AWS Timestream
Overview
Amazon Timestream is a fast, scalable, fully managed, purpose-built time series database that makes it easy to store and analyze trillions of time series data points per day. AWS Timestream saves you time and cost in managing the lifecycle of time series data by keeping recent data in memory and moving historical data to a cost-optimized storage tier based on user-defined policies. AWS Timestream's purpose-built query engine lets you access and analyze recent and historical data together, without having to specify its location.
Introduction to AWS Timestream
Time Series data is a sequence of data points recorded over time intervals to measure events that change over time. Time Series Data is about measuring some value, whether that value is the car's speed or the price of a stock.
Everything that goes into a time-series database like AWS Timestream will have an associated timestamp. It is about measuring these data points as they vary over time. Trillions of time series data points may be easily stored and analyzed daily, thanks to AWS Timestream. Its specially designed query engine allows you to access and analyze recent and historical data together without specifying its location. With built-in time series analytics capabilities, Amazon Timestream lets you quickly spot patterns and trends in your data.
AWS Timestream is a serverless platform that automatically scales up or down to optimize performance and capacity. You can concentrate on developing and optimizing your applications because you don't have to worry about managing the underlying infrastructure. Amazon Timestream has built-in time series analytics functions, which help you identify trends and patterns in your data in near real-time.
The frequently used services for collecting data like IoT devices as well as machine learning tools are also integrated with Timestream. AWS IoT Core, Amazon Kinesis, Amazon MSK, and open-source Telegraf can all be used to transfer data to Amazon Timestream. Through JDBC, you may visualize data using tools like Amazon QuickSight, Grafana, and business intelligence software. AWS Timestream with Amazon SageMaker is also a good option for quick and robust data transfer in the machine learning domain.
Concepts
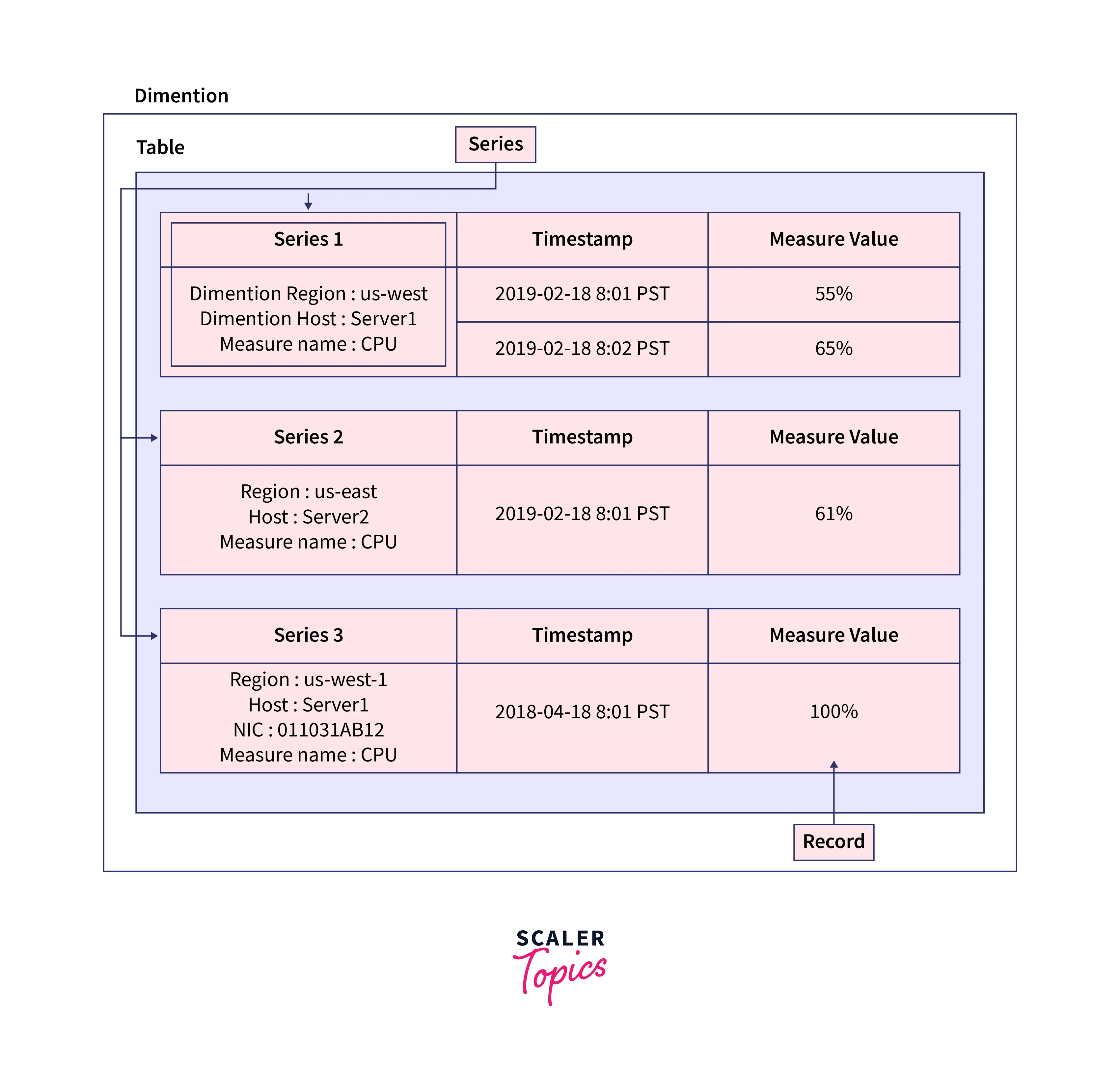
The main AWS Timestream concepts are listed below.
