Basic Image Operations in Computer Vision
Overview
Computer vision is a field of AI that enables machines to understand and interpret visual data. Image processing is a key component of computer vision, involving basic operations such as color, brightness, contrast, and sharpness adjustments. Image segmentation divides images into smaller regions or objects using techniques like thresholding and edge detection. Image registration aligns and matches images from different viewpoints or times. These operations enable machines to process and analyze visual data for a wide range of applications, from healthcare and autonomous vehicles to robotics and surveillance.
Introduction
The emphasis of image processing is the processing of raw images to apply some kind of change. Typically, the purpose is to refine images or prepare them as input for a certain job, whereas computer vision aims to describe and understand images. For example, noise reduction, contrast, and rotation operations are common image processing components that can be handled at the pixel level without requiring a comprehensive understanding of the image.
Image Representation
An image comprises a rectangular array of dots known as pixels and is also defined as a two-dimensional function. To represent digital images, we mostly use two methods. Suppose a digital image with M rows and N columns is created by sampling the image f(x, y). The values of the coordinates (x, y) are now discrete quantities. We will utilize integer values for these discrete coordinates to simplify the notation and make things easier. As a result, the coordinates at the origin have the values (x, y) = (0, 0). The following coordinate values along the image's first row are shown as (x, y) = (0, 1). It's crucial to remember that the second sample along the first row is denoted by the notation (0, 1). It doesn't necessarily imply that these were the physical coordinate values when the image was captured.
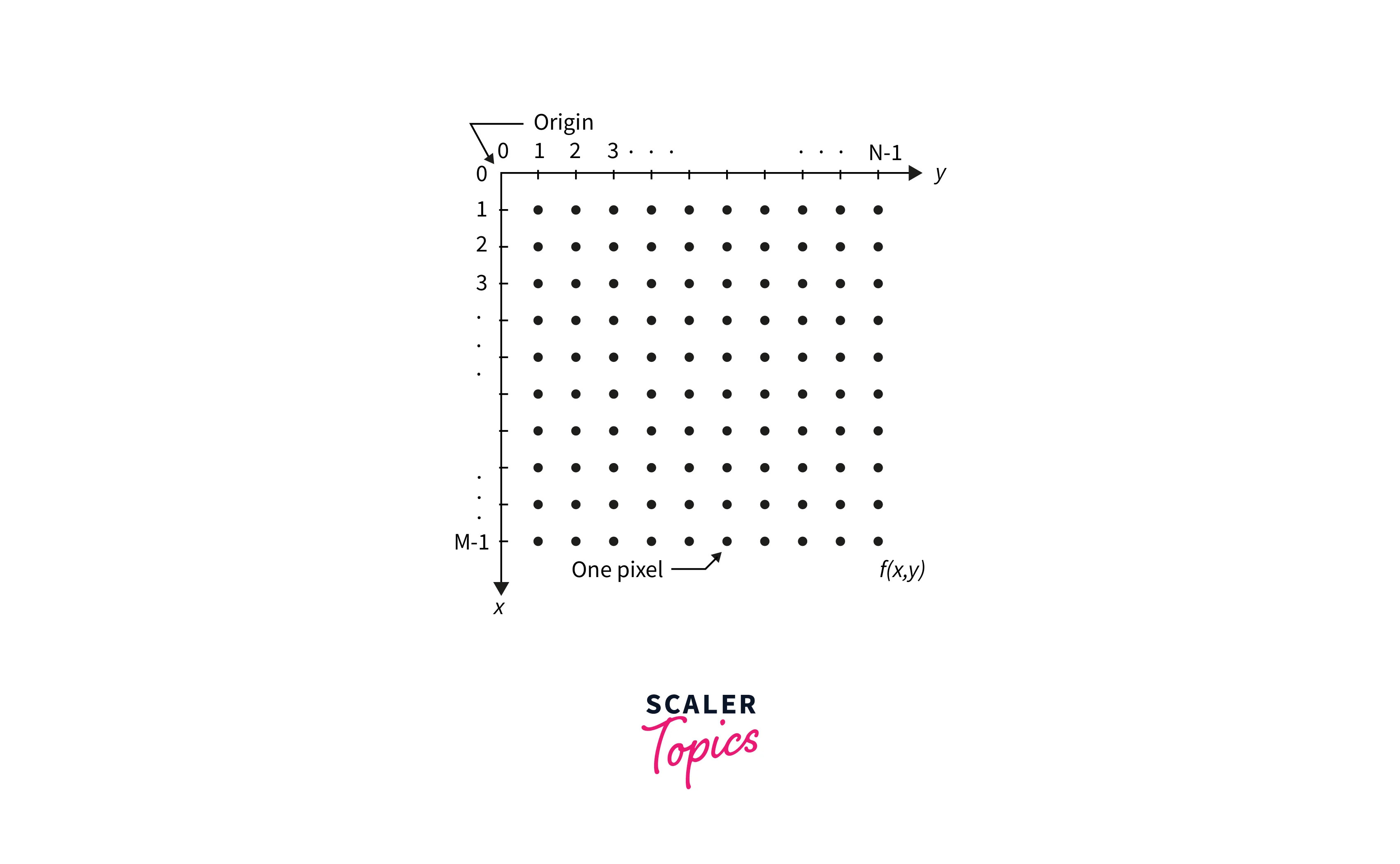
Types of Image Representation
Image as a Matrix
Going on to how an image is represented, the most basic method, which you may have already considered, is to express an image as a matrix. By definition, an image is a set of square pixels (picture elements) arranged in columns and rows in an array or matrix. The elements in these arrays or matrices also represent the pixels or intensity values of the image.
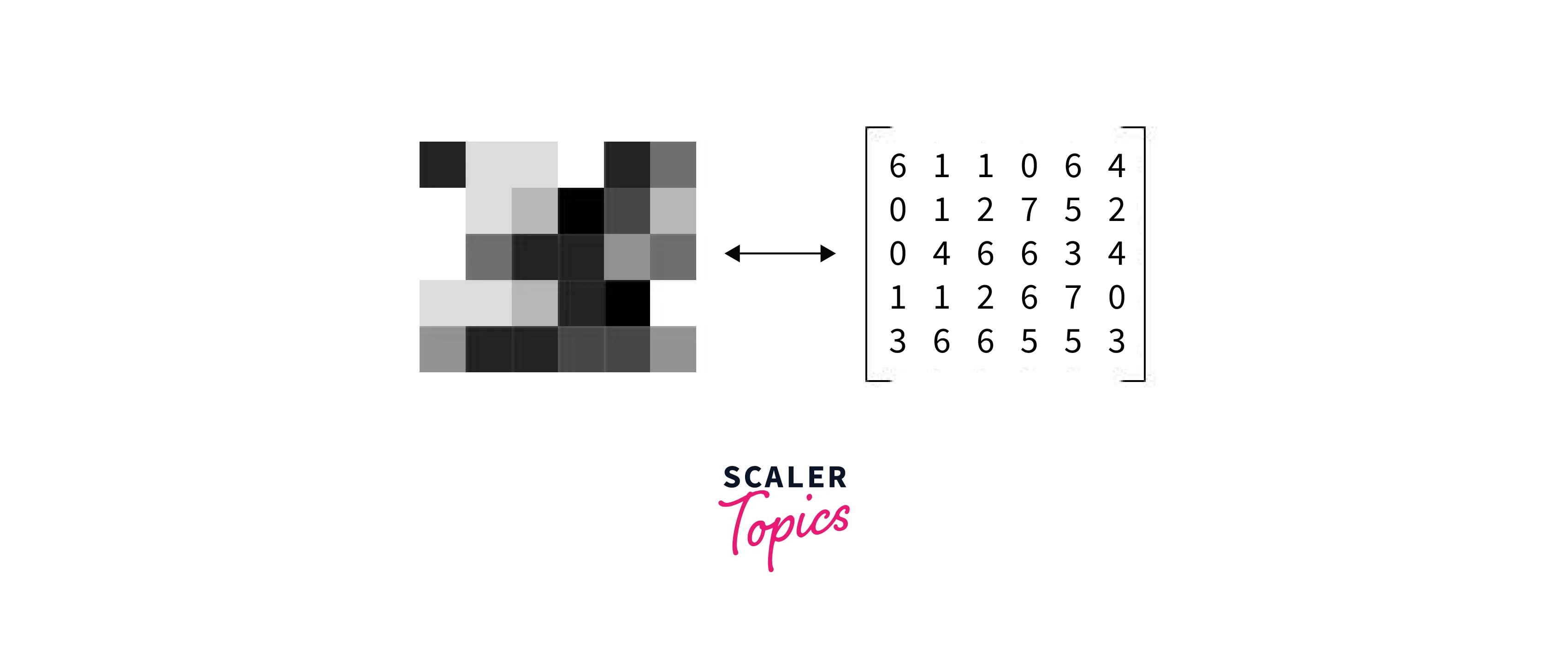
People frequently used up to a byte to represent each pixel in an image. This means that 0 is black and 255 is white, and values between 0 and 255 reflect the intensity for each pixel in the image. A matrix of this kind is constructed for each color channel in the image. Normalizing numbers between 0 and 1 is also typical.
