Integrations, Best Practices, Scalability
Overview
Amazon DynamoDB is now one of the most rapidly developing database services. However, it is a NoSQL database that necessitates data modeling in ways that SQL databases do not. As a company, you wouldn't want to spend more time and money on how your database architecture works in the backend when you might be focusing on innovation. DynamoDB does it all with the click of a button, which is a feature that enterprises and startups want for mission-critical applications and serverless computing. Amazon DynamoDB is an AWS-provided fully managed NoSQL database service. It is intended to automatically scale tables to accommodate for capacity while maintaining excellent performance with little management.
Integrating With Other AWS Services
The import and export features of Amazon DynamoDB offer a straightforward and effective method to move data between Amazon S3 and DynamoDB tables without writing any code. The import and export functionalities of DynamoDB allow you to relocate, change, and copy DynamoDB table accounts or AWS accounts. You may import from S3 sources and export DynamoDB table data to Amazon S3 to analyze your data and derive meaningful insights using AWS services such as Athena, Amazon SageMaker, and AWS Lake Formation. You may also import data straight into new DynamoDB tables to create new applications with single-digit millisecond speed at scale, make data sharing between tables and accounts easier, and simplify disaster recovery and business continuity strategies.
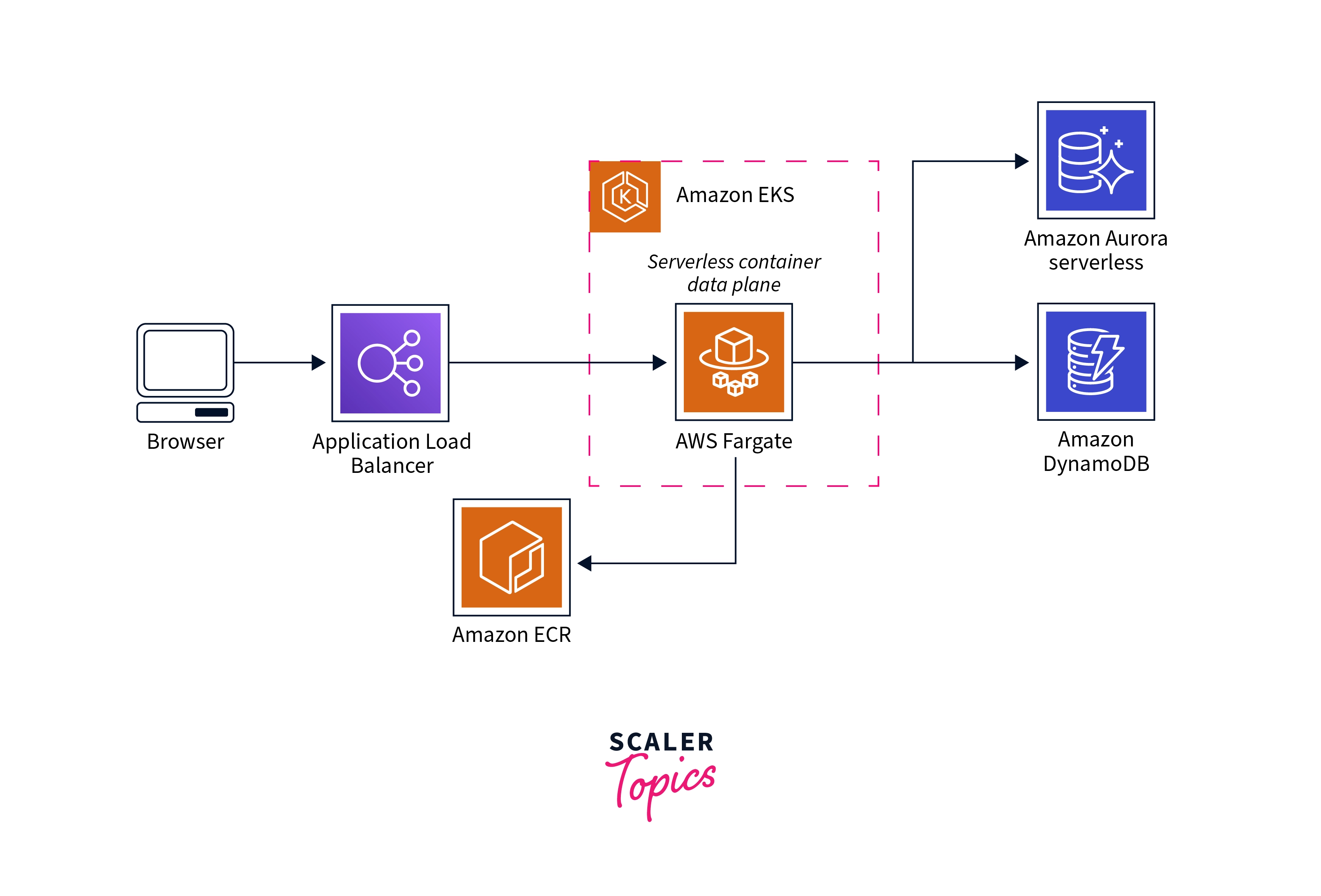
Integrating with Amazon Cognito
Amazon Cognito is the preferred method for obtaining AWS credentials for your online and mobile apps. Amazon Cognito assists you in avoiding hardcoding your AWS credentials in your files. It generates temporary credentials for your application's authorized and unauthenticated users by utilizing AWS Identity and Access Management (IAM) roles.
