Azure Data Explorer
Overview
Azure Data Explorer (ADX) presents itself as a robust and highly dynamic PaaS (Platform as a Service) solution from Microsoft's Azure suite, offering comprehensive data exploration services for large-scale data. In an era where the infusion of rapid data influx and expedited analytics is pivotal, Azure Data Explorer facilitates users in scrutinizing voluminous datasets, eliciting pivotal insights promptly, and shaping logical, data-driven decisions. Culling data from varied sources, it enables users to coalesce, analyze, and visualize data expeditiously, ensuring an organization can delve deep into the complex data landscape effortlessly.
What is Azure Data Explorer?
Azure Data Explorer, often abbreviated as ADX, is an end-to-end service provided by Microsoft Azure, crafted specifically for real-time analysis of large volumes of data. The platform is optimized for ad-hoc data querying and exploration, making it a highly sought-after tool for organizations aiming to derive rapid insights from their vast repositories of structured and semi-structured data.
How does It Work?
Azure Data Explorer service essentially embarks on three pivotal steps, as illustrated in this diagram:
-
Creation of a Cluster and Database:
This step involves setting up the foundational architecture, which will house the data. The cluster, in Azure Data Explorer's ecosystem, is a combination of compute and storage resources. Within each cluster, a database is created, which is the elemental unit for managing and storing data. The symbolic representation in the image shows interconnected blocks, possibly indicating the integrated and structured nature of the cluster and database.
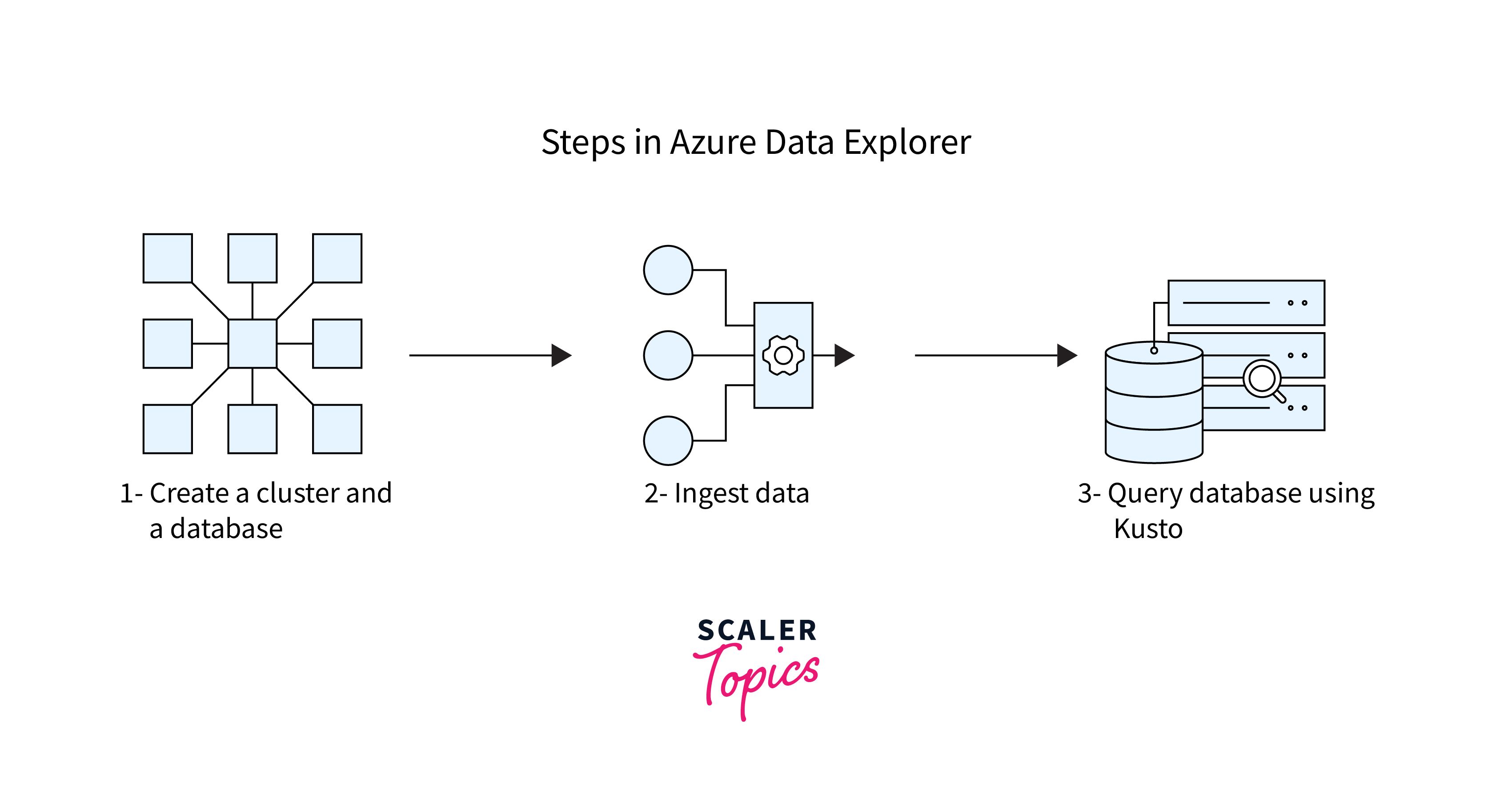
-
Ingestion of Data:
Once the cluster and database are ready, the next pivotal step is to ingest data into Azure Data Explorer. The process involves importing data from various sources, be it real-time streams, logs, or bulk data sources. This is depicted by the interlinked chain or molecule-like structure, suggesting the interconnected nature of data sources and their seamless integration into the Azure Data Explorer system.
-
Querying Database using Kusto:
After data ingestion, the data residing within the database can be queried, analyzed, and visualized. Azure Data Explorer employs a specialized query language known as Kusto Query Language (KQL). Kusto aids users in diving deep into their data, extracting valuable insights, and even visualizing the results.
Key Components of Azure Data Explorer
The Azure Data Explorer (ADX) has multiple components that work in harmony to offer a powerful and efficient data exploration service. Here are the key components:
-
Cluster:
This is the fundamental unit of compute and storage resource in ADX. A cluster serves as a container for one or more databases. Each cluster consists of a set of compute nodes and provides the necessary resources to run the queries and manage the data.
-
Database:
Within a cluster, the data is stored in databases. A database is the primary unit for managing resources in ADX. It contains the tables, metadata, and data that you ingest.
-
Table:
Databases are further organized into tables. Each table in ADX has a schema that defines the structure of the data, including columns and their respective data types. Tables store the data in a structured format.
-
Mapping:
When ingesting data from diverse sources, mappings define the transformation rules. It helps translate the source data format into the table schema, ensuring that data ingested adheres to the structure of the table in the database.
-
Kusto Query Language (KQL):
This is the heart of the data exploration capability in ADX. KQL is a rich and expressive language that allows users to query large datasets and retrieve meaningful results in real-time. It provides a wide array of operators and functions to manipulate and visualize data.
Creating Azure Data Explorer Cluster
Creating a cluster in Azure Data Explorer is the foundational step before you can ingest and analyze data. Here's a step-by-step guide on how to set up your Azure Data Explorer Cluster:
Creating a Database
To initiate a cluster in Azure Data Explorer, follow the process as you would when setting up any Azure resource. Start by:
-
Logging into the Azure Portal
-
Navigate to the search bar and type 'Azure Data Explorer cluster', then select "Create".
-
Input essential details, including your subscription, desired Resource group (or create a new one), and your ADX cluster name. Consider the pricing details and select the appropriate tier. For demonstration purposes, opt for a lower-priced specification like the development tier (Dev D11). It's essential to be cautious and not use such tiers for production deployments.
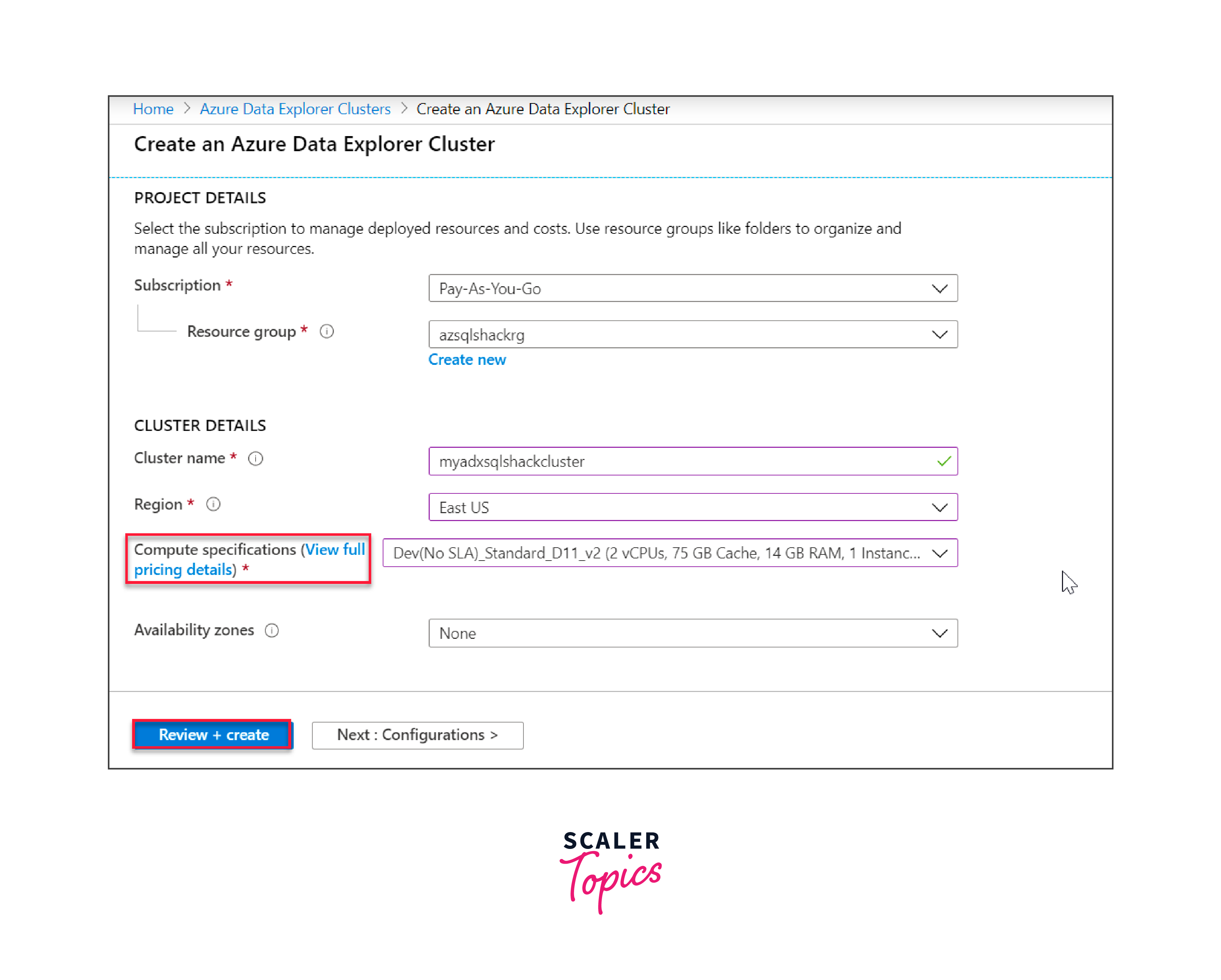
Click on 'Review + create' to inspect the cluster's details and finalize its creation.
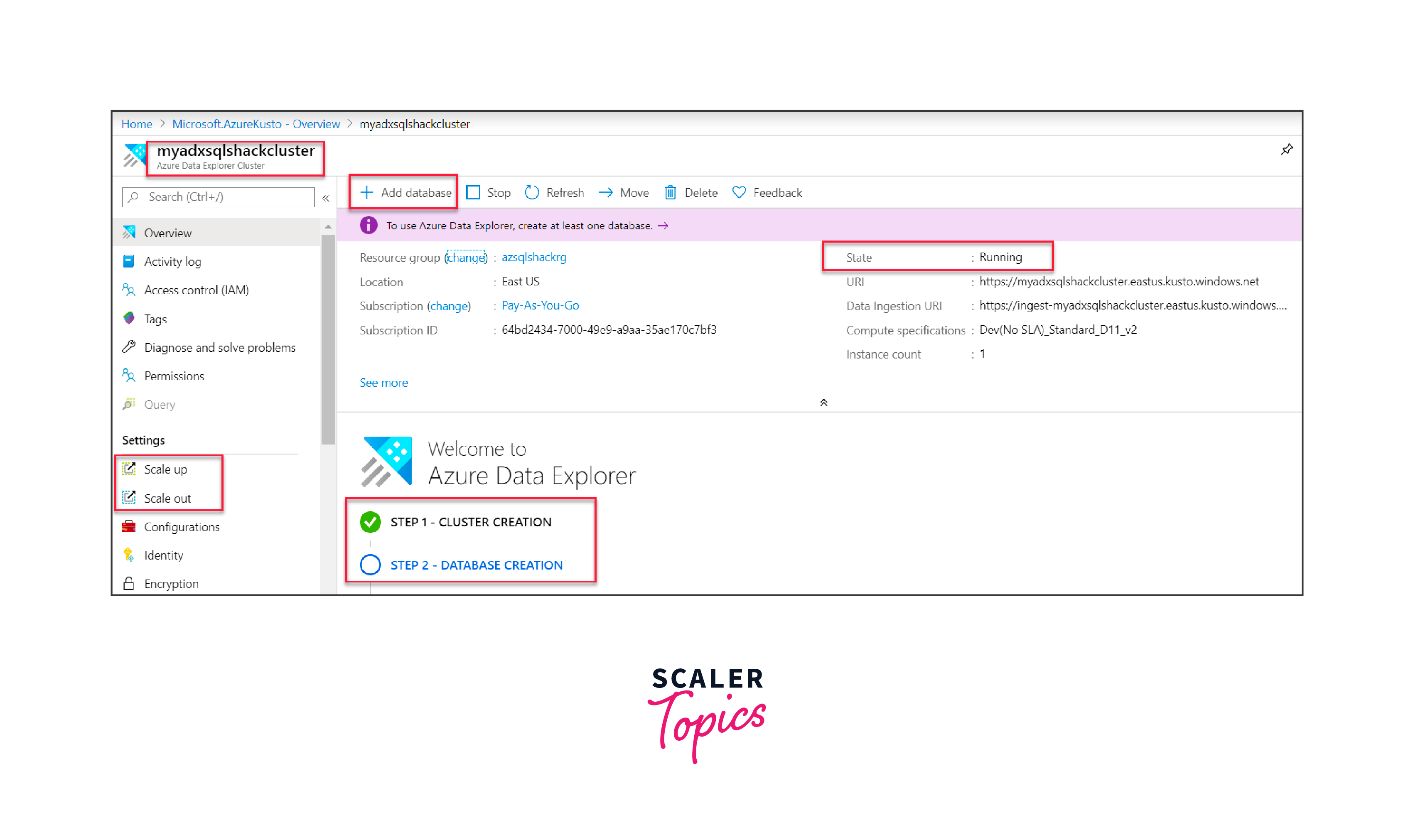
Your newly-created cluster, say "myadxsqlshackcluster", should now be operational. From here, you have the flexibility to scale it based on your specific needs.
To set up a database:
-
Navigate to the next step by clicking on "Add database".
-
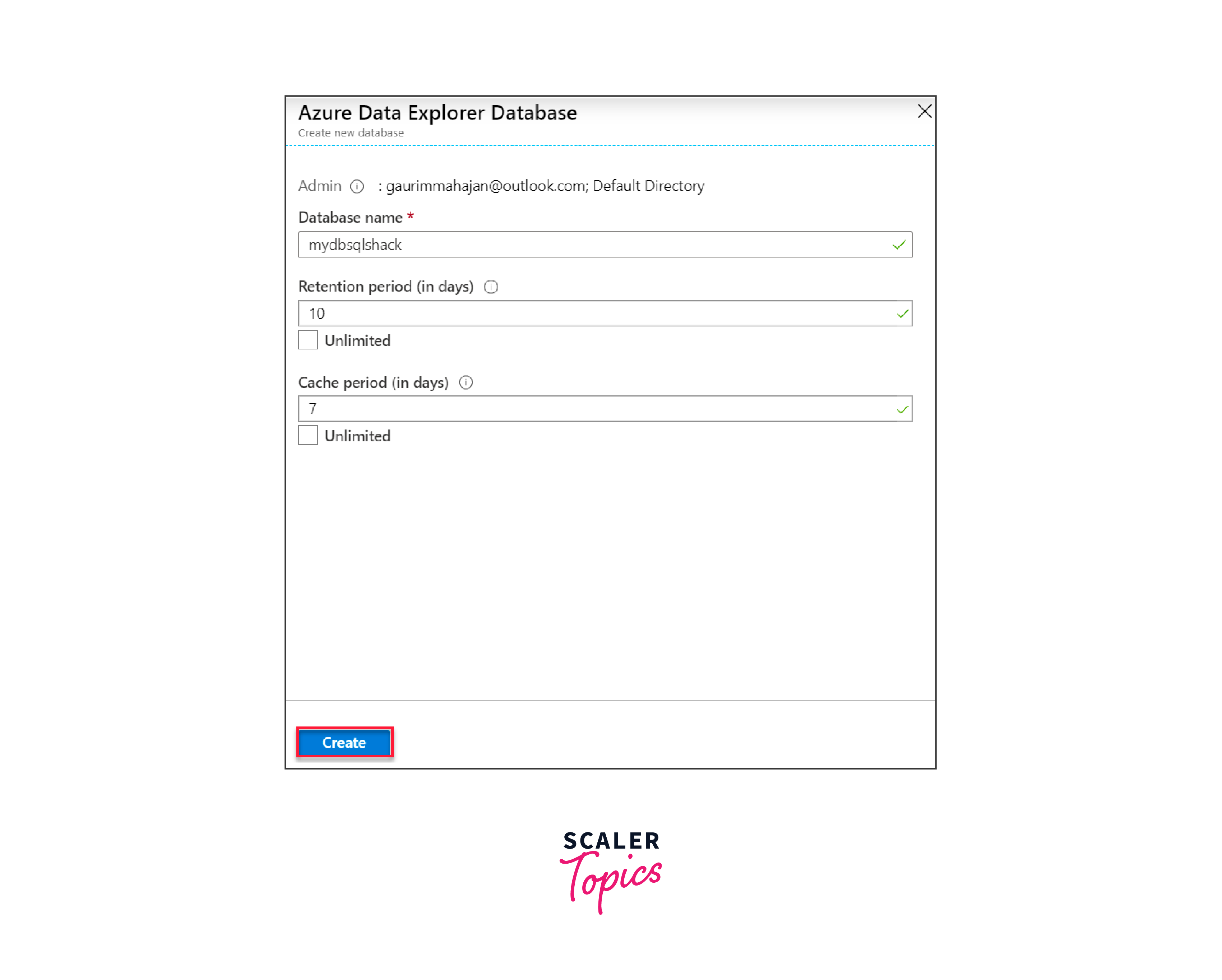
Enter key details for your database: the name, data retention period, and cache duration. ADX offers a unique feature allowing you to determine how long data remains in the cache, a choice between hot or cold storage. Choose the most appropriate settings for your use case.
-
After filling out the necessary information, click "Create".
-
With your cluster and database now ready, enter the database and execute simple commands like ".show database" to retrieve database specifics.
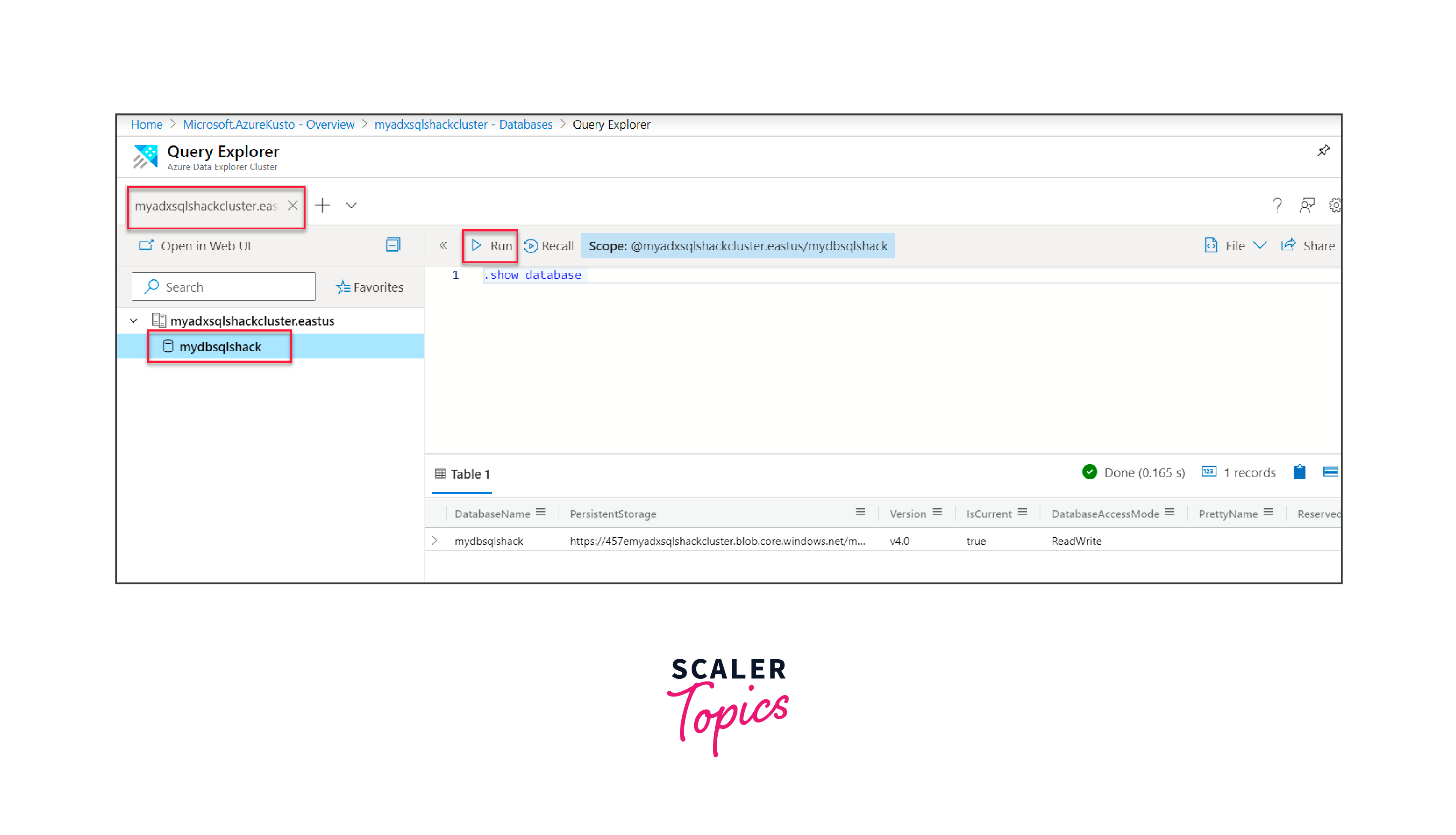
Web UI for Azure Data Explorer
Azure Data Explorer also comes equipped with a Web User Interface (Web UI), granting users an alternative method to interact with their data.
The Web UI facilitates an immersive experience for users, whether they're ingesting data or querying it. After setting up your database:
-
Navigate to the Web UI.
-
To ingest data, choose from various sources like Event Hub, Blob Storage, or IoT Hub. Azure Data Explorer supports a plethora of ingestion methods, including connectors like Kafka, Azure Data Factory, and more.
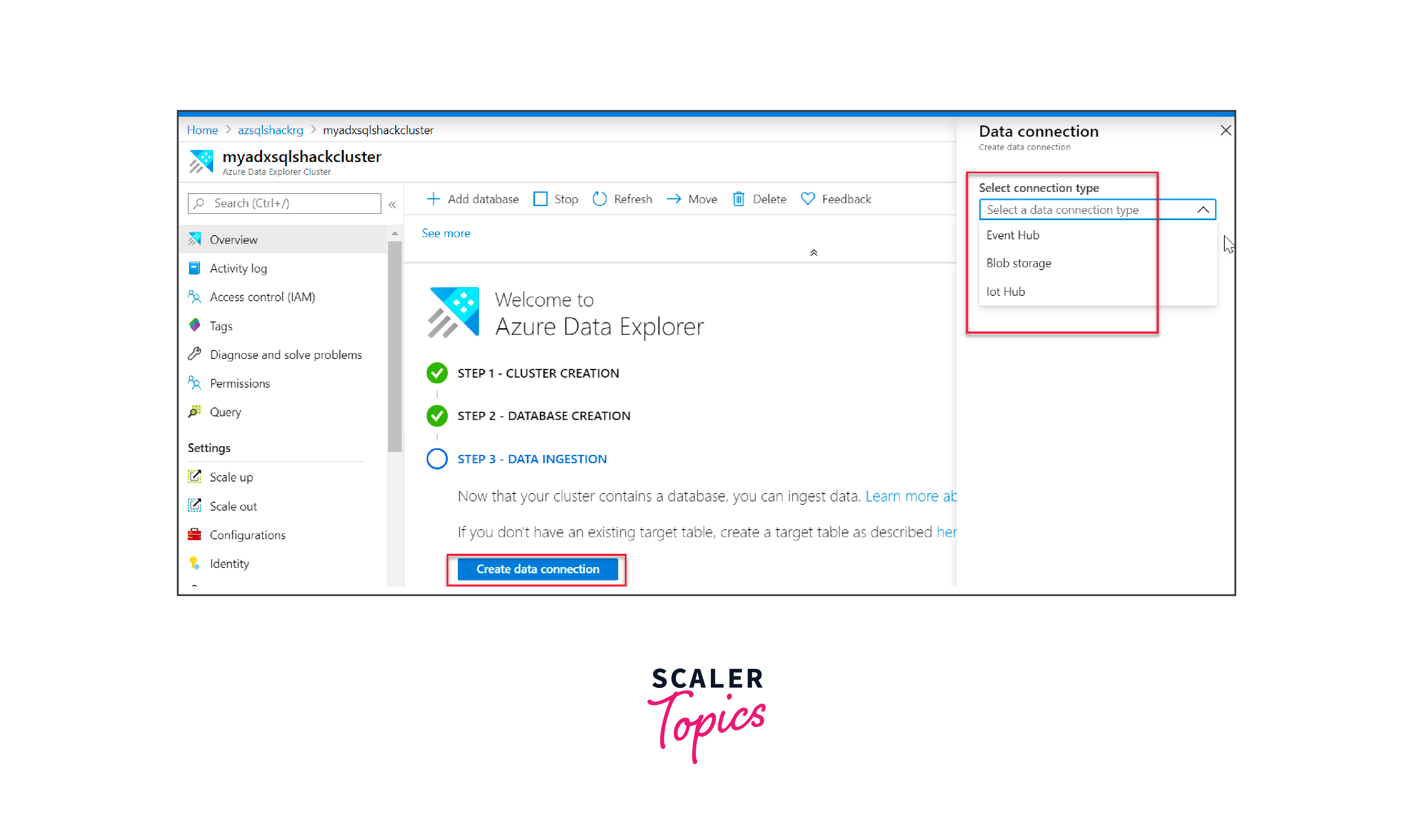
For demonstration purposes, ingest sample data from Azure Blob Storage into your ADX database by entering the relevant commands in the query explorer.
Input the following commands into the query explorer. The initial command establishes a table named CrimeData, while the subsequent command introduces data from a csv file into this table. The csv file in question, CrimeData.csv, is stored within an Azure Blob Container, specifically in a container labeled "mycontainer".
In essence, the process of creating an Azure Data Explorer Cluster, setting up a database, and utilizing the Web UI is intuitive and streamlined, making data exploration efficient and user-friendly.
Working with Internal Data
Azure Data Explorer (ADX) offers a robust platform for analyzing large datasets quickly, and a significant part of its utility comes from how it handles internal data. Internal data refers to the data already ingested into the ADX environment.
-
Data Ingestion:
The first step in working with internal data is ingestion. ADX supports various ingestion methods, whether it's streaming data in real-time from Azure services like Event Hub or IoT Hub, or batch ingestion from sources like Blob Storage. The goal is to move data from its source into ADX to avail the power of fast querying capabilities.
-
Schema Management:
After ingesting data, the next task is to manage the data structure. ADX allows schema-on-read, which means you don't need to define a schema before ingesting data. However, for better data organization and efficient querying, it's recommended to define a schema that structures your data appropriately.
-
Querying with Kusto Query Language (KQL):
Internal data in ADX is queried using KQL. KQL is a rich language that supports a variety of operations including filtering, aggregation, and joining. This allows you to derive insights from your data efficiently. For instance, to retrieve the top 10 records from a table named CrimeData, you'd use:
FAQs
Q. How does Azure Data Explorer ensure data security?
A. Azure Data Explorer ensures data security via Azure’s robust security model, employing measures like data encryption, virtual network service endpoints, and managed private endpoints.
Q. Can I run real-time analytics with Azure Data Explorer?
A. Yes, Azure Data Explorer is specifically designed to support real-time analytics and can handle multiple real-time data ingestion and queries.
Q. What is Kusto Query Language (KQL) in Azure Data Explorer?
A. KQL is a rich querying language that provides expressive and intricate querying capabilities in Azure Data Explorer, aiding in exploring, analyzing, and visualizing large datasets.
Q. How does data ingestion take place in Azure Data Explorer?
A. Data ingestion in Azure Data Explorer can be done through various methods like batch ingestion, streaming ingestion, and integrations with other Azure services.
Conclusion
- Azure Data Explorer (ADX) is a powerful platform tailored for fast and efficient data analytics, especially with vast datasets.
- Setting up ADX involves creating clusters, and databases, and understanding pricing dynamics, ensuring an optimized environment.
- To harness ADX's full potential, it's crucial to effectively manage and query internal data using Kusto Query Language (KQL).
- Integration capabilities with other Azure services expand ADX's versatility, allowing for enhanced data processing and analytics.
- Proper management of data ingestion, retention, and caching ensures cost-effective and optimal performance throughout the data lifecycle.