Artificial Intelligence Algorithms
In the rapidly evolving tech landscape, artificial intelligence (AI) has become a pivotal force driving innovation and efficiency. At the heart of AI's transformative power are artificial intelligence algorithms, sophisticated computational procedures that enable machines to learn from data, make decisions, and predict outcomes with astonishing accuracy.
What is Artificial Intelligence?
Artificial Intelligence (AI) is the technology that allows machines to mimic human intelligence, enabling them to think and learn. It includes various technologies that empower computers to process complex information, make decisions, and execute tasks traditionally needing human intellect, like interpreting visual cues, recognizing speech, making informed decisions, and translating languages. The goal of AI is to develop systems capable of adapting, enhancing their performance, and possibly functioning independently by leveraging sophisticated algorithms and extensive data processing.
What is an AI algorithm?
An AI algorithm is a computational formula or set of instructions designed to carry out tasks that typically require human-like intelligence. These tasks could range from recognizing patterns in data, making predictions based on past observations, to understanding natural language. AI algorithms are designed to sift through data, absorb the information, and utilize their newfound knowledge to make well-informed choices. This process is at the core of machine learning, where algorithms adjust and improve over time based on the data they process, without being explicitly programmed for each specific task.
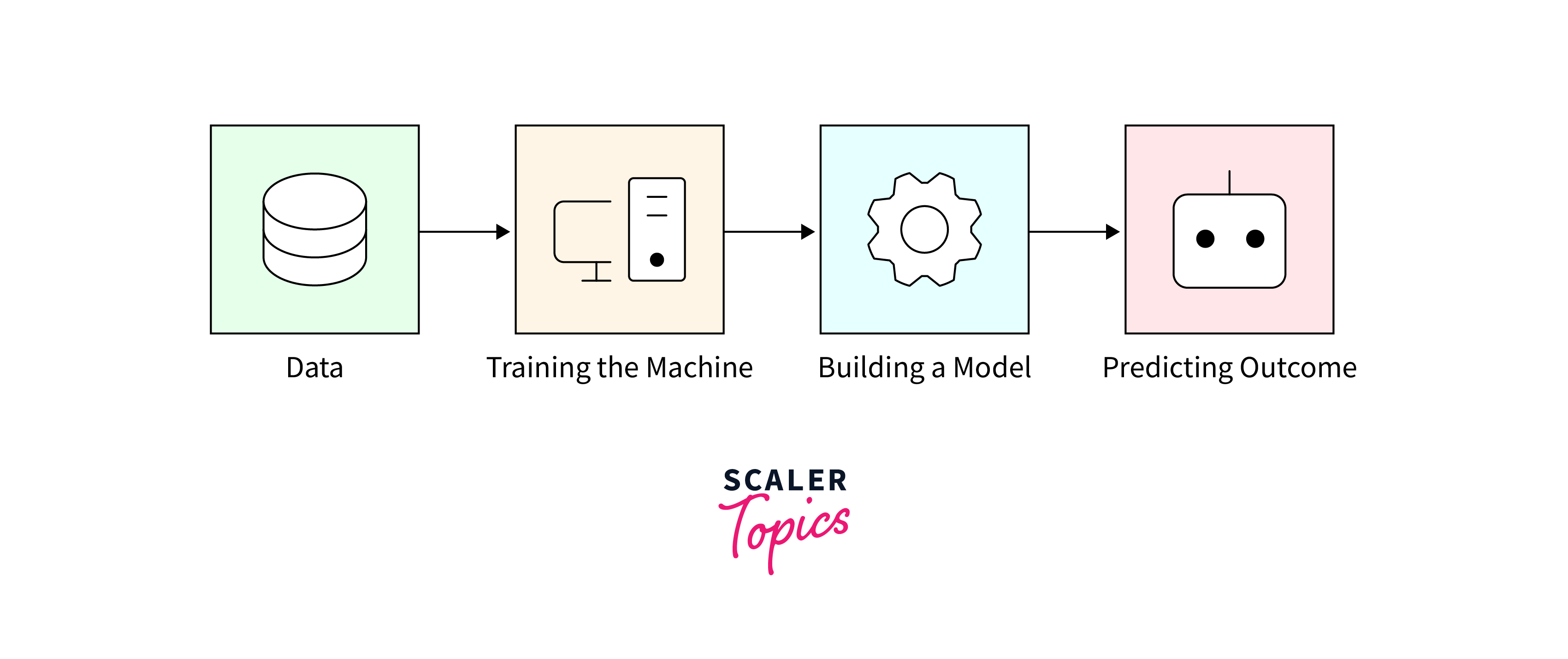
The power of AI algorithms lies in their ability to screen through vast amounts of data, identifying complex patterns and relationships that might not be immediately apparent to human analysts. By doing so, they can solve problems, optimize processes, and predict future trends with a high degree of accuracy. These algorithms can be tailored to a wide range of applications, from simple tasks like filtering spam emails to more complex ones like autonomous driving or personalized medicine, showcasing their versatility and importance in advancing AI technology.
How do AI algorithms work?
Artificial intelligence algorithms function by processing and analyzing vast datasets to identify patterns, infer correlations, and derive insights that guide decision-making processes. Initially, these algorithms are trained using large sets of data, where they learn to recognize patterns and relationships within the data.During this learning stage, the algorithms build models capable of making forecasts or decisions about new data that they haven't encountered before. The training process involves adjusting the algorithm's parameters until it achieves the desired level of accuracy and efficiency in its task.
Once trained, artificial intelligence algorithms can apply their learned models to new data, making predictions or decisions with a degree of autonomy. This ability to learn from data and improve over time is what distinguishes AI algorithms from traditional static algorithms. They continuously refine their models through a process known as machine learning, where the algorithm's performance improves as it is exposed to more data. This iterative learning process enables AI algorithms to adapt to new data and evolving conditions, making them incredibly powerful tools for a wide range of applications, from natural language processing and image recognition to complex decision-making systems.
Types of AI algorithms
Artificial intelligence algorithms can be broadly categorized based on their learning approach and the type of problem they are designed to solve. The main types include:
-
Supervised Learning: This method utilizes algorithms trained on data with predefined labels, where each input is matched with its correct output, enabling the algorithm to learn how to predict outcomes based on input data. Supervised learning is frequently applied to tasks like classification, where the algorithm sorts inputs into various categories, and regression, where it forecasts a continuous quantity.
-
Unsupervised Learning: It algorithms work with unlabeled data, finding hidden patterns or intrinsic structures in input data. These algorithms are used for clustering, dimensionality reduction, and association tasks, where the algorithm organizes the data into clusters, reduces the number of variables, or identifies rules that describe large portions of the data.
