Data Lake Analytics
Overview
Azure Data Lake Analytics is a cloud-based service provided by Microsoft Azure that enables you to analyze large volumes of data using a serverless and scalable approach. It allows you to write and execute queries using familiar languages like U-SQL and manage data processing pipelines efficiently. With Data Lake Analytics, you can process and gain insights from big data without the need to manage infrastructure, as the service automatically scales resources based on demand.
What is Data Lake Analytics?
Data Lake Analytics is a cloud-based big data analytics service that provides organizations with a powerful platform for processing and analyzing vast amounts of data. Whether your data is structured, semi-structured, or unstructured, Data Lake Analytics can handle it, making it suitable for a wide range of data processing tasks, including data preparation, transformation, and analysis.
![]()
How Does it Work?
Azure Data Lake Analytics works by providing a serverless and scalable platform for processing and analyzing large volumes of data stored in Azure Data Lake Storage or other Azure data sources. Here's an overview of how it works:
- Job Submission:
You start by defining and submitting jobs to Azure Data Lake Analytics. Jobs can be written in U-SQL, a language developed by Microsoft that combines SQL-like syntax with C# expressions. These jobs contain the logic for processing and analyzing your data. - Resource Allocation:
When you submit a job, Azure Data Lake Analytics dynamically allocates the necessary resources for job execution. This includes allocating processing power, memory, and storage as needed to complete the job efficiently. The serverless nature of the service means that you don't have to manage clusters or worry about resource provisioning. - Data Ingestion:
Azure Data Lake Analytics can access data stored in Azure Data Lake Storage, Azure Blob Storage, Azure SQL Data Warehouse, and other Azure data sources. You specify the data source and location in your job definition. - Data Processing:
The U-SQL jobs you submit define how the data should be processed. U-SQL scripts can include SQL-like queries for data transformation, filtering, aggregation, and more. Additionally, you can use C# expressions for custom data processing tasks. The service processes the data in parallel, taking advantage of the distributed and scalable nature of Azure Data Lake Storage. - Output and Results:
The results of the job can be stored in Azure Data Lake Storage, written to Azure SQL Data Warehouse, or sent to other Azure services for further analysis or reporting. - Monitoring and Debugging:
Azure Data Lake Analytics provides monitoring and debugging tools to help you track the progress of your jobs, identify errors, and troubleshoot issues. You can monitor job status, view execution logs, and analyze job performance. - Scaling:
The service automatically scales resources up or down based on the complexity and resource requirements of your jobs. This ensures that your jobs run efficiently without manual intervention. - Security and Compliance:
Azure Data Lake Analytics offers robust security features, including role-based access control (RBAC), data encryption, and auditing capabilities. This helps you secure your data and ensure compliance with regulatory requirements. - Cost Management:
You pay for the resources consumed during job execution, making it a cost-effective solution. Azure Data Lake Analytics offers cost monitoring and management tools to help you optimize spending.
Creating an Azure Data lake analytics account.
-
Log into the Azure Portal:
Log in to your Azure account using your credentials at Azure Portal. -
Search for Data Lake Analytics:
- Search for Data Lake Analytics using the search bar.
- Choose Data Lake Analytics from the search results.
