DynamoDB Autoscaling in AWS
Overview
Take a social networking app as an illustration, where the majority of users are present throughout the afternoon. However, there is no requirement for the same amounts of throughput at night. Take a look at a fresh game app for mobile devices as another illustration, which is gaining popularity surprisingly quickly. The available database resources may be exceeded if the game gets too popular, which would slow down performance and result in disgruntled users. In order to adjust database resources for fluctuating consumption levels during these types of workloads, manual intervention is frequently necessary.
Introduction To DynamoDB Autoscaling
In order to automatically alter provided throughput capacity on your behalf in response to actual traffic patterns, Amazon DynamoDB auto scaling makes use of the AWS Application Auto Scaling service. In order to accommodate unexpected surges in traffic without throttling, a table or global secondary index might enhance the read and write capacity of the data it is provided with. Application Auto Scaling reduces throughput as the workload goes down so that you won't be charged for unused provided capacity. Some of the important points to note are:
- You may develop a scaling strategy for a table or a global secondary index using the Application Auto Scaling. The scaling policy provides the minimum and maximum provided capacity unit values for the table or index, as well as whether you wish to scale read capacity or write capacity (or both).
- You may define the read and write capacity auto-scaling target utilization values between 20 and 90 percent.
- Global secondary indexes are supported by DynamoDB - auto-scaling in addition to tables. Each global secondary index has a provided throughput capacity that is distinct from the base tables.
- Application Auto Scaling modifies the supplied throughput parameters for the index when you construct a scaling strategy for a global secondary index to make sure that its real utilization remains at or close to your target utilization ratio.
- DynamoDB Auto Scaling employs the AWS Application Auto Scaling service, which employs a target tracking mechanism to change the provided throughput of DynamoDB tables/indices upward or decrease in response to the actual workload.
- After you've enabled DynamoDB Auto Scaling, all you need to do is provide the desired goal utilization and upper and lower boundaries for read and write capacity. The functionality will then use AWS CloudWatch to monitor throughput use and modify supplied capacity as needed.
How Does DynamoDB Autoscaling Work?
A high-level overview of how DynamoDB auto scaling controls a table's throughput capacity can be found in the following diagram.
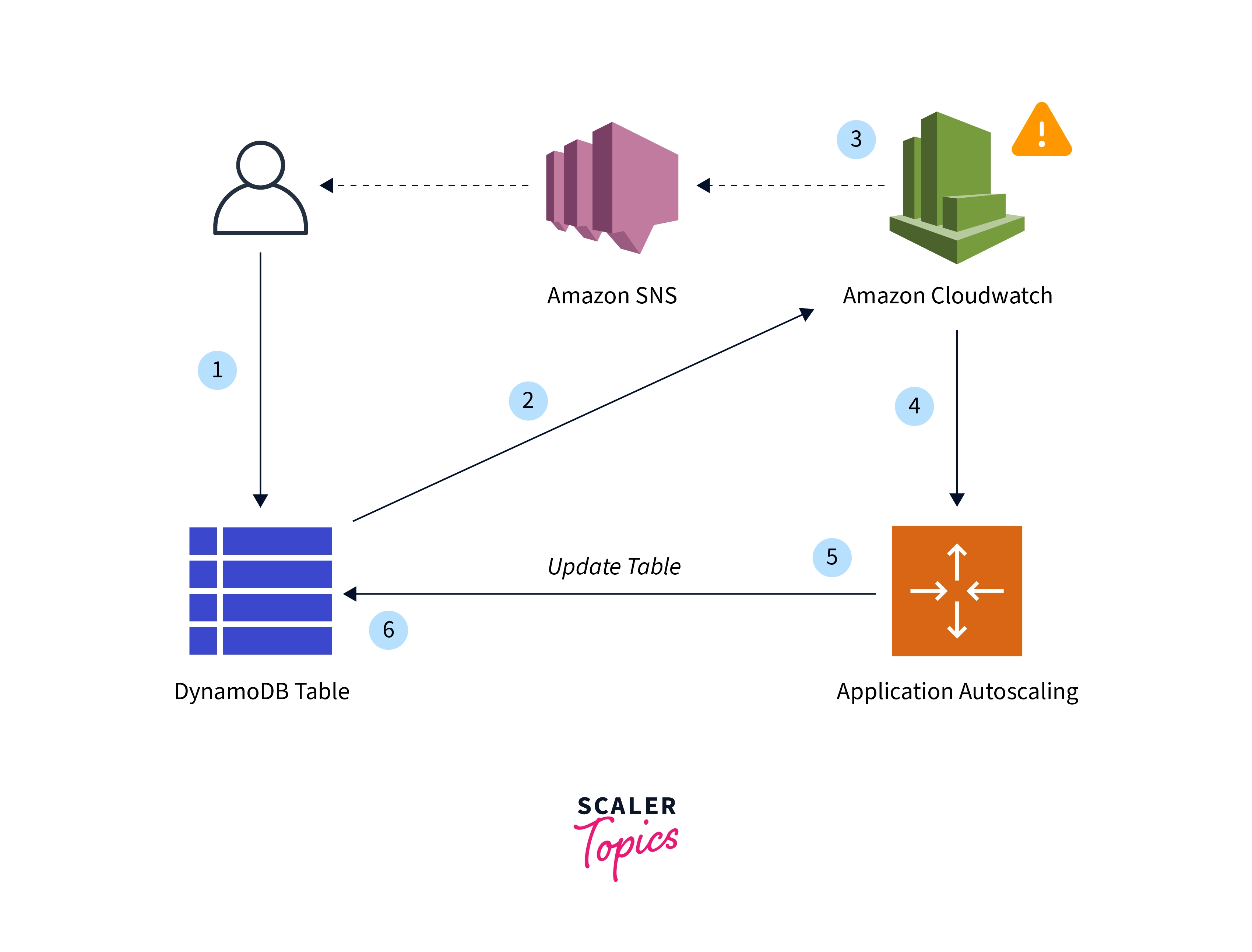
The Auto-Scaling Procedure As Represented In The Prior Figure May Be Summed Up By The Stages Below:
- For your DynamoDB table, you build an Application Auto Scaling policy.
