Azure ML Sdk
Overview
Azure ML SDK, or Azure Machine Learning Software Development Kit, stands as a powerful tool for data scientists, developers, and engineers to build, train, and deploy machine learning models. In this article, we will explore the capabilities and features of Azure ML SDK to understand how it can streamline and enhance the machine learning workflow.
What is Azure Machine Learning SDK
Azure ML offers a diverse range of services from data preparation and model training to deployment and monitoring.
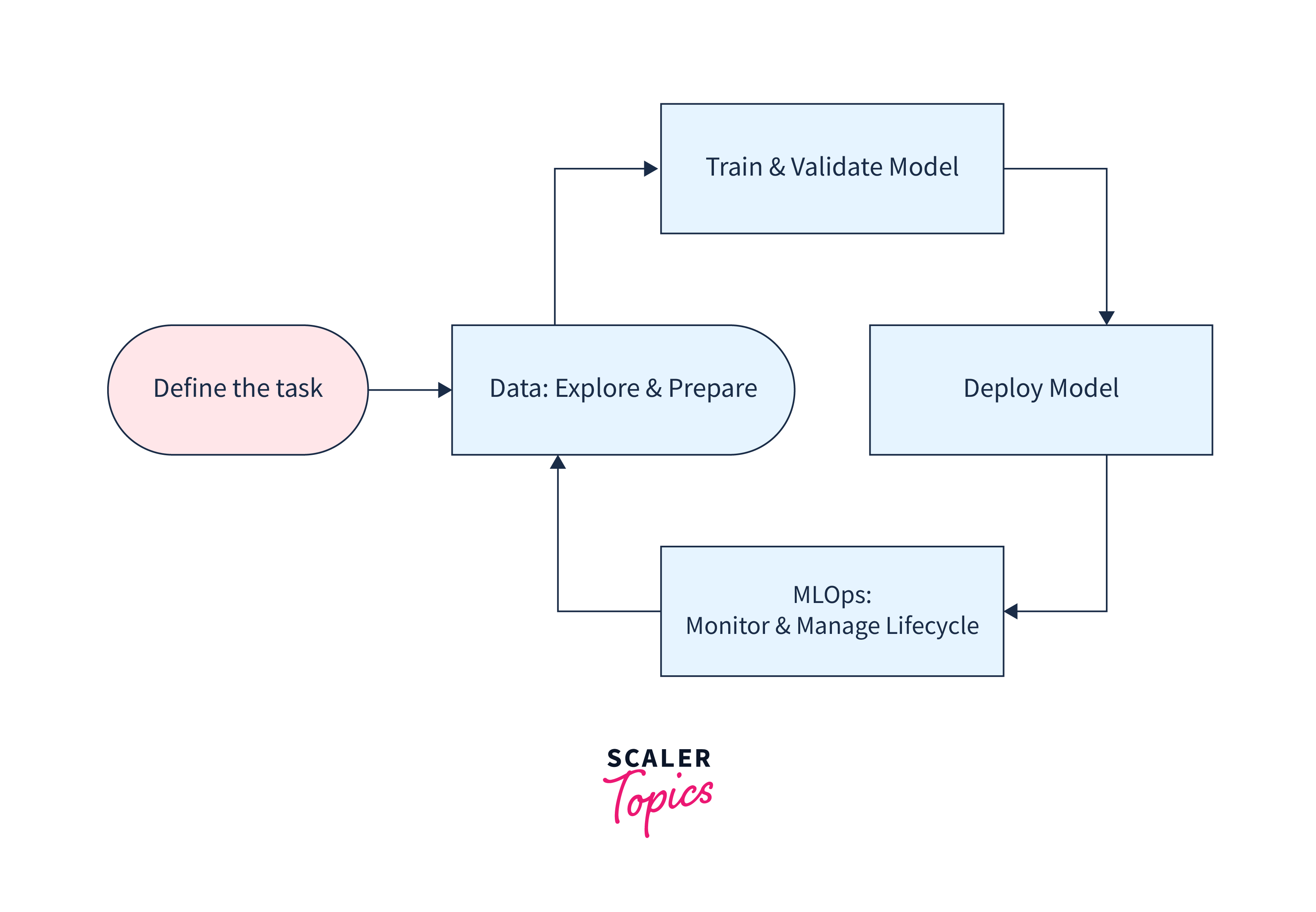
Azure Machine Learning SDK is a robust toolkit designed to simplify and accelerate the process of developing, training, and deploying machine learning models. It serves as a bridge between data scientists and Azure's cloud-based machine learning services, offering tools to build, train, and deploy models efficiently. It offers a unified interface to control and manage the entire ML workflow. It provides a Python-based toolkit that empowers users to interact with Azure ML services programmatically, enabling tasks like experiment tracking, model deployment, and pipeline orchestration.
