Amazon Neptune
Overview
Amazon Neptune is an Amazon Web Services fully managed graph database. Amazon Neptune supports common graph models such as property graph and RDF, as well as query languages such as Apache TinkerPop's Gremlin, openCypher, and SPARQL, as well as other Amazon Web Services products.
What is Amazon Neptune?
The AWS Neptune graph database service makes creating and executing applications that operate on highly linked datasets simple because it is quick, dependable, and fully controlled. A purpose-built, high-performance graph database engine serves as the foundation of Neptune. This engine is designed to query the graph with millisecond latency while keeping billions of relationships. You can create searches that effectively explore densely linked datasets with Neptune since it supports the well-liked graph query languages Apache TinkerPop Gremlin,` the W3C's SPARQL, and Neo4j's openCypher. Graph applications, including recommendation engines, fraud detection, knowledge graphs, medication discovery, and network security, are all powered by Neptune.
How Does It Work?
With a virtualized storage layer that is SSD-backed and made specifically for database workloads, AWS Neptune is engineered to offer higher than 99.99% availability while enhancing database speed. Storage on AWS Neptune is fault-tolerant, self-healing, and repairs for disc failures are done in the background, so that database availability is not impacted. With no crash recovery or database cache rebuilding required, Neptune is built to detect database crashes and resumes.
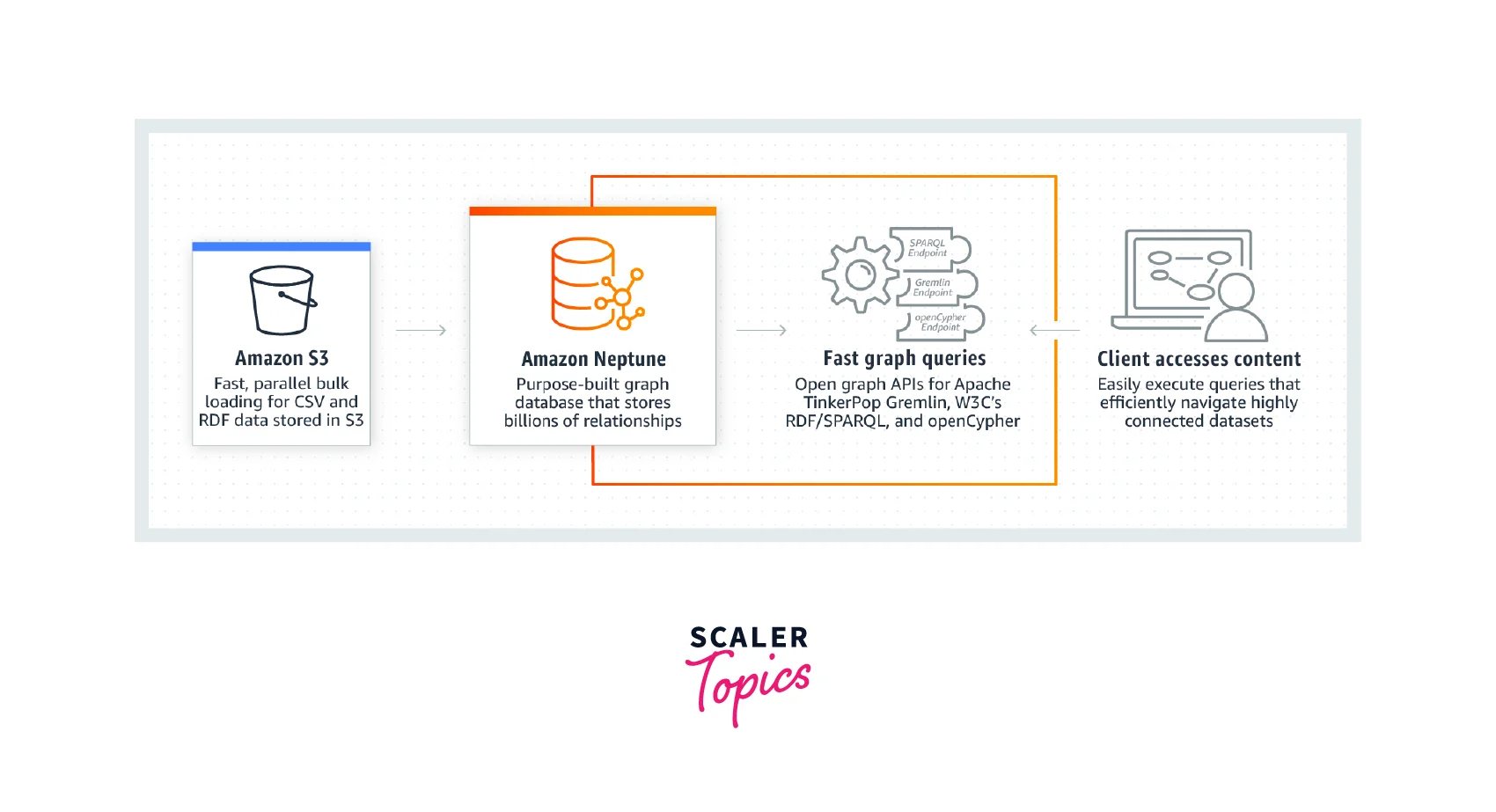
It uses fast graph queries that open graph APIs for Gremlin, SPARQL, and openCypher, which helps clients to access content and easily execute queries that efficiently navigate highly connected data sets.
Key Service Components:
Primary DB Instance: Supports read and write operations and handles all data changes to the cluster volume. Each Neptune DB cluster has one primary DB instance that is in charge of writing (that is, loading or changing) the contents of the graph database.
Neptune Replica: This replica connects to the same storage disk as the parent DB instance and only allows read activities. In addition to the core DB instance, each Neptune DB cluster can have up to 15 Neptune Replicas. This ensures high availability by placing Neptune Replicas in different Availability Zones and distributing reading client load.
Cluster Volumes: Neptune data is saved in the cluster volume, which is built for dependability and high availability. A cluster volume is a collection of data copies spread across various Availability Zones in a single AWS Region. Your data is very durable and unlikely to be lost since it is automatically replicated between Availability Zones.
Features of Amazon Neptune
High Performance and Scalability Graph Queries with High Throughput and Low Latency Amazon Neptune is a high-performance graph database engine designed specifically for Amazon. Neptune stores and explores graph data effectively, employing a scale-up, an in-memory efficient framework to enable quick query processing over vast networks. You may use Gremlin or SPARQL with Neptune to run sophisticated queries that are simple to create and perform effectively.
Easy Scaling of Database Compute Resources You may expand the computation and storage capabilities supporting your operational cluster down or up with a few clicks in the AWS Management Console by generating a new replica instance of the necessary size or deleting the instance. Compute scaling processes normally take a few minutes to complete.
Instance Monitoring and Repair Your Amazon Neptune databases and their supporting EC2 instances are constantly examined for stability. If the instance that powers your databases fails, the databases and related processes are recreated automatically. Because Neptune restoration does not necessitate the possibly time-consuming replaying of DB redo logs, instances restarting times are often 30 seconds fewer.
Multi-AZ Deployments with Reading Replicas When an instance fails, Amazon Neptune automatically switches to one of up to 15 Neptunereplicasyou've set up in each of the three Availability Zones. If no Neptune clones have been deployed, Neptune will try to generate a new DB instance for you immediately if a replica fails.
Fault-tolerant and Self-healing Storage Each 10GB block of your DB volume is replicated six times in three different Availability Zones. Amazon Neptune employs fault-tolerant storage, which supports the loss of up to two copies of data without impacting database write availability and up to three copies without affecting database read availability.
Automatic, Continuous, Incremental Backups and Point-in-Time Restore Amazon Neptune's backup feature allows for point-in-time recovery of your instance. This enables you to restore your Database at any point within the retention period, up to the last five minutes. Your automatic backup retention duration can be set to up to 35 days.