For example, to set up your JavaScript files to utilize an Amazon Cognito unauthenticated role to access the Amazon DynamoDB web service, perform the following.
To configure credentials for Amazon Cognito integration, follow these steps:
- Create an Amazon Cognito identity pool that accepts anonymous identities.
- Copy the following policy into a file called myCognitoPolicy.json. Replace the identity pool ID (us-west-2:12345678-1ab2-123a-1234-a12345ab12) with your own IdentityPoolId acquired in the previous step.
- Create an IAM role that assumes the previous policy. In this way, Amazon Cognito becomes a trusted entity that can assume the Cognito_DynamoPoolUnauth role.
- Attach a managed policy to provide the Cognito DynamoPoolUnauth role full access to DynamoDB (AmazonDynamoDBFullAccess).
- Obtain and copy the Amazon Resource Name for the IAM role (ARN).
- Add the Cognito DynamoPoolUnauth role to the DynamoPool identity pool. The syntax to use is KeyName=string, where KeyName is unauthenticated and the string is the role ARN collected in the previous step.
- In your files, provide the Amazon Cognito credentials. Change the IdentityPoolId and RoleArn as needed.
- You may now use Amazon Cognito credentials to run JavaScript applications against the DynamoDB web service.
Integrating with Amazon Redshift
Amazon Redshift provides extensive business intelligence capabilities and a robust SQL-based interface to Amazon DynamoDB. You may run advanced data analysis queries on data copied from a DynamoDB table into Amazon Redshift, including joins with other tables in your Amazon Redshift cluster after the data is in Amazon Redshift.
A copy transaction from a DynamoDB table counts against the table's read capacity in terms of provisioned throughput. Your SQL queries in Amazon Redshift after the data has been transferred do not affect DynamoDB. This is because your queries operate on a copy of DynamoDB's data rather than DynamoDB itself.
You must first construct an Amazon Redshift table to act as the data's destination before you can load data from a DynamoDB table. Keep in mind that you are moving data from a NoSQL environment to an SQL environment and that some restrictions apply to one but not to the other. Consider the following differences:
- Table names in DynamoDB can be up to 255 characters long, including '.' (dot) and '-' (dash) characters, and are case sensitive. Table names in Amazon Redshift are restricted to 127 characters, cannot include dots or dashes, and are not case-sensitive. Furthermore, table names must not contain any Amazon Redshift-restricted terms.
- The SQL notion of NULL is not supported by DynamoDB. In DynamoDB, you must specify how Amazon Redshift interprets empty or blank attribute values, interpreting them as NULLs or empty fields.
- The data types in DynamoDB do not immediately equate to those in Amazon Redshift. To handle the data from DynamoDB, you must verify that each column in the Amazon Redshift database is of the right data type and size.
An example COPY command from Amazon Redshift SQL is as follows:
The source table in DynamoDB in this case is my-favorite-movies-table. favoritemovies is the target table in Amazon Redshift. The read ratio 50 clause limits the proportion of provided throughput utilized; in this example, the COPY command will use no more than 50% of the read capacity units allocated to my-favorite-movies-table. We strongly advise that you set this ratio to be smaller than the average unused provisioned throughput.
Integrating with Amazon EMR
Amazon DynamoDB is connected with Apache Hive, an Amazon EMR-based data warehouse application. Hive can read and write data in DynamoDB tables, allowing you to do the following:
- Using an SQL-like language, query live DynamoDB data (HiveQL).
- Data may be copied from a DynamoDB table to an Amazon S3 bucket and vice versa.
- Data may be copied from a DynamoDB database to Hadoop Distributed File System (HDFS) and vice versa.
- Apply join operations on DynamoDB tables.
Amazon EMR is a service that enables rapid and cost-effective processing of massive volumes of data. To utilize Amazon EMR, you must first build a managed cluster of Amazon EC2 instances using the open-source Hadoop framework. Hadoop is a distributed program that uses the MapReduce algorithm to distribute tasks across numerous nodes in a cluster. Each node completes its assigned tasks in parallel with the other nodes. Finally, the outputs are combined on a single node to provide the final result.
You have the option of launching your Amazon EMR cluster as a persistent or transitory cluster:
- A persistent cluster remains active until it is terminated. Persistent clusters are useful for data processing, data warehouses, and other interactive applications.
- A transitory cluster runs for the duration of a workflow and then automatically shuts down. Transitory clusters are appropriate for jobs that need periodic processing, such as script execution.
Integrating with Amazon S3
The import and export features of Amazon DynamoDB offer a straightforward and effective method to move data between Amazon S3 and DynamoDB tables without writing any code.
The import and export functionalities of DynamoDB allow you to relocate, change, and copy DynamoDB table accounts or AWS accounts. You may import from S3 sources and export DynamoDB table data to Amazon S3 to analyze your data and derive meaningful insights using AWS services such as Athena, Amazon SageMaker, and AWS Lake Formation. You may also import data straight into new DynamoDB tables to create new applications with single-digit millisecond speed at scale, make data sharing between tables and accounts easier, and simplify disaster recovery and business continuity strategies.
