AWS Batch
Overview
AWS Batch is a completely managed service that allows users to asynchronously perform batch computing tasks of any scale over multiple different servers. AWS Batch manages the architecture for you, reducing the effort and time required to deploy, operate, monitor, and scale your batch computing operations.
What is AWS Batch?
AWS Batch allows you to run cluster computing applications on the Amazon Cloud Platform. It is a way for developers, academics, and professionals to access large amounts of computer capability. AWS Batch automates the tedious task of installing and maintaining the necessary infrastructure. This application appropriately supplies resources based on workloads specified to eliminate ability constraints, reduce computational costs, and deliver speed.
AWS Batch Features
-
Scaling Resources for Computing When utilizing AWS Fargate with Batch, you may have a full queue, scheduler, and computing infrastructure without maintaining a single element of computing infrastructure by setting up just a few concepts in Batch (a CE, job queue, and task specification). AWS Batch offers Managed Computing Environments, which automatically provide and scale compute resources based on your supplied jobs' quantity and capacity needs for those who desire EC2 instances. If you need to use different settings for your EC2 instances, all you have to do is launch EC2 instances with the Amazon ECS agent and execute compatible Linux and Docker editions. AWS Batch will then launch batch jobs on the newly generated EC2 instances.
-
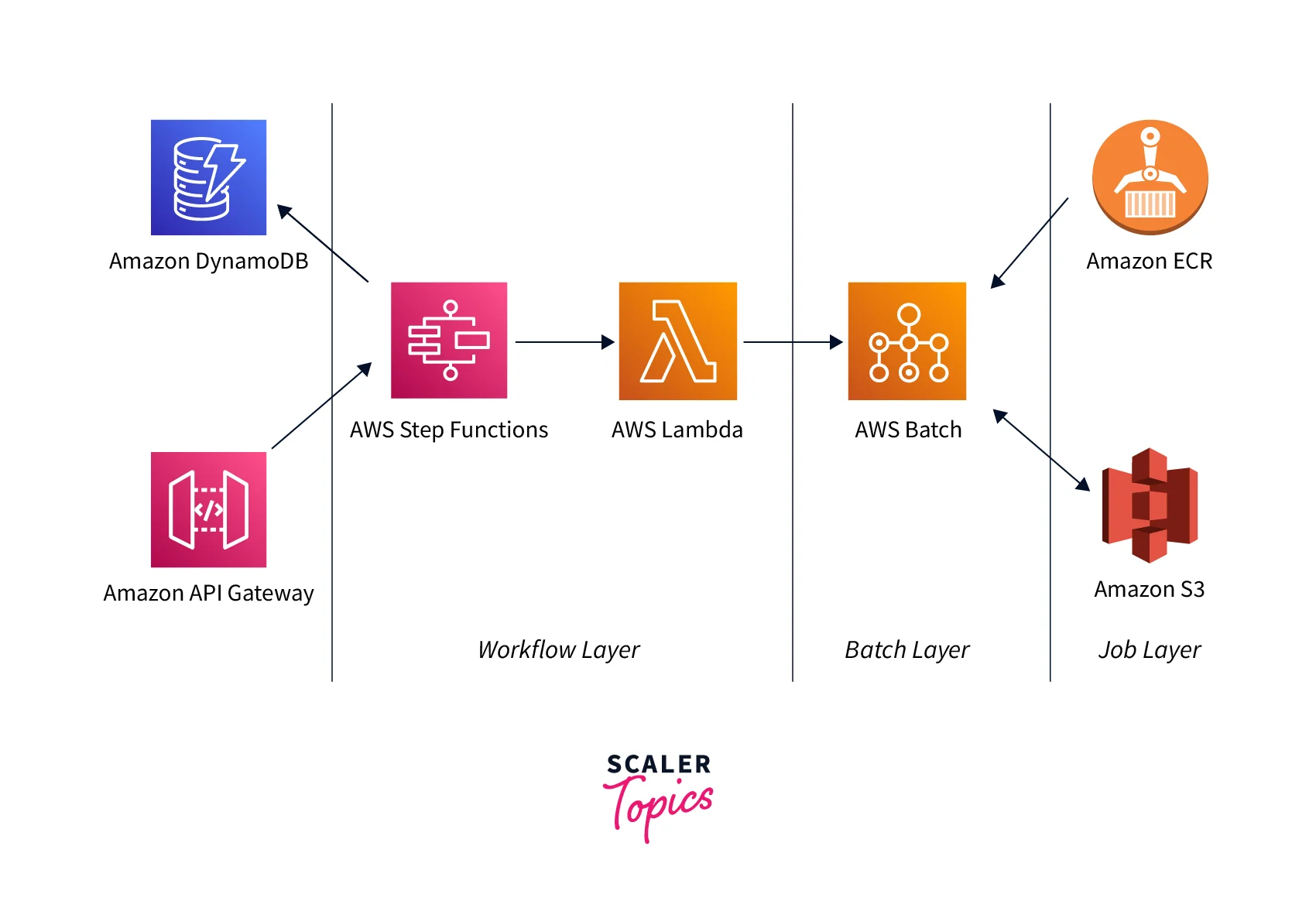
AWS Fargate with AWS Batch With AWS Batch and Fargate resources, you can create a serverless infrastructure for all batch operations. Fargate ensures that each task gets the precise amount of processing and storage required, resulting in no wasted resources, time, or the requirement to wait for an EC2 instance launching. If you're already using Batch, Fargate adds an extra degree of isolation from EC2. AMIs are not required to be managed or patched. If you have operations that operate on EC2 and others that run on Fargate, you don't have to worry about running two distinct processes when sending Fargate-compatible jobs to Batch. AWS offers a cloud-native planner that includes the managed queues and the capability to configure precedence, retries, constraints, latency, and other options. Batch handles Fargate submissions and job life cycles, so you don't have to.
-
Support for High-Performance Computing (HPC) Workloads that are Strongly Connected AWS Batch now supports multi-node concurrent tasks, allowing you to run the same jobs over numerous EC2 instances. This capability enables you to utilize AWS Batch to run operations such as huge, closely connected High-Performance Computing (HPC) applications simply and efficiently. AWS Batch also enables Elastic Fabric Adapter, a network interface that allows you to operate on AWS applications that demand high volumes of inter-node interaction.
-
Simple Job Dependency Modeling and Granular Job Descriptions AWS Batch enables you to describe how tasks will be performed by specifying resources such as CPU cores and RAM, AWS IAM roles, volume mounting points, container attributes, and configuration files. AWS Batch runs your jobs on AWS ECS as a container-based app. Batch also allows you to specify dependencies between tasks. For example, your batch task may consist of three distinct phases of processing, each with its resource requirements. You may use dependencies to build three tasks with distinct resource requirements, each dependent on the prior job.
-
Job Scheduling Based on Priority AWS Batch allows you to create several queues with varying priority levels. Batch jobs are queued until computational requirements are available to perform them. Considering each task's resource needs, the AWS Batch scheduler determines how, when, and where to perform queued jobs. As soon as no unresolved dependencies exist, the scheduler examines the priority of each queue and performs jobs in terms of priority on optimum computing resources.