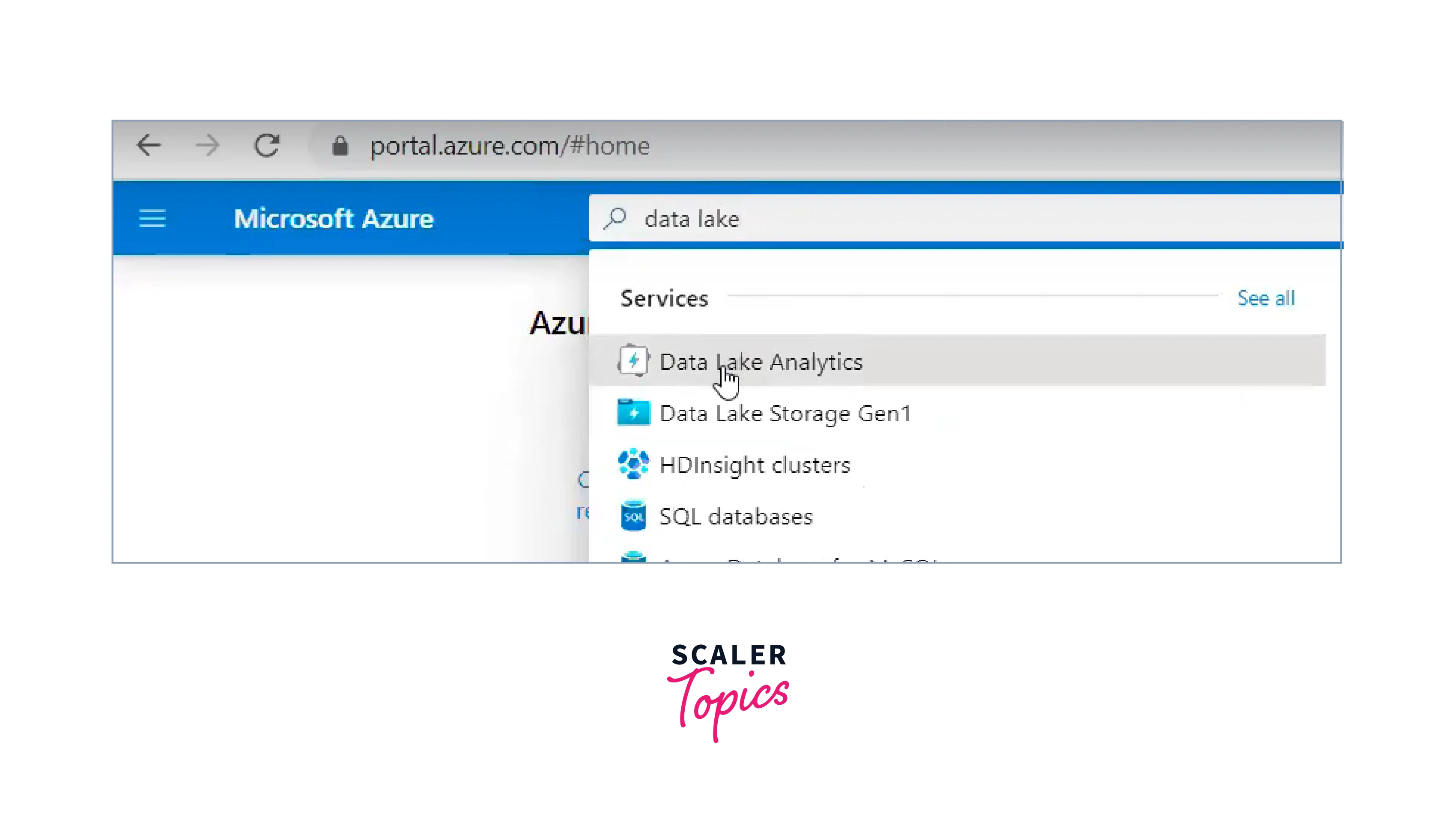
-
Configure Basics:
- You can start the configuration process by hitting the Create button.
- Choose a subscription for your Data Lake Analytics account.
- For the resource group you can either create a new one or choose an existing one.
- Choose a unique account name.
- Select the region where you want to deploy the account.
