Delta Lake
Overview
In the digital age, data has become the lifeblood of modern enterprises. The ability to collect, store, process, and analyze vast amounts of data efficiently is paramount for making informed business decisions and gaining a competitive edge. This is where Azure Data Lake comes into play, offering a robust and scalable solution for managing big data in the cloud.
Getting started with Delta Lake
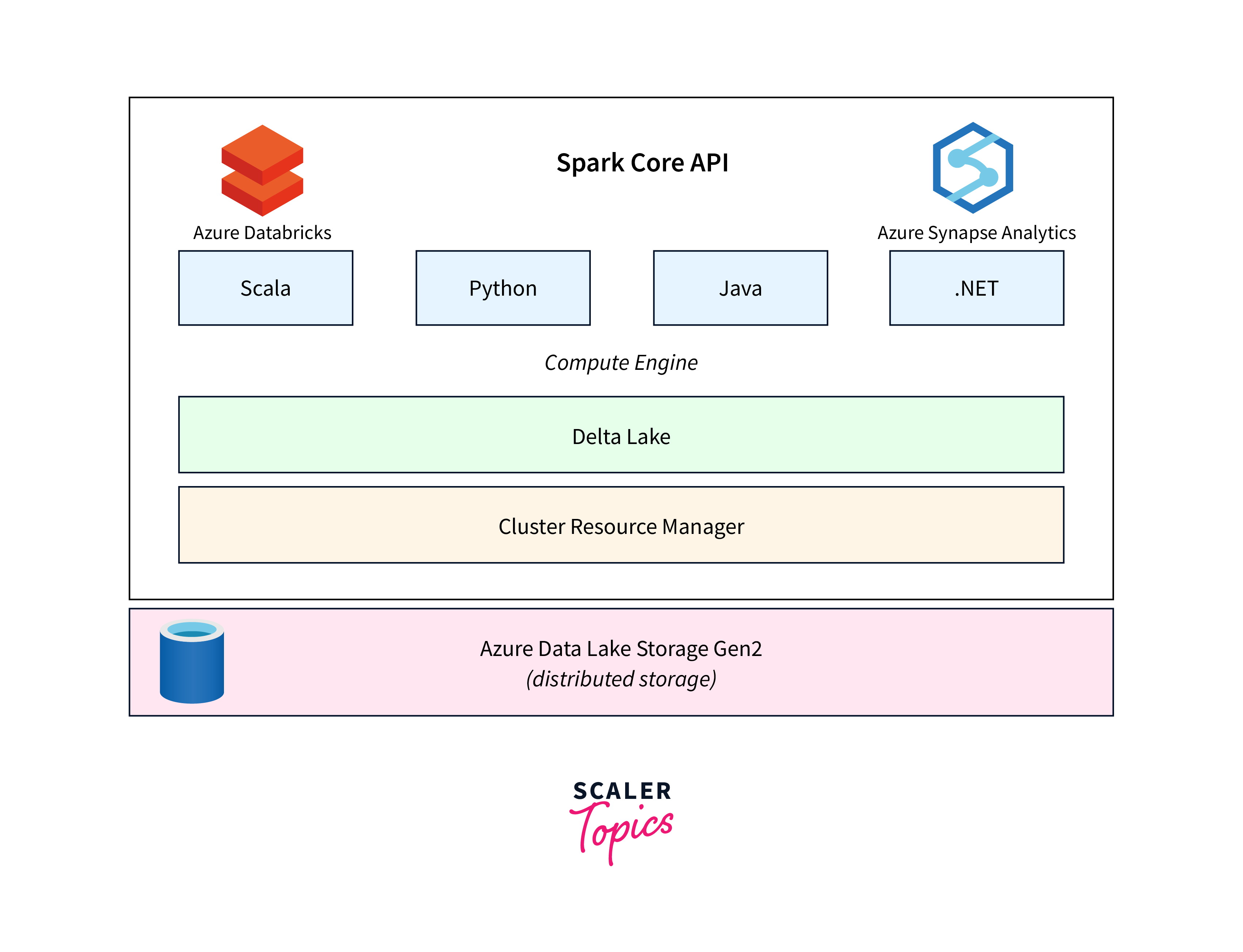
- Environment Setup: Begin by setting up an Azure subscription and creating a data lake storage account. You can do this through the Azure portal or using Azure CLI commands.
- Data Ingestion: Choose the data you want to store and process within your data lake. Prepare your data with a defined schema to enable schema enforcement. Use Azure Databricks or other compatible tools to ingest your data into the Delta Lake storage.