-
EC2 Launch Templates Integration You may construct customized templates for your compute resources and scale instances to match those demands using EC2 Launch Templates. To add storage volumes, select network interfaces, and specify permissions, you may construct your EC2 Launch Template. EC2 Launch Templates reduce the steps required to create Batch environments by encapsulating launch parameters within one resource.
-
Available Allocation Techniques Customers can select three techniques for allocating compute resources using AWS Batch. These solutions let clients consider throughput and pricing when determining how AWS Batch should expand instances on their behalf. Best Match: AWS Batch chooses the instance type that best meets the demands of the jobs, with a preference for the EC2 instance with the lowest possible cost. If further instances of the specified instance type are not accessible, it will wait for them to become readily accessible. If there aren't enough instances accessible, or if the client has reached Amazon EC2 service restrictions, subsequent jobs will be held until the present ones finish. This allocation technique reduces expenses but limits scalability. Best Fit Progressive: AWS Batch will choose new instance types that are big enough just to satisfy the needs of the queued jobs, with preferred instance types having less cost per unit vCPU. AWS Batch will choose new instance types if additional instances are present for our selected instance types. Spot Capacity Optimized: AWS Batch may choose from a variety of instance types that are large enough to satisfy the needs of the queued tasks, with priority given to less interrupted instance types. However, this method is only available for spot occurrences.
-
Access Control with Granularity AWS Batch uses AWS IAM to govern and manage the resources which your tasks may access, for example, AWS DynamoDB tables. You may also create policies for distinct individuals in your business using IAM. For instance, administrators can provide complete access to any AWS Batch API activity, programmers can be given restricted access to creating compute setups and registration tasks, and end users can be limited to the rights required to create and remove jobs.
AWS Batch Use Cases
- Automatic examination of operational costs, accomplishment statistics, and stock performance daily
- Explore libraries of tiny compounds quickly to collect accurate statistics for drug creation.
- Reduce the requirement for human involvement due to interdependence by automating content-rendering duties.
- Run compute-intensive ML training model and assessment effectively at any scalability.
- Link natively with AWS to enable scalability, connectivity, and administration features.
- Cut expenses by distributing computing jobs depending on volume and resource needs.
- Instantly scale your computational resources using managed service infrastructure that allows huge computation and modeling.
- AWS Batch streamlines complicated media supply chain workflows by coordinating the execution of diverse and dependent jobs at various levels of processing, and it provides a single framework for managing content preparation for various media supply chain contributors.
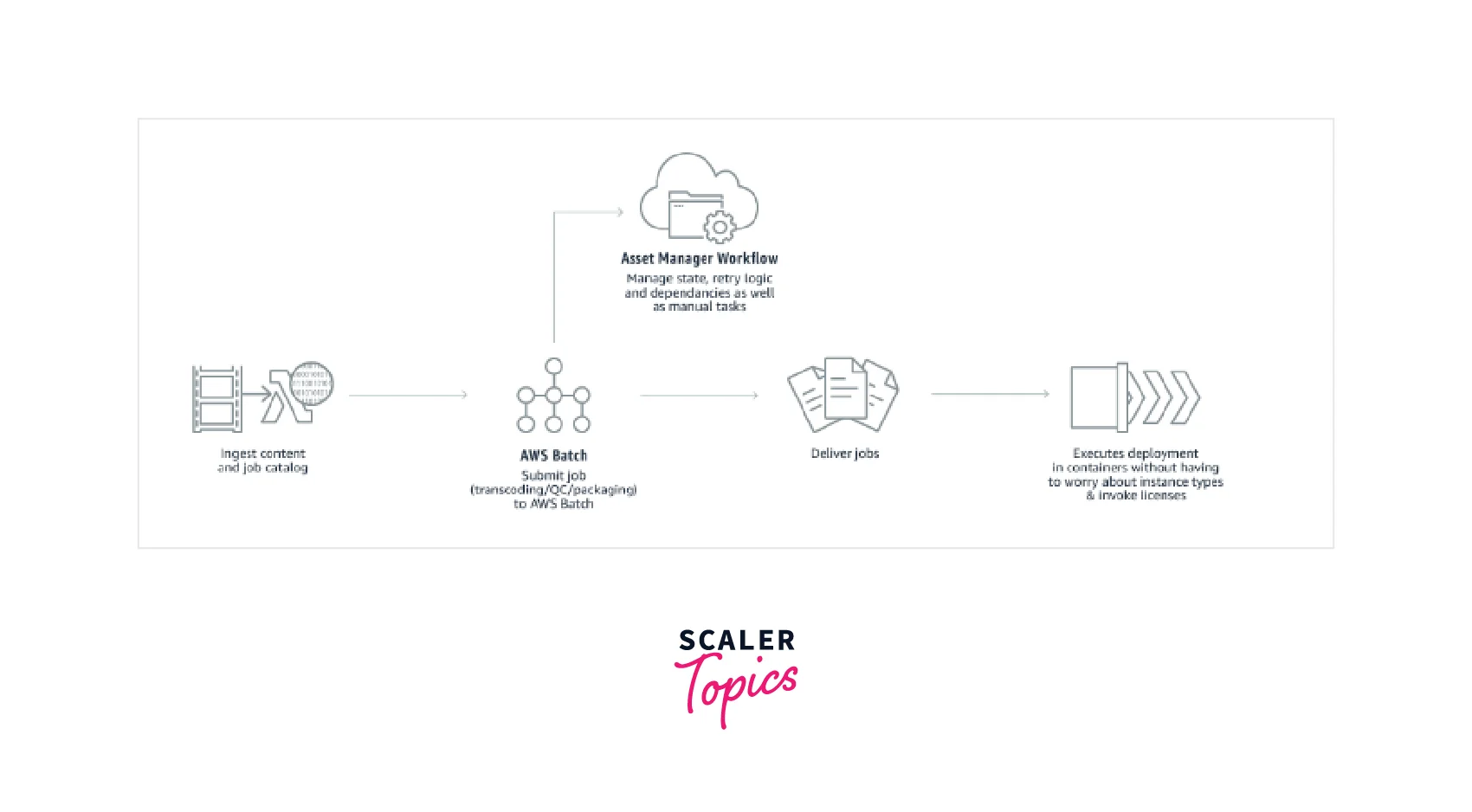
- By scheduling and monitoring the execution of asynchronous operations, AWS Batch speeds batch and file-based transcoding workloads by automating workflows, overcoming resource bottlenecks, and lowering the number of manual procedures.
