AWS Disaster Recovery
Overview
AWS cloud resources are accessed via the Internet, but they are also based on physical devices in various locations(data centers) around the globe. What if some natural calamity hit the location? What would happen to the customer's data and resources, which were hosted in data centers of these regions? To recover from such disasters, AWS has some strategies and plans known as AWS Disaster Recovery. It helps to quickly recover from the calamity.
What is AWS Disaster Recovery?
AWS Disaster Recovery is the service or backup provided by AWS to recover resources hosted on AWS Cloud in cases of disasters like natural calamities (flood, tsunami, earthquake, fire, etc.), power outage, security issues, etc. It focuses on the aim of recovering quickly from disasters.
AWS Disaster Recovery refers to the strategies and plans followed by AWS to cope with calamities. The goal of disaster recovery is achieved by planning backups in multiple availability zones of various regions. This backup is used for restoring resources and data stored in the cloud.
Importance of Disaster Recovery in AWS
Listed below is the importance of Disaster Recovery in AWS.
Ensure Business Continuity
In cases of disasters, a business day to day operations gets stopped. The main reason is they will be cut off from the resources stored in the cloud and unable to perform any operation related to these resources or data. There will be limitations on business operations leading to loss.
AWS Disaster Recovery is needed to ensure quick backup of data and resources so that the flow of day-to-day business activities is not hampered for longer.
Enhance System Security
AWS provides a secure environment for storing resources and data backups. Many companies use AWS to store data in the cloud, which limits suspicious activities and reduces any direct impact on the companies. Here AWS acts as a shield protecting the data.
Security risks are reduced enormously by integrating backups and restoring processes with data protection under AWS Disaster Recovery.
Customer Retention
Usually, when a disaster occurs, business work gets hampered. This leads to a loss of customers as they cannot fulfill their requirements. Customer frustration becomes inevitable if this continues for a longer duration of time.
AWS Disaster Recovery plans to train the employees to handle the customers. Customer confidence remains intact when they feel the business is planned and well-prepared to recover from disaster.
Recovery Costs
Depending on how impactful a disaster has been, huge losses can be suffered in terms of cost and productivity.AWS Disaster Recovery aims to reduce the expenses involved without impacting productivity.
Cloud storage solutions can be used effectively for data backups without much cost involved. Using these, you can continue your day-to-day business operations and reduce productivity loss.
Working on AWS Disaster Recovery
We know about AWS Disaster Recovery, so let's try to understand how they work. It mainly focuses on the applications that are affected and help run up the applications within minutes of an outage.
The organization addresses three main components. They are:
- Prevention - Prevention is one of the components to reduce the Disaster by ensuring all key systems are as reliable and secure as possible. We can't control a natural disaster, so we can only apply prevention to network problems, security risks, and human errors. We must set up the right tools and techniques to prevent any disaster.
