Machine Learning Pipelines With Azure ML Studio
Overview
Azure ML Studio's machine learning pipelines are powerful tools that simplify and streamline the model creation process. Data scientists and engineers may use these pipelines to coordinate and automate various processes in the machine learning workflow, from data pretreatment to model training and deployment. Azure ML Studio's user-friendly interface enables users to easily construct, execute, and monitor pipelines.
![]()
Azure ML Studio simplifies and streamlines the entire machine-learning process. It provides a graphical interface for creating, testing and deploying machine learning models. With Azure ML Studio, you can simply piece together data pre-processing, feature engineering, model training, and deployment phases, making complicated jobs look easy.
What are Azure Machine Learning Pipelines?
Azure Machine Learning Pipelines are strong tools that assist in streamlining and automating the end-to-end machine learning workflow. They enable data scientists and developers to organize and manage multiple steps of the machine learning process, from data preparation and model training to deployment and monitoring, all inside a single, coherent framework.
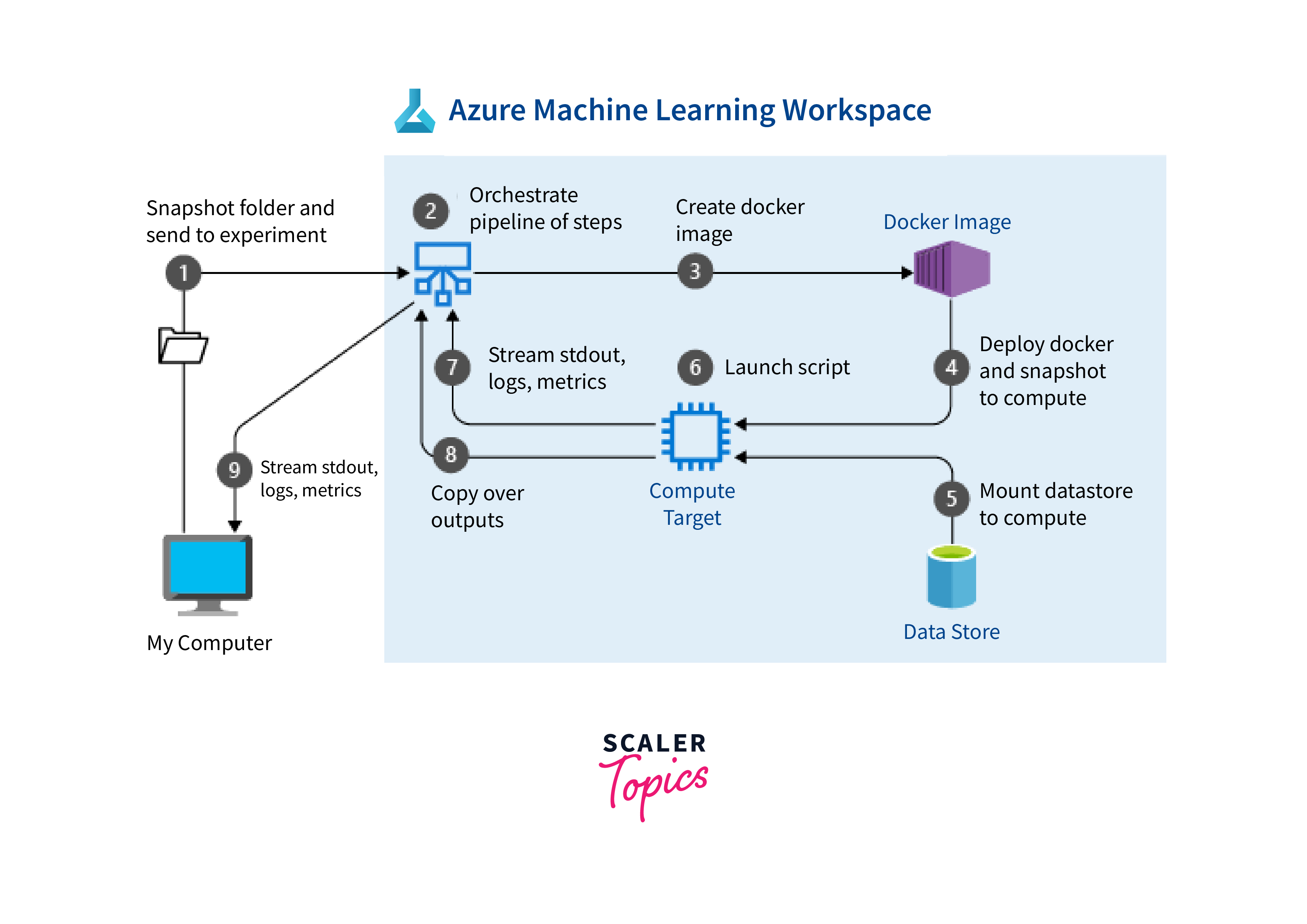
Pipelines in Azure ML Studio provide efficiency and reproducibility, like an assembly line for data and model processing. For simple tracking and version control, users specify stages, sources, operations, and dependencies. This platform enables teams to communicate quickly on machine learning projects while maintaining consistency and repeatability. The user-friendly interface allows organizations to derive important insights from their data by supporting end-to-end processes.
Prerequisites
To use Azure Machine Learning pipelines at their full potential it is required for a developer to have a deep understanding of the following concepts-
- Azure Fundamentals:
Knowing the fundamentals of Microsoft Azure is essential. Azure services, subscriptions, and resource groups should all be known to you. This information will assist you in efficiently navigating the Azure environment. - Machine Learning Concepts:
A thorough knowledge of machine learning principles is essential. To develop and maintain effective pipelines, you need to be familiar with data preparation, model training, and assessment. - Python Development:
Azure Machine Learning pipelines are written in Python, knowledge of the language is required. Python libraries such as scikit-learn, Pandas, and NumPy should be familiar to you. - Azure Machine Learning Studio:
Become acquainted with the Azure Machine Learning Studio, which serves as a platform for developing and maintaining pipelines. Discover how to build and customize workplaces and experiments. - Version Control (e.g., Git):
Understanding version control technologies such as Git is essential for effectively managing machine learning projects. - Docker:
Understanding containerization with Docker can help you package and deploy pipeline processes.
Register Component in Your Workspace
The registration of a component in your Azure Machine Learning workspace is a critical step in the development of effective data pipelines. Here are the simple yet technical procedures for accomplishing this:
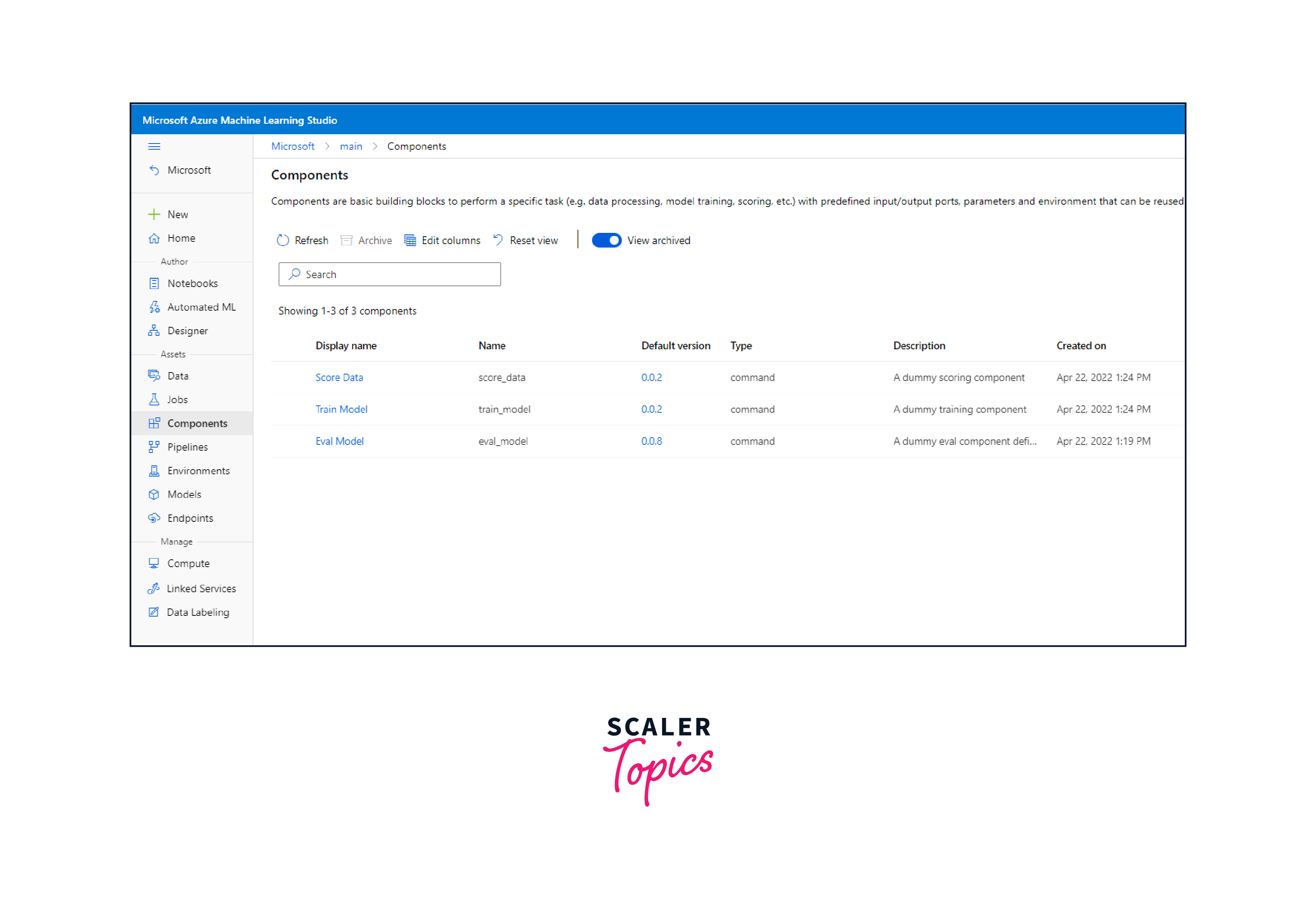
- Access Your Workspace:
Begin by navigating to your Azure Machine Learning workspace. Check that you are logged in and have the required permissions. - Define the Component:
Determine the purpose of your component. It might be data preparation, model training, or something else. - Write a Python Script:
Create a Python script that specifies the logic of your component. This script will serve as the component's heart. - Wrap the Script:
Wrap your script with the AzureML Python SDK's 'ScriptRunConfig' or 'PythonScriptStep' to make it a component. This step guarantees that your component can be executed in a pipeline. - Register the Component:
You can now register your component in your workspace by using Component.register() or PipelineStep.register(). Give it a name and a description for future reference. Version Control:
It's a good idea to version your components for easier monitoring and replication. - Use in Pipelines:
Finally, you may incorporate your registered component in your machine learning pipelines, optimizing your data processing and model-building procedures.
Create a Pipeline Using Registered Component
Using registered components to build a pipeline in Azure Machine Learning Pipelines is a simple procedure that improves the efficiency of your data operations. The following are the key stages to accomplishing this:
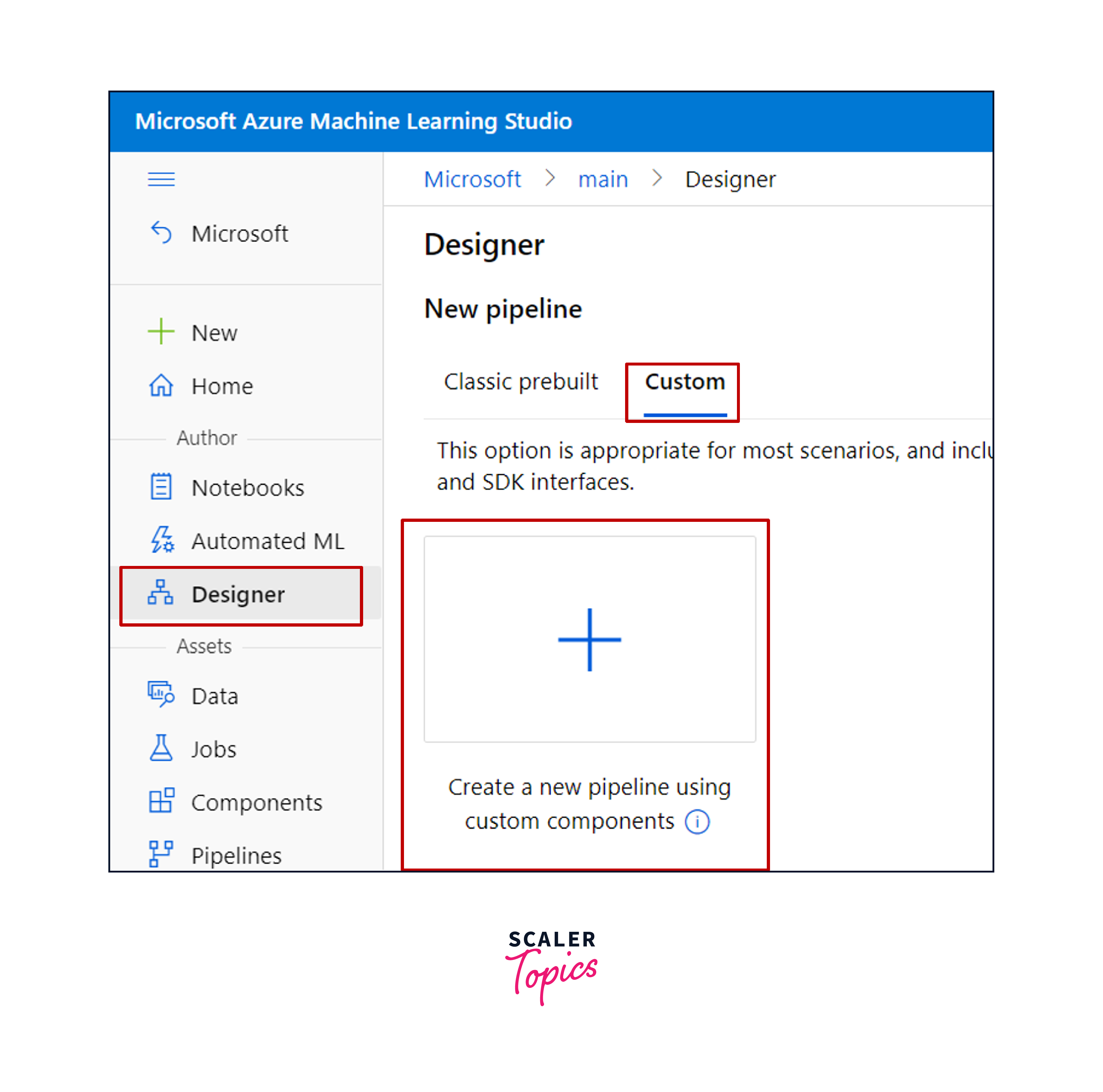
- Environmental Preparation:
Begin by making certain that your Azure Machine Learning environment is correctly configured. This covers the configuration of your workspace and compute resources. - Component Registration:
Specify which stages, code, or scripts should be included in your pipeline. Register these components in your Azure Machine Learning workspace to reuse them across several pipelines. - Pipeline Definition:
To define your pipeline, use the Azure Machine Learning SDK. You may now put your registered components together in a sequence to reflect your data processing or machine learning workflow. - Run Configuration:
Specify your pipeline's computing goal as well as any unique run parameters. This phase specifies where and how your pipeline will be run. - Execution:
Start your pipeline. This will start the registered components in the specified sequence, effectively automating your data workflow. - Monitoring and Logging:
Azure Machine Learning has capabilities for monitoring pipeline runs, allowing you to track progress and troubleshoot as needed.
Submit Pipeline
The important step in bringing your data processes to life is submitting a pipeline in Azure Machine Learning Pipelines. Here's a step-by-step instruction for submitting the pipeline you established earlier:
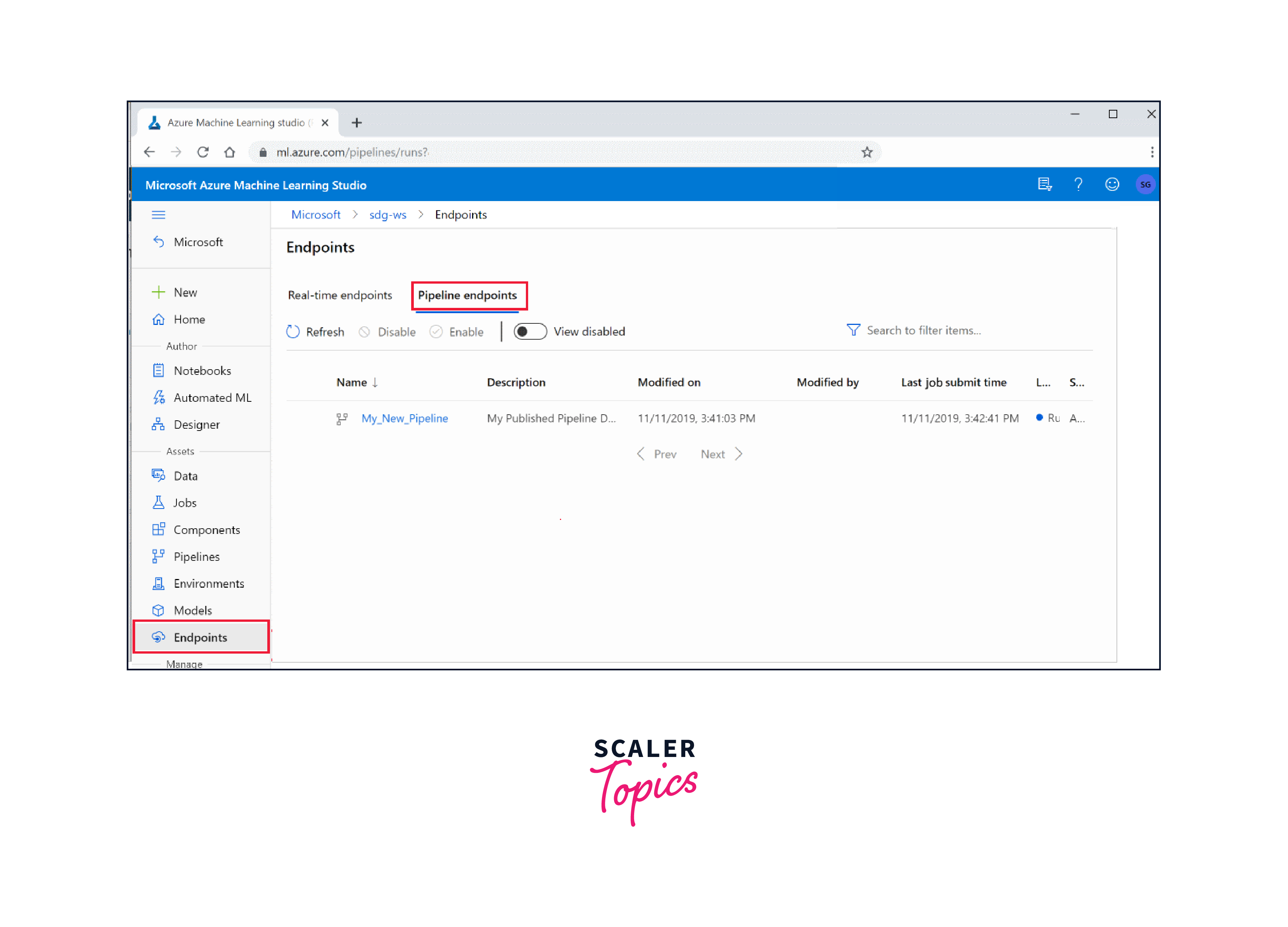
- Access Your Workspace:
Begin by navigating to your Azure Machine Learning workspace, which contains the pipeline definition. Check that you're in the appropriate environment. - Retrieve the Pipeline:
Using the Azure Machine Learning SDK, fetch the pipeline object you've created. This object holds all of the instructions for your machine learning or data processing procedure. - Create an Experiment:
Define an experiment to encapsulate your pipeline run. An experiment helps you organize and track multiple pipeline runs efficiently. - Submit the Pipeline:
Once you've completed your experiment, submit the pipeline using the submit function. This action initiates pipeline execution, coordinating the data processing or machine learning activities described therein. - Monitor development:
Using the Azure Machine Learning interface, you may track the development of your pipeline. It delivers real-time insights into each phase, making it simple to detect and resolve any problems that may develop. - Analyze and Validate:
After the pipeline run is finished, analyze the results and logs to confirm that everything went as planned.
common Pitfalls to Avoid
- Neglecting Data Quality:
Ensure your data is clean and well-prepared, as poor data quality can lead to unreliable model outcomes. - Overlooking Cost Management:
Keep an eye on Azure costs; unused resources and inefficient computing can lead to unexpected expenses. - Skipping Version Control:
Failing to use version control can result in confusion and difficulties when managing pipelines and models. - Ignoring Security Practices:
Neglecting security measures can jeopardize sensitive data; implement proper security protocols from the start. - Lacking Monitoring and Optimization:
Not continuously monitoring and optimizing your pipelines can lead to inefficiencies and missed opportunities for improvement.
Conclusion
- Azure Machine Learning Pipelines provide a streamlined method for automating and managing complicated data and machine learning operations, eliminating manual labor and mistakes.
- Azure Machine Learning provides repeatability by allowing users to version pipelines and components, making it simple to monitor and duplicate findings for experimentation and auditing.
- By enabling you to set compute objectives and scaling, these pipelines optimize resource utilization, assuring cost-effectiveness in data processing and model training.
- Azure Machine Learning Pipelines allow for parallel task execution, scaling out as required, which speeds up time-sensitive activities and improves efficiency.
- The platform has built-in monitoring and debugging tools for tracking pipeline run progress, making it simple to discover and fix issues in real time.
- They provide a coherent framework for data scientists and developers to organize and automate various steps, from data preparation to model deployment.
- These pipelines ensure efficiency, repeatability, and simplified version control for machine learning projects.
- Registering components in your Azure Machine Learning workspace is a critical step, and it involves defining, scripting, wrapping, and registering the component for future use.