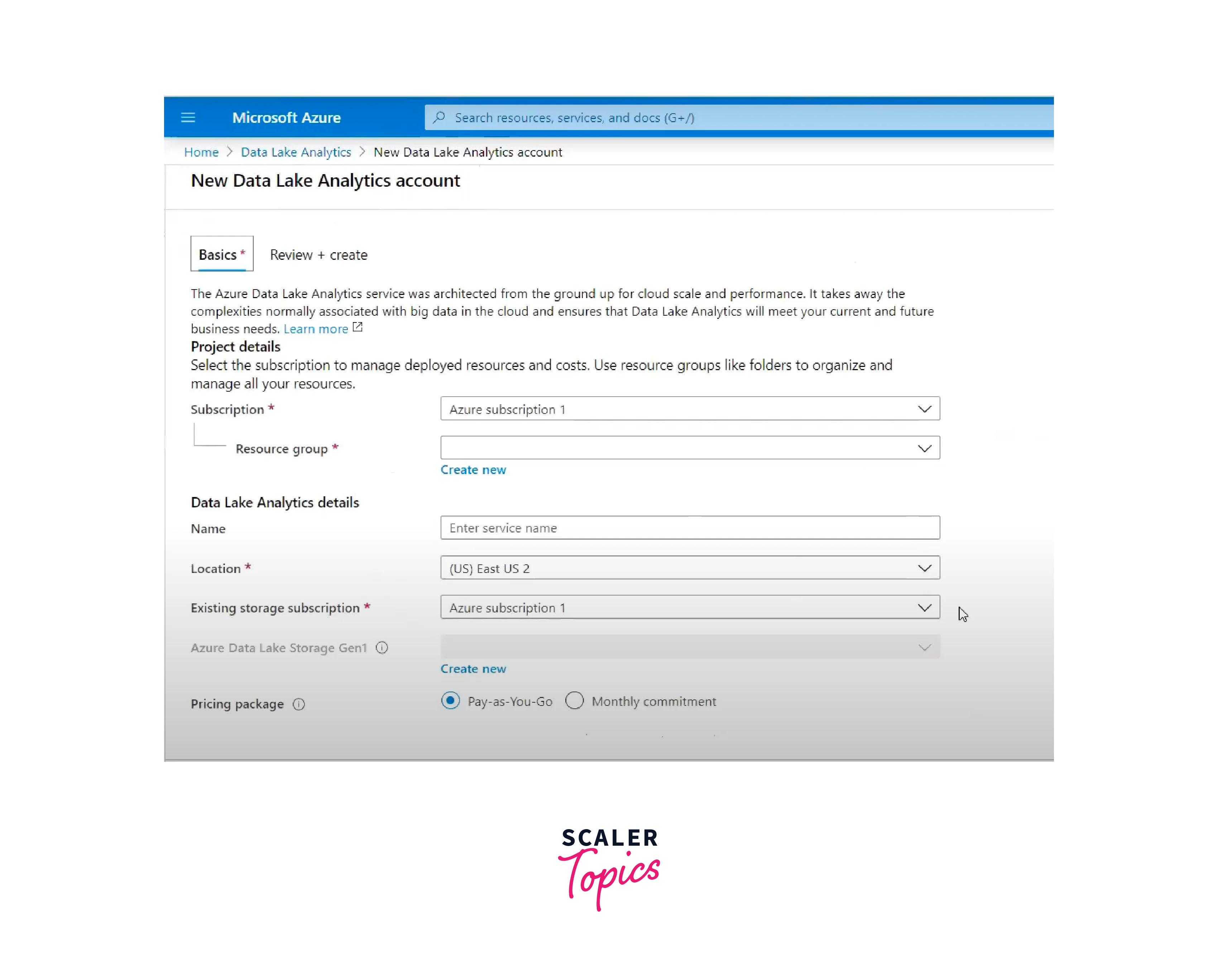
-
Review + Create:
- This page just helps you to review and confirm the configuration settings you want for your resource.
- Click "Create" to create the Azure Data Lake Analytics account. It takes a few minutes for the deployment to be ready.

-
Access the Account:
- Once the deployment is complete, navigate to the Data Lake Analytics account within the Azure portal.
- You can now access the Data Lake Analytics account to start creating and running U-SQL jobs.
