Adaptive Moment Estimation
Overview
Adaptive moment estimation is a stochastic gradient descent optimization algorithm well-suited for training deep learning models. It was introduced in a 2015 paper by D.P. Kingma and J.L. Ba. Adam works by keeping track of an exponentially decaying average of past gradients and past squared gradients and using this information to adapt the learning rates of model parameters during training.
Introduction
Optimization algorithms are a crucial component of many machine learning models, as they find the optimal values of the model's parameters. One of the most popular optimization algorithms is gradient descent, an iterative algorithm that uses the gradient of the objective function to find the minimum of that function. This tutorial will discuss a variant of gradient descent known as the Adam algorithm, an efficient and widely used optimization method for deep learning and other machine learning applications.
Gradient Descent
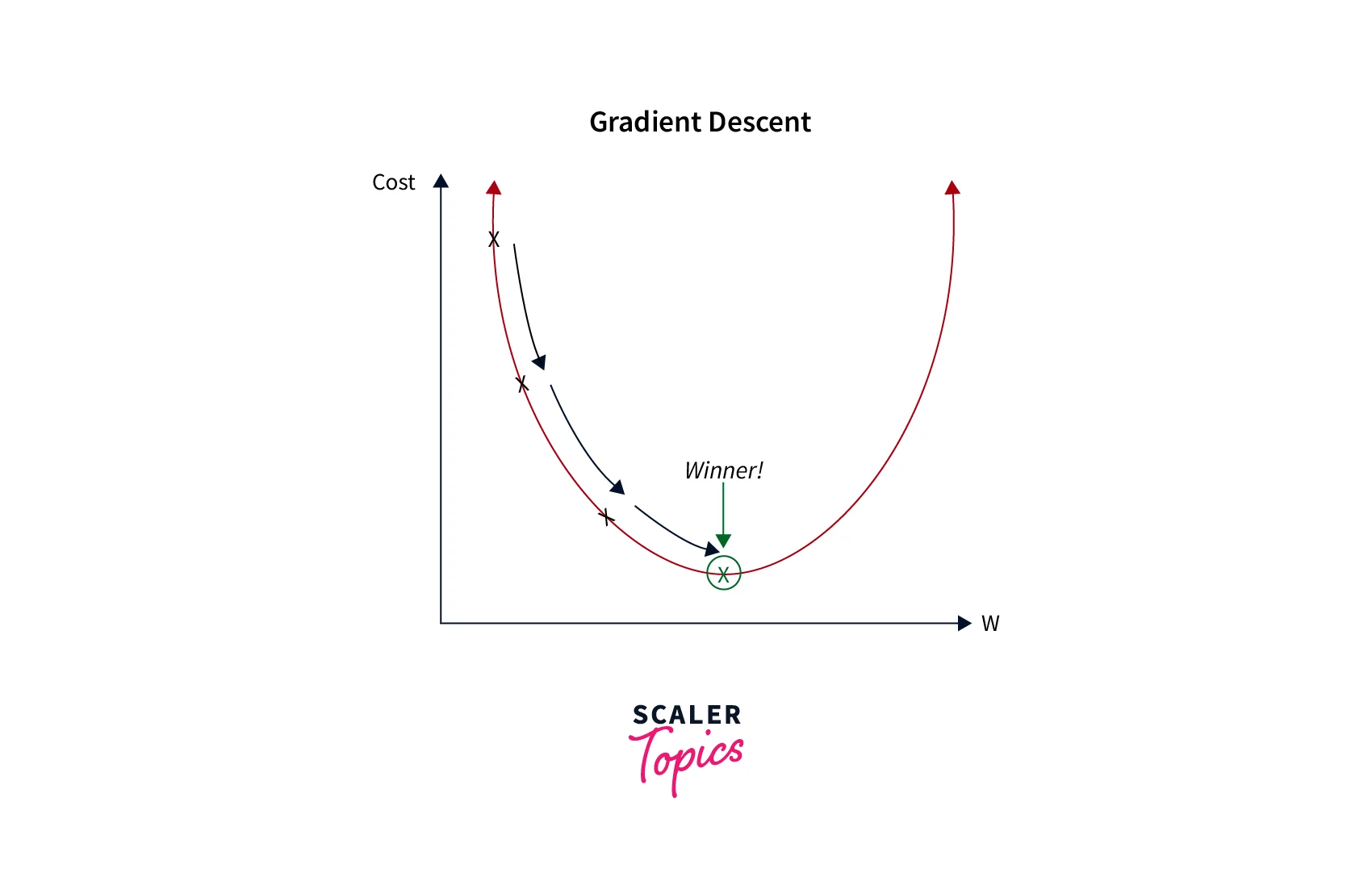
Gradient Descent is an optimization algorithm used to minimize a function. It works by iteratively moving toward the steepest descent, where the function decreases quickly. At each iteration, the algorithm updates the values of the parameters (coefficients and biases) in the function to minimize the loss.
