Uninformed Search Algorithms in Artificial Intelligence
Overview
Artificial intelligence (AI) refers to the ability of computers or machines to perform tasks that typically require human intelligence, such as learning, problem-solving, decision-making, perception, and natural language understanding. Now to solve tasks, AI uses certain problem-solving techniques to give the best optimal result quickly. In other words, AI makes use of Search techniques or Search algorithms. This article focuses on the uninformed search strategies in artificial intelligence.
Introduction
Uninformed search strategies in artificial intelligence refers to a class of search algorithms that do not use specific knowledge or heuristics about the problem domain to guide their search. Instead, they systematically explore the search space(The space of all feasible solutions (the set of solutions among which the desired solution resides) is called search space), starting from an initial state and generating all possible successors until reaching a goal state. Uninformed search algorithms are generally simple and easy to implement but could be more efficient in large search spaces or for problems with complex or irrelevant paths. Uninformed search algorithms are useful for solving simple problems or as a baseline for more complex search algorithms incorporating domain-specific knowledge. However, they may need to be more efficient and effective for more complex problems, where informed search algorithms, such as A* search, may be more appropriate.
The Various Types Of Uninformed Search Algorithms
Breadth-first Search
Breadth-first search (BFS) is one of the most important uninformed search strategies in artificial intelligence to explore a search space systematically. BFS explores all the neighbouring nodes of the initial state before moving on to explore their neighbours. This strategy ensures that the shortest path to the goal is found.
The algorithm works by starting at the initial state and adding all its neighbours to a queue. It then dequeues the first node in the queue, adds neighbours to the end of the queue, and repeats the process until the goal state is found or the queue is empty.
Here are the steps for performing BFS in a search space:
BFS explores all the nodes at a given distance (or level) from the starting node before moving on to explore the nodes at the next distance (or level) from the starting node. This means that BFS visits all the nodes that are closest to the starting node before moving on to nodes that are farther away.
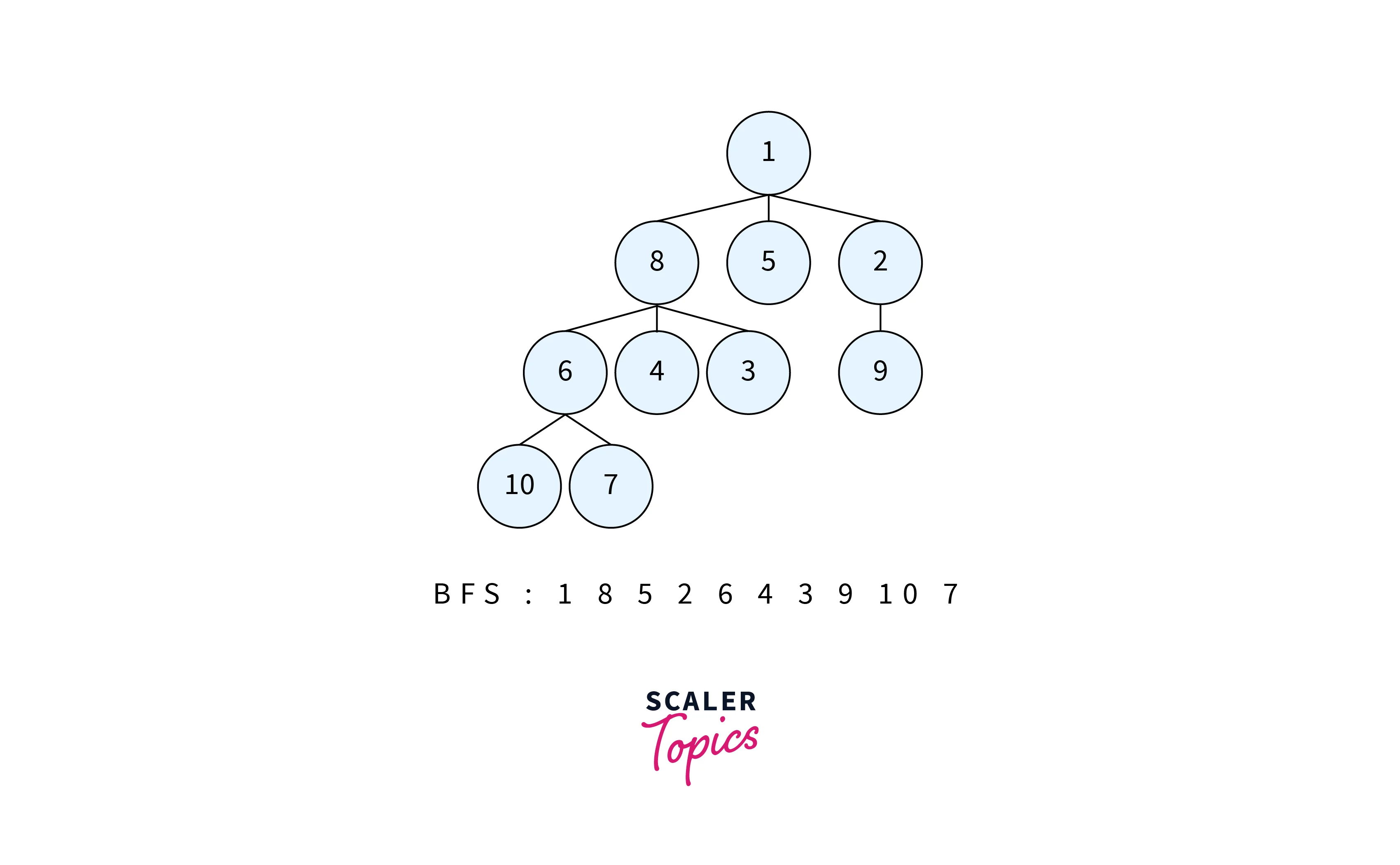
We use the queue data structure to implement BFS.
- Add the initial state to a queue.
- While the queue is not empty, dequeue the first node.
- If the node is the goal state, return it.
- If the node is not the goal state, add all its neighbors to the end of the queue.
- Repeat steps 2-4 until the goal state is found or the queue is empty.
Advantages
Breadth-first search (BFS) is an algorithm used in artificial intelligence to explore a search space systematically. Some advantages of BFS include the following:
