An Introduction To Document AI
Overview
In this article, we will learn about Google Document AI, a cloud-based document-processing AI tool developed by Google. We will also see how it uses advanced technologies such as computer vision and natural language processing to extract data from various types of documents, including text, images, and tables. This platform supports several types of data, including text, document overview information, key-value pairs, and table extractions. Google Document AI can be used for a wide range of applications, including personal and business use cases like resume analysis, language translation, invoice processing, etc.
What is Google Document AI?
Google Document AI is a cloud-based document processing tool, having use cases like OCR, document classification, data extraction etc. It is designed to extract data from various types of documents, including text, images, and tables, using advanced technologies such as computer vision and natural language processing.
The platform supports several types of data, including text, document overview information, key-value pairs, and table extractions. Google Document AI can be used for a wide range of applications, including personal and business use cases. The technology behind Google Document AI leverages machine learning algorithms to improve accuracy and automate the data extraction process.
It is a powerful tool for automating document processing workflows, saving time and resources, and increasing productivity.
Document AI includes several tools, such as:
- Document Understanding AI: It is a set of APIs that can be used to analyze documents and extract information from them. This can help automate tasks such as invoice processing, contract analysis, and form processing.
- Form Parser: It is an AI model that can be trained to extract data from PDF forms, speeding up the process of collecting and analyzing data.
- Procurement DocAI: It is an AI-powered tool designed to help automate procurement processes by analyzing invoices, purchase orders, and other procurement-related documents.
- Document AI Platform: The Document AI platform provides a unified interface and infrastructure to build, deploy, and manage document processing workflows. It offers pre-trained models and custom model training capabilities to suit specific document processing needs.
- AutoML Document AI: This feature empowers organizations to build custom machine-learning models for document analysis. AutoML Document AI allows for training models specific to document classification, entity extraction, and other document understanding tasks.
- Scalability and Security: Google Document AI is built on Google Cloud's robust infrastructure, offering scalability and reliability for processing large volumes of documents. It also prioritizes security, ensuring that documents and extracted data are protected through encryption and access control mechanisms.
Getting Started with Document AI
To get started with Google Document AI, you will need to follow these steps:
- Create a Google Cloud account: If you do not already have a Google Cloud account, you will need to create one to access Document AI. You can sign up for a free trial or choose a paid plan based on your business needs.
- Enable the Document AI API: Once you have created a Google Cloud account, you will need to enable the Document AI API. This can be done through the Google Cloud Console.
- Set up authentication: To use the Document AI API, you will need to authenticate your requests. This can be done using an API key or by setting up OAuth 2.0 authentication.
- Upload your documents: You can upload your documents to Google Cloud Storage or provide a URL to a publicly accessible document. Google Document AI supports a wide range of file formats, including PDF, PNG, and TIFF.
- Choose a processing option: Google Document AI provides several processing options, including document text detection, document structure analysis, and entity extraction. Choose the option that best suits your needs.
- Process your documents: Once you have selected your processing option, you can start processing your documents using the Document AI API. The platform will automatically extract and analyze the relevant data from your documents, providing you with structured data that can be used in other applications.
Overall, getting started with Google Document AI is a straightforward process that requires a Google Cloud account, API activation, authentication, document uploading, and processing. The platform provides a range of processing options and supports a wide range of file formats, making it a flexible and powerful tool for automating document processing workflows.
Types of Data Supported by Google Document AI
Different types of data are supported by Google Document AI for processing and analysis. Text is the first type, and it can be taken from a variety of sources, including scanned papers, photos, and PDF files.
The second piece of information is a document's overview, which includes metadata like the title, author, and creation date. Key-value pairs and table extractions, which entail locating and removing data from structured documents like invoices and receipts, are the third category.
The automation of numerous business activities, including data entry, document management, and financial analysis, depends on these data types. Document AI gives businesses a strong tool for increasing productivity and efficiency by supporting a variety of data sources. Let us see them one by one.
Text
Google Document AI supports text extraction from various types of documents using OCR technology. Here are some more details about text extraction in Document AI:
- Language Detection: Document AI can automatically detect the language of the text in a document. This is important because it allows Document AI to accurately extract and analyze text in different languages.