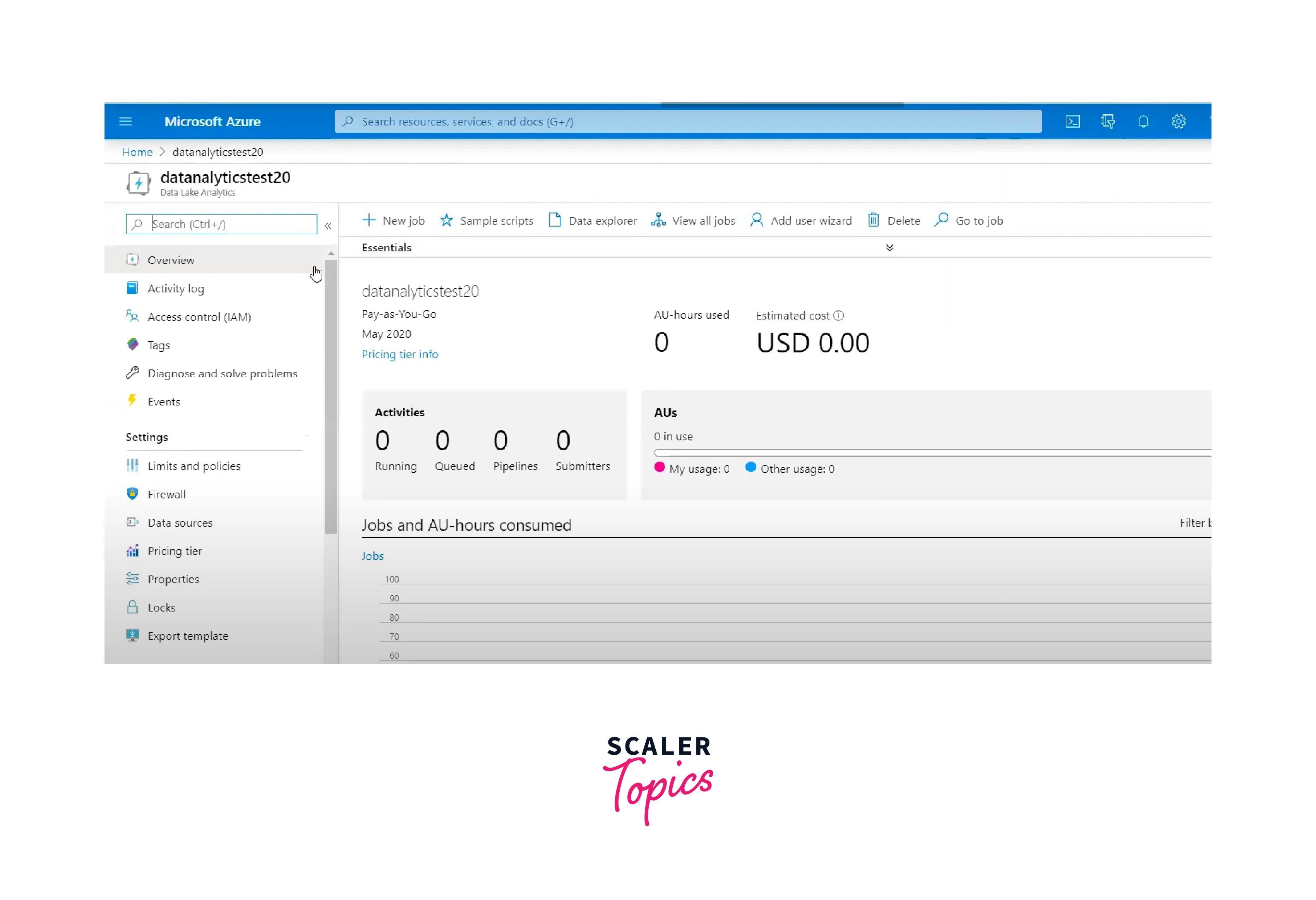
Key Capabilities of Azure Data Lake Analytics
Azure Data Lake Analytics offers several key capabilities for processing and analyzing large volumes of data:
- Scalable Processing:
- Automatically adjusts processing resources to match data volume and complexity.