Database Snapshots Database Snapshots are user-initiated backups of your instance that are saved in Amazon S3 and will be preserved until you delete them expressly. They use automatic incremental snapshots to decrease the time and storage needed. You can always construct a new instance from a Database Snapshot.
Global Database Amazon Neptune Global Database is intended for globally distributed applications, with a single Neptune database spanning many AWS Regions. It duplicates the graph data with minimal influence on database performance, allows for fast local reads with low latency in each Region, and supports disaster recovery in the event of a region-wide outage.
Supports openCypher Neptune facilitates the development of graph applications using openCypher, which is now one of the most popular query languages for graph database developers. OpenCypher's SQL-inspired syntax appeals to developers, business analysts, and data scientists because it provides a familiar structure for composing queries for graph applications.
Machine Learning Amazon Neptune ML is a new Neptune feature powered by Amazon SageMaker that employs Graph Neural Networks (GNNs), a machine learning approach designed specifically for graphs, to produce simple, quick, and accurate predictions using graph data. When utilizing Neptune ML, you can enhance the accuracy of most graph predictions by more than 50% compared to non-graph approaches.
Highly Secure Amazon Neptune operates on Amazon VPC, allowing you to isolate your Database behind your virtual network and access your on-premises IT infrastructure through industry-standard secured IPsec VPNs.
Encryption Amazon Neptune enables you to encrypt databases using keys created and managed by AWS Key Management Service (KMS). Data held at rest in the underlying storage is secured on a database instance operating with Neptune encryption, as are automatic backups, snapshots, and replicas within the same clusters.
Advanced Auditing Amazon Neptune lets you track database events without affecting database performance as little as possible. Logs can be used for database administration, security, governance, regulatory compliance, and other applications in the future. You may also keep an eye on things by submitting audit records to AWS CloudWatch.
Automatic Software Patching Amazon Neptune can keep the Database patched with the most recent fixes. Database Engine Version Management allows you to manage whether and when your instances are patched.
Database Event Notifications Important database events, such as automated failover, can be notified by email (or) SMS via Amazon Neptune. Using the AWS Management Console, you may subscribe to various database events related to your Amazon Neptune databases.
Fast Database Cloning Amazon Neptune cloning processes are fast and efficient, allowing whole multi-terabyte database clusters to be copied in minutes. Cloning may be used for various tasks like application development, testing, database upgrades, and executing analytical queries. Immediate data availability may considerably improve software development, update efforts, and analytic accuracy.
Cost Effectiveness With Amazon Neptune, no initial payment is required; instead, you only pay an hourly fee for each instance you start. Additionally, you may quickly destroy a Neptune database instance after you're done with it. You just pay for the storage you use, so there's no need to supply more than you need as a safety net.
Getting Started with Amazon Neptune
What Exactly Is A Graph Database?
The relationships between data items may be stored and searched more efficiently in graph databases.
The actual data objects are kept as the graph's vertices, while the connections between them are kept as edges. Each edge is routed from one vertex (the start) to another and has a type (the end). Vertices and predicates may refer to relationships and edges, respectively. Both vertices and edges in so-called property graphs may also be linked with extra qualities.
Here is a simple graph showing how friends and interests are represented in a social network:
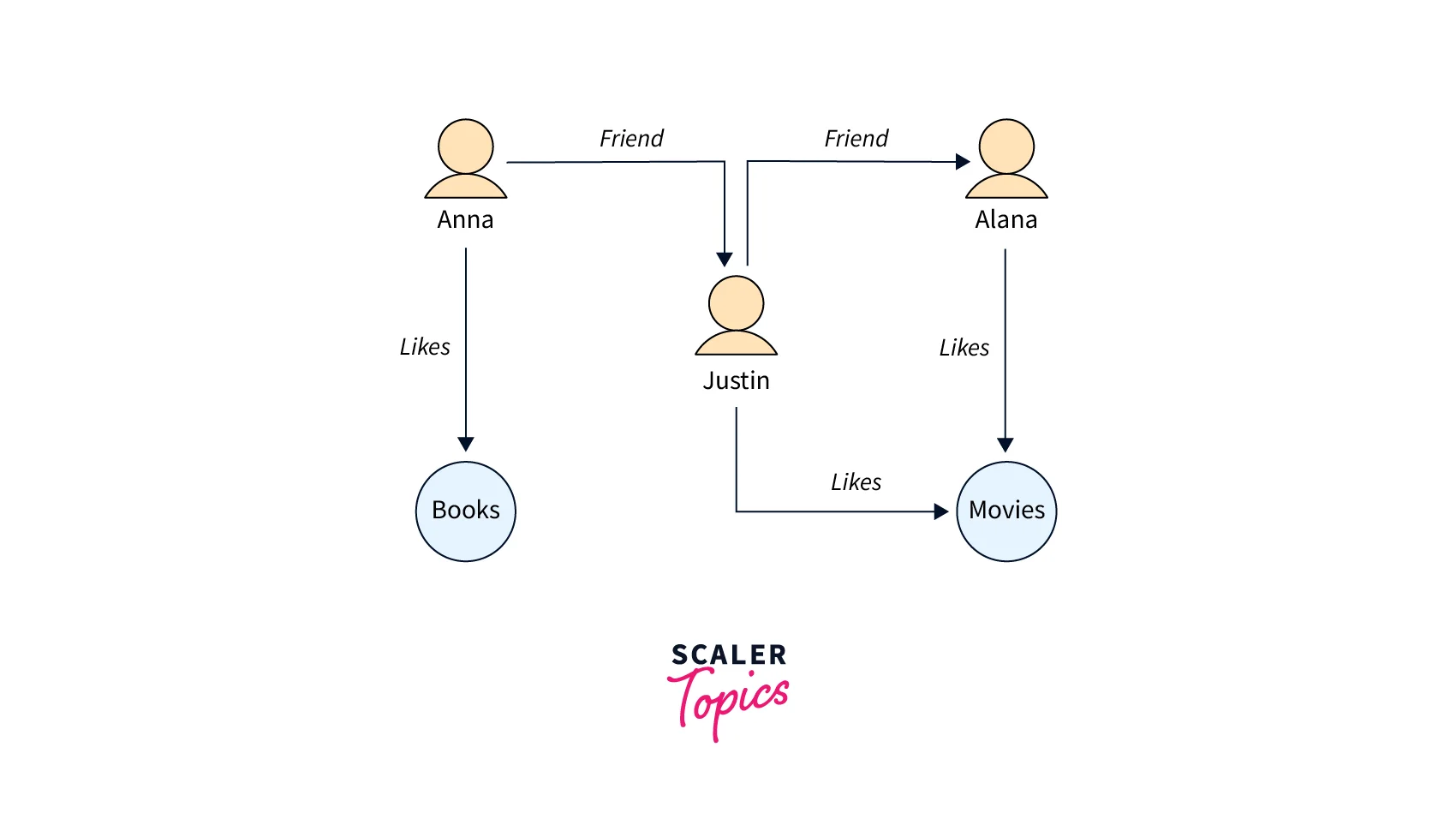
The vertices symbolize particular persons and interests they relate to, while the edges are depicted as labeled arrows.
This graph may be easily traversed to reveal Justin's friends' preferences.
Why Use A Graph Database?
A graph database is your obvious choice if connections or interactions between entities are at the heart of the data you seek to describe.
One benefit is that it's simple to describe data relationships as a graph and then create sophisticated queries that draw data from the network.
To build an identical application in a relational database, you must first establish several tables with numerous foreign keys and then code intricate joins and nested SQL queries. That method not only soon becomes cumbersome from a coding standpoint, but as the volume of data grows, so does its performance.
A graph database, like Neptune, on the other hand, may query relationships between billions of vertices without becoming sluggish.
What Can You Do With A Graph Database?
In terms of activities, ownership, parentage, purchasing decisions, interpersonal connections, familial ties, and other links, graphs can depict the interconnections between real-world entities in various ways.
