Azure Data Factory
Overview
Azure Data Factory is a cloud-based data integration service by Microsoft. It empowers organizations to create, schedule, and manage data pipelines that move and transform data from various sources to desired destinations. Offering a user-friendly interface and support for diverse data sources, it facilitates ETL (Extract, Transform, Load) processes, enabling data-driven decision-making. With its scalable and automated capabilities, Azure Data Factory streamlines data workflows, facilitating efficient data movement and transformation within a flexible and scalable environment.
What is Azure Data Factory?
Azure Data Factory is a cloud-based data integration service provided by Microsoft Azure. It enables organizations to create, schedule, and manage data pipelines that move data from various sources to destinations for purposes such as data warehousing, analytics, reporting, and more.
Here are the key components and features of Azure Data Factory:
- Data Pipelines: Azure Data Factory allows you to create data pipelines that define the flow of data from source to destination. Pipelines consist of a series of activities that perform tasks like data extraction, transformation, and loading. These activities can be orchestrated to create complex workflows.
- Data Movement: The service supports connecting to a wide range of data sources, both on-premises and in the cloud, including relational databases, cloud storage, big data platforms, and more. It facilitates moving data efficiently and securely between these sources and destinations.
- Data Transformation: Azure Data Factory provides data transformation capabilities to clean, transform, and enrich the data as it moves through the pipeline. This ensures that the data is in the right format and structure for analysis and reporting.
- Set up Alerts: Azure Data Factory allows you to set up alerts for specific conditions using Azure Monitor. These alerts notify you when certain predefined conditions are met during the execution of your data pipelines. You can configure alerts to trigger based on events like failed pipeline runs, high execution times, or other criteria you define. This proactive notification helps you promptly address issues and ensure the smooth operation of your data integration workflows.
- Integration with Azure Services: The service seamlessly integrates with other Azure services like Azure Data Lake Storage, Azure SQL Database, Azure Synapse Analytics (formerly SQL Data Warehouse), and more, enabling a holistic data ecosystem.
- Monitoring and Management: Azure Data Factory provides monitoring and logging features that allow you to track the execution of pipelines, identify bottlenecks, and troubleshoot issues. You can set up alerts and notifications for pipeline failures or anomalies.
- Security and Compliance: The service includes security features like encryption, identity and access management, and compliance certifications, ensuring that your data remains secure and compliant.