- Handwriting Recognition: Document AI can recognize both printed and handwritten text in a document. This allows for more flexibility in the types of documents that can be processed, such as forms and handwritten notes.
- Text Normalization: Document AI can normalize the text extracted from a document, which means it can convert the text to a standardized format. This can help improve accuracy and consistency when analyzing or processing the text.
- Text Classification: Document AI can classify the extracted text into different categories, such as names, addresses, or phone numbers. This can be useful in tasks such as contact information extraction or sentiment analysis.
Document Overview Information
It is another type of data supported by Google Document AI. Here are some more details about this feature:
- Document Language Detection: Document AI can automatically detect the language of a document, which is useful for accurately processing and analyzing the document.
- Page Count: Document AI can count the number of pages in a document. This can be useful for tasks such as document splitting or pagination.
- Orientation Detection: Document AI can detect the orientation of a document, whether it's landscape or portrait. This can help ensure that the document is processed correctly.
- Image Extraction: Document AI can extract images from a document, which can be useful for further analysis or processing. For example, if a document contains a chart or a graph, the image can be extracted and processed using computer vision techniques.
Key-Value Pairs and Table Extractions
It is another type of data supported by Google Document AI. Here are some more details about these features:
- Key-Value Pairs: Document AI can extract key-value pairs from structured documents, such as invoices and receipts. Key-value pairs are pairs of related data, such as a product name and its price. Document AI can extract these pairs using machine learning techniques that can identify patterns and structures in the document.
- Table Extractions: Document AI can extract tables from structured documents, such as financial reports or medical charts. Tables are structured data that are organized into rows and columns. By extracting tables, Document AI can help automate data entry and analysis tasks, reducing the need for manual data entry. Document AI can extract tables using computer vision and natural language processing techniques.
- Customization: Document AI provides tools for customizing the extraction of key-value pairs and tables to meet specific business needs. This can include defining new templates for extraction or training the model with new data to improve accuracy.
Example Uses of Google Document AI
Google Document AI uses a combination of computer vision and natural language processing to extract data from various types of documents. When a document is uploaded to the platform, it is first analyzed to determine its structure and content.
For text extraction, Google Document AI uses optical character recognition (OCR) technology to convert the text in the document into machine-readable text.
For table extraction, Google Document AI uses computer vision to identify the cells, rows, and columns in a table and extract the data within each cell.
For key-value pair extraction, Google Document AI can identify and extract information in specific formats, such as dates, phone numbers, and addresses.
Prerequisites
To use Google Document AI, there are several prerequisites that you should be aware of:
- Google Cloud Platform Account: Google Document AI is a cloud-based service provided by Google Cloud Platform. To use it, you need to create a Google Cloud Platform account and obtain the necessary permissions.
- Understanding of Machine Learning Concepts: While you do not need to be an expert in machine learning, it is important to have a basic understanding of machine learning concepts and terminology. This will help you understand how Google Document AI works and how to customize it to meet your specific needs.
- Supported File Types: Google Document AI supports several file types, including PDFs, TIFFs, and PNGs. Before using Google Document AI, ensure that your data is in a supported format.
- Training Data: Depending on your use case, you may need to provide training data to Google Document AI. This data is used to train the machine learning model to recognize patterns and extract information from your documents.
- API Access: Google Document AI provides an API that allows you to programmatically access the service. You will need to enable API access and authenticate your requests.
- Billing Information: Google Document AI is a paid service, and you will need to provide billing information to use it. Google provides several pricing plans, and you will be charged based on the number of pages processed.
By meeting these prerequisites, you will be able to effectively use Google Document AI to automate your document processing tasks and improve your business operations.
Code
Text extraction and text comprehension are the two components that makeup Document AI. The code for detecting text in PDFs can be used for text extraction:
The given code is an example of using the Google Cloud Vision API to perform OCR (Optical Character Recognition) on PDF files stored in Google Cloud Storage.
Here's a step-by-step explanation of the code:
- The necessary libraries are imported, including json, re (regular expression), google.cloud.vision, and google.cloud.storage.