- Ensures optimal performance and minimizes processing time for large datasets.
- U-SQL Language:
- Combines SQL-like querying for data extraction with C# for custom data transformations.
- Enables powerful data manipulation and analysis on both structured and semi-structured data.
- Distributed Computing:
- Leverages distributed processing across multiple nodes to handle large-scale data analysis.
- Accelerates data processing tasks by dividing workloads into smaller chunks.
- Separation of Storage and Compute:
- Stores data in Azure Data Lake Store or Azure Blob Storage for cost-effective storage.
- Scales compute resources independently to match processing requirements.
- Integration:
- Seamlessly integrates with Azure services like Azure Data Factory, Azure Databricks, and more.
- Creates end-to-end data pipelines for comprehensive data workflows.
- Analytics Scenarios:
- Performs data transformation, cleaning, and enrichment for downstream analytics.
- Aggregates data for reporting, identifying trends, and making data-driven decisions.
- Serverless Execution:
- Eliminates infrastructure management by handling resource provisioning automatically.
- Allows developers to focus on data processing logic rather than infrastructure setup.
- Data Enrichment:
- Combines data from different sources to create enriched datasets.
- Executes complex data transformations to extract meaningful insights.
- Advanced Analytics:
- Supports machine learning models for predictive and prescriptive analytics.
- Performs sentiment analysis, pattern recognition, and anomaly detection.
- Job Orchestration:
- Defines dependencies and sequences of jobs for complex data processing workflows.
- Manages job execution order and ensures efficient data processing.
- Azure Data Lake Analytics (ADLA) manages job dependencies and task sequencing through its Directed Acyclic Graph (DAG) scheduler, which is a fundamental component of its job orchestration mechanism.
- A DAG is a graphical representation of the job's workflow, where nodes represent tasks and edges represent dependencies between tasks. The graph is acyclic, meaning there are no cycles or loops, ensuring that tasks are executed in a specific sequence to avoid circular dependencies.
- Elastic Resources:
- Scales processing resources up or down based on workload fluctuations.
- Optimizes resource usage to balance performance and cost efficiency.
- Secure Data Access:
- Helps to implement high level of authentication and authorization.
- Provides data encryption in transit and at rest to maintain data security.
Conclusion
- Azure Data Lake Analytics (ADLA) is valuable for processing and analyzing large data volumes, complex transformations, and scalability.
- Azure Data Lake Analytics workflow involves writing U-SQL scripts, submitting them as jobs, which are automatically parallelized and executed on large-scale data stored in Azure Data Lake Storage, with results generated and stored in various formats.
- Real-world use cases for Azure Data Lake Analytics include large-scale data processing, ad-hoc analytics, ETL (Extract, Transform, Load) tasks, log analysis, sentiment analysis, and machine learning model scoring on big data.
- Benefits provided by Azure Data Lake Analytics
- Scalability:
Effortlessly handle large data volumes through elastic resource scaling, ensuring smooth processing without hardware limitations. - Parallel Processing:
Accelerate data tasks by distributing workloads across nodes, leveraging parallel processing for faster analytics. - SQL-Like Query Language:
U-SQL combines SQL and C# for powerful and expressive data transformations and analysis on structured and unstructured data. - Integration with Data Lake Storage:
Seamlessly process data from Azure Data Lake Storage, eliminating the need for data movement. - Advanced Analytics:
Integrate with Azure Machine Learning for complex analytics scenarios, enhancing insights through machine learning capabilities. - Managed Service:
Focus on analysis as Microsoft handles infrastructure management, monitoring, and maintenance for hassle-free operations. - Cost Efficiency:
Pay only for consumed resources, optimizing costs compared to provisioning and managing dedicated hardware.
- Scalability: