AWS Data Wrangler
Overview
With Amazon Data Wrangler, the process of collecting and preparing data for machine learning (ML) may be completed in a matter of minutes rather than weeks.
With Amazon Data Wrangler, you can speed up the feature engineering and data preparation processes and complete each step of the workflow for data preparation, such as data selection, purification, exploration, and visualization, from a single visual interface. Using the data selection tool in SageMaker Data Wrangler, you can quickly import any needed data from a range of data sources.
Introduction to AWS Data Wrangler
Enterprise organizations are using cloud services to create automated Extract Transform Load (ETL) pipelines, data lakes, and warehouses. Because of Amazon S3's resilience, availability, scalability, and affordability, data lakes on the AWS Cloud are constructed on top of it. One of the tools for requesting data from S3 is Amazon Athena. Amazon Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Athena is easy to use. The first Python library that springs to mind for programmatic interaction with AWS services is Boto3.
Boto3 is the Amazon Web Services (AWS) Software Development Kit (SDK) for Python, which allows Python developers to write software that makes use of services like Amazon S3 and Amazon EC2. However, utilizing the Boto3 package alone has yet to make it simpler to programmatically query the S3 data using Athena into Pandas data frames for ETL.
Amazon SageMaker is a managed service in the AWS public cloud. It provides the tools to build, train and deploy machine learning models for predictive analytics applications. Amazon Data Wrangler, a feature of Amazon SageMaker Studio, offers a complete solution for importing, preparing, transforming, formatting, and analyzing data. To simplify and streamline data pre-processing and feature engineering with little to no code, you may integrate a Data Wrangler data preparation flow into your machine learning operations. Workflows can be modified by adding your Python scripts and transforming them.
Once your data is ready, you can use Amazon SageMaker Pipelines to create fully automated machine-learning workflows and store them for later usage in the Amazon SageMaker Feature Store.
How Does It Work?
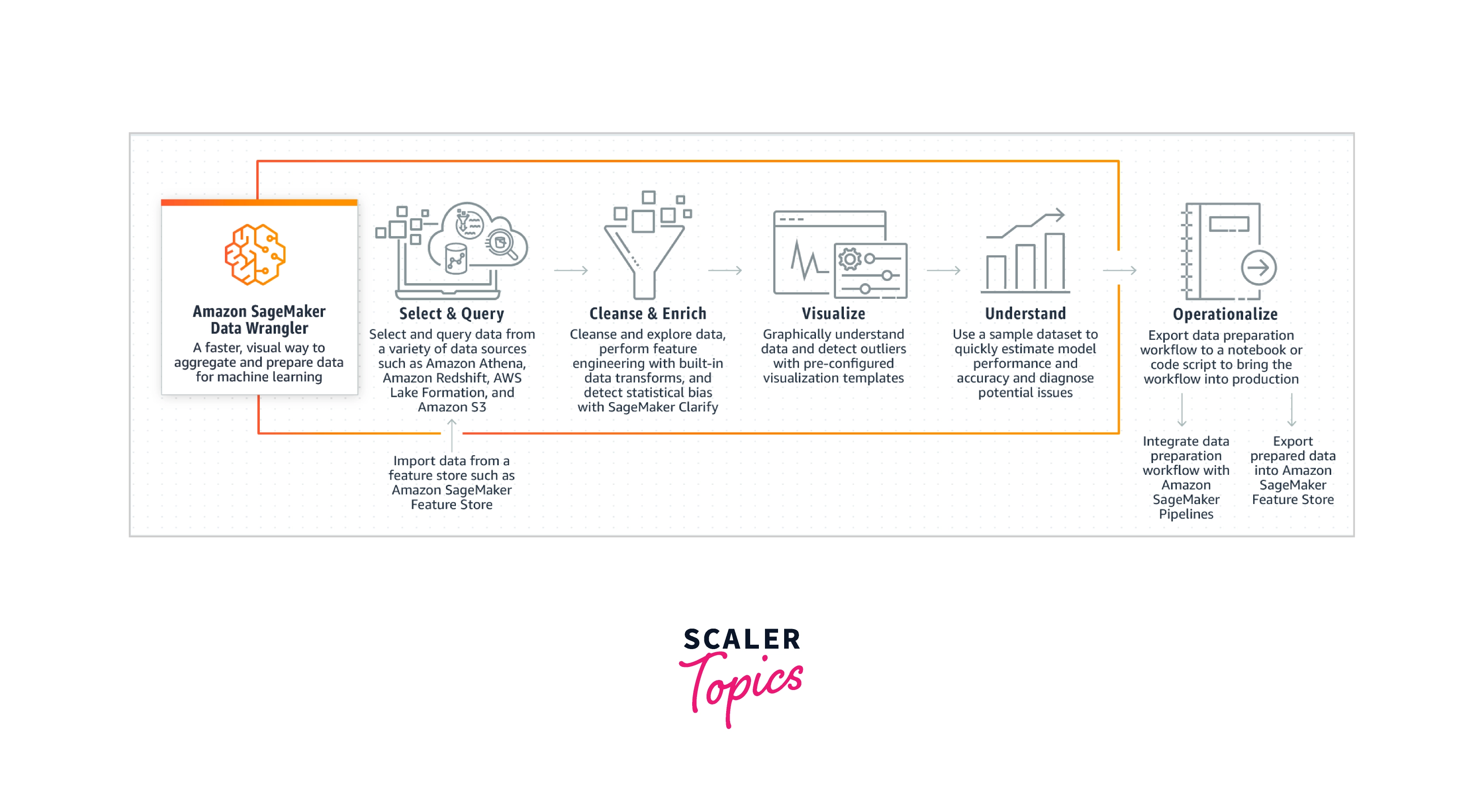
With Only a Few Clicks, Select and Query Data
You may easily choose data from a variety of data sources, including Amazon S3, Amazon Athena, Amazon Redshift, AWS Lake Formation, Snowflake, and Databricks Delta Lake, using the data selection tool in SageMaker Data Wrangler. Additionally, SageMaker allows you to directly import data from a variety of file types, including CSV files, Parquet files, ORC and JSON files, and database tables, as well as perform searches for data sources.