There are several variants of gradient descent, including batch gradient descent, which processes all the training examples in the dataset at each iteration, and stochastic gradient descent, which processes a single training example per iteration.
Stochastic Gradient Descent
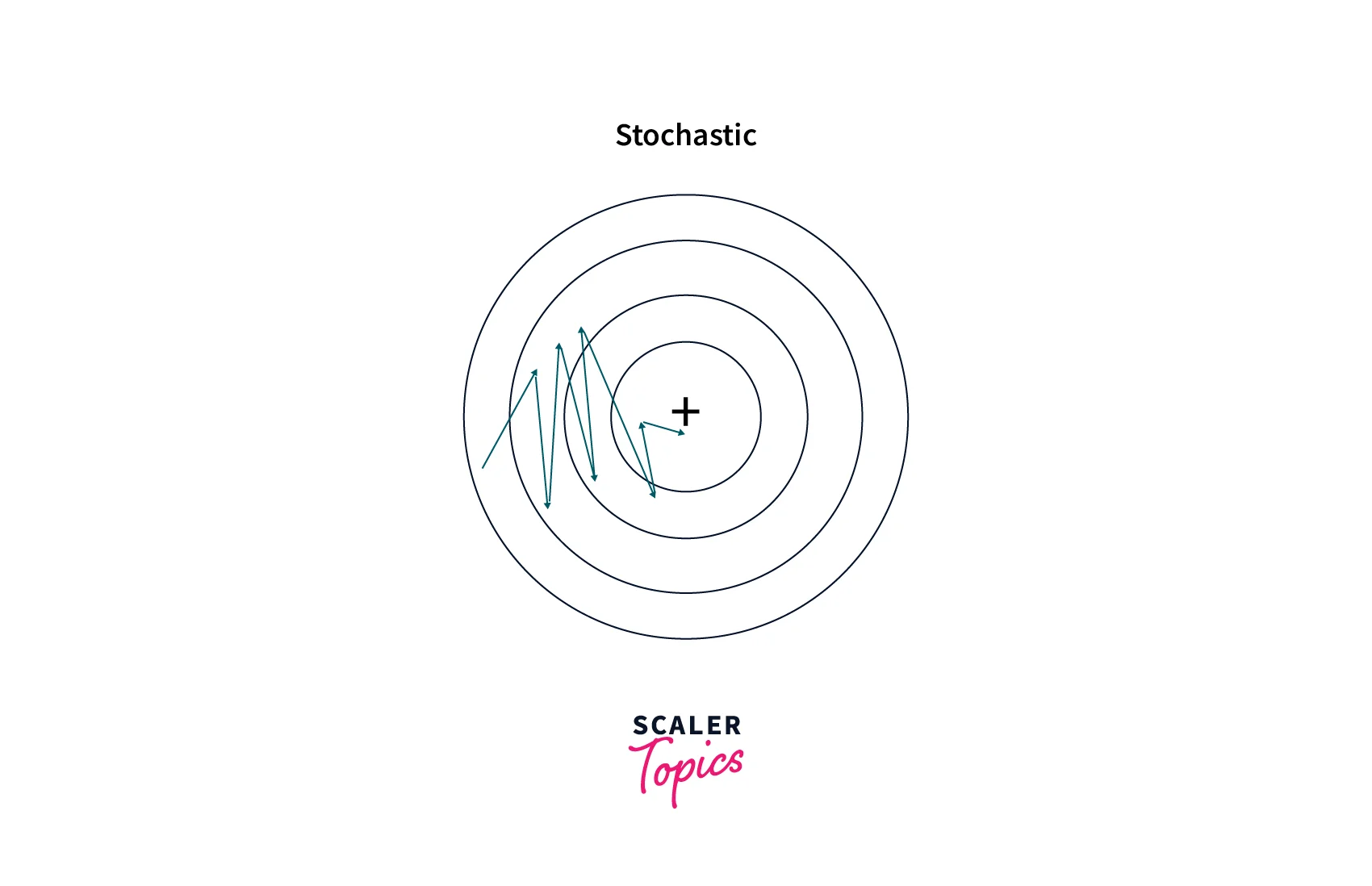
Stochastic gradient descent is an optimization algorithm used to find the values of parameters (coefficients and biases) in a machine learning model that minimize the loss function. It is a variant of gradient descent that uses only a single training example (a batch size of 1) per iteration to update the parameters.