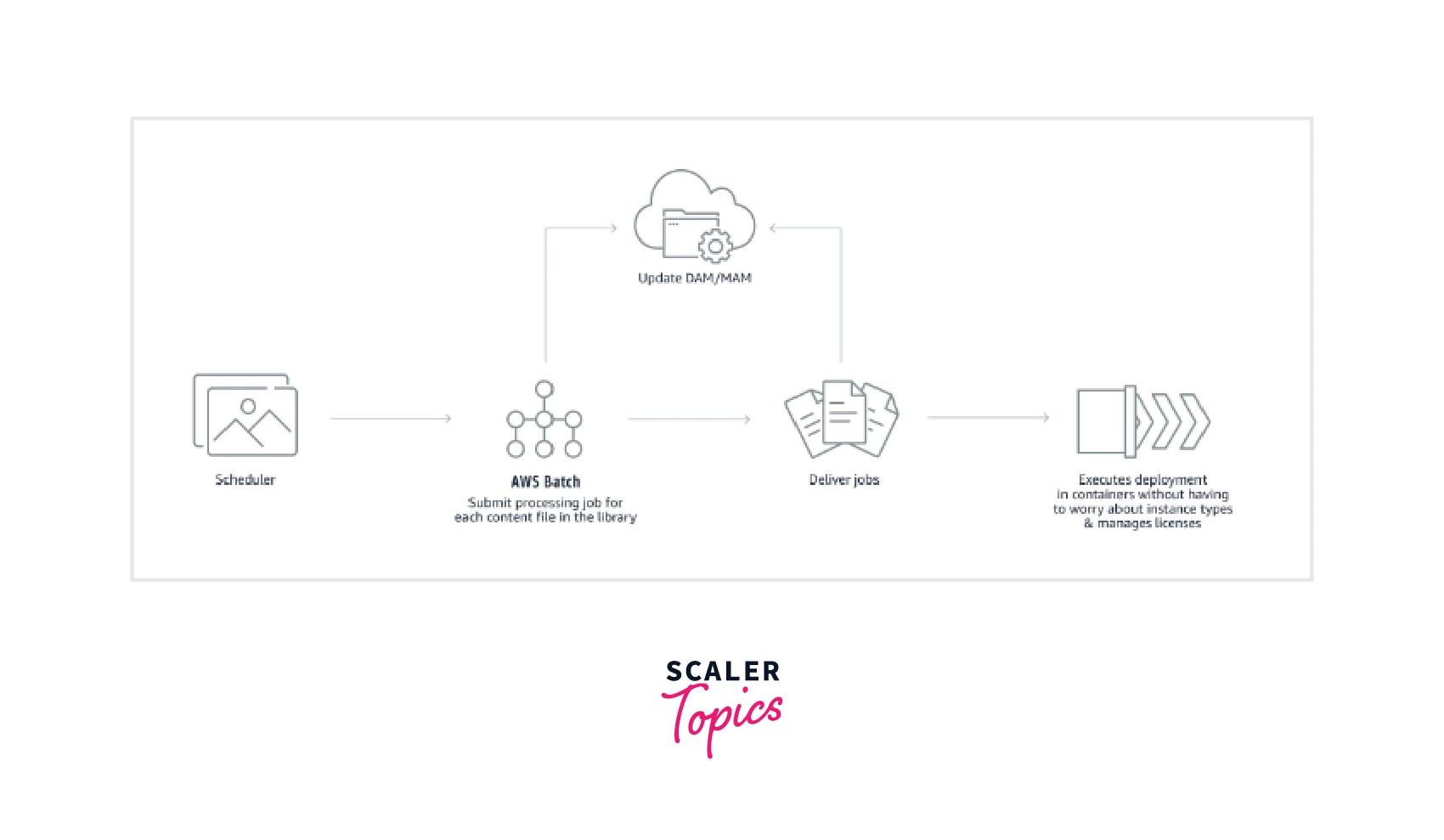
- AWS Batch gives content creators and post-production organizations options to automate content rendering tasks, reducing the need for human intervention due to execution dependencies or resource scheduling.
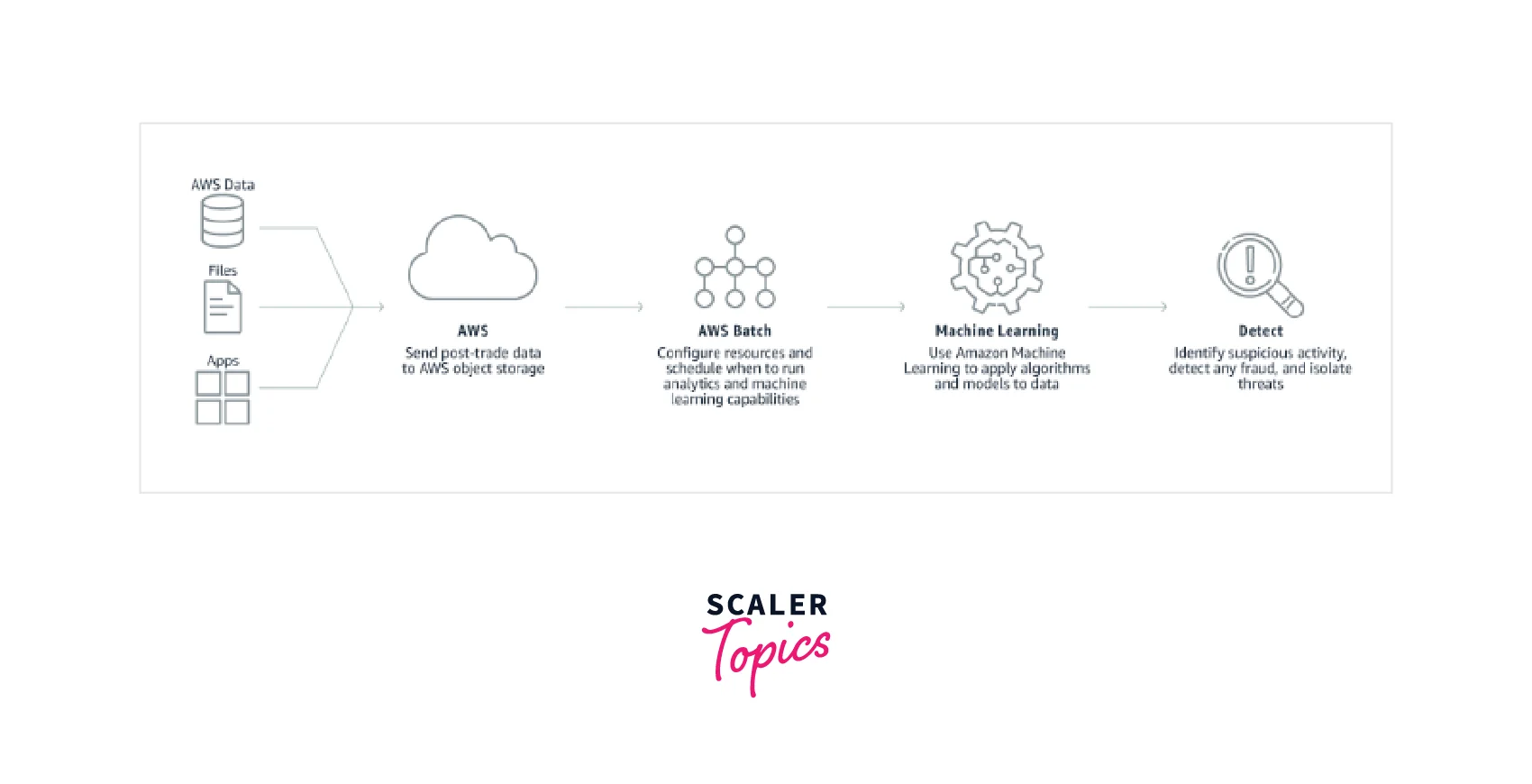
- Organizations may use AWS Batch to automate the data processing or analysis necessary to detect abnormal patterns in data that could indicate fraudulent conduct such as money laundering and payment fraud.