The following are some of the most typical applications for graph databases:
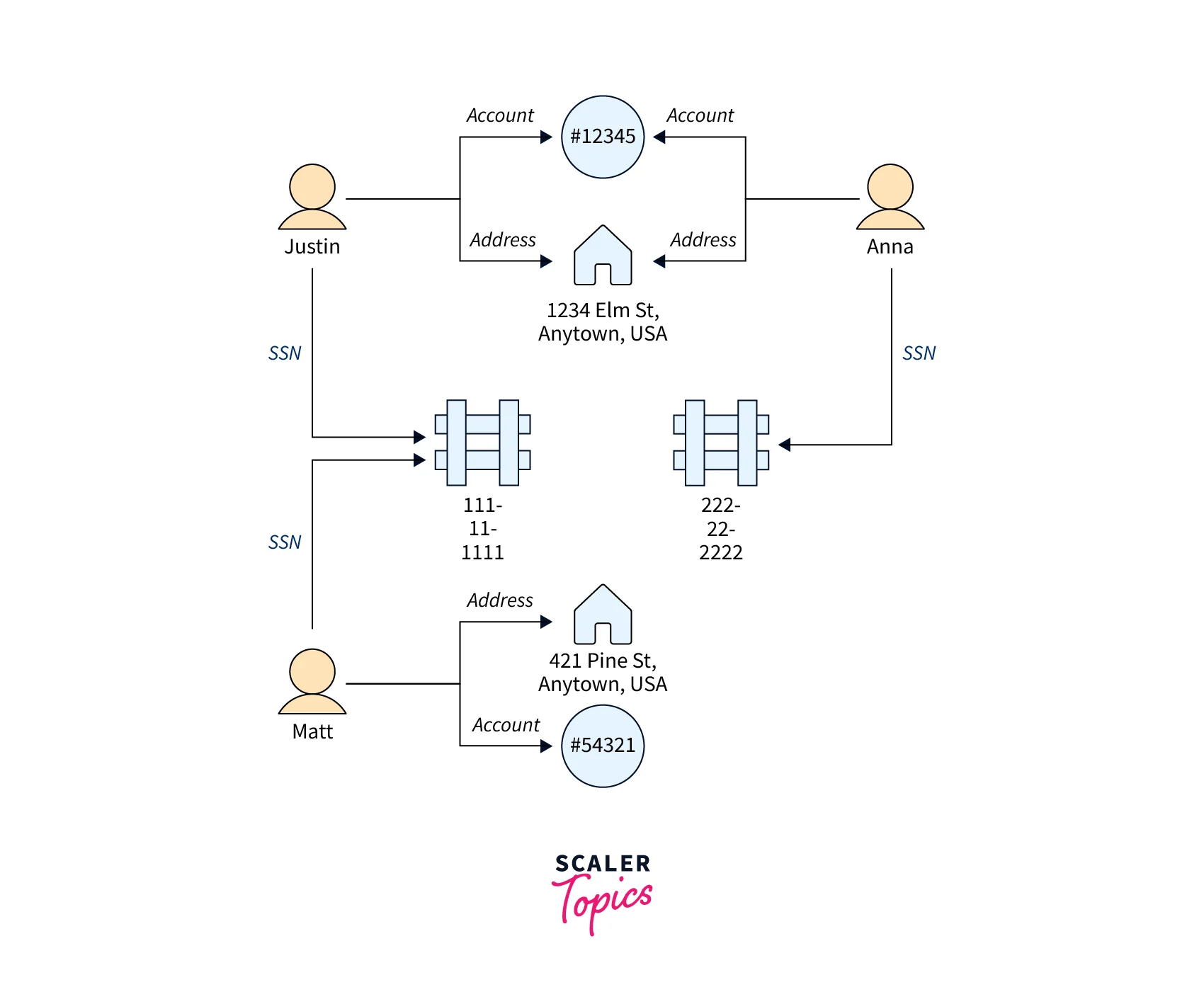
Knowledge Graphs Knowledge graphs let you organize and query all kinds of connected information to answer general questions. Using a knowledge graph, you can add topical information to product catalogs, and model diverse information such as is contained in Wikidata.
Identity Graphs In a graph database, you can store relationships between information categories such as customer interests, friends, and purchase history, and then query that data to make recommendations that are personalized and relevant.
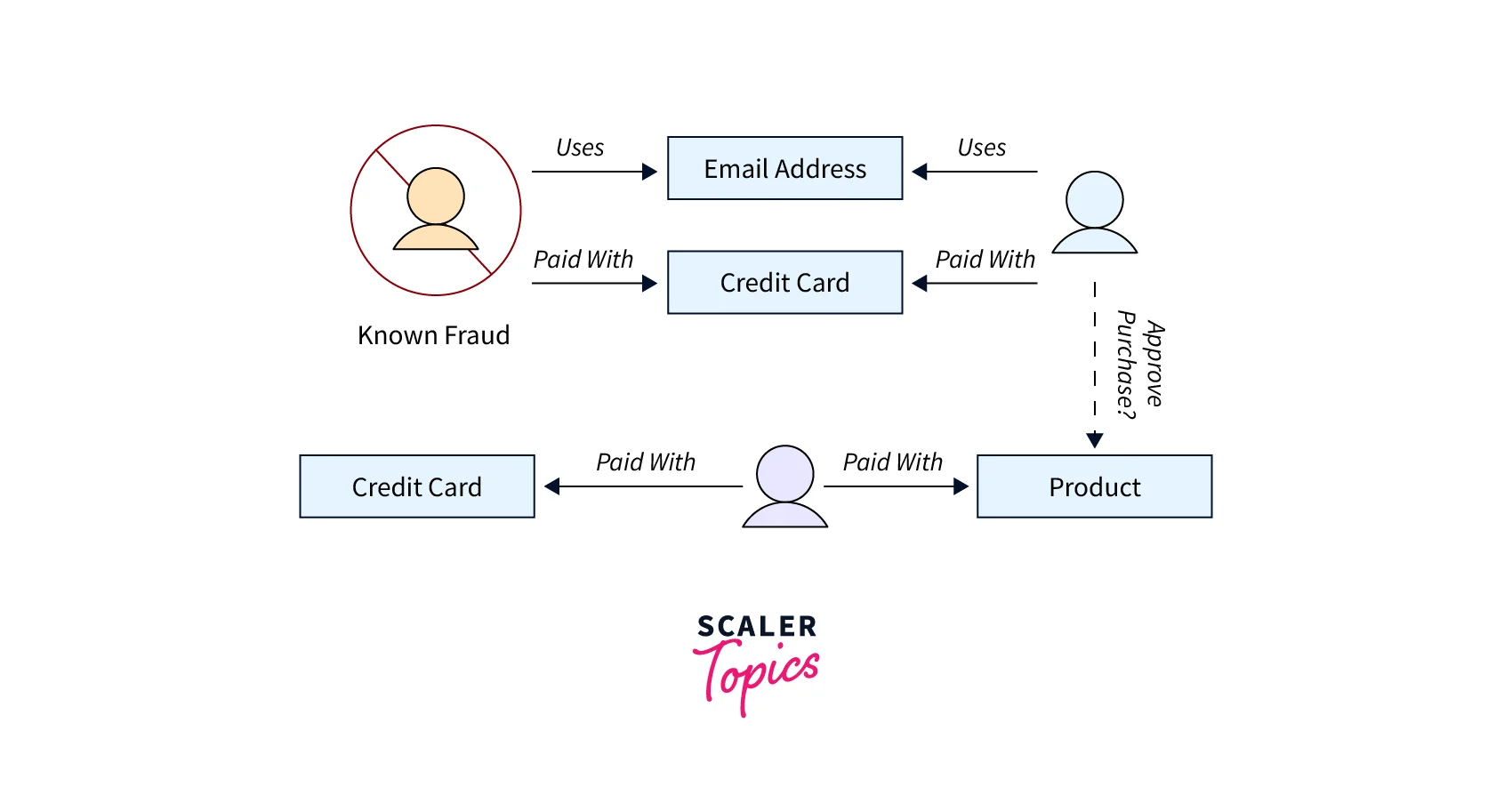
Fraud Graphs This is a common use for graph databases. They can help you track credit card purchases and purchase locations to detect uncharacteristic use, or to detect a purchaser is trying to use the same email address and credit card as was used in a known fraud case. They can let you check for multiple people associated with a personal email address or people in different physical locations who share the same IP address.