-
Semi-supervised Learning: It Semi-supervised learning falls between supervised and unsupervised learning. It uses a small amount of labeled data and a large amount of unlabeled data for training. This approach leverages the labeled data to guide the learning process in the right direction, making it useful when acquiring labeled data is expensive or time-consuming.
-
Reinforcement Learning: It algorithms learn by interacting with an environment. They make decisions, receive feedback in terms of rewards or penalties, and then adjust their actions accordingly. This type of learning is suitable for sequential decision-making problems, such as game playing or robotic navigation, where the algorithm learns to achieve a goal in an uncertain, potentially complex environment.
Supervised learning
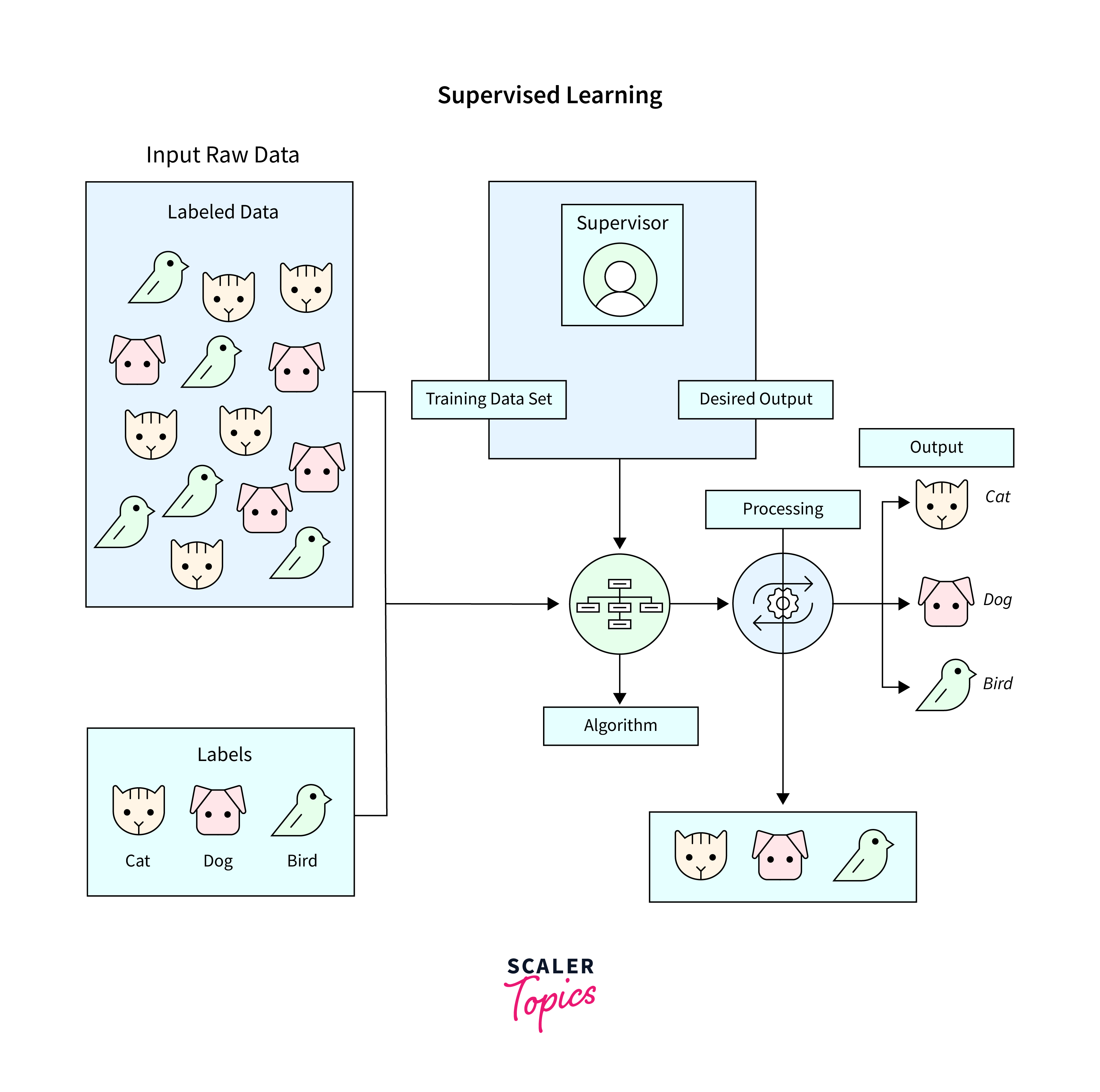
Supervised learning is a cornerstone methodology within the realm of artificial intelligence algorithms, where the model is trained on a labeled dataset. This labeled dataset provides the algorithm with example inputs and their corresponding outputs, enabling it to learn how to predict the output from new, unseen inputs.
Definitions: Classification and Regression
In the context of supervised learning, artificial intelligence algorithms are primarily divided into two categories: classification and regression.
- Classification involves categorizing data into predefined classes or groups. The aim is for the algorithm to correctly identify which category new data will fall into based on its training.
- Regression deals with predicting a continuous quantity. Here, the algorithm must determine a value within a continuous range, such as prices or temperatures, based on the input data.
Use Cases of Classification:
- Email Spam Detection: Classifying emails as spam or not spam based on content, sender, and other attributes.
- Customer Churn Prediction: Identifying customers likely to stop using a service, enabling businesses to take preventive actions.
Use Cases of Regression:
- House Price Prediction: Estimating the selling price of a house based on features like size, location, and number of bedrooms.
- Sales Forecasting: Predicting future sales volumes based on historical data, market trends, and promotional activities.