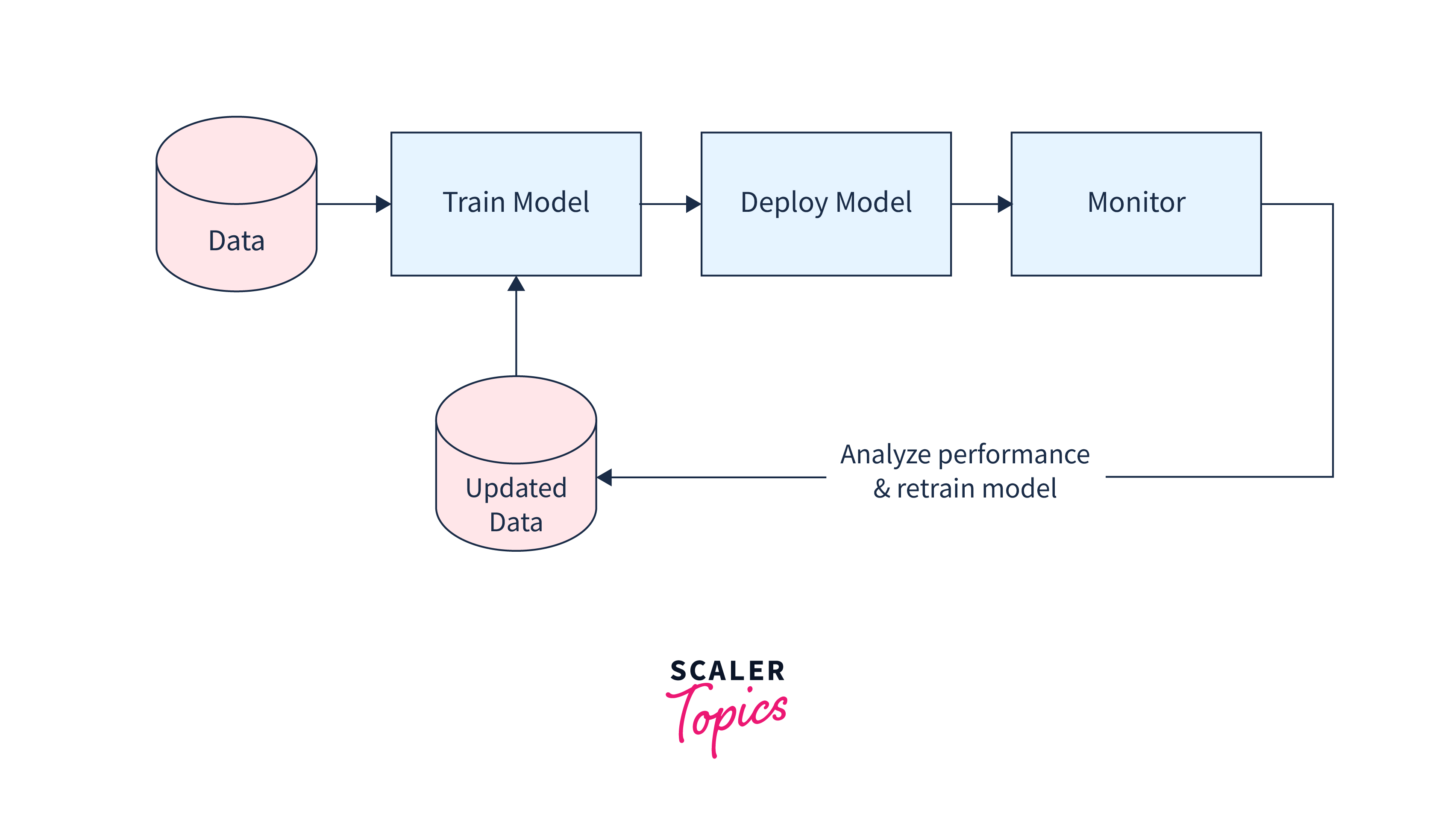
Key Features of the SDK
The Azure Machine Learning (Azure ML) SDK provides multiple features for Machine learning developers:
- Cloud-Native:
Azure ML is designed to work seamlessly with Azure cloud services. It allows you to easily deploy, manage, and scale machine learning models in the cloud. This cloud-native approach provides flexibility, scalability, and robustness to your machine-learning workflows. - Experimentation and Versioning:
Azure ML facilitates easy experimentation with different algorithms, hyperparameters, and data processing techniques. It enables you to track and manage versions of your models, datasets, and experiments, which is crucial for reproducibility and collaboration. - Automated Machine Learning (AutoML):
Azure ML includes AutoML, a powerful feature that automates the process of selecting the best machine learning model and hyperparameters for a given task. This is especially useful for users who may not have extensive machine-learning expertise. - Data Prep and Feature Engineering:
Azure ML offers tools for data preparation and feature engineering, which are critical steps in the machine learning pipeline. These tools help in cleaning, transforming, and engineering features to improve the performance of your models. - Model Deployment and Management:
Azure ML allows you to easily deploy models as web services or containers. This means you can integrate your models into applications, websites, or other services. It also provides tools for monitoring the performance of deployed models and managing their lifecycle. - MLOps and DevOps Integration:
Azure ML is designed to integrate seamlessly with MLOps (Machine Learning Operations) and DevOps practices. This ensures a streamlined process for deploying, monitoring, and managing machine learning models in production environments. - Version Compatibility:
The different components of the SDK have specific version requirements, especially when integrating with other Azure services or third-party libraries. A minimum python version of 3.7 is required for the SDK. - Scalability and Parallelism:
Azure ML is designed to handle large-scale machine learning workloads. It supports distributed training, allowing you to train models on large datasets across multiple compute resources in parallel. - Security and Compliance:
Azure ML is built on the secure Azure platform, which adheres to global data protection compliance practices and industry-leading security standards, including ISO 27001, HIPAA, and GDPR. It provides features like role-based access control (RBAC), encryption in transit and at rest, and compliance with various regulatory standards. Additionally, Azure ML SDK integrates with Azure Active Directory for secure authentication and identity management.
Stable vs. Experimental
The Azure Machine Learning SDK for Python offers various features, categorized into two main types: Stable and Experimental.
Stable Features
- Stable features are considered production-ready.
- These components are well-tested, recommended for most use cases, and are suitable for deployment in production environments.
- They undergo less frequent updates compared to experimental features, ensuring a high level of reliability and stability.
Experimental Features
- Experimental features, also referred to as features in preview are in a developmental phase.
- They encompass newly developed capabilities and updates that may not be entirely ready or fully tested for production usage.
- While these features are typically functional, they might introduce breaking changes.
- It's important to note that, as the term experimental suggests, these features are intended for experimentation and are not considered bug-free or stable.
Workspace
The workspace in Azure ML SDK acts as the central hub for your machine learning project. It provides a secure and collaborative environment for managing experiments, models, and data.
The Workspace class, found within the azureml.core.workspace module, provides the necessary functionalities to create, manage, and utilize workspaces effectively.
Creating a Workspace
Creating a new workspace is done using the Workspace.create() method, you can define essential parameters like the workspace name, Azure subscription ID, resource group, and location.
If you already have an existing Azure resource group that you'd like to use for the workspace, you can set create_resource_group to False.
Workspace Configuration
To reuse a workspace across multiple environments or projects, you can write the workspace details to a configuration JSON file. This file has crucial information such as subscription, resource, and workspace names. This way, you can easily access the workspace without the need for repetitive setup.
Subsequently, you can load your workspace by reading the configuration file.
Alternatively, you can use the static Workspace.get() method to retrieve an existing workspace directly, bypassing the need for configuration files.
