What is Azure Databricks?
Overview
Azure Databricks, a potent cloud-based platform, streamlines data analytics and machine learning with seamless Microsoft Azure integration. It merges Apache Spark's processing prowess and collaborative tools, accelerating data-driven choices. Databricks Machine Learning extends this, aiding data scientists and ML engineers in translating insights into real-world solutions. Its intuitive interface simplifies the entire ML lifecycle, from data prep to deployment. Databricks offers optimized ML algorithms, automated tuning, and interactive visualizations for agile exploration. Integration with diverse ML frameworks further enhances its capabilities, fostering efficient and impactful applications.
Databricks in Azure
Databricks has emerged as a powerhouse for leveraging the potential of data in the Azure ecosystem in the ever-changing world of data-driven decision-making. Databricks, with its range of capabilities suited to various elements of data management and analysis, enables organisations to transform raw data into useful insights. Let's take a closer look at the main components: Databricks SQL, Databricks Data Science and Engineering, and Databricks Machine Learning.

Databricks SQL
Databricks SQL makes it easier to query and analyze large databases. It is powered by Apache SparkTM and provides a uniform platform for data engineers and analysts to successfully communicate. Even if you're not a coding expert, the interactive workspace allows you to easily create SQL queries. This implies that you can easily extract information from structured and semi-structured data. Real-time visualizations assist in swiftly comprehending data patterns, allowing for timely and informed decisions.
Databricks Data Science and Engineering
This Databricks feature is a one stop solution for data scientists and engineers. Data is translated into usable insights here. The collaborative platform enables teams to easily create, test, and deploy data pipelines. The integrated notebooks support a variety of languages, including Python, Scala, and R, to accommodate a wide range of skill sets. Scalable clusters make resource-intensive operations like feature engineering and model training more efficient, opening the path for novel solutions.
Databricks Machine Learning
Machine learning has been a transformational force in changing data analysis and decision-making across sectors. Its capacity to uncover patterns from huge information and offer predictive insights has transformed how firms function. However, this potential is maximised when machine learning models are quickly produced, cooperatively fine-tuned, and seamlessly deployed at scale.
Databricks Machine Learning emerges as a significant facilitator in this scenario. It leverages the collaborative capability of Azure Databricks, allowing cross-functional teams to design, train, and deploy machine learning models collaboratively. This democratisation of machine learning allows data scientists, engineers, and domain specialists to pool their skills, resulting in more robust and accurate models.
Healthcare is a strong use case that exemplifies this empowerment. Consider the following scenario: medical researchers, data scientists, and physicians work together to develop an AI model that predicts illness outcomes based on patient data. These teams may work concurrently using Databricks Machine Learning, efficiently exchanging findings and refining models. Its automatic hyperparameter tweaking speeds up model optimisation, and its seamless interaction with MLflow makes version tracking and deployment a breeze.
To summarise, Databricks Machine Learning does more than just supply tools; it fosters an ecosystem in which varied skills may converge to generate innovation. Businesses may exploit the real potential of machine learning by enhancing data analysis and decision-making processes to meet complex issues across several domains.
Pros and Cons of Azure Databricks
Azure Databricks has emerged as a resilient solution in the changing world of data processing and analysis, enabling organisations to use big data with finesse. This cloud-based architecture, which combines Apache Spark with Microsoft Azure, has several benefits as well as a few points to consider. Let's look at the advantages and disadvantages of Azure Databricks.
Pros
- Streamlined Collaboration:
Azure Databricks promotes collaborative genius. In a single workspace, teams may collaborate effortlessly, breaking down walls between data engineers, data scientists, and analysts. This collaborative atmosphere improves productivity, decreases confusion, and speeds up project completion. - Scalability Beyond Bounds:
With Azure's underlying prowess, Databricks effortlessly handles vast datasets and intensive workloads. Its auto-scaling function dynamically adjusts resources, providing top performance without the need for user intervention. - Simplified Data Pipelines:
Creating and maintaining ETL (Extract, Transform, Load) pipelines has never been easier. Because of its visual tools and pre-built libraries, Databricks' easy interface allows users to construct pipelines with minimum code. - Advanced Analytics:
Databricks, powered by Apache Spark, enables sophisticated analytics and machine learning at scale. Data practitioners may recover insights that were previously buried in the data flood using techniques ranging from regression analysis to complicated neural networks. - Serverless Flexibility:
Users are freed from infrastructure administration using Azure Databricks. Because it is serverless, you can concentrate on queries, transformations, and analysis without worrying about server deployment or maintenance.
