Data Warehousing on AWS
Overview
A data warehouse is a central collection of data that can be examined to help decision-makers become more knowledgeable. Transactional systems, relational databases, and other sources all regularly and continuously feed data into a data warehouse. Through business intelligence (BI) tools, SQL clients, and other analytics software, business analysts, data engineers, data scientists, and decision-makers have access to the data.
What is a Data Warehouse?
A Data Warehouse is a centralized collection of integrated data that, when analyzed, may help with crucial choices that have a lot riding on them. Before entering the data warehouse, data is cleaned and validated as it flows from transactional systems, relational databases, and other sources.
To remain competitive, organizations now cannot function without data and analytics. For data analysis, performance monitoring, and decision assistance, business users rely on reports, dashboards, and analytics tools. These reports, dashboards, and analytics tools are made possible by data warehouses, which store data in a way that reduces the amount of time it is input into and exported from systems (I/O) and speeds up the delivery of query answers to large numbers of concurrent users.
Following that, business intelligence software, SQL clients, and other diagnostic tools can be used by data analysts to retrieve this data. To make daily decisions across the organization, many business departments rely on reports, dashboards, and analytics tools.
ETL (extract, transform, load) and E-LT (extract, load, transform) are the two main methods used to construct a data warehouse. Data warehousing is being moved to the cloud by businesses all over the world to boost efficiency and cut costs. Using analytics and data warehousing architecture in a contemporary way is covered in this whitepaper. It provides common design patterns to create data warehousing solutions using services offered by Amazon Web Services (AWS) and outlines services available to implement this architecture.
The most valuable asset in a company is its data. An enterprise must stimulate innovation, which stimulates growth:
- Organize all of the company's pertinent data points.
- All those who require data should have access to it.
- Possess the capacity to analyze data in a variety of ways.
- Create insights by distilling the data.
Data warehouses are a common feature of large businesses for reporting and analytics. They make use of information from numerous databases as well as their transaction processing systems.
On-premises data warehousing and traditional data warehouse designs provide several difficulties:
- They take a long time to upgrade and buy new gear, and they are tough to grow.
- Their administrative overhead expenses are rather substantial.
- Accessing, modifying, and joining data from several sources is expensive and difficult due to proprietary formats and siloed data.
- They are unable to distinguish between cold (rarely used) and warm (often used) data, which leads to increased expenditures and wasted capacity.
- They restrict the number of users and the available amount of data, which prevents data from becoming more democratic.
- They serve as a model for other legacy design patterns, such as retrofitting use cases to work with the incorrect tools rather than selecting the best tool for each use case.
How Does It Work?
The number of databases in a data warehouse is up to you. Data is arranged into tables and columns and stored in databases. A description of the data can be specified for each column, such as an integer, a data field, or a string. Schemas, which are best thought of as folder-like structures, can contain tables. Data is stored in various tables that the schema describes as it is being ingested. Which data tables to access and examine are decided by query tools using the schema.
Data Warehouse Architecture
A data warehouse architecture is a way of describing the total design of data processing, transmission, and display for end-user computing inside the company. Despite the variations across data warehouses, they always share several essential components in common.
Applications for data warehouses are made to accommodate user-specific, ad-hoc data requirements, which is now known as online analytical processing (OLAP). These include tools including trend analysis, summary reporting, profiling, forecasting, and more.
Either manually or through OLTP software, production databases are regularly updated. On the other hand, a warehouse database is regularly updated by operating systems, typically after hours. As OLTP data builds up in production databases, it is routinely removed, filtered, and placed into an accessible warehouse server. To represent the user's demands for sorting, combining, and summarising data, the warehouse must be redesigned as data is added. To do this, tables must be de-normalized, data must be cleaned of mistakes and redundancies, and new fields and keys must be created.
Tiers make form the architecture of a data warehouse. The front-end client is the highest tier; it displays outcomes using tools for reporting, analysis, and data mining. The analytics engine used to access and evaluate the data is included in the intermediate layer. Data is loaded and stored on the database server, which is the lowest layer of the system.
Data is kept in two separate forms of storage:
- fast storage, such as SSD drives, is used for often-accessed data, and
- inexpensive object stores, such as Amazon S3, are used for seldom accessed data. To improve query performance, the data warehouse will automatically ensure that frequently requested data is transferred into the "fast" storage.
Data warehouses and their architectural designs vary based on the circumstances of a business.
There are three typical Architectures:
- Basic data warehouse architecture.
- Structure of the data warehouse: Staging Area
- Staging Areas and Data Marts are included in the data warehouse architecture.
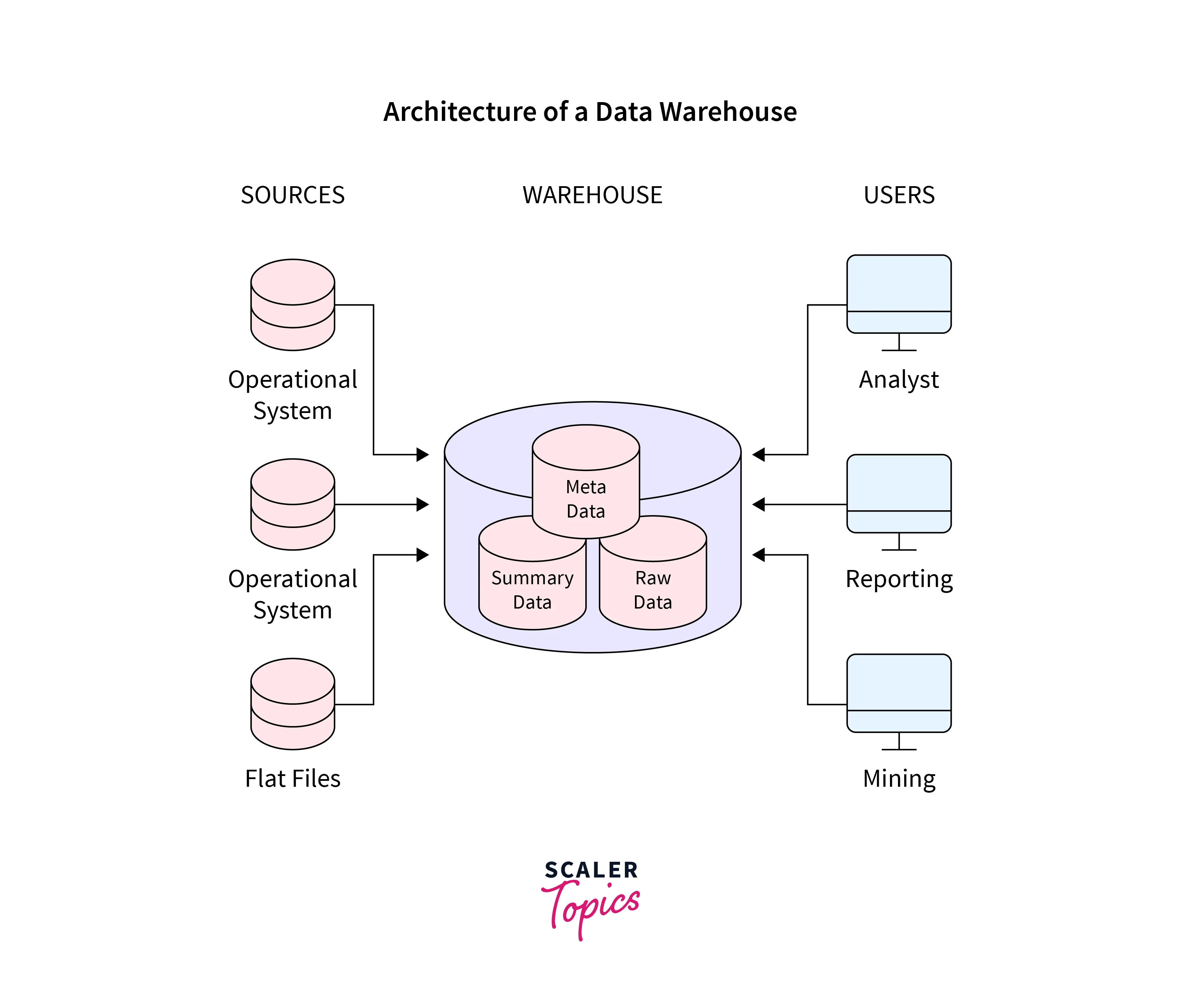
The Operational System:
A system that is used to handle an organization's regular daily transactions is referred to as an operational system in data warehousing.
