Azure Data Bricks
Overview
Microsoft Azure Data bricks is a cloud-based big data analytics and machine learning platform. It combines Apache Spark, a powerful data processing engine, with a collaborative workspace that enables data engineers, data scientists, and analysts to work together seamlessly. Azure Databricks allows users to process and analyze large datasets, build machine learning models, and gain valuable insights from their data efficiently and at scale.
Need of Azure DataBricks
Let's consider a scenario to understand where Azure Databricks comes into the picture:
A retail company is experiencing rapid growth and collecting large volumes of data from various sources, including online sales, customer interactions, and inventory management. They are struggling to analyze and process this data effectively due to the scale and complexity involved. The company's existing data infrastructure is unable to handle the massive amounts of data, leading to slow query performance and increased costs for managing on-premises resources.
In this situation, the retail company requires a scalable and efficient data analytics platform that can handle big data workloads, perform complex data processing, and support advanced analytics and machine learning. Azure Databricks emerges as the ideal solution, offering a unified analytics platform that combines Databricks SQL, Data Science and Engineering, and Machine Learning components.
By adopting Azure Databricks, the retail company gains the ability to:
- Efficient Data Processing:
Azure Data bricks utilizes the power of Apache Spark, a distributed data processing engine, to handle large volumes of data efficiently. Spark's parallel processing capabilities allow the retail company to process and transform data at scale, reducing processing times and improving overall efficiency. - SQL Queries:
With Databricks SQL, the retail company's analysts and data professionals can write SQL queries to access and analyze massive datasets. This familiar query language enables them to quickly gain insights from the collected data without needing to learn complex programming languages. - Collaborative Workspace:
Databricks provides a collaborative workspace where data engineers, scientists, and analysts can work together seamlessly. They can develop, test, and deploy data pipelines, machine learning models, and analytical workflows within a unified environment, fostering efficient teamwork and knowledge sharing. - AutoML:
Databricks Machine Learning simplifies the process of building and deploying machine learning models. AutoML capabilities help the retail company automate various aspects of model development, such as feature selection, hyperparameter tuning, and model selection. This accelerates the deployment of machine learning solutions, even for users without extensive data science expertise. - Auto-Scaling:
Azure Databricks provides the flexibility of auto-scaling resources based on demand. During periods of increased data processing requirements, resources can automatically scale up to ensure optimal performance. Conversely, during quieter times, the platform can scale down to save on costs by allocating resources only as needed.
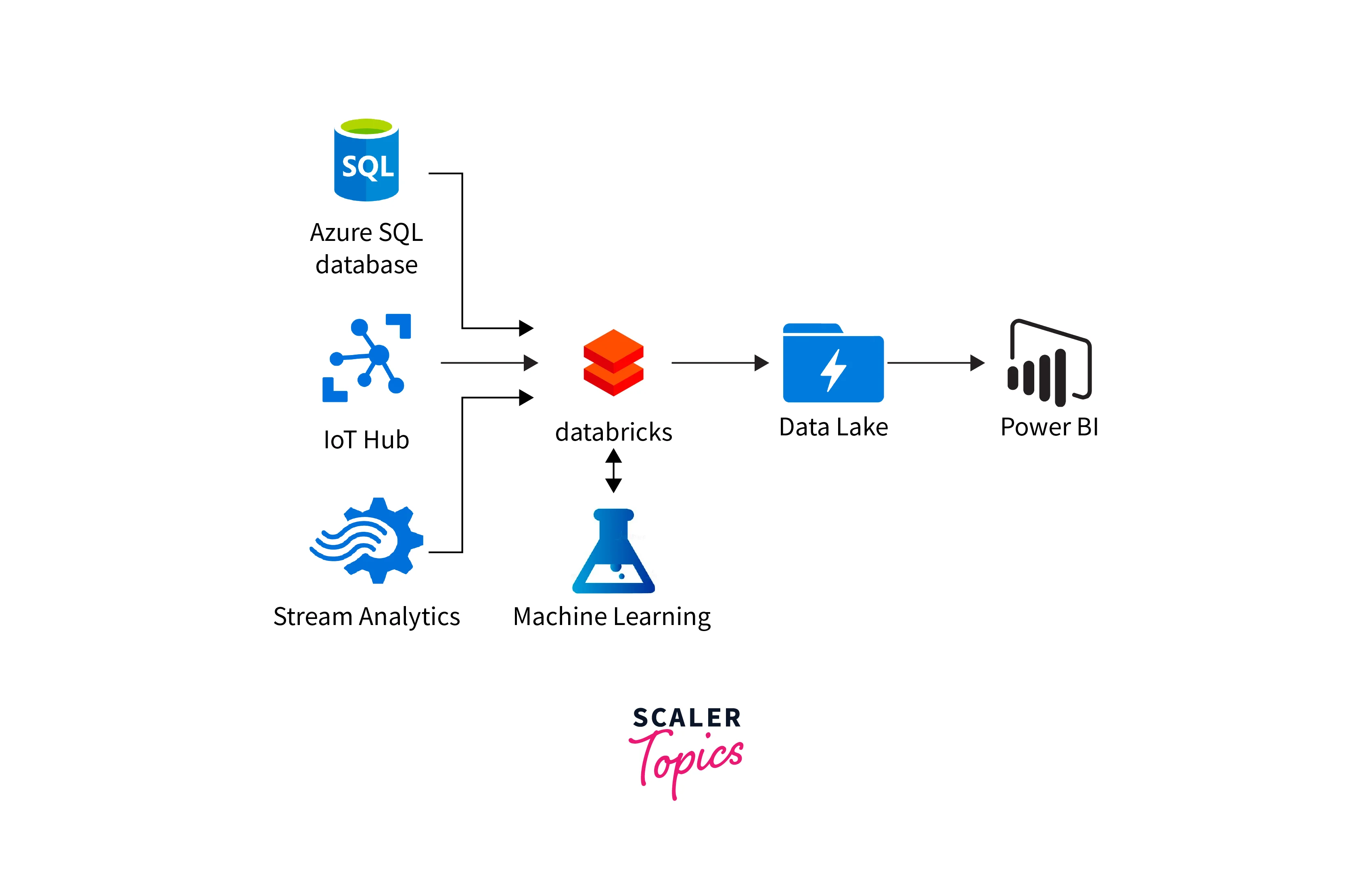
Databricks in Azure
Azure Data Bricks is a versatile data analytics and processing platform designed to handle a diverse range of data types and formats. It empowers organizations to gain insights from various data sources, enabling efficient analysis and exploration.
![]()
Some of the data types that Azure Databricks can effectively handle include:
- Structured Data:
Azure Databricks can seamlessly process structured data, which is organized into rows and columns. This data type is common in relational databases, spreadsheets, and CSV files. Databricks enables users to perform SQL-like queries and aggregations on structured data sources, facilitating efficient analysis and reporting. - Semi-Structured Data:
With support for semi-structured data formats like JSON, XML, and Parquet, Azure Databricks can manage data that doesn't adhere to a rigid schema. This flexibility is especially valuable when working with data that evolves or originates from diverse sources. - Unstructured Data:
Databricks go beyond structured and semi-structured data by enabling the processing of unstructured data. This category includes text, images, audio, and video files. While unstructured data lacks the uniformity of structured data, Databricks can extract meaningful insights from textual content and perform image and audio analysis, opening doors to sentiment analysis, image recognition, and more.
Azure Databricks is a comprehensive data and AI platform that offers three main components: Databricks SQL, Databricks Data Science and Engineering, and Databricks Machine Learning. Let's talk about each of them in detail.
Databricks SQL
This component provides a unified analytics platform that enables users to run SQL queries directly on data lakes and other data sources, making it easy to access and analyze large datasets with familiar SQL syntax. Some of its features include:
- Data engineers, data scientists, and analysts can use a unified analytics platform.