Visualize your Data to Better Understand it
With a selection of pre-configured solid visualization templates, SageMaker Data Wrangler aids in helping you comprehend your data and spot potential problems and extreme values. It is possible to use histograms, scatter plots, box and whisker plots, line plots, and bar charts. Without writing any code, you can easily design and change your visualizations using templates like the histogram.
Create Data Insights and a Data Quality Understanding
A quality and insights report is offered by SageMaker Data Wrangler, which automatically verifies data quality and aids in the identification of anomalies in your data. Once you have successfully verified the accuracy of the data, you can handle datasets for ML model training very rapidly by using your domain knowledge.
Prepare Data for ML
You may quickly and efficiently export your data preparation workflow to a SageMaker Data Wrangler processing job, SageMaker Autopilot training experiment, or processing job. SageMaker Data Wrangler provides a smooth experience for data preparation and ML model training in SageMaker Autopilot. With just a few clicks, you can immediately make, train, and improve ML models.
SageMaker Data Wrangler integrates your data preparation workflow with Amazon SageMaker Pipelines to automate model deployment and management. Additionally, SageMaker Data Wrangler releases features in the Amazon SageMaker Feature Store so you can share them with your team and repurpose them for use in other people's models and analyses.
Quickly Estimate ML Model Accuracy
- Built-in analyses in Amazon SageMaker Data Wrangler enable you to quickly create visualizations and data analysis. You can also write your code to create customized analyses.
- By choosing a phase in your data flow, then selecting Add analysis, you can add an analysis to a dataframe. Select the phase that contains the analysis, then select the analysis, to access a created analysis.
- 100,000 rows from your dataset are used to create all analyses.
The following analysis can be added to a dataframe:
- Data visualizations, such as scatter plots and histograms.
- Your dataset's fast summary includes the number of entries, the minimum, and maximum values (for numerical data), and the most and least common categories (for categorical data).
- A fast dataset model may be used to determine the relevance of each feature.
- A target leakage report can be used to assess whether one or more features have a high degree of correlation with your target feature.