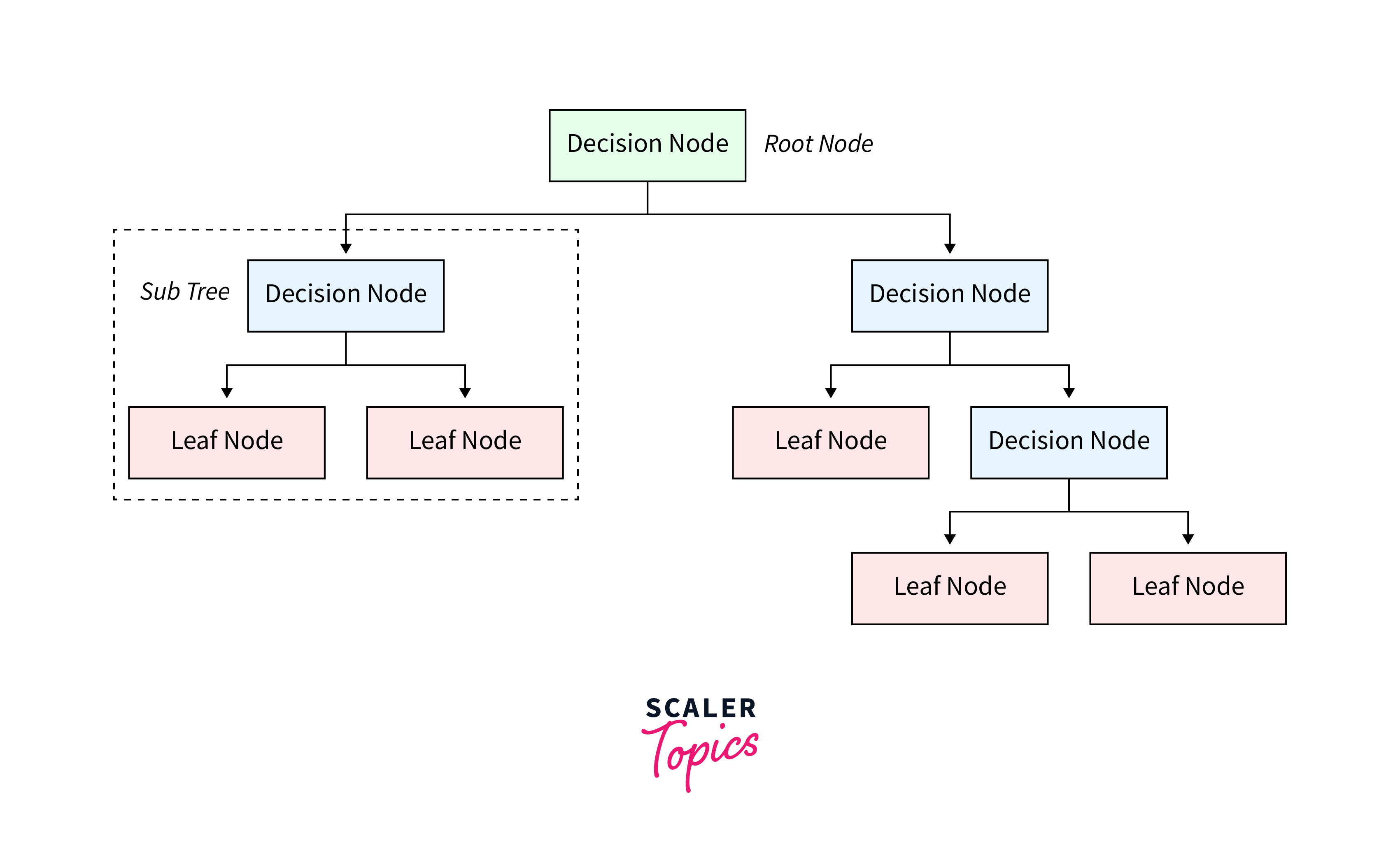
Decision Tree
A Decision Tree resembles a flowchart, with each internal node symbolizing a test on a feature, every branch denoting the test's result, and each leaf node indicating a category label. Artificial intelligence algorithms that employ decision trees arrive at decisions by moving from the tree's root down to its leaves, offering straightforward and understandable rules for classification.
Use Cases:
- Credit Risk Assessment: Classifying loan applicants as low, medium, or high risk based on financial attributes.
- Medical Diagnosis: Diagnosing diseases by analyzing patients' symptoms and test results through branching decision paths.
Random Forest
Random Forest improves upon the decision tree method by creating an ensemble of decision trees, typically trained with the "bagging" method. This approach involves training each tree on a random subset of the data and then averaging the predictions to improve accuracy and control over-fitting, making it a robust artificial intelligence algorithm for a wide range of tasks.
Use Cases:
- Fraud Detection: Identifying fraudulent activities in banking and financial transactions by analyzing patterns and anomalies.
- Image Classification: Categorizing images into different groups (e.g., animals, landscapes) based on their features using ensemble learning for improved accuracy.
Support Vector Machines
Support Vector Machines (SVM) stand out as robust artificial intelligence algorithms applicable to classification and regression challenges. The core principle of SVMs involves identifying the optimal hyperplane that distinctly divides various categories within the feature space, ensuring the greatest possible margin between the nearest points of these categories, referred to as support vectors.
Use Cases:
- Face Detection: Identifying and categorizing faces in images by differentiating face and non-face regions.
- Text and Hypertext Categorization: Classifying text documents or web pages into predefined categories based on their content.
Naive Bayes
The Naive Bayes algorithm utilizes Bayes' theorem, operating under the simplistic premise that each pair of features is conditionally independent. This straightforward approach allows Naive Bayes to achieve impressive effectiveness, making it especially valuable for text classification purposes, like identifying spam emails.
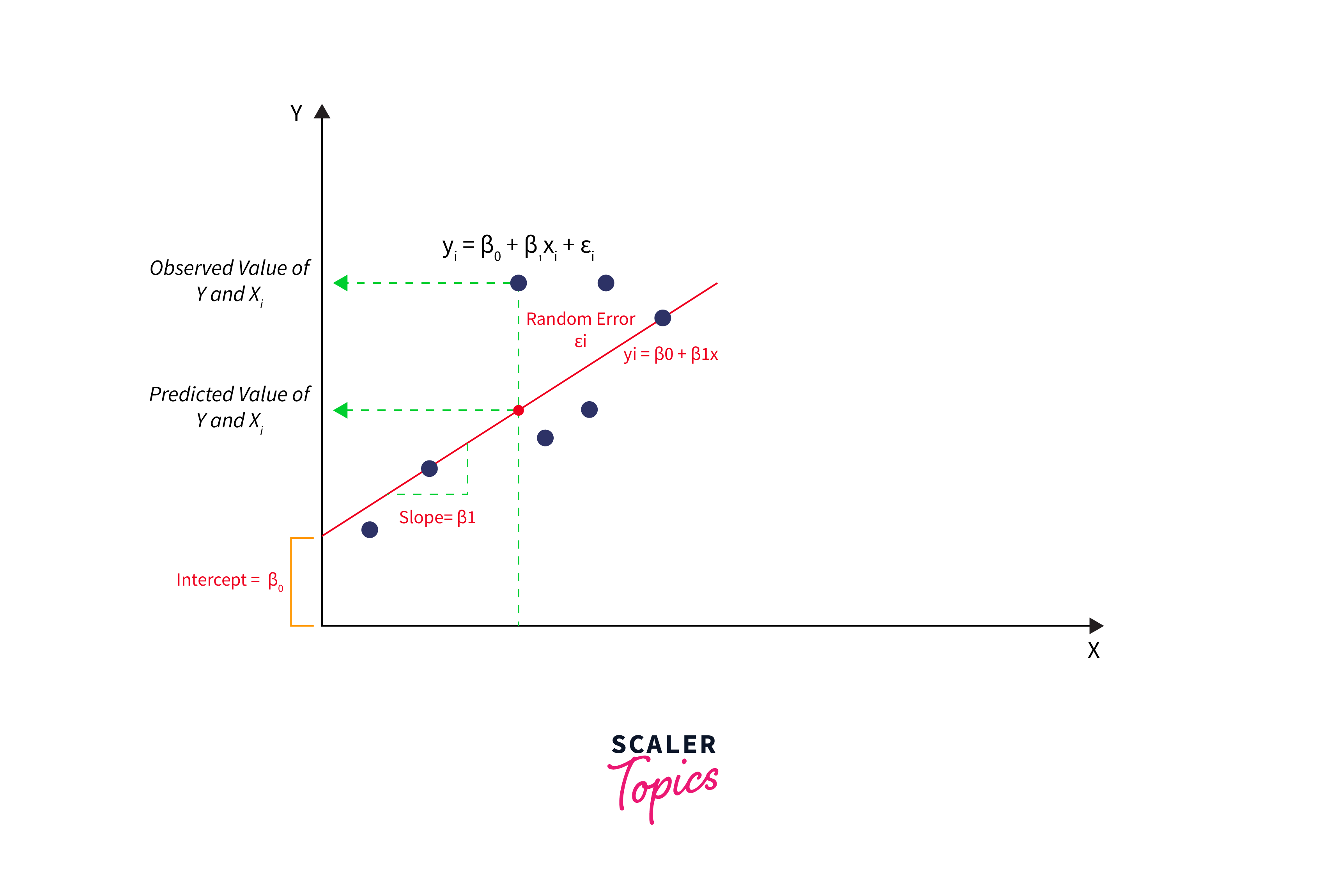
Linear Regression
As one of the most fundamental artificial intelligence algorithms within supervised learning, linear regression is predominantly employed for regression challenges. It establishes the connection between a dependent variable and one or several independent variables by applying a linear equation to the data collected.