AWS Batch Components
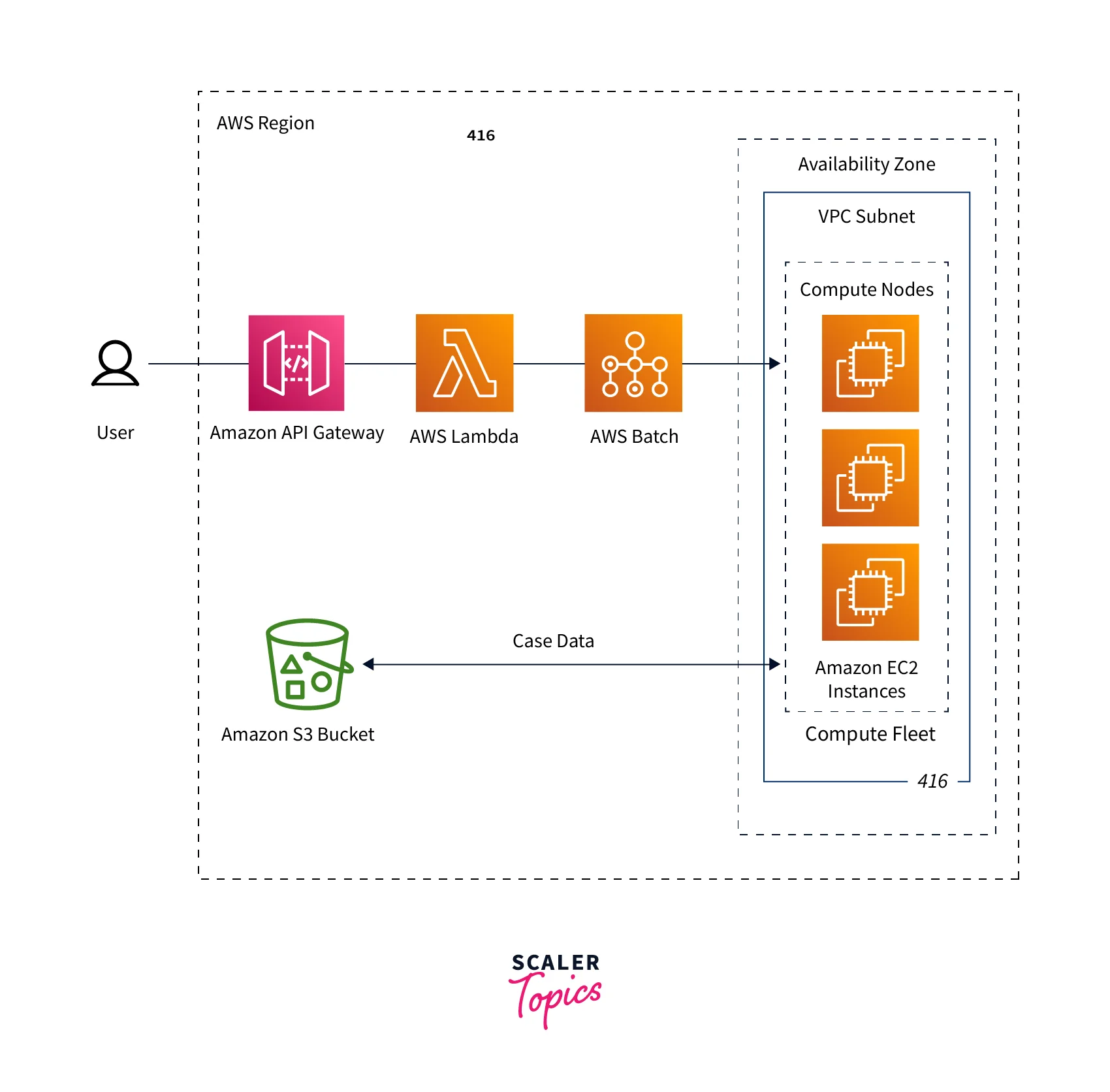
AWS Batch streamlines the execution of batch processes across various AWS Regions. AWS Batch computing environments may be created within an existing or a new Virtual Private Cloud. After a computing environment has been established and linked to a job queue, you may write job descriptions that indicate which Docker Container images will be used to perform your jobs. Containers' images are kept in and retrieved via container repositories that may be located in (or) out of the AWS environment.
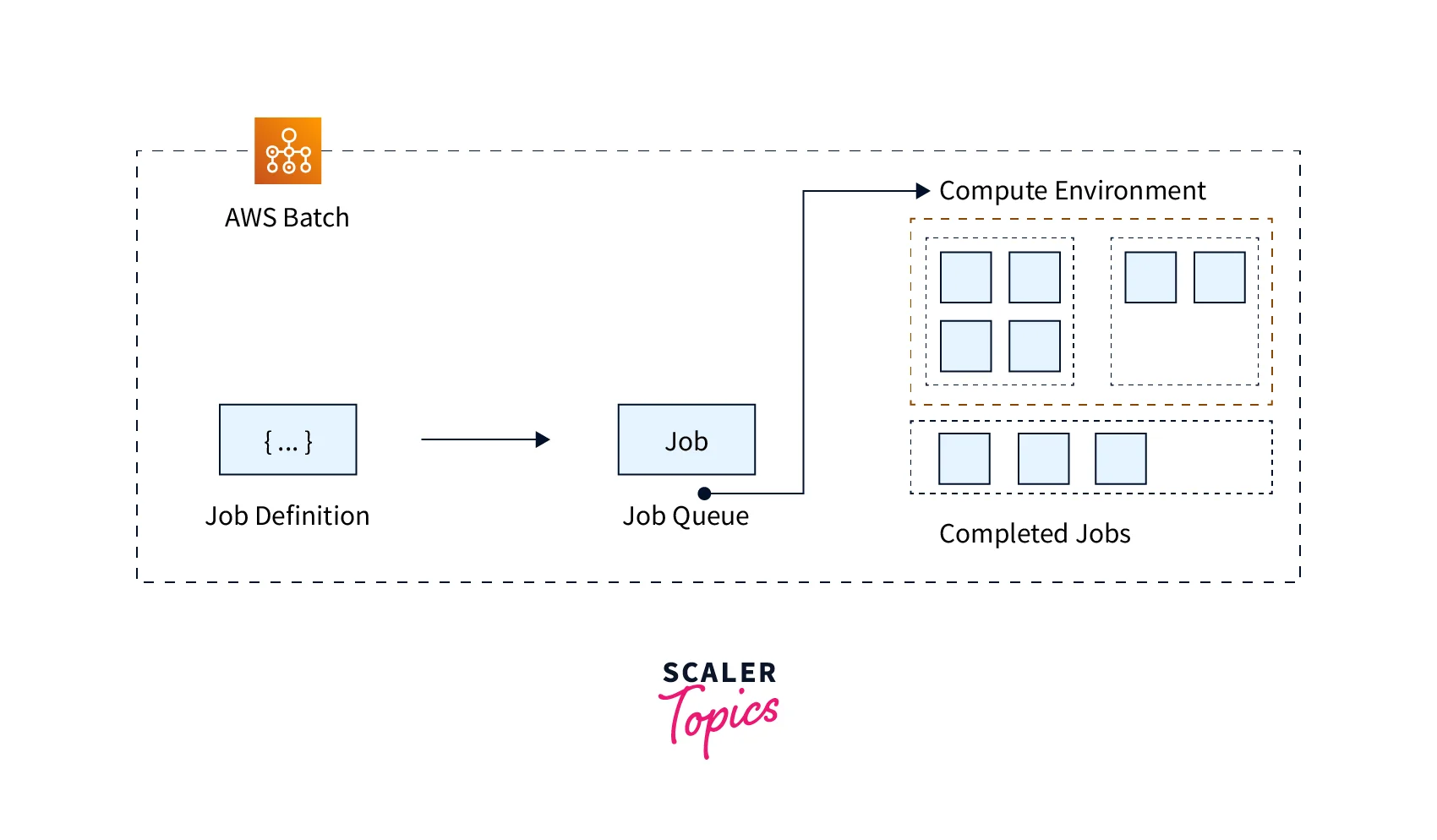
Jobs
The user provides a piece of work to AWS Batch, such as a Shell Script, Docker container image, and Linux Executable. Users can provide the name and parameters in the jobs definitions which run the AWS EC2 instances in your environment. One job can reference the other jobs with job ID (or) name and can depend on the execution of that other jobs.