Azure Data Factory use cases
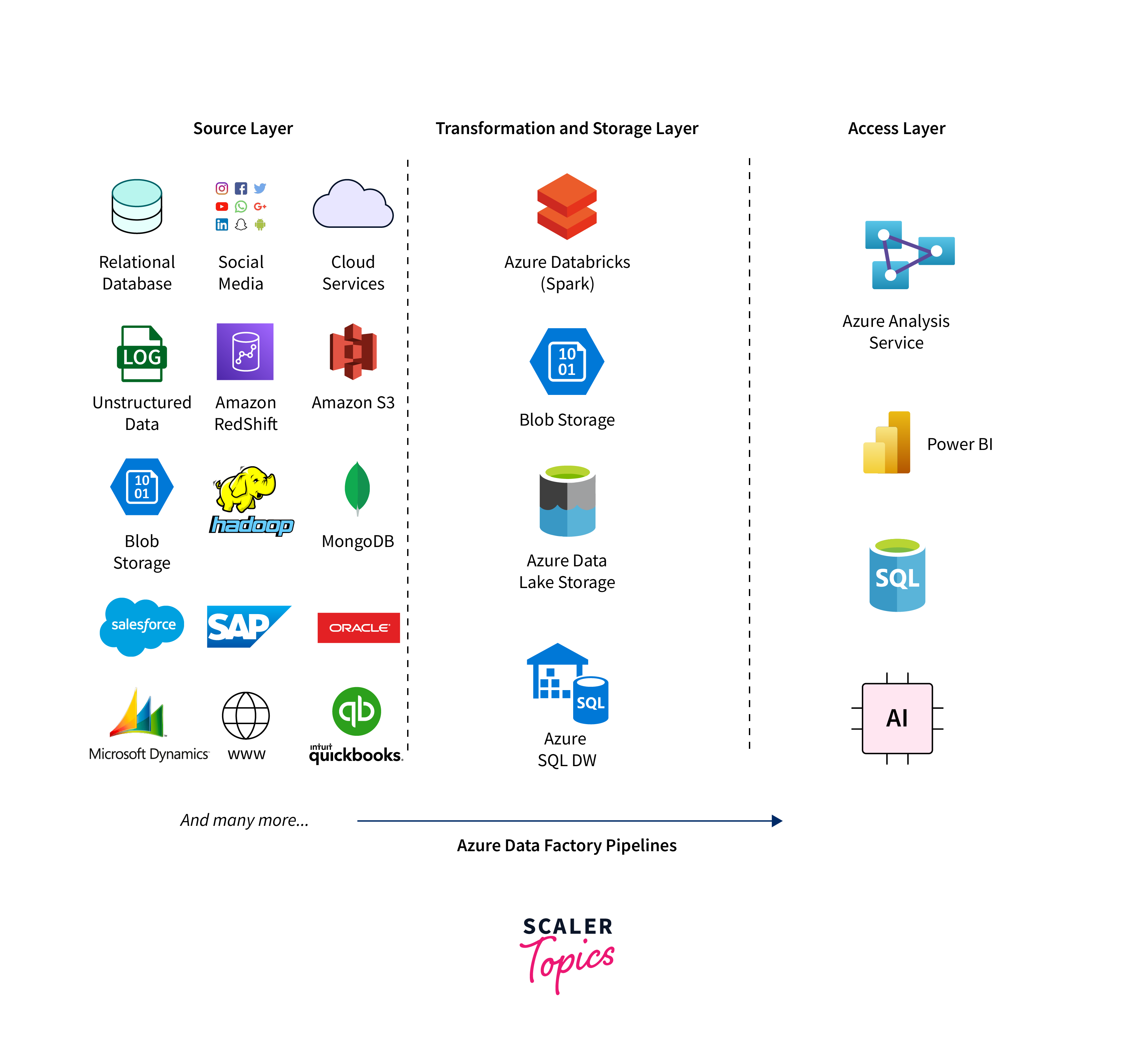
Azure Data Factory is a cloud-based data integration service that allows you to create, schedule, and manage data pipelines for moving and transforming data from various sources to various destinations. Here are more specific examples and scenarios illustrating the use cases of Azure Data Factory:
- Data Warehousing and ETL (Extract, Transform, Load):
- Scenario: You have sales data stored in an on-premises SQL Server database. You want to extract this data, transform it by cleansing and aggregating it, and then load it into an Azure SQL Data Warehouse for analysis.
- Use Case: Use Azure Data Factory to create a pipeline that extracts data from the on-premises SQL Server, applies transformation using Azure Data Flow, and loads the transformed data into Azure SQL Data Warehouse.
- Cloud Analytics:
- Scenario: Your organization uses various cloud-based applications like Salesforce, Google Analytics, and Azure Storage, and you want to perform cross-application analytics.
- Use Case: Use Azure Data Factory to orchestrate data movement from Salesforce, Google Analytics, and Azure Storage into a data lake like Azure Data Lake Storage. You can then use Azure Synapse Analytics (formerly Azure SQL Data Warehouse) or Azure Databricks to analyze and gain insights from the consolidated data.
- Real-time Data Ingestion:
- Scenario: You need to continuously ingest data from sources like Azure Event Hubs, IoT devices, or social media streams into Azure for real-time analysis.
- Use Case: Use Azure Data Factory to create a pipeline that subscribes to an Event Hub or other streaming source, and then routes the incoming data to appropriate storage or processing services like Azure Blob Storage or Azure Databricks for real-time analysis.
- Hybrid Data Movement:
- Scenario: Your organization has data scattered across on-premises databases, cloud-based storage, and SaaS applications. You want to centralize this data in Azure for reporting purposes.
- Use Case: Utilize Azure Data Factory to design pipelines that extract data from on-premises databases, cloud storage (e.g., Amazon S3), and SaaS applications (e.g., Salesforce), and move it to Azure Data Lake Storage or Azure SQL Database.
- Automating Azure Data Factory pipelines using the Azure Command-Line Interface (Azure CLI)
- Installation and Authentication:
- Install Azure CLI, use az login to authenticate.
- Commands:
- Create Data Factory: az datafactory create
- Manage Linked Services: az datafactory linked-service create/update/delete
- Manage Datasets: az datafactory dataset create/update/delete
- Manage Pipelines: az datafactory pipeline create/update/delete
- Trigger Pipeline Runs: az datafactory pipeline-run create
- Monitor Pipeline Runs: az datafactory pipeline-run query-by-factory
- Automation and Scripting:
- Use scripts (Bash, PowerShell) to automate pipeline tasks.