Social Networking One of the first and most common areas where graph databases are used is in social networking applications.
For example, suppose that you want to build a social feed into a website. You can easily use a graph database on the back end to deliver results to users that reflect the latest updates from their families, friends, people whose updates they "like," and people who live close to them.
Driving Directions A graph can help find the best route from a starting point to a destination, given current traffic and typical traffic patterns.
Logistics Graphs can help identify the most efficient way to use available shipping and distribution resources to meet customer requirements.
Diagnostics Graphs can represent complex diagnostic trees that can be queried to identify the source of observed problems and failures.
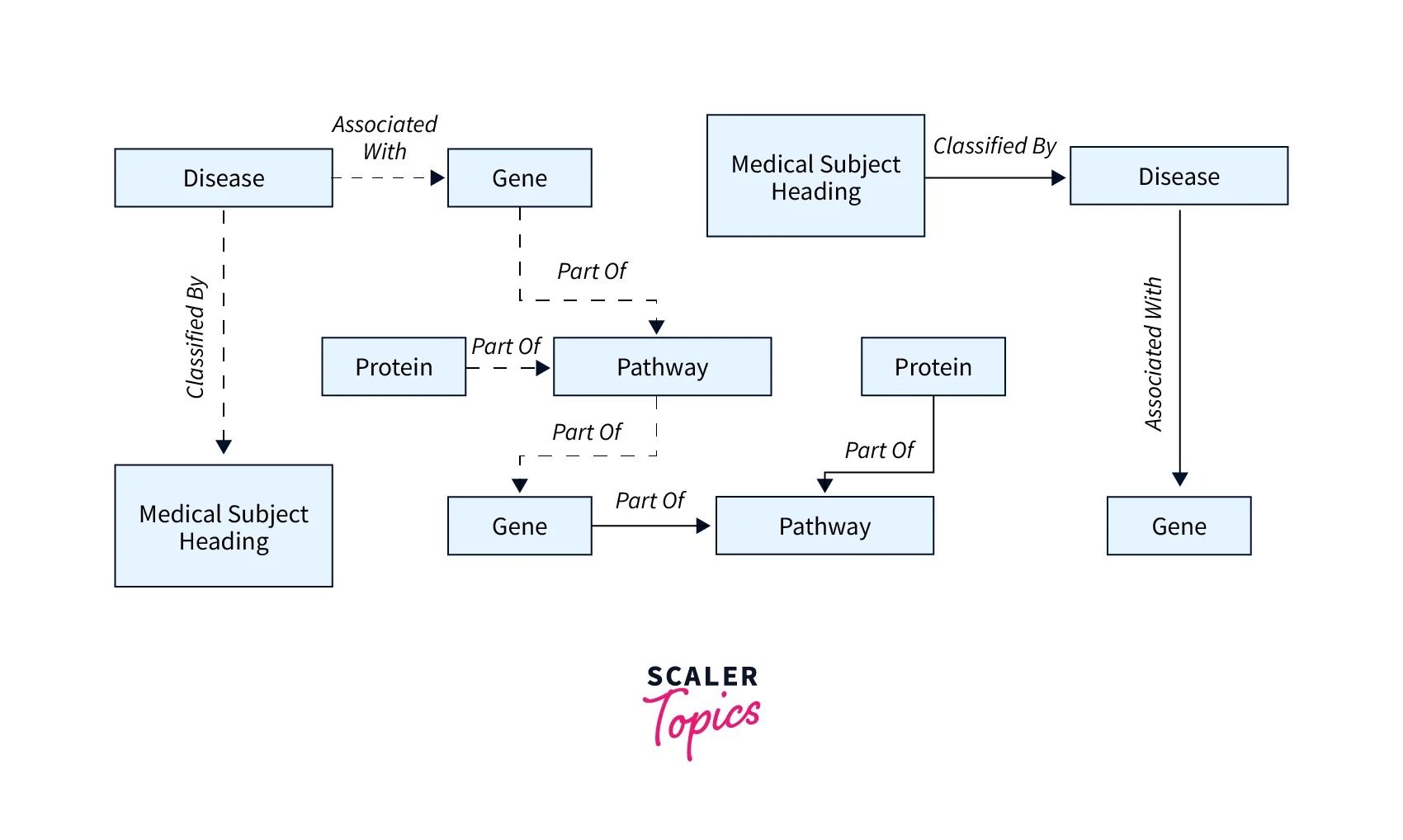
Scientific Research With a graph database, you build can applications that store and navigate scientific data and even sensitive medical information using encryption at rest. For example, you can store models of disease and gene interactions. You can search for graph patterns within protein pathways to find other genes that might be associated with a disease. You can model chemical compounds as a graph and query for patterns in molecular structures. You can correlate patient data from medical records in different systems. You can topically organize research publications to find relevant information quickly.
Regulatory Rules You can store complex regulatory requirements as graphs, and query them to detect situations where they might apply to your day-to-day business operations.
Network Topology and Events A graph database can help you manage and protect an IT network. When you store the network topology as a graph, you can also store and process many different kinds of events on the network. You can answer questions such as how many hosts are running a given application. You can query for patterns that might show that a given host has been compromised by a malicious program, and query for connection data that can help trace the program to the original host that downloaded it.
How Do You Query A Graph?
Neptune supports three specialized query languages for various types of graph data.
Gremlin A graph traversal language for property graphs is called Gremlin. In Gremlin, a query is a traversal consisting of discrete steps following an edge to a node. For further details, consult the Gremlin documentation at Apache TinkerPop3.
openCypher openCypher is a declarative query language for property graphs. In 2015, it was open-sourced and included in the openCypher project under an Apache 2 open-source license.
SPARQL Based on the graph pattern matching established by the World Wide Web Consortium (W3C) and the SPARQL 1.1 Query Language specification, SPARQL is a declarative query language for RDF data.
