Azure Machine Learning Prediction
Overview
Azure Machine Learning Prediction is part of Azure Machine Learning, and it helps organizations use machine learning models for making real-time predictions. It integrates well with Azure services, making it a strong choice for deploying, monitoring, and managing predictive models in areas like finance, healthcare, and manufacturing. This means better decision-making and automation of tasks. It's flexible, allowing for both batch processing and real-time predictions, which can be a game-changer for businesses and data experts.
Data Selection and Data Cleaning
Data Selection
The success of any machine learning project hinges on the data you work with. Data selection is the process of identifying and gathering the right data for your project. It starts with a clear understanding of the problem you're trying to solve. What features or variables are relevant to this problem? Where does your data come from?
You'll need to evaluate the data sources, data volume, data quality, and data sampling. Ensure that your data is not only relevant but also representative of the problem you're tackling. Data relevance is the cornerstone of building effective machine learning models.
Data Cleaning
Once you've selected your data, the next step is data cleaning. Data quality is paramount. In this phase, you'll address issues such as missing data, outliers, inconsistent data types, and data transformation. Missing data can be handled by removal or imputation. Outliers, those pesky data points that don't fit the norm, require special attention. Data types need to be consistent and appropriate for the machine learning algorithms you plan to use. This may involve encoding categorical data or standardizing numerical features.
Data cleaning also includes data validation and documentation. Ensure that the data is free from inconsistencies and errors. Document the steps you take during data cleaning, as this is crucial for reproducibility and maintaining data quality over time.
Data Split
Training Data
With your clean and relevant data in hand, it's time to think about data splitting. The most common split involves three subsets: training data, validation data, and testing data.
Training data is the largest subset and forms the foundation of your machine learning model. This data is used to train the model, allowing it to learn patterns and relationships. Typically, training data constitutes around 60-80% of your total dataset.
Validation Data
Validation data is a critical part of the machine learning workflow. It's used to fine-tune your model and optimize its hyperparameters. This independent dataset helps you assess the model's performance during training and prevent overfitting. A good rule of thumb is to allocate 10-20% of your data to validation.
Testing Data
Testing data serves as the ultimate benchmark for your model. It represents real-world, unseen data. Evaluating your model's performance on the testing data helps you gauge its ability to generalize beyond the training set. Like validation data, testing data typically constitutes 10-20% of your dataset.
In cases where data is limited, techniques like k-fold cross-validation can be employed to make the most of the available data. Stratified splitting ensures that class proportions are preserved in classification tasks.
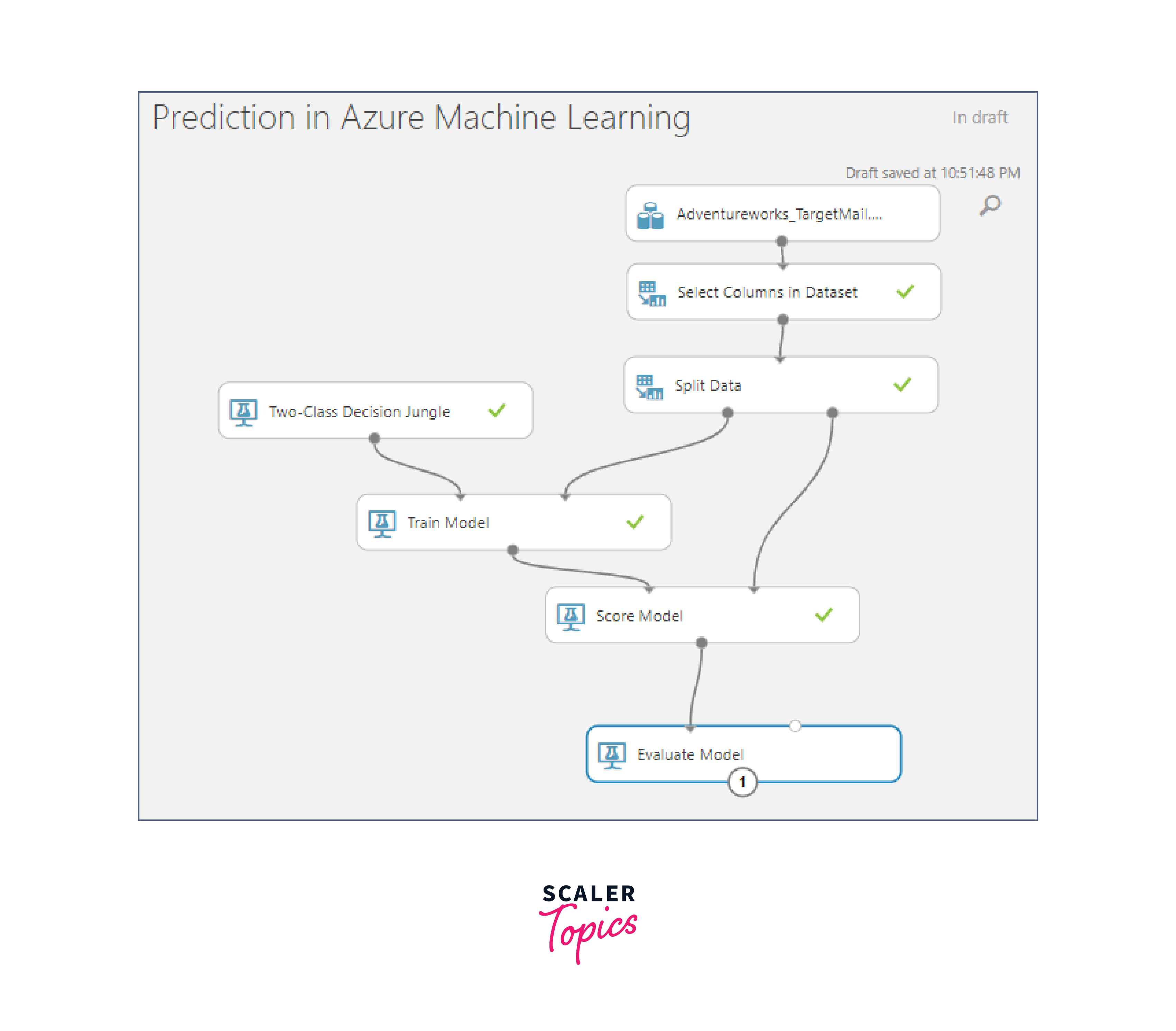
The Training Model
Model Selection
The heart of any machine learning project is the model. Model selection is the process of choosing the right algorithm to solve your problem. Azure offers a diverse range of machine learning algorithms, from simple linear regression to complex deep learning models.
Consider the nature of your problem, the data you have, and the goals you aim to achieve when selecting a model. It's also essential to keep scalability, interpretability, and computational resources in mind.
Model Training
With your selected model in place, it's time to train it using the training data. During training, the model learns from the data, identifying patterns and relationships that will enable it to make predictions or classifications. The Azure platform provides a managed environment for training models, taking care of the underlying infrastructure.
Hyperparameter Tuning
Model performance can often be improved by adjusting hyperparameters. Hyperparameters are settings that govern the learning process of the model. Azure offers tools for hyperparameter tuning, allowing you to optimize your model's performance.
The Score Model
Scoring New Data
Once your model is trained, it's ready for real-world applications. The score model phase involves using your trained model to make predictions or classifications on new, unseen data. This is where the value of your machine learning model truly shines.
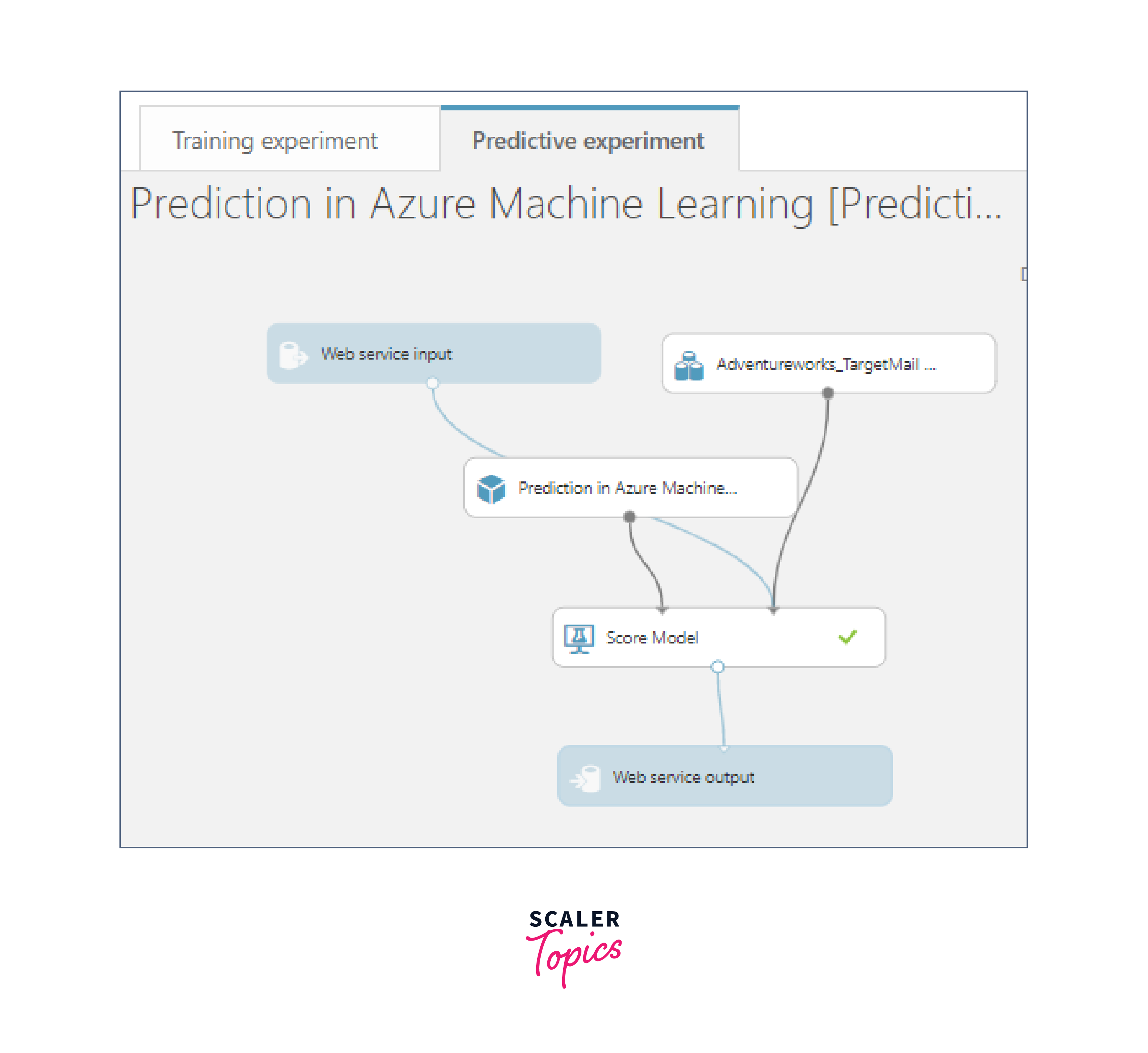
Azure enables you to deploy your model as a web service, making it accessible for real-time scoring. This means your model can be integrated into various applications and services to make predictions on the fly.
Evaluating the Model
Performance Metrics
The quality of a machine learning model is determined by how well it performs. To assess performance, you'll need to use appropriate metrics. Classification tasks often use metrics like accuracy, precision, recall, and F1-score. Regression tasks may rely on metrics like mean squared error (MSE) or R-squared.
Overfitting and Bias
Overfitting and bias are two common challenges in machine learning and statistical modeling that can impact the performance and generalization of models.
-
Overfitting:
-
Definition: Overfitting occurs when a model learns the training data too well, capturing noise or random fluctuations in the data rather than the underlying patterns. As a result, the model performs well on the training data but fails to generalize to new, unseen data.
-
Causes: Overfitting often happens when a model is too complex relative to the size of the training data. It can also be exacerbated by noise in the training data or when the model is trained for too many iterations.
-
Signs of Overfitting:
- High accuracy on training data but poor performance on validation or test data.
- The model fits the training data closely, capturing even minor fluctuations.
- Large differences between training and validation/test performance.
-
Mitigation Techniques:
- Regularization: Introducing penalties on large model parameters to prevent them from becoming too specific to the training data.
- Cross-validation: Splitting the data into multiple folds for training and validation to get a better estimate of model performance.
- Data augmentation: Increasing the diversity of the training data by applying transformations like rotations, flips, or noise.
-
-
Bias:
-
Definition: Bias in machine learning refers to the systematic error in predictions due to a model's inability to capture the true underlying relationship in the data. It can result from factors like a model being too simplistic or making assumptions that do not hold across different data distributions.
-
Types of Bias:
- Selection Bias: Arises when the training data is not representative of the overall population, leading the model to learn patterns specific to the training set.
- Algorithmic Bias: Occurs when the model itself has built-in biases due to the data it was trained on or the features used.
- Measurement Bias: Arises from errors or inaccuracies in the data collection process.
-
Mitigation Techniques:
- Diverse and representative training data: Ensuring that the training data covers a wide range of scenarios and is representative of the target population.
- Fair feature selection: Avoiding the use of features that might introduce or perpetuate bias.
- Regular audits and monitoring: Continuously evaluating model performance and biases, and making adjustments as needed.
-
Addressing both overfitting and bias is crucial for developing robust and reliable machine learning models that generalize well to new, unseen data while avoiding unfair or inaccurate predictions.
Publish to Gallery
Sharing Knowledge
Machine learning is a collaborative field, and sharing knowledge is crucial. The Azure platform allows you to publish your experiments, datasets, and trained models to the Azure Machine Learning gallery. This fosters collaboration and knowledge sharing among data scientists and machine learning practitioners.
Scalability: Azure Machine Learning Prediction is a versatile service designed to cater to the diverse needs of both small-scale projects and large enterprise-level applications. Its scalability is a standout feature, capable of handling a broad spectrum of workloads and data volumes. For small-scale projects, it offers the flexibility to start with minimal resources and scale up as the project grows. At the enterprise level, it seamlessly accommodates extensive data volumes and complex workloads, ensuring that machine learning models can handle real-world, high-demand scenarios without compromising performance. Its adaptability makes it a valuable asset for organizations of all sizes, from startups to industry giants.
Cost Management: Azure Cost Management is a suite of tools and strategies that empower users to effectively monitor and optimize expenses associated with using Azure Machine Learning Prediction. It provides transparency into resource usage and costs, helping organizations keep their budgets in check. Users can gain granular insights into spending patterns, identify cost drivers, and set budgets to prevent overspending. By implementing cost management best practices, organizations can maximize their return on investment in Azure Machine Learning Prediction. Additionally, they can leverage tools like cost alerts and quotas to proactively manage and control their cloud expenses, ensuring financial sustainability and efficiency in their machine learning projects.
Deployment of Azure Model
Deploying a model in Azure involves several steps and considerations. Here are the key points for deploying a model in Azure:
-
Prepare and Train Your Model:
- Develop and train your machine learning model using Azure Machine Learning or any other suitable framework.
-
Azure Machine Learning Service:
- Use Azure Machine Learning Service to manage and deploy your model.
-
Model Packaging:
- Package your trained model and its dependencies into a deployable format, such as Docker containers or ONNX.
-
Choose Deployment Method:
- Select the appropriate deployment method based on your model's requirements. Common options include Azure Container Instances, Azure Kubernetes Service (AKS), Azure Functions, Azure App Service, and more.
-
Containerization (If Applicable):
- If deploying in containers, create Docker images for your model. Define the necessary environment and dependencies in the Dockerfile.
-
Deploy to Azure:
- Deploy your model to the chosen Azure service. This may involve deploying a container to Azure Container Registry or deploying a web service to Azure App Service or AKS.
-
Scalability and Resource Management:
- Configure scaling options to handle varying workloads and allocate sufficient resources to ensure model performance.
-
Authentication and Authorization:
- Implement authentication and authorization mechanisms to control who can access your deployed model.
-
Monitoring and Logging:
- Set up monitoring and logging to track the performance of your deployed model, detect issues, and gather insights for improvement.
-
Endpoint and API Creation:
- Create an API endpoint for your model, allowing external applications to make predictions by sending requests to this endpoint.
-
Testing and Validation:
- Thoroughly test your deployed model to ensure it functions as expected, including unit tests, integration tests, and performance tests.
-
Version Control:
- Implement version control for your model to manage updates and rollbacks.
-
Security Considerations:
- Implement security best practices, including network security, data protection, and encryption.
-
Cost Management:
- Keep track of the cost associated with your deployed model, and optimize resource usage as needed.
-
Documentation and API Documentation:
- Document your deployed model, including usage instructions and API documentation for consumers.
-
Continuous Integration/Continuous Deployment (CI/CD):
- Implement CI/CD pipelines to automate the deployment process and streamline updates.
-
Compliance and Regulations:
- Ensure that your model deployment complies with relevant regulations, especially if handling sensitive data.
-
Backup and Disaster Recovery:
- Plan for backup and disaster recovery to ensure business continuity in case of failures.
-
Service Level Agreements (SLAs):
- Define SLAs for your model's availability, performance, and support.
-
User Acceptance Testing:
- Conduct user acceptance testing to ensure the deployed model meets the expectations of stakeholders.
Conclusion
- Azure Machine Learning Prediction simplifies the end-to-end machine learning process, from data ingestion and cleaning to model training and deployment. This streamlining allows data scientists and developers to focus on building and deploying models rather than managing infrastructure.
- The service is highly scalable, making it suitable for small-scale projects and large enterprise-level applications. It can handle a wide range of workloads and data volumes.
- Azure Machine Learning Prediction provides a variety of algorithms and tools for model training. This enables data scientists to experiment with different techniques and fine-tune models for optimal performance.
- Azure Machine Learning Prediction includes features for data security and compliance. It supports Azure Active Directory for authentication and offers options for data encryption and compliance with industry standards and regulations.
- Azure Cost Management tools help you monitor and optimize the costs associated with using Azure Machine Learning Prediction. You can keep track of resource usage and budget effectively.