- DevOps Integration:
- Integrate CLI commands into CI/CD pipelines (Azure DevOps, Jenkins) for streamlined deployment.
- Pipeline Monitoring
- Monitoring tools track Azure Data Factory pipeline runs, providing insights into execution, errors, and performance. Use Azure Portal, Metrics, Alerts, Logs (Log Analytics), and Application Insights. Optimize pipelines by identifying bottlenecks, adjusting settings, and resolving errors based on monitoring insights.
How does Azure Data Factory work?
Azure Data Factory works through a three-step process:
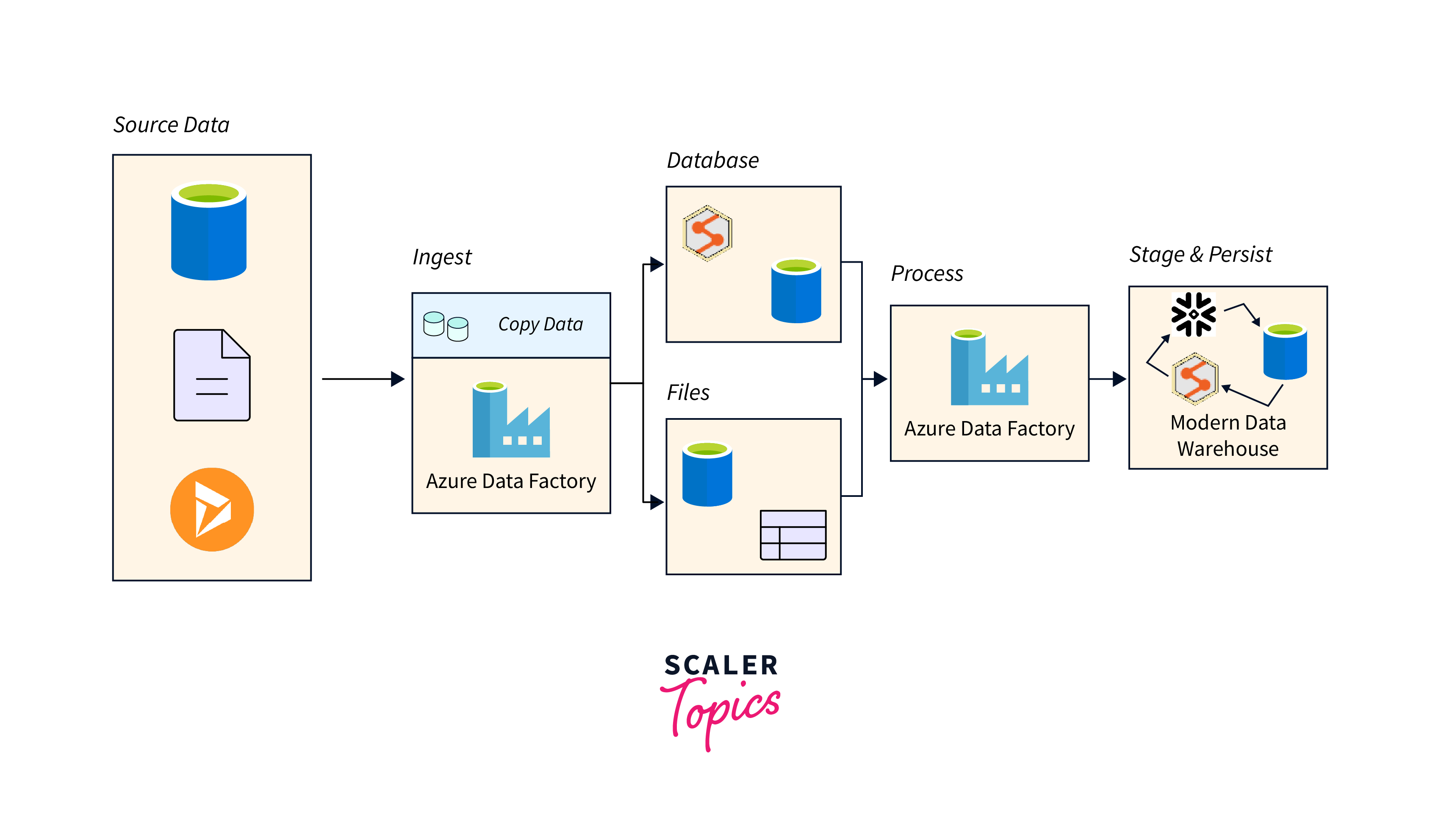
- Author & Deploy: In this step, you define the data movement and transformation tasks. This involves creating data pipelines using the Azure Data Factory interface, which provides both graphical and code-based options. You specify the source of your data, the destination where you want to move it, and any necessary transformations.