- A personalized graphic made with your code.
Getting Started with AWS Data Wrangler
Pre-requisites
You need to finish the following requirements before using Data Wrangler.
-
You require access to an Amazon Elastic Compute Cloud (Amazon EC2) instance to use Data Wrangler.
-
Set up the necessary permissions as outlined in Security and Permissions.
You must have an active Studio instance to use Data Wrangler. See Onboard to Amazon SageMaker Domain for information on how to start a new instance. Use the steps in Access Data Wrangler once your Studio instance is ready.
Access Data Wrangler
Using Data Wrangler in SageMaker Studio, you can:
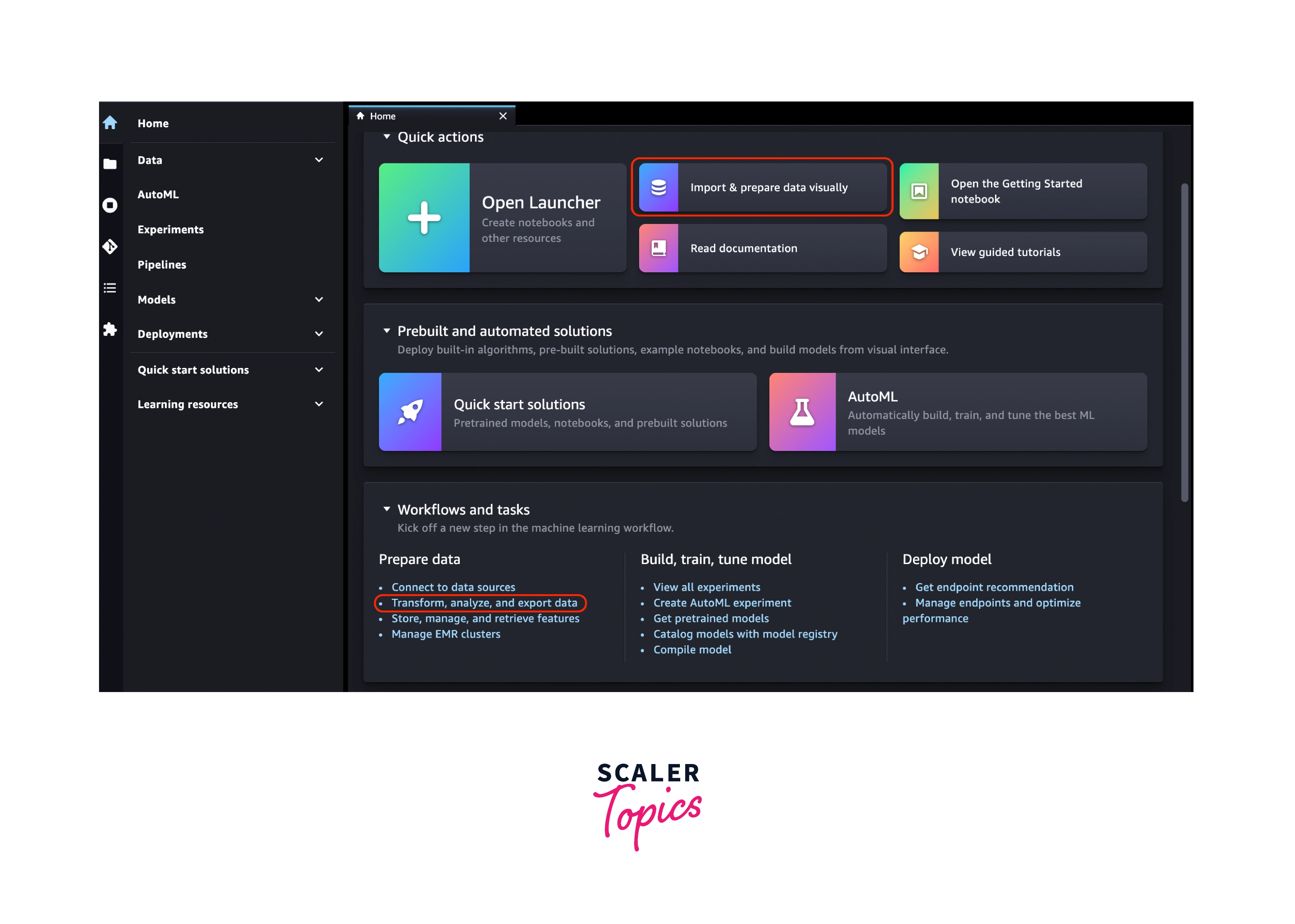
Select Open Studio next to the user you wish to use to open Studio.