Flat Files:
Each file in a flat file system must have a unique name and the system as whole stores transactional data in these files.
Metadata:
A collection of informational data that describes and describes other data.
Several uses for metadata in data warehouses include:
To make discovering and using specific instances of data more accessible, metadata condenses all relevant information about data. Simple document metadata includes things like author, date created or updated, file size, and data built or altered.
The best suitable data source is chosen for a query using metadata.
Detailed and concisely presented information:
All of the previously defined, highly summarised (aggregated), and weakly summarised data is saved in this section of the data warehouse.
To improve query performance, the material has been condensed. Each time new data is imported into the warehouse, the summary record is updated accordingly.
Tools for end-user access:
A data warehouse's main objective is to give company management information they can utilize to make strategic decisions. These customers employ end-client access tools to communicate with the warehouse.
The following are a few examples of end-user access tools:
- Query and Reporting Tools.
- Tools for developing applications.
- Information systems for executives.
- Online tools for processing analytics
- Data mining software.
Data Warehouse Architecture With Staging Area
Before putting your operational information into the warehouse, it must be cleaned and processed.
Despite data warehouses using a staging area, we can accomplish this programmatically (A place where data is processed before entering the warehouse).
A staging area simplifies data purification and consolidation for operational methods using data from many source systems. This is especially true for enterprise data warehouses, which integrate all pertinent data for a business.
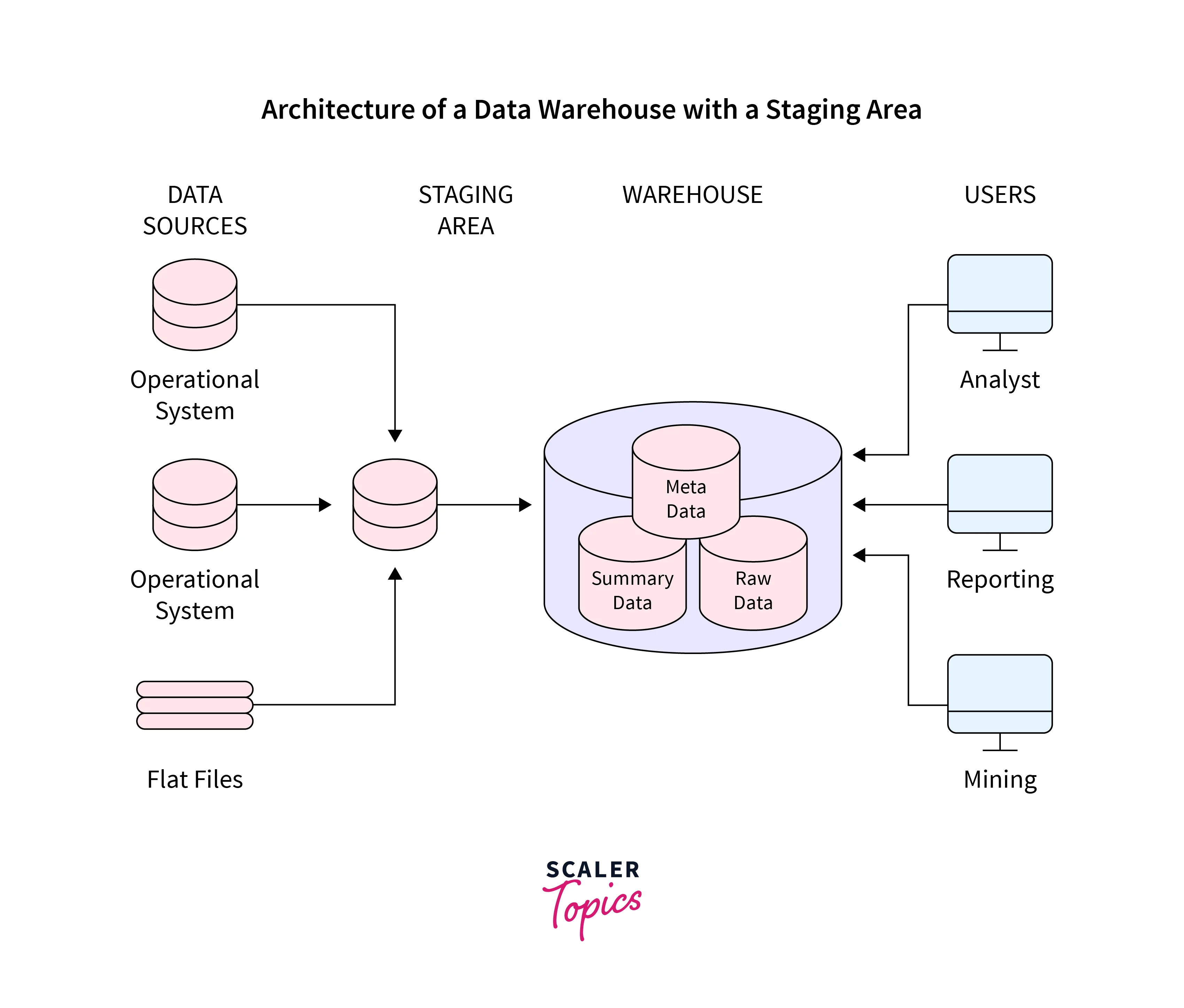
A copy of a record from source systems is placed in a data warehouse staging area for temporary usage.
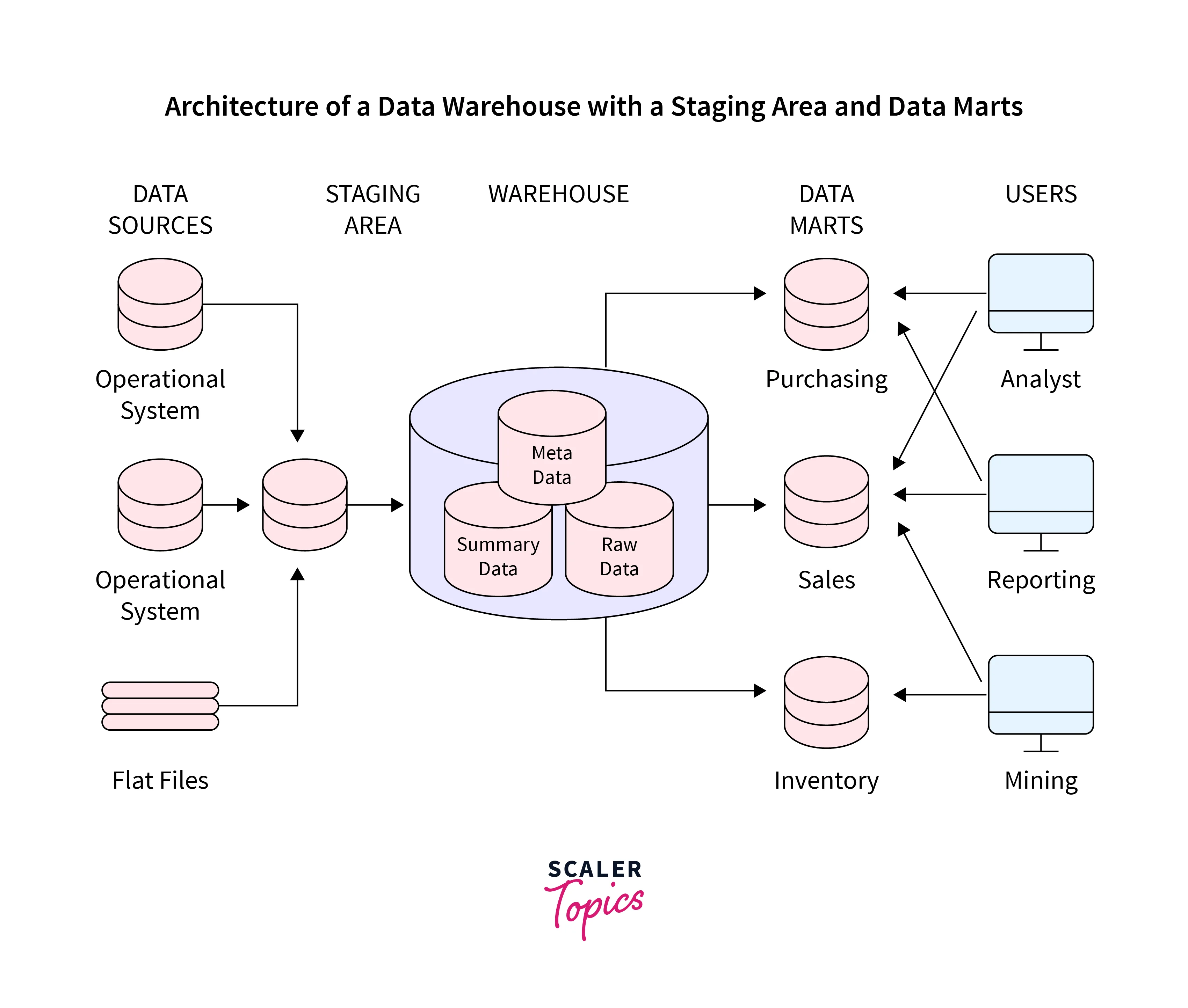
Data Warehouse Architecture With Staging Area and Data Marts
For various departments within our company, we could wish to alter the architecture of our warehouse.
Adding data marts will help us do this. A data mart is a sector of a data warehouse that can give information for reporting and analysis on a section, unit, department, or activity in the business, such as sales, payroll, production, etc.
The image shows an illustration of separating stock holding, sales, and purchases. In this hypothetical scenario, a financial analyst wishes to examine previous data on sales and purchases or mine historical data to forecast consumer behaviour.
Properties of Data Warehouse Architectures
For a data warehouse system, it is important to have the following architectural characteristics:
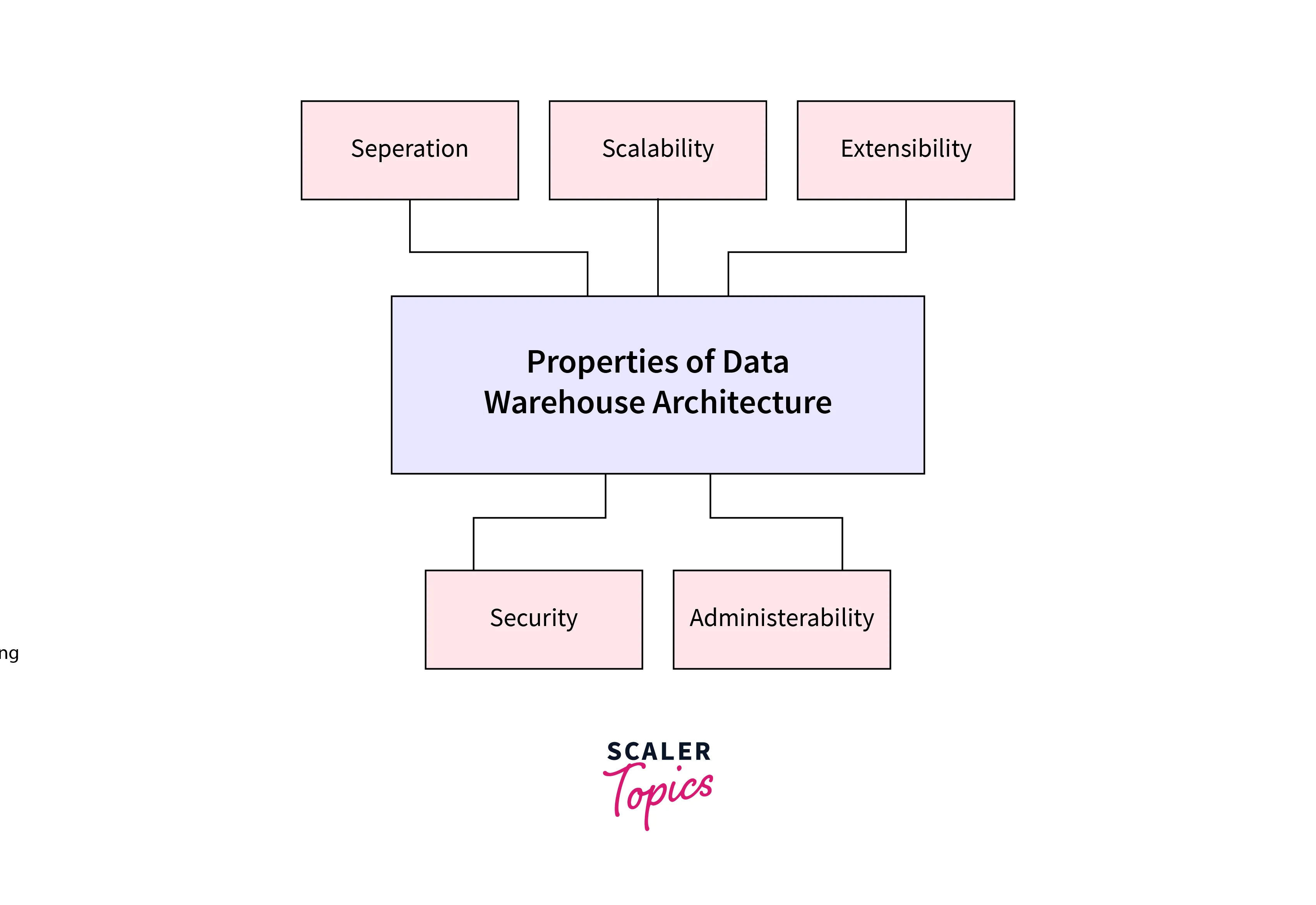
- Separation: It is best to maintain as much of a distance between analytical and transactional operations.
- Scalability: Hardware and software architectures should be easy to update as the volume of data that must be handled and processed and the number of users' needs that must be satisfied progressively rise.
- Extensibility: The architecture should be adaptable to new tasks and developments in technology without requiring a complete overhaul of the entire setup.
- Security: Given the strategic information kept in data warehouses, accesses must be monitored.
- Administration: The administration of a data warehouse shouldn't be difficult.
Types of Data Warehouse Architectures
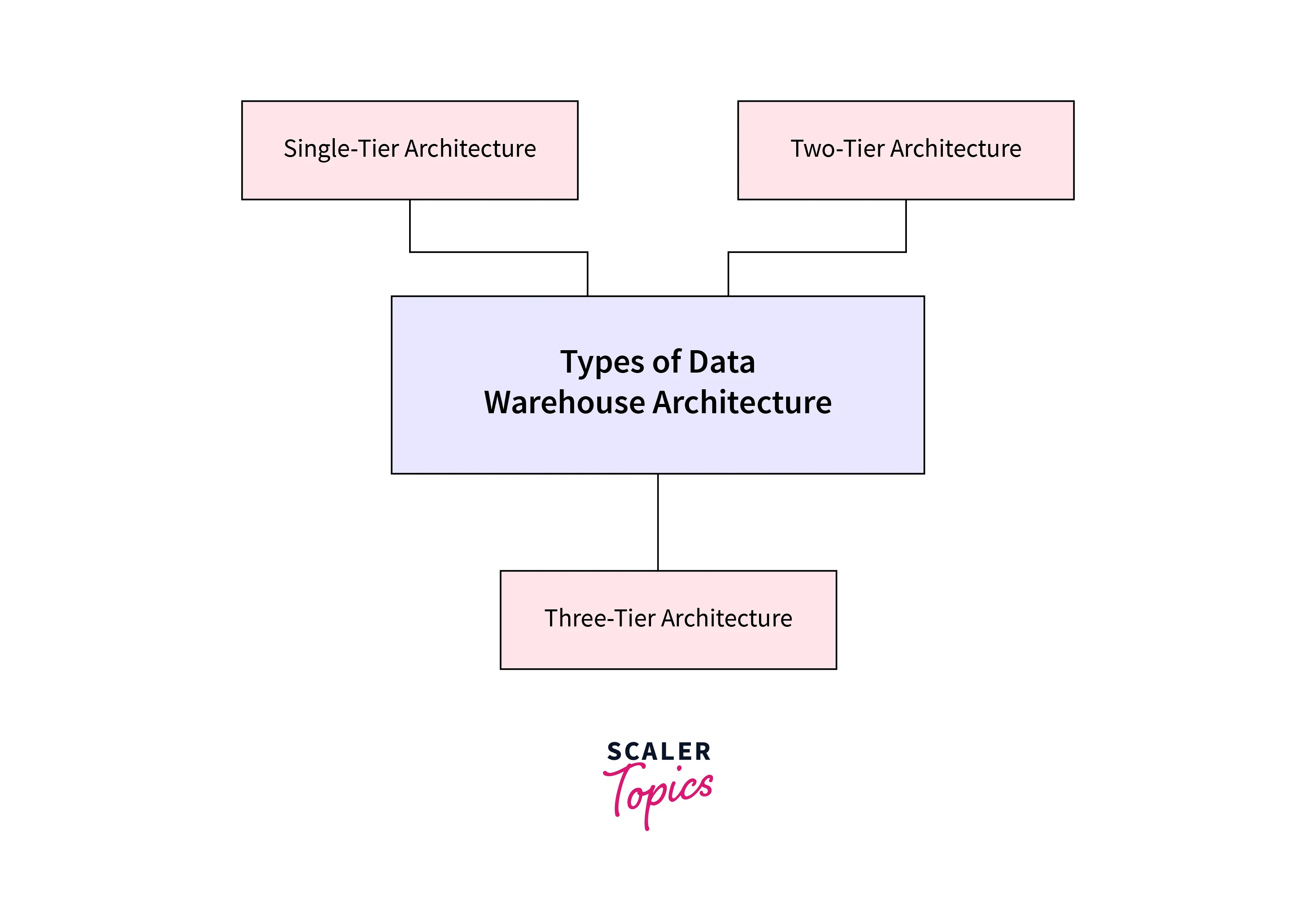
Single-Tier Architecture:
In reality, single-tier architecture is not frequently employed. To do this, it eliminates redundant data to keep as little data as possible.
The source layer is the sole layer that is accessible, as seen in the picture. Data warehouses are virtual in this approach. This indicates that the data warehouse is a multidimensional representation of operational data produced by a particular middleware, or intermediate processing layer.
Single-Tier Architecture
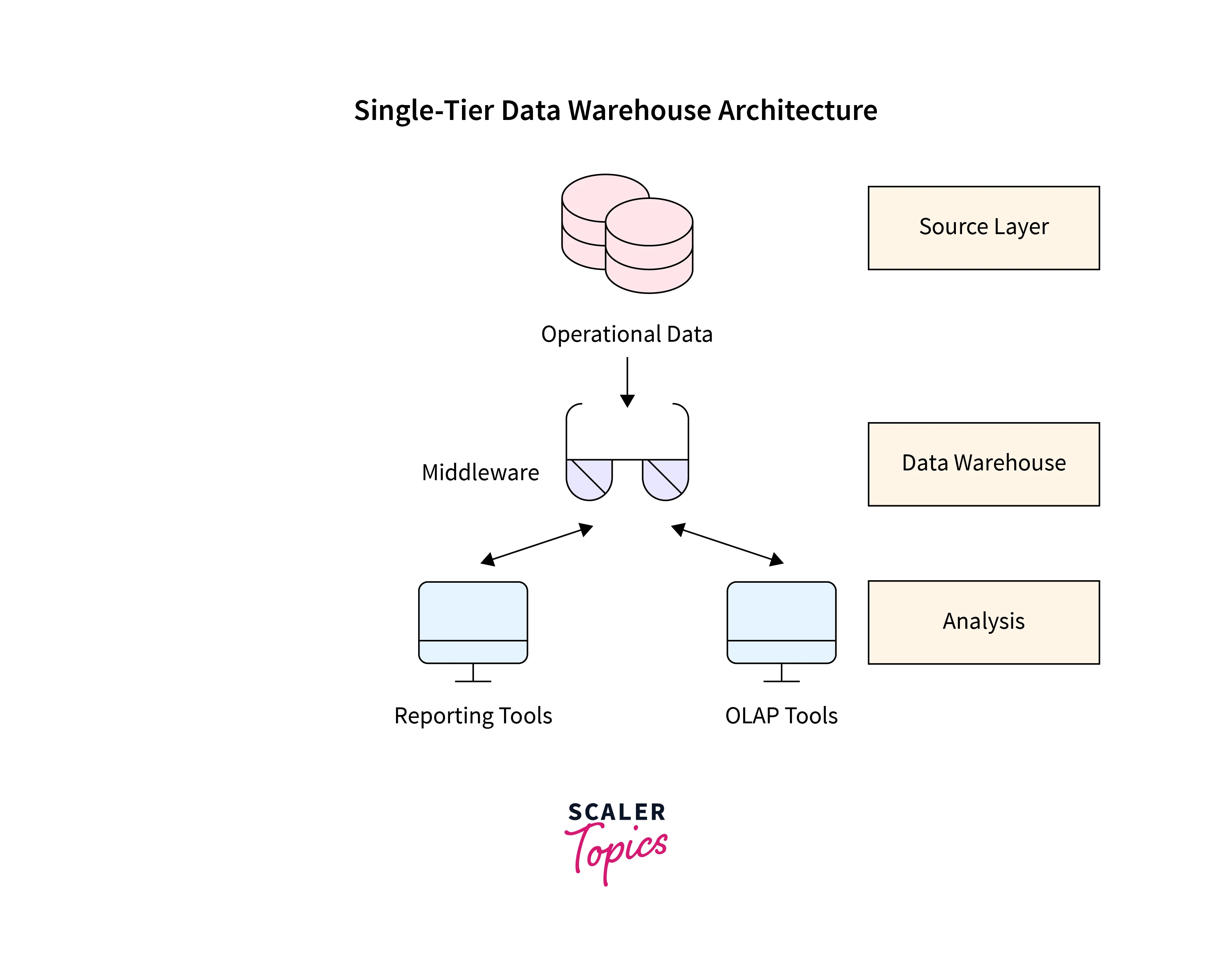
This design is vulnerable because it doesn't provide the necessary level of separation between analytical and transactional processing. After the middleware understands them, analysis queries are accepted with operational data. Transactional workloads are impacted by inquiries in this way.
Two-Tier Architecture:
As seen in Fig., the necessity for separation is crucial in developing the two-tier architecture for a data warehouse system.
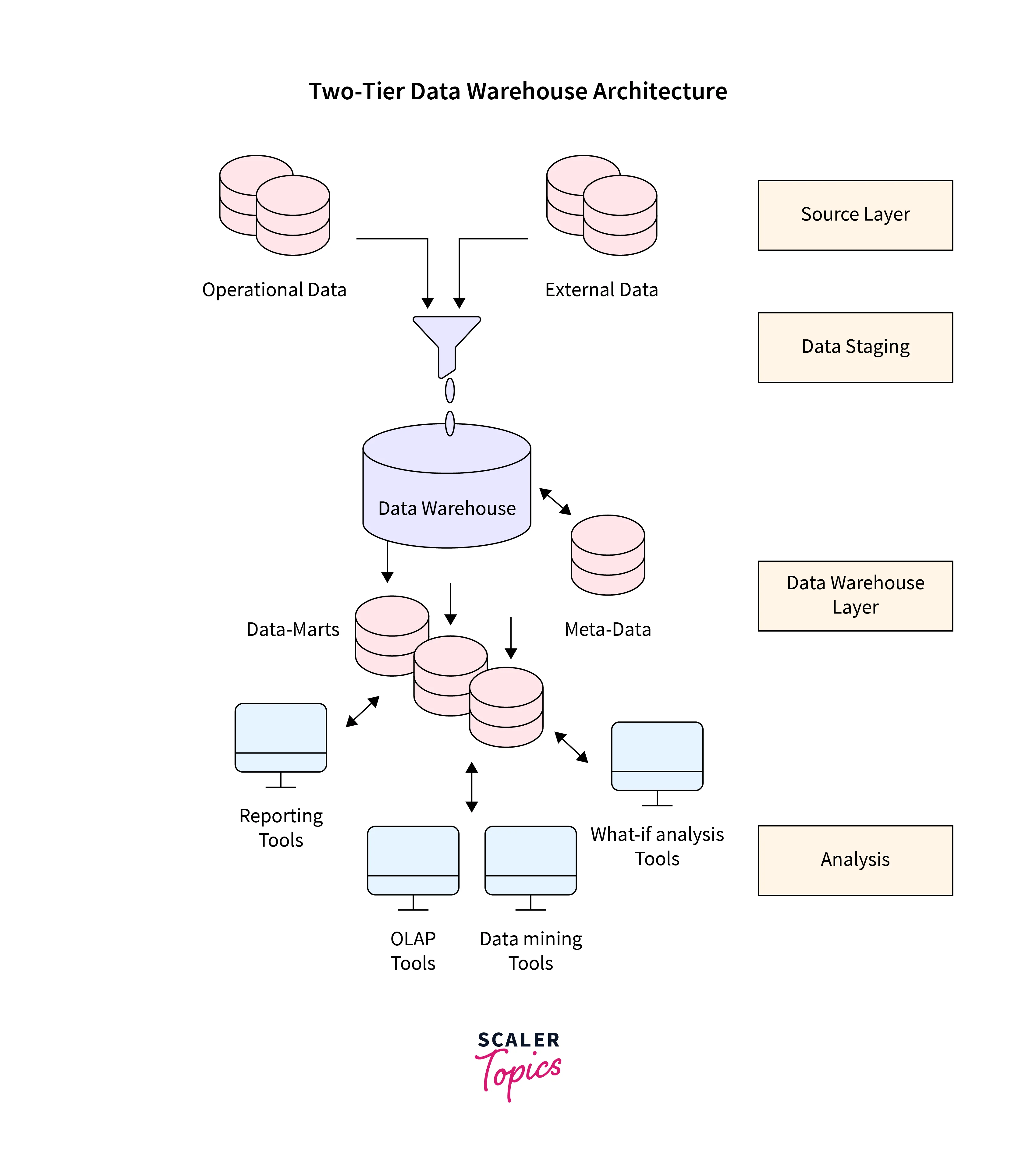
Although it is sometimes referred to as a two-layer architecture to emphasize a division between physically accessible sources and data warehouses, in reality, it consists of four consecutive stages of data flow:
- Source Layer: A data warehouse system draws its information from a variety of sources. That information may originate from an information system outside the boundaries of the company, or it may be first housed in corporate relational databases or historical databases.
- Data Staging: The data that has been saved in the source should be retrieved, and cleaned to eliminate discrepancies and fill in any gaps, then integrated to combine data from many sources into a single standard schema. Extraction, Transformation, and Loading Tools (ETL) may extract, convert, clean, verify, filter, and load source data from heterogeneous schemata into a data warehouse.
- Layer of the Data Warehouse: A data warehouse is used as a logically centralized, single repository for information. The data warehouses can be directly accessed, but they can also serve as a source for data marts, which are intended for certain corporate departments and partially reproduce the contents of data warehouses. Source, access, data staging, user, data mart schema, and other information are stored in meta-data repositories.
- Analysis: This layer allows for rapid and flexible access to integrated data so that reports can be generated, data can be dynamically analyzed, and fictitious business scenarios can be simulated. A user-friendly GUI, complicated query optimizers and aggregate information navigators should all be included.
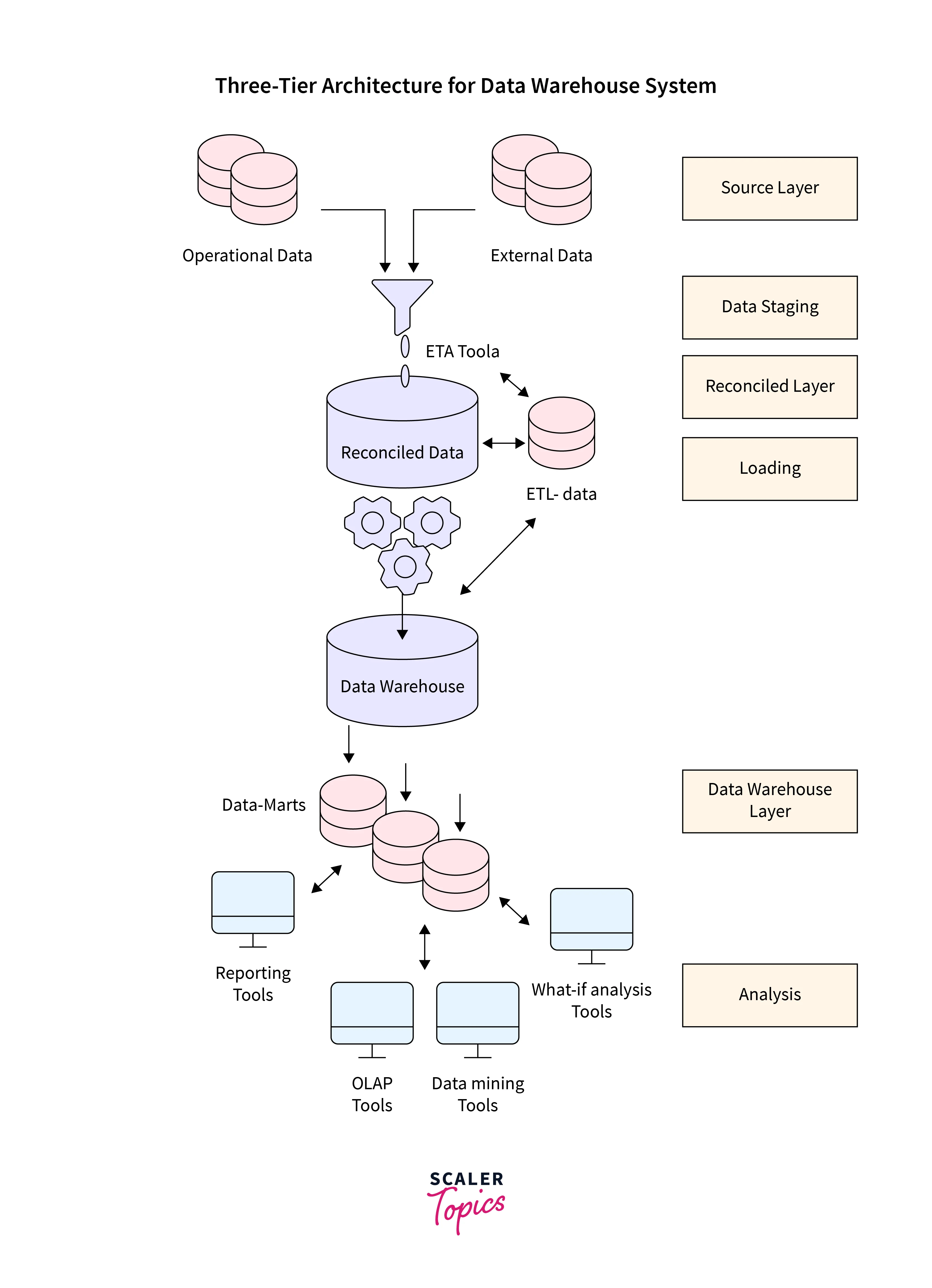
Three-Tier Architecture
The data warehouse layer, the reconciliation layer, and the numerous source systems-containing source layer make up the three-tier architecture (containing both data warehouses and data marts). The source data and data warehouse are separated by the reconciliation layer.
A standard reference data model is produced for a whole business, which is the reconciled layer's key benefit. It also distinguishes between issues relating to the data warehouse populating and those relating to the extraction and integration of source data. In some circumstances, the reconciled layer is also used directly to improve the performance of some operational tasks, such as generating daily reports that cannot be adequately prepared uThree-Tier Architectures corporate applications or generating data flows to feed external processes regularly to gain the benefits of cleaning and integration.
Benefits of Data Warehouse
Here are Some Advantages of a Data Warehouse:
- Well-informed Decisions.
- Gathered information from a variety of sources.
- Examination of historical data.
- Consistency, correctness, and quality of the data.
- the performance of both systems is improved by separating the analytics processing from transactional databases.
- Managers and executives no longer have to base company choices on limited information or gut feeling thanks to the availability of data from many sources. Insights for marketing, finance, operations, and sales may also be fueled by data warehouses and the BI they connect to.
- Users can run their data queries without much help from IT, which will save them more time and money. Business users won't have to wait for IT to produce the reports as a result, and diligent IT analysts can concentrate on keeping the company operating.
- Each department will give findings that are consistent with those of the other departments since data from different departments is standardised. You may be more confident in the accuracy of your data if it has data virtualization capabilities. And solid business judgments are based on precise facts.
- To study various periods and patterns and create forecasts for the future, a data warehouse stores a lot of historical data. Such information normally cannot be utilised to create reports from a transactional system or kept in a transactional database.
- Businesses that have implemented data warehouses and complementary BI systems have increased revenue and reduced costs more than businesses that haven't.
How Do Data Warehouses, Databases, and Data Lakes Work Together?
To store and analyze data, firms typically employ a database in conjunction with a data lake and a data warehouse. It is simple to integrate because of Amazon Redshift's lake house architecture.
When working with data throughout your database, data lake, and data warehouse, it's beneficial to adhere to one or more standard patterns as the volume and diversity of data grow.
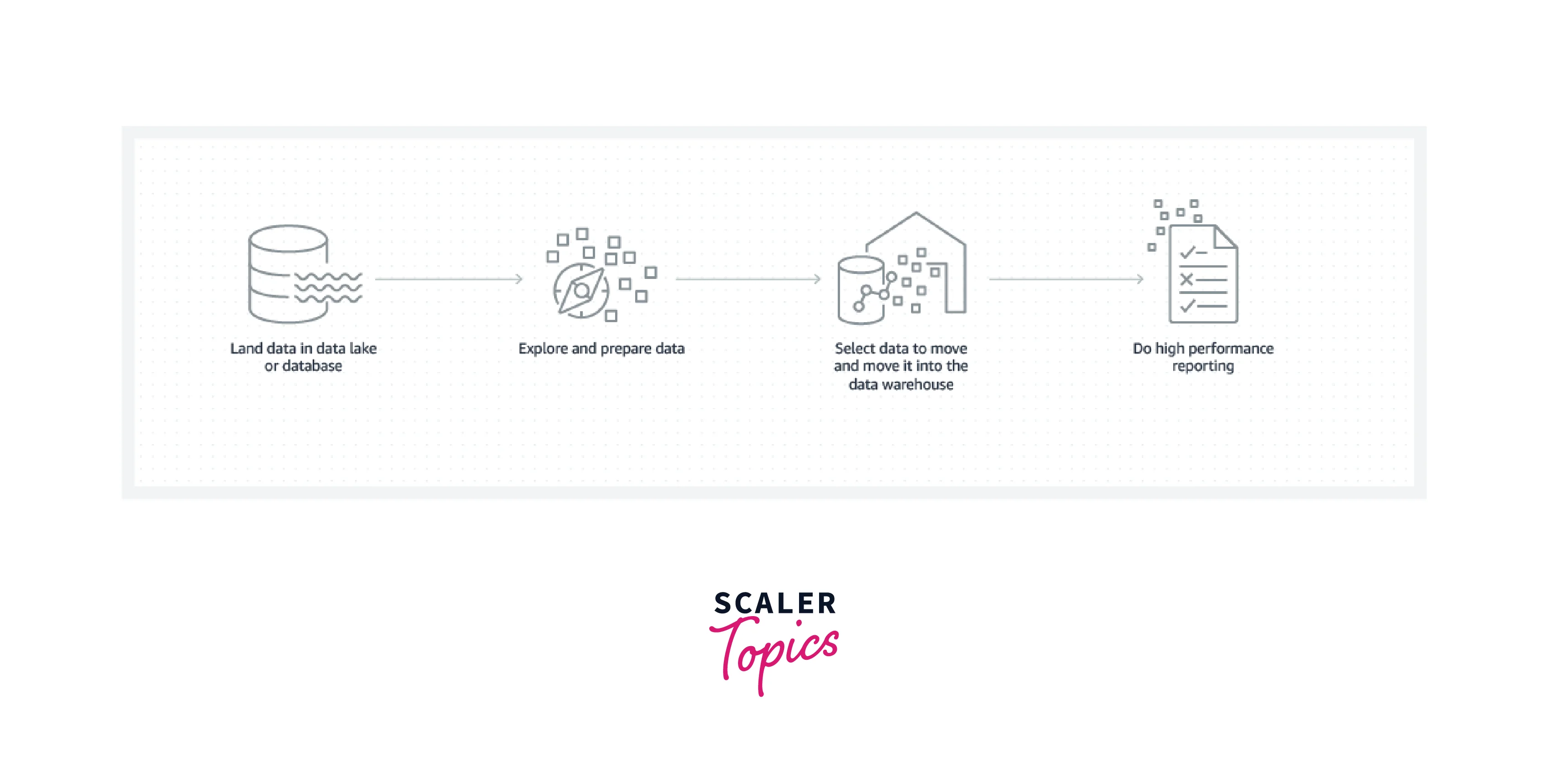
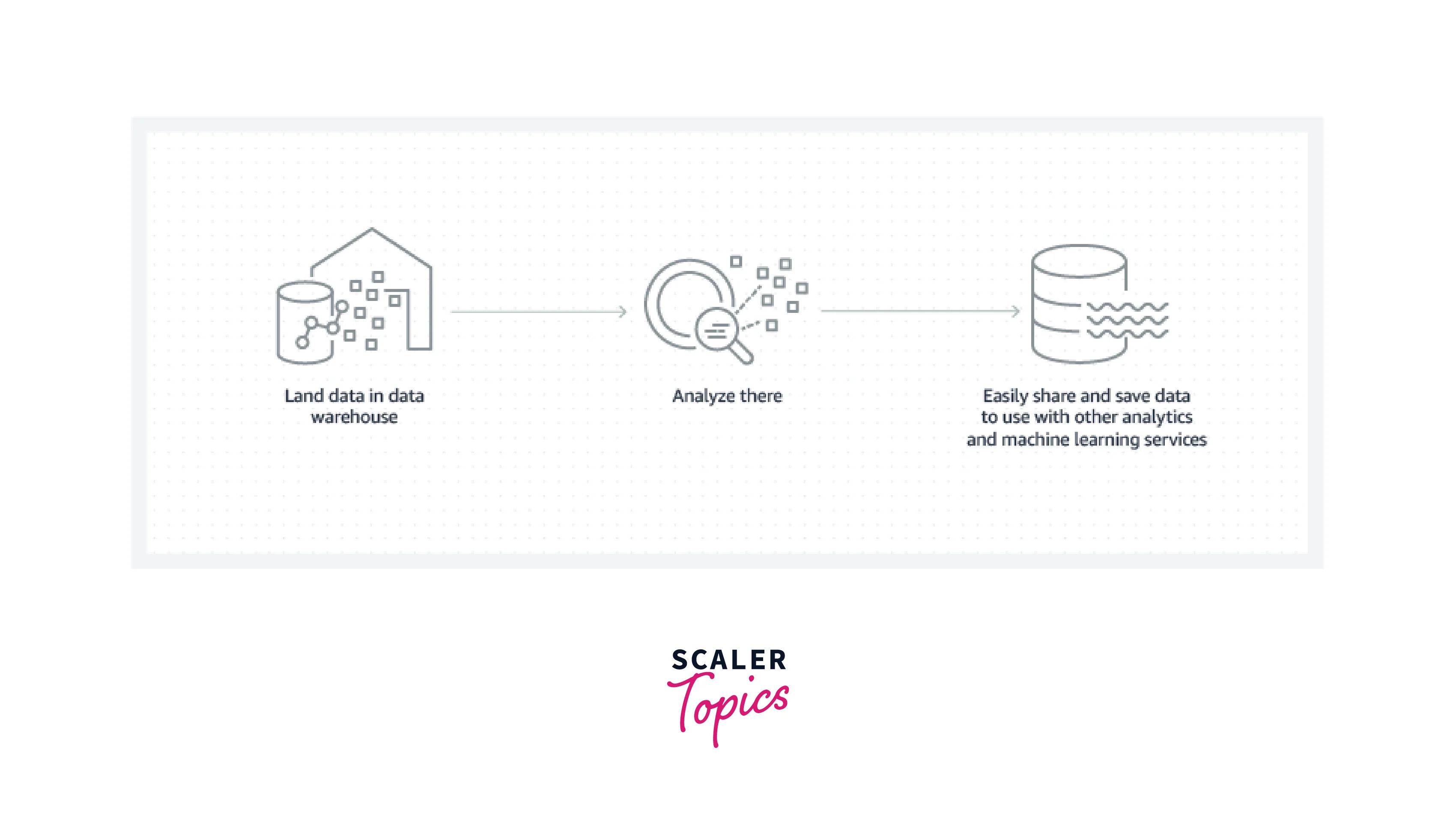
Data analytics, which involves reading vast amounts of data to comprehend relationships and trends across the data, is a speciality of a data warehouse. When recording transactional details or other data, a database is used to collect and store the information.
A data lake, in contrast to a data warehouse, is a single location that houses all data, whether it is structured, semi-structured, or unstructured. The schema is used when a data warehouse is used, which necessitates the organization of the data in a tabular manner. SQL needs to be able to query the data, hence the tabular format is required. The format of the data does not, however, have to be tabular for all applications. Data may be accessed by some applications even if it is "semi-structured" or entirely unstructured, such as big data analytics, full-text search, and machine learning.
By scaling your system in parallel with the increasing quantity of data that is gathered, saved, and queried, accessing virtually endless storage and computation power, and only paying for the resources you use, AWS enables you to benefit from all of the key advantages of on-demand computing. To swiftly build an end-to-end analytics and data warehousing solution, AWS offers a wide range of managed services that easily interface with one another.
Data Lake vs Data Warehouse
| Data Warehouse | Data Lake |
|---|---|
| Relational information derived from operational databases, transactional systems, and line-of-business applications | Including structured, semi-structured, and unstructured data |
| However, they may also be written during the analysis process. Frequently developed before the data warehouse implementation | as of the analysis, written (schema-on-read) |
| employing local storage, the fastest query results. | Utilizing inexpensive storage and isolating computing from storage, query responses become more rapid. |
| Highly edited material that acts as the main version of reality. | Anything that might or might not be curated (i.e. raw data). |
| data developers, business analysts, and data scientists. | Data scientists, developers, engineers, and architects, together with business analysts who use curated data. |
| Analytics, batch reporting, and visualizations. | Big data, profiling, operational analytics, streaming, exploratory analytics, data discovery, and machine learning. |
Data Warehouse vs Database
| Data Warehouse | Transactional Database |
|---|---|
| Big data, reporting, and analytics. | Handling transactions. |
| Data gathered and standardized from a variety of sources. | SData gathered in its current state from a single source, such as a transactional system. |
| Bulk write operations are performed according to a pre-set batch schedule. | Designed to increase transaction performance by being optimized for continual write operations as new data becomes available. |
| Denormalized models, such as the Snowflake or Star models. | Extremely static, standardized schemas. |
| The use of columnar storage has been optimized for ease of access and quick query processing. | High-performance row-oriented physical block writes are prioritized throughout. |
| Streamlined to reduce I/O and increase data performance. | Large numbers of quick read operations. |
Data Mart vs Data Warehouse
| Data Warehouse | Data Mart |
|---|---|
| Centralised, with many different subjects combined. | Decentralized, narrow subject matter. |
| Organization-wide. | Only one neighbourhood or division. |
| several sources | One or more sources, or a subset of data that has already been gathered and stored in a data warehouse. |
| Large can range from a hundred gigabytes to a petabyte. | Small, usually between 10 and 100 gigabytes. |
| Top-down | Bottom-up |
| Complete, in-depth information | Might contain a data summary |
Data Warehouse on AWS
By scaling your system in parallel with the increasing quantity of data that is gathered, saved, and queried, accessing virtually endless storage and computation power, and only paying for the resources you use, AWS enables you to benefit from all of the key advantages of on-demand computing. To swiftly build an end-to-end analytics and data warehousing solution, AWS offers a wide range of managed services that easily interface with one another.
An end-to-end analytics process, also known as a stack, is illustrated below along with its major phases. Throughout each stage, AWS provides a range of managed services.