- Monitor & Manage: Once you've defined your pipelines, you can monitor and manage their execution. Azure Data Factory provides monitoring tools to track the progress of your pipelines, offering insights into activities such as data movement, transformation, and orchestration.
- Operationalize & Manage: After successfully monitoring and managing your pipelines, you can operationalize them for ongoing data integration tasks. Azure Data Factory allows you to schedule the execution of pipelines at specific intervals or trigger them based on events.
Data migration activities with Azure Data Factory
Azure Data Factory provides a variety of data migration activities that enable you to efficiently move data from source to destination while performing necessary transformations and transformations. Here are some common data migration activities you can perform using Azure Data Factory:
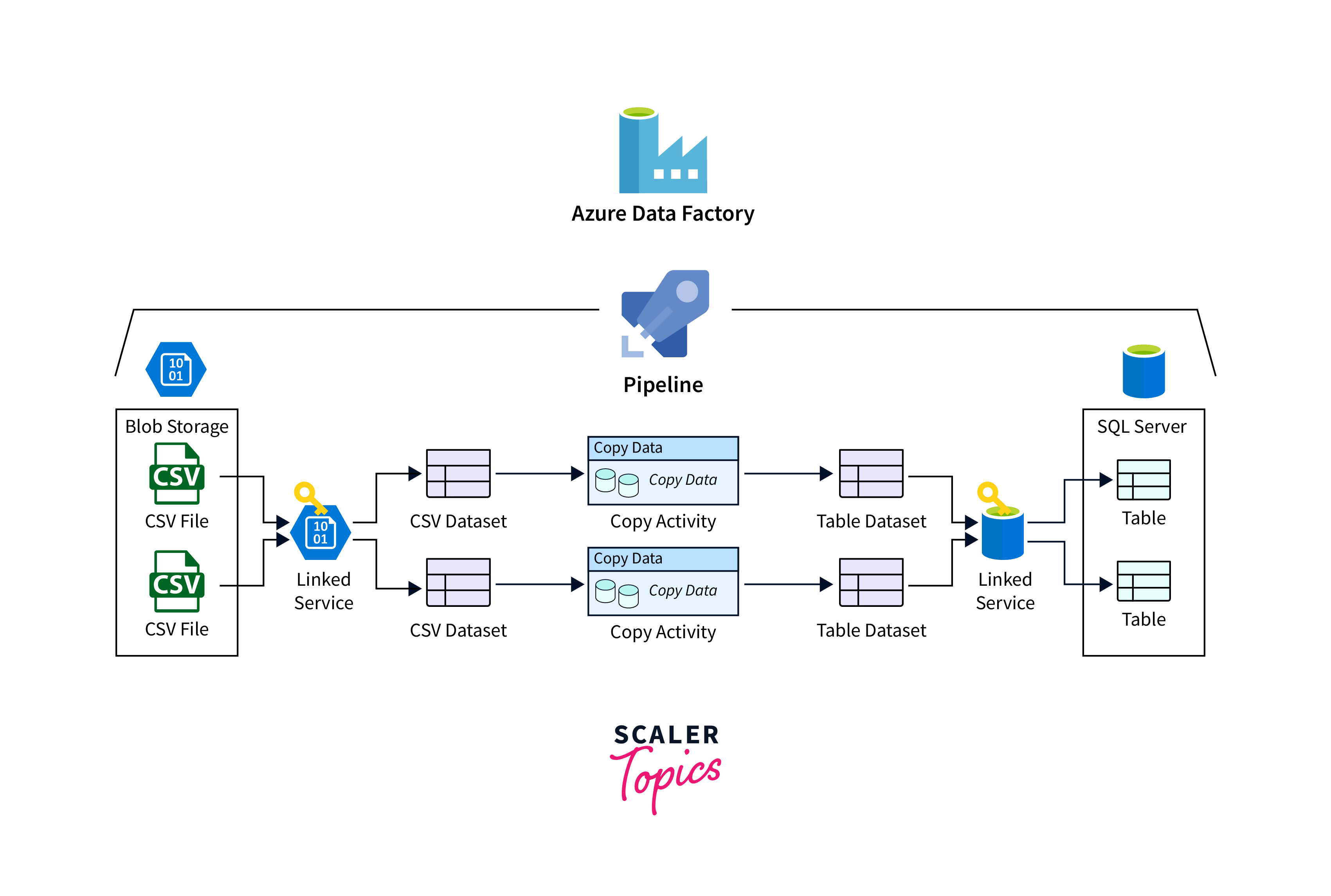
- Copy Data Activity: The "Copy Data" activity is the foundation of data migration in Azure Data Factory. It allows you to move data from a source to a destination, whether they are both within Azure or involve on-premises sources. This activity supports various sources and destinations, including Azure Blob Storage, Azure SQL Database, Azure Data Lake Storage, on-premises databases, and more.