Image as a function
In its most general form, an image is a function f from R2 to R (f: ℝ² → ℝ).It just helps us have operations on images more effectively if we represent it also as a function.A function(f) being going fromR 2 to R, which simply corresponds to one particular coordinate location on the image, say (i, j) and that is what we mean by R2 – f( x, y ) gives the intensity of a channel at position (x, y) , that is If values are normalized, the intensity value can range from 0 to 1 or from 0 to 255. – defined over a rectangle, with a finite range: f: [a,b]x[c,d] → [0,1] – A color image is just three functions pasted together:
• f( x, y ) = (fr( x, y ), fg( x, y ), fb( x, y ))

Advantages and Disadvantages of Image Representations
- It relates to how the transmitted information, such as color, is digitally coded and how the image is saved, i.e., how an image file is structured.
- For the successful identification and recognition of items in a scene, image representation and description are essential.
- Digital images can be modified using matrices since they are matrices when broken down into the finest bits of information (pixels).
- The matrix format of an image also enables operations like brightness addition and rotation.
- Also, because the color value information is readily available and well-organized, filters that can alter an image's coloring are simple.
- Image processing has benefited tremendously from matrix manipulation.
- Matrix only accepts photos in.jpg or.jpeg format. The system won't accept other file types, including those based on the.jpg standard, like.png.
- Every image that Matrix processes uses the sRGB color profile. Nevertheless, photographs with an "Uncalibrated" Color Representation or any other standard may be "color shifted" or lose quality during upload. Images with no Color Representation defined may be used.
- This is the suggested minimum size because Matrix saves all listing photos at 2048 pixels wide by 1536 pixels tall. 3000 by 3000 pixels is the largest size that Matrix will accept. Pictures that are larger than 3000 pixels in either direction may not upload.
- Image Transformation is possible when an image is represented as a function.
Image Acquisition and Preprocessing
Image acquisition and preprocessing are particularly important in applications like medical imaging, where high-quality images are critical for accurate diagnosis and treatment.
Image Acquisition
In the context of image processing, image acquisition can be roughly defined as acquiring an image from a source, typically a hardware-based source, to send it via subsequent processes.
The initial stage in the workflow sequence for image processing is always image capture because processing is impossible without an image. It can be crucial in some sectors to have a constant baseline from which to work, and the obtained image is entirely unprocessed and is the product of whatever hardware was used to generate it. If the image captured by a sensor (e.g., a camera) is not already in digital form, it is converted using an analog-to-digital converter.
Image Acquisition Techniques
The image acquisition process depends entirely on the hardware system, which may include a sensor, also a hardware device. Light is converted into electrical charges by a sensor. A camera's sensor measures the reflected energy from the scene being captured.
The most common and fundamental sensor for image acquisition is the photodiode. It is made of silicon materials and has an output voltage proportional to the incoming light. The typical approach for acquiring a 2D digital image employs a matrix of single sensors. Two technologies exist side by side.
- The CMOS (complementary metal oxide semiconductor) technique is the dominant technology for reading the output voltage of each sensor: each sensor is coupled with its analog-to-digital conversion circuit.