- Integration with Azure Databricks: Delta Lake works seamlessly with Azure Databricks, providing an optimized environment for data processing and analytics. Provision a Databricks cluster and connect it to your data lake storage.
- Creating Delta Tables: Define Delta tables using familiar SQL statements within your Databricks notebook. Delta tables are essentially optimized parquet files that provide ACID properties and time travel capabilities. Specify partitioning columns for efficient querying.
- Data Manipulation and Querying: Perform data manipulations using standard SQL statements. Delta Lake ensures that these operations maintain data integrity through ACID transactions. Leverage partitioning and indexing to improve query performance.
- Schema Evolution: As your data evolves, you may need to update your schema. Delta Lake provides mechanisms to handle schema changes while maintaining compatibility with existing data.
- Time Travel: Explore historical data versions using Delta Lake's time travel feature. Query data at specific points in time for auditing, debugging, or reproducing analyses without complicated backup and restore processes.
- Optimizing Performance: Delta Lake provides optimization techniques like data skipping, predicate pushdown, and caching for faster query execution. Tune your queries and configure your cluster for optimal performance.
- Monitoring and Management: Monitor the performance of your Delta Lake environment using Azure Monitor and other available tools. Keep an eye on resource utilization, query performance, and data integrity.
Converting and Ingesting Data to Delta Lake

- Data Preparation: Begin by ensuring your source data is structured and conforms to a well-defined schema. This schema-on-write approach is crucial for maintaining data integrity and enabling schema enforcement within Delta Lake.
- Integration with Azure Databricks: If not already done, set up an Azure Databricks environment and connect it to your data lake storage. This integration provides the ideal platform for data processing and conversion.
- Creating Delta Tables: Utilize Databricks notebooks to create Delta tables from your source data. You can do this by leveraging the CREATE TABLE statement with the USING delta clause. Define the schema, partitioning columns, and other relevant table properties.
- Data Conversion: Transform your data into the Delta format using Databricks' powerful data manipulation capabilities. This may involve data cleaning, aggregations, or any necessary data transformations.