Here is a small example of code for stochastic gradient descent in Python:
This is a very basic example of Stochastic Gradient Descent; in practice, it might need some modifications like the decay of learning rate, mini-batch size, momentum, etc.
It's worth noting that the above code snippet is for optimizing a simple quadratic function with scalar input; in practice, it will be used with much more complex functions with high-dimensional input.
Stochastic Gradient Descent (SGD) is faster than Batch Gradient Descent as it updates parameters using single examples, making it ideal for large-scale machine-learning problems. However, the updates can be noisy, leading to optimization instability. Thus a learning rate schedule or techniques like momentum or adaptive gradient can be used to mitigate this issue.
Adam Optimization Algorithm
Adam (Adaptive Moment Estimation) is an optimization algorithm used to update the parameters of a neural network. It combines the concepts of momentum and learning rate decay. Adam algorithm is an adaptive learning rate method that uses past gradients to scale the learning rate. This helps the algorithm to converge faster and more robustly. Adam algorithm is considered one of the best optimization algorithms for training deep neural networks.
Code Implementation
Here is an example of implementing the Adam algorithm in Python using the popular deep-learning library Keras.
The Adam optimizer compiles the model in this example, and the learning rate (lr) is set to 0.001. The model is then trained using the fit method with the specified batch size and the number of epochs.