- Metrics on utilized capacity are published by DynamoDB to Amazon CloudWatch
- When the table's used capacity goes over (or below) your desired level of usage for a certain period of time, Amazon CloudWatch issues an alarm. Using the Amazon Simple Notification Service, you may view the alarm on the console and get notifications (Amazon SNS).
- The Application Auto Scaling feature is activated by the CloudWatch alarm to assess your scaling policy.
- To modify the provided throughput for your table, Application Auto Scaling sends a UpdateTable request.
- In order to get the table's allocated throughput capacity closer to your intended usage, DynamoDB performs the UpdateTable request.
You Must Define A Scaling Policy In Order To Enable DynamoDB Auto-Scaling For The ProductCatalog Table. The Following Is Detailed In This Policy:
- You wish to administer a table or a global secondary index.
- what kind of capacity to handle (read capacity or write capacity).
- The top and lower limits for the parameters for provided throughput.
- your intended usage.
It Is Important To Be Aware Of The Following When Utilizing DynamoDB Auto Scaling:
- According to your auto-scaling policy, DynamoDB auto scaling can boost read capacity or write capacity as often as necessary. As stated in Service, account, and table quotas in Amazon DynamoDB, every DynamoDB quota is still in place.
- You may still manually change the provided throughput parameters even while DynamoDB auto-scaling is in effect. There are no current CloudWatch alerts linked to DynamoDB auto scaling that are impacted by these human modifications.
- We strongly advise that you apply auto-scaling uniformly to any indexes that are part of a table that contains one or more global secondary indexes when you activate DynamoDB auto-scaling for that table. In addition to preventing throttling, this will assist guarantee improved performance for table writes and reads. If you choose to Apply identical settings to global secondary indexes in the AWS Management Console, auto-scaling will be enabled. For further details, read Enabling DynamoDB auto scaling on existing tables.
- Any related scalable targets, scaling policies, or CloudWatch alerts are not necessarily also removed when you delete a table or global table replica.
- Auto-scaling is not turned on when a GSI is created for an already-existing table. During the GSI construction, you will need to manually regulate the capacity. The GSI's auto-scaling will function normally after the backfill process is finished and it enters an active state.
Note:
- Application Auto Scaling generates a pair of Amazon CloudWatch alerts for you when you define a scaling policy. Your provided throughput parameters are represented by each pair as having upper and lower bounds. These CloudWatch alerts are set off when the table's real usage veers from the course and continues to do so for an extended length of time.
- You get notified via Amazon SNS when one of the CloudWatch alarms is set off (if you have enabled it). The Application Auto Scaling feature is then activated by the CloudWatch alarm, and it informs DynamoDB to change the provided capacity of the ProductCatalog table as necessary.
What Are The Types Of DynamoDB Autoscaling?
You may supply your DynamoDB tables in a variety of ways. The only available approach at first was to manually provide your tables' throughput. But it was difficult to scale this approach up or down in response to consumption or demand. An abrupt increase meant that your table wouldn't have enough throughput to deal with requests, and mistakes would happen. To grow your tables, you have to manually develop your own unique solution and utilize the AWS APIs. This added to your workload for a well-maintained database.
The Two Types Of Autoscaling Policies Are:
- With Provisioned Auto-Scaling, you could choose a goal utilization as well as a minimum and maximum provisioned capacity. AWS will then scale your table throughput up or down as necessary to try to reach the desired utilization. Even while this was excellent at handling gradual increases in database demand, the table could not scale in time for really quick spikes in load.
- You need not consider provisioning throughput while using On-demand Scaling. As opposed to this, your table will automatically scale in the background. Extreme load fluctuations are possible but are effortlessly managed by AWS. Additionally, this results in a modification to DynamoDB's pricing structure. You pay per read or write request when using on-demand scaling as opposed to paying for a specified throughput.
Provisioned With Auto-Scaling
How It Works?