- ACID Transactions: One of Delta Lake's key features is ACID transactions. As you perform data conversions, Delta Lake ensures that your operations are atomic, consistent, isolated, and durable, guaranteeing data reliability.
- Optimized Storage: Delta tables are stored in an optimized parquet format, which provides efficient storage and query performance. The storage layout helps with data skipping and predicate pushdown, enhancing query execution speed.
- Ingestion and Append Operations: If your data is streaming or batched, use Databricks' capabilities to append new data to your Delta tables. This maintains data versioning and ensures your historical context remains intact.
- Schema Evolution: If your source data schema evolves over time, Delta Lake accommodates changes gracefully. You can apply schema updates to existing tables while maintaining compatibility with existing data.
- Time Travel: After ingesting data into Delta Lake, leverage the time travel feature to access historical versions of your data. This can be crucial for auditing, debugging, and reproducing analyses.
Updating and Modifying Delta Lake tables
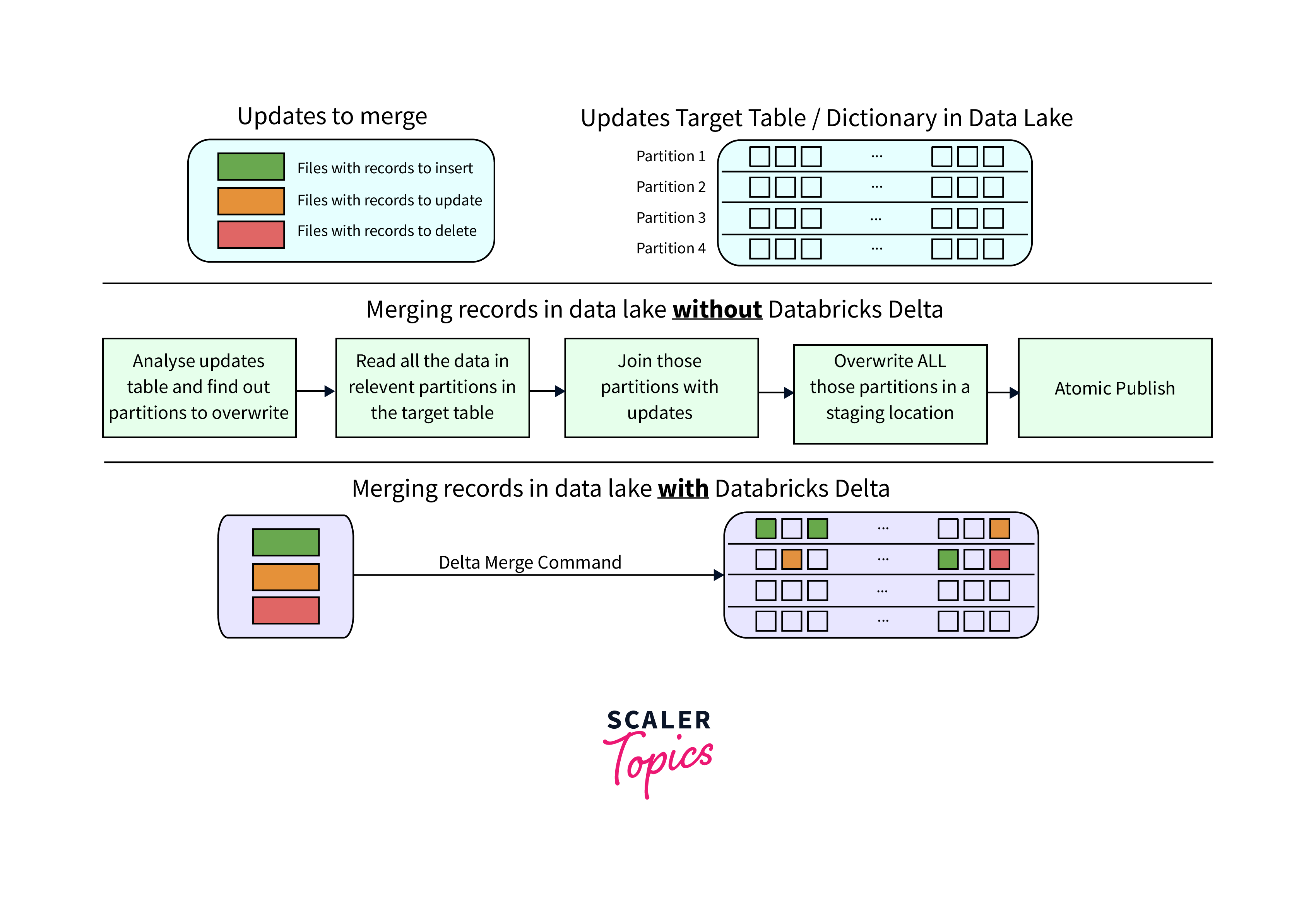
- Schema Updates: Modify table schemas using the ALTER TABLE statement in Azure Databricks. Delta Lake allows you to add, rename, or change columns while preserving compatibility with existing data.
- Data Modifications: Use Databricks to perform updates, inserts, or deletes on your Delta tables. ACID transactions ensure that these operations maintain data consistency and reliability.
- Upserts: Implement upserts by combining INSERT and UPDATE operations. This helps you add new data while updating existing records, efficiently managing changing datasets.
- Time Travel: Delta Lake's time travel feature lets you access previous versions of data. Before making modifications, create checkpoints or snapshots to retain a historical record of your changes.
- Optimized Storage: Delta Lake's parquet-based storage format optimizes data storage and query performance. Changes are organized efficiently, contributing to faster queries.
- Partitioning and Indexing: Adjust partitioning columns and create indexes as needed to enhance query efficiency after modifications.
- Transaction Logs: Delta Lake maintains transaction logs that capture every change, enabling rollbacks if necessary. This supports data auditing and debugging.
- Data Consistency: Delta Lake's ACID properties ensure that updates or modifications are either fully applied or not at all, preventing partial or erroneous changes.
- Collaboration: Azure Databricks facilitates collaborative data engineering. Share notebooks, document changes, and discuss modifications with your team.