Types of Jobs
- Array Jobs An array job is one that has shared parameters such as the task specification, vCPUs, and memory. It operates as a set of related but distinct basic jobs that may be deployed across different hosts and executed concurrently.
- Multi-Node Parallel Jobs You may execute large-scale, closely linked, high-performance computing applications and distributed GPU model training using AWS Batch multi-node parallel processes without having to launch, configure, and manage Amazon EC2 resources directly.
- GPU Jobs GPU jobs help you to run jobs that use an instance's GPUs.
Job States
- SUBMITTED A job that's submitted to the queue, and has not yet been evaluated by the scheduler. If there are dependencies, the job is moved to PENDING. If there are no dependencies, the job is moved to RUNNABLE.
- PENDING A job that resides in the queue and isn't yet able to run due to a dependency on another job or resource. After the dependencies are satisfied, the job is moved to RUNNABLE.
- RUNNABLE A job that resides in the queue, has no outstanding dependencies and is therefore ready to be scheduled with a host.
- STARTING These jobs have been scheduled to a host and the relevant container initiation operations are underway. After the container image is pulled and the container is up and running, the job transitions to RUNNING.
- RUNNING The job is running as a container job on an Amazon ECS container instance within a computing environment. When the job's container exits, the process exit code determines whether the job succeeded or failed. An exit code of 0 indicates success, and any non-zero exit code indicates failure.
- SUCCEEDED The job has successfully completed with an exit code of 0. The job state for SUCCEEDED jobs is persisted in AWS Batch for at least 7 days.
- FAILED The job has failed all available attempts. The job state for FAILED jobs is persisted in AWS Batch for at least 7 days.
AWS Batch Job Environment Variables
- AWS_BATCH_CE_NAME This variable is set to the name of the compute environment where your job is placed.
- AWS_BATCH_JOB_ARRAY_INDEX This variable is only set in child array jobs. The array job index begins at 0, and each child job receives a unique index number.
- AWS_BATCH_JOB_ATTEMPT This variable is set to the job attempt number. The first attempt is numbered 1.
- AWS_BATCH_JOB_ID This variable is set to the AWS Batch job ID.
- AWS_BATCH_JOB_NODE_INDEX This variable is only set in multi-node parallel jobs. This variable is set to the node index number of the node. The node index begins at 0, and each node receives a unique index number.
- AWS_BATCH_JOB_NUM_NODES This variable is set to the number of nodes that you have requested for your multi-node parallel job.
- AWS_BATCH_JQ_NAME This variable is set to the name of the job queue to which your job was submitted.
Job Dependencies
When submitting an AWS Batch job, you can indicate the job IDs on which the job is dependent. When you do this, the AWS Batch scheduler guarantees that your job runs only after the stated requirements have been completed successfully. When they are successful, the dependent job moves from PENDING to RUNNABLE, then to STARTING and RUNNING. If any of the job dependents fails, the dependent job goes from PENDING to FAILED.
Job A, for example, can express a reliance on up to 20 other tasks, all of which must succeed before it can execute. You can then submit further jobs that are dependent on Job A as well as up to 19 other jobs.
You can declare a SEQUENTIAL type dependence for array tasks without supplying a job ID so that each child array job completes sequentially, beginning at index 0. You may also use a job ID to establish an N TO N type dependence. As a result, each index child of this task must wait for the matching index child of each dependence to finish before starting.
Job Timeouts
You can set a timeout duration for your jobs so that if they run longer than that, AWS Batch will terminate them. For instance, suppose you have a job that you know should only take 15 minutes to accomplish. Because your application may become trapped in a loop and operate indefinitely, you can set a timeout of 30 minutes to end the stalled operation.
In your task specification or when you submit the job, you include an attemptDurationSeconds parameter, which must be at least 60 seconds.
Timeout terminations are handled as best as possible. You should not anticipate your timeout to be terminated exactly when the job attempt expires (it may take a few seconds longer). If your application necessitates exact timeout execution, accordingly logic has to be implemented.
A job that is terminated due to exceeding the timeout length is not retried. If a task attempt fails independently, it can retry if retries are enabled, and the timeout countdown for the current attempt is reset.
Child jobs in an array have the same timeout configuration as the parent job.
Job Definitions
It outlines the job execution. An outline of your work's resources is what you may refer to as a job description. To grant access to additional AWS resources, you may give your task to the IAM role. You also include the necessary CPU and memory specifications. Additionally, the job definition controls configuration files, centralized storage mount points, and container properties. When publishing individual Jobs, it is possible to specify new values in place of many parameters included in the job definition.
Job Queues
AWS Batch tasks are queued in a particular job queue until they are scheduled to be executed on a computing environment. A work queue is linked to many computing environments. You may also specify priorities for these computing environments and separate work queues. You can have a priority queue for time-sensitive jobs that you send and a lower priority queue for any time jobs. Computational power is less expensive.
To Create a Job Queue:
- Go to link to access the AWS Batch console.
- Select the Region to utilize from the navigation bar.
- Select Job Queues, and Create from the navigation pane.
- Enter a unique name for your work queue in the Job queue name field. There can be up to 128 letters (uppercase and lowercase), digits, and underscores.
- Enter an integer number for the work queue's priority in Priority. When coupled with the same computing environment, job queues with a higher priority are reviewed first.
- Select Enabled for State so that your job queue may accept job submissions.
- Select one or more computing environments from the list to associate with the work queue in the order that the queue should try a placement in the Connected compute environments section. You can link up to three computed environments with a job queue.