- The CCD's essential concept is employing a unique conversion circuit. Each sensor's potential is shifted pixel by pixel: potentials are shifted by one column, then those in the last column are counted by a unique circuit. Digitization is the final step in digital picture generation, which is both the sampling and quantization of the observed scene.
Sampling is converting a continuous scene into a discrete map. The matrix of pixels does this naturally. Sampling a continuous image results in information loss. Intuitively, it is obvious that sampling reduces resolution.
Quantization converts continuous light intensities into a finite collection of numbers. Images are generally quantized into 256 gray values; each pixel consumes one byte (8 bits). The reason for allocating 256 gray values to each pixel is not only because it is well-matched to computer architecture but also because the amount of values is sufficient to give humans the illusion of continuous gray value change.
Such distortions, in addition to greater effect and quantization noise, can impact image acquisition. The two most common distortions are noise and blurring.
Image Preprocessing Techniques
Image Enhancement Image enhancement refers to manipulating images to get relevant results for completing specific tasks. Preferably, this procedure pertains to image filtering by completing activities such as noise removal, contrast modification, brightness, and sharpening of photos to improve the quality of the original photographs.
It highlights or hones the edges and borders of images and differentiates them to make realistic showcases more suitable for display and inspection. To achieve the mentioned attributes, picture augmentation broadens the dynamic range of selected features, allowing them to be easily identified.
Image restoration Image restoration is accomplished by reversing the blurring process, which is accomplished by imaging a point source and using the point source image, known as the Point Spread Function, to recover the image information lost during the blurring phase.
Image restoration differs from image enhancement in that the latter is intended to highlight characteristics of the image that make the image more pleasant to the observer rather than necessarily producing real data from a scientific standpoint. Image restoration techniques aim to decrease noise and regain resolution loss.
Image compression Image compression is used to reduce the size of memory capacity without affecting or destroying its quality, sparing an image or the data transmission required to communicate it. Image compression is defined as reducing the amount of information expected to express to a digital image.
Image segmentation Image segmentation is an essential step in image processing that includes dividing an image into several segments to differentiate the object of interest from the background. Thresholding, boundary-based segmentation, region-based segmentation, template matching, and texture segmentation are all segmentation methods.These methods allow you to locate objects in an image and identify their boundaries.
Image representation and description This process occurs after the picture segmentation of objects. It is used to effectively discover and recognize items in a scene to define the quality characteristics during design recognition or in quantitative codes for competent capacity during image compression.
The representation is related to showing visual output as a border or region. It can include shape properties in corners or regional representations such as roughness or skeletal shapes.
The description, on the other hand, is most generally known as feature selection, and it collects useful information from an image. The retrieved information can aid in accurately distinguishing between object classes.
Image Labeling The process of labeling an object based on its description for classification purposes. This is a critical stage in Computer Vision. A vast enough corpus of images must be analyzed and labeled for the Computer Vision model to find comparable items in additional images.
Comparison of Image Acquisition and Preprocessing Techniques
- Techniques for image acquisition and preprocessing are crucial to image processing. The initial phase in the procedure, image acquisition, establishes the caliber of the image that will be used for future analysis. On the other hand, preprocessing techniques are employed to enhance the acquired image's quality and prepare it for additional analysis.
- The application and the kind of image that needs to be obtained will determine which image acquisition method is best. Digital cameras, for instance, can be used to take pictures of items, whereas X-ray equipment can be used to take pictures of an object's internal structure.
- The type of image and analysis must be done to determine which preprocessing method should be used. For instance, image enhancement techniques can be used to improve an image's visual appeal, while image segmentation techniques can be used to divide an image into several areas or segments.
In conclusion, the choice of image acquisition and preprocessing techniques in image processing depends on the application and the required analysis.
Image Transformation
Image transformation is the process of altering the appearance of an image in some way. This may involve changing the scale or orientation of the image, applying filters or other effects, or transforming the image to a different color space.