Cons
- Cost Complexities:
While the serverless model decreases operating expenses, expenditures might escalate depending on demand. Organizations must be alert to avoid unforeseen costs, especially if inquiries and data processing are not optimized. - Learning Curve:
While the Databricks interface is simple to use, learning the platform's full capabilities necessitates a significant investment of time and effort. The amount of functionality provided may overwhelm inexperienced users. - Vendor Lock-In:
While leveraging Azure Databricks speeds up integration inside the Azure ecosystem, it may result in vendor lock-in. Migrating complicated Databricks workloads to a new platform may be difficult. - Limited Offline Access:
Databricks is a cloud-native system that relies on internet access. This reliance may impede instances in which offline access to data processing or development environments is required. - Security Considerations:
While Azure provides sophisticated security safeguards, data breaches, and vulnerabilities are always a risk in any cloud environment. Organizations that handle sensitive data must have robust security procedures.
Databricks SQL
Databricks SQL emerges as a strong solution that offers clarity to the difficulties of data processing in the ever-changing field of data management and analytics. This essay looks into the fundamentals of Databricks SQL, highlighting its strengths in data management, computation management, and robust authentication mechanisms.
Data Management
The outstanding data management capabilities of Databricks SQL are at its heart. The days of juggling various data silos and complex pipelines are over. Databricks SQL enters the picture to provide a uniform platform where data from a variety of sources converges harmoniously. Databricks SQL offers easy querying and analysis of data stored in structured databases, semi-structured files, or huge data lakes.
The Lakehouse architecture, a game-changing idea that combines the dependability of data warehouses with the scalability of data lakes, lies at the heart of this data harmony. Delta Lake, a proprietary technique that brings ACID transactions to data lakes, is used by Databricks SQL. This means you can rely on your data for accuracy and consistency while also reaping the scalability benefits that were previously reserved for data lakes.
Computation Management