Logistic Regression
Despite its name, logistic regression is used for binary classification tasks rather than regression. It estimates probabilities using a logistic function, which is especially useful for cases where you need to classify inputs into two possible outcomes, such as spam or not spam.
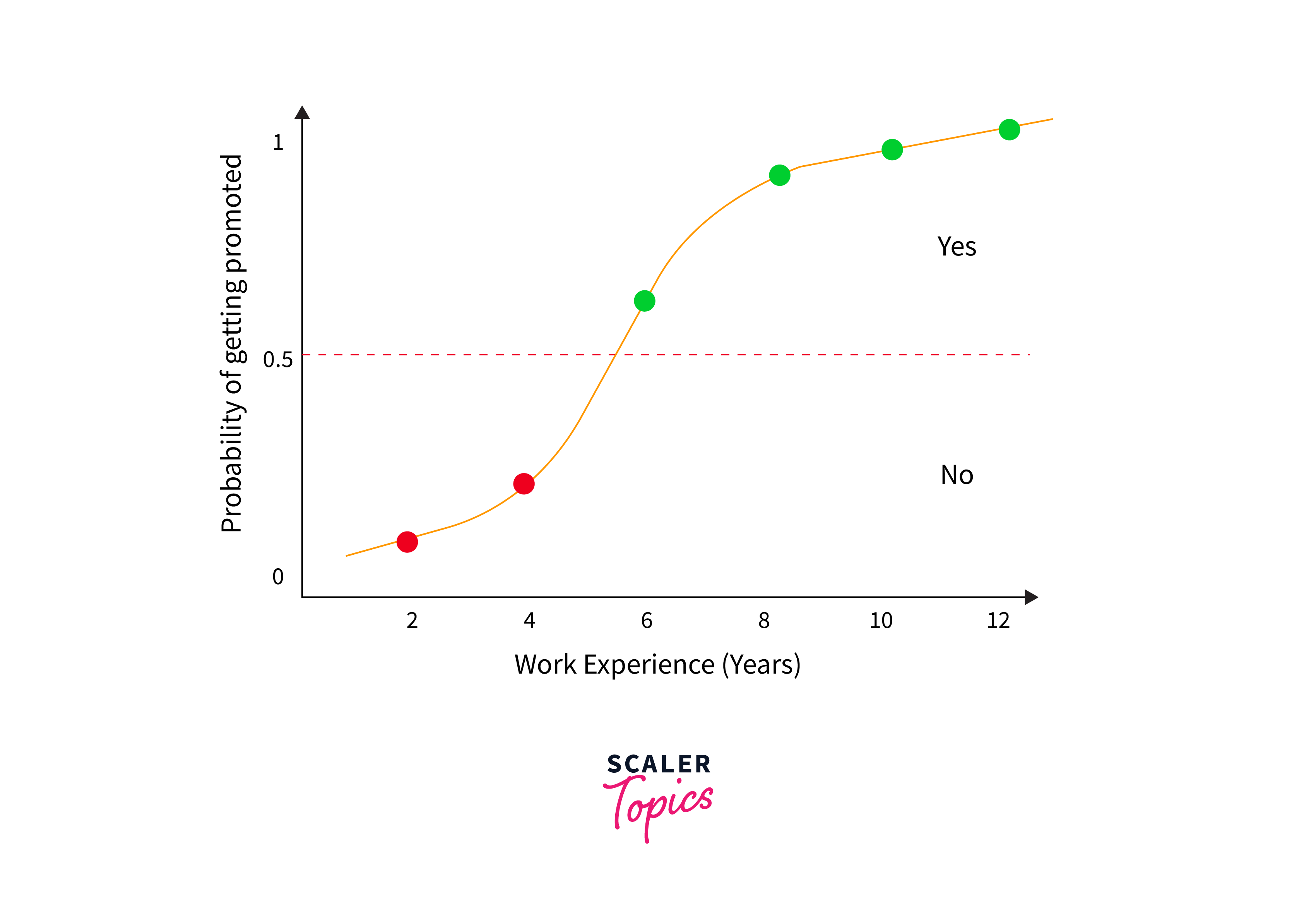
Use Cases:
- Marketing Campaign Effectiveness: Predicting the likelihood of a customer responding positively to a campaign.
- Disease Prediction: Estimating the probability of a patient having a certain disease based on risk factors.
Unsupervised learning
Unsupervised learning is a critical area in the field of artificial intelligence algorithms where the system learns patterns from untagged data. The goal is to explore the underlying structure or distribution in the data to learn more about it. Unlike supervised learning, unsupervised learning algorithms do not require labeled outcomes, making them particularly useful for exploratory data analysis, dimensionality reduction, and more.
Definition: Clustering
Clustering is a principal technique in unsupervised learning used by artificial intelligence algorithms to group a set of objects in such a way that objects in the same group (or cluster) are more similar to each other than to those in other groups. It's widely used in statistical data analysis for various applications, such as market research, pattern recognition, and image processing.