- The async_detect_document function is defined, which takes two parameters: gcs_source_uri (the URI of the source PDF file in Google Cloud Storage) and gcs_destination_uri (the URI where the JSON output files will be stored in Google Cloud Storage).
- The function initializes the Cloud Vision API client using vision.ImageAnnotatorClient().
- It sets the OCR feature type to vision.Feature.Type.DOCUMENT_TEXT_DETECTION.
- The source and destination configurations are set using vision.GcsSource and vision.GcsDestination objects.
- An async_request is created with the specified features and configurations.
- The client.async_batch_annotate_files method is called with the async_request to start the asynchronous OCR process.
- The code waits for the operation to finish using operation.result(timeout=420). The timeout is set to 420 seconds (7 minutes).
- Once the operation is completed, the output files in Google Cloud Storage are listed.
- The first output file is processed. It is downloaded as a JSON string and loaded into a Python dictionary using json.loads.
- The full-text annotation for the first page is extracted from the response.
- The full-text content is printed to the console.
This code demonstrates how to perform OCR on PDF files using the Google Cloud Vision API and extract the text content from the processed document.
Applications of Google Document AI
Personal
Google Document AI has a wide range of applications for personal use, such as:
- Organizing Personal Documents: Google Document AI can help in organizing and categorizing personal documents, such as bills, receipts, and insurance documents. It can extract important information from these documents and create a searchable database that makes it easy to find the required documents.
- Digitizing Paper Documents: Document AI can be used to digitize paper documents such as letters, notes, and diaries. By converting these documents into searchable digital formats, they become easier to manage and access.
- Language Translation: With its natural language processing capabilities, Document AI can help translate documents from one language to another. This can be useful when dealing with documents written in a foreign language.
- Resume Analysis: Document AI can help analyze resumes and extract important information such as education, work experience, and skills. This can be helpful for job seekers in optimizing their resumes for specific job openings.
- Personal Finance Management: Google Document AI can be used to extract financial information from bank statements, bills, and receipts. This can help in tracking expenses and managing personal finances.
Business
Google Document AI has a wide range of applications for businesses, such as:
- Invoice Processing: Document AI can extract information from invoices, such as invoice number, date, vendor details, and line items. This can help businesses automate their accounts payable processes and reduce manual data entry.
- Contract Analysis: Document AI can analyze contracts and extract key information, such as terms and conditions, payment schedules, and obligations. This can help businesses understand the terms of their contracts and identify any potential risks.
- Customer Support: Document AI can be used to automate customer support processes, such as responding to frequently asked questions and routing support tickets to the appropriate teams.
- Compliance Monitoring: Document AI can be used to monitor regulatory compliance by analyzing legal documents and extracting relevant information. This can help businesses identify compliance issues and take corrective action.
- Fraud Detection: Document AI can be used to detect fraudulent documents, such as fake invoices or expense reports. By analyzing these documents, Document AI can identify patterns and anomalies that suggest fraud.
Technology Behind Google Document AI
Computer Vision (CV) and Natural Language Processing (NLP) are two areas in which Google Document AI has implemented its own proprietary AI technology. In contrast to NLP, which is the act of deciphering usable information from a collection of words or sentences, computer vision is the discipline that attempts to enable machines to understand images.
In essence, Google Document AI makes use of computer vision technology, notably optical character recognition, to identify words and phrases in a given PDF. These words and phrases are then used as inputs to an NLP network to determine the significance of their meanings. The fundamental methods applied in these disciplines are succinctly described below.