Please follow this link to understand how you can setup Neptune
Examples of Matching Gremlin and SPARQL Queries
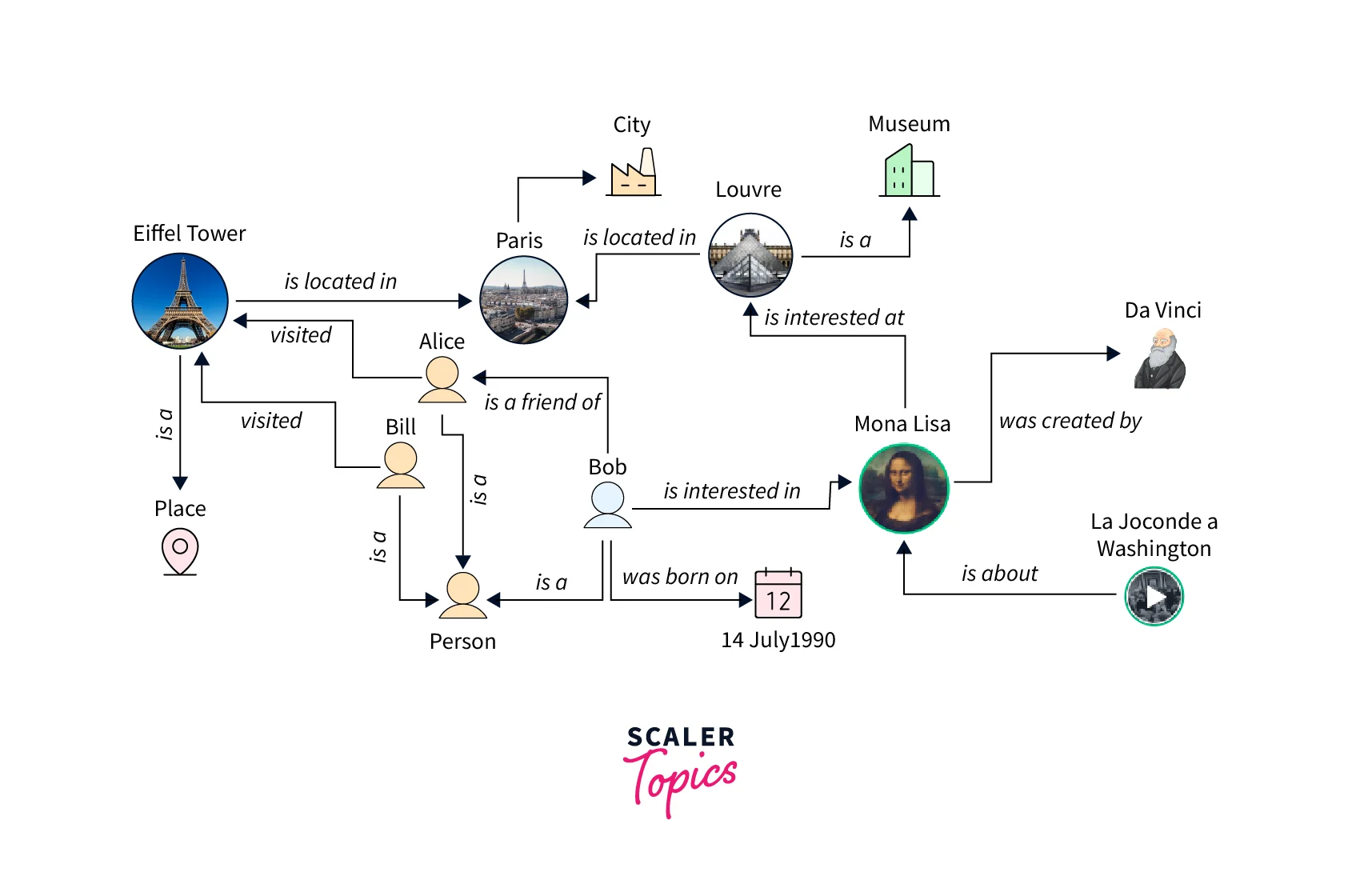
Given the following graph of people (nodes) and their relationships (edges), you can find out who the "friends of friends" of a particular person are— for example, the friends of Howard's friends.
Diagram showing relationships among people including their friendships.
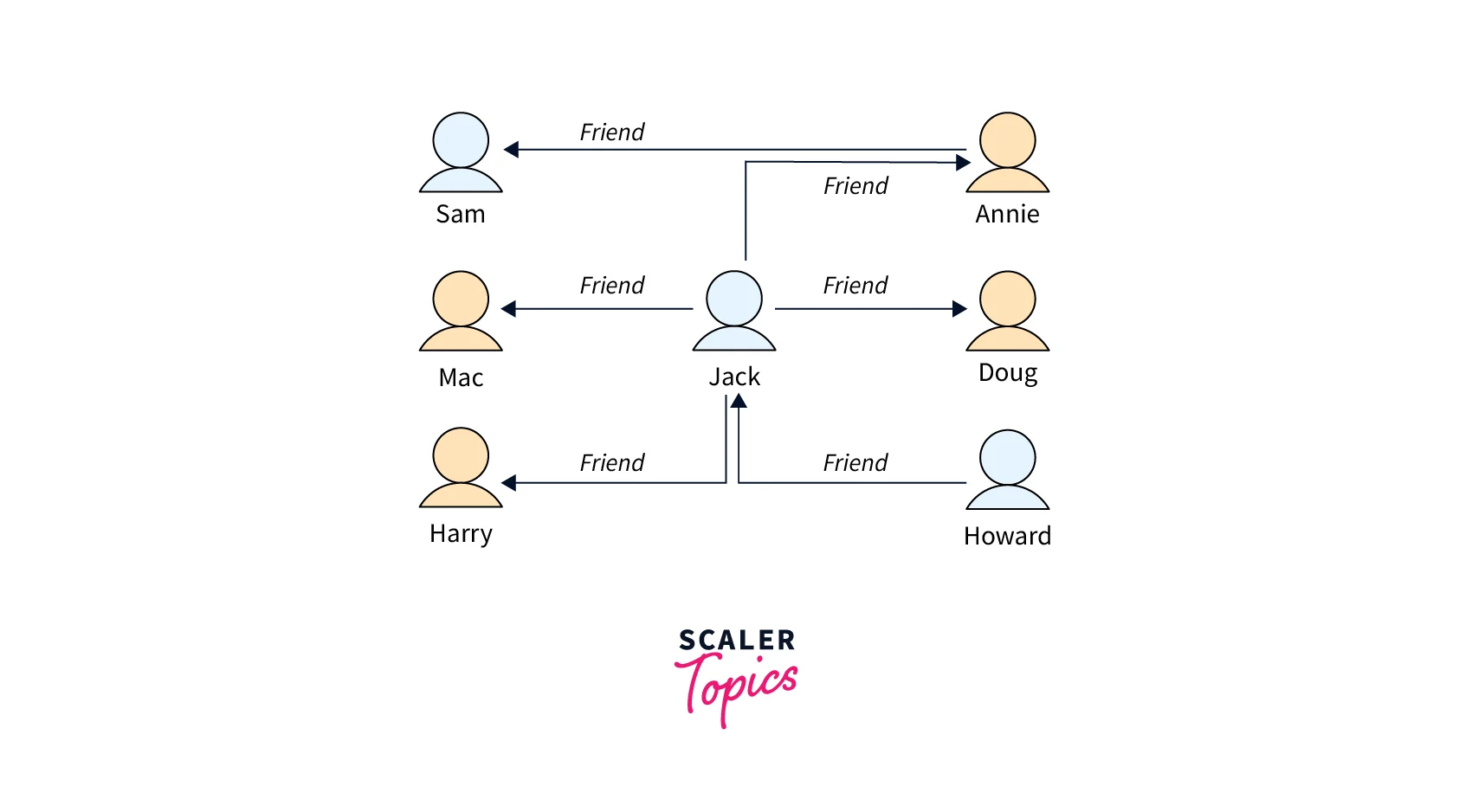
Looking at the graph, you can see that Howard has one friend, Jack, and Jack has four friends: Annie, Harry, Doug, and Mac. This is a simple example with a simple graph, but these types of queries can scale in complexity, dataset size, and result size.
Here is a Gremlin traversal query that returns the names of the friends of Howard's friends:
Here is a SPARQL query that returns the names of the friends of Howard's friends:
Use Cases of Amazon Neptune
Build Connections Between Identities Easily build identity graphs for identity resolution solutions, such as social graphs, and accelerate ad targeting, personalization, and analytics updates.
Build Knowledge Graph Applications Add topical data to product catalogs and general model information, and help users quickly navigate highly connected datasets.
Build Graph Queries Build graph queries for near-real-time identity fraud pattern detection in financial and purchase transactions.
Security Graphs To Improve IT Security Proactively detect and investigate IT infrastructure using a layered security approach. Visualize all infrastructure to plan, predict and mitigate risk.
Social Networking Amazon Neptune can quickly and easily process large sets of user-profiles and interactions to build social networking applications. Neptune enables highly interactive graph queries with high throughput to bring social features into your applications. For example, if you are building a social feed into your application, you can use Neptune to provide results that prioritize showing your users the latest updates from their family, from friends whose updates they ‘Like,’ and from friends who live close to them.