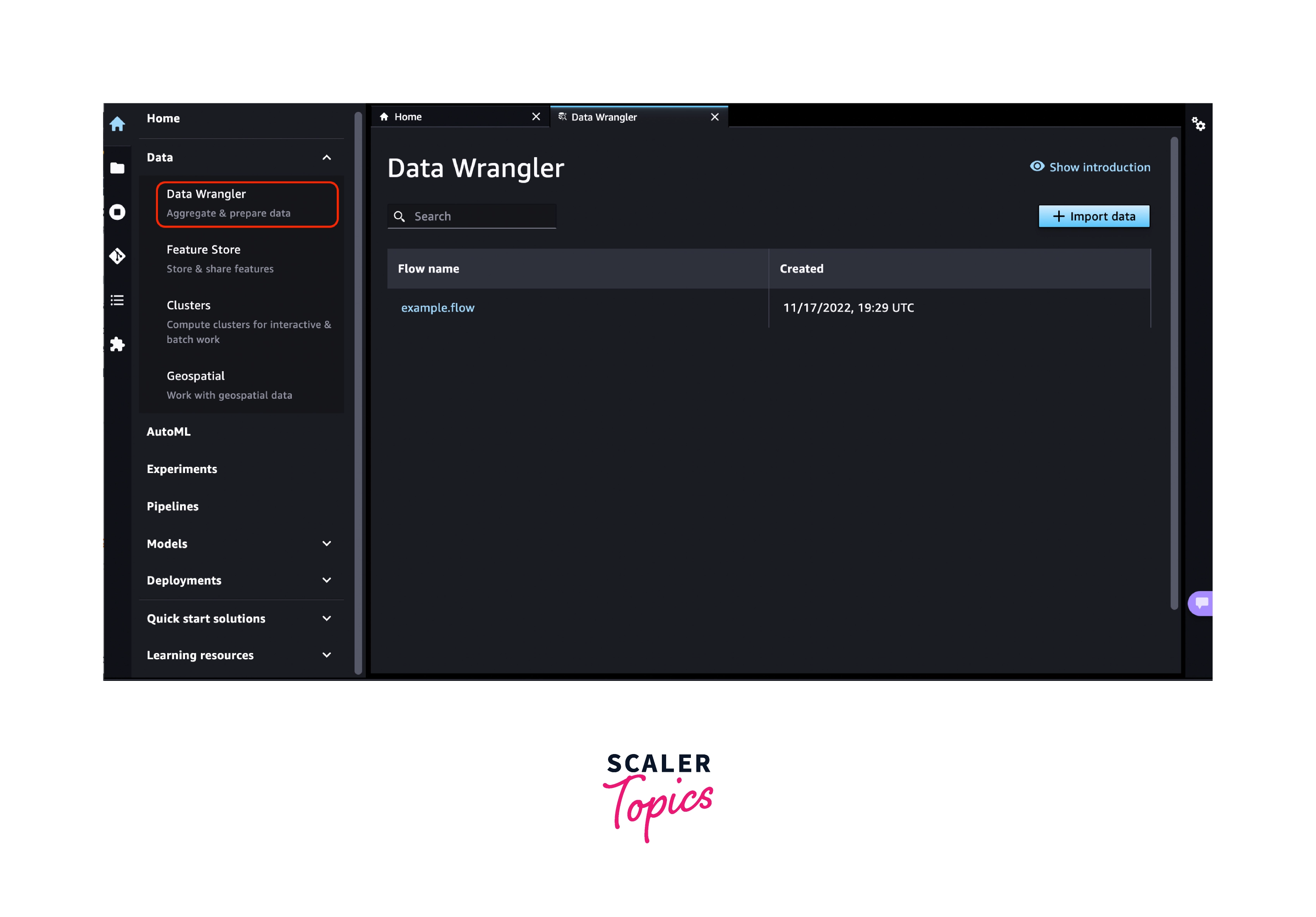
Select the + symbol on the New data flow card under ML tasks and components when Studio starts. This generates a new directory in Studio with your data flow's .flow file inside. The .flow file opens in Studio by default.