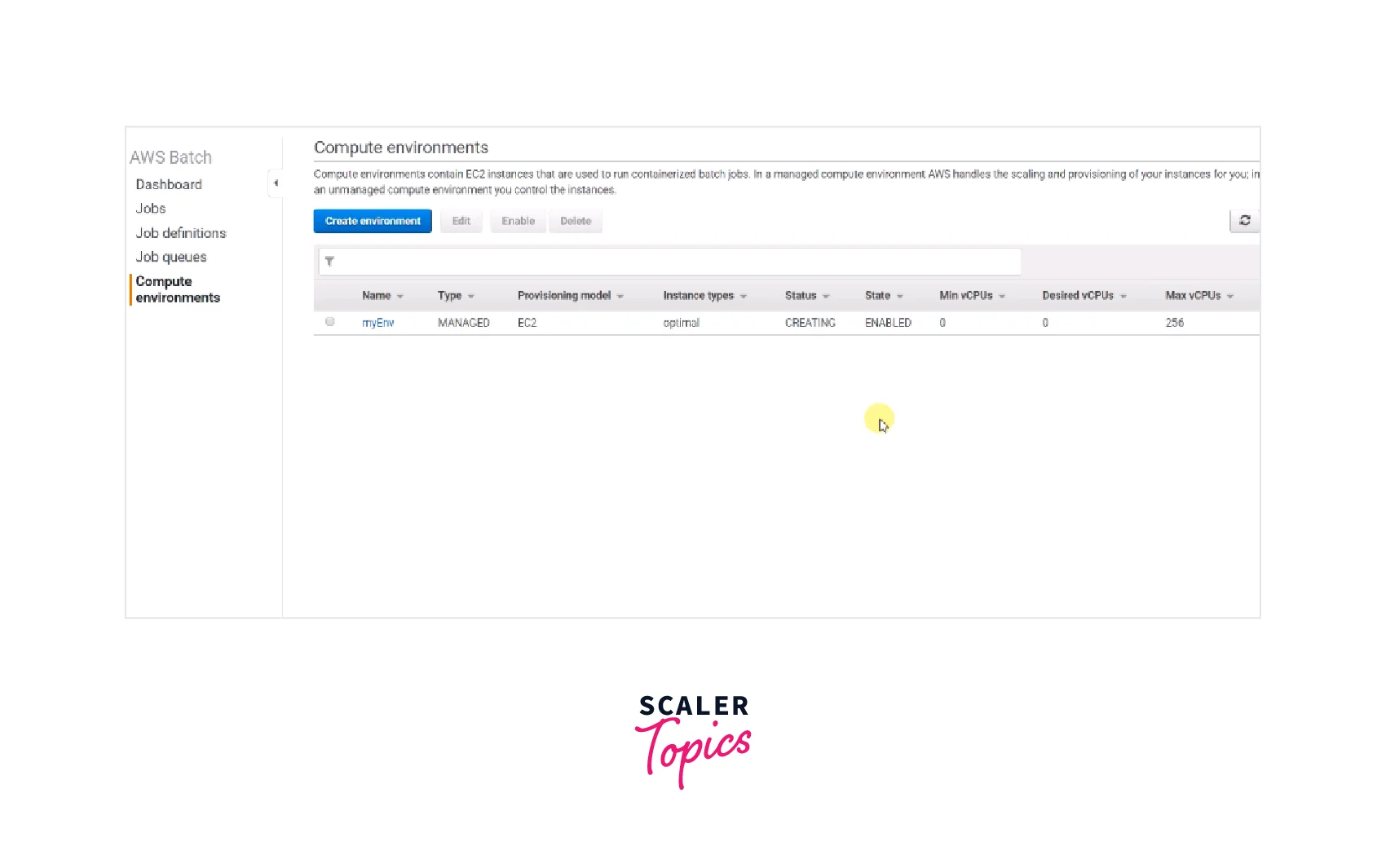
Compute Environment
- A collection of computing resources is referred to as a computing infrastructure used to execute tasks.
- When using managed computing setups, you select the desired computation type at various levels. You may create computing environments that utilize a certain EC2 instance.
- You may create computing environments that utilize a certain EC2 instance.
- Only stating that you wish to utilize the latest instance types is an alternative. Other options include a targeted set of VPC subnetworks and the price you're ready to shell out for EC2 Spot Instances as a part of the cost of On-Demand Instances.
- Users can select the environment's minimal, preferred, and largest number of virtual machine instances.
How to Initiate and Launch Pipeline AWS Batch Jobs
It allows users to install and configure batch computing tools to spend more time studying data and solving problems. The AWS batch Tasks tool makes starting and running data pipeline jobs a breeze.
1. Prerequisites
- Check that your AWS Batch area's task queue and computing environment are operational.
- User will need the ready-to-use configured Docker environment to produce the pipeline jobs.
- Install the AWS CLI beforehand, which enables the user to send the required commands to the different Amazon Services.
2. Building the Fetch and Run Docker image
The "fetch and run" Docker image is a script that uses the AWS Command Line Interface(CLI) by accepting the environment variables for running the job scripts.
After unzipping the "fetch and run" folder, you'll discover two files: Dockerfile and fetch_and_run.sh.
Run the below command to make the docker image. docker build -t x/fetch_and_run
It will generate as shown below:

3. Creating an ECR Repository
Create an ECR repository that will allow you to store, maintain, and delete Docker images. You may save the docker image and adjust accessibility privileges so that the AWS Batch Tasks tools can properly retrieve the newly generated "fetch-and-run" docker image while running pipeline tasks.
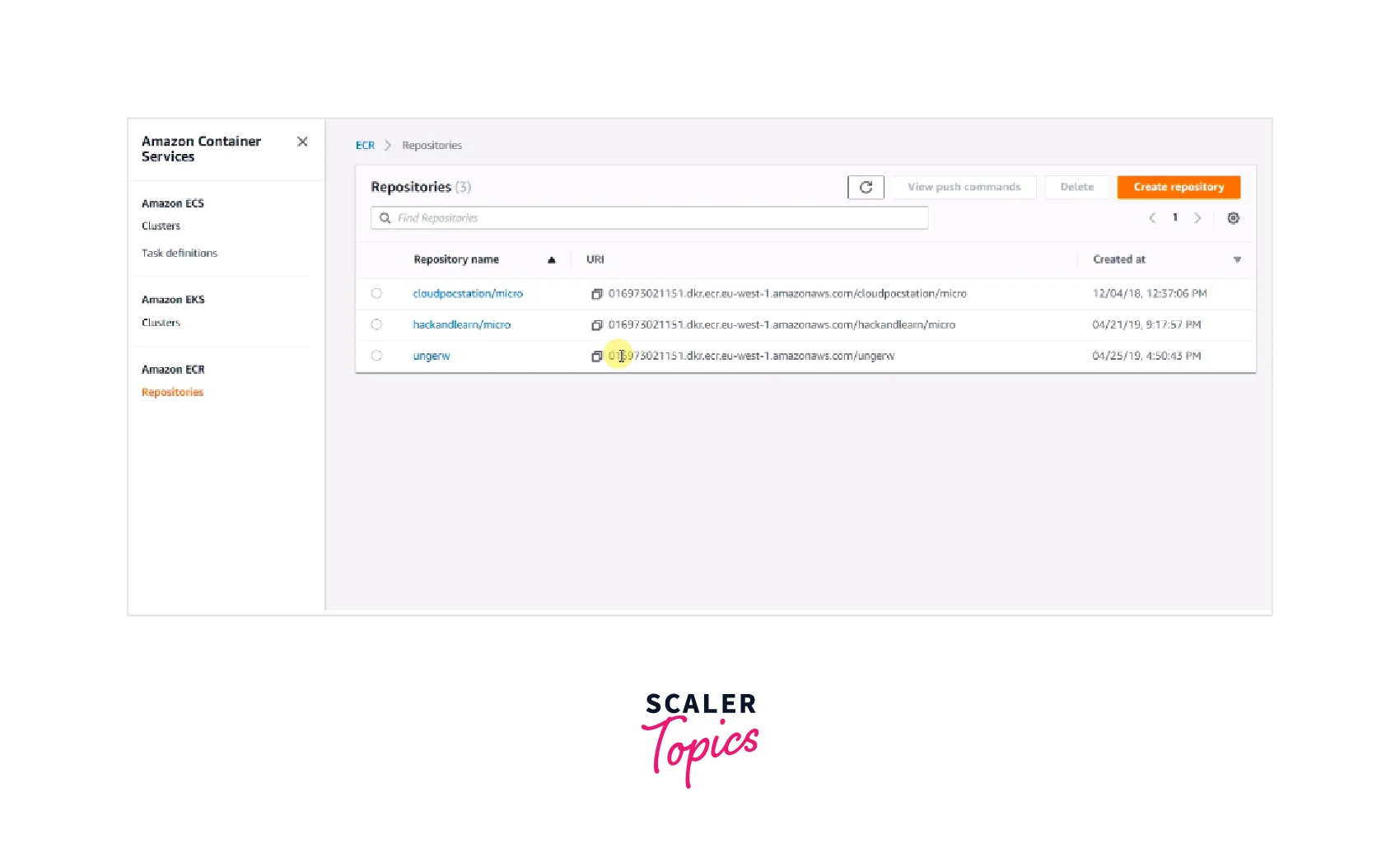
- First, log in to the ECR interface and click "Create Repository."