Gradient Descent With Adam
Two-Dimensional Test Problem
First, let's define the test problem as a Python function:
Gradient Descent Optimization With Adam
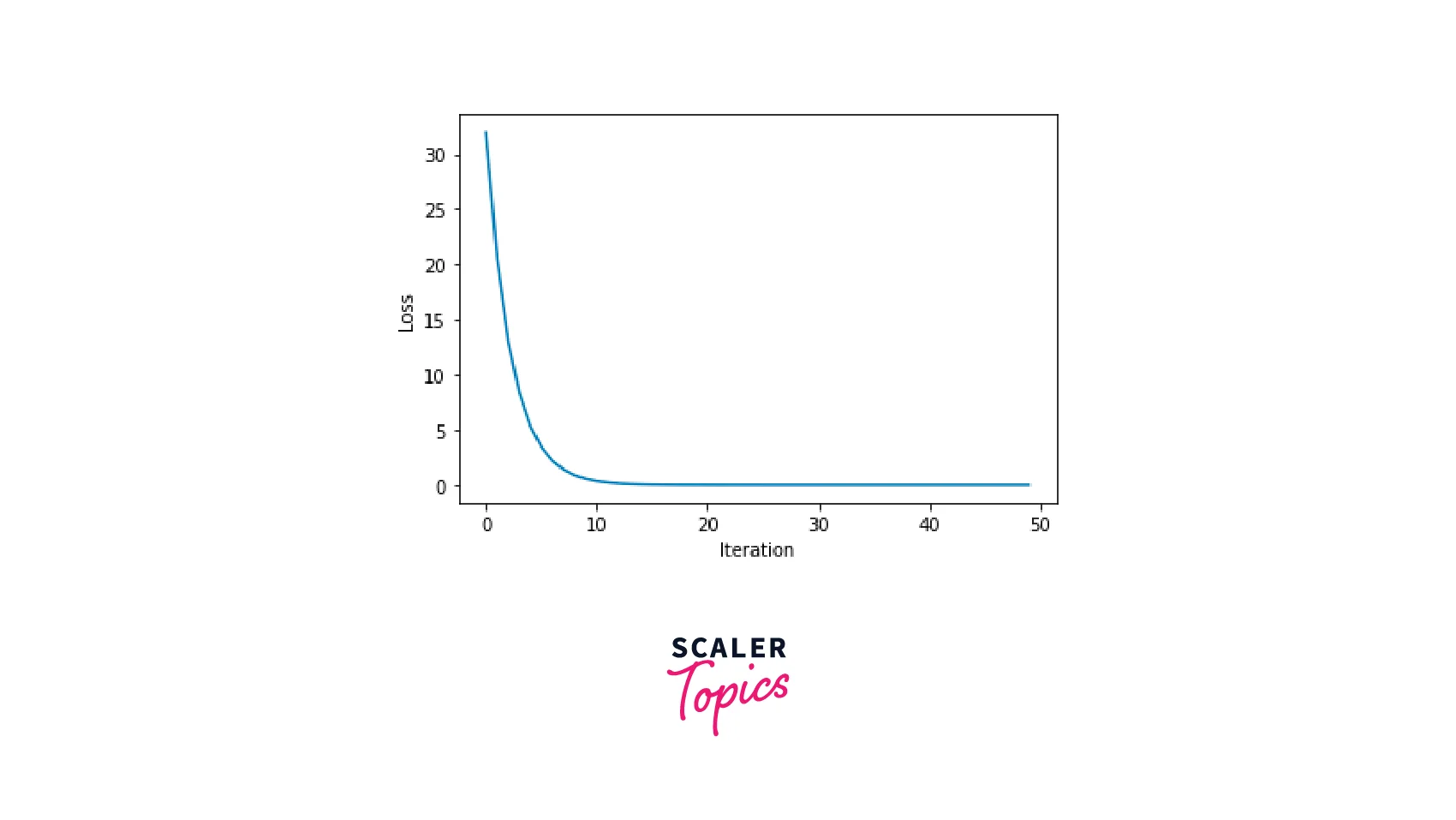
The plot generated by the given code is a line plot that shows the value of the loss function at each iteration of the optimization process. The x-axis represents the iteration number, and the y-axis represents the loss. As the optimization progresses, you should see the loss decrease over time.
Output
Visualization of Adam
This is a 3D surface plot showing the loss function over a range of values for the variables m and ``b```.
Output
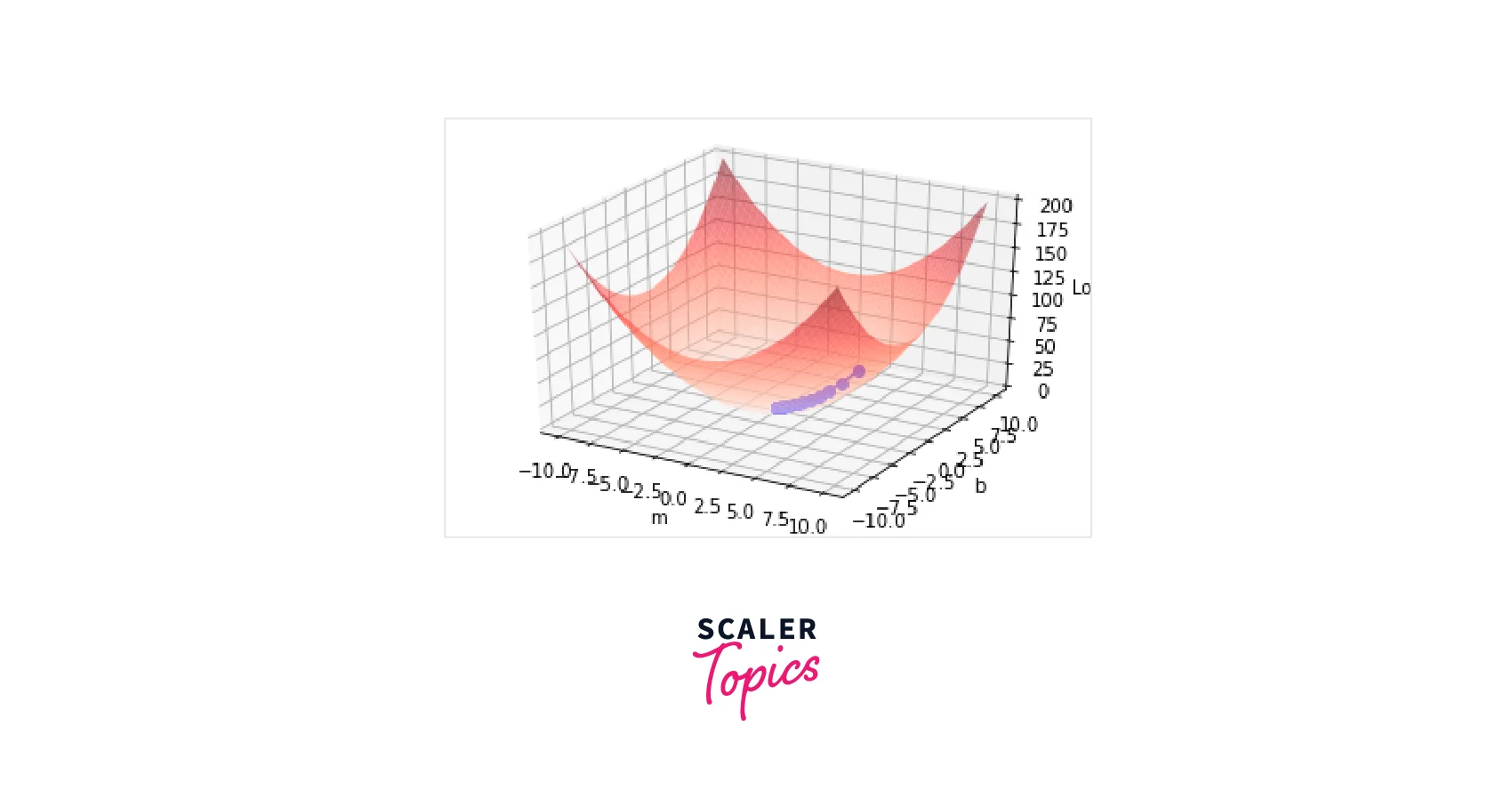 The x-axis represents m, the y-axis represents b, and the z-axis represents the loss. The plot's surface is colored according to the value of the loss, with red indicating high loss and blue indicating low loss.
The x-axis represents m, the y-axis represents b, and the z-axis represents the loss. The plot's surface is colored according to the value of the loss, with red indicating high loss and blue indicating low loss.
On top of the surface plot, a series of blue dots and lines are plotted, showing the algorithm's optimization path as it tries to find the minimum of the loss function. The dots represent the values of m and b at each iteration, and the lines connect the dots to show the progression of the optimization process.
Nadam Optimization Algorithm