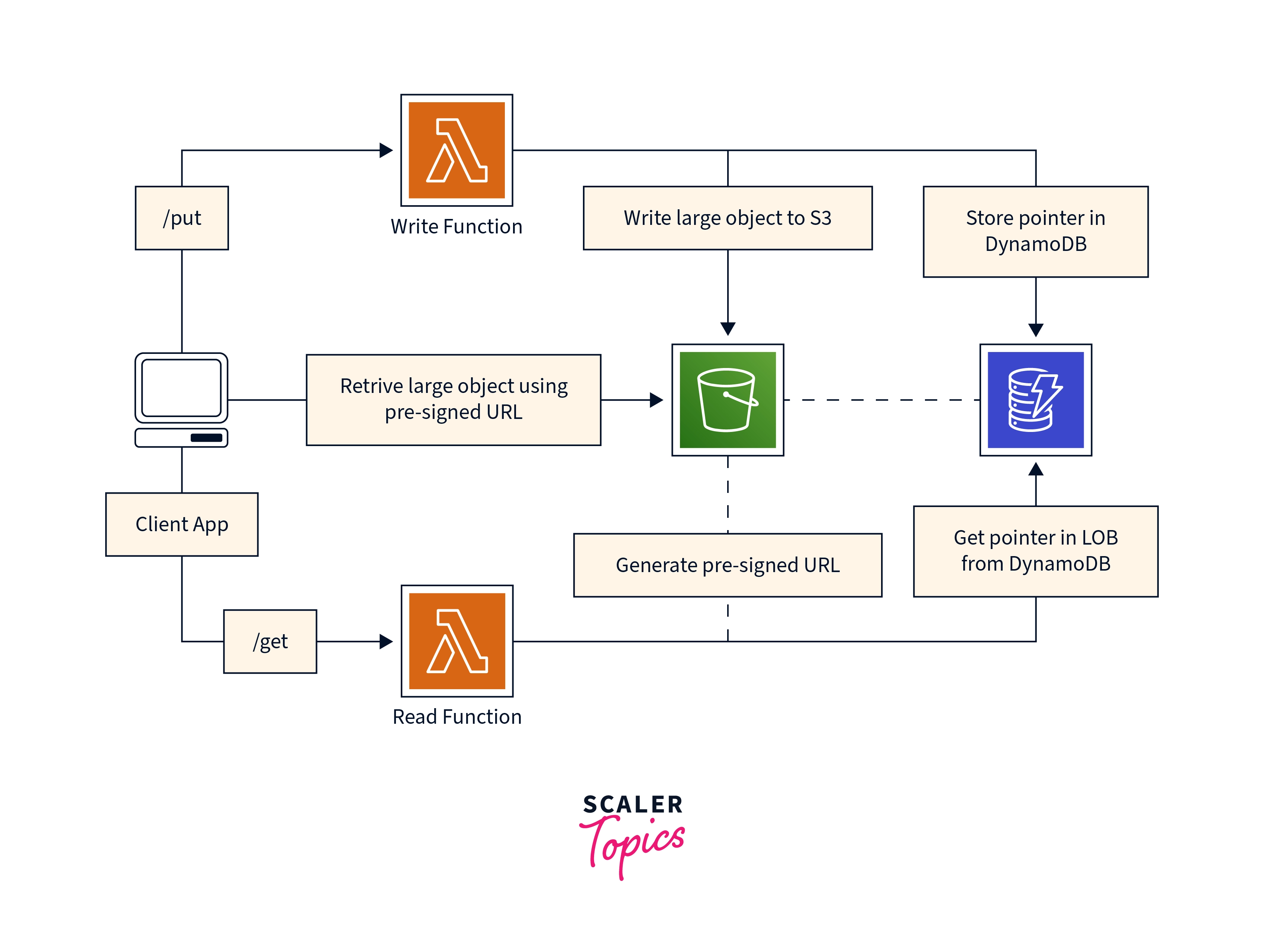
Import from Amazon S3
Your data must be in an Amazon S3 bucket in CSV, DynamoDB JSON, or Amazon Ion format to be imported into DynamoDB. Data can be compressed in ZSTD or GZIP format before being imported, or it can be imported in its uncompressed state. A single Amazon S3 or numerous Amazon S3 objects with the same prefix can be used as the source data.
When you start the import request, your data will be loaded into a new DynamoDB table. After the import, you may build this table with secondary indexes and then query and update your data across all primary and secondary indexes. After the import is finished, you may add a global table replica.
Import timings are proportional to the properties of your data in Amazon S3. This covers characteristics such as data size, data format, compression strategy, data distribution uniformity, number of Amazon S3 items, and others. Data sets with evenly distributed keys, in particular, will be faster to import than skewed data sets. For example, if your secondary index's key is partitioned by month of the year and all of your data is from December, importing this data may take substantially longer.
On the base table, it is anticipated that the properties connected to keys would be distinct. The import will continue until just the most recent overwrite is left if any keys are not unique. For instance, if the primary key is the month and several things have September set as the primary key, each new item will replace the previously written items, leaving just one item with September as the primary key. In some situations, the target table's number of items processed will differ from the number of items listed in the import table description.
Export to Amazon S3
You may export data from an Amazon DynamoDB table to an Amazon S3 bucket at any moment throughout your point-in-time recovery window using DynamoDB table export. When you export a DynamoDB table to an S3 bucket, you may use other AWS services like Athena, AWS Glue, and Lake Formation to execute analytics and complicated queries on your data. DynamoDB table export is a fully managed method for exporting DynamoDB tables at a scale that is far quicker than alternative solutions that include table scans.