- Anticipation - It includes predicting possible disasters which can be happened in the future, knowing their consequences, and planning according to the situation to recover. It is mainly based on a past incident that will happen and analyze those situations and come up with a disaster recovery solution.
- Mitigation - After a disaster scenario, how a business response is a mitigation. It aims to lower the negative impact on business procedures. If, in any event, a disaster, all key stakeholders should do the following steps:
- Updating documentation
- Conduct disaster recovery tests at regular intervals
- In the event of an outage, identify manual operating procedures
- Coordinate the disaster recovery strategy with some experts
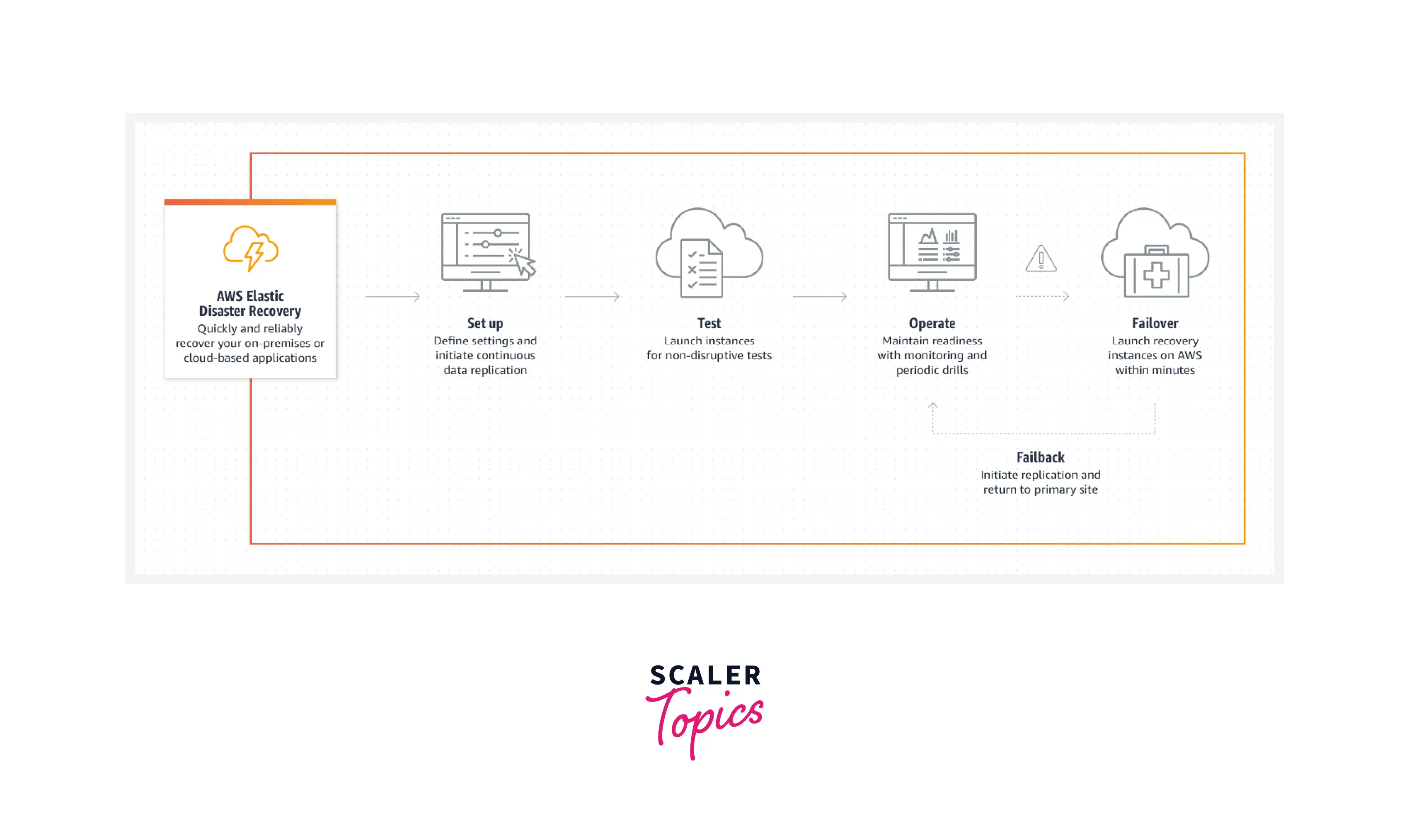
Key Elements of an AWS Disaster Recovery Plan
Some key elements are present in AWS Disaster Recovery Plan. Let's talk about those key elements in detail.
Internal and External Communication
It is very much important to communicate. The team who are taken care of the whole disaster recovery plan, from creating, implementing, and managing the entire thing, must communicate with each other about their roles and responsibilities. If any disaster happens, the team should know where the fault is and how to communicate with each other.
Recovery Timeline
The recovery timeline is when the disaster recovery team decides when the systems should be back to normal operations after any disaster. Many examples show those things when the Instagram and WhatsApp servers are down. In some cases, this timeline may be longer, but in some cases, it will be fixed in a few minutes. The recovery timeline has the following two objectives:
- Recovery time objective - A Recovery time objective (RTO) determines the maximum time before the complete disaster recovery. It may vary according to the IT infrastructure and systems.
- Recovery point objective - It is the maximum time acceptable for data loss after any disaster. If RPO is in minutes or hours, we must constantly back up the data across sites.
Data Backups
The data recovery plan decides how to back up the data. It provides us with cloud storage, vendor-supported backups, and internal offsite data backups. Onsite backup is not suitable for natural disaster events. The disaster recovery team should know about the data backup and how to implement the system.
Testing and Optimization
We must keep testing the disaster recovery plan once or twice a year. These tests help document and fix any gaps found during the testing. We should update all security and data protection strategies frequently. It will optimize the disaster recovery plan and prevent unauthorized access.
Disaster Recovery Options
There are various ways in which you can plan for disaster recovery. These options vary depending on the downtime and cost involved.
While planning strategies for disaster recovery, we need to keep in view the two main points:
- RTO: RTO stands for Recovery Time Objective. It is the longest gap or delays a business can tolerate from when the disaster occurred until data recovery.
- RPO: RPO stands for Recovery Point Objective. Say, if an organization backs up data every 10 minutes, then at most, a company can lose 10 minutes of work/data. Hence RPO is 10 minutes here.
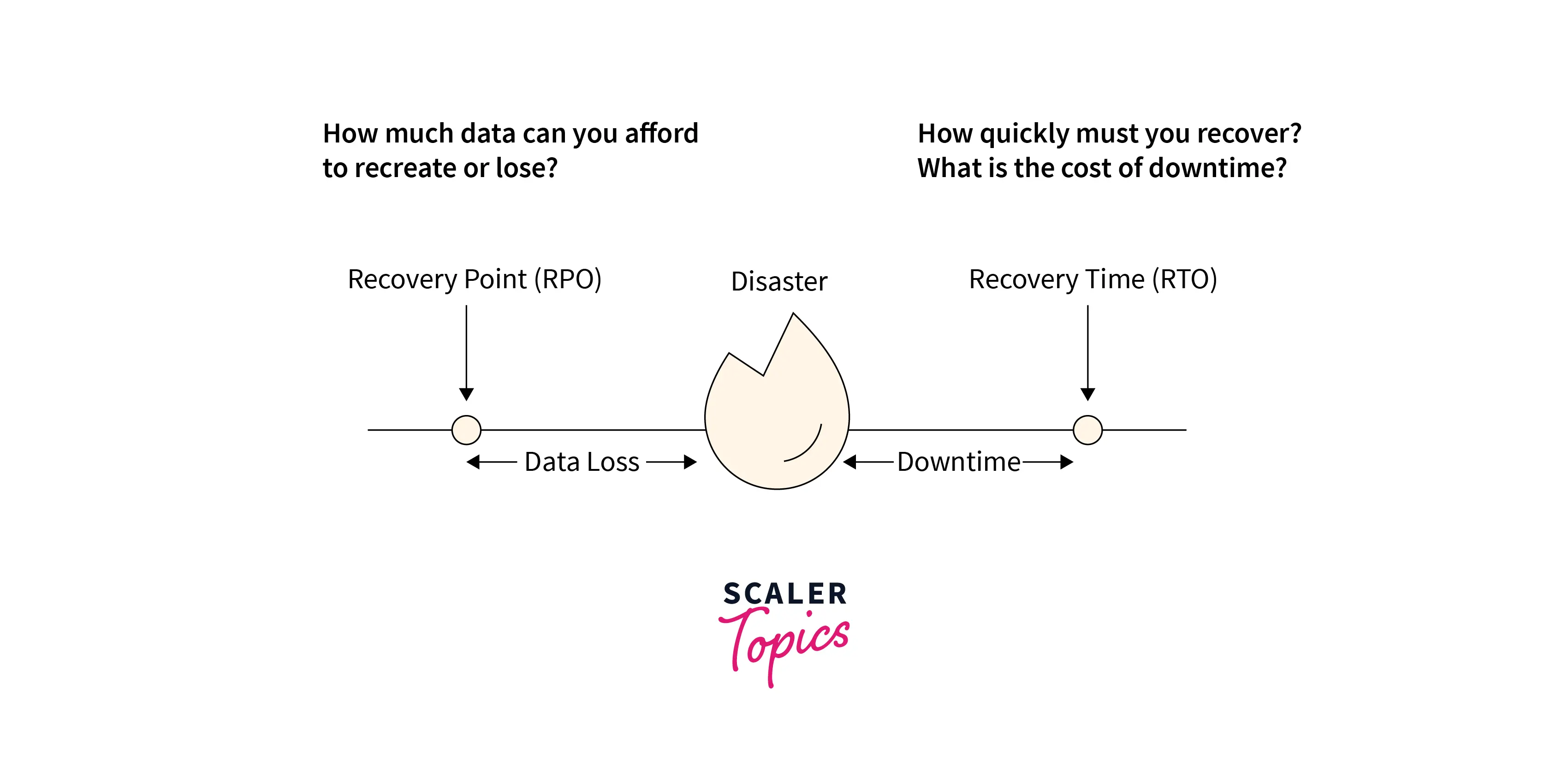
Having understood the two important factors determining downtime, let's discuss the various options you can opt for while planning for disaster recovery.