A new flow can also be started by choosing File -> New, and then Data Wrangler Flow from the top navigation bar.
In Studio, you could see a carousel that introduces you to Data Wrangler when you create a new .flow file. This could take a while.
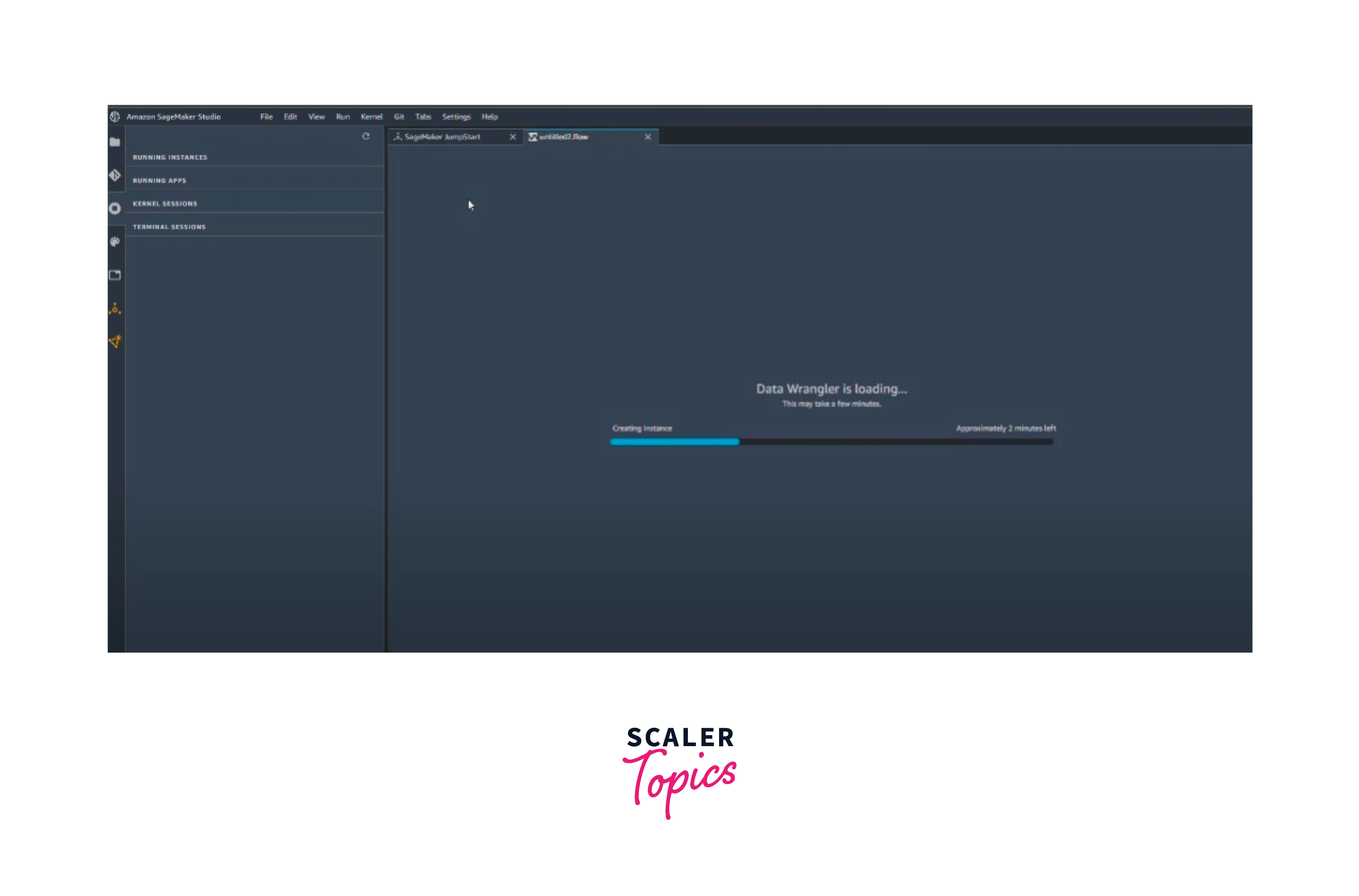
This message is visible as long as the KernelGateway app is listed as Pending on your User Details page. Select the name of the user you are using to access Studio in the SageMaker console on the Amazon SageMaker Studio page to view the status of this app. A KernelGateway app can be found in the Apps section of the User Details page. Wait until the Data Wrangler app state is Ready, before using it. The first time you run Data Wrangler, this could take up to five minutes.