Computer Vision
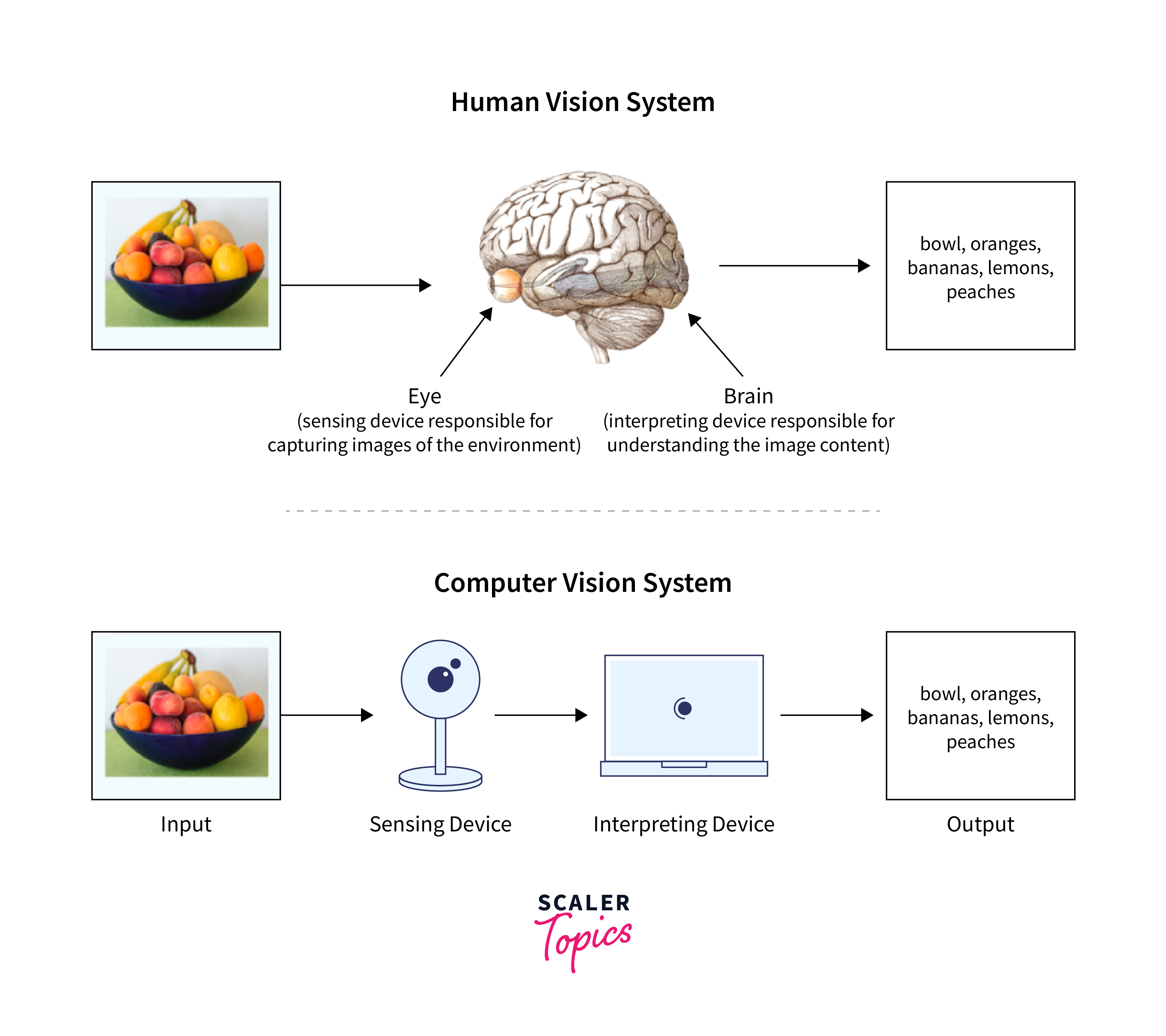
Computer vision algorithms are used to perform tasks such as text detection, text recognition, and layout analysis. Text detection involves identifying regions within an image that contain text, while text recognition involves converting the text within these regions into a machine-readable format.
Layout analysis involves identifying the structure of a document and its various components, such as headings, paragraphs, and tables. Google Document AI uses a range of computer vision techniques, including convolutional neural networks (CNNs), optical character recognition (OCR), and image segmentation algorithms.
These algorithms are trained on large datasets of images and text to improve their accuracy and performance. By using computer vision techniques, Google Document AI can extract information from a wide range of document types, including scanned documents, PDFs, and images. It can analyze complex layouts and extract structured data from tables, forms, and invoices. This makes it a powerful tool for document processing and analysis in a variety of industries, including finance, healthcare, and legal.
