Amazon Redshift
Overview
Amazon Redshift is a data warehousing solution from AWS ( Amazon Web Services ). It is a fast, fully managed, petabyte-scale data warehouse service in the cloud that is easy and affordable to analyze all of your data using the business intelligence tools you already have. Redshift AWS dataset sizes range from a few hundred gigabytes to a petabyte. It also provides access to data analytics tools, artificial intelligence and machine learning applications.
What is Amazon Redshift?
Amazon Redshift is a fast and powerful, fully managed, petabyte-scale data warehouse service in the cloud that makes it easy and affordable to analyze all of your data using the business intelligence tools you already have. The first step in creating a data warehouse is to launch a collection of computing resources called nodes, which are grouped together into units called clusters.
Redshift AWS dataset sizes range from a few hundred gigabytes to a petabyte. Amazon Redshift provides a wide variety of data import options and can be deployed with a few clicks. For extra security, Redshift's data is always encrypted.
![]()
Redshift helps in retrieving valuable insights from large amounts of data. With the user-friendly AWS interface, you can create a new cluster in a few minutes without having to worry about managing the infrastructure.
Redshift Spectrum is an Amazon database feature that lets a data analyst conduct fast, complex analysis on objects stored in the cloud. An analyst can perform SQL queries directly on the data stored in Amazon S3 buckets.
How Does It Work?
In order to deliver the best price performance at any scale, Amazon Redshift uses machine learning and AWS-designed hardware to analyse structured and semi-structured data from operational databases, data warehouses, and data lakes.
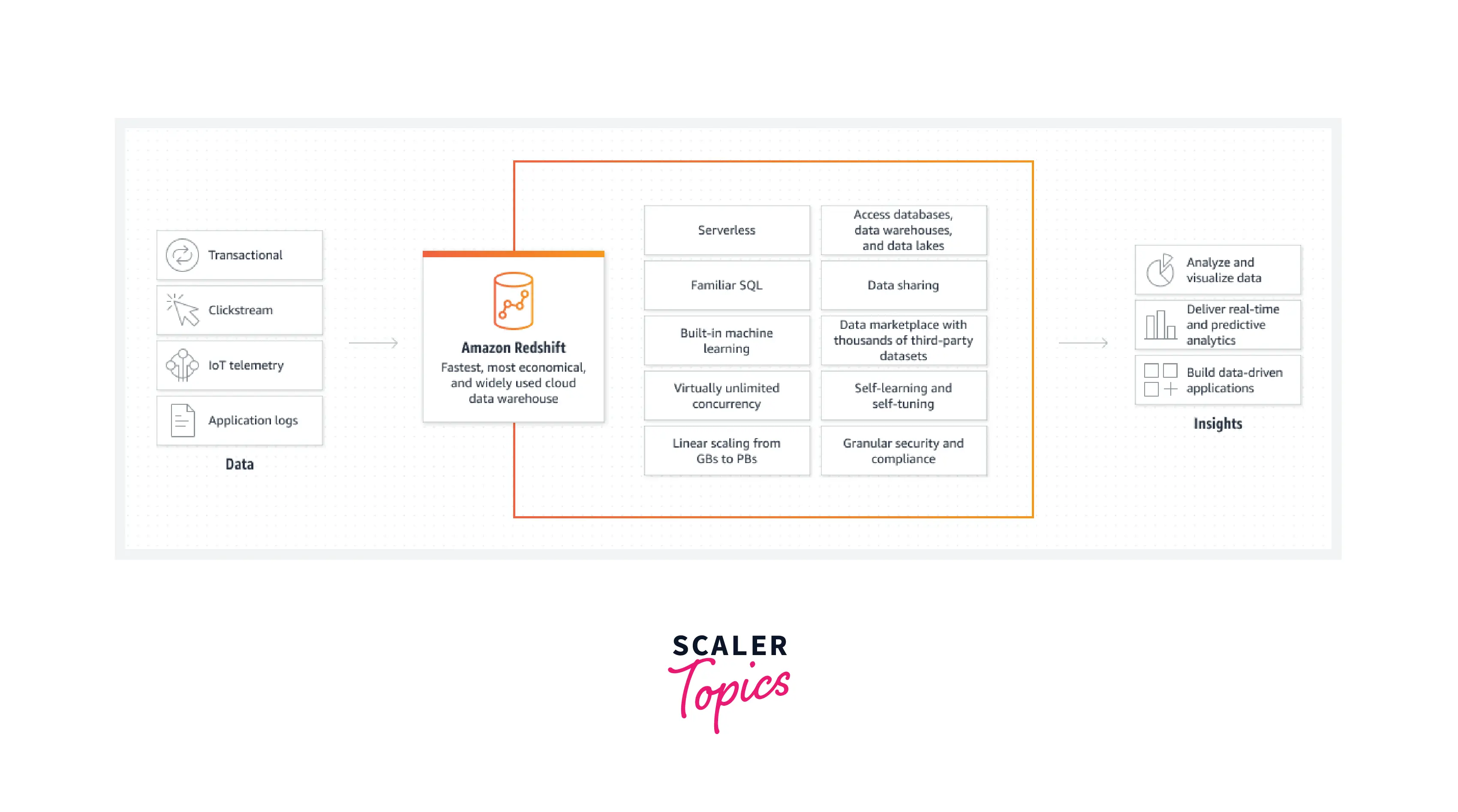
What is Unique about Amazon Redshift?
Redshift is built on top of PostgreSQL 8.0.2. This suggests that Amazon Redshift can be used with the standard SQL queries. Redshift is an OLAP - style database. Online analytical processing (OLAP) is software technology that analyze data stored in a database. Although, this isn't what differentiates Redshift from other services. Amazon Redshift stands out for its quick responses to queries on huge databases having petabytes of data.
The massively parallel processing (MPP) design enables fast querying. With MPP, different computer processors work together concurrently to perform the required computations. Occasionally, the processes can be delivered by processors distributed over many servers.
Amazon Redshift Configuration
Redshift consists of two different kinds of nodes: Single node and Multi-node. A single node has the capability to store up to 160 GB of data. On the other hand, a node that consists of multiple nodes is referred to as a multi-node and it is of two types:
- Leader Node: It receives queries and controls client connections. The queries are parsed and created into execution plans by a leader node after being received by the client applications. It coordinates the parallel execution of these plans with the compute node, combines all intermediate results, and then returns the final result to the client application.
- Compute Node: Execution plans are carried out by a compute node, and intermediate results are then transmitted to the leader node for aggregation before being returned to the client application. Up to 128 compute nodes are supported.
