Caching Strategies
Overview
A cache is a high-speed data storage layer used in computing that temporarily stores certain data so that requests for it later on can be satisfied more rapidly than by querying the data's primary storage location. Data that has already been retrieved or calculated can be reused more effectively, thanks to caching.
Typically, cache data is kept in RAM or other fast-access hardware. By minimizing the need to contact the lower storage layer beneath, a cache primarily serves to increase the performance of data retrieval. To enable quicker access to files, caching is a technique that involves keeping copies of the files in a cache or other temporary storage site.
How to Apply Caching?
The data in a cache may be used in combination with a computer program, although it is frequently stored in fast equipment like RAM (Random-access memory). By reducing access to the slower storage tier below, a cache primarily aims to boost data recovery performance.
Trading off capacity for speed, a cache typically stores a subset of data transiently, in contrast to databases whose data is usually complete and durable.
What are Some Common Caching Strategies Used in AWS?
Even while caching is a generic idea, some forms stand out above the rest. They are essential and cannot be overlooked if developers want to comprehend the most popular caching strategies.
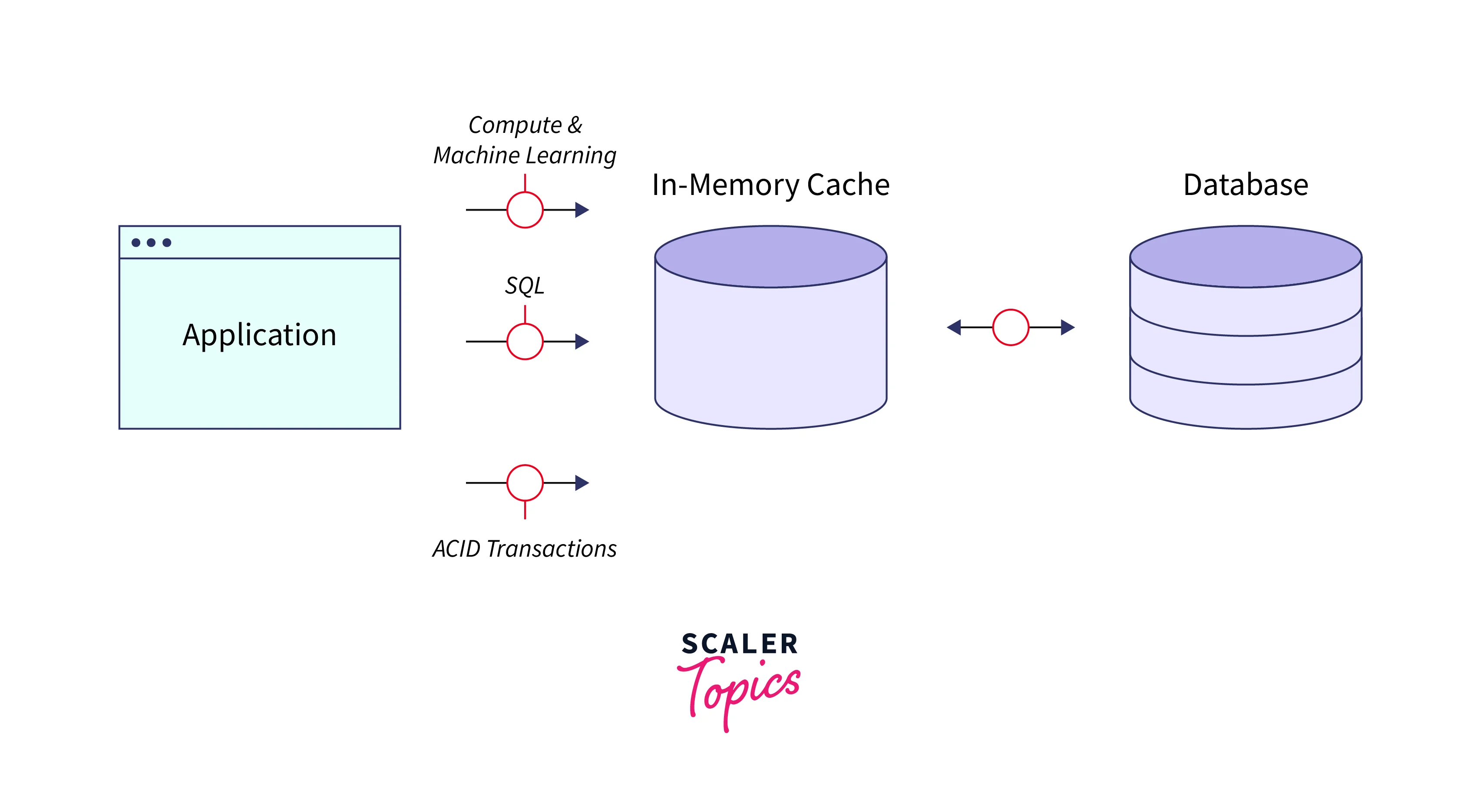
In-Memory Caching
-
This method stores cached data directly in RAM, which is faster than the traditional storage system where the original data is kept. Key-value databases are the foundation for the most widespread application of this kind of caching.
-
The most common implementation of this type of caching is based on key-value databases. They can be seen as sets of key-value pairs. The key is represented by a unique ID, while the value is represented by the cached data.
-
Essentially, this means that each piece of data is identified by a unique key. By specifying this key, the key-value database will return the associated value.
-
Such a method is quick, effective, and simple to comprehend. This is why developers who are attempting to create a cache layer typically choose this method.
Database Caching
- Every database often includes some form of caching. In particular, an internal cache is typically utilized to prevent making too many database queries. The database can quickly provide previously queried data by caching the results of the most recent queries run.
- In this manner, the database can delay running queries during the duration that the requested cached data is valid. Although every database has a unique way of doing this, the most common method relies on employing a hash table to store key-value pairs.
- As was previously demonstrated, the value is looked up using the key. Note that ORM (Object Relational Mapping) solutions typically include this form of caching by default.
Web Caching
There are two further subcategories that fall under this:
-
Web Client Caching:
Most Internet users are accustomed to this kind of cache, which is kept on clients. It is also known as web browser caching because it typically comes with browsers. In most cases, this is way faster than downloading through the network. -
Web Server Caching:
This system is designed to store resources on the server side for later usage. Particularly when dealing with continuously generated content, which requires time to create, such a strategy is beneficial. On the other hand, it is useless for static content. Web server caching reduces the effort required and speeds up page delivery by preventing servers from becoming overloaded.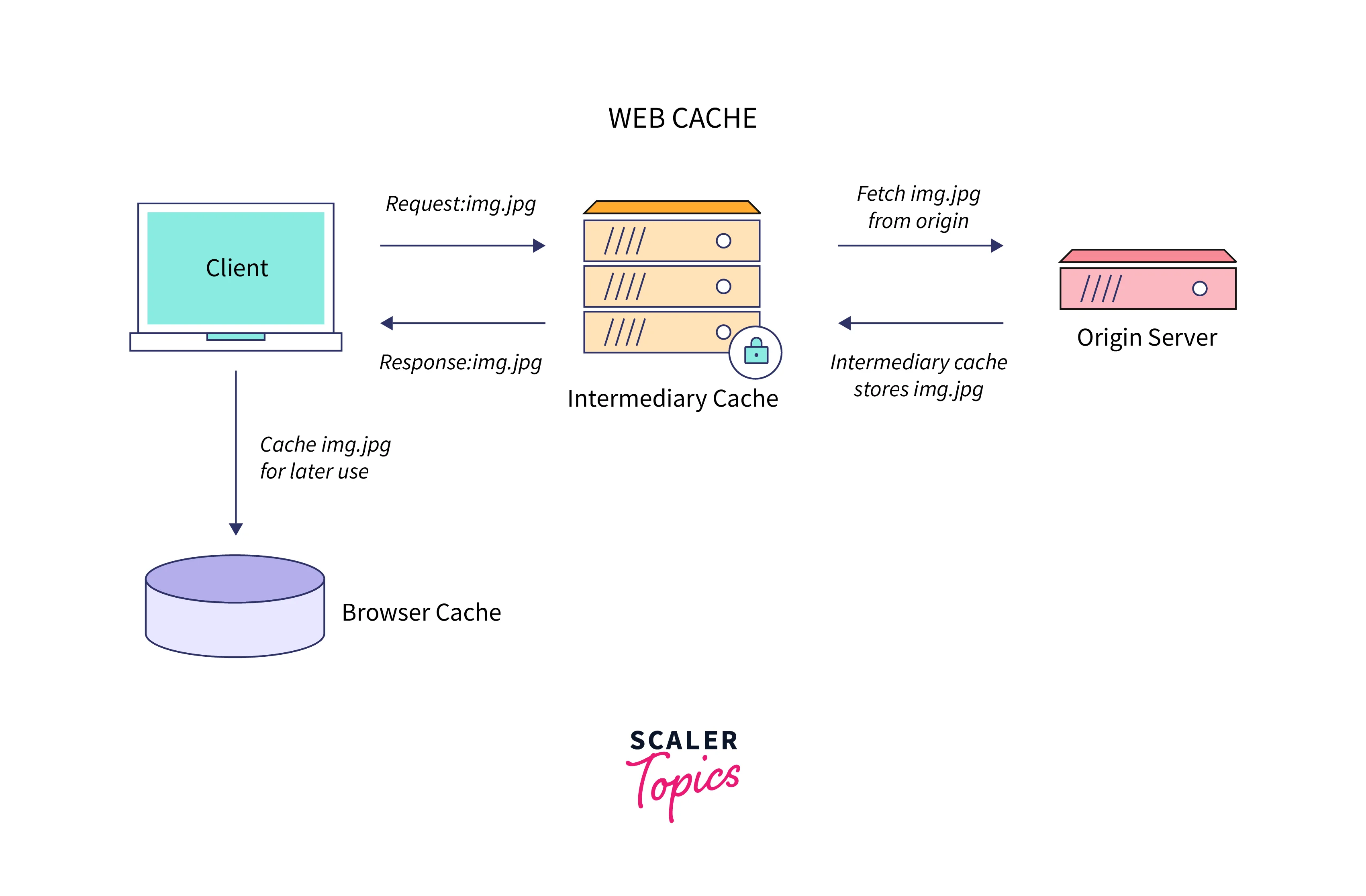
CDN Caching
- The term "Content Delivery Network" refers to a system for caching media files, stylesheets, and web pages in proxy servers. Between the user and the origin server, it functions as a system of gateways that stores its resources.
- A proxy server intercepts requests for resources when a user makes one and determines if it has a copy. If so, the user receives the resource right away; if not, the request is sent back to the origin server.
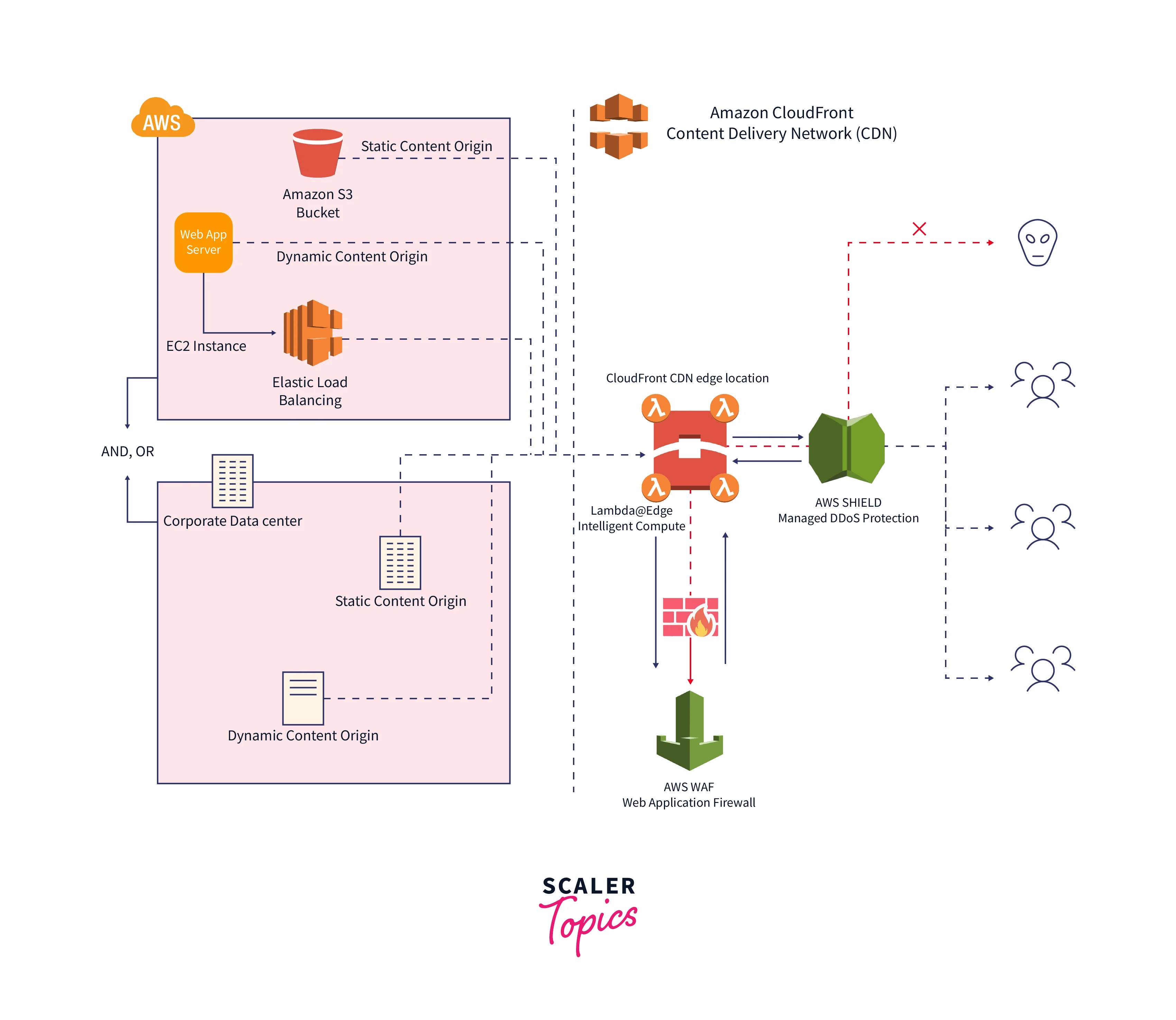
- User queries are dynamically routed to the closest of these proxy servers, which are dispersed throughout the world.
Lazy Loading
Data is only loaded into the cache using the lazy loading caching approach when it is actually needed. It functions as explained below.
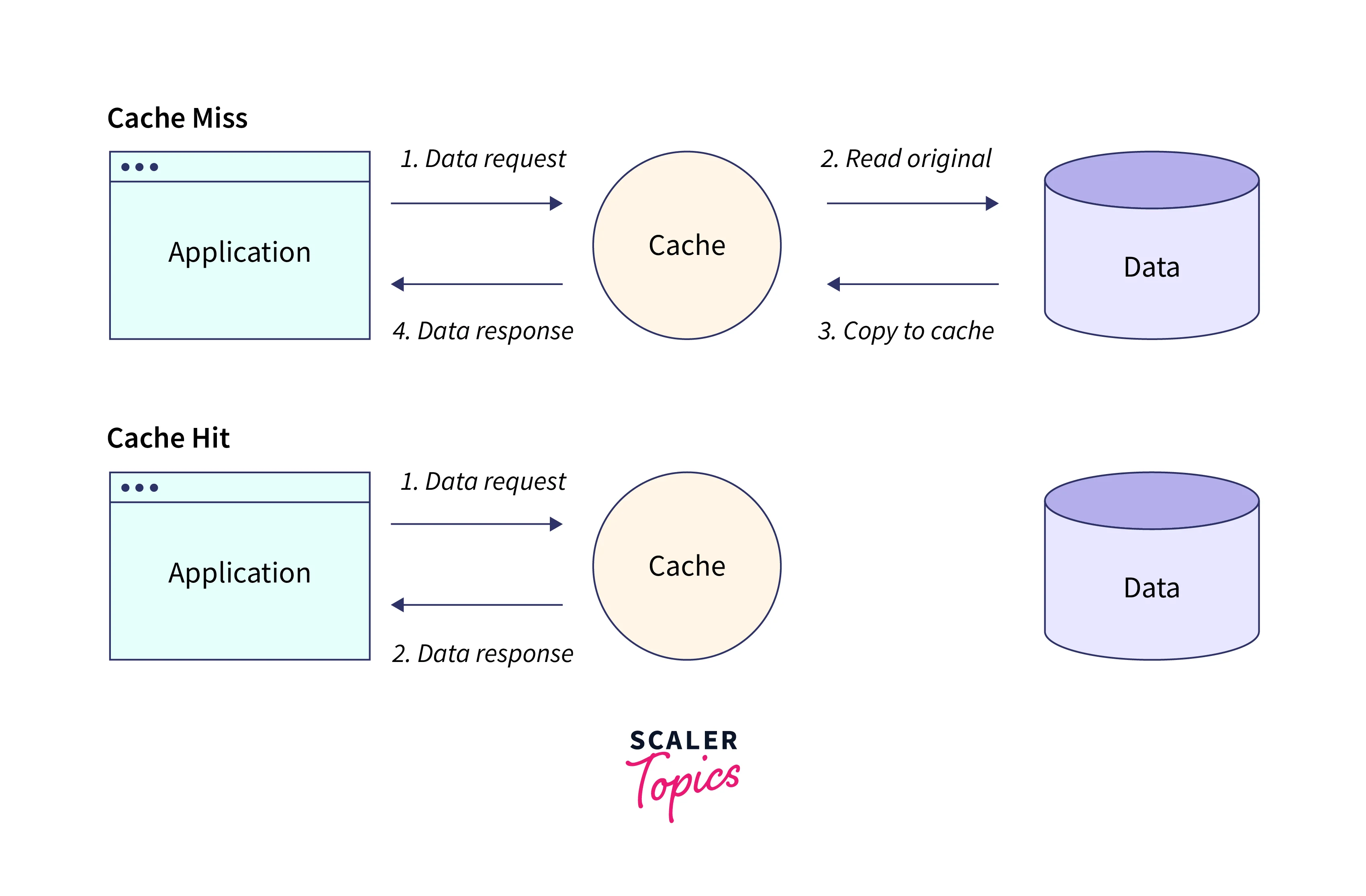
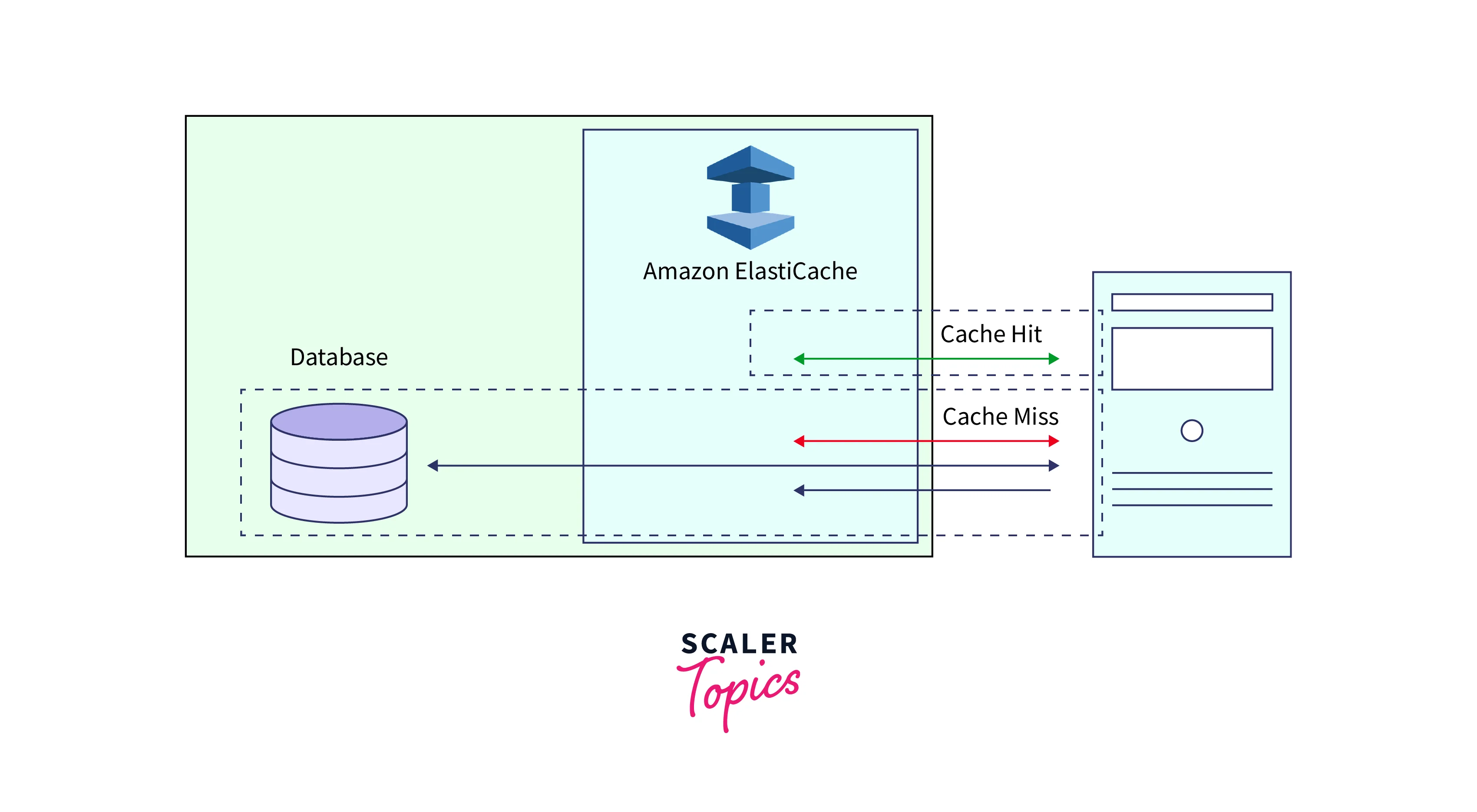
An in-memory key-value store called Amazon ElastiCache lies between your application and the data store (database) it uses. Your application first checks the ElastiCache cache whenever it requests data. ElastiCache provides the data to your application if it is current and already stored in the cache. Your application asks the data from your data store if it is missing from the cache or has expired. The data is then returned to your application by your data storage. The data obtained from the store is then written to the cache by your application. When it is requested again, it can be obtained more quickly in this method.
Application Flow
If the content is in the cache and hasn't expired, a cache hit happens:
- Data from the cache is requested by your application.
- The application receives the data from the cache.
When data is either out of date or not in the cache, a cache miss occurs:
- Data from the cache is requested by your application.
- A null is returned because the cache does not contain the requested data.
- The data is obtained by your application by making a request to the database.
- The new data is added to the cache by your application.
Advantages
Lazy loading has the following benefits:
- The cache only contains requested data. Lazy loading prevents the cache from being overfilled with unnecessary data because the majority of data is never requested.
- Node failures won't render your application unusable.
- Your application keeps running even when a node fails and is replaced by a new, empty node, albeit with more latency. Each cache miss causes a database query when requests are sent to the new node. In order for upcoming requests to be fulfilled from the cache, the data copy is simultaneously added to the cache.
Disadvantages
- There is a penalty for cache misses. Three trips are required for each cache miss:
- Initial data request from the cache
- Searching the database for the information
- Adding the information to the cache Data delivery to the application maybe noticeably delayed as a result of these misses.
- Stale Data:
If information is only written to the cache when there is a cache miss, the cache's data may eventually become out of date. As a result, when data is altered in the database, there are no changes made to the cache. The Write-through and Adding TTL methods can be applied to resolve this problem.
Pseudocode
An illustration of lazy loading logic in pseudocode is provided below.
The application code for this example that retrieves the data is as follows:
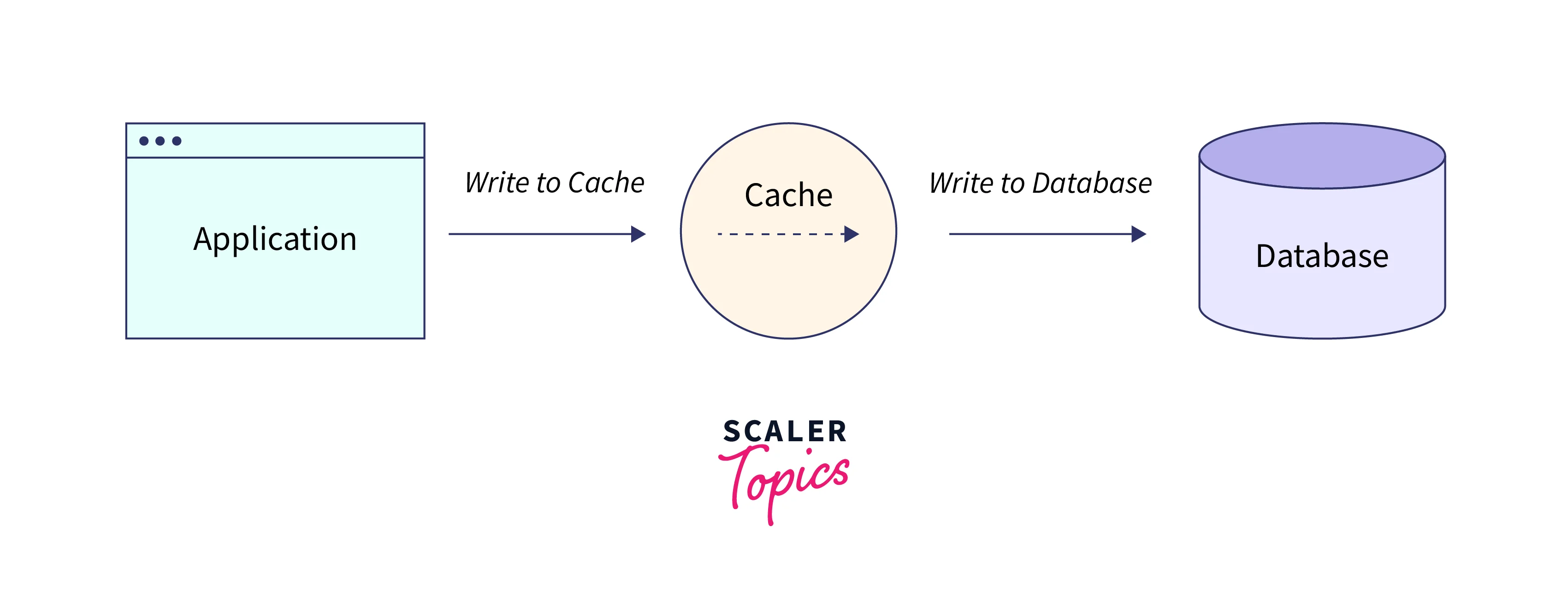
Write-Through
Every time information is posted to the database, the write-through strategy updates or adds information to the cache.
Application Flow
With this plan, data is simultaneously written to the respective database and cache. Fast retrieval is guaranteed by the cache, and since data is simultaneously written to the primary data store and the cache, there is total consistency.
There is extra latency, though, because every write operation must be performed twice.
Advantages
The following are some benefits of write-through:
- The cache never contains stale data. The information in the cache is always up to date because it is updated each time information is added to the database.