Geometric Transformations of Images
Image geometric transformations include translation, rotation, and affine transformation. Translation The altering of an object's location is known as translation. If you know the (x,y) shift and let it be (tx,ty), you may construct the transformation matrix M as follows:
M=
[1 0 tx
0 1 ty]
You can take make it into a Numpy array of type np.float32 and pass it into the cv.warpAffine() function .cv.warpAffine() function Applies an affine transformation to an image. Rotation The transformation matrix of the form M is used to rotate an image for an angle.
M=
[cosθ sinθ
-sinθ cosθ]
However, OpenCV supports scaled rotation with an adjustable center of rotation, allowing you to rotate in whatever direction you want. The modified transformation matrix is given by
[α β (1−α)⋅center.x−β⋅center.y
β α β⋅center.x+(1−α)⋅center.y ]
where, α=scale⋅cosθ, β=scale⋅sinθ OpenCV includes a function, cv.getRotationMatrix2D, to find this transformation matrix.
Affine Transformation
All parallel lines in the original image will remain parallel in the output image after affine transformation. We require three points from the input image and their matching places in the output image to find the transformation matrix. Then cv.getAffineTransform returns a 2x3 matrix to be provided to cv.warpAffine.
Color Transformations
Color Transforms converts three-band red, green, and blue (RGB) images to one of several specialized color spaces and back to RGB. You can generate a color-enhanced color composite image by adjusting the contrast stretch between the two transforms. You can also substitute the value or lightness band with another band (generally with higher spatial resolution) to create an image that combines one image's color features with another's spatial properties.
Contrast stretching is a simple technique for increasing the contrast of a digital image by rescaling the pixel values to a larger range. It can enhance the visibility of details and features in an image, particularly if the original image has low contrast or bad lighting. But, contrast stretching has some drawbacks that you should be aware of when using it in your digital image processing applications. To avoid this, always examine the image's histogram before and after contrast stretching and modify the parameters accordingly. Other techniques, such as histogram equalization or adaptive contrast enhancement, can improve contrast without clipping or saturating the pixel values.
Comparison of Image Transformation Techniques
There are numerous image transformation techniques, each having pros and cons. Below are some of the most frequent techniques, along with a quick comparison: The process of resizing an image is known as scaling. It can be used to enlarge or decrease the size of an image. Scaling an image larger may result in detail loss while scaling it smaller may result in quality loss. Rotation is spinning an image at a specific angle. It can be used to adjust an image's orientation or to provide interesting visual effects. However, rotating an image may result in information loss at the image's edges. Translation is shifting an image within the visual frame to a different location. It can be used to align an image or to build a composite image from several photographs. There is no information loss during translation. Shearing alters an image by shifting pixels along one axis while holding the other axis constant. It can be used to rectify an image's skewness or to produce fascinating aesthetic effects. Shearing does not result in information loss. Warping is the process of changing an image by extending or compressing it unevenly. It can be used to rectify picture distortion or to provide interesting effects. Warping may result in information loss along the image's edges. Cropping is the process of eliminating a section of an image. It can be used to isolate a certain area of an image or to remove undesired elements. Cropping may result in data loss.
Each transformation approach has advantages and disadvantages, and the unique application and desired outcome determine the technique used.
Image Segmentation
Definition and Explanation of Image Segmentation
Image segmentation is a computer vision approach that divides an image into several segments or areas based on pixel values. Image segmentation aims to simplify or modify an image's representation into something more meaningful and easier to examine.
Image segmentation has numerous uses, including object detection and tracking, picture compression, medical image analysis, and robotics.
Types of Image Segmentation
Image segmentation can be accomplished in a variety of ways, including:
Thresholding: This technique includes defining a pixel intensity threshold for an image, above or below which the pixels are separated into different regions.
Region-based segmentation: This technique groups pixels together based on similarities in color, texture, or other visual qualities.
Edge detection is the process of recognizing edges or boundaries between various regions in an image.
Clustering is a technique that groups comparable pixels based on their spatial closeness and color similarity.
Watershed segmentation is a technique that simulates the flow of water over an image, with the image's peaks and valleys determining the segmentation borders.