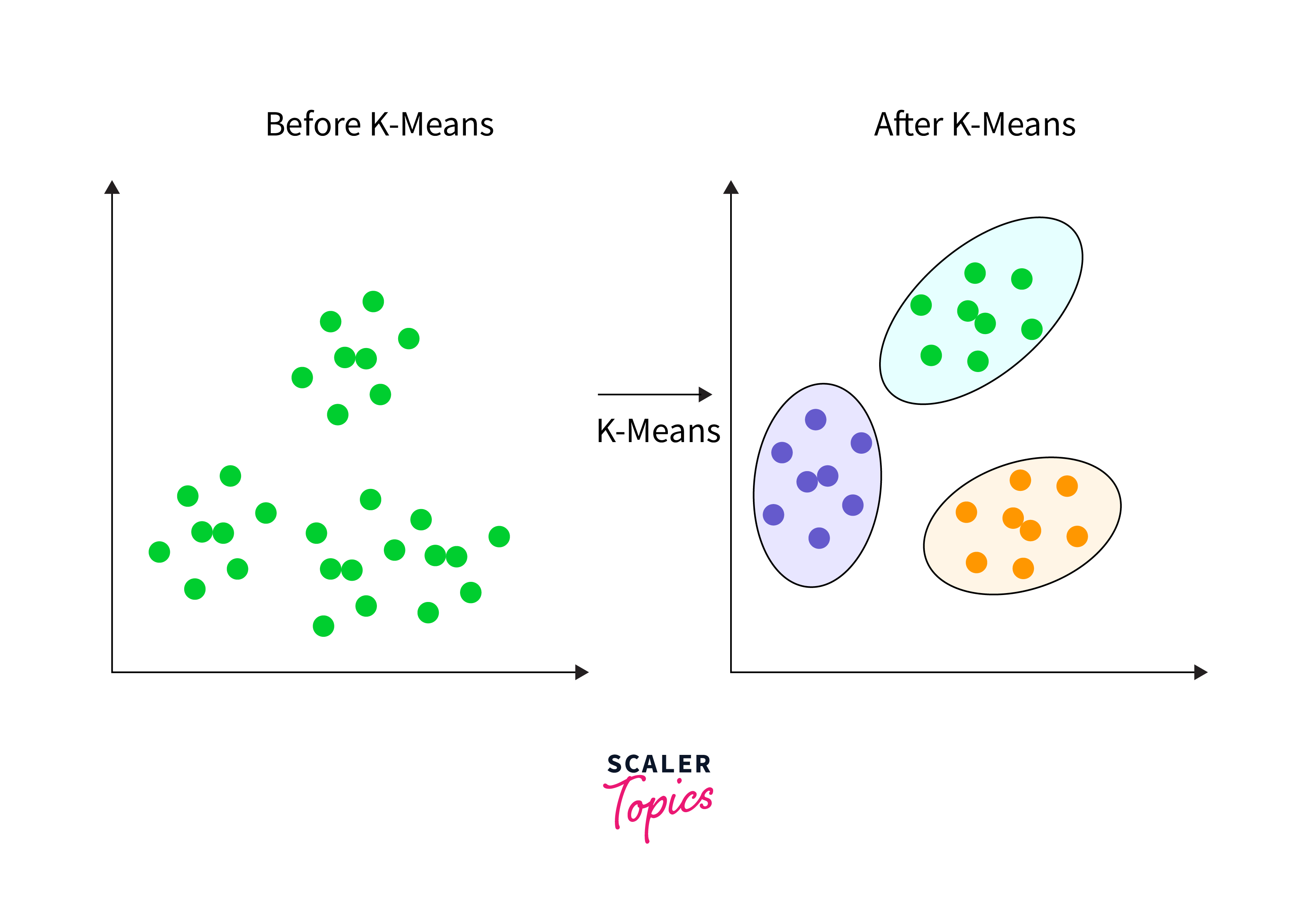
K-means Clustering
K-means clustering is simple and one of the most popular clustering algorithms used in artificial intelligence. Its objective is to divide n data points into k groups, ensuring that each point is assigned to the group whose mean is closest, effectively making that mean the representative of the group. This algorithm is particularly effective in cases where the data is clearly defined and well separated.
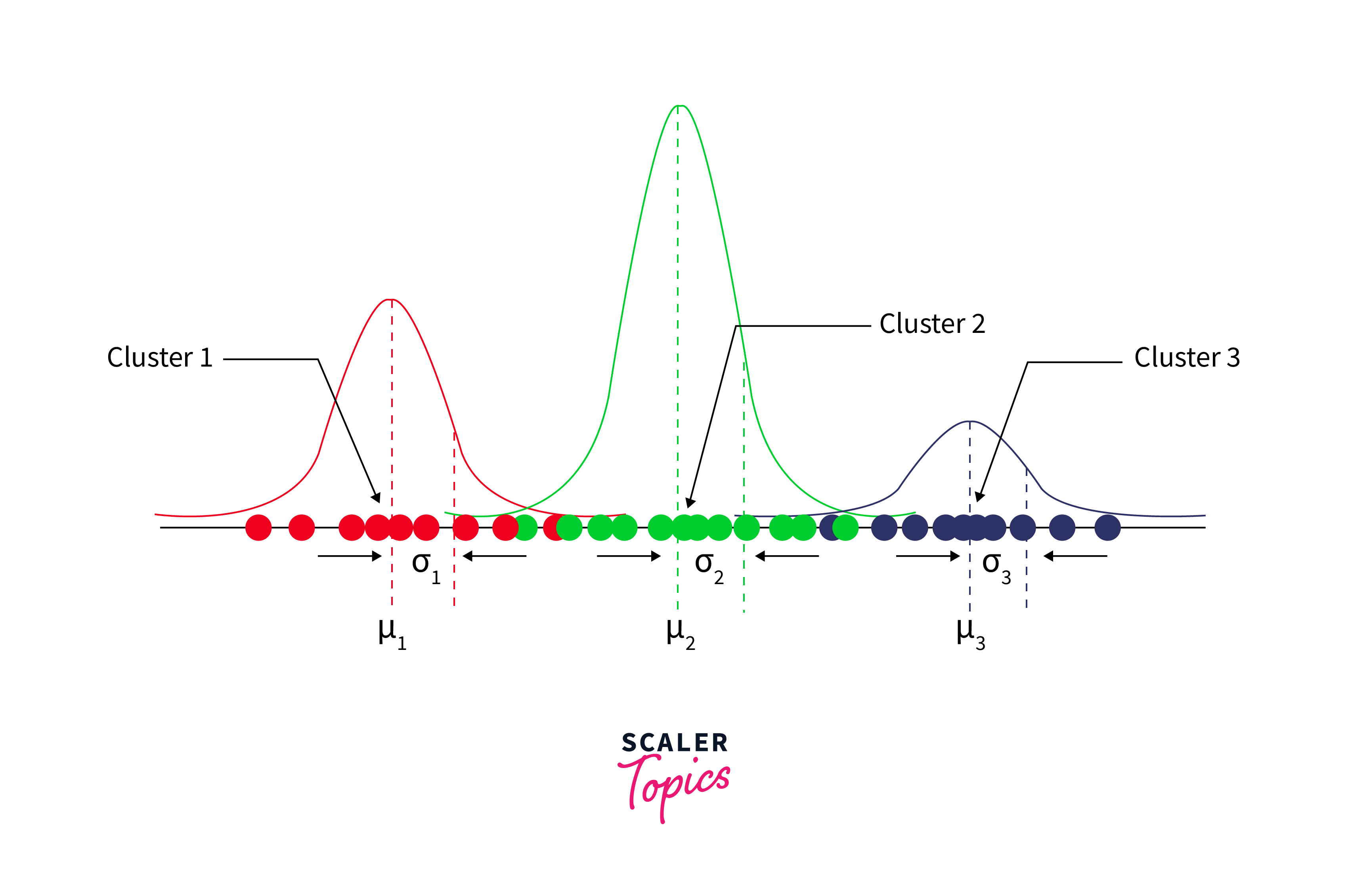
Gaussian Mixture Model
The Gaussian Mixture Model (GMM) is a more sophisticated approach compared to K-means. It assumes that the data is generated from a mixture of several Gaussian distributions with unknown parameters. GMMs are used in artificial intelligence algorithms not just for clustering but also for density estimation. Unlike K-means, GMMs can incorporate the covariance structure of the data as well as the centers of the latent Gaussians, providing a more flexible approach to clustering.