- Completeness:
BFS is guaranteed to find the goal state if it exists in the search space, provided the branching factor is finite. - Optimal solution:
BFS is guaranteed to find the shortest path to the goal state, as it explores all nodes at the same depth before moving on to nodes at a deeper level. - Simplicity:
BFS is easy to understand and implement, making it a good baseline algorithm for more complex search algorithms. - No redundant paths:
BFS does not explore redundant paths because it explores all nodes at the same depth before moving on to deeper levels.
Disadvantages
- Memory-intensive:
BFS can be memory-intensive for large search spaces because it stores all the nodes at each level in the queue. - Time-intensive:
BFS can be time-intensive for search spaces with a high branching factor because it needs to explore many nodes before finding the goal state. - Inefficient for deep search spaces:
BFS can be inefficient for search spaces with a deep depth because it needs to explore all nodes at each depth before moving on to the next level.
Time and Space Complexity
The time and space complexity of breadth-first search (BFS) in artificial intelligence can vary depending on the size and structure of the search space.
Time complexity:
The time complexity of BFS is proportional to the number of nodes in the search space, as BFS explores all nodes at each level before moving on to deeper levels. For example, if the goal state is at the deepest level, BFS must explore all nodes in the search space, resulting in a time complexity of , where is the branching factor, and is the depth of the search space.
Space complexity:
The space complexity of BFS is proportional to the maximum number of nodes stored in the queue during the search. For example, if the search space is a tree, the maximum number of nodes stored in the queue at any given time is the number of nodes at the deepest level, which is proportional to . Therefore, the space complexity of BFS is .
Example
Suppose we have a search space with an initial state "A" and a goal state "E" connected by nodes as follows:
To perform BFS on this search space, we start by adding the initial state "A" to a queue:
We dequeue the first node in the queue, which is "A", and add its children "B" and "C" to the end of the queue:
We then dequeue "B" and "C" and add their children to the end of the queue:
We dequeue "C" and add its child "E" to the end of the queue:
Finally, we dequeue "D" and "E" and find that "E" is the goal state, so we have successfully found a path from "A" to "E" using BFS.
Depth-first Search
Depth-first search (DFS) is popular among the uninformed search strategies in artificial intelligence to explore and traverse a graph or tree data structure. The algorithm starts at a given node in the graph and explores as far as possible along each branch before backtracking.
DFS is a recursive algorithm that follows the following steps:
- Mark the starting node as visited.
- Explore all adjacent nodes that have not been visited.
- For each unvisited adjacent node, repeat steps 1 and 2 recursively.
- Backtrack if all adjacent nodes have been visited or there are no unvisited nodes.
- DFS can be implemented using a stack data structure or recursion. The recursive implementation is simpler to understand but can cause a stack overflow if the graph or tree is too large.
DFS has several applications in AI, including pathfinding, searching for solutions to a problem, and exploring the state space of a problem. It is particularly useful when the solution is far from the starting node because it can explore the graph deeply before exploring widely.
Advantages
- Memory efficiency:
DFS uses less memory than breadth-first search because it only needs to keep track of a single path at a time. - Finds a solution quickly:
If the solution to a problem is located deep in a tree, DFS can quickly reach it by exploring one path until it reaches the solution. - Easy to implement:
DFS is a simple algorithm to understand and implement, especially when using recursion. - Can be used for certain types of problems:
DFS is particularly useful for problems that involve searching for a path, such as maze-solving or finding the shortest path between two nodes in a graph.
Disadvantages
- Can get stuck in infinite loops:
DFS can get stuck in an infinite loop if there are cycles in the graph or tree. This can be avoided by keeping track of visited nodes. - May not find the optimal solution:
DFS only sometimes finds the shortest path to a solution. It may find a suboptimal path before finding the shortest one. - Can take a long time:
In some cases, DFS may take a long time to find a solution, especially if the solution is located far from the starting node.
Time and space complexity
The time and space complexity of depth-first search (DFS) depend on the size of the graph or tree being traversed and the implementation of the algorithm.
Time Complexity:
In the worst-case scenario, DFS has a time complexity of , where |V| is the number of vertices in the graph or tree and |E| is the number of edges. This is because DFS visits every vertex and edge once. However, the time complexity can be reduced to if the graph or tree is a simple connected graph.
Space Complexity:
The space complexity of DFS is proportional to the tree's height or the graph's maximum depth. In the worst-case scenario, where the tree or graph is very deep and has no branches, the space complexity of DFS is , where h is the tree's height. This is because DFS uses a recursive function call stack to keep track of the current path being traversed.
Example
Traversing a binary tree
Consider the following binary tree:
To traverse this tree using DFS, we start at the root node (1) and explore as far as possible along each branch before backtracking. Here is the order in which the nodes would be visited.
We first visit the root node (1), then the left child (2), and so on. Once we reach a leaf node (4), we backtrack to the last node with an unexplored child (2) and continue exploring its other child (5). We continue this process until all nodes have been visited.
Depth-limited Search
Among the uninformed search strategies in artificial intelligence, Depth-limited search (DLS) is a variant of depth-first search (DFS) that limits the depth of the search tree to a certain level. DLS is commonly used in artificial intelligence (AI) to explore a search space efficiently while avoiding the problems of infinite loops and memory overflow that can arise in regular DFS.
DLS is particularly useful when the search space is large and there is limited memory available. By limiting the depth of the search tree, we can ensure that the search algorithm only explores a finite portion of the search space, which reduces the risk of running out of memory.
Algorithm
- Initialize the search:
Start by setting the initial depth to 0 and initialize an empty stack to hold the nodes to be explored. Enqueue the root node to the stack. - Explore the next node:
Dequeue the next node from the stack and increment the current depth. - Check if the node is a goal:
If the node is in a goal state, terminate the search and return the solution. - Check if the node is at the maximum depth:
If the node's depth is equal to the maximum depth allowed for the search, do not explore its children and remove it from the stack. - Expand the node:
If the node's depth is less than the maximum depth, generate its children and enqueue them to the stack. - Repeat the process:
Go back to step 2 and repeat the process until either a goal state is found or all nodes within the maximum depth have been explored.
In DLS, we limit the depth of the search tree to a certain level (let's say 3). This means that we only explore paths that are three levels deep or less. If we haven't found the goal state by the time we reach this depth limit, we backtrack and explore other paths that are still within the limit.
Advantages
- Memory efficient:
DLS limits the depth of the search tree, which means that it requires less memory compared to other search algorithms like breadth-first search (BFS) or iterative deepening depth-first search (IDDFS). - Time efficient:
DLS can be faster than other search algorithms, especially if the solution is closer to the root node. Since DLS only explores a limited portion of the search space, it can quickly identify if a solution exists within that portion. - Avoids infinite loops:
Since DLS limits the depth of the search tree, it can avoid infinite loops that can occur in regular depth-first search (DFS) if there are cycles in the graph.
Disadvantages
- Suboptimal solutions:
DLS may not find the optimal solution, especially if the depth limit is set too low. If the optimal solution is deeper in the search tree, DLS may terminate prematurely without finding it. - Highly dependent on depth limit:
The performance of DLS is highly dependent on the depth limit. If the depth limit is set too low, it may not find the solution at all. On the other hand, if the depth limit is set too high, it may take too long to complete. - May miss some solutions:
If the solution is deeper than the depth limit, DLS may miss it altogether. In contrast, iterative deepening depth-first search (IDDFS) can find all solutions in the search space, albeit at a higher cost in terms of time and memory.
Time and space complexity
The time and space complexity of Depth-limited search (DLS) depends on several factors, including the depth limit, the branching factor(The branching factor refers to the average number of child nodes that each node has.) of the search tree, and the position of the goal state in the search space. Here are the details:
Time Complexity:
The time complexity of DLS is O(b<sup>l</sup>), where b is the branching factor of the search tree, and l is the depth limit. This is because DLS explores all paths up to the depth limit, and each level can have, at most, b nodes. Therefore, the total number of nodes explored by DLS is the sum of the nodes at each level, which is given by the formula
Space Complexity:
The space complexity of DLS is O(bl), where b is the branching factor of the search tree, and l is the depth limit. This is because DLS only keeps track of the nodes up to the depth limit in the search tree. Therefore, the total number of nodes stored in memory by DLS is at most bl.
Example
Suppose we have a binary tree as follows:
We want to find the node with the value "G" using a Depth-Limited Search with a depth limit of 2.
Starting at the root node "A," we can expand its children "B" and "C." Since we have a depth limit of 2, we cannot expand any further, and we backtrack to the parent node "A."
Next, we expand the other child of "A," which is "C." We can expand its children "F" and "G." Since the node with the value "G" is found at a depth of 2, we stop the search and return the node with the value "G".
Therefore, the output of the Depth-Limited Search with a depth limit of 2 in this example is the node with the value "G."
Note that if the depth limit was set to 1, the search would not have found the node with the value "G" as it would have stopped at a depth of 1 without exploring the subtree rooted at "G."
Iterative Deepening Depth-First Search
Iterative deepening depth-first search (IDDFS) is a graph traversal algorithm that combines the advantages of depth-first search (DFS) and breadth-first search (BFS) while avoiding their drawbacks. IDDFS performs a depth-first search to a limited depth and then gradually increases the depth limit until a solution is found. It repeats this process until the goal state is found or all nodes have been explored. The algorithm is complete, optimal, and has a time complexity similar to BFS.
Here are the steps for IDDFS:
- Set the depth limit to 0.
- Perform DFS to the depth limit.
- If the goal state is found, return it.
- If the goal state is not found and the maximum depth has not been reached, increment the depth limit and repeat steps 2-4.
- If the goal state is not found and the maximum depth has been reached, terminate the search and return failure.
Advantages
- Optimal solution:
IDDFS guarantees to find the optimal solution, provided that the cost of each edge is identical. - Memory-efficient:
IDDFS uses less memory than breadth-first search (BFS) because it only stores the current path in memory, not the entire search tree. - Complete:
IDDFS is complete, meaning it will always find a solution if one exists. - Simple implementation:
IDDFS is easy to implement since it is based on the standard depth-first search algorithm.
Disadvantages
- Inefficient for branching factors that are very high:
If the branching factor is very high, IDDFS can be inefficient since it may repeatedly explore the same nodes at different depths. - Redundant work:
IDDFS may explore the same nodes multiple times, leading to redundant work. - Time complexity can be high:
The time complexity of IDDFS can be high if the depth limit needs to be increased multiple times before finding the goal state.
Time and space complexity
Time Complexity
The time complexity of the Iterative Deepening Depth-First Search (IDDFS) is O(b^d), where b is the branching factor of the search tree, and d is the depth of the goal state. This time complexity is the same as that of Breadth-First Search (BFS) but with a lower memory requirement.
The IDDFS algorithm performs a series of depth-first searches with increasing depth limits. At each iteration, the search depth is increased by one level. The algorithm terminates either when the goal state is found or when the maximum depth is reached.
Each iteration of the algorithm takes O(b^d) time, where b is the branching factor and d is the current depth limit. The total time complexity of the algorithm is the sum of the time complexity of each iteration up to the depth of the goal state, which is O(b^d).
Space complexity:
The space complexity of IDDFS is O(bd), where b is the branching factor and d is the maximum depth of the search tree. This space complexity is lower than that of BFS, which has a space complexity of O(b^d), where b is the branching factor and d is the depth of the goal state.
IDDFS only needs to store the nodes along the current path being explored, and as a result, it can be more memory-efficient than BFS. However, IDDFS can still be slower than other algorithms, such as A* search, if the search space is particularly complex or if the heuristic function is well-designed.
Example
Consider the following graph:
- To perform IDDFS on this graph, we start at the root node A and explore its first child, which is B.
- We then recursively explore the first child of B, which is E. Since E has no children, we backtrack to its parent B and explore its second child, which is F. Again, we recursively explore F's first child, but since F has no children, we backtrack to B.
- Next, we explore B's second child, which is C. We recursively explore C's first child, which is G. G has no children, so we backtrack to C and explore its second child, which is D. Since D has no children, we backtrack to A.
- At this point, we have explored all nodes at depth 1 (i.e., A, B, C, and D). We then start the process again, increasing the depth by 1. We explore A's second child, which is C. However, since we have already explored all nodes at depth 1, we skip over B and its children (E and F) and start at C.
- We recursively explore C's first child, which is G. Since G has no children, we backtrack to C and explore its second child, which is D. Again, D has no children, so we backtrack to A.
- We continue this process, exploring all nodes at depth 2 (i.e., E, F, and G), then all nodes at depth 3 (i.e., none), and finally, all nodes at depth 4 (i.e., none). Therefore, the order of exploration for this DDFS is as follows:
Uniform Cost Search
Uniform Cost Search (UCS) is an informed search algorithm used in artificial intelligence to solve problems where the path cost is the main concern. UCS is a best-first search algorithm that expands the node with the lowest path cost g(n) first, where g(n) is the cost of the path from the initial state to node n. UCS guarantees to find the optimal solution to the problem provided that the cost function is non-negative.
The algorithm works as follows:
- Initialize the frontier with the start node, and set the cost of the start node to zero. The frontier in a search algorithm contains states that have been seen, but their outgoing edges have not yet been explored
- While the frontier is not empty, select the node with the lowest cost and remove it from the frontier.
- If the selected node is the goal node, return the solution.
- Otherwise, expand the selected node and add its children to the frontier with the corresponding path cost.
- If a child node is already in the frontier with a lower path cost, update its cost with the lower value.
- Repeat steps 2-5 until the goal node is found or the frontier is empty.
UCS can be implemented using a priority queue, where the priority is given by the path cost. UCS is complete and optimal, but it can be very slow in practice, especially for problems with large state spaces. To improve efficiency, UCS can be combined with heuristics, resulting in A* search, which expands nodes in the order of their estimated total cost to the goal.
Advantages
Optimal solution:
UCS always finds the optimal solution if the edge weights are non-negative. It explores the path with the lowest cost first and, thus, guarantees to find the shortest path.
Completeness:
UCS is a complete algorithm, meaning that it will find a solution if one exists.
Efficient for small edge weights:
UCS is efficient when the edge weights are small, as it explores the paths in an order that ensures that the shortest path is found early.
Easy to understand:
UCS is a simple algorithm to understand, and it is easy to implement.
Disadvantages
- Inefficient for large edge weights:
UCS can be very inefficient when the edge weights are large, as it explores all the possible paths in an order that depends on the cost of the path. - Memory intensive:
UCS stores all the paths it has explored in a priority queue, which can be very memory intensive if the graph is large. - Inefficient for graphs with cycles:
UCS can get stuck in a loop if the graph has cycles and the cost of the loop is less than the cost of the shortest path. This is known as the "cycle problem" and can cause UCS to explore an infinite number of paths. - Requires knowledge of all edge weights:
UCS requires knowledge of all the edge weights before it can start searching. This can be a disadvantage if the weights are unknown or change dynamically.
Time and space complexity
Time Complexity:
In the worst case, UCS will explore all the possible paths in the search space before finding the goal node. The time complexity of UCS is exponential in the worst case, and it can be written as O(bd), where b is the branching factor of the search tree, and d is the depth of the goal node. However, if the goal node is closer to the starting node, the time complexity can be much lower.
Space Complexity:
UCS uses a priority queue to store the nodes it has explored, and the space complexity depends on the maximum number of nodes in the queue. The maximum number of nodes in the queue is proportional to the size of the search space, which can be written as O(bd). The space complexity of UCS is also affected by the way the priority queue is implemented. If a binary heap is used as the priority queue, the space complexity can be reduced to O(bd).
Example
Consider the following graph:
Each node represents a location, and the number on the edges represents the cost of traveling between two locations. So, for example, the cost of traveling from A to B is 3, from A to C is 2, and so on.
Let's say we want to find the shortest path from node A to node D using Uniform Cost Search. Here's how the algorithm works:
- Start with node A as the initial node, and set its cost to 0.
- Generate the child nodes of A, which are B and C.
- Add the child nodes to a priority queue, ordered by their path cost.
- Choose the node with the lowest path cost from the priority queue, C.
- Generate the child nodes of C, which is D.
- Add D to the priority queue.
- Choose the node with the lowest path cost from the priority queue, B.
- Generate the child nodes of B, which is D.
- Add D to the priority queue.
- Choose the node with the lowest path cost from the priority queue, D.
- We have reached the goal node and stopped and returned the path from A to D.
The resulting path is A -> C -> D, with a total cost of 7.
Bidirectional Search
Bidirectional search is an algorithm used in artificial intelligence to find the shortest path between a source node and a destination node in a graph. Unlike traditional search algorithms that start from the source node and explore the graph in a single direction, bidirectional search simultaneously explores the graph from both the source and destination nodes until they meet in the middle.
Here's how the bidirectional search algorithm works:
- Start with the source and destination nodes.
- Create two search trees:
one from the source node and the other from the destination node. - Expand the search tree from the source node by generating its child nodes.
- Expand the search tree from the destination node by generating child nodes.
- Check if any node in the search tree from the source node matches a node in the search tree from the destination node.
- A path between the source and destination nodes has been found if a match is found. Return the path.
- If a match is not found, repeat steps 3-6 until a match is found or there are no more nodes to explore.
Advantages
- It can significantly reduce the search space and improve search efficiency, especially in large graphs, as it simultaneously explores the graph from both the source and destination nodes.
- It can reduce the time and memory complexity of the search algorithm compared to traditional search algorithms.
- It is particularly useful when the graph is very large, and there is no way to reduce its size.
- It can also be useful in cases where the cost of expanding nodes is high, as it can reduce the number of nodes that need to be expanded.
Disadvantages:
- It may only sometimes be possible to start the search from both ends of the graph.
- It can be challenging to find an efficient way to check if a match is found between the search trees, leading to increased time complexity.
- Bidirectional search may sometimes be slower than traditional search algorithms, especially for smaller graphs.
- It requires more bookkeeping and additional data structures to keep track of both search trees.
Time and Space Complexity
Time Complexity:
The time complexity of the bidirectional search is typically O(b/2), where b is the branching factor of the graph and d is the distance between the source and destination nodes. This is because the search algorithm simultaneously expands nodes from both the source and destination nodes, reducing the search space by 2d/2.
Space Complexity:
The space complexity of the bidirectional search is also typically O(bd/2), as the search algorithm needs to store the search trees from both the source and destination nodes. However, this can be reduced by using more efficient data structures or limiting the search trees' depth.
Example
Consider the graph:
Suppose we want to find the shortest path between node A and node J using bidirectional search. The branching factor of this graph is three since each node has three neighboring nodes on average. Therefore, the distance between A and J is 5, as the shortest path is A-B-C-F-I-J.
Conclusion
- Uninformed search algorithms systematically explore the search space, starting from an initial state and generating all possible successors until reaching a goal state.
- BFS explores all the neighboring nodes of the initial state before moving on to explore their neighbors.
- DFS starts at a given node in the graph and explores as far as possible along each branch before backtracking.
- Depth-limited search (DLS) is a variant of depth-first search (DFS) that limits the depth of the search tree to a certain level.
- IDDFS performs a depth-first search to a limited depth, then gradually increases the depth limit until a solution is found.
- UCS aims to solve problems where the path cost is the main concern.
- BS/Bidirectional Search aims to find the shortest path in a graph between a source node and a destination node.