To export data from an Amazon DynamoDB table to an Amazon S3 bucket, the source table's point-in-time recovery (PITR) must be enabled. Within the PITR window, you can export table data from any point in time for up to 35 days.
Best Practices for Designing and Using Partition Keys Effectively
The primary key that uniquely identifies each item in an Amazon DynamoDB database can be basic (a partition key alone) or composite (a partition key combined with a sort key).
In general, you should build your application to provide consistent activity across all logical partition keys in the table and its secondary indexes. You may define the access patterns required by your application, as well as the read and write units required by each table and secondary index.
By default, each partition in the table will aim to give the full capacity of 3,000 RCU and 1,000 WCU. The overall throughput across all partitions in the table may be controlled by the provided throughput in provisioned mode or by the table-level throughput limit in on-demand mode.
With burst capacity, DynamoDB gives some flexibility for your throughput provisioning. When you aren't utilizing all of your available throughputs, DynamoDB saves a portion of that spare capacity for later bursts of throughput to address use surges.
DynamoDB may also utilize burst capacity in the background for background maintenance and other duties without warning. Please keep in mind that these burst capacity parameters may change in the future.
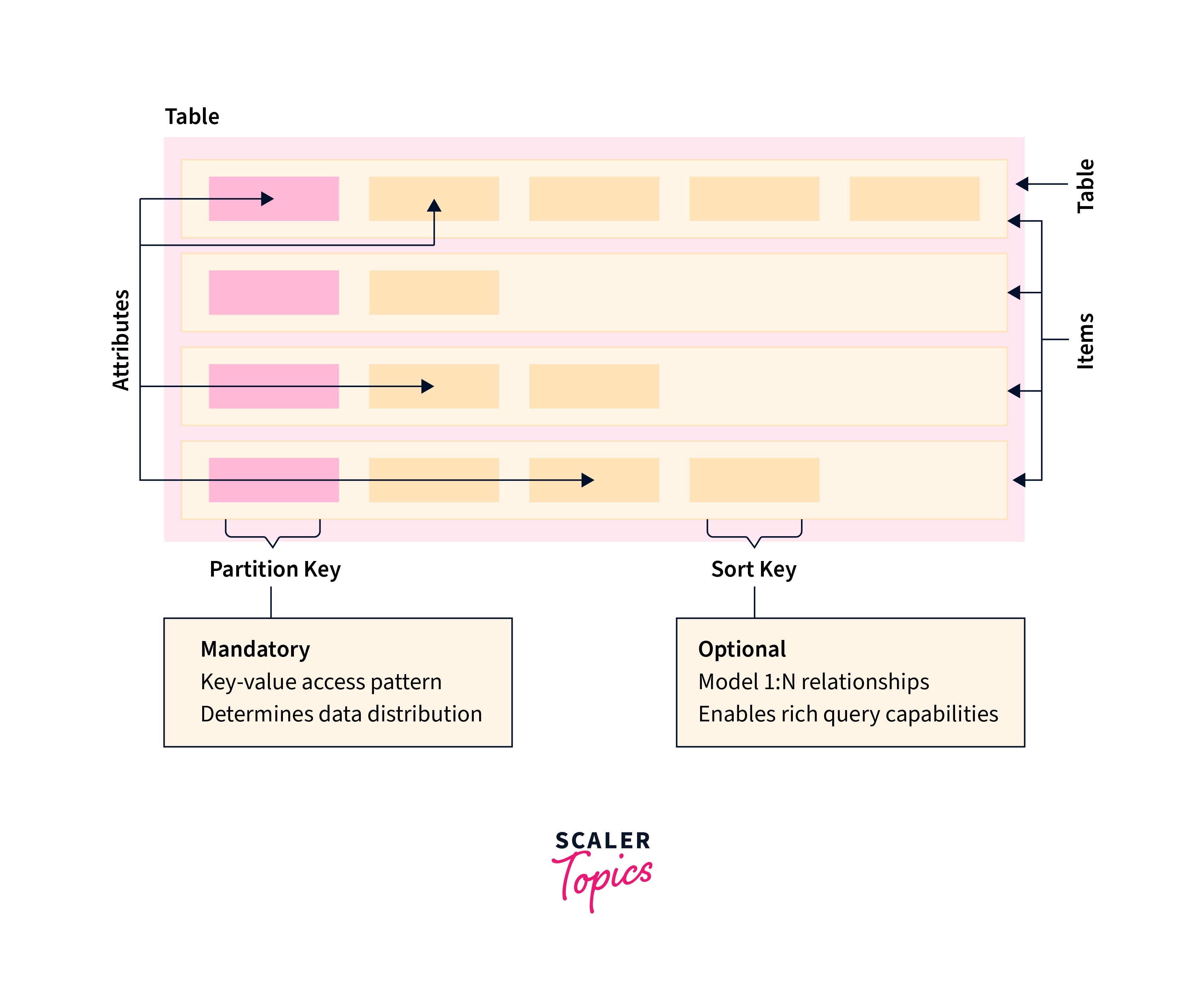
Best Practices for Using Sort Keys to Organize Data
In an Amazon DynamoDB table, the primary key that uniquely identifies each item in the table can be made up of both a partition key and a sort key.