Use Cases:
- Customer Segmentation: Grouping customers into clusters based on purchasing behavior and preferences for targeted marketing.
- Anomaly Detection: Identifying unusual data points in datasets, such as fraudulent financial transactions or abnormal system behavior.
Both supervised and unsupervised learning
In the realm of artificial intelligence algorithms, both supervised and unsupervised learning methods play pivotal roles. Among these, the K-nearest neighbor algorithm and Neural Networks stand out for their versatility and wide-ranging applications across both learning paradigms.
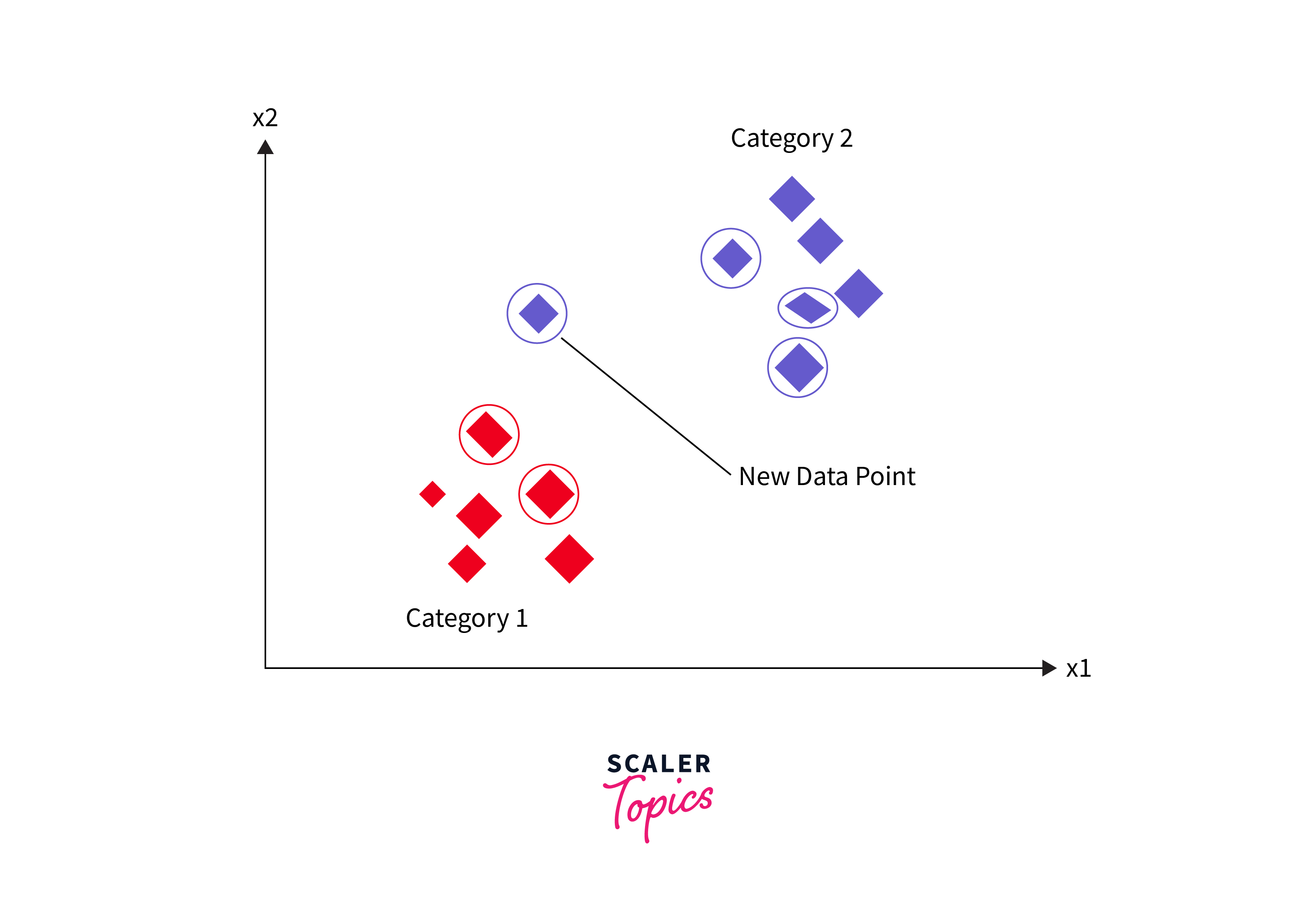
K-nearest Neighbor Algorithm
The K-nearest neighbor (KNN) algorithm is a simple, yet powerful tool in the artificial intelligence algorithms toolkit, applicable in both supervised and unsupervised learning contexts. In supervised learning, KNN is used for classification and regression tasks. It operates on a simple principle: for a given input, the algorithm finds the 'k' closest training examples in the feature space and predicts the output based on the majority label (for classification) or the average of the labels (for regression) of these neighbors. In unsupervised learning, KNN is utilized for clustering, determining the natural grouping of data based on similarity measures. The simplicity of KNN, coupled with its effectiveness, makes it a widely used algorithm in AI.