- Time series- A collection of data points (or records) that were gathered over some time. A stock's price over time, an EC2 instance's CPU or memory usage over time or the temperature or pressure reading from an IoT sensor over time are a few examples.
- Record-A single data point in a time series.
- Dimension-A property that describes a time series' meta-data. An attribute's name and value together make up a dimension. Think of the following instance:
- When considering a stock exchange as a dimension, the dimension value is "NYSE," and the dimension name is "stock exchange."
- Measure - The actual value that the record is measuring. The stock price, CPU or memory usage, and temperature or humidity reading are a few examples. Measures are made up of measure names and values. Think about the following instances:
- The measured value for a stock price is the actual stock price at a certain point in time, and the measured name for a stock price is "stock price."
- The measured value for CPU utilization is the actual CPU utilization, and the measure name for this metric is "CPU utilization."
- Timestamp - Indicates the date when a measure for a particular record was gathered. Timestream supports nanosecond-level timestamps.
- Table - A container for a set of related time series.
- Database - A top-level container for tables.
AWS Timestream Architecture
Amazon Timestream was created from the ground up to gather, store, and handle massive amounts of time series data. Its serverless architecture offers scale-out, fully decoupled query processing, storage, and data intake systems. This design makes each sub-system simpler, reducing the likelihood of associated system failures, scaling bottlenecks, and the difficulty of achieving unshakable stability. As the system scales, each of these components assumes a greater significance. More information about each is provided below.
Please be patient with us while we fully comprehend the timestream architecture because it can be a bit complicated and challenging.
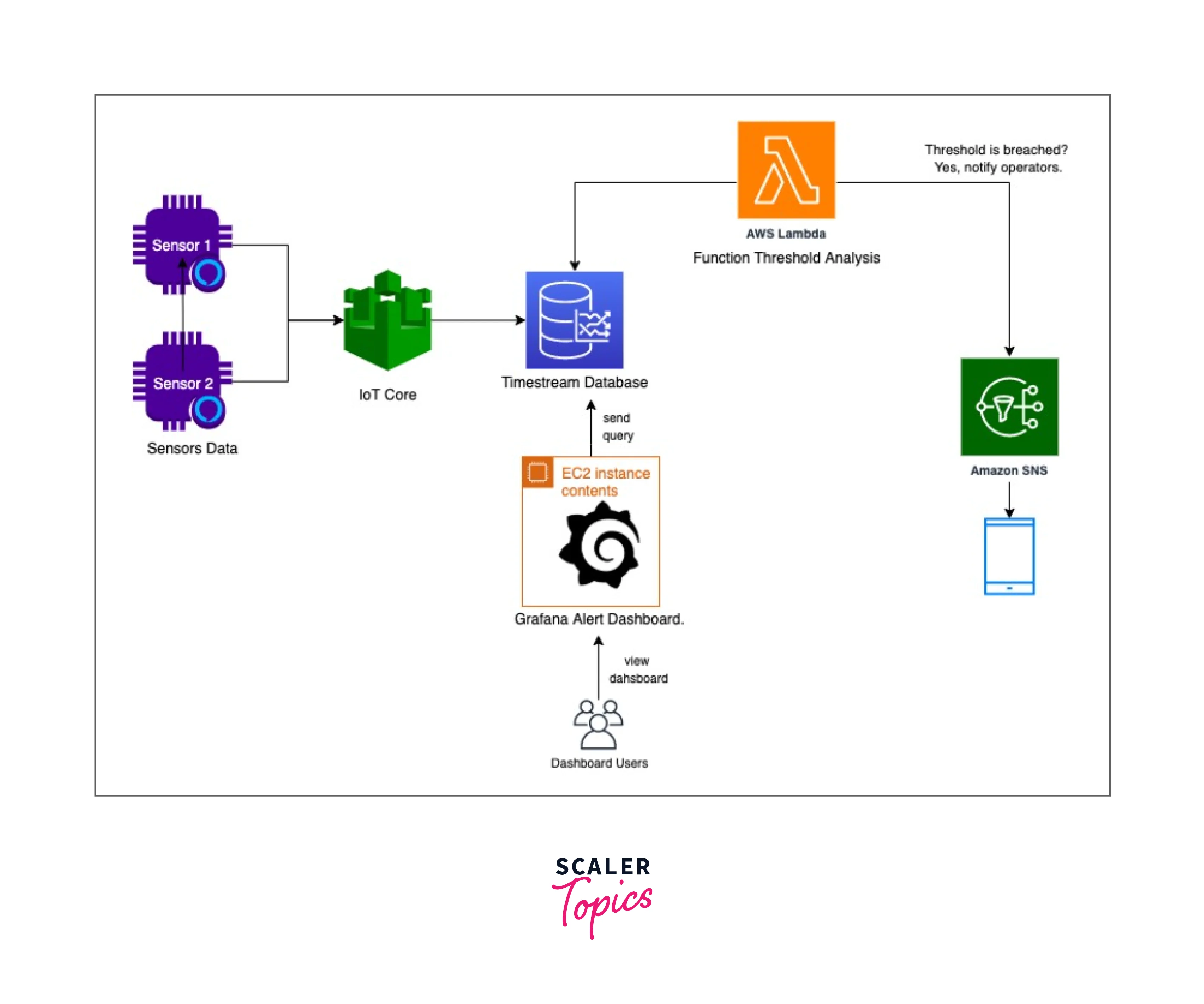
In Amazon Timestream, there are four parts to the architecture. The architecture of Amazon Timestream is entirely automated, and each of these components has a crucial function.
The four types of Amazon Timestream architecture are given below:
- Write architecture
- Query architecture
- Storage architecture
- Cellular architecture
Write Architecture
Data can be written directly to a magnetic disc or another magnetic storage device for the apps that produce less throughput (work per unit of time) and late arrival data.
What are late arrival data, exactly? Late arrival data is, as the name implies, data that comes in late and is saved late, which means that its timestamp is earlier than the current time.
Characteristics of the Write Architecture
The working of write architecture is as follows:
- In a manner similar to the high throughput writes in the memory store, data written to the magnetic disc is duplicated over three AZs and is based on a quorum.
- Before writing information to storage, whether it is in memory or on a magnetic disc, AWS Timestream automatically divides and indexes the data.
- One Timestream table may have hundreds, thousands, or even millions of partitions.
- Data sharing and direct communication between individual partitions are not possible (shared-nothing architecture). Instead, the partitioning of a table is tracked by a highly available partition tracking and indexing service.
- It creates another layer of separation of concerns to reduce the impact of system failures and the likelihood of associated shortcomings.
Query Architecture
As timestream queries are written in SQL with extensions for time series-specific support (for time series-specific data types and functions), developers familiar with SQL will find the learning curve relatively short.
When data is stored in Timestream, data is organized concerning time as well as across time, based on context attributes written with the data. Having a partitioning scheme that divides "space" in addition to time is important for massively scaling a time series system. The resulting partitions are referred to as "Tiles" since they represent divisions of a two-dimensional space that are designed to be of similar size.
An adaptive, distributed query engine employs metadata from the tile tracking and indexing service to easily access and aggregate data across data stores when the query is submitted. This creates a positive client experience by reducing many complications to a simple and familiar database abstraction.
Characteristics of Query Architecture
The characteristics of query architecture are given below:
- Queries are executed by a specialized group of workers, with the number of workers assigned to each query determined by the query's complexity and storage capacity.
- Massive parallelism is used on both the system's query execution and storage fleets to achieve performance for sophisticated queries over big data sets.
- One of Timestream's greatest assets is its capacity to swiftly and efficiently analyze large amounts of data.
- Thousands of machines may be working on a single query that runs over terabytes or even petabytes of data simultaneously.
Storage Architecture
Data is arranged in AWS Timestream in chronological order and across time-based on context attributes written with the data. When massively scaling a time series system, having a partitioning mechanism that divides "space" and "time" is critical. This is because most time-series data is written at or near the present time.
As a result, simply partitioning by time does not effectively distribute write traffic or allow for effective data pruning at query time. This is critical for large-scale time series processing, and it has enabled Timestream to scale orders of magnitude greater than the best serverless systems available today.