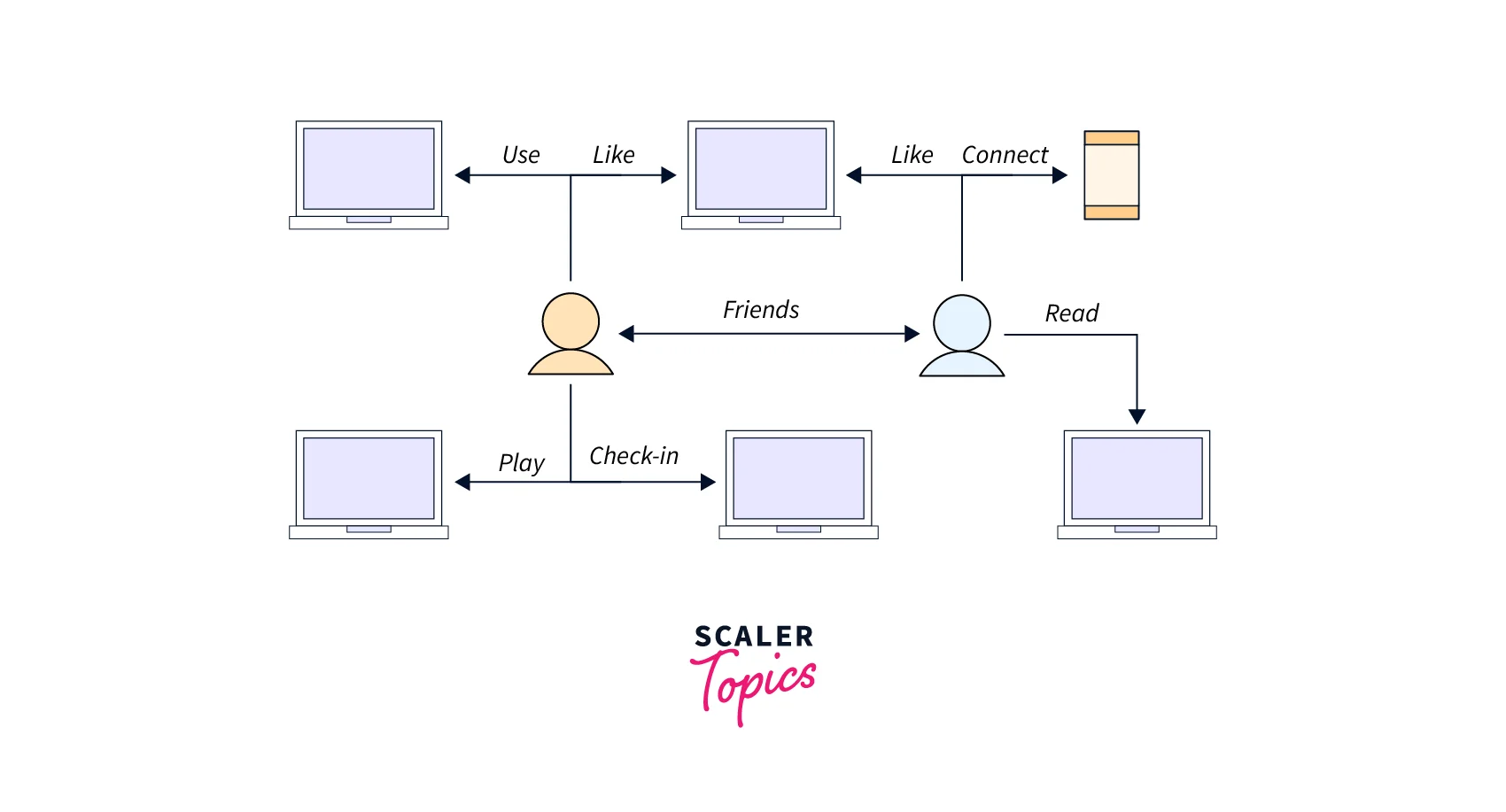
Recommendation Engines Amazon Neptune allows you to store relationships between information such as customer interests, friends, and purchase history in a graph and quickly query it to make recommendations that are personalized and relevant. For example, with Neptune, you can use a highly available graph database to make product recommendations to a user based on which products are purchased by others who follow the same sport and have similar purchase histories. Or, you can identify people that have a friend in common but don’t yet know each other, and make a friendship recommendation.
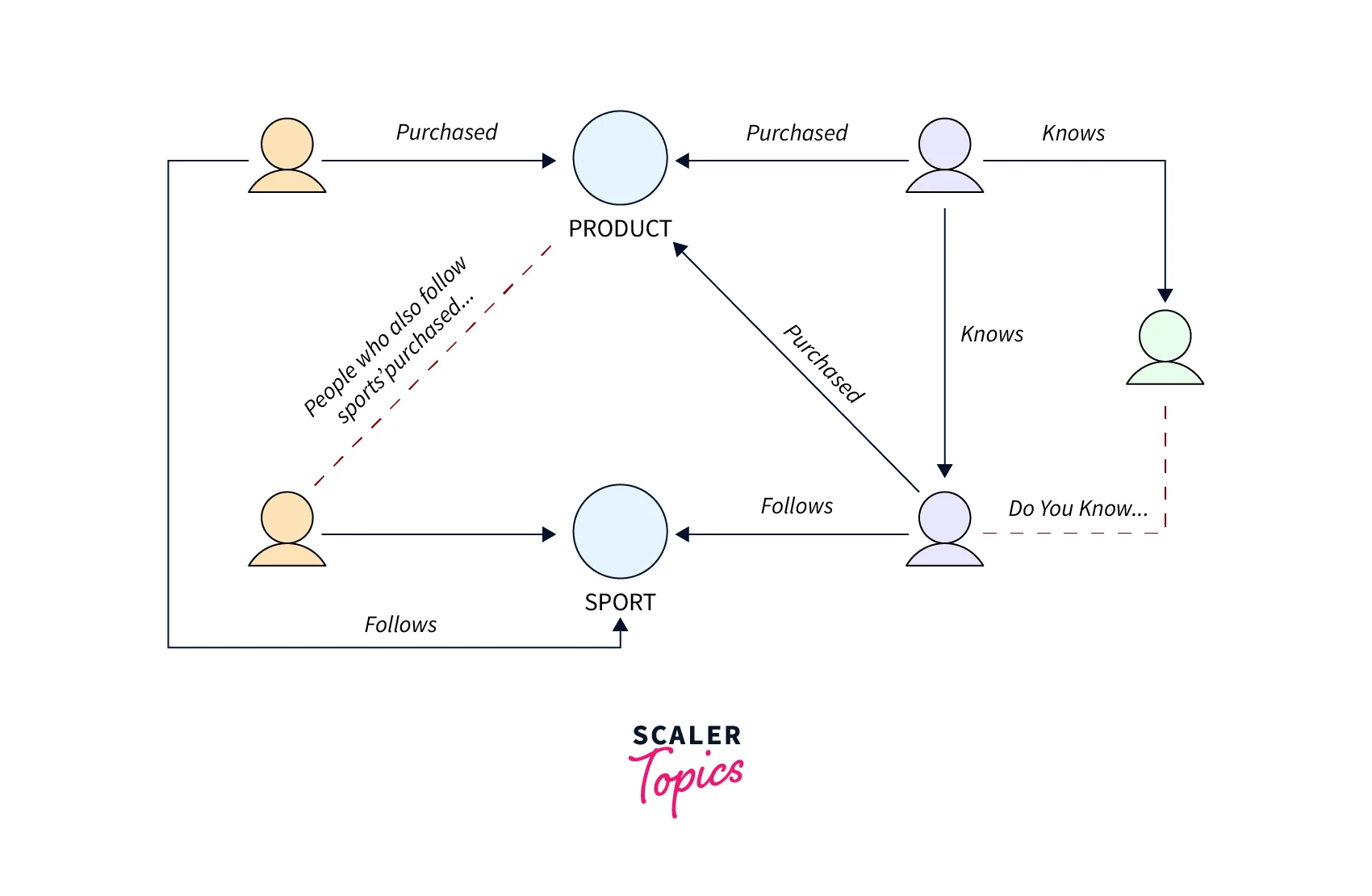
Fraud Detection With Amazon Neptune, you can use relationships to process financial and purchase transactions in near real-time to easily detect fraud patterns. Neptune provides a fully managed service to execute fast graph queries to detect that a potential purchaser is using the same email address and credit card as a known fraud case. If you are building a retail fraud detection application, Neptune can help you build graph queries to easily detect relationship patterns like multiple people associated with a personal email address, or multiple people sharing the same IP address but residing in different physical addresses.