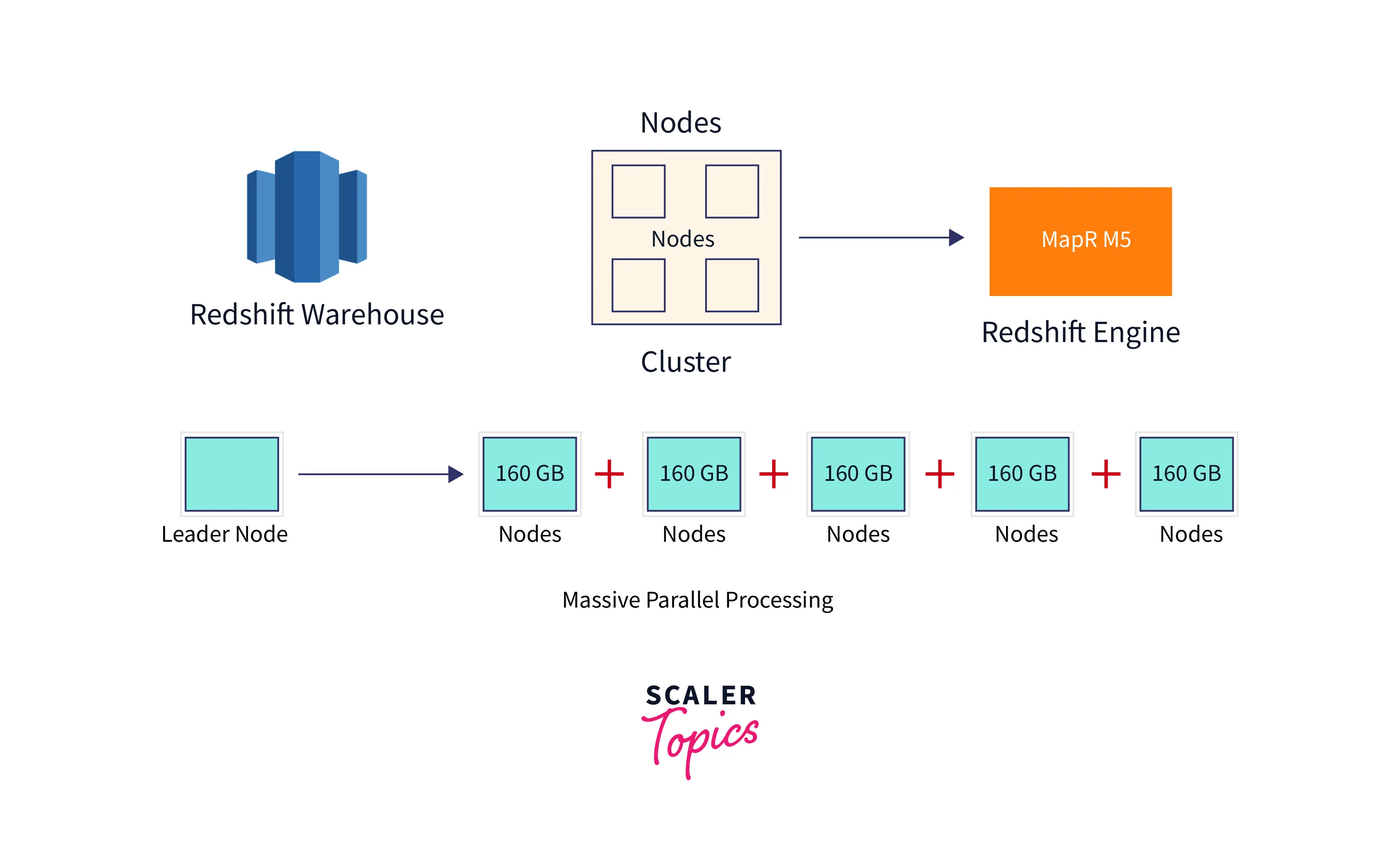
A redshift warehouse is a collection of computing nodes, which are arranged in a cluster for organizational purposes. A Redshift Engine, which houses one or more databases, controls each cluster.
Features of Amazon Redshift
Redshift is known for focusing on continuous innovation, but its architecture is what enhanced it to the most versatile cloud data warehouse solutions. The six features that make Redshift different from the other data warehouses are listed below.
-
Faster performance: Compression, parallel processing, and columnar data storage are all features of Amazon Redshift that help to reduce the total amount of I/O required for query processing. This boosts the efficiency of queries.
-
Simple and Easy to setup: Redshift is easy to set up and use. With just a few clicks in the AWS Console, you can create a new data warehouse, and Redshift will set up the necessary infrastructure for you. You are able to focus on your data rather than the administration in AWS because all administrative tasks, including backups and replication, are automated.
-
No Upfront Costs: You only pay for the resources you actually provision. With On-Demand pricing, there are no upfront costs or long-term commitments, and Reserved Instance pricing offers significantly lower prices. Visit the Billing Console to learn more.
-
Fault tolerance: The ability of a system to continue operating even when some components malfunction is referred to as fault tolerance. Fault tolerance in data warehousing determines a job's ability to continue running even if some processors or clusters are unavailable.
-
Compatible:
- Amazon Redshift employs ODBC and JDBC connections, which are standards in the industry.
- The built-in commands in Amazon Redshift allow you to load data from on-premises servers, Amazon S3, Amazon DynamoDB, your Amazon EC2 instances, and other AWS services in parallel to each node. These services can all be accessed via SSH. Redshift can also be integrated with Amazon Kinesis.
-
Secure: You can customise the Redshift to use SSL to secure your data by setting a few parameters. All data written to the disc will be encrypted if you enable encryption.
Use Cases of Amazon Redshift
Optimize your business intelligence
Redshift makes it easy and affordable to run high performance queries on petabytes of semi-structured and structured data so that you can use business intelligence tools to create effective reports and dashboards.
Increase developer productivity
Without having to configure drivers and manage database connections, AWS Redshift provides simplified data access, ingest, and egress across a wide range of programming languages and platforms.
Collaborate and share data
Redshift data sharing enables us to securely and seamlessly collaborate on real-time data with people inside and outside of your organisation.
Operational analytics on events
To get real-time operational insights on your applications and systems, you can combine structured data from your data warehouse with semi-structured data from your S3 data lake, such as application logs.
Real-time analytics
Many businesses have to make decisions on the basis of real-time data and quite often should act quickly to put those decisions into action. Uber is a good example. Uber must act quickly based on historical and current data. It must make decisions regarding dynamic pricing, where to send drivers, what route to take, predicted traffic, and a range of other factors.
Redshift can be used in these situations as the MPP technology helps to make accessing and processing data faster.
When to Use Amazon Redshift?
AWS Redshift is used when there is a huge amount of data to analyze. For Redshift to be a viable solution, the data should at least be of a petabyte-scale (10^15^ bytes). The MPP technology used by Redshift is efficient only at that scale. Beyond the size of data, there are other use cases of Redshift that prove beneficial such as Real-time analytics, Log analysis, and Business intelligence.
How to Set Up Amazon Redshift?
The steps to Set Up Amazon Redshift are listed below.