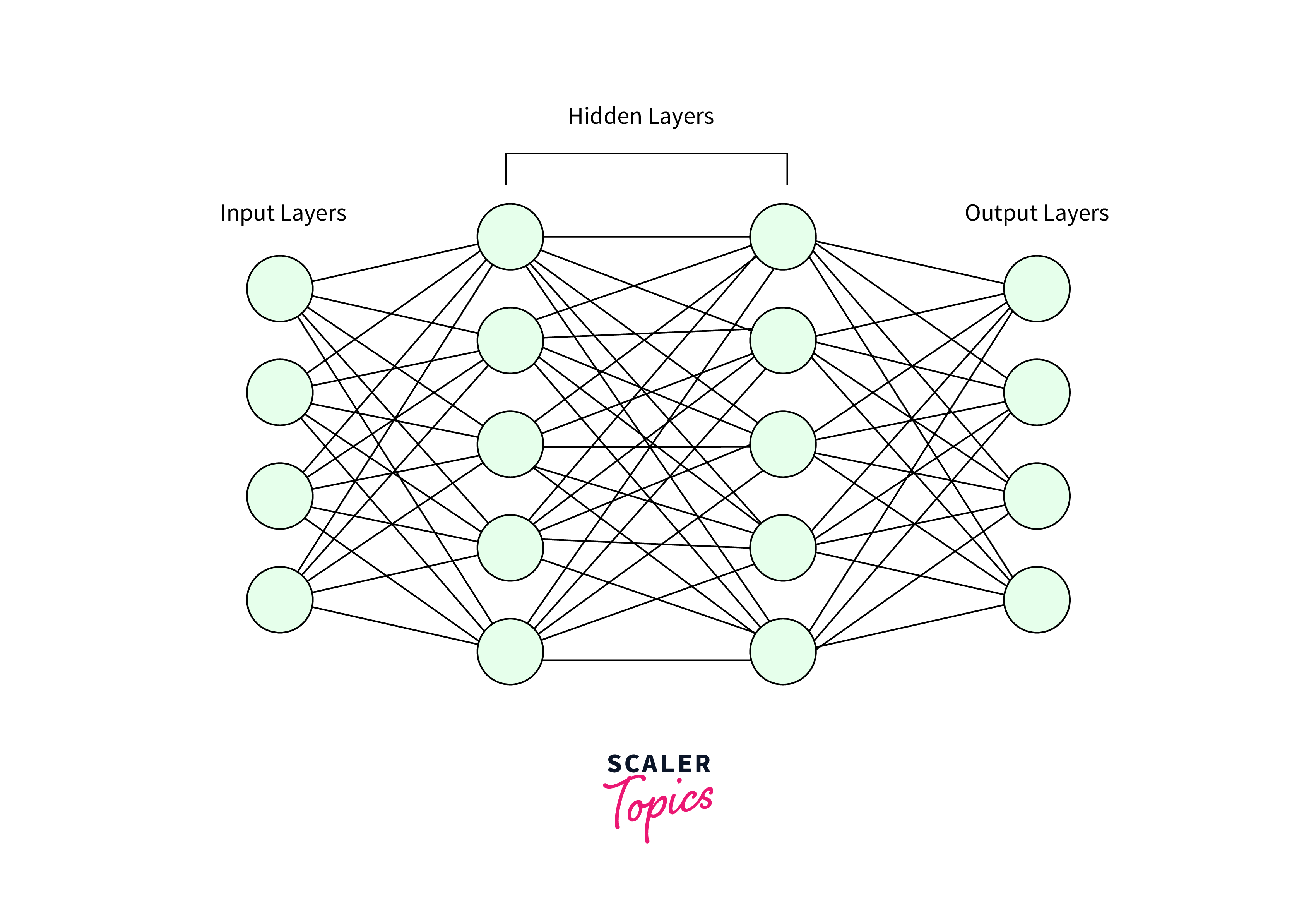
Neural Networks
Neural Networks, particularly deep learning models, are at the forefront of many breakthroughs in artificial intelligence algorithms. These models are inspired by the biological neural networks in the human brain, consisting of layers of interconnected nodes or "neurons" that process information. In supervised learning, Neural Networks are trained with labeled data, adjusting the weights of connections to minimize the difference between actual and predicted outputs. This capability allows them to excel in complex tasks like image and speech recognition, natural language processing, and more. In unsupervised learning, Neural Networks can be used in deep learning models like autoencoders, which learn efficient data codings in an unsupervised manner, useful for dimensionality reduction and feature learning.
Reinforcement learning
Reinforcement learning represents a unique framework in the realm of artificial intelligence algorithms, centered on the strategy agents should employ to act within an environment, aiming to maximize a cumulative reward. Distinct from both supervised and unsupervised learning, reinforcement learning is marked by an absence of direct oversight and requires agents to undertake a series of decision-making steps. Imagine teaching a robot to navigate a maze; the robot doesn't know the path initially but learns by trying different routes. Each time the robot moves closer to the exit, it receives a "reward" (a positive signal), and each time it hits a dead end, it gets a "penalty" (a negative signal).
Over many attempts, the robot identifies patterns in which actions lead to rewards and which to penalties. Gradually, it forms a strategy or 'policy' that maximizes its rewards, effectively learning the best path through the maze. This process of trial, error, and reward is at the heart of reinforcement learning, enabling machines to learn from their interactions with the environment and improve their performance over time without being explicitly programmed with the correct path.
Definitions: Model, Policy, Value
- Model: In reinforcement learning, the model represents the environment. It is the agent's understanding of how the environment behaves, encompassing the probabilities of reaching a new state given the current state and an action.
- Policy: The policy outlines the approach an agent uses to decide on its subsequent move, considering the present state. This strategy could be deterministic, with actions directly correlated to specific states, or stochastic, involving actions selected according to a probability distribution.
- Value: The value function estimates how good it is for the agent to be in a given state or how good it is to perform a certain action in a state. The value essentially reflects the expected long-term reward for state-action pairs, guiding the agent's decisions.
Value-based
Value-based methods focus on optimizing the value function without explicitly defining a policy. The agent learns the value of each action in a given state and chooses actions based on these value estimates. Algorithms like Q-learning and Deep Q-Networks (DQN) fall under this category, where the primary goal is to learn the optimal value function.