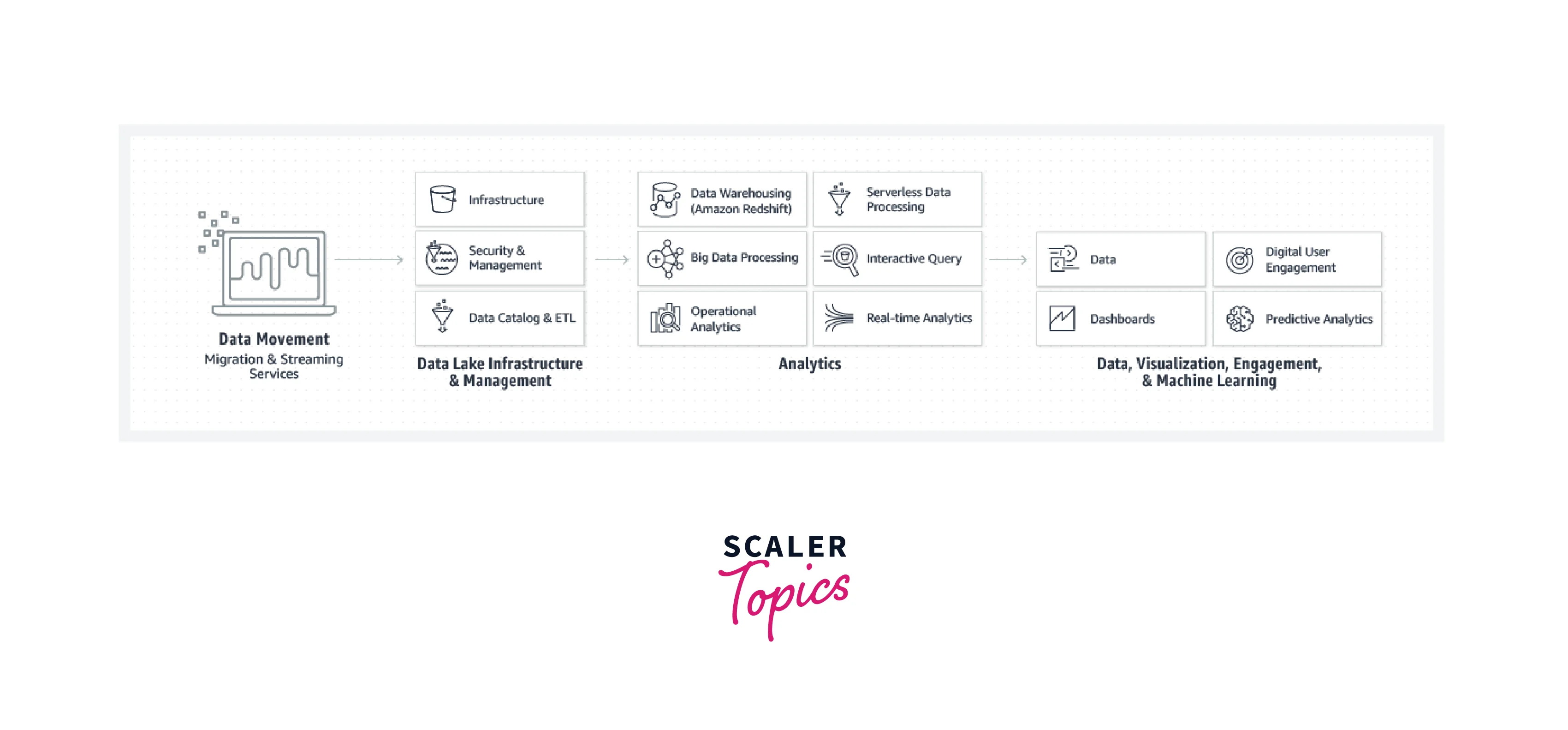
Our cost-effective, quick, and fully managed data warehouse solution is called Amazon Redshift. With this service, you can combine exabyte-scale data lake analytics with petabyte-scale data warehousing, and you only pay for what you need.
Organizations like yours have the chance to use more potent analytics than ever before in the age of big data, where humans produce 2.5 quintillion bytes of data every single day. It is still difficult to collect, arrange, and sort data, though. Simply put, the context is lacking and there is too much information. The most widely used commercial data warehouse solutions, like Amazon Redshift, assert that they provide structured, useful data for businesses.
According to AWS Redshift, its price-performance ratio is "up to 3 times better than any other data warehouse," making it the fastest cloud data warehouse on the planet. The size and scope of your business will determine these outcomes, though, and other approaches might be much more successful.
Amazon Redshift Data Warehouse Overview
Comparing Amazon Redshift to conventional data warehouses, it performs differently. When organizing and sorting data, several searches may be required on other systems, like Snowflake, which store data in rows. Redshift is a column-oriented database management system, stores data in columns, and facilitates faster data analysis. In comparison to rival products like Snowflake, Amazon Redshift claims to be 2 times faster.
Before moving the data to the data warehouse, AWS Redshift enables you to store the data in a data lake. (A data warehouse has organized data; a data lake contains raw, unsorted data.) The ability to combine data with a data lake, according to one customer of Amazon Redshift, has allowed them to "integrate new data sources within hours instead of days or weeks." Another user claims the platform is "easy to understand," "simple to use," and processes data "quickly" in a post on the software review website G2.com. (As of right now, G2's average user rating for AWS Redshift is 4.2/5.)
Benefits of AWS Redshift Data Warehouse
Users may get rapid speeds using AWS Redshift. However, it also earns praise from consumers for its excellent value for money, giving businesses access to a quick and potent data warehouse for a very low price. Compared to Snowflake's $2.01 per hour rate, prices start at $0.25.
There are further advantages. Additional nodes may be added to AWS Redshift to expand its capacity for handling huge data sets, enabling you to examine data without slowing down query response times. Additionally, Amazon Redshift includes security measures like the following to safeguard sensitive data:
- SSL data transmission encryption.
- Both client-side and server-side data encryption
- Access restriction at the column level.
- Access control.
- Login information.
Amazon Redshift vs Traditional Data Warehouses
The purpose of traditional data warehousing approaches is to provide programmed capabilities like:
- Roll-up: Information is made generic by being summed up.
- Pivot: Cross tabulation is done by rotating the data.
- Slice and Dice: Working with the dimensions to perform projection operations
- Drill-down: Providing more information
- Selection: Data is accessible by value and range.
- Sorting: By ordinal value, the data is sorted.
Data warehousing has the following main advantages:
- A repository of data used for comparative and competitive analyses.
- Improved completeness thanks to high-quality information.
- With any other data backup source, disaster recovery strategies.
Amazing Redshift makes use of columnar storage to boost I/O effectiveness, parallelize queries across multiple nodes, and deliver quick query performance. Additionally, the service provides unique ODBC and JDBC drivers, which developers can easily download from the Connect Client tab of the Console. You can use a variety of well-known SQL clients thanks to it.
Even though Amazon Redshift is impressive, several other data warehouse products compete with it on the market, including the following ones (among others):
- Analytics in Azure Synapse (formerly known as - - Microsoft Azure SQL Data Warehouse)
- Snowflake
- Business Warehouse SAP
- BigQuery on Google
The aforementioned data warehousing technologies have been contrasted on features, capabilities, cost, and other aspects by both common users and professional analysts.
Conclusion
- A data warehouse is a central collection of data that can be examined to help decision-makers become more knowledgeable.
- Transactional systems, relational databases, and other sources all regularly and continuously feed data into a data warehouse.
- A data lake is a collection of large amounts of unprocessed, unaltered big data from various sources, typically in the form of files or object blobs.
- The speed of AWS Redshift's cloud data warehouse is touted as being unmatched, and it boasts "up to 3 times better price-performance than any other data warehouse."
- Applications for data warehouses are made to accommodate user-specific, ad-hoc data requirements, which is now known as online analytical processing (OLAP).
- All of this results in faster data analytics and the elimination of sluggish Redshift database queries. Once you have extracted, converted, and loaded data into AWS Redshift, you can connect Redshift to business intelligence programs like Looker and Tableau to access unmatched data algorithms and immediate insights that will aid in your decision-making.
- Any modern company's competitive strategy revolves around effectively and efficiently mining data and a data warehouse is a key element of this data mining.