Well-designed sort keys provide two major advantages:
- They collect similar information in one location where it can be efficiently queried. A well-designed sort key allows you to get often-needed groupings of related objects using range queries using operators such as begins with, between, >, and so on.
- Composite sort keys allow you to establish hierarchical (one-to-many) connections in your data that you may query at any level of the hierarchy. For example, in a table of geographical places, you may structure the sort key as follows.
Using Sort Keys for Version Control
Many applications require a history of item-level updates for audit or compliance purposes, as well as the ability to quickly obtain the most current version. Using sort key prefixes, there is an excellent design pattern that does this:
- Make two identical duplicates of each new item: At the beginning of the sort key, one copy should have a version-number prefix of zero (such as v0_), while the other should have a version-number prefix of one (such as v1_).
- When the item is changed, use the next higher version-prefix in the sort key of the updated version, and put the new contents into the item with version-prefix zero. This implies that the most recent version of any item may be easily accessed by using the zero prefix.
Best Practices for Using Secondary Indexes in DynamoDB
Secondary indexes are frequently required to support the query patterns that your application demands. At the same time, overusing secondary indexes or using them inefficiently might add expense and degrade performance needlessly.
Points to Remember:
- Secondary index guidelines in DynamoDB
- Indexes should be used wisely.
- Pick your projections with caution.
- To avoid fetches, optimize frequent requests.
- When constructing local secondary indexes, keep item-collection size constraints in mind.
- Make use of sparse indexes.
- Materialized aggregation searches using Global Secondary Indexes
- Overloading Global Secondary Indexes
- Utilization of the Global Secondary Index Selective table queries can benefit from write sharding.
- Make an eventually consistent duplicate using Global Secondary Indexes
Best Practices for Storing Large Items and Attributes
Amazon DynamoDB presently restricts the size of each item stored in a table. If your application requires more data to be stored in an item than the DynamoDB size restriction allows, you can attempt compressing one or more big attributes or splitting the item into numerous items (efficiently indexed by sort keys). You may alternatively save the item as an object in Amazon Simple Storage Service (Amazon S3) and save the Amazon S3 object identifier in your DynamoDB item.
Compressing Large Attribute Values
Compressing big attribute values allows them to fit under DynamoDB item restrictions, reducing storage costs. GZIP and LZO compression methods generate binary output, which you may subsequently store in a Binary attribute type.
Storing Large Attribute Values in Amazon S3
As previously stated, you may also utilize Amazon S3 to store huge attribute values that cannot be stored in a DynamoDB object. You may save them in Amazon S3 as an object and then save the object identifier in your DynamoDB item.
You may also leverage Amazon S3's object metadata support to give a link back to the parent item in DynamoDB. Save the item's main key value as Amazon S3 metadata for the object in Amazon S3. This frequently aids in the upkeep of Amazon S3 items.
Best Practices for Handling Time Series Data in DynamoDB
The general design principles of Amazon DynamoDB encourage that you utilize as few tables as possible. A single table is sufficient for the majority of applications. However, when dealing with time series data, it is typically advisable to have one table per application for each period.
Design Pattern for Time Series Data
Consider a typical time series scenario in which you wish to track a large number of occurrences. Because of your write access pattern, all of the events being logged have today's date. Your read access pattern may be to read today's events the most frequently, yesterday's events considerably less frequently, and previous events very infrequently. One approach is to incorporate the current date and time into the main key.
The following design style frequently handles this type of problem effectively:
- Create one table each time, with the necessary read and write capability and indexes.
- Build the table for the following period before the conclusion of each period. Direct event flow to the new table just before the current session finishes. You can give these tables titles that correspond to the periods they have documented.
- Reduce a table's supplied write capacity to a smaller value (for example, 1 WCU) as soon as it is no longer being written to, then provision whatever read capacity is necessary. As older tables age, reduce their provided read capability. You have the option of archiving or deleting tables whose contents are rarely or never used.
Best Practices for Managing Many-to-many Relationships
Adjacency lists are a design pattern that may be used to describe many-to-many connections in Amazon DynamoDB. In general, they provide a means to represent graph data (nodes and edges) in DynamoDB.
Adjacency List Design Pattern
An adjacency list can be used to model a many-to-many relationship between two entities in an application. The partition key is used in this pattern to represent all top-level entities (synonymous with nodes in the graph model). By setting the value of the sort key to the target entity ID, any relationships with other entities (edges in a graph) are represented as an item within the partition (target node).
The benefits of this pattern include fewer data duplication and easier query patterns for locating all entities (nodes) associated with a target object (having an edge to a target node).
An invoicing system with various bills is a real-world illustration of how this pattern has proved beneficial. A bill can appear on many invoices. In this example, the partition key is either an InvoiceID or a BillID. BillID partitions include all bill-specific characteristics. InvoiceID partitions include an item that stores invoice-specific characteristics as well as an item for each BillID that rolls up to the invoice.
Materialized Graph Pattern
Many applications are constructed upon understanding peer rankings, common relationships between entities, neighbor entity status, and other forms of graph-style operations. Consider the following schema design pattern for these sorts of applications.