The Nadam optimization algorithm is an extension of the Adam algorithm incorporating the Nesterov momentum term. It is designed to combine the benefits of both Adam and Nesterov momentum and has been shown to have faster convergence and better generalization performance in some cases.
The algorithm maintains exponential moving averages of the gradients and squared gradients, similar to Adam. It also maintains a moving average of the past gradients, which is used to compute the Nesterov momentum term. The update rule for the parameters is similar to Adam's but includes the Nesterov momentum term and bias correction for the moving averages of the gradients and squared gradients.
Code Implementation
Here is the complete code for the Nadam optimization algorithm
This function takes four arguments: x and yis the training data, learning_rate is the learning rate, and num_iterations is the number of iterations to run the optimization for. It returns the optimized values of the parameters m and b.
Conclusion
- Adam stands for Adaptive Moment Estimation and is a popular choice for optimizing neural network models.
- Adam algorithm combines the benefits of two other optimization algorithms: AdaGrad, which handles learning rates well, and RMSProp, which handles moving averages of the gradients.
- Adam algorithm uses an exponentially decaying average of past squared gradients to scale the learning rate, which helps the optimization converge more quickly.
- Adam also includes a bias-correction term in its updates to help mitigate the issue of diminishing learning rates, which can occur when training deep neural networks.