- Next, enter "x/fetch and runun" as the ECR repository name and then click on "Next Step."
4. Pushing the Docker Image to the ECR repository
The Docker image should now be uploaded to the newly created "x/f and e" repository. Run the script in the AWS CLI to carry out the process of adding the Docker images to the ECR repository.
5. Upload the Pipeline Job to AWS S3
The first step is to make a file named "PJ.sh" using the sample text below, after which you must submit the scripts to an AWS S3 bucket.
After executing the given code, execute the following command to publish the scripts to the AWS S3 bucket.
5. Creating an IAM Role
The user will need an IAM role to access the batch job from AWS S3. So as "fetch and run" will need the job description stored in the AWS S3, we need the IAM Role.
6. Creating a Job Definition
Now, gather all of the sources and write a job definition to utilize when launching job batches Jobs tool activities.
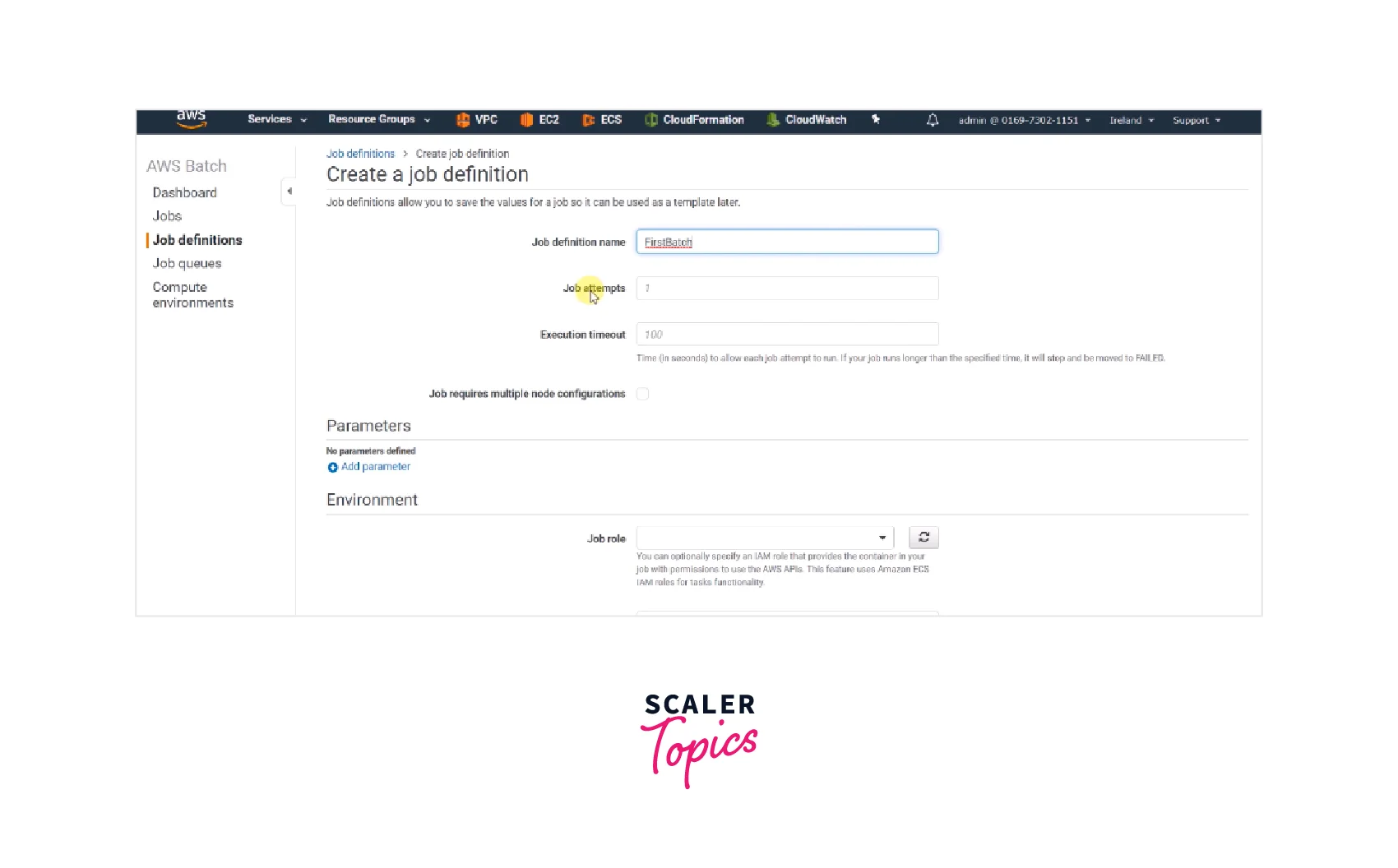
- Navigate to the AWS Batch Jobs dashboards and choose the Job Definitions.
- Then enter "fetch and run" in the Job Definition area.
- Once all the essential fields have been completed, click "Create job definition".
7. Running a Pipeline Job
- At this step, you should submit and execute a task that uploads and executes the job script utilizing the "fetch and run" images.
- Select Submit Job under the Jobs menu in the AWS batch jobs tool interface's left sidebar.
- In the Job entry box, type "script test."
- Then, in the Task description field, select the freshly produced retrieve and execute job description.
- In the Job Queue box, select the first-run job queue.
AWS Batch Pricing
- There are no extra fees with AWS Batch.
- You pay for the AWS resources you construct, for example, EC2 instances, AWS Lambda functions, or AWS Fargate, to store and execute your application.
- You may leverage your Reserved Instances, Savings Plan, EC2 Spot Instances, and Fargate with AWS Batch by selecting your compute-type needs while setting up your AWS Batch computing environments. Discounts can be applicable at the time of billing.
Benefits of AWS Batch
- Services in Finance It is used by various financial services firms ranging from fintech startups to established corporations for risk management, end-of-day trade processing, and fraud monitoring. You may use AWS Batch to eliminate human error, boost speed and accuracy, and cut expenses through automation, allowing you to focus on the business's evolution.