- Data Transformation Activities: During data migration, it's often necessary to transform the data to match the target schema or to improve data quality. Azure Data Factory supports transformations like data type conversion, data masking, data cleansing, and data enrichment.
- Lookup Activity: The "Lookup" activity allows you to retrieve data from a reference dataset, which can be useful for data enrichment or validation during migration. For instance, you might use a lookup to validate that certain values exist in a reference table before migrating data.
- Control Flow Activities: Control flow activities in Azure Data Factory provide orchestration and control over the order of execution of your migration tasks. Activities like "If Condition," "ForEach," and "Until" loops help manage complex migration scenarios where different actions need to be taken based on certain conditions.
Azure Data Factory key components
Datasets represent data structures within the data stores
Datasets define the data structures within the data stores. They represent the input and output data for activities within a pipeline. Datasets provide the schema and location information needed to read or write data. Datasets are essentially a logical representation of your data, abstracting the underlying physical storage.
A pipeline is a group of activities
A pipeline is a logical grouping of activities that define the data workflow. It represents the sequence in which data activities should be executed. Pipelines allow you to organize and orchestrate data movement, transformation, and processing tasks in a coherent manner.
Activities define the actions to perform on your data
Activities are the fundamental building blocks of a pipeline. They define the actions to be performed on your data. There are various types of activities, including data movement activities (e.g., copying data), data transformation activities (e.g., data flow transformations), control flow activities (e.g., conditional statements), and more.
Linked services define the information needed for Azure Data Factory to connect to external resources
Linked services define the connection information required for Azure Data Factory to connect to external data stores, databases, or services. They encapsulate the details of authentication, connection strings, and other relevant configurations.
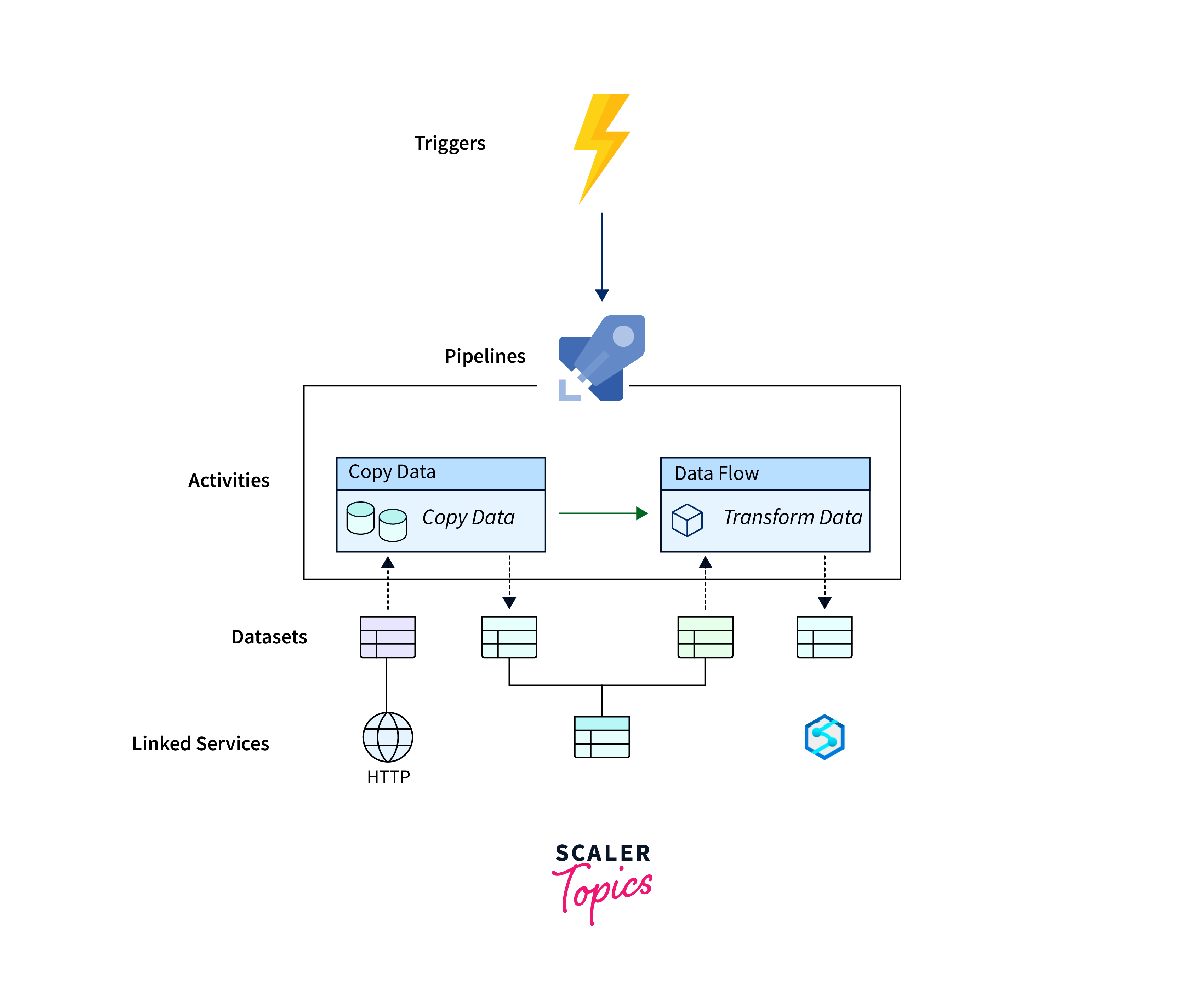
How the Azure Data Factory components work together
Azure Data Factory components work together in a coordinated manner to facilitate the movement, transformation, and management of data. Let's explore how these components collaborate within a data integration process:
- You define datasets to represent your data sources and destinations, specifying their structure and location.
- Linked services are set up to establish connections to external data stores or services.
- Activities are created to perform actions on your data, such as copying data, transforming it, or running scripts.
- Pipelines are designed to organize and orchestrate the sequence of activities, utilizing the datasets and linked services.
- Triggers are configured to initiate the execution of pipelines based on schedules, events, or manual requests.
- When a trigger is activated, the pipeline starts executing. Activities within the pipeline interact with datasets and linked services to move and process data.
- Throughout the process, monitoring tools provide insights into the progress and performance of activities and pipelines.
In essence, Azure Data Factory components work collaboratively to define, execute, and manage data integration workflows, offering a structured approach to handling data movement and transformations across diverse sources and destinations.
Azure Data Factory access zones
Azure Data Factory does not have a concept referred to as "access zones." However, the Azure has introduced a feature called "Availability Zones" which is related to ensuring high availability and fault tolerance for Azure services, including data-related services like Azure Data Factory.
Availability Zones are physically separate data centers within an Azure region. They are designed to provide the redundancy and resilience by ensuring that services deployed in one zone remain available even if one of the zones experiences an outage. This feature is especially important for critical workloads that require maximum uptime.
While Azure Data Factory itself does not directly utilize access zones, you can deploy and configure it to leverage availability zones to enhance its resilience and ensure continuous data integration processes. This can be done by placing the resources used by Azure Data Factory, such as Azure Integration Runtimes, in different availability zones.
Data Migration in Action
Certainly, let's walk through a simplified example of a data migration scenario using the Azure Data Factory.
Scenario: Data Migration from On-Premises Database to Azure SQL Database
In this example, let's consider a scenario where you want to migrate data from an on-premises SQL Server database to an Azure SQL Database. 1. Define Linked Services: Create linked services for source and destination (e.g., on-premises SQL, Azure SQL) with the connection info. 2. Create Datasets: Make datasets for source and destination (tables, columns). 3. Design Pipelines: Build pipeline:
- Copy Data (Source to Staging): Copy from source to staging (e.g., Blob Storage).