Databricks SQL's power extends beyond data storage and into compute management. Databricks SQL speeds query processing with its distributed computing platform, guaranteeing that even the most complex analytical queries are handled at lightning speed. This is accomplished by leveraging the powerful Apache Spark engine, which powers Databricks SQL and enables parallel processing and in-memory computing.
In addition, Databricks SQL is designed for data scientists, analysts, and engineers. Its collaborative environment encourages natural interaction, allowing teams to collaborate on the same dataset. The notebook interface allows users to build, visualize, and share their queries, encouraging iterative exploration and improvement.
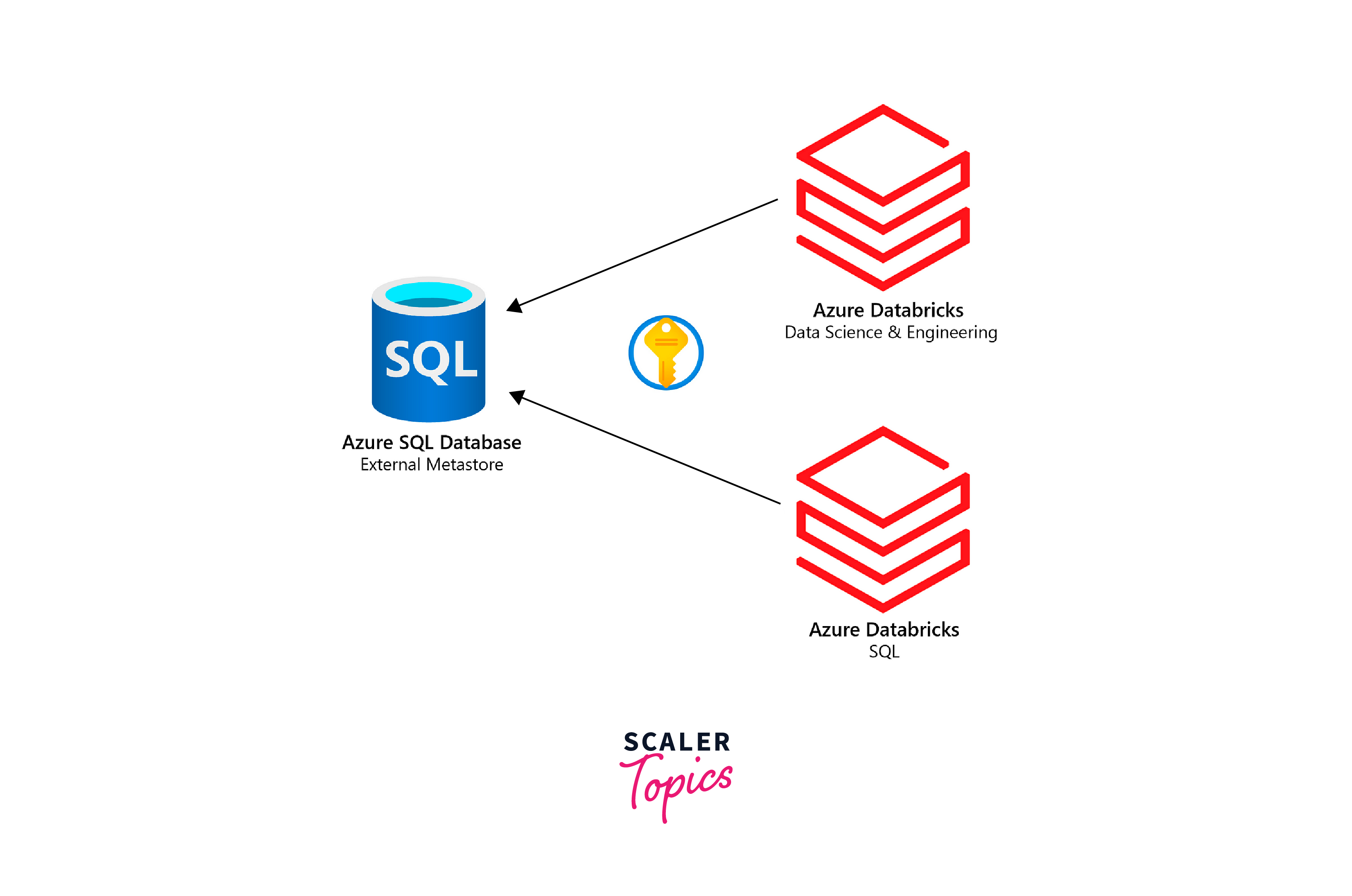
Authorization
In an era where data breaches make news, Databricks SQL stands as a data security fortress. Robust authorization methods are weaved into its fabric to ensure that sensitive data access is scrupulously managed. Fine-grained permissions may be provided using role-based access control (RBAC), defining who can view, alter, or delete certain data assets.
In addition to RBAC, Databricks SQL interfaces with current identity providers to give a unified Single Sign-On (SSO) experience. This implies that users can use their organizational credentials to get access Databricks SQL, streamlining authentication without compromising security.
Databricks Data Science & Engineering
Databricks have emerged as a cornerstone for simplified data science and engineering endeavors in the dynamic arena of modern data-driven organizations. This platform smoothly integrates a variety of features, allowing professionals to get meaningful insights from data and build solid solutions. Let's have a look at the main components of the Databricks ecosystem.
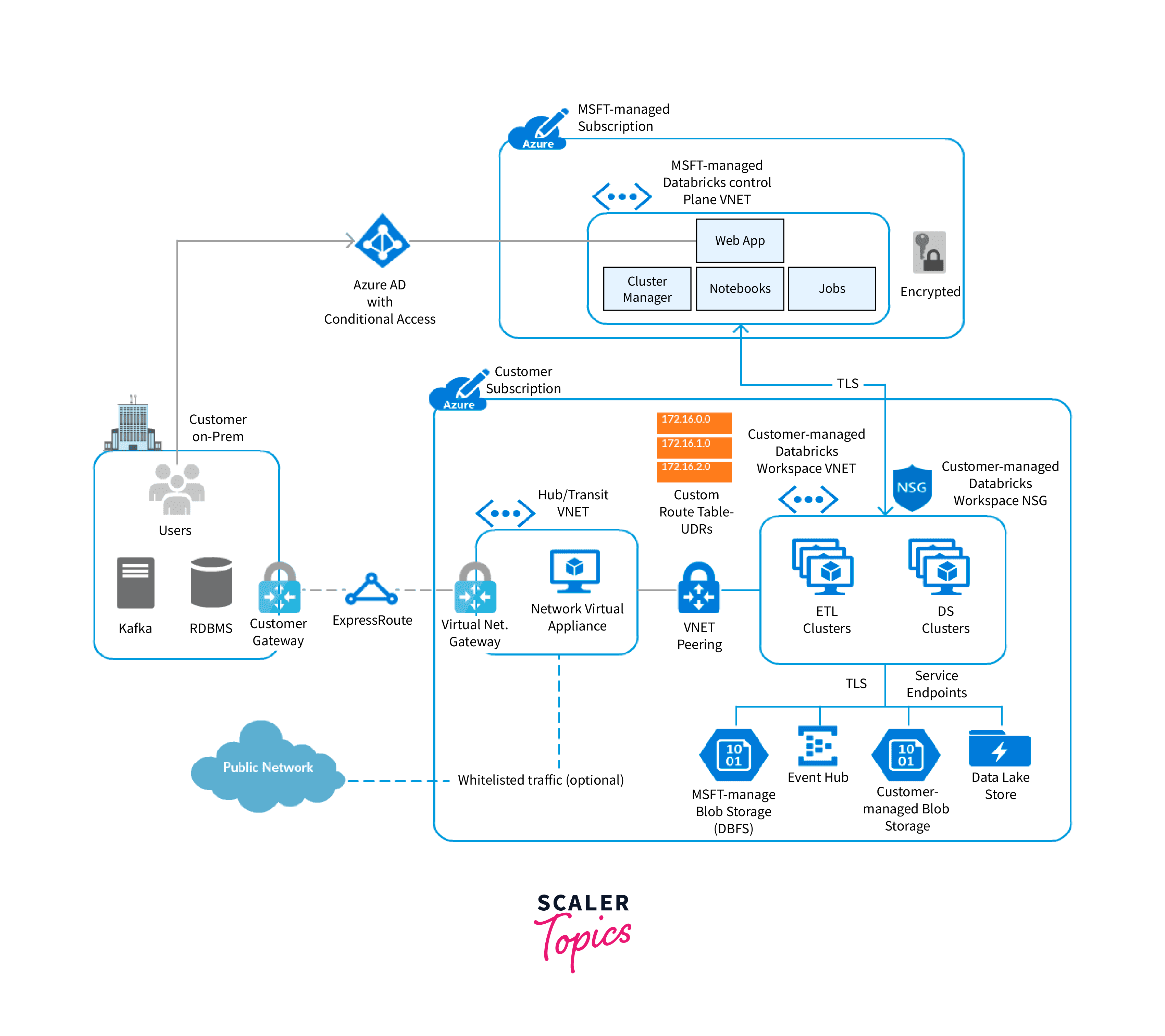
Workspace
The Databricks Workspace serves as a digital canvas for the delicate craftsmanship of data science and engineering. It's a simple web-based platform where teams can interact, explore, and create. Consider it a virtual workshop where data analysts, engineers, and scientists can get together to brainstorm ideas, discuss code, and fine-tune techniques.
Interface
The Databricks interface offers a simple method to access the platform's arsenal. Its interactive design promotes a fluid workflow, allowing users to move easily between project phases such as data exploration transformation and model deployment. This interface eliminates the steep learning curve, allowing experts to concentrate on the problem-solving process rather than the tool.
Data Management
A solid data management system is at the heart of Databricks. This feature allows for simple data ingestion, storage, and organization. It enables teams to rapidly aggregate data from different sources, cleanse and prepare it for analysis, and store it. Data engineers and scientists may devote more effort to extracting insights now that data administration has been simplified.
Computation Management
Databricks improve computation management by utilizing distributed computing. This under-the-hood wizardry distributes difficult operations over numerous processors, significantly lowering processing time. This distributed technique enables enormous datasets and sophisticated calculations to be handled without breaking a sweat.
Databricks Runtime
Databricks Runtime is the engine powering your data science vehicle. It is a full environment with pre-packaged libraries that are optimized for performance. This avoids the time-consuming job of setting environments, allowing practitioners to concentrate on model construction, analysis, and innovation.
Job
Within Databricks, the Job feature automates repeated processes. It's like having a dedicated helper that conducts planned operations, such as data import, model training, and report production. Jobs guarantee that important procedures are carried out consistently and reliably.
Model Management
Model management is critical in the field of machine learning. Databricks provides model deployment, monitoring, and versioning tools. This enables data scientists to go easily from model experimentation to real-world deployment while keeping a close watch on model performance.
Authorization and Authentication
In the digital world, security is a top priority. Databricks emphasizes this by providing strong authentication and permission protocols. This guarantees that only authorized individuals have access to sensitive data and functionality, protecting the organization's intellectual assets' integrity and privacy.
Databricks Machine Learning
Databricks Machine Learning stands out in the ever-changing field of data science as a strong platform that enables organisations to realize the full potential of their data. Databricks Machine Learning is, at its heart, a collaborative environment that merges data engineering and sophisticated analytics.
This platform allows data engineers, data scientists, and machine learning engineers to collaborate on projects in a unified workspace. Databricks streamlines data pretreatment, transformation, and feature engineering by using Apache Spark's distributed computing capabilities. Its AutoML capabilities make model selection and hyperparameter tuning easier, especially for individuals unfamiliar with machine learning.