Timestream tables begin as a single division (tile) and are later divided in the spatial dimension as throughput demands. Tiles split in the time dimension when they reach a particular size, allowing for increased read parallelism as the data size expands.
Timestream is a database that manages the lifecycle of time series data automatically. Timestream supports establishing table-level rules to move data between stores automatically, and it offers two data stores: an in-memory store and a cost-effective magnetic store.
Characteristics of Storage Architecture
- Incoming high-throughput data writes are sent to the memory store, which optimizes data for writing and reads conducted around the current time for the dashboard and alerting inquiries.
- It allows data to automatically migrate from the memory store to the magnetic store to optimize cost once the main time frame for writes, alerts and dashboarding needs has passed.
- Timestream allows you to specify a data retention policy on the memory store. Data is directly written into the magnetic store for late arrival data.
- The data is restructured into a highly optimized format for big-volume data reads once it is available in the magnetic store (due to the expiration of the memory store retention period or direct writes into the magnetic store).
- The magnetic store also features a data retention policy that can be set if the data reaches a point where it is no longer helpful.
- The data is automatically deleted when the period selected for the magnetic storage retention policy is exceeded.
- Except for minor settings, Timestream manages the data lifetime seamlessly behind the scenes.
Cellular Architecture
The system is also built using a cellular architecture to guarantee that AWS Timestream can provide almost infinite scaling for your applications while still assuring 99.99% availability. Instead of scaling the entire system, Timestream divides into numerous smaller versions of itself, known as cells. As a result, cells can be tested at full scale, and activity in any other cells within a specific region is not affected by a system issue in one cell.
Features of AWS Timestream
-
Serverless auto-scaling architecture: With its fully decoupled design, which enables data ingestion, storage, and query to scale independently, Amazon Timestream can provide practically limitless scaling for an application's requirements. You don't need to manage infrastructure or provision capacity using Amazon Timestream.
-
Data storage tiering: Amazon Timestream streamlines your data lifecycle management with magnetic storage for old data and memory storage for recent data. The magnetic store is optimized for quick analytical queries, whereas the memory store is optimized for quick point-in-time questions. You don't need to configure, oversee, or manage a complex data archival procedure using Amazon Timestream. To automatically shift data from the memory store to the magnetic store and to erase it from the magnetic store when it reaches a specific age, you may quickly establish data retention policies.
-
Purpose-built adaptive query engine: You can access data without using several tools while using Amazon Timestream. Thanks to Amazon Timestream's specially designed adaptive query engine, you may retrieve data from many storage tiers using a single SQL statement. It accesses and integrates data from several storage levels without your input.
-
Built-in time series analytics: Amazon Timestream defines time series as a native data type and provides time series analytics. Advanced aggregates, window functions, and complicated data types like arrays and rows are all supported.
-
Always encrypted data: You don't need to manually encrypt data in transit or at rest because Amazon Timestream automatically encrypts all of your data. You can also specify an AWS KMS customer-managed key (CMK) with Amazon Timestream to encrypt data in the magnetic store.
-
Performant and cost-effective time-series analytics: For calculating and storing aggregates, rollups, and other real-time analytics required to power frequently visited operational dashboards, business reports, applications, and device-monitoring systems, Amazon Timestream's scheduled queries provide a fully managed, serverless, and scalable solution.
AWS Timestream Use Cases
-
It provides support to IoT applications: Users can quickly assess time-series data produced by IoT applications using Amazon Timestream's built-in analytical capabilities, which include smoothing, approximation, and interpolation. Some of the instances include collecting motion or temperature data from the device sensors, interpolating to identify time ranges without motion, or alerting consumers to take actions such as turning off the light to save energy.
-
It supports DevOps applications: DevOps systems that check health and usage indicators in real-time and analyze data to optimize performance and availability are ideal for using Amazon Timestream. Users can utilize Amazon Timestream to collect and analyze operational metrics such as CPU/memory utilization, network data, and IOPS to monitor health and optimize instance utilization.
-
It supports Analytics applications: Large amounts of data may be easily stored and analyzed, thanks to Amazon Timestream. Users can use Amazon Timestream, for instance, to store and manage clickstream data for incoming and outgoing web traffic for their apps. Amazon Timestream also offers aggregate data analysis and learning services, such as path-to-purchase and cart abandonment rates.
AWS Timestream Pricing
There are no upfront prices or minimum charges when using Amazon Timestream; you only pay for the services you utilize. Using Amazon Timestream is subject to usage fees based on the following criteria:
- Writes: The volume of data entered into a table by your apps (rounded to the closest KB).
- Queries: Quantity of data scanned by the serverless distributed query engine used by Amazon Timestream to produce query results (rounded to the nearest MB, with a 10 MB minimum).
- Memory store: The volume of data kept in each table's memory store.
- Magnetic store: The volume of data kept in each table's magnetic store.
Although the pricing changes as the regions change, the below demonstrates the pricing for the US East (N. Virginia) region.
| Metric | Price |
|---|---|
| Writes - 1 million writes of 1KB size | $0.50 |
| Queries-Per GB scanned | $0.01 |
| Memory Store - Price per GB stored per hour | $0.036 |
| Magnetic Store - Price per GB stored per month | $0.03 |
The following functionalities are additionally provided by Amazon Timestream without charge.
- High Availability: Amazon Timestream offers high availability of your write by automatically replicating data and resources across at least three Availability Zones within a single AWS Region.
- Security: Whether it is in transit or at rest, all data in Amazon Timestream is always secured using AWS Key Management Service (KMS) keys.
- Monitoring: The Amazon CloudWatch Metrics released by Amazon Timestream is free of charge.
- Metadata queries: There are no charges for queries such as SELECT 1, SHOW DATABASES, SHOW TABLES, SHOW MEASURES, and others.
Getting Started with AWS Timestream
This section demonstrates how to build a database with example data sets and how to execute sample queries. Time series data from a truck's speed, position, and load are included in the IoT dataset to simplify fleet management and pinpoint areas for improvement. To increase the performance and availability of applications, the DevOps dataset includes EC2 instance metrics for CPU, network, and memory use.

Using the AWS Console
Step 1:
- Go to the Amazon Timestream Console.
- Click on Create Database button under the Getting Started option.
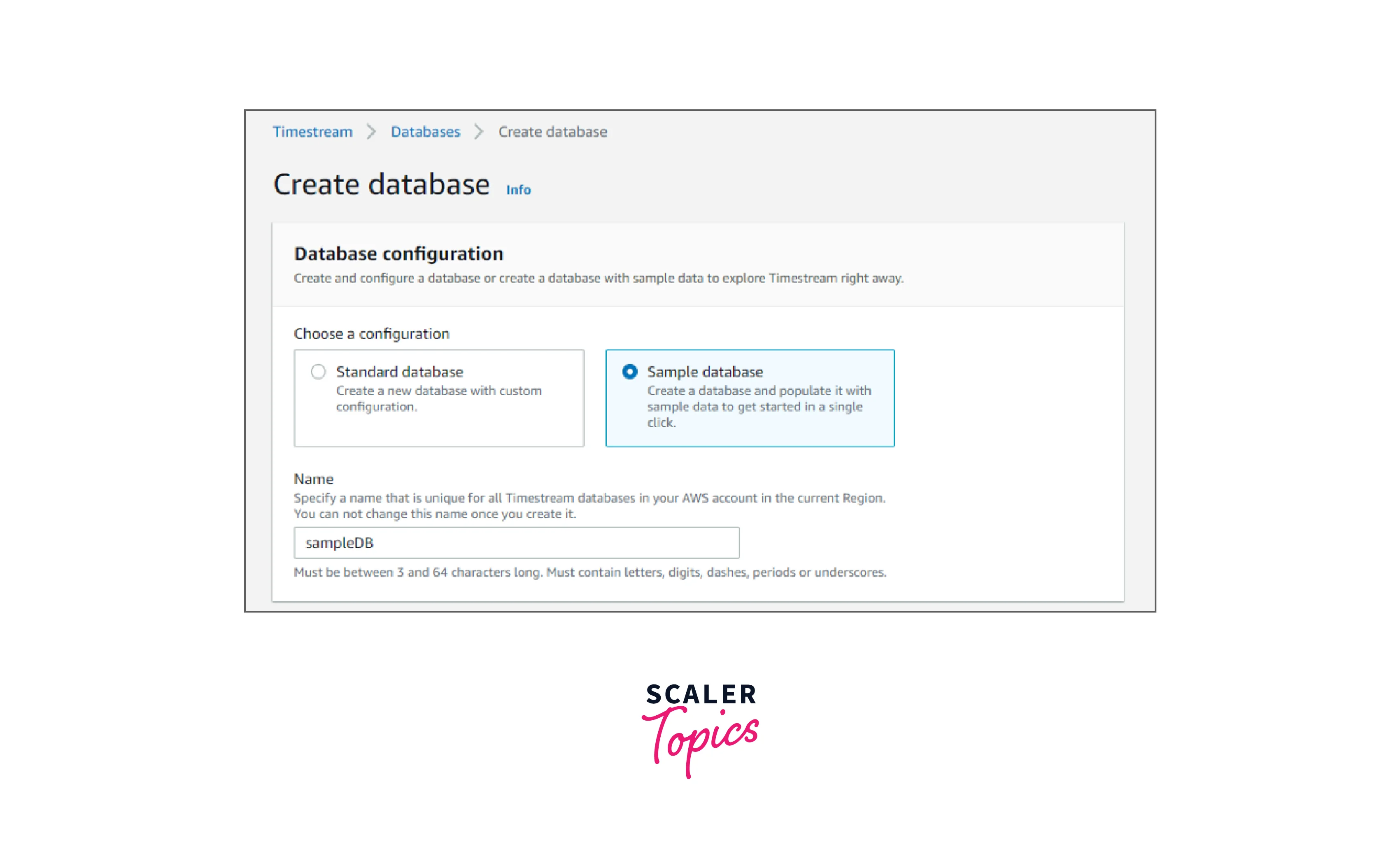
Step 2:
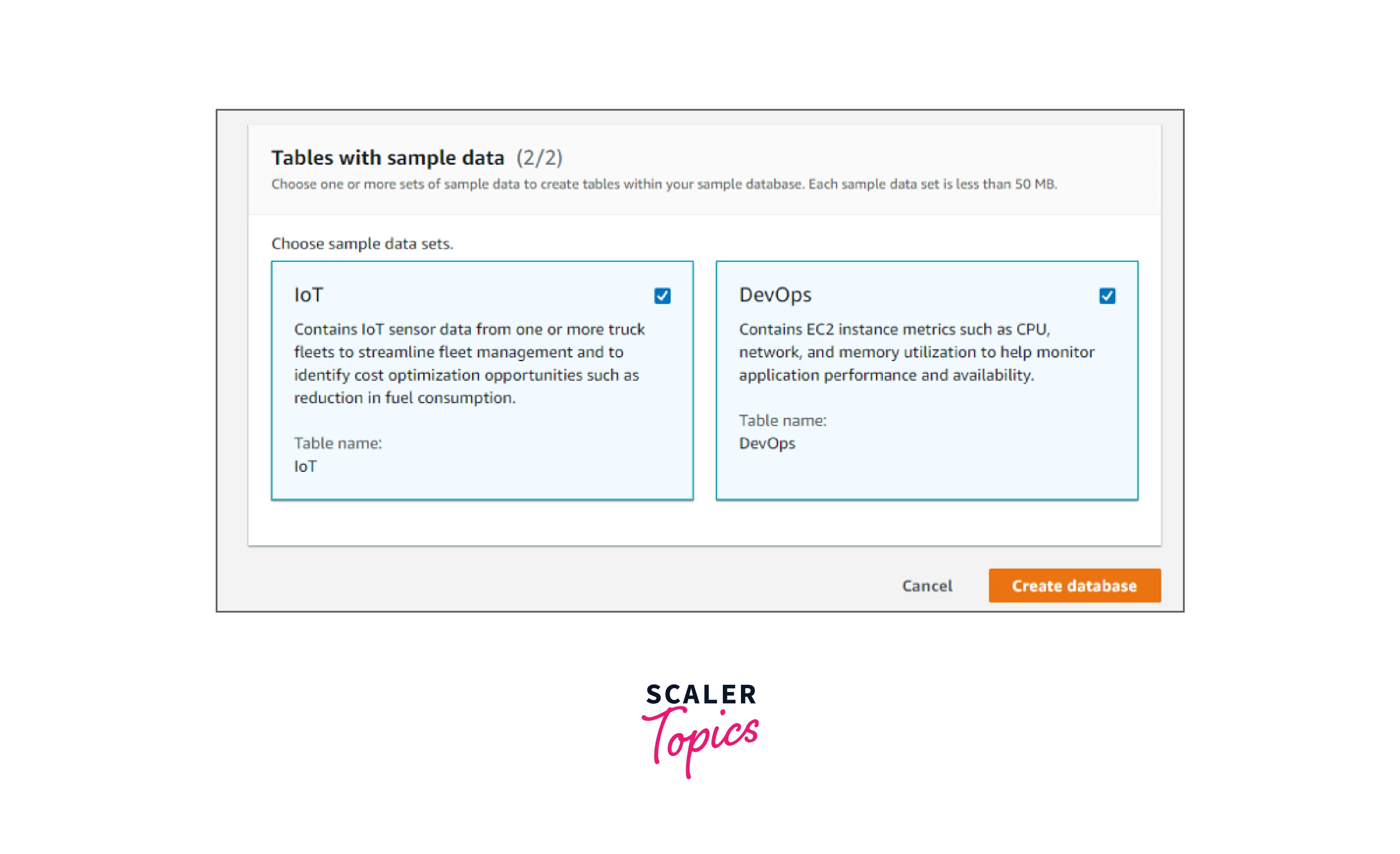
- Select either Standard Database or Sample Database as your database configuration; for now, let's choose Sample Database.