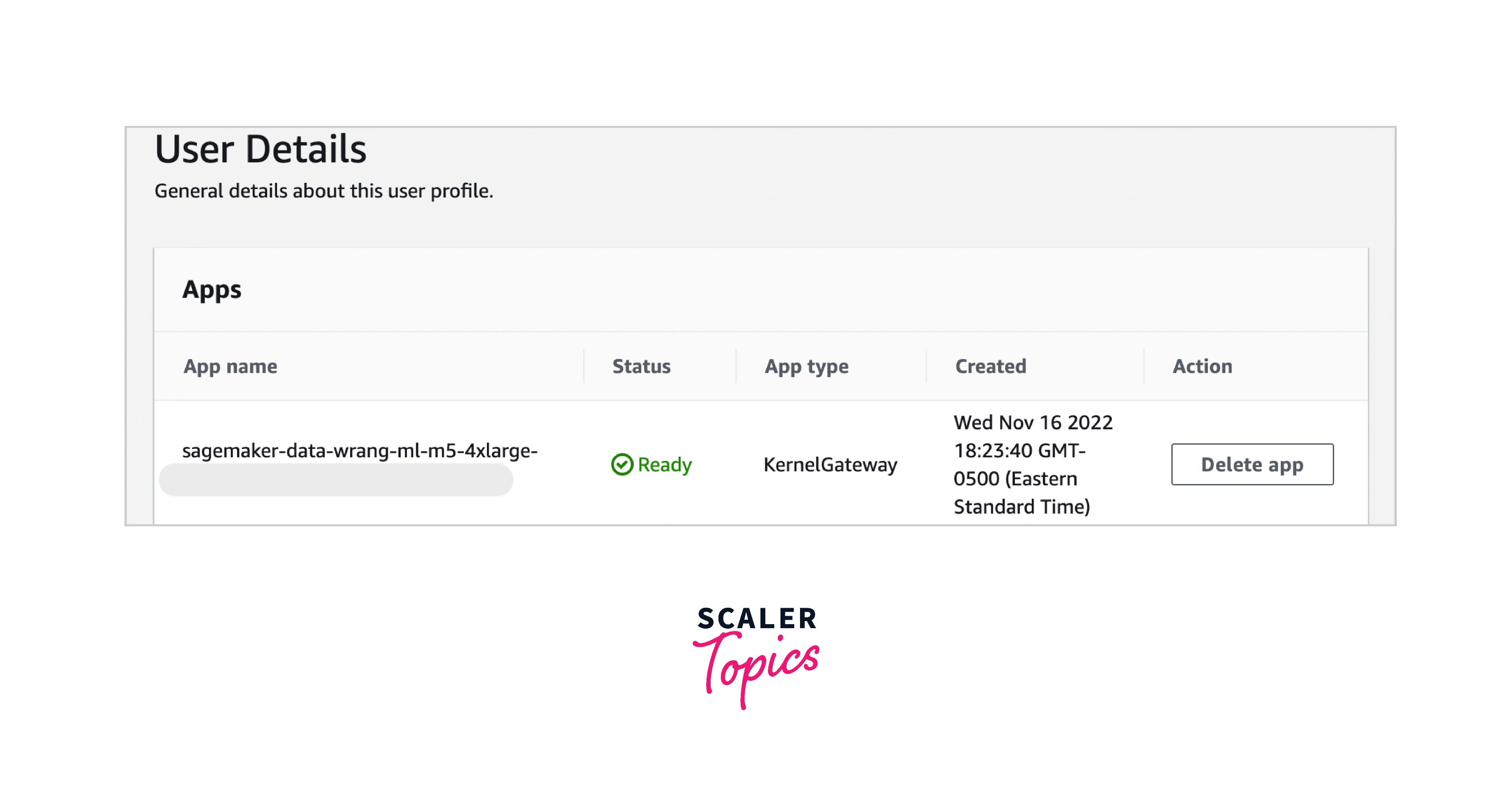
-
Select a data source, then use it to import a dataset to get going. A dataset that has been imported shows up in your data flow. When you import a dataset, it appears in your data flow.
-
After you import a dataset, Data Wrangler automatically infers the type of data in each column. Choose + next to the Data types step and select Edit data types, if you want to edit the inferred data type.
-
Add transformations and analytics using the data flow.
-
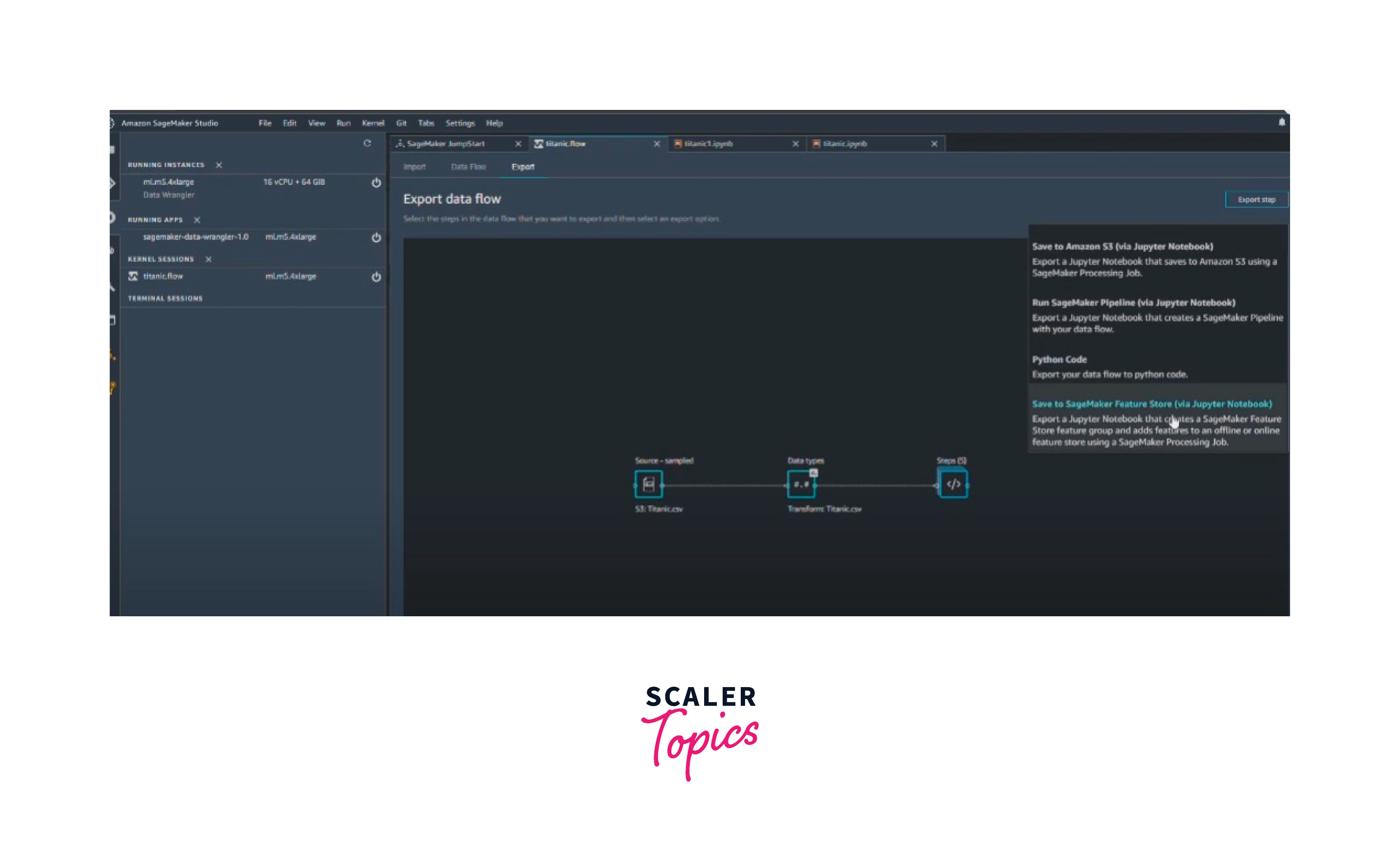
To export a complete data flow, click on Export and choose an export option.