- Read penalty versus write penalty
Every write requires two journeys:
- The cache is updated
- Updating the database This causes the process to lag. Nevertheless, end users can tolerate latency better when updating data than when retrieving it. There is an underlying impression that updates are more work and so take longer.
Disadvantages
- Missing Data:
There are data gaps if a new node is spun up, whether through scaling out or node failure. Until this information is added to or changed in the database, it remains absent in the new node. By using write-through and lazy loading, you can reduce this. - Cache Churn:
Resources are wasted since the majority of data is never read. It is possible to reduce unused space by including a time to live (TTL) value.
Pseudocode
Here is an illustration of write-through logic using pseudocode.
The application code for this example that retrieves the data is as follows:
Time-To-Live
Time to live (TTL) is a numeric value that indicates how long the key will be valid. This number is specified by Memcached in seconds. An application is regarded as if the key had not been found while attempting to read an expired key. The cache is refreshed after the database is searched for the key. This method does not ensure that a value is current. However, it prevents data from becoming too stale and necessitates periodic database refreshment of the cached values.
Application Flow
The time to live (TTL) or hop limit refers to how many hops a packet can make before the network discards it. TTL values serve as a guide for packets' maximum range.
- An eight-bit element in the packet header, set by the sender host, contains the initial TTL value.
- Each router in the path to the destination reduces the TTL field of the datagram after the sender sets it.
- Whenever the router forwards IP packets, the TTL value is decreased by at least one.
- The router discards the packet when its TTL value reaches 0 and instead sends an ICMP message back to the source host.
- This technique prevents packets from endlessly looping by ensuring that they are dropped after a certain amount of time.
- The TTL number serves to limit the amount of time that data can stay on the network. Finding out how long the data has been on the network and how long it will be on the network is also helpful.
Advantages
- TTL limits how long data packets can travel across the network. TTL controls data caching and improves performance in applications.
- TTL is also applied in various situations, including DNS and content delivery network (CDN) caching.
Disadvantages
It does not ensure that a value is current and demands periodic database refreshment of cached entries.
Pseudocode
The pseudocode shown below demonstrates write-through logic using TTL.
The application code for this example that retrieves the data is as follows:
Caching Best Practices
- Understanding the reliability of the data being cached is crucial when constructing a cache layer. High hit rates signify a successful cache since they show that the requested data was available.
- When the data requested is not in the cache, it is known as a cache miss. The data can be properly expired by applying controls like TTLs (Time to live). The demand for a highly available cache environment, which can be met by in-memory engines like Redis, may be another factor to take into account.
- In some circumstances, as opposed to caching data from a primary location, an in-memory layer can be employed as a stand-alone data storage layer.
- In order to assess whether this situation is appropriate, it's critical to define an appropriate RTO (Recovery Time Objective—the amount of time it takes to recover from an outage) and RPO (Recovery Point Objective—the last point or transaction captured in the recovery) on the data stored in the in-memory engine.
- The majority of RTO and RPO requirements can be satisfied by applying design methods and varied In-Memory engine features.
Conclusion
- We store frequently visited data in a temporary memory, quick access local storage called a cache. To reduce computational costs, increase throughput, and decrease the time it takes to retrieve frequently used application data, a technique called caching is implemented.
- The localization concept is the foundation of cache. Data that is regularly accessed is maintained close to the system.
- There are two possible outcomes when a system receives a request. A cache hit occurs when a copy of the data is present in the cache; a cache miss occurs when the data must be retrieved from the main data store.
- The four common methods of caching are In-memory Caching, Web Caching, CDN Caching, and Database Caching.
- The way that data is put into (and removed from) cache memory is determined by a set of rules called a cache policy. Since a cache is a temporary storage because it is made up of copies of data, we must choose when to write to the cache and when to the main data store.
- Time to live (TTL) is a numeric value that indicates how long the key will be valid. This number is specified by Memcached in seconds.
- Data is only loaded into the cache using the lazy loading caching approach when it is actually needed.
- Every time information is posted to the database, the write-through strategy updates or adds information to the cache.