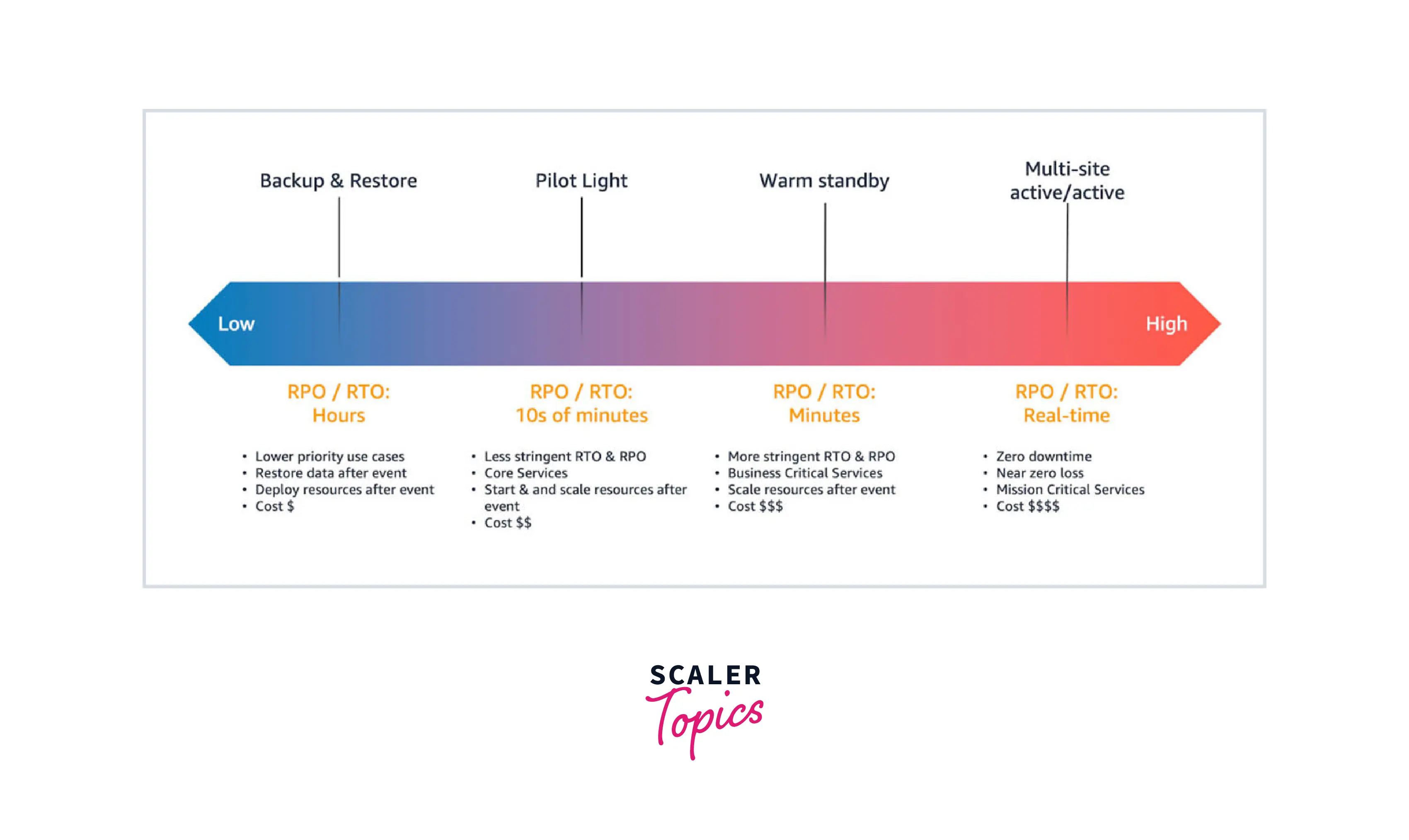
1. Backup and Restore
- Under these, in case of disasters, data is backed up in some other systems and restored. Usually, the data replication process is used to store multiple copies in different AWS regions.
- Least cost is involved in this disaster recovery method.
- RTO is high as the data servers are deployed after the disaster.
- AWS Snapshots and Dynamic Databases play a significant role in backup and restoration methods.
2. Pilot Light
- Under the pilot light method as well data replication method is involved.
- In this, the core infrastructural services run in a backup location in standby mode. In case of disaster, the mode is changed, and they serve as full-fledged core services. The additional services are triggered after the disaster.
- RTO is comparatively low as the core infrastructure services only need to be started and scaled in case of disaster.
- AWS Elastic Disaster Recovery, Amazon S3 Replication, Amazon RDS read replicas, Amazon Aurora global databases, Amazon DynamoDB global tables, etc., are some of the services which play a crucial role in the pilot light method.
3. Warm Standby
- Under these, the core infrastructural services and the minimal additional services are kept in standby mode in some other regions.
- Low RTO as the full backup system is kept in standby mode, which needs to be started with auto-scaling enabled.
- Cost involved is comparatively high.
- AWS auto-scaling and AWS EC2 auto-scaling are some of the services which play a crucial role in the Warm Standby option.
4. Multi-Site active/active
- Under this, an entire copy of the production environment is replicated and kept in standby mode in other AWS regions.