Provisioned with Auto-Scaling considers a few options for both read and write capacity in order to optimize your table:
- Target Utilization - This is a percentage that DynamoDB will strive for your consumed table capacity to be this % of your overall table capacity. For example, if you set this to 70% and make 70 requests worth of supplied capacity, your table will strive for 100 allocated capacity.
- Minimum Provided Capacity - This is the smallest provisioned capacity that your table will allow. DynamoDB will not scale your table allocated capacity below this number.
- Maximum Provisioned Capacity - This is the maximum provisioned capacity that your table will allow. DynamoDB will not scale your table-allocated capacity over this number.
These figures relate to both the reading and writing capacities. You may also configure the write capacity to match the read capacity.

DynamoDB publishes the utilized table capacity to CloudWatch behind the scenes. CloudWatch will generate an alarm if the utilized capacity exceeds the policy for an extended period of time. This warning will trigger Application Auto Scaling, which will review the scaling strategy and send a UpdateTable request to DynamoDB to modify the throughput.
Limitations
- This method has a few shortcomings. It is crucial to note, however, that some of these constraints are not caused by Auto-Scaling, but rather by limitations in DynamoDB table capacity in general. These limits, however, may occur more frequently while utilizing Auto-Scaling.
- For starters, you may only reduce the capacity of your table four times each day. However, if no drop has occurred in the previous hour, an extra decline is permitted. This implies that if your traffic is very fluctuating, you may end up paying for more capacity than you use, which can be wasteful.
- Furthermore, Auto-Scaling does not restrict you from manually adjusting throughput. These manual modifications have no effect on current Auto-Scaling alerts. However, it is useful to know that it is feasible and that it has no effect on Auto-Scaling alerts.
- Finally, it is critical to understand that scaling operations do not occur quickly. It may take some time for the new scaling capacity to be supplied and available. This implies that if you suddenly receive a large number of requests, it may take some time for your capacity to scale up to match the additional demand. This means that Auto-Scaling is best suited for instances where traffic will steadily increase rather than experiencing unexpected spikes. However, it is critical to recognize that Auto-Scaling and changes to allocated capacity do not occur in real-time.
On-Demand Scaling
How It Works
On-Demand Scaling is a whole different mechanism for allocating table capacity. This new approach is quite similar to serverless technologies such as AWS Lambda and AWS API Gateway. AWS assumes the responsibility for determining how many servers/capacity to supply. The payment structure for DynamoDB is altered as a result of this. Instead of paying for a set amount of throughput, you pay for each request made to your table.
You May Enable This In JavaScript By Doing Something Like This:
The crucial component here is to set the BillingMode to PAY PER REQUEST.
When issuing an updateTable command, you may additionally change the BillingMode to PAY PER REQUEST:
Of course, you may also do all of these tasks using the AWS Console.
When you switch to On-Demand Scaling or Provisioned Capacity, all of your data will be preserved. It is not necessary to move or destroy your data. Everything is taken care of behind the scenes for you.
Limitations
- The fact that you can only switch from Provisioned Capacity to On-Demand Scaling once per day is perhaps the most significant constraint of On-Demand Scaling. Because this is a one-way constraint, you may potentially go from On-Demand Scaling to Provisioned Capacity as many times as you like.
- The DynamoDB throughput default quotas remain in effect. This is set to 40k read request units and 40k write request units by default. However, by contacting AWS support, you may simply seek a service quota increase.
- Finally, all indexes will employ On-Demand Scaling. You cannot mix and combine On-Demand Scaling and Provisioned Capacity for the table and its indexes.
Which To Use?
Remember that with Provisioned with Auto-Scaling, you are essentially paying for throughput 24 hours a day, seven days a week. On-Demand Scaling, on the other hand, requires you to pay for each request. This implies that for applications that are still in development or have minimal traffic, On-Demand Scaling may be more cost-effective than worrying about providing throughput. However, at scale, once you have a more consistent usage pattern, this may quickly alter.
Problems With The Current System And Ways To Make Improvements
AWS revealed the long-awaited auto-scaling capabilities for DynamoDB, however, we discovered that it takes too long to scale up and does not scale up aggressively enough since it is limited by utilizing spent capacity as a scaling measure rather than real request count. Auto-scaling DynamoDB is a prevalent issue for AWS customers:
Two Issues Are:
- The response time to scaling up is poor (10-15 minutes)
- It did not scale adequately to sustain the 70% usage level.