-
To view all the flow files you've made, finally, pick the Components and registries button and choose Data Wrangler from the dropdown list. This menu can be used to locate and switch between data flows.
AWS Data Wrangler Customers
- Intuit:
For small businesses, accountants, and individuals, Intuit is a business and financial software company that creates and markets financial, accounting, and tax preparation software as well as related services. - GE Healthcare:
By improving outcomes for both patients and providers, GE Healthcare is revolutionizing healthcare by leveraging data and analytics across hardware, software, and biotech. GE Healthcare now has access to robust artificial intelligence tools and services through Amazon SageMaker, leading to better patient care. - ADP, Inc.:
ADP is a top provider of human capital management (HCM) solutions on a global scale. ADP DataCloud makes use of the unrivaled workforce data collected from over 30 million employees of ADP to provide executives with actionable insights that can aid in making decisions in real-time to better manage their companies. - Dow Jones:
Global news and business information provider Dow Jones & Co. distributes information to individuals and businesses via publications, websites, mobile apps, video, newsletters, magazines, exclusive databases, conferences, and radio. - Celgene:
The goal of the multinational biopharmaceutical business Celgene is to make patients' lives better all around the world. The search for, creation of, and commercialization of novel treatments for patients with cancer, and other unmet medical needs are the main objectives.
AWS Data Wrangler Top Alternatives
- Dask:
Dask scales Python natively. Dask offers high-level parallelism for analytics, allowing your favorite tools to perform well at scale. - logit.io:
Complete observability of logs, metrics, and traces is provided by Logit.io. The platform also includes Prometheus, OpenSearch, and Grafana in addition to alerting and monitoring. Get real-time information about your applications and services by ingesting any kind of data. - RSpec:
RSpec is a Behavior-Driven Development testing tool for the Ruby programming language that includes a robust command line program, textual examples, and other features. - Databricks:
Databricks provides a Unified Analytics Platform that accelerates innovation by unifying data science, engineering, and business. - InSpec:
It is a useful application used for Data Analysis, Building the workflow, Testing, Deploying, and Testing Frameworks. - Pandas:
For the Python programming language, Pandas is an open-source library that offers high-performance, simple-to-use data structures and tools for data analysis. - Apache Flink:
A streaming dataflow engine called Flink gives distributed computations data distribution, communication, and fault tolerance.
Conclusion
- Amazon SageMaker Data Wrangler is a new capability of Amazon SageMaker that helps data scientists and engineers quickly and easily prepare data for machine learning (ML) applications using a visual interface.
- This article explained how AWS Data Wrangler works. It focussed on how we can Select and query data with just a few clicks.
- In this article, we also learned how we could quickly analyze and predict an ML Model's accuracy. AWS Data Wrangler is also helpful in the visualization of the data for better understanding.
- This article also explained how to get started with AWS Data Wrangler. It covered how we can access and use AWS Data Wrangler from the SageMaker Studio.
- Ultimately, we look into some companies like Intuit and GE Healthcare that used AWS Data Wrangler for their proper functioning and some alternatives for AWS Data Wrangler like Apache Flink, and Databricks.