Knowledge Graphs Amazon Neptune helps you build knowledge graph applications. A knowledge graph allows you to store information in a graph model and use graph queries to enable your users to easily navigate highly connected datasets. Neptune supports open source and open standard APIs to allow you to quickly leverage existing information resources to build your knowledge graphs and host them on a fully managed service. For example, if a user is interested in The Mona Lisa, you can also help them discover other works of art by Leonardo da Vinci or other works of art located in The Louvre. Using a knowledge graph, you can add topical information to product catalogs, build and query complex models of regulatory rules, or model general information, like Wikidata.
Life Sciences Amazon Neptune helps you build applications that store and navigate information in the life sciences and process sensitive data easily using encryption at rest. For example, you can use Neptune to store models of disease and gene interactions and search for graph patterns within protein pathways to find other genes that may be associated with a disease. You can model chemical compounds as a graph and query for patterns in molecular structures. Neptune also helps you integrate information to tackle challenges in healthcare and life sciences research. You can use Neptune to create and store data across different systems and topically organize research publications to quickly find relevant information.
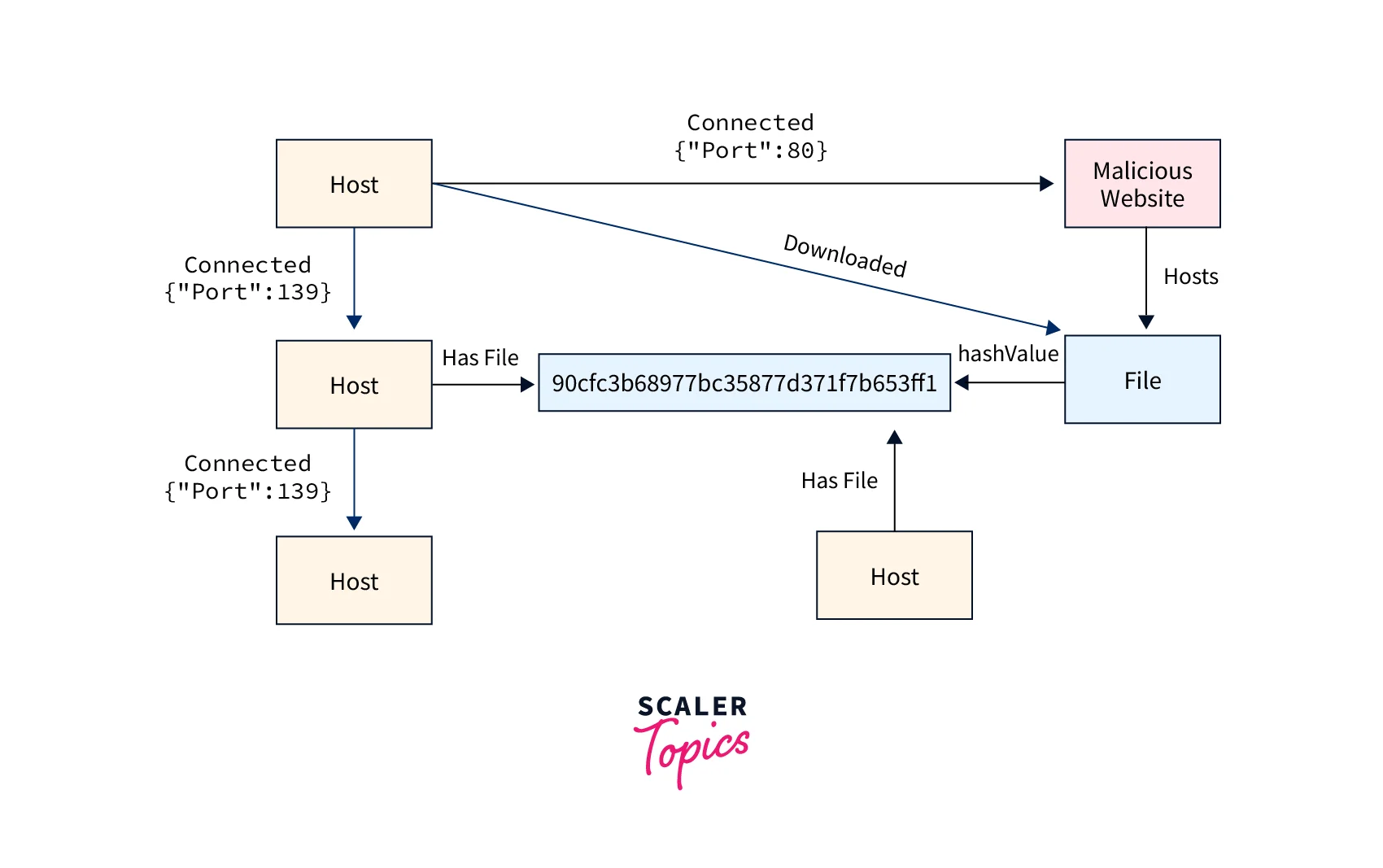
Network / IT Operations
You can use Amazon Neptune to store a graph of your network and use graph queries to answer questions like how many hosts are running a specific application. Neptune can store and process billions of events to manage and secure your network. If you detect an event that is an anomaly, you can use Neptune to quickly understand how it might affect your network by querying for a graph pattern using the attributes of the event. You can query Neptune to find other hosts `or devices that may be compromised. For example, if you detect a malicious file on a host, Neptune can help you to find the connections between the hosts that spread the malicious file and enable you to trace it to the original host that downloaded it.
Amazon Neptune Security
AWS places the highest priority on cloud security. Users have access to a data center and network architecture intended to fulfill the demands of the most security-conscious enterprises as AWS customers.
Security of the Cloud - Amazon Web Services is in charge of protecting the infrastructure that allows AWS services to be provided in the AWS Cloud. You may also get security services from AWS. Third-party auditors regularly evaluate and verify our security's efficacy as part of AWS compliance initiatives.
Security in the Cloud - Your obligation is determined by the AWS service you use. Other considerations include the sensitivity of your data, your company's requirements, and applicable laws and regulations.
Data Protection in Amazon Neptune
The AWS shared responsibility model applies to data protection in Amazon Neptune. As described in this model, AWS is responsible for protecting the global infrastructure that runs all of the AWS Cloud. You are responsible for maintaining control over the content that is hosted on this infrastructure. This content includes the security configuration and management tasks for the AWS services that you use. For more information about data privacy, see the `Data Privacy FAQ.
For data protection purposes, we recommend that you protect AWS account credentials and set up individual user accounts with AWS Identity and Access Management (IAM). That way each user is given only the permissions necessary to fulfill their job duties. We also recommend that you secure your data in the following ways:
-
Use` multi-factor authentication (MFA) with each account.
-
Use SSL/TLS to communicate with AWS resources. We recommend TLS 1.2 or later.
-
Set up API and user activity logging with AWS CloudTrail.
-
Use AWS encryption solutions, along with all default security controls within AWS services.
-
Use advanced managed security services such as Amazon Macie, which assists in discovering and securing personal data that is stored in Amazon S3.
-
If you require FIPS 140-2 validated cryptographic modules when accessing AWS through a command line interface or an API, use a FIPS endpoint.