- Multi-site active/active means the replicated production environment can server traffic from every AWS region to which it is deployed.
- We have another strategy named hot standby active/passive under which the traffic is served from a single AWS region others are used for disaster recovery.
- In case of disaster, the replicated production environment is ready to serve the traffic with zero downtime resulting in extremely low RTO.
- The cost involved is much higher compared to other options.
- Various AWS services work together under this to make the production environment available in less than milliseconds.
How to Detect Disasters?
It is very much important to know and detect disasters. When the workloads do not deliver the expected business outcomes, we declare a disaster and recover from an incident. For aggressive recovery, the response time coupled with information is critical in meeting recovery objectives.
We can use Service Health Dashboard to get information on service availability. We can create a Support Request if any real-time operational issues are faced.
AWS Health Dashboard provides information about AWS Health events using an event log from the past 30 days. This also helps to detect any disaster.
Automated failover based on health checks For the most stringent RTO requirements. The functionality of the workloads and go beyond shallow heartbeat checks are done in deep health checks. These are the few ways how we can detect disasters and plan to recover.
Creating an AWS Disaster Recovery Team
We know more about Disaster recovery, let's try to create a team to handle this. AWS Disaster Recovery Team consists of a team of experts who are experts in the IT domain and leadership roles, which will be crucial to the team.
Some Key areas are there to be taken care of. They are:
- Crisis management - The experts in charge of crisis management can implement the disaster recovery plan. They communicate with the other members and customers to implement the disaster recovery process.
- Business continuity - The disaster recovery plan aligns with results from the business, and the business continuity manager will manage this. They help to include business continuity planning in disaster recovery.
- Impact recovery and assessment - The expert impact assessment experts in IT infrastructure and business applications. They fix the network infrastructure, servers, and databases and manage other disaster recovery tasks, like Application integrations, Data consistency maintenance, and Application settings and configuration.
Best Disaster Recovery Methods
There are various Disaster Recovery Methods. Some of the best ones are listed below:
Backups
- The most straightforward method of disaster recovery is to create backups.
- Data should be frequently backed up on some removable drivers, off-site servers, or cloud servers.
- Data backed up on AWS cloud servers are stored in a highly secure environment and scalable.
Data Centers
- The data centers must be prepared for recovery in natural disasters like fire or power outages.
- Data centers should have the equipment to deal with fires, like fire suppression tools, so that the servers are least impacted.
- They also need power backups to avoid or deal with power outages.
Virtualization
- Under this, the data backups are stored in virtual machines on-site or off-site.
- Companies automate the process of backing up data from these virtual machines.
- As a part of disaster recovery using virtualization Amazon EC2 is used for transferring data continuously.
AWS Elastic Disaster Recovery
- AWS provides a dedicated service for disaster recovery named AWS Elastic Disaster Recovery.
- In case of disaster, AWS Elastic Disaster Recovery is used to move critical business resources within the AWS cloud to some other regions.
Cold Site
- This is another way to allow daily business operations to be functional in case of disasters.
- The resources, data, servers, etc., are moved to rarely used physical locations called cold sites.
- Cold site is normally integrated with other disaster recovery methods.
Role of AWS in Disaster Recovery
The role of AWS in Disaster Recovery is significant. AWS provides a dedicated service for disaster recovery named AWS Elastic Disaster Recovery.
AWS Elastic Disaster Recovery reduces downtime and data loss with better and fast recovery of cloud-based applications. It helps decrease the RPO to seconds and RTO to a few minutes. Disaster recovery helps recover operations quickly after unexpected events, like data center hardware failures or software issues. It is a flexible solution to add or remove servers and test various applications.
Elastic Disaster Recovery gives the following benefits.
- It reduces the costs by removing idle recovery site resources.
- It helps to convert cloud-based applications to run natively on Amazon Web Services.
- If any disaster happens, it restores applications within minutes to their current stable state.
Conclusion
- AWS Disaster recovery helps the organization anticipate and addresses technology-related disasters.
- The disaster can be caused due to natural reasons like earthquakes or fire, technical failures, human errors, power outages, etc.
- There are multiple methods to plan for disaster recovery, which vary in time and cost involved like:
- Backup and Restore: Low cost and high time.
- Pilot light: High cost and low time compared to backups.
- Warm Standby: High cost and low time compared to the pilot light.
- Multi-site active/active: High cost and zero downtime.
- There are multiple methods to recover data like Backups, virtualization, AWS Elastic Disaster Recovery, etc.
- While creating an AWS disaster recovery team, you must take care of key factors like crisis management, business continuity, etc.