Natural Language Processing
NLP involves a range of techniques such as entity recognition, sentiment analysis, and summarization. Entity recognition involves identifying and categorizing named entities such as people, places, and organizations. Sentiment analysis involves determining the emotional tone of the text, such as whether it is positive or negative.
Summarization involves extracting the key information from the text and presenting it in a condensed form. Google Document AI uses a range of NLP techniques to extract meaning from the text within documents.
One of the key benefits of using NLP techniques in document analysis is the ability to analyze unstructured data. This means that Google Document AI can analyze natural language text, which is often messy and difficult to parse. By understanding the meaning of the text, one can extract valuable insights from documents that would be difficult or impossible to extract using traditional rule-based approaches.
Competition and Alternatives
Amazon Textract
Amazon Textract is a cloud-based OCR service that provides competition to Google Document AI. Amazon Textract uses advanced machine learning algorithms to recognize text and data from scanned documents, forms, and tables. Some of the key features and benefits of Amazon Textract include:
- Accurate OCR: Amazon Textract uses state-of-the-art OCR algorithms to accurately recognize text and data from a wide range of sources, including scanned documents, images, and PDFs.
- Table Extraction: Amazon Textract can automatically detect tables within documents and extract the data into a structured format.
- Easy to Use: Amazon Textract is easy to set up and use, with simple APIs that can be integrated into a wide range of applications and workflows.
- Scalable: Amazon Textract is designed to scale to meet the needs of even the largest organizations, with the ability to process millions of pages of documents per day.
- Cost-effective: Amazon Textract is offered on a pay-per-use basis, with no upfront costs or minimum fees.
ABBYY and Kofax
ABBYY and Kofax are two companies that provide competition to Google Document AI. They offer enterprise-grade OCR solutions that can extract data from documents, forms, and tables.
Some of the key features and benefits of ABBYY and Kofax include:
- Advanced OCR Algorithms: ABBYY and Kofax use advanced OCR algorithms to accurately recognize text and data from a wide range of sources, including scanned documents, images, and PDFs.
- Intelligent Data Capture: Both ABBYY and Kofax offer intelligent data capture solutions that can automatically extract data from documents, forms, and tables into a structured format.
- Easy Integration: ABBYY and Kofax provide APIs that can be easily integrated into a wide range of applications and workflows.
- Scalability: ABBYY and Kofax solutions are designed to scale to meet the needs of even the largest organizations, with the ability to process millions of pages of documents per day.
- Industry-Specific Solutions: ABBYY and Kofax offer industry-specific OCR solutions for industries such as finance, healthcare, and legal, which provide specialized features and benefits tailored to the needs of those industries.
Nanonets
Nanonets is a cloud-based OCR platform that provides competition to Google Document AI. It uses advanced machine-learning algorithms to extract data from scanned documents, forms, and tables.
Some of the key features and benefits of Nanonets include:
- Accurate OCR: Nanonets uses advanced OCR algorithms to accurately recognize text and data from a wide range of sources, including scanned documents, images, and PDFs.
- Table Extraction: Nanonets can automatically detect tables within documents and extract the data into a structured format.
- Customizable: Nanonets provides a user-friendly interface to customize the OCR engine to specific use cases, ensuring better accuracy.
- Easy to Use: Nanonets are easy to set up and use, with simple APIs that can be integrated into a wide range of applications and workflows.
- Scalable: Nanonets are designed to scale to meet the needs of even the largest organizations, with the ability to process millions of pages of documents per day.
- Cost-effective: Nanonets offers pay-as-you-go pricing, which means users only pay for what they use.
Conclusion
Here are the main points to conclude about Google Document AI:
- Google Document AI is a powerful tool that can extract data from a wide range of document types using computer vision and natural language processing technologies.
- The platform supports various types of data, including text, document overview information, key-value pairs, and table extractions.
- Google Document AI can be used for a wide range of applications, including personal and business use cases.
- The technology behind Google Document AI leverages machine learning algorithms to improve accuracy and automate the data extraction process.
- There are several alternatives to Google Document AI, including Amazon Textract, ABBYY and Kofax, and Nanonets.
- Ultimately, the choice of OCR platform will depend on the specific needs of the user, including the types of documents to be processed, the level of accuracy required, and the budget available.