- Run SQL queries directly on data lakes and various data sources.
- Leverages Apache Spark for efficient and scalable query processing.
- Optimizes data lake access with Delta Lake technology.
- Supports data virtualization for seamless data querying and joining.
Databricks Data Science and Engineering
This aspect of Databricks allows data engineers and data scientists to collaborate on building and managing data pipelines, perform exploratory data analysis, and create advanced analytics solutions using Apache Spark and Python/Scala notebooks. Some of its features include:
- Data engineers and data scientists can work together in this collaborative workspace.
- Notebooks supporting Python, Scala, SQL, and more for flexible data analysis.
- Data processing using Apache Spark for large-scale data operations.
- Design, schedule, and manage data pipelines for data movement and transformation.
- Access to machine learning libraries for building and training models.
Databricks Machine Learning
This feature empowers data scientists to develop and deploy machine learning models at scale. It provides an integrated environment to explore data, experiment with various algorithms, and deploy production-ready models with ease. Some of its features include:
- AutoML and hyperparameter tuning for efficient model building.
- Centralized model registry for tracking and versioning models.
- Seamless model deployment and serving with integrations to Azure services.
- Deep integration with MLflow for managing the machine learning lifecycle.
- MLOps capabilities for model governance and collaborative development.
Pros and Cons of Azure Databricks
Advantages of Azure Databricks
The advantages of using Azure Databricks are:
- Scalability and Performance:
Azure Databricks leverages the power of Apache Spark, enabling high-performance data processing and analytics at scale. It can handle large volumes of data efficiently, making it suitable for big data workloads. - Unified Platform:
Databricks provides a unified environment for data engineers, data scientists, and analysts to collaborate. This integration fosters seamless data workflows and promotes cross-functional collaboration. - Fully Managed Service:
Azure Databricks is a fully managed service, meaning Microsoft handles infrastructure provisioning, setup, and maintenance. Users can focus on data analysis and modeling without worrying about infrastructure management. - Auto-Scaling:
Databricks can automatically scale resources up or down based on workload demands. This guarantees that resources are used efficiently and effectively. - Optimized for Data Lake Storage:
Databricks is designed to work well with Azure Data Lake Storage, providing optimized performance and reliability for data stored in data lakes. - Delta Lake Integration:
Databricks natively supports Delta Lake, which adds transactional capabilities to data lakes. It enables ACID transactions, data versioning, and schema evolution, enhancing data reliability and manageability. - Rich Ecosystem:
Azure Databricks integrates seamlessly with other Azure services, such as Azure Machine Learning, Azure Data Lake Storage, and Azure Synapse Analytics, allowing users to leverage a wide range of tools and services. - Collaborative Workspace:
The notebook-based workspace encourages collaboration between team members, making it easier to share code, insights, and best practices.
Disadvantages of Azure Databricks
Cons of Azure Data Bricks:
- Cost:
While Databricks offers excellent features, it can be relatively expensive compared to self-managed Apache Spark clusters. Users should carefully consider their workload requirements and budget constraints. - Learning Curve:
For those new to Apache Spark or big data technologies, there can be a learning curve associated with using Databricks effectively. Training and familiarization may be required for some team members. - Vendor Lock-In:
Choosing Azure Databricks may tie an organization to the Azure ecosystem, limiting portability to other cloud platforms. - Limited Control:
While Databricks handles most of the infrastructure management, it also means users have less control over the underlying infrastructure and configuration. - Service Availability:
Reliance on a cloud service can lead to potential downtime if there are issues with the service or the cloud provider. - Data Transfer Costs:
When using Databricks with data stored in other cloud services, data transfer costs may add to the overall expenses.
Databricks SQL
Databricks SQL is a unified analytics platform that enables users to run SQL queries directly on data lakes and various data sources, leveraging the power of Apache Spark for scalable and efficient data processing.
Data Management
- Supports data ingestion from diverse sources, including data lakes, databases, and external files.
- Users can create and manage tables and views to organize and represent the data in a structured manner.
- Utilizes Delta Lake technology to optimize data lake access, providing features like ACID transactions and schema evolution for reliable data management.
Computation Management
- Leveraging the underlying capabilities of Apache Spark, Databricks SQL performs data processing and analytics using SQL queries efficiently and at scale.
- Spark's distributed computing capabilities allow for parallel execution of queries, enabling faster data processing on large datasets.
- Databricks SQL automatically optimizes query execution plans to enhance performance and improve query response times.
Authorization
- Databricks SQL integrates with Azure Active Directory to enforce authentication and authorization controls for user access.
- Role-Based Access Control (RBAC) allows administrators to define granular permissions, ensuring data privacy and preventing unauthorized access.
- Users can securely collaborate in the workspace, sharing queries and insights with authorized team members while restricting access for others.
Databricks Data Science & Engineering
Databricks Data Science & Engineering is a collaborative workspace that empowers data engineers and data scientists to work together seamlessly, providing tools and features to manage data, perform computations, and build advanced analytics solutions.
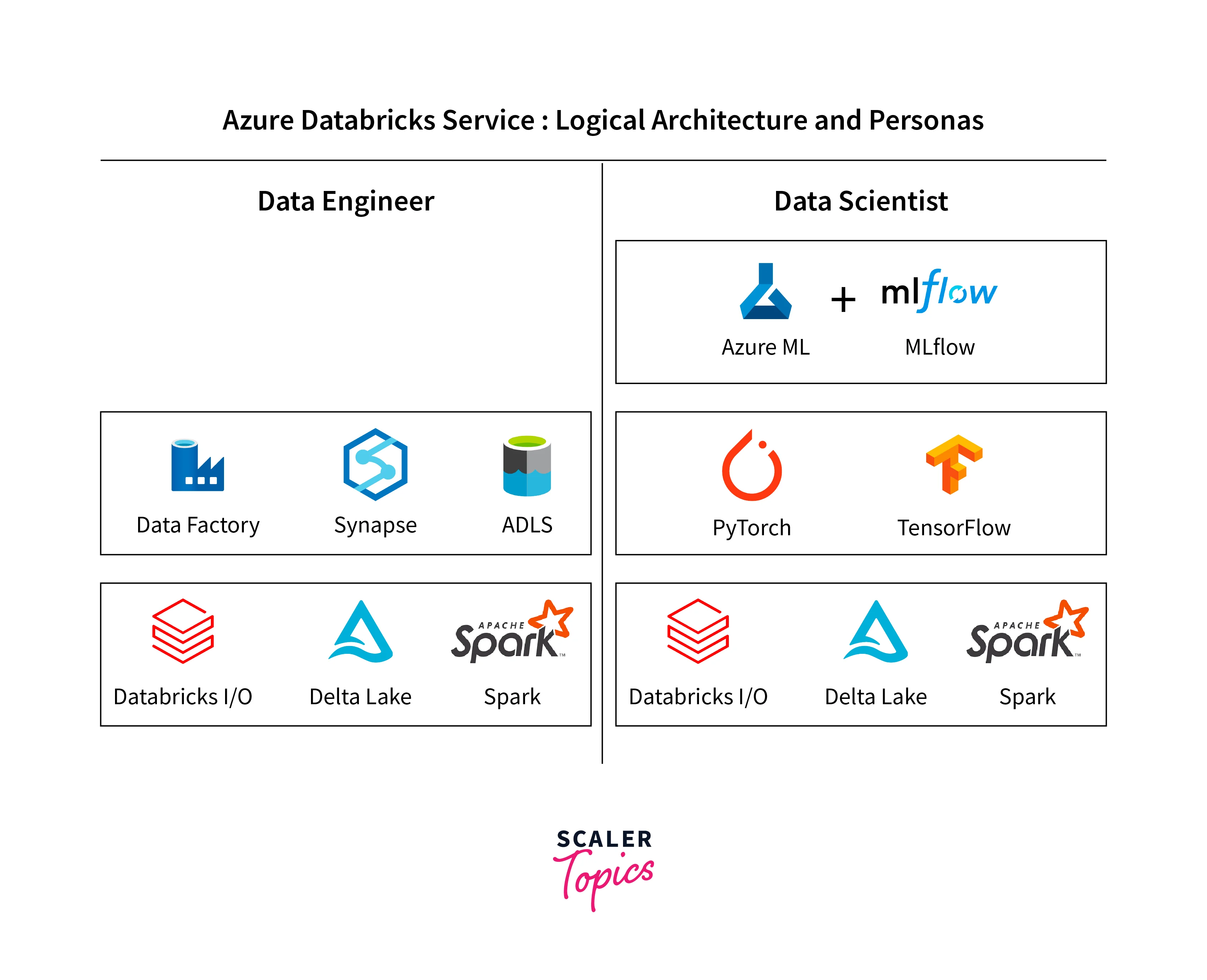
Workspace
- Offers a collaborative workspace with notebooks, where data engineers and data scientists can create and share code, queries, and visualizations.
- Supports multiple programming languages such as Python, Scala, SQL, R, and more, allowing users to leverage their preferred language for data exploration and analysis.
- Encourages version control and collaboration with features like Git integration and interactive notebooks.
Interface
- Provides an interactive web-based interface that allows users to interact with data, code, and visualizations, simplifying the process of exploring and analyzing data.
- The interface is user-friendly and accessible, making it suitable for both data experts and business users.
Data Management
- Facilitates data management by allowing users to connect to various data sources like data lakes, databases, and cloud storage platforms.
- Supports data ingestion, storage, and organization using tables and views, providing a structured representation of the data.
- Integrates with Delta Lake, enabling advanced data reliability, versioning, and ACID transactions.
Computation Management
- Leverages the power of Apache Spark to perform data processing and analytics tasks efficiently and at scale.
- Allows users to execute complex data transformations, aggregations, and machine learning workflows using Spark's distributed computing capabilities.
- Automatically optimizes query execution plans for better performance and faster results.
Databricks Runtime
- Databricks Runtime is the optimized runtime environment provided by Databricks, pre-configured with all necessary libraries and optimizations for efficient data processing and machine learning.
- It comes in different versions and is continuously updated to include the latest improvements and enhancements.
Job
- Enables users to schedule and manage data engineering and data science tasks as jobs, automating repetitive tasks and workflows.
- Jobs can be set to run on a regular schedule or triggered based on certain events, making it easier to manage data pipelines and analytical processes.
Model Management
- Provides features for managing machine learning models throughout their lifecycle, from training and evaluation to deployment and monitoring.
- Users can track and version models, making it easy to reproduce results and ensure model governance.
Authentication and Authorization
- Integrates with Azure Active Directory for secure authentication, ensuring that only authorized users can access the platform.
- Role-Based Access Control (RBAC) allows administrators to define user permissions and access levels, ensuring data security and compliance.
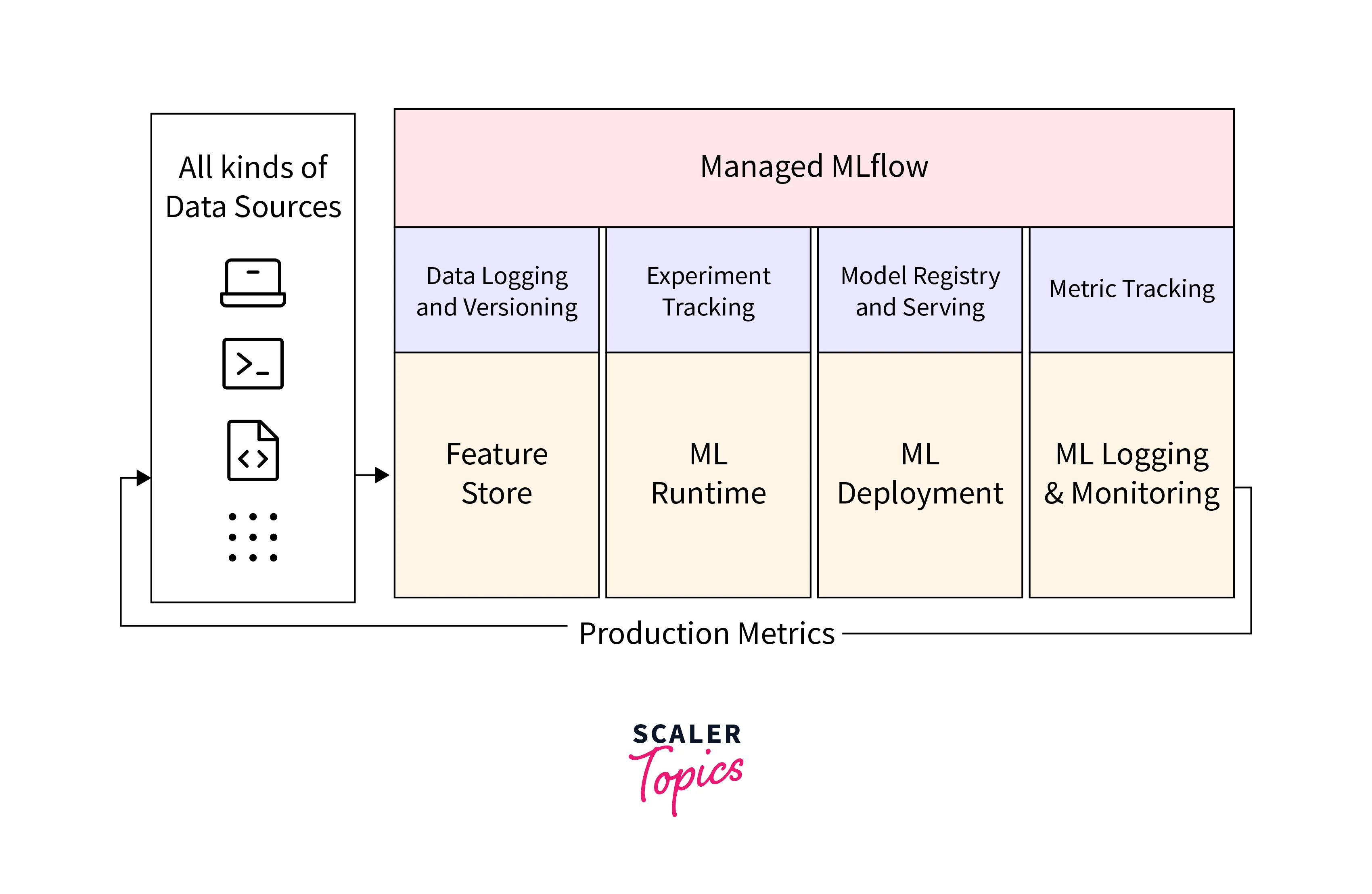
Databricks Machine Learning
Databricks Machine Learning is a comprehensive set of tools and capabilities that empower data scientists to develop, train, and deploy machine learning models at scale, all within the Databricks platform.
Automated Machine Learning
- Databricks AutoML automates the process of building machine learning models by automatically selecting the best algorithms, hyperparameters, and feature engineering techniques.
- AutoML helps data scientists save time and effort in the model development process, making it easier to experiment with different approaches and identify the most effective solutions.
Model Development and Training
- Databricks provides a rich set of machine learning libraries and frameworks, such as MLlib, Scikit-learn, TensorFlow, and XGBoost, allowing data scientists to leverage their preferred tools for model development.
- The platform supports distributed computing through Apache Spark, enabling the training of large-scale machine learning models on big datasets.
Model Tracking and Versioning
- Databricks enable data scientists to track and manage model versions effectively, ensuring reproducibility and making it easy to compare different iterations of models.
- Model versioning simplifies collaboration among team members and facilitates model governance.
Model Deployment and Serving
- Databricks make it easy to deploy trained machine learning models into production. Models can be deployed as RESTful endpoints for real-time predictions or batch-scoring jobs for bulk predictions.
- Integrations with Azure Kubernetes Service (AKS) and Azure Machine Learning Service (AML) provide options for scalable and efficient model deployment.
MLOps Capabilities
- Databricks Machine Learning promotes MLOps practices by providing features for managing the entire machine learning lifecycle.
- It allows teams to collaborate effectively, version control models, track experiments, and automate workflows to improve productivity and ensure the reliability of machine learning applications.
Integration with MLflow
- Databricks integrates seamlessly with MLflow, an open-source platform for managing the machine learning lifecycle.
- MLflow enables users to package code, environment, and data to reproduce experiments and share results across different platforms.
Pricing of Azure Databricks
Azure Databricks pricing can be a bit complex, as it involves multiple factors such as instance types, usage, and additional features. Here's an overview of the pricing components:
- Databricks Units (DBUs):
Azure Databricks pricing is based on Databricks Units (DBUs). DBUs are a unit of processing capability per hour and are used to measure the compute resources consumed by your workloads. Different instance types have different DBU costs associated with them. - Instance Types:
Azure Databricks offers different instance types optimized for various workloads, including standard instances for data engineering and analytics, and GPU instances for machine learning and AI workloads. Each instance type comes with a specific DBU cost. - Cluster Configuration:
The number of nodes and their configurations in your clusters impact pricing. Larger clusters with more nodes and higher compute resources will have higher costs. - Usage:
You are billed based on the actual usage of Databricks clusters, meaning you are charged for the hours your clusters are running. If you auto-scale or shut down clusters when not in use, you can control costs. - Storage:
Azure Databricks also utilizes Azure Blob Storage for data storage. Storage costs for your data are separate from Databricks compute costs. - Additional Features:
Azure Databricks offers premium features like Delta Lake and MLflow for advanced data management and machine learning. These features may have associated costs. - Support Plans:
Depending on your needs, you can choose different levels of support plans, which may impact your overall costs.
Latest Features of Azure Databricks
Recent features added to Azure Data bricks include:
- Delta Lake Integration:
Azure Data bricks has incorporated Delta Lake as a foundational storage layer within the Databricks Lakehouse Platform. - Transaction Log and ACID Transactions:
Delta Lake extends Parquet data files with a transaction log, enabling ACID transactions and scalable metadata management. - Delta Tables by Default:
All tables created on Azure Databricks are now Delta tables by default, offering benefits like data versioning and improved metadata handling. - Open Transaction Log Protocol:
Delta Lake's transaction log protocol is open and accessible, allowing any system to read the log for data accessibility and interoperability. - Enhanced Data Management:
The integration of Delta Lake with Databricks SQL enables various operations, including creating, reading, writing, updating, and querying data. - Delta Live Tables:
This feature simplifies ETL development by managing data flow between Delta tables. It supports both batch and streaming operations on the same table.
Conclusion
- Azure Data Bricks is a comprehensive data and AI platform in Azure, comprising three main components: Databricks SQL, Databricks Data Science and Engineering, and Databricks Machine Learning.
- Databricks SQL provides a unified analytics platform, enabling SQL queries on data lakes and various sources, powered by Apache Spark and Delta Lake.
- Databricks Data Science and Engineering is a collaborative workspace supporting notebooks in Python, Scala, SQL, and more, with features for data management, computation, and job scheduling.
- Databricks Machine Learning offers automated ML, model development, deployment, tracking, and integration with MLflow, empowering data scientists with efficient machine learning workflows.