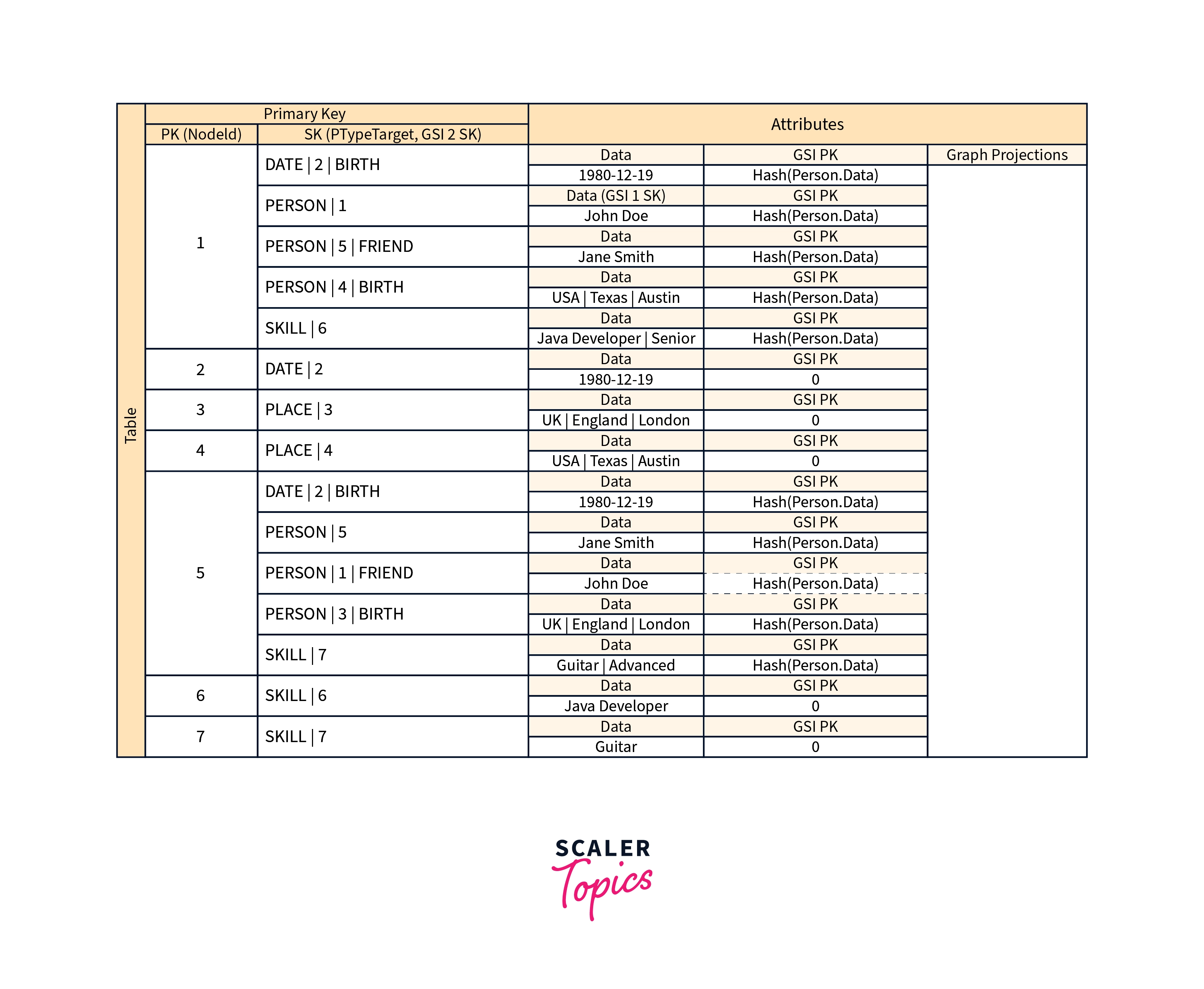
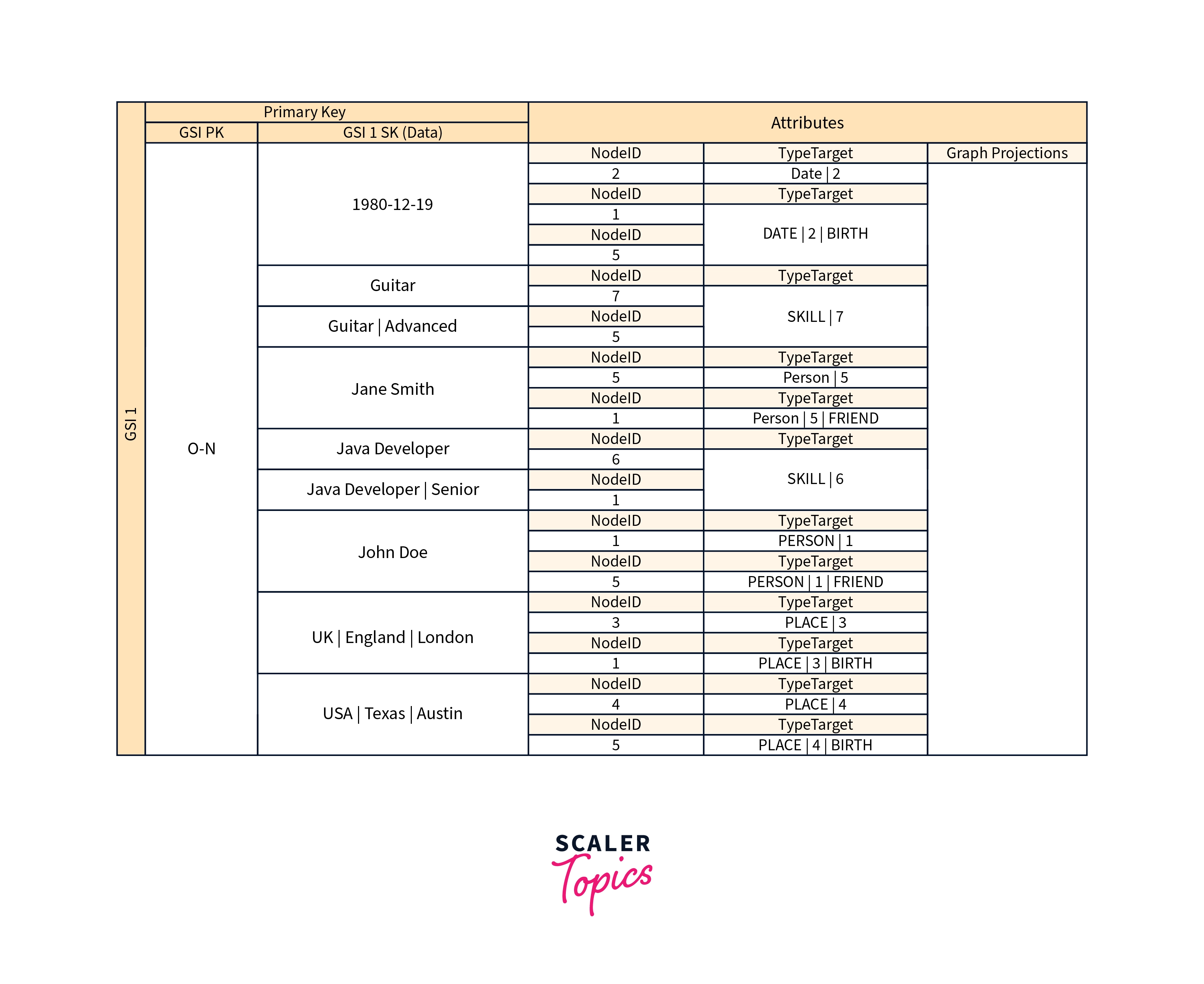
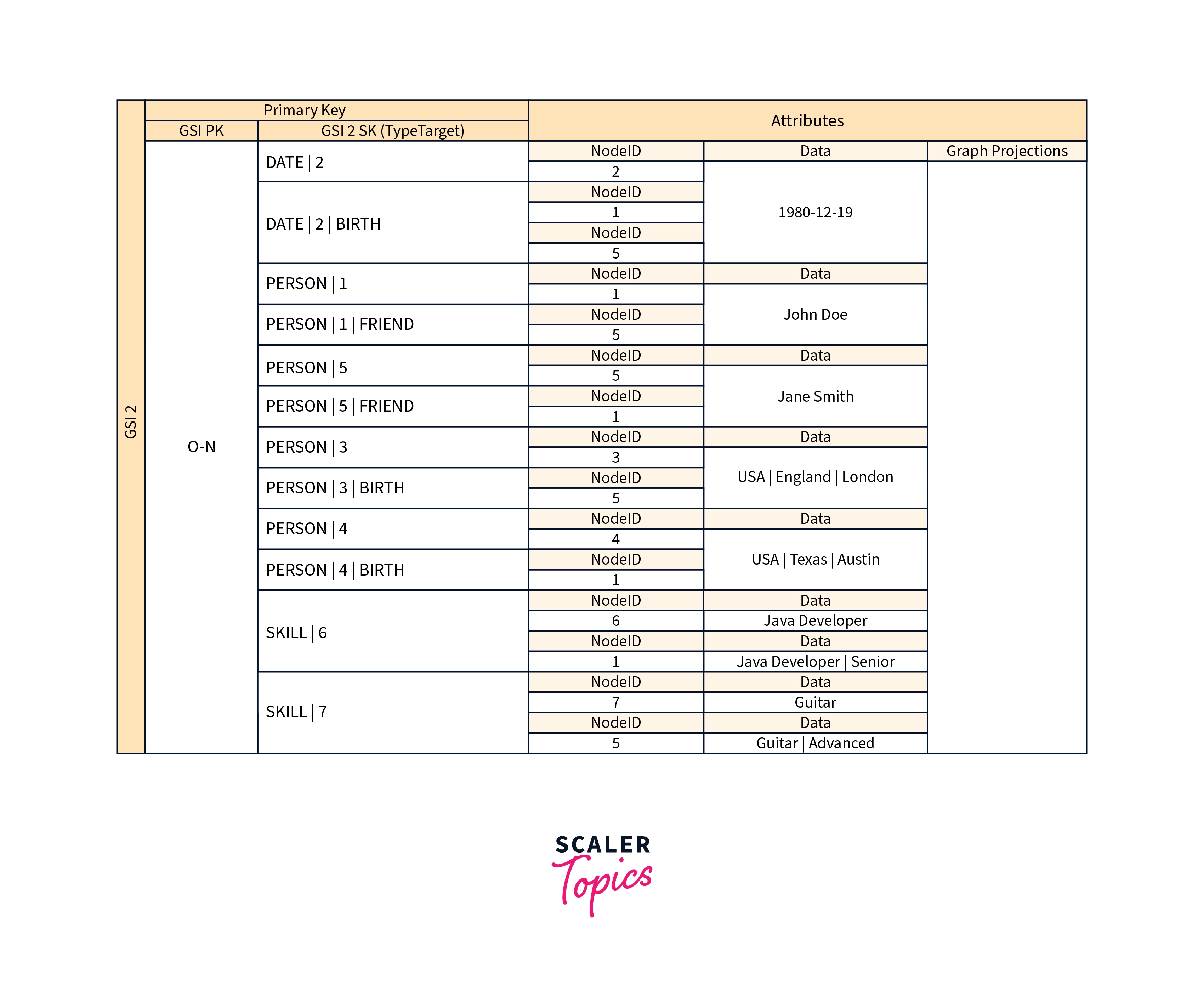
The above schema depicts a graph data structure defined by a collection of data partitions holding the items that constitute the graph's edges and nodes. Edge objects have two attributes: Target and Type. These properties are used as part of a composite key called "TypeTarget" to identify an item in the main table partition or a second global secondary index.