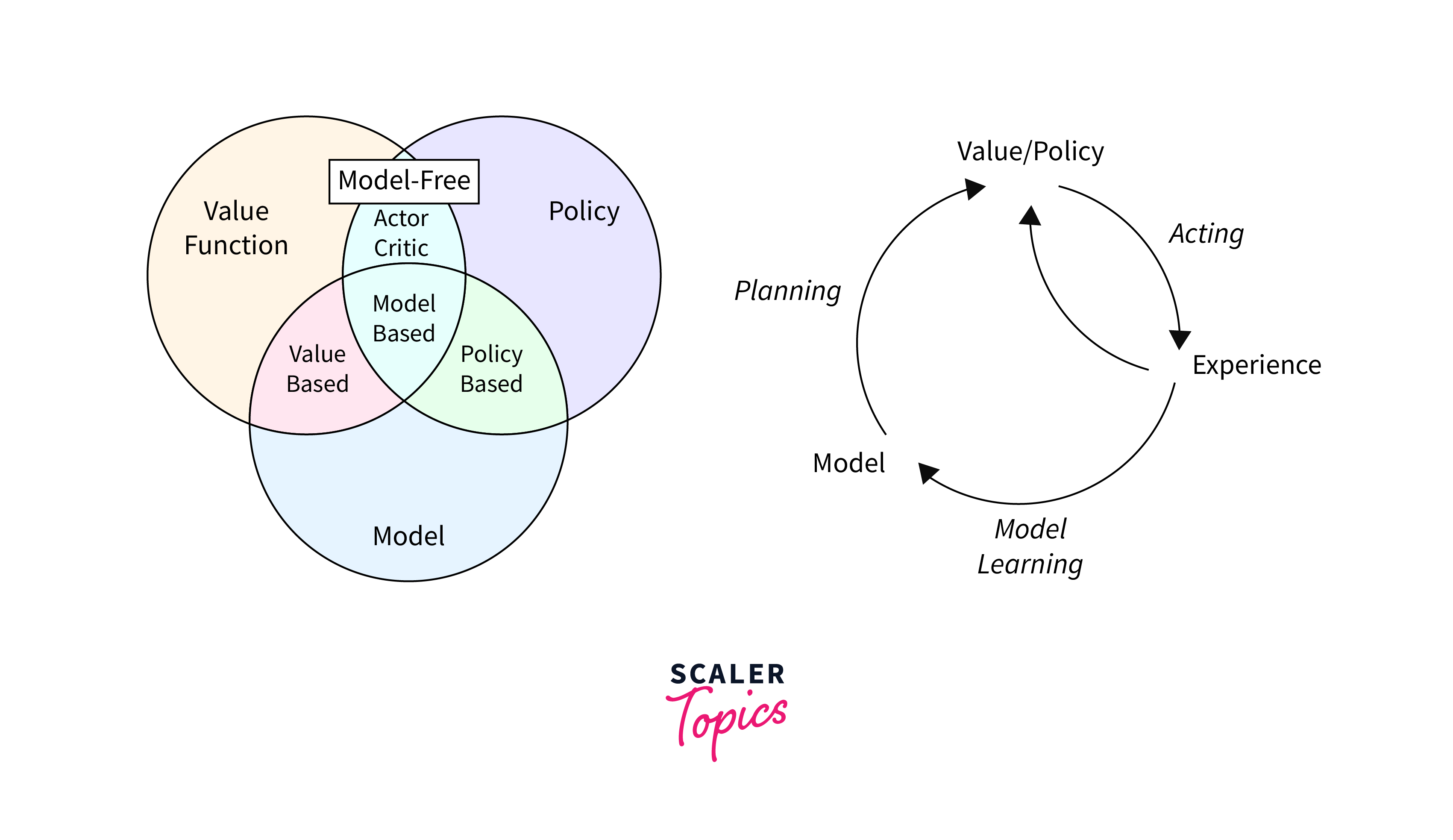
Policy-based
Policy-based methods directly learn the policy that maximizes the cumulative reward without needing a value function as an intermediary. These methods are particularly useful in high-dimensional or continuous action spaces. Techniques such as Policy Gradients work by adjusting the parameters of the policy in a direction that increases the expected rewards.
Model-based
Model-based reinforcement learning involves the agent learning or using a model of the environment to plan. By understanding how actions affect the environment, the agent can predict future states and make informed decisions. This approach can be more sample efficient, as the agent can "imagine" or simulate future states without needing to explore them through actual interactions, which can be time-consuming or costly.
Uses of AI algorithms
Artificial intelligence algorithms are instrumental in various domains, offering innovative solutions and enhancing efficiency:
- Enhancing Customer Experiences: AI algorithms personalize user experiences in retail and online services, providing tailored recommendations and customer support through chatbots.
- Improving Healthcare Diagnostics: In healthcare, AI algorithms assist in early disease detection and diagnosis through advanced image analysis, contributing to more accurate and timely treatments.
- Optimizing Supply Chains: They streamline logistics and inventory management in supply chains, predicting demand and optimizing routes to reduce costs and improve efficiency.
- Advancing Autonomous Technology: AI algorithms are crucial in developing self-driving cars, enabling them to interpret sensor data for safe navigation and decision-making on the roads.
- Facilitating Scientific Research: In research, AI algorithms accelerate discoveries by analyzing data, predicting experiment outcomes, and simulating complex scientific processes.
- Safeguarding Financial Transactions: In finance, they detect fraudulent activities and manage risk by analyzing transaction patterns and customer behavior.
AI algorithms and business
Artificial intelligence algorithms have become a transformative force in the business world, reshaping industries and creating new opportunities for innovation and efficiency. Their integration into various business operations and strategies has led to significant competitive advantages, improved customer experiences, and operational efficiencies.
- Customer Relationship Management: AI algorithms analyze customer data to provide personalized experiences, product recommendations, and targeted marketing, enhancing customer engagement and loyalty.
- Operational Efficiency: AI algorithms automate everyday tasks and refine processes, liberating human resources for higher-level strategic work, thereby cutting expenses and boosting productivity.
- Informed Decision-Making through Data: AI algorithms sift through extensive datasets to reveal key insights, trends, and patterns, empowering businesses to make well-informed choices and discover potential new markets.
- Supply Chain Optimization: From forecasting demand to managing inventory and optimizing delivery routes, AI algorithms enhance the efficiency and responsiveness of supply chains.
- Fraud Detection and Risk Management: In the financial sector, AI algorithms are pivotal in identifying fraudulent transactions and assessing credit risks, protecting businesses and consumers alike.
Conclusion
- AI algorithms are capable of addressing a wide range of problems, from simple classification tasks to complex decision-making processes, showcasing their adaptability to different domains and challenges.
- Through mechanisms like supervised, unsupervised, and reinforcement learning, these algorithms continuously learn from data, enhancing their accuracy and efficiency over time.
- Across sectors such as healthcare, finance, autonomous driving, and environmental protection, AI algorithms are transforming industries with creative solutions and enhancing the efficiency of operations.
- By analyzing vast amounts of data, AI algorithms enable businesses and organizations to make better decisions, uncover new opportunities, and better understand their customers.
- The ongoing development and refinement of AI algorithms promise even greater advancements and potential applications, suggesting a future where AI's role in solving complex problems and enhancing human capabilities is bound to expand.