Incremental and Streaming Workloads on Delta Lake
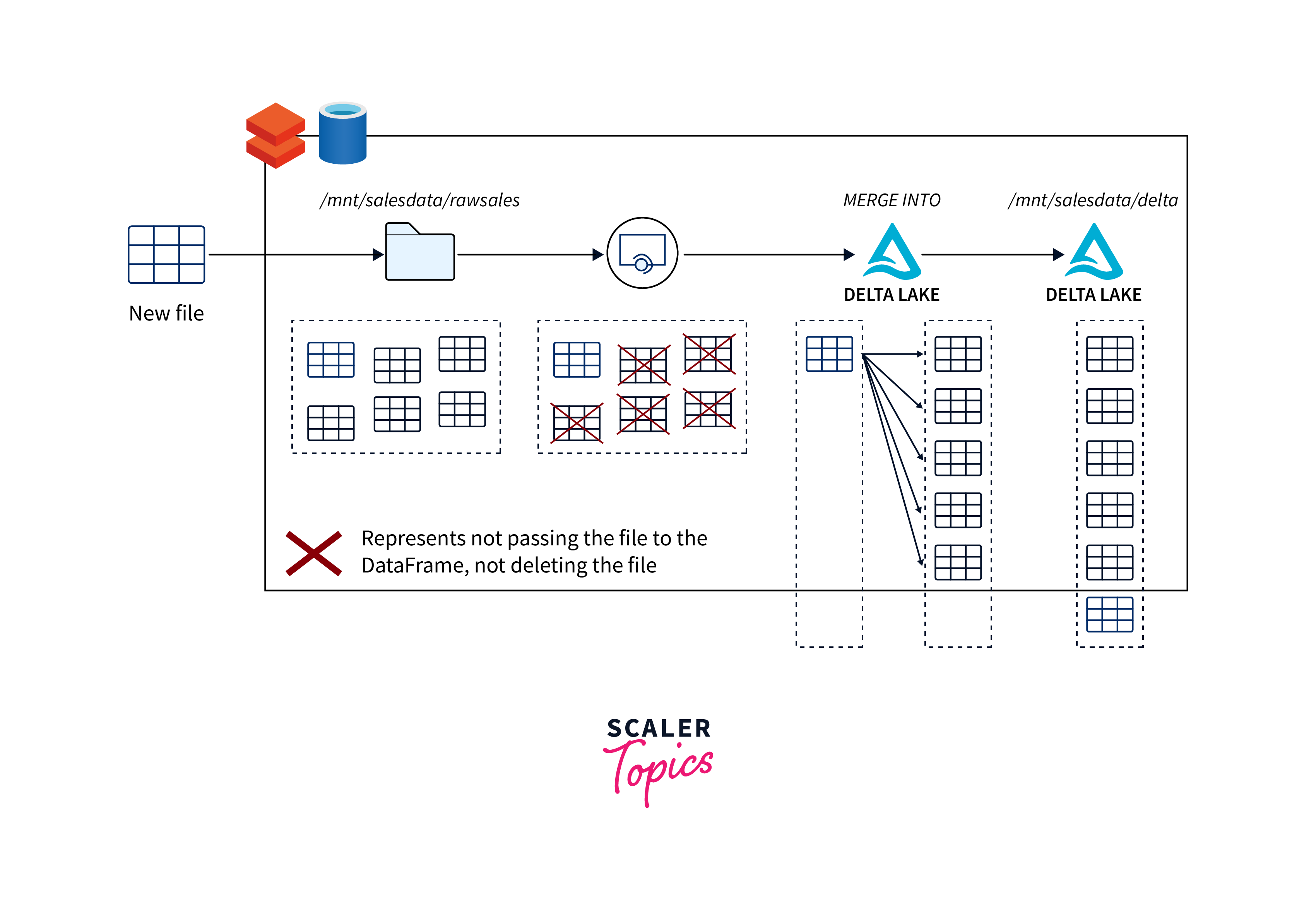
-
Incremental Workloads: Delta Lake enables incremental data processing by allowing you to append new data or modify existing data in a structured and reliable manner. With ACID transactions, changes are guaranteed to be consistent and durable, maintaining data integrity. This is crucial for scenarios where you need to continuously add new data to your existing datasets while ensuring accurate analytics results.
-
Streaming Workloads: Delta Lake seamlessly integrates with Azure's streaming services, enabling real-time data ingestion and processing. You can use services like Azure Stream Analytics or Azure Databricks to ingest streaming data directly into Delta tables. The parquet-based storage format of Delta Lake optimizes data storage and querying even for high-velocity streaming data, while ACID properties maintain transactional consistency. This empowers organizations to process and analyze streaming data effectively for timely insights.
Querying Previous Versions of a Table

Querying previous versions of a table is a fundamental capability of Delta Lake, providing historical context and facilitating auditing, debugging, and analysis.
Delta Lake's time travel feature allows you to access and query data as it existed at specific points in time. By specifying a timestamp or version number, you can retrieve the state of the table at that moment, revealing insights into changes and trends over time. This is invaluable for tracking data modifications, understanding historical trends, and validating past analyses.
Delta Lake Schema Enhancements
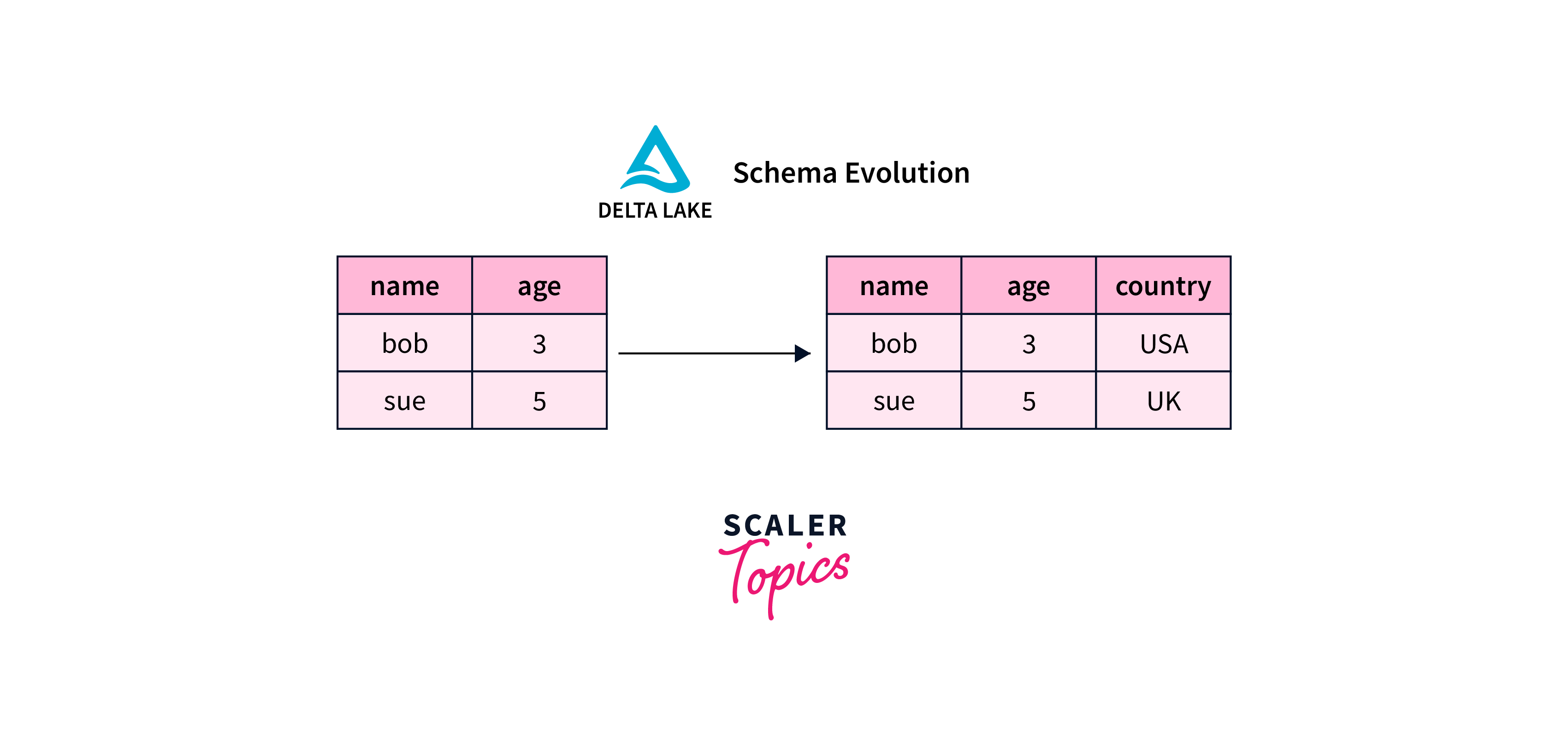
Delta Lake introduces schema enhancements that revolutionize data management within the Azure ecosystem. The schema-on-write approach enforces structured data at the point of ingestion, enhancing data quality and integrity. This prevents inconsistent or incompatible data from entering the lake, minimizing downstream errors.
Schema evolution allows seamless adaptation to changing requirements. You can alter table schemas using ALTER TABLE statements, enabling new columns, data types, or constraints. This flexibility accommodates evolving data without sacrificing existing analytics processes.
Managing Files and Indexing Data with Delta Lake
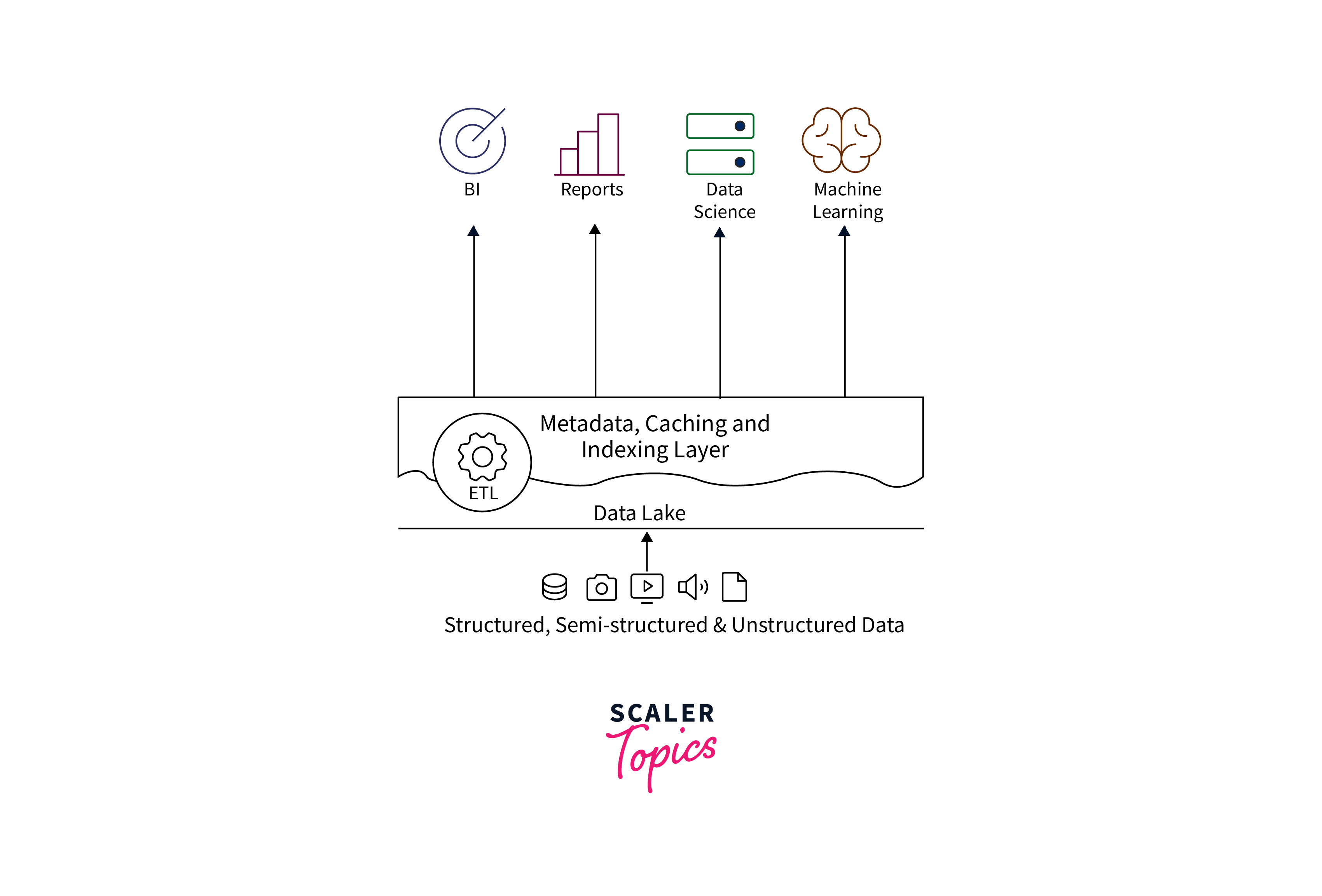
Delta Lake simplifies file management and enhances data indexing within its structure, contributing to improved data processing and query performance.
-
File Management: Delta Lake organizes data as optimized parquet files, reducing storage overhead and enhancing read and write efficiency. It automatically compacts and manages small files through a process known as "file compaction," ensuring optimal storage utilization and query performance.
-
Data Indexing: Delta Lake leverages indexing techniques for faster query execution. It uses Z-Ordering to sort data within files based on selected columns, enhancing filtering efficiency. Additionally, it supports bitmap indexing, facilitating rapid filtering and aggregation operations.
Configuring and reviewing Delta Lake settings
Configuration:
- Table Properties: Define table-specific settings using table properties like format, partitioning, and clustering columns. Set properties for retention policies, compaction, and optimization.
- File Formats: Choose between different file formats (e.g., parquet, delta) based on your workload and storage requirements.
- Concurrency Control: Configure the level of concurrency for read and write operations, balancing resource utilization and performance.
- Retention Policies: Set retention periods to automatically clean up old data versions, managing storage costs.
Review:
- Resource Utilization: Monitor CPU, memory, and storage consumption to optimize cluster allocation and performance.
- Query Performance: Evaluate query execution times and performance bottlenecks. Adjust indexing and partitioning as needed.
- Version Management: Review version history and time travel usage. Ensure appropriate data retention for compliance and analytics needs.
- Compaction Efficiency: Assess file compaction effectiveness to maintain storage efficiency and query speed.
- Data Integrity: Regularly validate data consistency, ACID transactions, and schema adherence.
Data Pipelines Using Delta Lake and Delta Live Tables
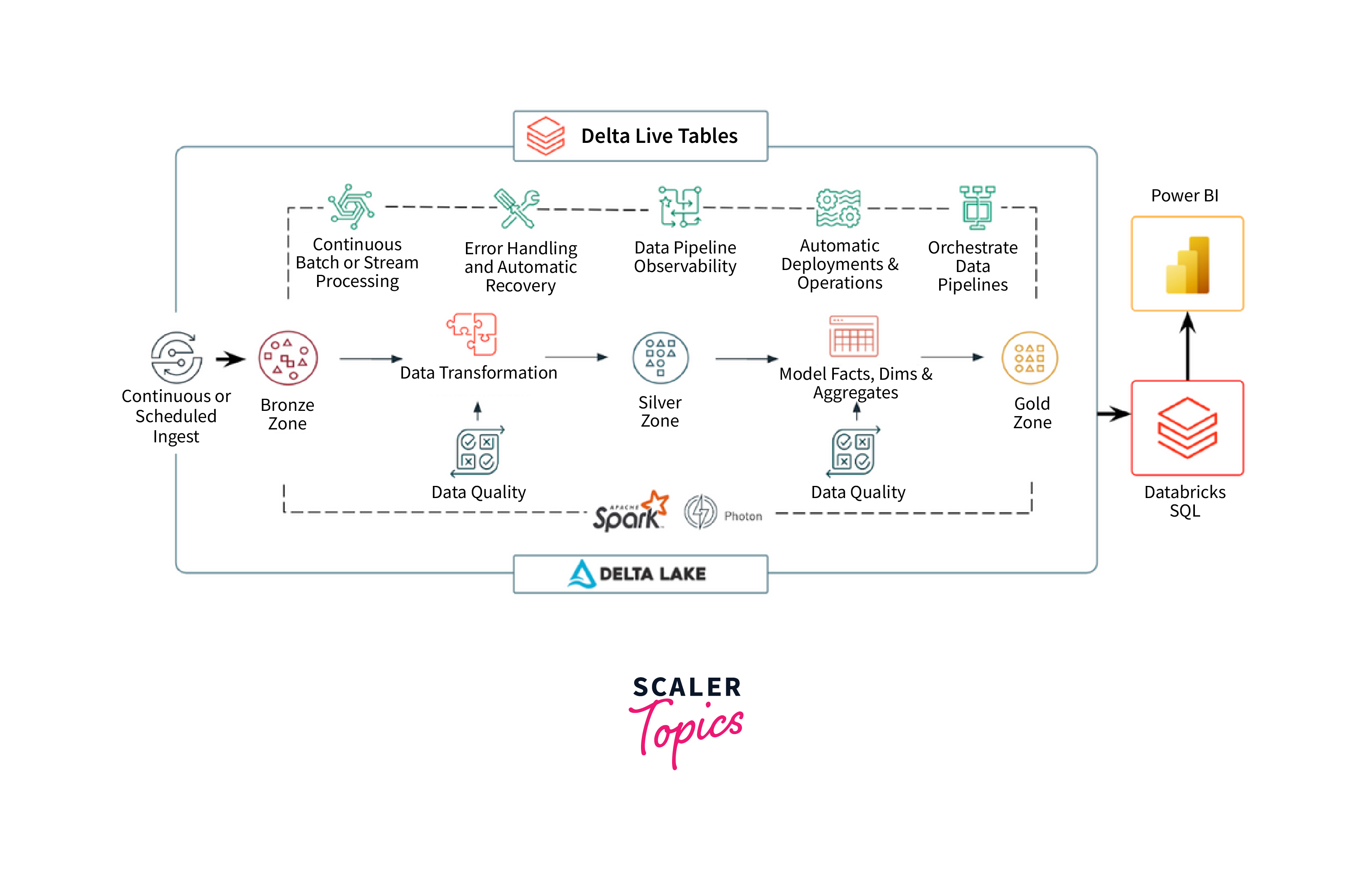
-
Delta Lake serves as the core storage layer, providing ACID transactions, schema enforcement, and time travel capabilities. Data ingestion and transformations are orchestrated using platforms like Azure Databricks. Data is ingested into Delta Lake tables with defined schemas, ensuring data integrity. Batch processes or streaming pipelines can append, modify, or aggregate data while maintaining transactional consistency.
-
Delta Live Tables builds on Delta Lake's foundation, offering an integrated change data capture (CDC) solution. It enables real-time data synchronization between source systems and Delta Lake tables. Changes in source data are captured and applied to Delta Lake in real-time, ensuring that analytics and reporting are up-to-date with minimal latency.
Troubleshooting Delta Lake features
Data Integrity Issues:
- Inconsistent Data: If data appears incorrect, verify schema enforcement during data ingestion to prevent malformed records.
- Failed ACID Transactions: Ensure that your transactions are well-formed and that any failures are appropriately handled using try-catch blocks or retries.
Query Performance:
- Slow Queries: Optimize query performance by evaluating partitioning and indexing strategies. Consider using Z-Ordering for improved filtering efficiency.
- Large Transaction Logs: Regularly vacuum transaction logs to keep them manageable and maintain efficient query performance.
Configuration and Settings:
- Incorrect Table Properties: Review and update table properties if needed. Ensure settings match your workload and retention policies.
- Concurrency Control: Adjust the level of concurrency based on your cluster resources and workload demands.
File Management:
- Small File Issue: Address small file issues by enabling automatic file compaction or manually running optimization jobs.
- Overpartitioning: Excessive partitioning can lead to performance overhead. Reevaluate partitioning strategies for balance.
Time Travel and Versioning:
- Data Retention: Ensure that you maintain an appropriate data retention policy, balancing historical analysis needs with storage costs.
- Querying Historic Data: If encountering issues with time travel queries, review timestamps, and version numbers used in the queries.
Delta Live Tables:
- Real-time Sync Issues: If changes aren't reflecting in real-time, check connectivity, change capture settings, and error logs in Delta Live Tables.
Monitoring and Debugging:
- Logging and Monitoring: Use Azure Monitor or other logging tools to track resource utilization, query performance, and potential errors.
- Diagnostic Tools: Utilize Databricks notebooks for diagnosing issues, testing solutions, and understanding query execution plans.
Delta Lake API documentation
The API documentation includes:
- API Reference: A detailed reference guide outlining the APIs available for creating, managing, and querying Delta Lake tables. It includes descriptions of parameters, return values, and usage examples.
- Data Manipulation: Instructions for performing common data manipulation tasks like inserting, updating, and deleting records within Delta Lake tables. This includes using SQL statements or programmatic APIs.
- Configuration and Settings: Detailed explanations of table properties, configuration options, and settings that control Delta Lake behavior. This helps users tailor Delta Lake to their specific data and performance requirements.
- Concurrency and Transactions: Information on handling concurrent operations and managing transactions to ensure data consistency and reliability.
- Optimization Techniques: Guidance on optimizing query performance, including using indexing, partitioning, and file compaction strategies.
- Time Travel and Versioning: Explanations of how to utilize Delta Lake's time travel feature to query historical data versions and manage data retention.
- Streaming and Integration: Documentation on integrating Delta Lake with streaming platforms and data pipelines, enabling real-time data ingestion and processing.
- Error Handling: Guidance on interpreting error messages, debugging common issues, and resolving potential errors encountered while using Delta Lake.
Conclusion
- Delta Lake is a storage solution that enhances data lakes in Azure, offering ACID transactions and schema enforcement for reliable data processing. It is an open-source storage layer.
- Delta lakes offers ACID (Atomicity, Consistency, Isolation, Durability) transactions to data lakes.
- Delta Lake is designed for big data and analytics workloads.
- Delta Lake works with popular data processing engines like Apache Spark. It enables time travel, allowing access to historical data snapshots.
- Delta Lake helps manage data quality and consistency in data lakes.