Steps Involved in Image Segmentation
The process of image segmentation in computer vision typically involves the following steps: 1.Image pre-processing: The input image is pre-processed in this step to eliminate noise, improve contrast, and normalize the illumination. This step is necessary to ensure that the image segmentation algorithm can recognize and classify the various sections in the image accurately. 2.Feature extraction: In this step, relevant features from the pre-processed image are extracted, such as color, texture, shape, and intensity. The features used are determined by the application and the properties of the image being segmented. 3.Image segmentation: The image is segmented into many segments or areas based on the extracted features in this step. This can be accomplished through the use of many approaches such as thresholding, clustering, edge detection, and region expansion. 4.Post-processing: The generated regions may need to be modified or post-processed after segmentation to remove tiny artefacts or merge adjacent sections. This step ensures that the final segmentation result is correct and consistent. 5.Evaluation: Lastly, the quality of the segmentation result is assessed using a variety of measures such as precision, recall, and F1 score. This phase is critical for ensuring that the segmentation algorithm is robust and capable of generalizing to new pictures.
Advantages and Disadvantages of Image Segmentation Techniques
Advantages
- Image segmentation provides a more detailed and relevant comprehension of an image by splitting it into smaller sections or items. This enables more accurate image analysis and interpretation.
- Image segmentation can boost the efficiency and accuracy of many image processing tasks like object detection, tracking, and classification.
- Image segmentation can be used to compress an image by decreasing the number of bits necessary to represent it. This can help with image storage and transmission.
- Image segmentation is utilized extensively in medical imaging for disease diagnosis, planning, and monitoring. It can aid in the identification of anomalies and regions of interest in medical images.
Disadvantages
- Image segmentation can be computationally expensive and time-consuming, especially when dealing with large and complicated images. This may limit its usefulness in real-time or high-speed applications.
- Sensitivity to noise and artifacts
segmentation can be susceptible to noise and distortions in the image, resulting in erroneous or inconsistent segmentation results. - Dependency on image features: The performance of image segmentation algorithms can be heavily influenced by image qualities such as texture, color distribution, and illumination.
- Subjectivity: Image segmentation can be subjective, depending on the segmentation method and settings used, as well as the user's skill. This can cause differences in segmentation results, limiting their dependability.
Image Feature Extraction
The process of choosing or extracting useful information or features from an image is known as image feature extraction. Several computer vision applications, such as object identification, recognition, and tracking, depend on it. The following are some of the most common image feature extraction techniques:
Types of Image Feature Extraction
Edge detection is a technique for extracting the boundaries or edges of objects in an image. It works by detecting differences in image intensity or colour.
Blob detection is a technique for extracting regions of interest in an image that has a similar intensity or hue. It is frequently used to detect circular or elliptical objects.
Corner detection is a technique for detecting the corners or places of interest in an image. It is frequently employed in feature-based matching and tracking.
Texture analysis is a technique for extracting the texture patterns or features of an image. It is frequently employed in picture classification and segmentation.
Scale-invariant feature transform (SIFT): SIFT is a prominent feature extraction approach for identifying and extracting critical points in an image that are insensitive to changes in scale, rotation, and lighting.
HOG is a feature extraction technique that calculates the gradient magnitudes and orientations in an image and generates a histogram of the gradient orientations.
Convolutional neural networks (CNNs): CNNs are deep learning models that can learn and extract characteristics from photos automatically. They have demonstrated extraordinary success in a wide range of computer vision applications, including object identification and recognition.
Steps Involved in Image Feature Extraction
The steps involved in image feature extraction in computer vision typically include the following: Image preprocessing includes cleaning and improving the input image to remove noise, artifacts, and other undesired elements that could interfere with feature extraction. Image smoothing, contrast enhancement, and noise reduction are all common preprocessing techniques.
Feature selection: In this step, a set of relevant features that can represent the salient qualities of the input image is chosen. Domain expertise, image analysis techniques, or machine learning algorithms are frequently used to choose features.
Feature extraction: In this stage, the selected features from the input image are computed. A variety of approaches, including edge detection, corner detection, texture analysis, and deep learning, can be used to extract features.
Feature representation: In this stage, the extracted features are represented in a suitable manner that may be used for further analysis or categorization. Feature vectors, histograms, and graphs are examples of common representations.
Feature normalization is the process of scaling or normalizing feature values such that they are similar across images or datasets. Mean normalization, standardisation, and min-max scaling are examples of common normalization approaches.