- Data Flow (Transformation): Use Data Flow for the visual data transformations.
4. Run and Monitor: Manually run or schedule pipeline. Monitor via Azure Data Factory tools. 5. Validate and Iterate: Check destination data for accuracy. Compare source and destination data.
DataCopy Wizard on Azure
The "DataCopy Wizard" refer to the "Copy Data" feature within Azure Data Factory. Azure Data Factory's "Copy Data" tool allows you to easily create, schedule, and monitor data copy pipelines that move data from source to destination. This feature simplifies the process of the data migration, replication, and synchronization between different data stores, whether they are on-premises or cloud-based.
Here's how the "Copy Data" feature typically works:
- Source and Destination Setup: Choose source (on-premises, cloud) and destination (Azure SQL, Data Lake). Configure connectivity and authentication.
- Mapping and Transforming: Define source-to-destination mapping, handle schema changes, apply transformations, conversions, and filters.
- Scheduling Copy: Set copy schedule—one-time, recurring, or triggered by the events.
- Monitoring and Alerts: Monitor progress, set alerts for failures or issues.
- Validation and Check: After copying, validate data accuracy and quality by comparing source and destination.
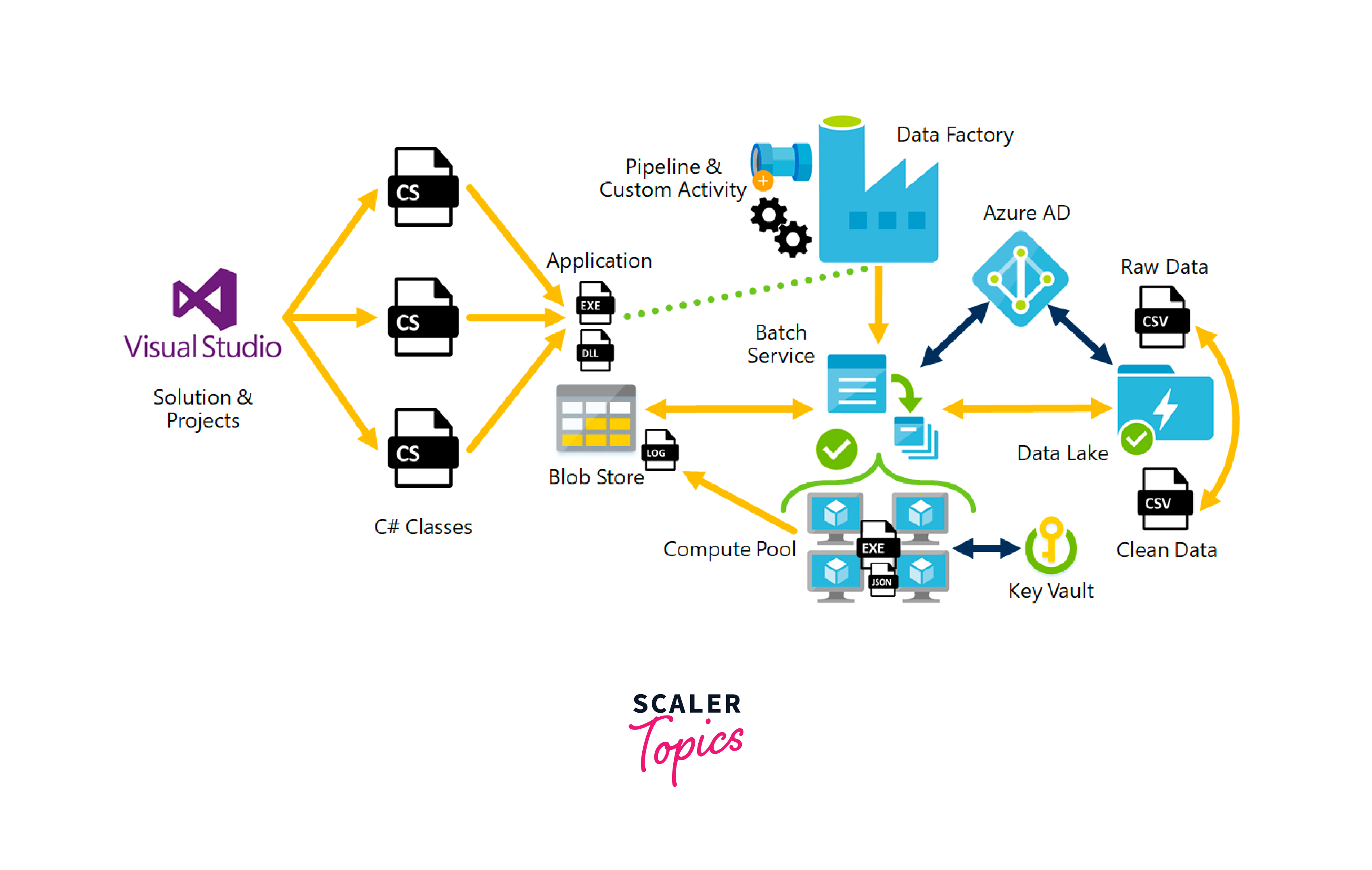
Custom DataCopy Activities
Here's how you can create custom data copying using Data Flow activities:
- Create Data Flow Activity: Add a Data Flow activity in the Azure Data Factory pipeline. Design data transformation visually using source, transformations, and sink.