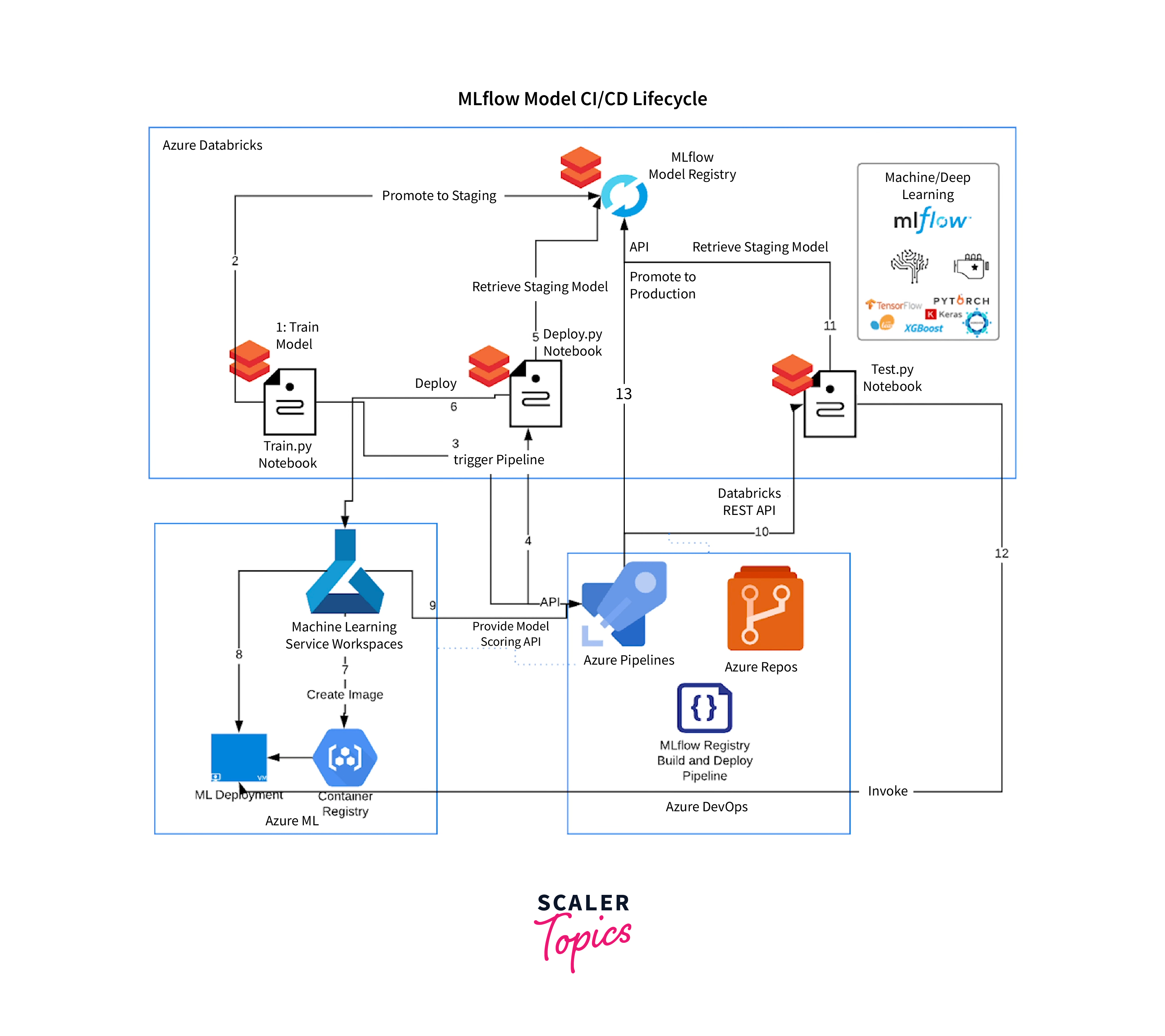
Databricks Machine Learning does not end at experimentation; via MLflow integration, it smoothly expands models to production. This guarantees that significant data insights are turned into real-world effects. It supports a broad range of tech stacks by integrating with major libraries and languages.
Conclusion
- Azure Databricks integrates data processing, machine learning, and collaborative exploration, bridging data engineering and data science on one platform.
- Azure Databricks makes use of Apache Spark for seamless large data management, providing rapid processing, real-time analytics, and simplified infrastructure administration, freeing teams to focus on data insights.
- Azure Databricks maximizes data processing via Spark's distributed capabilities for quick analytics and real-time insights.
- Azure Databricks Platform automates infrastructure, allowing focus on data value extraction, not resource setup complexity.