Step 1 − Launch a Redshift Cluster
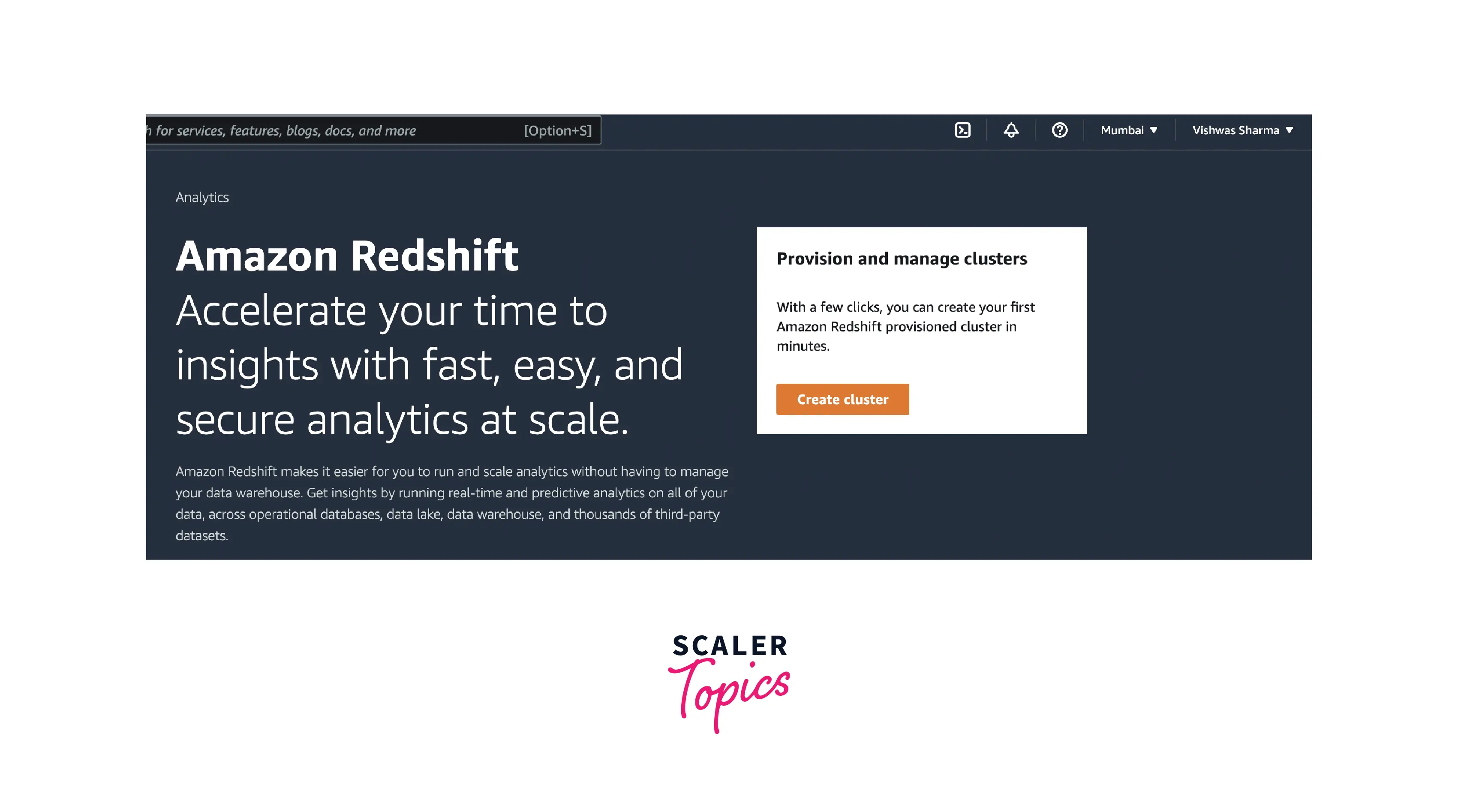
- Open the Amazon Redshift console by logging into the AWS Management Console and clicking the following link: Open Console.
- Use the Region menu in the top right corner of the screen to select the region where you want the Redshift cluster to be created.
- Create Cluster by clicking the button as shown below.
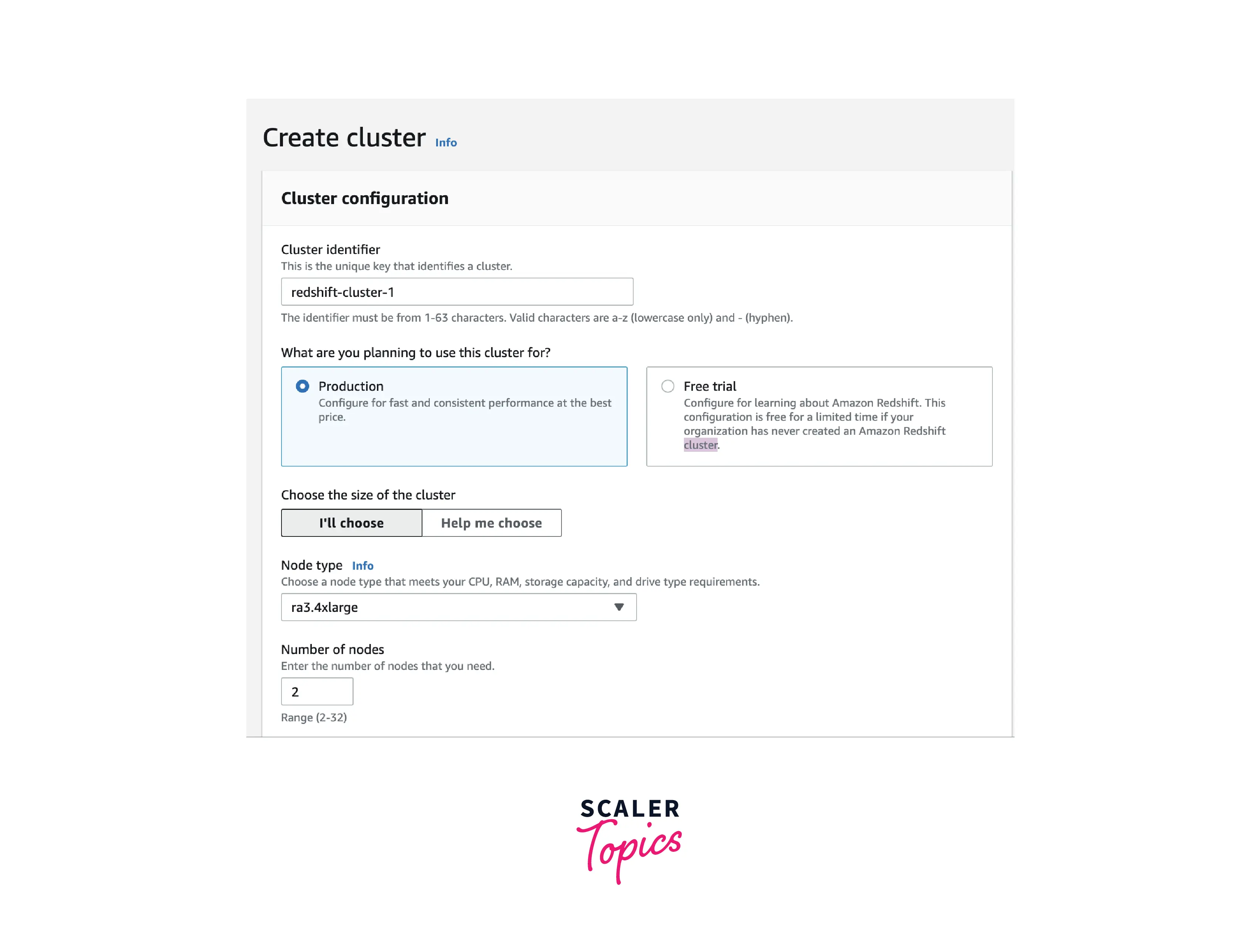
- The page for Cluster Details appears. Enter the required info, then press the Continue button to access the review page.
- At the top, you can see your cluster is being created.

- Review the information on the Cluster Status by selecting the cluster from the list. Cluster status will be displayed on the page.
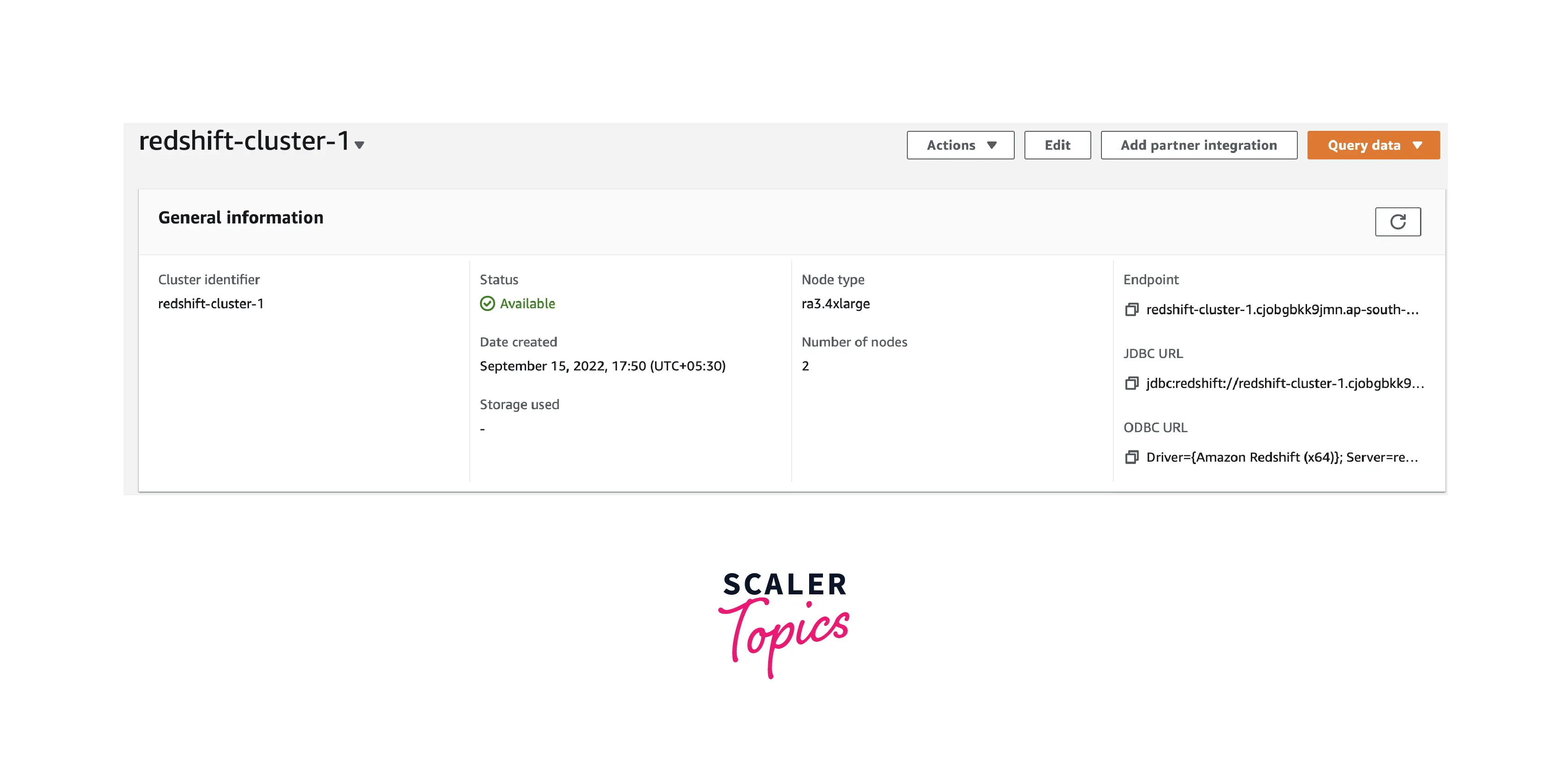
Step 2 − Configure Security Group to authorize client connections to the cluster
To authorize the client connections, configure a security group to the cluster. The authorizing access to Redshift depends on whether the client authorizes an EC2 instance or not.
To create the security group on EC2-VPC platform, follow the below steps.
- Click Clusters in the navigation pane of Amazon Redshift Console once it has opened.
- Pick and choose which cluster you want. Open the Properties tab.
- In Network and security settings section, open Security tab.

- Click Security from the list. Click the Inbound tab once the Security group page is displayed.
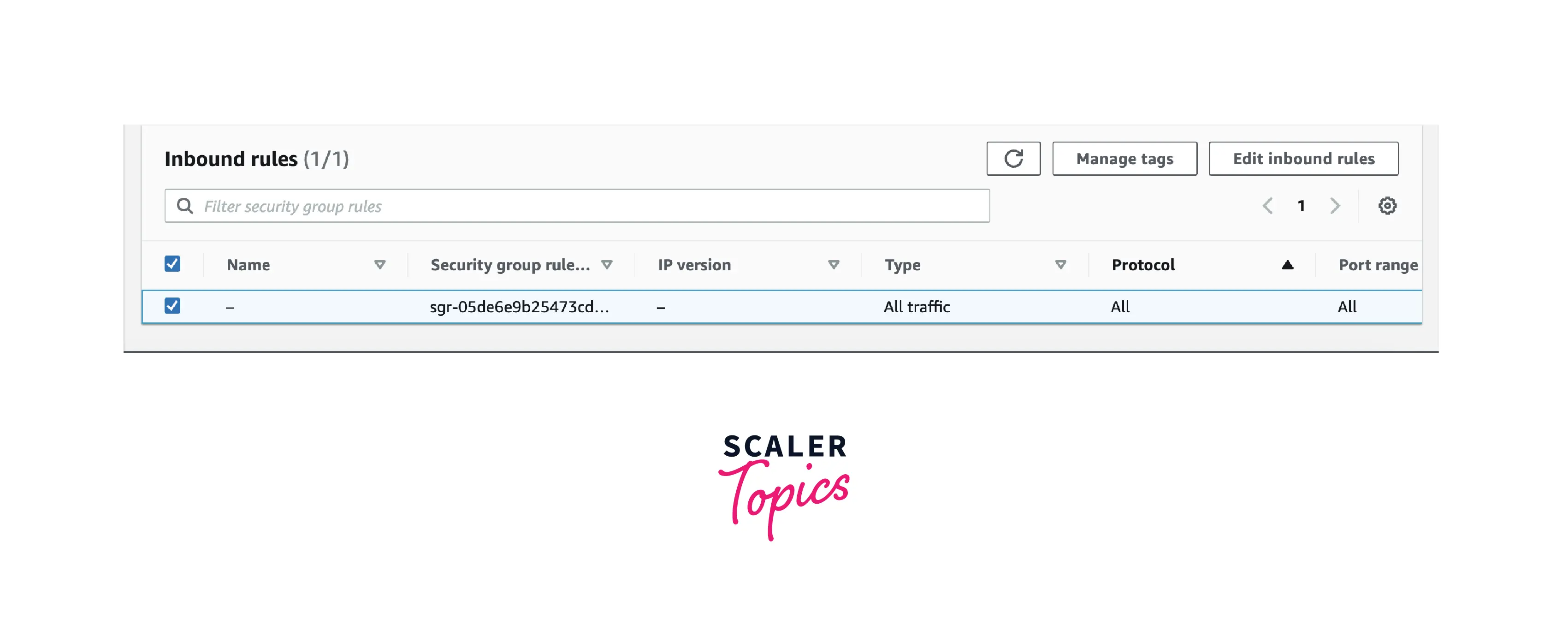
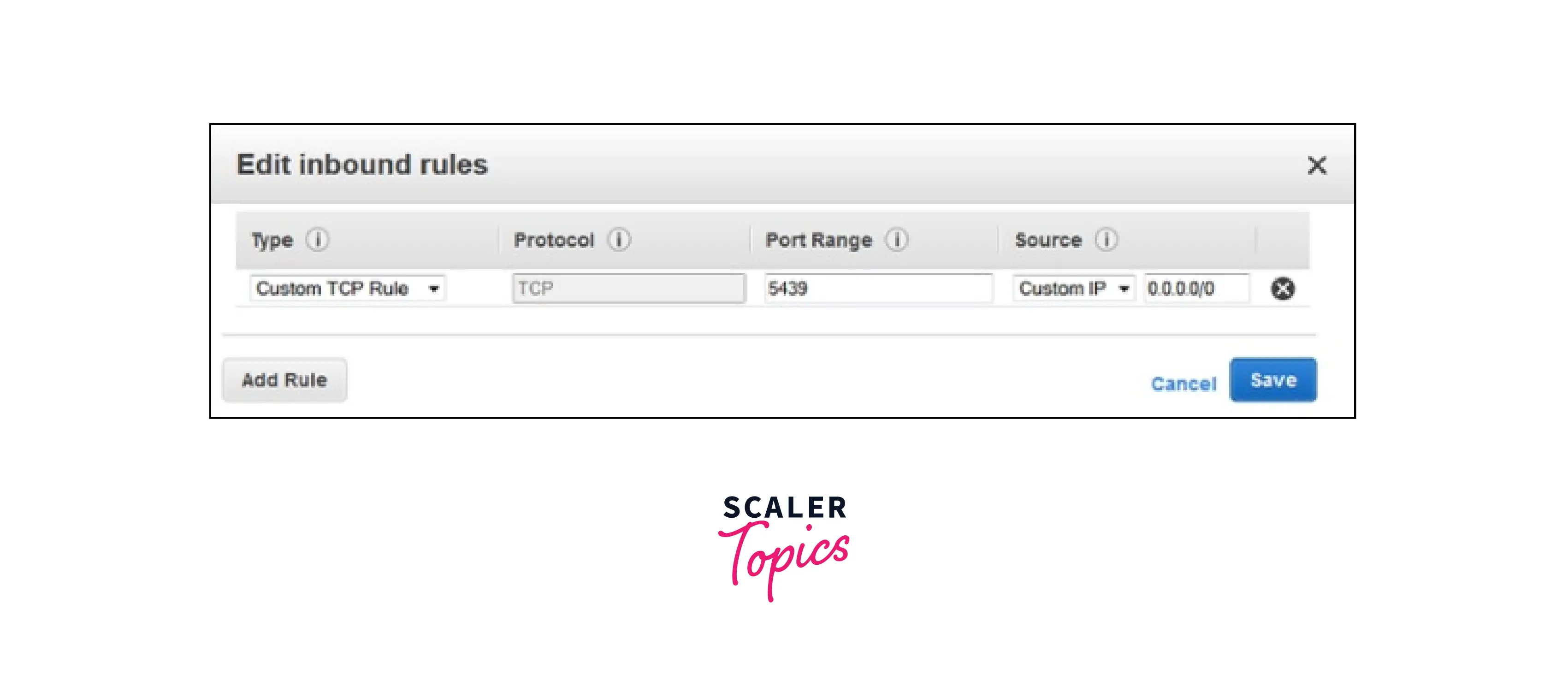
Click Edit button from the menu. Set the fields as indicated below, then press the Save button.
- For type choose Custom TCP and TCP in protocol.
- Type port number as 5439 as by-default port for Amazon Redshift is 5439.
- For Source, select the Custom IP and type 0.0.0.0/0.
Step 3 − Connect to Redshift Cluster.
Direct connections and SSL connections are the two choices to connect to the Redshift Cluster. The steps to connect directly are mentioned below.
- An SQL client tool can be used to connect to the cluster. Redshift AWS supports SQL client tools that work with ODBC or JDBC PostgreSQL drivers.
- Steps to get the Connection String:
- Cluster option can be chosen in the Navigation pane of the Amazon Redshift Console.
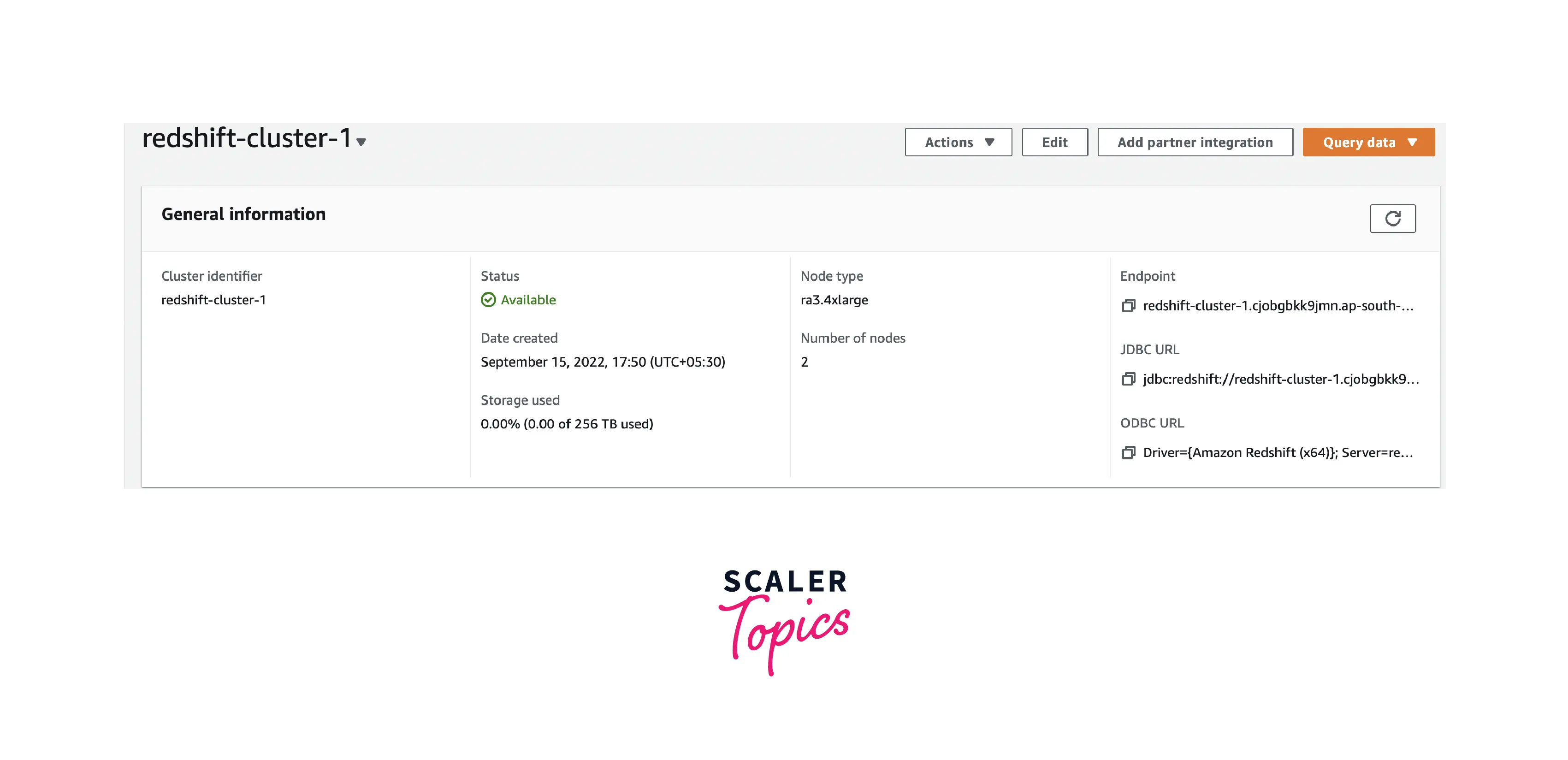
- Click the Configuration tab after selecting the desired cluster.
- When you click on Cluster Database Properties, a page with the JDBC URL appears as seen in the picture below. Copy the URL.
You must install SQL Workbench/J beacuse Redshift AWS does not provide any SQL client tools or libraries. SQL Workbench/J is a free, DBMS-independent SQL query tool that is used to run SQL queries either interactively or as a batch job.
To connect the Cluster to SQL Workbench/J, follow the steps below:
- Open SQL Workbench/J.
- Select Create a new connection profile.
- Click on the Manage Drivers button. After that the Manage Drivers dialogue box will appear.
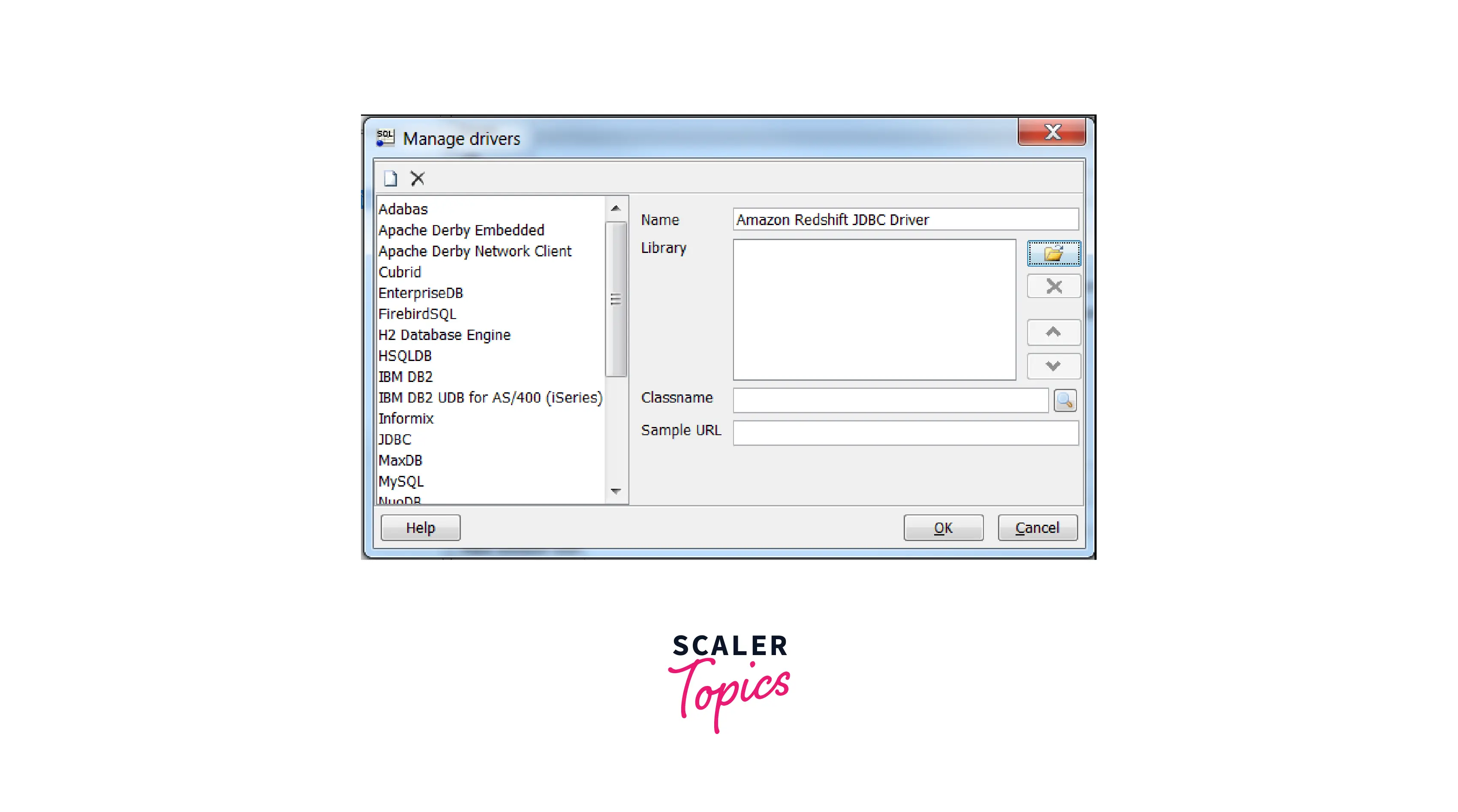
- Navigate to the driver location by clicking the folder icon.
- Select the JAR File(s) that are needed for the JDBC driver in SQL Workbench/J.
- Click the Open button to finish.
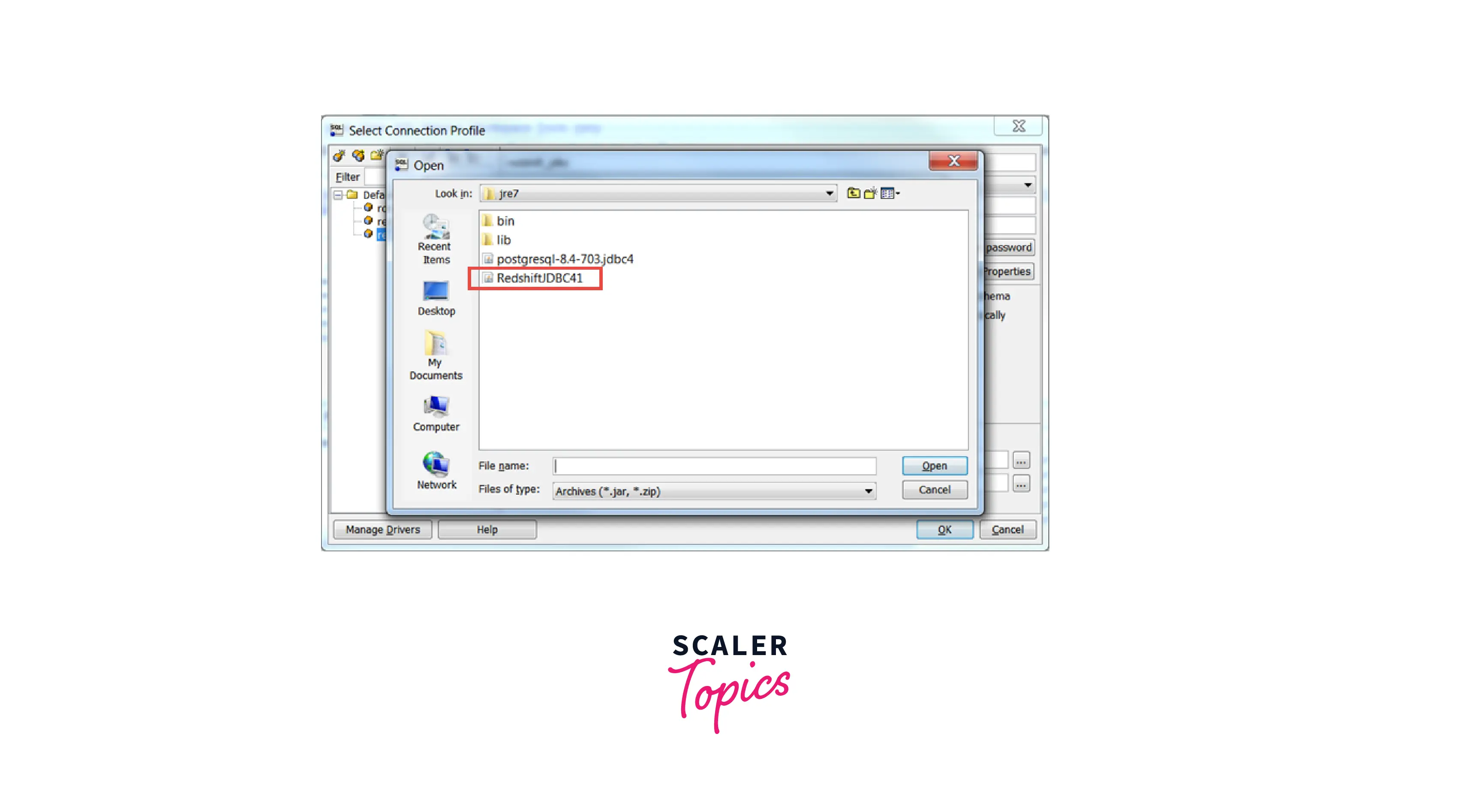
- Both the Classname and Sample URL boxes should be left empty. Select OK and Select the Driver from the list.
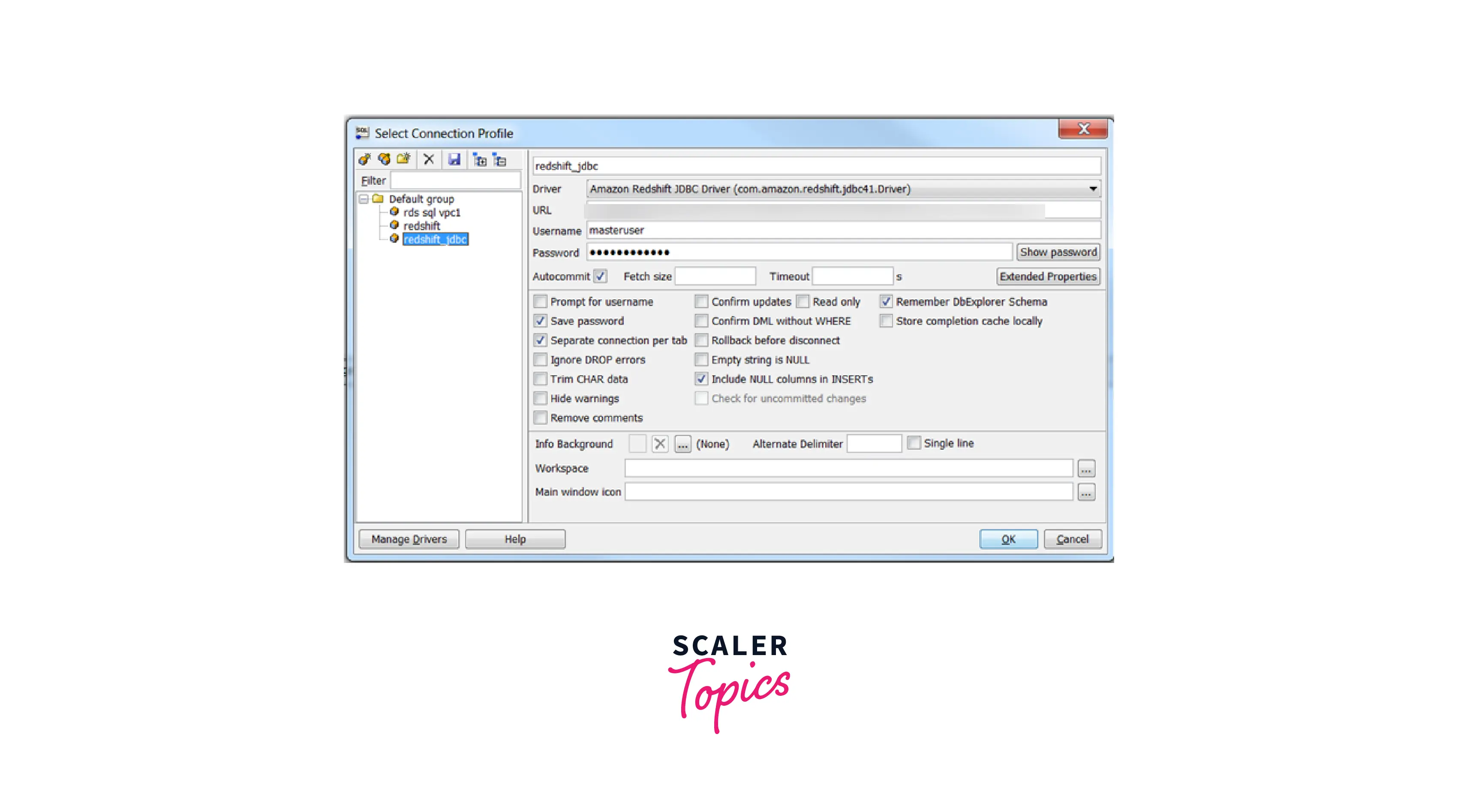
- In the Connection Profile page, paste the copied JDBC URL into the URL field. Also, enter the username and password that we created in the Database configuration section in Step 1.
- Select the Autocommit box.
- Click Save profile list.
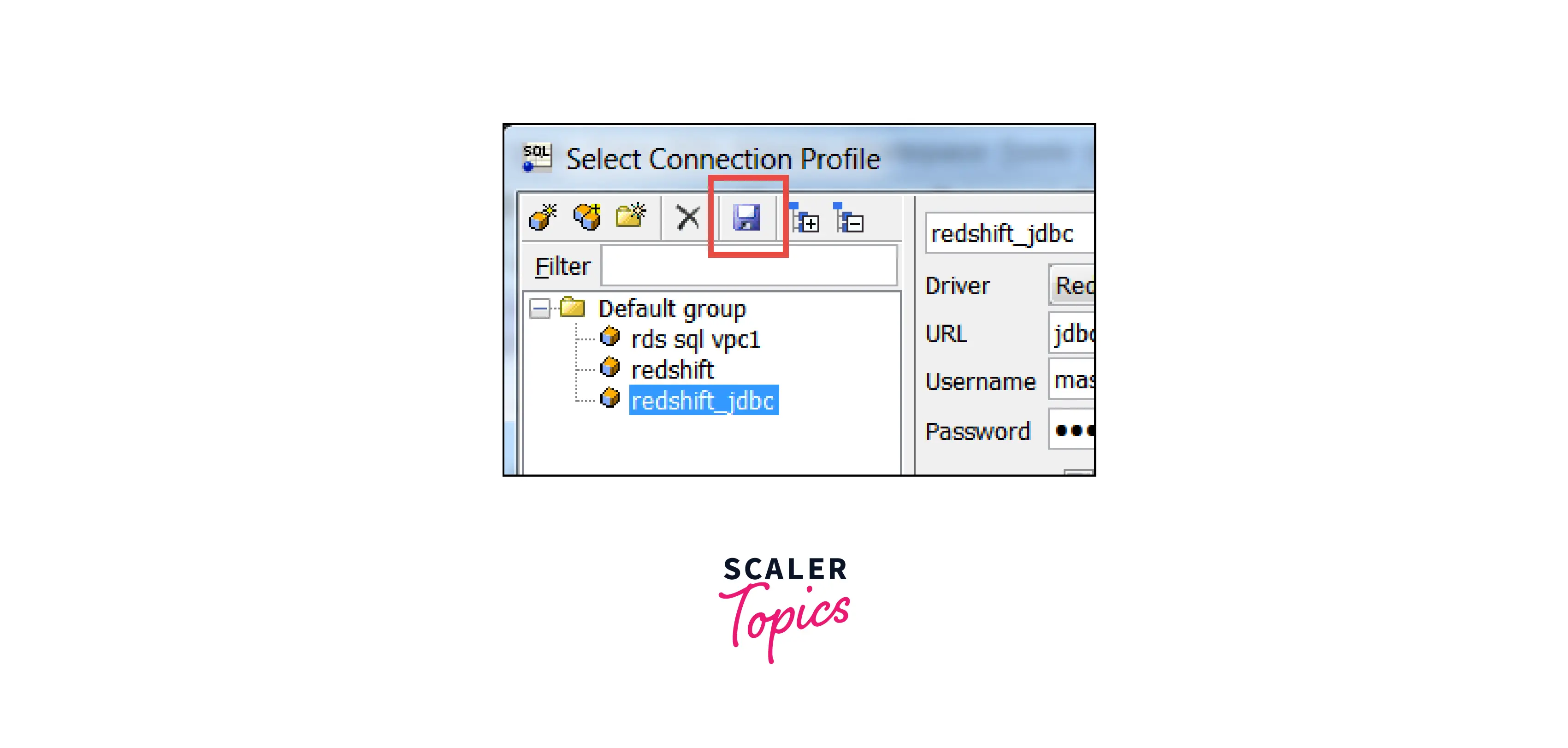
- Choose OK
Advantages and Disadvantages of Amazon Redshift
Advantages
The cost-benefit to your business is a very distinctive benefit of using AWS Redshift. It is considerably less expensive (roughly one-twentieth the price of rivals like Teradata and Oracle).
- Speed: When MPP technology is used, the speed of delivering output on larger datasets, especially when reaching petabytes of magnitudes, is unbeatable.
- Widely Adopted: One of the first cloud-native data warehousing technologies, Amazon Redshift, has a thriving and significant customer base.
- Scalability: Redshift is a flexible architecture that can scale in seconds to meet changing storage demands.
- Data Encryption: Redshift presents different encryption and security tools that make protecting warehouses even easier.
- Automate repetitive tasks: Redshift has features that make it possible to automate tasks that need to be done repeatedly.
- Ease of querying: The popular PostgreSQL querying language is similar to that used by Amazon Redshift. Anyone who is familiar with PostgreSQL can start interacting with Redshift Clusters by using their SQL skills.
- Performance And Security: Amazon Redshift is an MPP ( Massively Parallel Processing ) database. AWS Redshift gives you greater control over when data is viewable and accessible as Redshift includes SSL encryption for data in transit, and AWS S3 servers offer both client- and server-side encryption.
- Easy Deployment and Consistent Backup: Amazon automatically backs up data regularly. In just a few minutes, a Redshift cluster can be deployed from anywhere in the world.
Disadvantages
Prior to choosing Redshift as your data warehousing solution, it is crucial to take into consideration some of its disadvantages.
- OLAP Limitations: OLAP databases are optimized for analytical queries on large datasets. Hence, OLAP lacks in performing basic database tasks such as Insert / update / delete operations. It is often easier to re-create a table with new changes than to insert / update tables in Redshift.
- Indexing: Redshift indexes and stores data using distribution and sorting keys. To work on the database, you must understand the principles underlying the keys. AWS does not provide any system to change the keys or manage them with minimal knowledge.
- Uniqueness: Having unique data and avoiding redundancies is one of the fundamental principles of a database. No tool or method is offered by AWS Redshift to guarantee data uniqueness. Redshift will contain redundant data points if overlapping data from various sources is being migrated there.
- Parallel Uploads: Not all databases are supported for parallel upload by Redshift. Redshift supports ultra-fast MPP parallel uploads to Amazon S3, EMR, and DynamoDB. In an environment where multiple simultaneous users are executing queries, Redshift might experience performance issues.
Cost of Amazon Redshift
- You can start small at $0.25 per hour with Amazon Redshift and scale up to petabytes of data and thousands of simultaneous users.
- When you try Amazon Redshift Serverless for the first time you get a $300 credit with an expiration period of 90-days toward your storage and compute use.
- When you use on-demand nodes, you only pay for memory capacity by the hour with no long-term commitments and no upfront costs.You are billed hourly while the launched node is running, until it is terminated. The price depends on whether you are using Current generation or the previous generation as well as the region.
- You only pay for the compute capacity your data warehouse uses when it is active when you use the Amazon Redshift Serverless option.
- In Amazon Redshift managed storage pricing: You pay for the data stored at a fixed GB-month rate at the price of $0.024 per GB Storage/month.
- In Redshift Spectrum, we are charged $5 per terabyte of data scanned.
- You can get a two-month free trial of DC2 large node as part of the AWS Free Tier and receive 750 hours per month for free if you have created a Redshift cluster.
- Within the same AWS Region, there are no charges for data backup, restore, load, and unload operations between Amazon Redshift and Amazon S3.
Redshift vs Traditional Data Warehouses
A data warehouse is a center where data is collected from different resources. Raw data collected from the resources are transformed and presented in the form of reports to users. It provides the storage and analytics capacity needed to drive business intelligence.
Traditional data warehouses have existed for a very long time and presented numerous challenges. Building and maintaining a traditional data warehouse from scratch is very expensive. The cost of infrastructure is directly proportional to the size of the data, which requires management commitment and throughput planning. By using its unique architecture and business model, Amazon Redshift, a modern data warehouse, has helped different organizations in overcoming these challenges.
Redshift services can be scaled to meet demand, so an organisation only pays for the capacity they actually use at any particular time. As a result, Redshift provides a level of efficiency and agility that is not possible with other infrastructures or data warehouses.
Conclusion
- AWS Redshift is a fully managed, fast, petabyte-scale data warehouse service that makes it easy and affordable to analyze all of your data using the business intelligence tools.
- Redshift AWS dataset sizes range from a few hundred gigabytes to a petabyte. It provides access to data analytics tools, artificial intelligence and machine learning applications.
- In order to deliver the best performance, Amazon Redshift uses machine learning and AWS-designed hardware to analyse structured and semi-structured data from data warehouses.
- Redshift is a column-oriented OLAP-style (Online Analytical Processing) database. It is built on top of PostgreSQL. This suggests that Redshift can be used with standard SQL queries.
- A redshift warehouse is a collection of computing nodes, which are arranged in a cluster for organizational purposes.
- Amazon Redshift is used when there is a huge amount of data to analyze. For Redshift to be a viable solution, the data has to be at least of a petabyte-scale (10^15^ bytes).
- The massively parallel processing (MPP) design enables fast querying. With MPP, different computer processors work together concurrently to perform the required computations.
- When you try Amazon Redshift Serverless for the first time you are eligible for a $300 credit with a 90-day expiration date toward your compute and storage use.
- Within the same AWS Region, there are no charges for data backup, restore, load, and unload operations between Amazon Redshift and Amazon S3.
- Redshift provides a level of efficiency and agility that is not possible with other infrastructures or data warehouses.