- Computing with High Performance In areas such as pricing, market position, and risk management, the Financial Services industry has expanded the use of high-performance computers. Organizations have gained speed, scalability, and cost savings by moving compute-intensive applications to AWS. Organizations may use AWS Batch to automate the sourcing and scheduling of these activities, saving money and speeding up decision-making and go-to-market times.
- After-Trade Analysis Trading desks are continuously looking for ways to enhance their positions by examining, among other things, the day's transaction expenses, execution data, and market performance. This necessitates batch processing of enormous data sets from many sources after the trading day has ended. AWS Batch provides the automation of these tasks, allowing you to understand the relevant risk heading into the following day's trading cycle and make smarter data-driven decisions.
- Fraud Monitoring Fraud is an issue that affects all businesses, particularly financial services. Amazon Machine Learning allows more intelligent data analysis through algorithms and models to address this issue. Organizations can automate the data processing or analysis necessary to discover odd patterns in their data that might signify fraudulent activities such as money laundering and payments fraud when combined with AWS Batch.
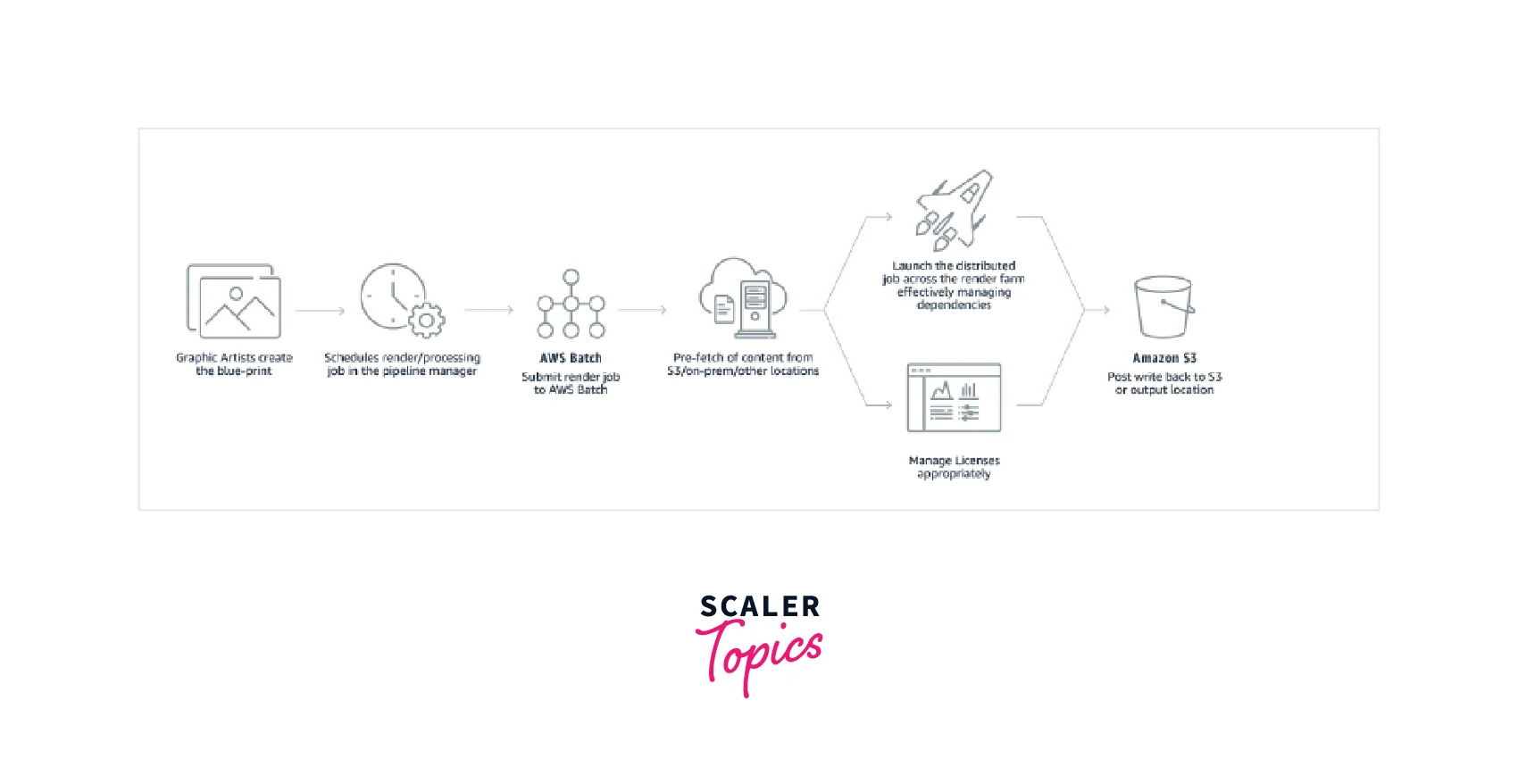
- Life Sciences AWS Batch enables drug discovery researchers to explore libraries of tiny compounds more efficiently and quickly to select structures most likely to attach to a therapeutic target, generally a protein receptor or enzyme. Scientists can collect better data to begin drug design and better knowledge of the importance of a certain biochemical process, which might lead to the creation of more effective medications and cures.
- Sequencing of DNA After doing primary analysis on a genomic sequence to generate raw files, bioinformaticians can utilize AWS Batch to perform secondary analysis. Customers may utilize AWS Batch to simplify and automate the assembly of raw DNA reads into a full genomic sequence by comparing multiple overlapping reads and the reference sequence, possibly reducing data mistakes caused by the erroneous alignment between the reference and the sample.
- Electronic Media AWS Batch gives content creators and post-production companies the tools to automate content rendering tasks, reducing human intervention due to execution dependencies or resource scheduling. This covers scaling computing cores in a render farm, using Spot Instances, and coordinating the execution of various process stages.
AWS Batch vs AWS Lambda
According to the creators of AWS, AWS Batch offers "Fully Managed Batch Processing at Any Scale." It enables programmers, researchers, and engineers to run thousands of batch computing tasks on AWS promptly and efficiently. It dynamically assigns the optimal number and kind of computing resources based on the submitted batch jobs' volume and specific resource demands.
On the other hand, AWS Lambda is said to be able to "automatically run code in response to changes to objects in Amazon S3 buckets, messages in Kinesis streams, or updates in DynamoDB." AWS Lambda is a computing service that automatically runs your code in response to events and maintains the underlying compute resources for you. You may create your back-end services that operate at AWS scale, performance, and security, or you can use AWS Lambda to add unique logic to existing AWS services.
Conclusion
- Users can run a single task on numerous servers using AWS Batch multi-node parallel jobs. Because multi-node parallel job nodes are single tenants, only one job container is executed on each Amazon EC2 instance.
- When using AWS Batch, there are no additional costs. The user only needs to pay for the AWS resources you create, such as EC2 instances, AWS Lambda functions, or AWS Fargate, to store and run your application.
- You may define resources like CPU cores and RAM, AWS IAM roles, volume mounting points, container properties, and configuration files in AWS Batch to determine how tasks will be carried out.
- The tools they need to automate content rendering operations are provided by AWS Batch, which minimizes the requirement for human involvement.
- AWS Batch provides essential data for your batch tasks. You may monitor indications of computing capacity and active, pending, and completed jobs.