We strongly recommend that you never put confidential or sensitive information, such as your customers' email addresses, into tags or free-form fields such as a Name field. This includes when you work with Neptune or other AWS services using the console, API, AWS CLI, or AWS SDKs. Any data that you enter into tags or free-form fields used for names may be used for billing or diagnostic logs. If you provide a URL to an external server, we strongly recommend that you do not include credentials information in the URL to validate your request to that server.
You use AWS-published API calls to manage Neptune through the network. Clients must support Transport Layer Security (TLS) 1.2 or later using strong cipher suites, as described in Encryption in Transit. Most modern systems such as Java 7 and later support these modes.
Amazon Neptune Pricing
Free Tier
-
As part of the AWS Free Tier`, you can get started with Amazon Neptune for free. If your organization has never created an Amazon Neptune cluster until April 20, 2022, or later, you are eligible to use 750 hours of the Neptune db.t3.medium or db.t4g. medium instance, 10 million I/O requests, 1 GB of storage, and 1 GB of backup storage for free for 30 days.
-
Your free trial starts from the day when you create your first Amazon Neptune cluster. Once your free trial expires or your usage exceeds the free allowance, you can keep it running at our standard on-demand rates.
On-Demand Instance Pricing On-Demand Instances let you pay for your database by the hour with no long-term commitments or upfront fees. This frees you from the costs and complexities of planning, purchasing, and maintaining hardware and transforms what are commonly large fixed costs into much smaller variable costs.
Instance pricing applies to both primary instances, used for read-write workloads, and to Amazon Neptune replicas, used to scale reads and enhance failover. Neptune uses Multi-Availability-Zone (Multi-AZ) architecture to failover to one of your replicas if an outage occurs. The cost of Multi-AZ deployments is simply the cost of the primary instance plus the cost of each Neptune replica. To maximize availability, we recommend placing at least one replica in a different Availability Zone from the primary instance.
| Instance Type | Pricing |
|---|---|
| db.t3.medium | $0.098 per Hour |
| db.t4g.medium | $0.093 per Hour |
Database Storage and IOs Storage consumed by your Amazon Neptune database is billed in per GB-month increments, and I/Os consumed is billed in per million request increments. You pay only for the storage and I/Os your Neptune database consumes and does not need to provision in advance.
Region: US East(Ohio)
Storage ------------> 0.20 per 1 million requests
Global Database Amazon Neptune Global Database is an optional feature providing low-latency global reads and disaster recovery in the unlikely event of region-wide outages. You pay for replicated write I/Os between the primary region and each secondary region. The number of replicated write I/Os to each secondary region is the same as the number of in-region write I/Os performed by the primary region. Apart from replicated write I/Os, you pay standard Neptune rates for instances, storage, cross-region data transfer, and backup storage.
Region
Replicated Write I/Os -----------> $0.20 per million replicated write I/Os
Backup Storage
Region
Backup Storage -----------> $0.021 per GB-month
-
Backup storage for Amazon Neptune is the storage associated with your automated database backups and any customer-initiated database cluster snapshots. Increasing your backup retention period or taking database cluster snapshots increases the backup storage consumed.
-
Backup storage is allocated by region. Total backup storage space is equivalent to the sum of the storage for all backups in that region.
-
Moving a database snapshot to another region increases allocated backup storage in the destination region.
-
There is no additional charge for backup storage of up to 100 percent of your total Neptune database storage for each Neptune database cluster. There is also no additional charge for backup storage if your backup retention period is one day and you don’t have any snapshots beyond the retention period.
-
Backup storage as well as snapshots you store after your database cluster is deleted will be charged at the above rates.
-
For example, if you have 2 active Neptune database clusters each with 300 GB-month of consumed database storage, we provide up to 600 GB-month of backup storage at no additional charge.
Data Transfer
- Data transferred between Amazon Neptune and Amazon EC2 Instances in the same Availability Zone is free.
- Data transferred between Availability Zones for replication of Multi-AZ deployments is free.
- Amazon Neptune database instances outside VPC: For data transferred between an Amazon EC2 instanceandAn Amazon Neptune database instance in different Availability Zones of the same Region, there is no Data Transfer charge for traffic in or out of the Amazon Neptune database instance.
- You are only charged for the Data Transfer in or out of the Amazon EC2 instance, and standard Amazon EC2 Regional Data Transfer charges apply.
- Amazon Neptune database instances inside VPC: For data transferred between an Amazon EC2 instance and an Amazon Neptune database instance in different Availability Zones of the same Region, Amazon EC2 Regional Data Transfer charges apply on both sides of the transfer.
The pricing below is based on data transferred “in” and “out” of Amazon Neptune.
Region
Data Transfer OUT From Amazon Neptune To Internet AWS customers receive 100GB of data transfer out to the internet free each month, aggregated across all AWS Services and Regions (except China and GovCloud). The 100 GB free tier for data transfer out to the internet is global and does not apply separately or individually to AWS Regions.
| First 10 TB / Month | $0.09 per GB |
| Next 40 TB / Month | $0.085 per GB |
| Next 100 TB / Month | $0.07 per GB |
| Greater than 150 TB / Month | $0.05 per GB |
Amazon Neptune Workbench Amazon Neptune Workbench provides Neptune notebooks, which you can use to run graph queries and visualize results in Jupyter Notebooks hosted by Amazon SageMaker. A Neptune notebook instance is priced per instance hour running in Ready State.
Region
| Instance Type | vCPU | Memory | Price per Hour |
|---|---|---|---|
| ml.t3.medium | 2 | 4 GiB | $0.05 |
| ml.t3.large | 2 | 8 GiB | $0.10 |
| ml.t3.xlarge | 4 | 16 GiB | $0.20 |
| ml.t3.2xlarge | 8 | 32 GiB | $0.399 |
Benefits of Amazon Neptune
Supports Open Graph APIs Amazon Neptune supports open graph APIs for both Gremlin and SPARQL and provides high performance for both of these graph models and their query languages. It lets you choose the Property Graph model and its open-source query language, Apache TinkerPop Gremlin, or the W3C standard Resource Description Framework (RDF) model and its standard query language, SPARQL.
High Performance and Scalability Amazon Neptune is a purpose-built, high-performance graph database. It is optimized for processing graph queries. Neptune supports up to 15 low latency read replicas across three Availability Zones to scale read capacity and execute more than one-hundred thousand graph queries per second. You can easily scale your database deployment up and down from smaller to larger instance types as your needs change.
High Availability and Durability Amazon Neptune is highly available, durable, and ACID (Atomicity, Consistency, Isolation, Durability) compliant. Neptune is designed to provide greater than 99.99% availability. It features fault-tolerant and self-healing storage built for the cloud that replicates six copies of your data across three Availability Zones. Neptune continuously backs up your data to Amazon S3 and transparently recovers from physical storage failures. For High Availability, instance failover typically takes less than 30 seconds.
Highly Secure Amazon Neptune provides multiple levels of security for your database, including network isolation using Amazon VPC, support for IAM authentication for endpoint access, HTTPS encrypted client connections, and encryption at rest using keys you create and control through Amazon Key Management Service (KMS). On an encrypted Neptune instance, data in the underlying storage is encrypted, as are the automated backups, snapshots, and replicas in the same cluster.
Fully Managed With Amazon Neptune, you don’t need to worry about database management tasks such as hardware provisioning, software patching, setup, configuration, or backups. Neptune automatically and continuously monitors and backs up your database to Amazon S3, enabling granular point-in-time recovery. You can monitor database performance using Amazon CloudWatch.
Conclusion
-
With a cheap cost for that sort of capacity, Amazon Neptune is a fully managed graph database service that expands to handle billions of relationships and allows you to query them with millisecond latency.
-
You may use AWS Key Management Service-created and managed keys to encrypt your databases using Amazon Neptune (KMS).
-
To provide straightforward, speedy, and precise predictions using graph data, Amazon Neptune ML is a machine learning technique created exclusively for graphs.
-
With a few clicks in the AWS Management Console, you may increase or decrease the computing and storage resources supporting your operating cluster.