Best Practices for Implementing a Hybrid Database System
In some cases, switching from one or more relational database management systems (RDBMS) to Amazon DynamoDB may not be advantageous. In certain instances, a hybrid system may be desirable.
If you don't want to migrate everything to DynamoDB
For example, some firms have made significant expenditures in the programming that generates a plethora of reports required for accounting and operations. They are unconcerned with the time it takes to prepare a report. A relational system's flexibility is ideally suited to this type of activity, and recreating all of those reports in a NoSQL setting may be complex.
Some organizations also have several historical relational systems that they bought or inherited throughout the years. Data migration from these systems may be too dangerous and costly to justify the effort.
However, the same firms may now discover that their operations rely on high-traffic customer-facing websites with millisecond response times. Relational solutions cannot scale to satisfy this goal without incurring exorbitant (and frequently unacceptable) costs.
Best Practices for Modeling Relational Data in DynamoDB
Data is stored in a normalized relational format in traditional relational database management system (RDBMS) systems. Hierarchical data structures are reduced to a collection of common elements that are stored across numerous tables using this structure.
This provides a versatile API for obtaining data, but it requires a large amount of processing. You must often query data from numerous sources, and the results must be compiled for display. This executes sophisticated queries across many tables before sorting and integrating the generated data.
Another reason that might cause RDBMS systems to slow down is the requirement to implement an ACID-compliant transaction structure. When stored in an RDBMS, the hierarchical data structures utilized by most online transaction processing (OLTP) systems must be broken down and dispersed across numerous logical tables. As a result, an ACID-compliant transaction architecture is required to avoid race conditions that might arise if an application attempts to read an object that is being written. A transaction framework adds considerable cost to the writing process by definition.
These are the key scaling hurdles for conventional RDBMS platforms. It remains to be seen whether the NewSQL group can produce a distributed RDBMS solution successfully. However, even this is unlikely to address the two previously mentioned restrictions. The processing costs of normalization and ACID transactions must remain considerable regardless of how the service is supplied.
Best Practices for Querying and Scanning Data
Performance considerations for scans
Avoid performing a Scan operation on a big table or index with a filter that eliminates many results if at all feasible. In addition, when a table or index grows in size, the Scan process becomes slower. The Scan operation analyses each item for the specified values and can consume all of the throughput allocated to a big table or index in a single operation. Design your tables and indexes such that your applications may use Query instead of Scan for quicker response times.
Avoiding Sudden Spikes in Reading Activity
When you construct a table, you specify the read and write capacity unit requirements. The capacity units for readings are represented as the number of strongly consistent 4 KB data read requests per second. A read capacity unit is defined as two 4 KB read requests per second for eventually consistent readings. By default, Scan operations conduct eventually consistent reads and can return up to 1 MB (one page) of data. As a result, a single Scan request can require (1 MB page size / 4 KB item size) / 2 (eventually consistent reads) = 128 read operations. If you request highly consistent readings instead, the Scan operation will require twice as much allocated throughput—256 read operations.
Conclusion
- Amazon DynamoDB is now one of the fastest-growing database services. However, it is a NoSQL database that necessitates data modeling in a way that SQL databases do not.
- DynamoDB provides two capacity options, each with its charging model: provisioned and on-demand.
- In provisioned capacity mode, you select how many read and write capacity units you want available for your tables ahead of time. Requests are throttled if your tables exceed the limit.
- Due to its simplicity, Amazon DynamoDB is suited for small-scale applications. However, it excels at working on an ultra-large scale, as required by Amazon. Many other strong applications, such as Snapchat, Zoom, and Dropbox, rely on it.
- Amazon Cognito is the preferred method for obtaining AWS credentials for your online and mobile apps. Amazon Cognito assists you in avoiding hardcoding your AWS credentials in your files.
- Amazon Cognito generates temporary credentials for your application's authorized and unauthenticated users by utilizing AWS Identity and Access Management (IAM) roles.
- Amazon Redshift provides extensive business intelligence capabilities and a robust SQL-based interface to Amazon DynamoDB.
- You may run advanced data analysis queries on data copied from a DynamoDB table into Amazon Redshift, including joins with other tables in your Amazon Redshift cluster after the data is in Amazon Redshift.
- Amazon DynamoDB is connected with Apache Hive, an Amazon EMR data warehouse application.
- Without writing any code, Amazon DynamoDB import and export features provide a straightforward and effective method to move data between Amazon S3 and DynamoDB tables.