- In the Name field, give your new database a name.
- If you had selected the Sample Database, choose the sample data sets of your choice as either IoT, DevOps, or both, then hit on Create Database.
Step 3:
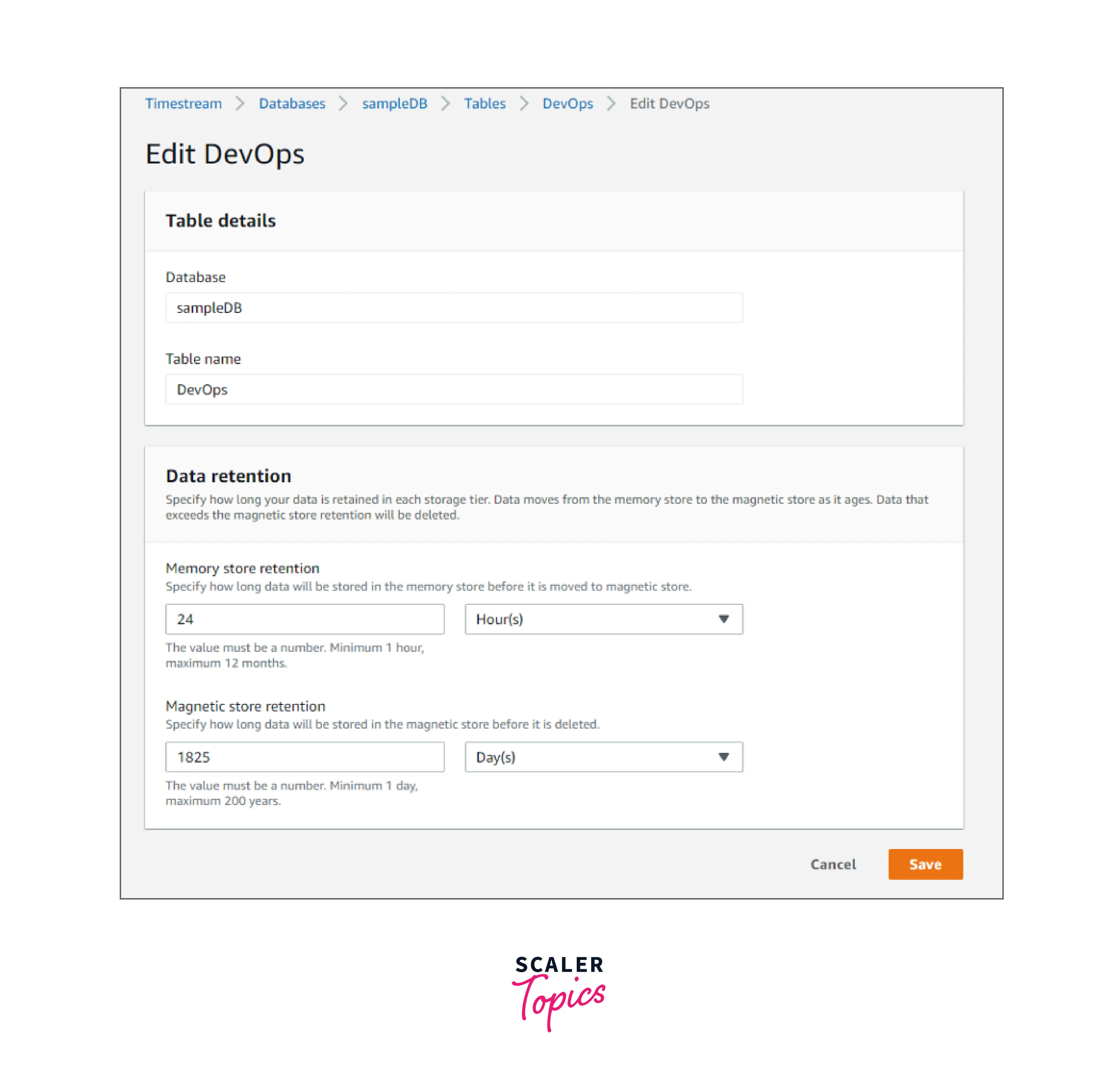
- Under the Databases tab, select your database.
- Choose either the DevOps or IoT tables from the Tables Tab to get the appropriate table.
- You will be able to view the table's Summary details. Click the Edit button in the top right corner if you want to edit it.
- Change the information as necessary.
- Carefully consider the memory store retention and magnetic store retention duration since once these times have passed, the data is destroyed from the storage.
- Save the changes.