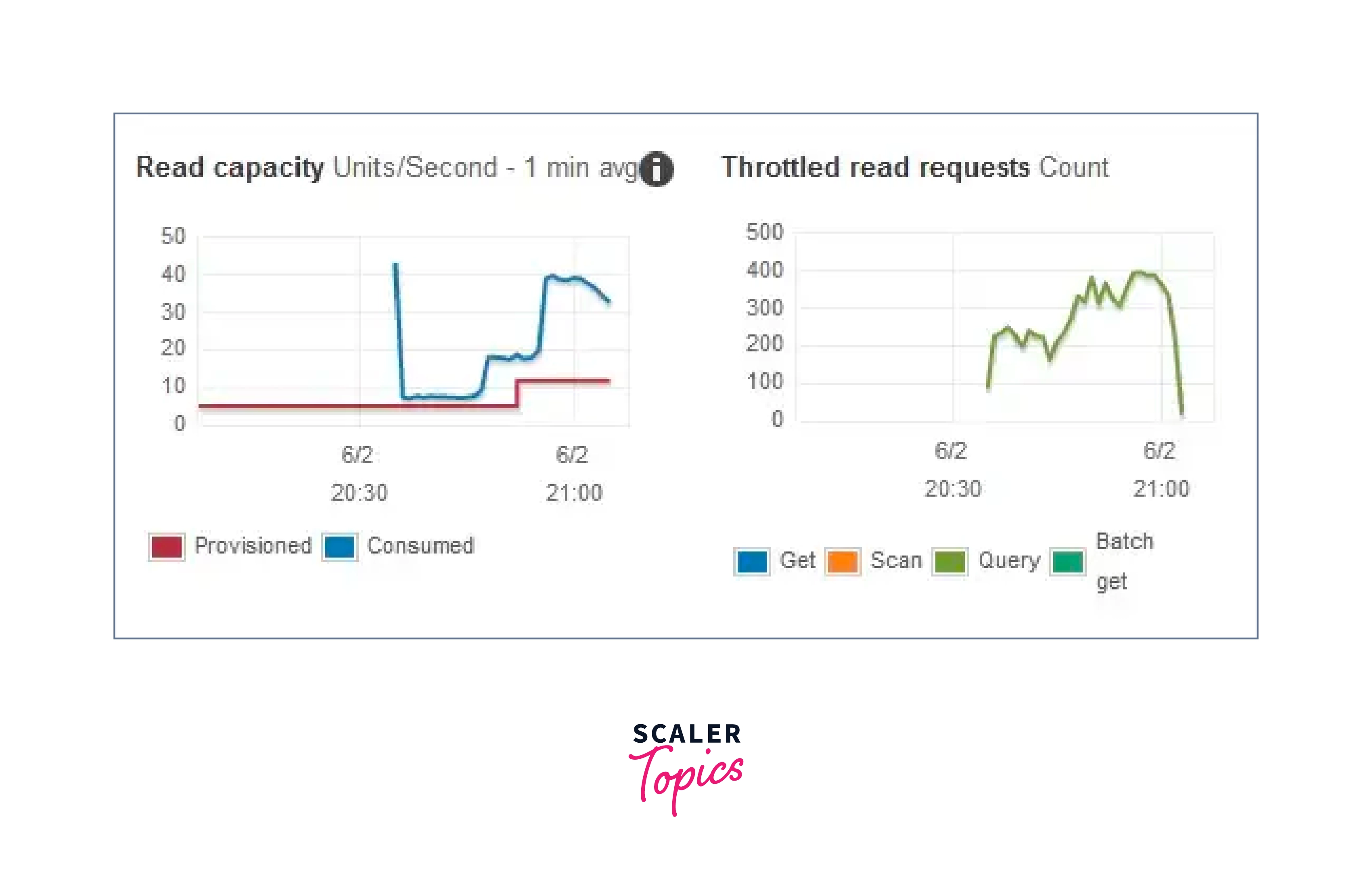
Despite the scaling activity, there is a substantial number of throttled activities. Would you have accepted this outcome if you were manually scaling the table? When you change the auto-scaling parameters for a table's read or write throughput, it automatically creates/updates CloudWatch alerts for that table — four for writes and four for reads. As seen in the picture below, DynamoDB auto scaling leverages CloudWatch alerts to initiate scaling operations. When the used capacity units exceed the utilization threshold on the table (which is set to 70% by default) for 5 minutes in a row, the associated supplied capacity units are scaled up.
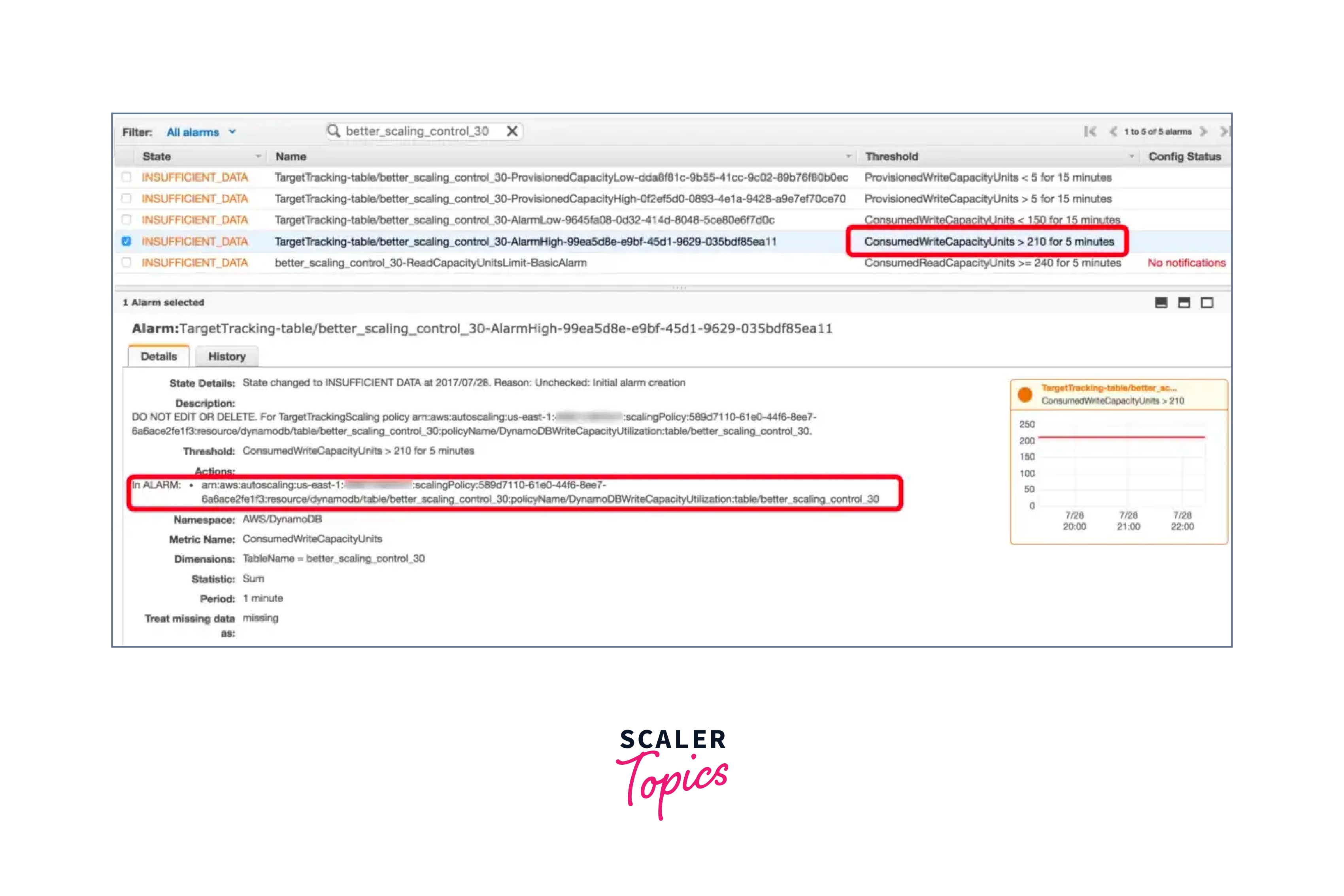
According To Our Tests, DynamoDB's Poor Scaling Performance Is Due To Two Issues:
- The CloudWatch alerts need 5 consecutive threshold violations. When you consider the delay in CloudWatch data (which is normally a few minutes behind), scaling actions can occur up to 10 minutes after the targeted utilization threshold is first breached. This reaction time is just too sluggish.
- Instead of the actual request count, the new supplied capacity unit is derived based on spent capacity units. Even while it is possible to briefly surpass the supplied capacity units using burst capacity, the spent capacity units are bound by the provisioned capacity units. This implies that once the stored burst capacity has been depleted, the real request count may begin to outrun the used capacity units, and scaling up may be unable to keep up with the growth in actual request count.
Based On These Data, We Suggest That The System May Be Improved In Two Ways:
- Scaling up should be triggered after one threshold violation rather than five, in keeping with the philosophy of "scale up early, scale down gently."
- Scaling activity is triggered based on real request count rather than spent capacity units, and new supplied capacity units are calculated based on actual request count as well.
As part of this investigation, we also prototyped these improvements (by hijacking the CloudWatch alarms) to illustrate their improvement.
Testing Methodology
- The most significant aspect of this test is the ability to generate the necessary traffic patterns in a consistent and reproducible manner.
- To do this, we create a recursive function that will send BatchWrite requests to the DynamoDB table under test every second. The items per the second rate are determined depending on the elapsed time (t) in seconds, allowing us to build the traffic pattern we choose.
Given that a Lambda function may only execute for 5 minutes if context.getRemainingTimeInMillis() is less than 2000, the function will recurse and provide the most recently recorded elapsed time (t) in the payload for the next execution. As a result, the traffic pattern depicted below is continuous and smooth.
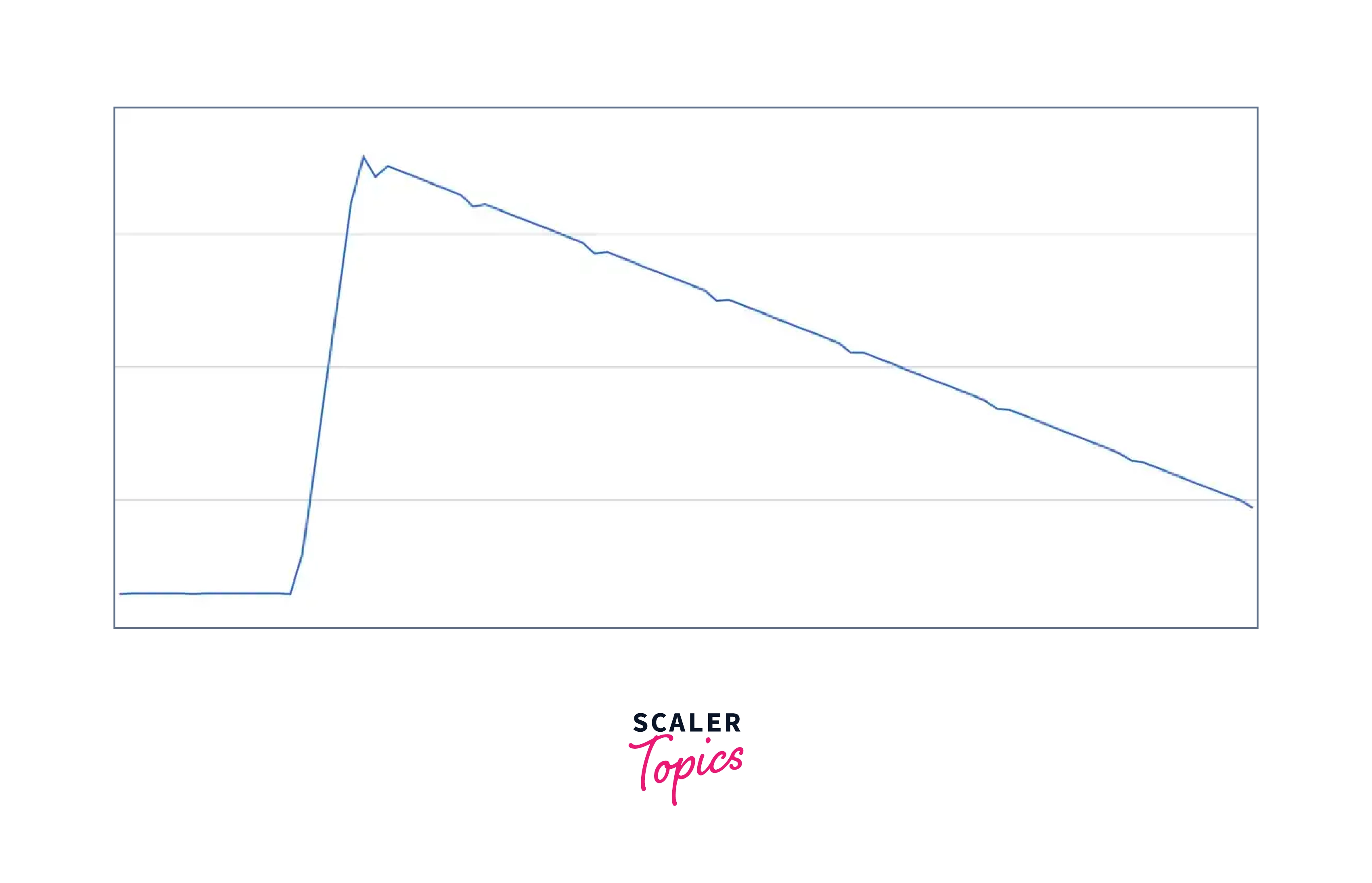
The Bell Curve Most people should recognize this traffic pattern: a slow and steady growth of traffic from the trough to the peak, followed by a rapid drop-off when users go to sleep. The next day, after a period of continuous traffic during the night, things begin to build up again. The peak is generally around 3-4 am UK time for many of us whose user base is centered in the North American region — all the more reason we need DynamoDB Auto Scaling to do its job and not wake us up!
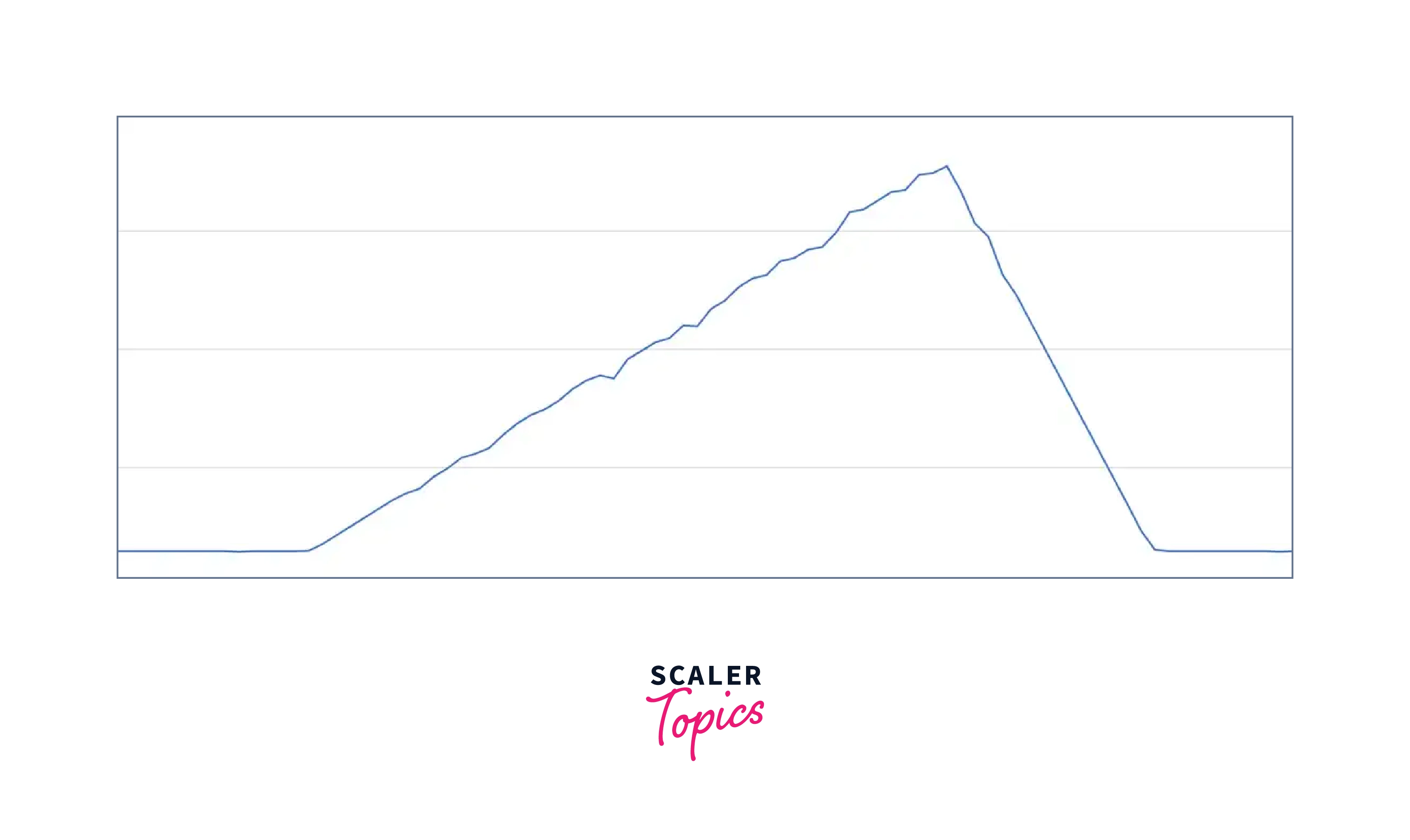
This traffic pattern is distinguished by the following characteristics: a) constant traffic at the trough, b) gradual and steady build-up to the peak, c) rapid drop off towards the trough, and repeat.
Top Heavy This rapid influx of traffic is generally caused by an event, such as a marketing campaign, an app store promotion, or, in our case, a scheduled LiveOps event. In most situations, these occurrences are predictable, and we use our automated tooling to scale up DynamoDB tables ahead of time. However, in the odd case of an unanticipated rush of traffic (which has occurred on a few occasions), a smart auto-scaling system should scale up fast and aggressively to minimize interruption to our players.
To understand how it handles certain traffic patterns, we ran them through multiple utilization level settings (the default is 70%). We measured the system's performance by:
- The percentage of successful requests (i.e. utilized capacity / total number of requests)
- During the test, the total number of throttled requests
The identical traffic patterns were then evaluated against the two hypothetical auto-scaling improvements we described above. We used CloudWatch events to hijack the CloudWatch alarms generated by DynamoDB auto-scaling in order to prototype the suggested improvements.
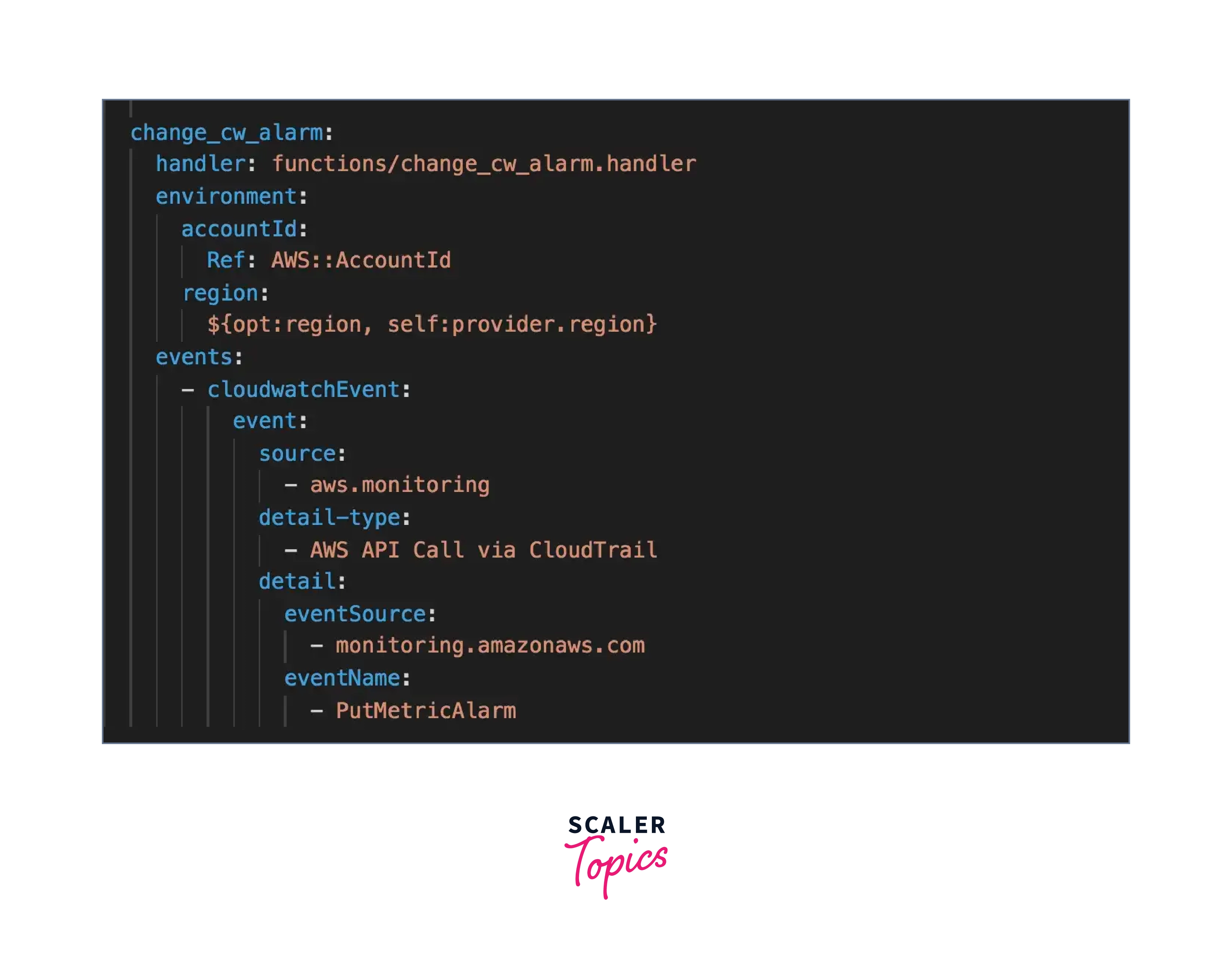
When you make a PutMetricAlarm API call, our change cw alarm function is called, which updates the current CloudWatch alarms with the required modifications — for example, setting the EvaluationPeriods to 1 minute for hypothesis 1.

The change cw alarm function set the breach threshold for CloudWatch alarms to 1 minute.
For hypothesis 2, we must assume responsibility for scaling up the table because we need to calculate the newly supplied capacity units using a custom measure that records the actual request count. As a result, the AlarmActions for the CloudWatch alarm are likewise overridden here.

Result (Bell Curve)- As follows is how the test is put up:
- 50 write capacity units are initially present on the table.
- 25 writes per second is the steady state for 15 minutes.
- Over the following 45 minutes, traffic steadily grows to reach peak level (300 writes/s).
- Over the course of the following 15 minutes, traffic steadily decreases to 25 writes/s.
- The rate of writing remains constant at 25 wpm.
Several Conclusions From These Findings:
- Write operations are never throttled at 30% to 50% utilization levels; this is what we want to see in production.
- Initially, writes were throttled at the 60% utilization level due to the delayed reaction time (issue 1) while the system adapted to the continuous rise in load, but it was finally able to adapt.
- Things started to go apart at utilization levels of 70% and 80%. As the system failed to adjust to the increased level of real utilization, the rise in the actual request count exceeded the growth in capacity units used. As a result, more and more write operations were throttled.
Results (Top Heavy) This is how the test is put up:
- 50 write units are initially available on the table.
- Traffic stays constant at 25 writes/s for 15 minutes.
- The following 5 minutes see a continuous increase in traffic until it reaches its highest level (300 writes/s).
- Then, traffic starts to slow down at a pace of 3 writes/s each minute.
Observations Based On The Findings Above Include:
- Most of the throttled writes at 30%–60% utilization levels can be attributable to the sluggish response time (problem 1). As the table became larger, the number of throttled writes rapidly reduced.
- Additionally, the system didn't scale up rapidly enough at 70% to 80% utilization levels (problem 2). As a result, we throttled writes for a longer period of time, which significantly reduced overall performance.
Conclusion
- When the real demand remains high or low for a prolonged period of several minutes, DynamoDB auto scaling just alters the supplied throughput parameters.
- In the long run, the Application Auto Scaling target tracking mechanism aims to maintain the goal utilization at or close to the figure you've selected.
- Autoscaling is just a robot managing capacity for you; it's not magic. However, the robot has two major issues: it can only increase capacity so quickly, and it has very little understanding of traffic patterns.
- Once DynamoDB Auto Scaling is activated, all that is left to do is provide the desired target utilization and read and write capacity upper and lower boundaries. The functionality will then use AWS CloudWatch to monitor throughput use and modify supplied capacity as necessary.
- The Amazon Command Line Interface (Amazon CLI) may be used to control Amazon DynamoDB auto scaling instead of the Amazon Web Services Management Console.
- It is crucial to remember that scaling activities take time to complete. The new scaling capacity may take some time to provision and become operational.
- Your allocated throughput capacity will be automatically adjusted on your behalf in response to actual traffic patterns using Amazon DynamoDB auto-scaling, which makes use of the AWS Application Auto Scaling service.