Feature reduction: In this stage, the extracted features' dimensionality is reduced to improve computing efficiency, minimize noise, or prevent overfitting. Principal component analysis (PCA), linear discriminant analysis (LDA), and feature selection algorithms are examples of common reduction techniques.
Advantages and Disadvantages of Image Feature Extraction
Advantages:
- Accuracy: By giving a more relevant and informative representation of visual data, feature extraction can assist enhance the accuracy of computer vision algorithms.
- Reduced dimensionality: Feature extraction can assist in reducing the dimensionality of input data, making it easier to handle and evaluate.
- Domain-specific features: Feature extraction can be adapted to specific domains or applications, allowing the acquisition of domain-specific aspects that generic image analysis approaches may not capture.
- Transfer learning: Pre-trained models can be fine-tuned for new applications with limited labeled data using feature extraction as a pre-processing step.
Disadvantages:
- Information loss: Feature extraction might result in information loss since some features may be lost or aggregated during the process.
- Noise sensitivity: Feature extraction can be susceptible to noise and other picture distortions, affecting the quality and dependability of derived features.
- Overfitting: Overfitting occurs when the extracted features are particular to the training data and do not generalize well to new data.
- Feature extraction can be computationally expensive, particularly for large datasets and complicated feature extraction approaches.
Image Classification
Image classification is a task in computer vision in which an image is classified into one or more specified classes or categories. Image categorization seeks to automate the process of detecting and distinguishing objects, sceneries, or patterns in digital photographs.
Types of Image Classification
There are several approaches to image classification, including:
Binary Classification: Binary classification is a sort of image classification in which an image is classified into one of two categories. Differentiating between cats and dogs, for example.
Multi-Class Classification: A sort of image classification in which the aim is to categorise an image into one of the numerous classes. For instance, categorizing an image of an animal into one of numerous groups, such as cats, dogs, birds, or fish.
Multi-Label Classification: Multi-label classification is a sort of image classification in which many labels are assigned to an image. For instance, detecting several things in an image and labeling each object.
Hierarchical Classification is a method of image classification in which the classes are grouped in a hierarchical tree structure. A tree structure of animal classifications, for example, where the top level includes broad groups like mammals, birds, and reptiles, and the lower levels include more particular classes like cats, dogs, and bears.
Object Detection and Classification: Object detection and classification is a type of image classification that detects and localizes objects within an image in addition to classifying it. Identifying and classifying all instances of vehicles in an image, for example.
Semantic Segmentation: Semantic segmentation is a sort of image classification in which each pixel in an image is assigned a semantic label. Labeling all pixels in an image that belong to a specific object, such as a person or an automobile, is one example.
Steps Involved in Image Classification
Data Collection: The process of gathering a dataset of labeled photographs, each of which is associated with a predefined label or category.
Data Preprocessing: The preparation of data so that it can be used to train the model. This stage involves duties including image scaling, normalization, and data augmentation.
Feature Extraction: The extraction of visual features from an input image utilizing techniques such as edge detection, texture analysis, and deep learning.
Feature Selection: The selection of relevant and discriminative traits that can be utilized to distinguish across classes.
Model Training: Using a supervised learning technique, such as logistic regression, decision trees, or deep neural networks, a machine learning model is trained on the extracted features and labels.
Model Evaluation: A separate test set is used to evaluate the trained model's accuracy and generalization performance. To assess the model's performance, many measures such as accuracy, precision, recall, and F1 score can be utilized.
Model Deployment: The deployment of the trained model to categorize new, unseen images by extracting their attributes and predicting their labels using the learned model.
Advantages and Disadvantages of Image Classification Techniques
Advantages
- Image classification algorithms automate the image analysis process, making it faster and more efficient than manual analysis.
- Objectivity: Picture classification systems produce consistent, objective results by removing any potential for subjective biases presented by human analysts.
- Scalability: Image classification techniques can handle vast amounts of data and can be readily scaled up or down according to the size of the dataset.
- Image classification techniques are versatile in that they may be used for a large range of image kinds and formats, making them valuable in a variety of domains and applications.
Disadvantages
- Dependency on data quality and quantity: Image classification systems' accuracy is dependent on the quality and amount of training data. The generated model may be inaccurate if the dataset is small or non - representative.
- Image classification systems can be complicated, necessitating particular knowledge and experience to implement and interpret.
- Overfitting: Image classification models can overfit to training data, which means they perform well on training data but poorly on fresh, unknown data.
- Sensitivity to feature selection: The features employed in image classification can have a considerable impact on the model's performance, and choosing the proper features can be challenging and time-consuming.
- Computationally expensive: Certain picture categorization techniques, particularly those based on deep learning algorithms, can be computationally expensive and necessitate a large amount of computing power.
Applications of Basic Image Operations
Medical Imaging
Medical imaging and diagnostics have grown in importance in modern healthcare because they provide crucial insights that can assist clinicians in detecting and diagnosing disorders. Users can perform a variety of image processing procedures in 2D and 3D images, including:
- Image filters are used to reduce and remove undesirable noise or distortions.
- Cropping and resampling input data to make image processing easier and faster
The progress of computer vision in healthcare in recent years has resulted in faster and more accurate diagnoses. Medical images can be instantly examined for disease indications using computer vision algorithms, allowing for more accurate diagnosis in a fraction of the time and cost of traditional procedures. By avoiding unnecessary treatments, assisted or automated diagnostics help to lower total healthcare expenses. Image recognition systems have demonstrated tremendous success in detecting illness patterns.
Robotics
Image processing is a basic part of robotics, allowing machines to comprehend and interpret visual data from their surroundings. Robots can extract meaningful information from images and utilize it to make decisions and complete tasks by applying image enhancement, restoration, and segmentation techniques.
Image enhancement techniques improve an image's quality so that a robot can better interpret it. Image restoration techniques help a robot understand images more properly. Image processing techniques can also be utilized for 3D reconstruction and localization, which are critical for robots to understand their surroundings and navigate.
Surveillance and Security
The three primary categories of visual tracking, biometrics, and digital media security can be used to put together the numerous problems of security in daily life that can be resolved by utilizing image processing techniques. Visual tracking refers to computer vision techniques that analyze a scene to extract features representing things (e.g., pedestrians) and track them to provide input to analyze any unusual behavior.
Biometrics is the technology of detecting, extracting, and analyzing physical or behavioral characteristics of humans for identifying purposes. In digital media security, watermarking techniques are commonly used to protect copyright by embedding information within media files.
Autonomous Vehicles
Semantic segmentation is a popular perception method for self-driving automobiles in which each pixel of an image is assigned to a specified class. Many segmentation models are assessed in this context regarding accuracy and efficiency. To recognize lanes, street signs, and obstructions accurately, a multistage pre-processing approach is used.
The proposed system, utilized to control the autonomous vehicle, processes the photos recorded by the autonomous automobile. Canny edge detection was used to detect the edges in the acquired image, and the Hough transform was used to detect and designate the lanes immediately to the left and right of the car.
Augmented Reality
Integrating virtual features in a real-world setting is known as augmented reality. It is a new way of looking at information in connection with the real world. In augmented reality, many methods of image processing are employed for a variety of different input sources. Several outputs can be generated based on the input sources.
Preprocessing evaluates the scanned image for noise, skew, and tilt. Following preprocessing, the noise-free image is sent to the segmentation step, where it is broken into individual characters. The scanned image is subsequently transformed to grayscale and then to binary.
Feature Extraction: Feature extraction comes after segmentation. Individual image glyphs are considered for image extraction in this case. In augmented reality, real-time image processing is performed so that a user can hover a camera over a page and acquire augmented information such as a 3D model, video, or explanation about that page.
Conclusion
- Fundamental image operations are required in computer vision for processing and evaluating digital images.
- These operations include reading and writing image files, scaling images, and converting images to different formats.
- Image enhancement techniques can enhance image quality by lowering noise, increasing contrast, or sharpening edges.
- Image segmentation is separating an image into several segments or areas, whereas feature extraction is detecting essential features in an image.
- Image classification is the process of labeling or categorizing an image based on its qualities or attributes, and numerous approaches and algorithms are available to accomplish this goal.