The variable ws_other_environment now represents a Workspace object, ready for use in various machine learning tasks.
Experiment
An experiment in Azure ML SDK is a logical container for trials, each of which corresponds to an individual run of a machine learning model. It allows you to track and organize your work, making it easier to reproduce and share your experiments.
Creating or Fetching an Experiment
To initiate an experiment, you first need to either retrieve an existing Experiment object by name from your Workspace or create a new one if the specified name doesn't already exist.
Listing Experiments
Azure ML enables you to view all the Experiment objects contained within your Workspace.
Retrieving Runs
Within an Experiment, individual model runs are represented as Run objects. To access these runs, you can use the get_runs() function.
Starting an Experiment
Depending on your working environment, there are two distinct methods to initiate an experiment trial.
- The start_logging() function for interactive environment(Jupyter notebooks).
- The submit() function for standard Python environment.
The following line of code demonstrates the initiation of an experiment:
The variable run now holds the Run object for the active experiment.
Run
A run represents a single execution of a script, which includes training a model, pre-processing data, or any other machine learning task. Runs are crucial for version control and tracking the performance of your models.
Tagging and Creating a Run
Tags and the child hierarchy feature are used for easy lookup of past runs. Custom categories and labels, attached using the tags parameter, help organize and classify runs. To create a Run object, you submit an Experiment object along with a run configuration object.
Run objects are used to register stored model files, a pivotal step in preparing deployment models.
Listing Runs
The static list function is employed to retrieve a list of all Run objects associated with a specific Experiment. It can be further filtered using tags for more targeted retrieval.
Retrieving Run Details
The get_details function provides a detailed output for a specific run. The returned dictionary encompasses essential information like Run ID, status, start and end times, compute target (local or cloud), dependencies, versions used, and training-specific data (varies based on model type).
Model
Azure ML SDK offers the Model class which provides methods for transferring models and offers model registration capabilities, allowing you to version, store, and retrieve your models within the Azure cloud.
Working with Local Models
Azure ML supports the registration of models originating from local development environments. The following example demonstrates how to create a simple prediction model using scikit-learn.
Model Registration in Workspace
Model registration empowers you to store and version your machine learning models within your Azure Workspace. Each registered model is identified by a unique name and version. Registering the same name multiple times will create new versions of the model.
Managing Registered Models
Once the model is registered in your Workspace, it becomes easy to manage, download, and organize your models. To retrieve a model object, you can use the Model class constructor. The download function allows you to retrieve the model, including its cloud folder structure.
Model Deletion
If you need to remove a model from your Workspace, the delete function allows you to do so efficiently.
ComputeTarget, RunConfiguration, and ScriptRunConfig
In Azure Machine Learning, managing and configuring compute targets is a fundamental aspect of model training and experimentation.
ComputeTarget
The ComputeTarget class serves as the abstract parent class for creating and managing compute targets, which represent the resources where machine learning models are trained. These targets can be either local machines or cloud resources, including Azure Machine Learning Compute, Azure HDInsight, or remote virtual machines.
To create a compute target, you instantiate a RunConfiguration object and define the target type and size. The following example sets up an AmlCompute target, which creates a runtime remote compute resource within your Workspace. This resource automatically scales when a job is submitted and is deleted upon job completion.
Setting Up Environment Dependencies
To ensure the remote compute resource has the necessary Python environment dependencies, you use the CondaDependencies class. For example, if your training script relies on libraries like scikit-learn and numpy, these dependencies need to be installed in the environment.
ScriptRunConfig and Experiment Submission
The ScriptRunConfig class allows you to attach the compute target configuration and specify the path to your training script, such as train.py. You then submit the experiment using the config parameter of the submit() function. Calling wait_for_completion on the resulting run allows you to monitor the asynchronous run output, including environment initialization and model training progress.
- The training script train.py in the provided example trains a simple scikit-learn model for predicting customer churn.
- After the run is complete, the trained model file, e.g., customer-churn-model.pkl, becomes available in your Azure ML Workspace.
Environment
Environments in Azure ML SDK enable you to manage Python packages, and even options for PySpark, Docker, and R, ensuring consistency and reproducibility in your experiments.
- Azure ML environments can be configured for various purposes, from training models to scoring them.
- Environments are not limited to Python and can also accommodate PySpark, Docker, and R configurations.
- Internally, environments result in Docker images that provide a consistent execution environment for training and scoring.
- Environments facilitate reproducible and auditable machine learning workflows, ensuring consistency in results.
Creating an Environment
To create an environment, you utilize the Environment class from the SDK. Here's an example:
Adding Packages
Packages can be added to an environment using Conda, pip, or private wheel files. The CondaDependencies class helps manage these dependencies.
Setting Up a Run Configuration
To following code illustrates on setting up run configuration using ScriptRunConfig.
A default environment is created, if the environment is not specified in the run congiuration.
Pipeline, PythonScriptStep
Pipelines allow you to automate and orchestrate complex machine learning workflows and even the ability to publish pipelines for easy re-running through REST endpoints.
Configurations
- Start by specifying the Azure Machine Learning workspace, compute target, and storage.
- Define the input and output data sources. This can be achieved using different types of datasets, including Dataset for existing Azure datastores, PipelineDataset for typed tabular data, and PipelineData for intermediate file or directory data.
Creating a PythonScriptStep
The PythonScriptStep allows you to execute a Python script on a specified compute target. It can take various parameters such as the script name, arguments for the script, compute target, inputs, and outputs.
Creating an Experiment and Submitting the Pipeline
An experiment has to be created for the execution of the pipeline.
AutoMLConfig
The AutoMLConfig class is a powerful tool to configure parameters for automated machine learning training. Automated machine learning is a process that systematically explores various combinations of machine learning algorithms and their hyperparameter settings to find the best-fit model based on the chosen accuracy metric.
Example
In this example, we've configured an AutoMLConfig for a classification task. We specify the training features (X) and labels (y), set the maximum number of iterations to 30, and allocate 5 minutes per iteration. The primary metric to optimize is the weighted Area Under the Curve (AUC). Additionally, we perform 5-fold cross-validation.
Submitting the Experiment
After submitting the experiment, you can observe the training accuracy for each iteration. Once the run is completed, you can retrieve the best-fit model using run.get_output().
Model Deployment
Azure ML SDK supports model deployment to various endpoints, allowing you to make your models accessible for predictions and inference. Azure ML provides the InferenceConfig class to define the necessary environment for hosting the model as a web service.
The process involves combining the environment, inference compute, scoring script, and registered model in a deployment object, followed by the deploy() operation.
Here's an example of how you can deploy a model to Azure Container Instances:
- In this example, we start by registering the model that we intend to deploy.
- We then create an InferenceConfig, which combines the scoring script and the environment details.
- Following this, we set up the deployment configuration specifically for Azure Container Instances.
- Finally, the model, inference configuration, and deployment configuration, along with the web service name and location are used to deploy the model as a web service.
Dataset
In Azure Machine Learning, the Dataset class plays a crucial role in managing and exploring data. It enables easy integration of data into your machine learning workflow, providing versioning and reproducibility capabilities.
TabularDataset
TabularDataset is employed for handling data in a tabular format, which is usually generated by parsing one or more files.
FileDataset
On the other hand, the FileDataset class is used to reference one or more files. These files can reside in data stores or be accessible through public URLs.
Conclusion
- Azure Machine Learning provides a robust suite of tools and services, enabling the seamless development, training, and deployment of machine learning models. Its comprehensive ecosystem matches both traditional and automated machine learning approaches.
- Within Azure ML, components like Workspace, Experiment, Run, Model, ComputeTarget, and Environment form the backbone of machine learning operations. These elements collectively perform the creation, execution, and management of ML workflows.
- The Azure ML SDK offers versatility by supporting both stable and experimental features. This flexibility empowers developers to experiment with cutting-edge functionalities while ensuring stability for production-grade use cases.
- Developers can programmatically create and manage essential elements like compute targets, automML workspaces, model deployment, pipelines, and runs. This capability allows automated workflows and seamless collaboration across teams.
- Datasets provides a structured approach to data management for Azure ML. Whether in tabular or file format, Azure ML’s TabularDataset and FileDataset enable efficient handling, versioning, and integration of data into machine learning workflows.