- Configure Source and Sink: Set source (e.g., table) and sink (e.g., storage) in the Data Flow activity.
- Add Transformations: Insert transformations (filter, join, etc.) between source and sink to modify data.
- Data Type and Expressions: Change data types, apply expressions for formatting during copying.
- Map Columns: Align source columns with destination columns for the the accurate data placement.
Monitor and manage Azure Data Factory pipelines
Monitoring and managing Azure Data Factory pipelines is essential to ensure the reliability, performance, and success of your data integration workflows. Azure Data Factory provides various tools and features to help you monitor and manage your pipelines effectively:
- Azure Portal Dashboard: View pipeline, activity, and trigger status directly on the Azure portal.
- Monitoring Dashboard: Track pipeline execution, activity runs, and the outcomes.
- Activity Runs: Access detailed logs, metrics, data, and errors for activities.
- Alerts and Notifications: Set alerts for failures or delays, get email notifications, trigger Logic Apps or Functions.
- Triggers and Scheduling: Monitor trigger and schedule the accuracy.
- Retries and Reruns: Retry or rerun failed activities, with manual or automatic options.
Final Result Test
To efficiently confirm the successful migration of your data to Azure SQL, you can take the following steps without any plagiarism:
For a rapid validation of your data migration in Azure SQL, I suggest installing the sql-cli utility through npm. This utility serves as a versatile cross-platform command line interface for the SQL Server. To get started, execute the following command to install sql-cli globally:
Subsequently, establish a connection to your Azure SQL Database using the sql-cli tool. Utilize the command provided below:
Here, replace placeholders such as yoursqlDBaddress, username, password, and databasename with your specific connection details. This command will initiate a connection to your Azure SQL Database.

Azure Data Factory pricing
Here's a general overview of the key factors that can influence the Azure Data Factory pricing:
- Data Movement and Transformation: Azure Data Factory charges are based on the volume of data moved between sources and destinations, as well as the data transformation activities performed. This includes both the ingested and the processed data. The pricing structure varies based on the region and destination type.
- Activity Runs and Execution: Azure Data Factory pricing considers the number of activity runs and executions you perform within your pipelines. This encompasses the data copying, data transformations, and other pipeline activities.
- Integration Runtimes: Azure Data Factory supports integration runtimes that connect to various data sources and destinations. Depending on the type of integration runtime you use (e.g., Azure, Self-hosted, Azure-SSIS), pricing may differ. Integration runtimes are the often billed based on the number of nodes and their performance level.
- Monitoring and Management: Some premium features related to monitoring, logging, and managing your data pipelines may have associated costs. Advanced monitoring capabilities might require additional charges.
Conclusion
- Azure Data Factory (ADF) emerges as a robust cloud-based data integration service that orchestrates and automates the data movement and transformation workflows in the cloud environment.
- The modern era's abundance of data is a valuable asset. However, transitioning to the cloud presents challenges. ADF bridges this gap, allowing businesses to harness data's potential during the cloud migration.
- ADF doesn't store data itself but facilitates the creation of data-driven workflows. These workflows manage data movement between supported data stores and process data using compute services, both on-premises and in the cloud.
- ADF finds applications in various scenarios, including supporting data migrations, extracting data from diverse sources into Azure Data Lake, executing data integration processes, and seamlessly integrating data from disparate ERP systems for efficient reporting.