Step 4:
- From the left tab, choose the Query Editor.
- There are countless queries you can run on your data.
- From the top tab, choose Sample Queries. You have access to many pre-defined searches here.
- Below is a sample query for the IoT table to get a list of all the sensor attributes and values being monitored for each truck in the fleet.
- We run the below query in the Query Editor to get the desired output.
Step 5:
- Select Monitoring from the left-hand tab.
- Numerous graphs and other visual representations of your data analysis are available here.
Benefits and Limitations of AWS Timestream
Benefits of AWS Timestream
- High efficiency at a low price: With query performance up to 1,000 times faster and costs as little as one-tenth the price of relational databases, Timestream is meant to provide interactive and inexpensive real-time analytics.
- Serverless with auto-scaling: Because it is serverless, you don't need to worry about managing servers or allocating resources; instead, you can concentrate on creating your apps.
- Data lifecycle management: The demanding job of managing data throughout its lifecycle is made simpler. There is storage tiering, with a magnetic store for older data and a memory store for more recent data.
- Access to data made easier: Thanks to Amazon Timestream, you no longer need many tools to access recent and historical data.
- Purpose-built for time series: Time series data can be quickly evaluated because of SQL's built-in smoothing, approximation, and interpolation procedures.
- Always Encrypted: You can also provide an AWS KMS Customer-Managed Key (CMK) to Amazon Timestream to encrypt data in the magnetic store.
Limitations of AWS Timestream
- Currently, the service only provides coverage for seven different regions including US East (N. Virginia), US East (Ohio), US West (Oregon), EU (Ireland), EU(Frankfurt), Asia Pacific(Sydney), and Asia Pacific(Tokyo).
- Although it supports ANSI-2003 SQL, cross-table joins are not supported. However, you may utilize joins across CTEs based on the same table.
- The tables in Timestream are append-only, which means no deletes or modifications are allowed, unlike relational databases.
TimescaleDB vs AWS Timestream
Amazon Timestream and TimescaleDB can be categorized as Databases tools. We will contrast TimescaleDB to Amazon Timestream on the following criteria:
- Insert and Query Performance
Depending on the kind of query, TimescaleDB outperforms AWS Timestream by 5–175 times for queries and by 6000 times for inserts. Remarkably, there were workloads and query types that Amazon Timestream could not handle but was readily supported by TimescaleDB.
- Cost for Equivalent Workloads
Fully-managed TimescaleDB was discovered to be 154x less expensive than Amazon Timestream for identical workloads (224x less costly if you're self-managing TimescaleDB on a VM) and to insert twice as many metrics.
- Query language, Ecosystem, and Ease-of-use
Amazon Timestream does not support joins between tables and normalized datasets because it is not a relational database. Deriving value from your data also heavily relies on CASE statements and Common Table Expressions (CTEs) when requesting multiple measurement values, which can result in some complicated queries because Amazon Timestream enforces a particular narrow table model on your data.
On the other hand, TimescaleDB completely embraced the SQL language and enhanced it with methods explicitly designed to simplify the time-series analysis. In addition to storing time-series data and metadata, TimescaleDB is a relational database that enables developers to join across tables as needed. Because of this, TimescaleDB has a low learning curve for new users and gives them complete flexibility over how they query their data.
- Cloud Offering
Amazon Timestream is only accessible as a serverless cloud service on Amazon Web Services. It is currently accessible in three U.S. regions, two EU regions, and two Asia Pacific regions.
On the other hand, TimescaleDB is available on AWS, GCP, and Azure, in over 75 regions, and in 2000 in different conceivable region/storage/compute configurations.
- Time Series Intelligence
Amazon Timestream supports Time Series Intelligence, while TimescaleDB does not support Time Series Intelligence. Time series intelligence software enables organizations to generate insights from raw time series data. Time series intelligence software, sometimes referred to as time series analytics software, provides features so data teams can analyze, visualize trends, forecast, and predict outcomes based on time series data.
Conclusion
- Amazon Timestream is a fast, scalable, and serverless time-series database. We learned about Timestream concepts including Time series, Dimension, Measure, Timestamp, etc. This article also explains how dimension works and the different measures in AWS Timestream.
- AWS Timestream helps provide higher efficiency at a lower price. Also, we learned that AWS Timestream provides serverless auto-scaling at much ease.
- Although with various valuable benefits and real-life use cases, we learned that AWS Timestream also has limitations. The fundamental rule includes that it does not support cross-table joins and it is only available in limited AWS regions.
- Ultimately, we pointed out the differences between AWS Timestream and Amazon TimescaleDB. The differences were based on Performance, Cost, Cloud offering, Query language, Ecosystem, Ease of use, and Time-series intelligence.