative values not to get trained properly, affecting the training and, ultimately, the performance. This is called the "Dying ReLU" problem
4. Leaky ReLU
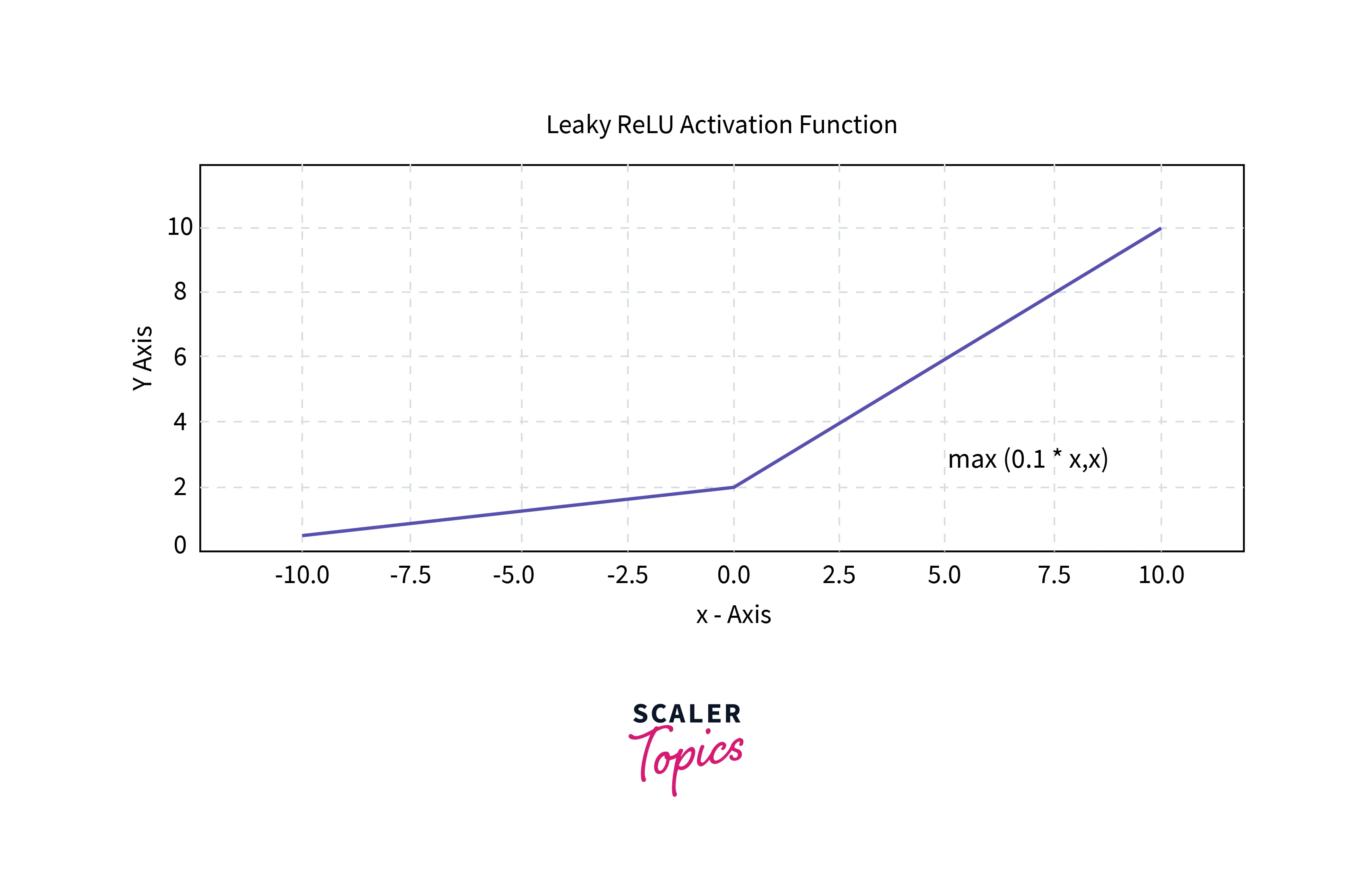
To tackle the dying ReLU problem, Leaky ReLU combats that by having a small slope to the negative half instead of 0. The slope is usually 0.01.
So technically, the output range is [-inf,+inf], but the positive values will be much higher mapped than the negative values. This creates non-linearity.
If the slope is random instead of fixed, it is called Randomized ReLU.
ReLU and Leaky ReLU are differentiable. This is because they are both Monotonic, and their derivatives are Monotonic.
5. SoftMax Activation Function:
Softmax Activation function is used in multi-class classification tasks. The SoftMax function is expressed below.
SoftMax is usually used in the output layer to express the classification in terms of probability. It takes in the values of each object and outputs the probability of each instance so that the sum of probabilities is 1.
How to Choose the Right Activation Function?
Selecting the right activation function is important in a Machine Learning problem. Based on the input and output data, the use of the activation function varies. Activation functions are not supposed to be considered hyperparameters that can be tuned. But it is selecting the right functions based on the application.
The Activation Functions are used in two cases:
-
Hidden Layers
-
Output Layer
Hidden Layer Activation function
As we saw earlier, our preferred Hidden Layer activation function is the ReLU Activation, which can handle Non-linear data. ReLU is preferred over Sigmoid and Tanh as it overcomes the problem of Vanishing/Exploding Gradient.
Tanh and Sigmoid Activation Functions are most commonly used in Recurrent Neural Networks (RNN). In addition, a Softmax Activation Function is commonly used for classification tasks at the output layer.
Output Layer Activation Function
There are three most commonly used Activation Functions for the output layer.
- Linear Activation Function
- Sigmoid Activation Function
- SoftMax Activation Function
As we saw the pros and cons of these layers, Sigmoid is used for Binary Classification, while SoftMax is used for Multi-class classification. The linear Layer is used extensively when the data needs to be flattened.
Conclusion
- Activation functions are the gates of the Neural Network.
- It adds non-linearity to the system.
- Without activation functions, the model would work just like Linear Regression.
- Different activation functions have different purposes and use.