Introduction to Batch in Big Data Analytics
Overview
Batch data processing is an important part of big data analytics which requires processing massive amounts of data in batches. This strategy entails gathering data from many sources, organizing it into batches, and processing it later. Batch processing is efficient because it minimizes the time necessary to process huge datasets, making it an effective method for dealing with Big Data. Furthermore, it enables complicated computations and transformations of data, allowing enterprises to get useful insights. As a result, organizations can use batch data processing to evaluate data regularly and gain valuable insights to drive business decisions.
Introduction
Batch data processing is essential in big data analytics for dealing with massive amounts of data. Batch processing entails collecting data from numerous sources, organizing it into batches, and processing it later. This strategy is very effective when dealing with big data sets that cannot be processed in real-time.
Batch data processing divides a large dataset into smaller parts or batches. The batches are processed in order, and the results are saved before proceeding to the next batch. As a result, it is possible to automate the process, making it more efficient and scalable.
Batch processing is an important tool in data processing and analytics. It is especially handy when dealing with big data volumes that cannot be processed in real-time. It is commonly utilized in finance, healthcare, and retail, where vast data must be processed regularly.
Data is processed in batches regularly, often daily or weekly. This plan lets firms review data regularly and extract useful insights to drive business choices. Batch processing also enables organizations to do complex computations and transformations on data, allowing them to unearth important insights that would not be possible with real-time processing.
There are various advantages to batch data processing over real-time processing. It is more efficient, economical, and scalable. It also enables enterprises to process massive amounts of data without overburdening their systems, making it suitable for dealing with Big Data.
What is Batch Data Processing?
Batch data processing is a way of handling and processing huge amounts of data in groups or batches. Data is collected from numerous sources, grouped into batches, and processed later in this procedure. Batch data processing enables efficient and scalable data processing, particularly when working with big data sets.
Batch data processing is utilized in many businesses that handle massive amounts of data. This strategy is especially useful when processing huge amounts of data regularly is a crucial component of corporate operations, such as banking, healthcare, and retail.
Data in batch data processing is often processed regularly, such as daily, weekly, or monthly. The batches are processed one at a time, with the results saved before proceeding to the next. This method allows organizations to execute complex computations and transformations on data, allowing them to unearth important insights and trends.
Batch data processing has various advantages over real-time processing, including higher efficiency, lower cost, and scalability. It is also less error-prone than real-time processing because data may be examined and validated before processing.
Essential Parameters for Batch Processing
Batch processing is essential to big data analytics, allowing firms to handle massive amounts of data efficiently and effectively. However, several critical characteristics must be examined to achieve proper batch processing.
Let us now look at the various essential parameters involved in batch processing:
- Batch size:
Batch size is the amount of data processed at one time. The batch size should be tailored for the given use case and infrastructure to guarantee that the processing is efficient and effective. - Processing frequency:
The frequency at which batches are processed is determined by the processing frequency. The frequency should be established depending on the organization's demands, such as the rate at which data is generated and the data's commercial use case. - Processing time:
Processing time is the time required to process a batch of data. It should be optimized to ensure that processing is completed on time and does not cause bottlenecks in the system. - Fault tolerance:
The ability of a system to recover from faults or failures during batch processing is called fault tolerance. A fault-tolerant system is required to ensure that data is neither lost nor corrupted during processing. - Data integration:
Data integration is the process of merging data from several sources to form a complete dataset. It is critical to have a data integration procedure in place to ensure data is correctly formatted and processed during batch processing.
Batch in Big Data Analytics
Batch data processing is essential to big data analytics, allowing firms to handle massive amounts of data efficiently and effectively. Batch processing is especially effective in areas where processing huge amounts of data regularly is vital to corporate operations, such as banking, healthcare, and retail. In addition, batch processing is used in various sectors to evaluate data regularly and gain important insights that can influence business decisions.
Scalability is one of the key benefits of batch processing. Organizations may handle massive volumes of data without overwhelming their systems by breaking them into manageable chunks and processing them on a schedule. This method also allows for parallel processing, in which numerous batches can be handled simultaneously, boosting efficiency and decreasing processing time.
Another advantage of batch processing is its low cost. As a result, organizations can use their resources more efficiently and save costs by processing data in batches.
Advantages and Disadvantages of Batch Data Processing
Batch data processing is a systematic way of dealing with huge amounts of data. This strategy offers various benefits and drawbacks for businesses when implementing data processing systems.
Advantages of Batch Data Processing
- Scalability:
Because batch data processing is extremely scalable, companies may handle enormous amounts of data without overburdening their systems. - Cost-effectiveness:
Batch data processing is less expensive than real-time processing because it allows enterprises to use their resources better. - Reduced Errors:
Batch data processing allows data to be examined and validated before processing, eliminating errors and ensuring data accuracy. - Effective processing:
Batch data processing enables parallel processing, in which many batches can be handled concurrently, lowering processing time and boosting efficiency.
Disadvantages of Batch Data Processing
- Delayed Processing:
Batch data processing necessitates processing data on a schedule, which might result in processing and decision-making delays. - Limited Real-time Insights:
Because data is handled on a schedule rather than in real-time, batch data processing is not suited for real-time insights. - Limited Interactivity:
Because batch data processing requires data to be processed and stored before it can be accessed, it limits data interactivity. - Inability to Handle Streaming Data:
Batch data processing is not useful in streaming data since it requires data to be collected and processed in batches.
As a result, while implementing data processing solutions, businesses should carefully assess the benefits and drawbacks, considering their individual business goals and use cases.
Use Cases of Batch Processing
Batch processing has numerous applications in various industries, including banking, healthcare, retail, and manufacturing. Following are some examples of common batch processing applications:
- Financial analysis:
In finance, batch processing executes complicated computations and analyses on enormous amounts of financial data. It lets financial firms recognize patterns and trends, forecast future events, and improve risk management. - Healthcare data management:
Healthcare organizations use batch processing to manage patient data, such as medical records and test results. It enables reliable data analysis, identifying trends in patient data, and improving medical diagnosis and treatments. - Retail inventory management:
Batch processing manages inventory and sales data in the retail industry. It allows retailers to assess sales trends, develop pricing tactics, and manage inventory. - Manufacturing quality control:
In manufacturing, batch processing is utilized to examine data on product quality and find problems. Manufacturers can use it to improve product quality, cut waste, and streamline production processes. - Fraud detection:
Batch processing detects fraudulent actions in the banking and insurance industries. It allows institutions to process vast amounts of data to find abnormalities, patterns, and trends that may suggest fraud.
Finally, batch processing has a wide range of applications in various industries. It lets enterprises handle huge volumes of data efficiently and effectively, allowing for accurate analysis and important insights that drive business choices.
Batch Processing vs Stream Processing
Big data analytics has two approaches for handling data: batch processing and stream processing. Here are the main distinctions between the two:
Batch Processing is processing huge amounts of data at regular intervals. Data is collected over time and processed in batches, making it perfect for simultaneously handling massive amounts of data. In addition, batch processing is less expensive and more scalable than stream processing, making it excellent for processing huge datasets, generating reports, and performing complex analyses.
Stream Processing is processing data as it is generated in real time. This strategy is ideally suited for applications requiring instantaneous insights, such as real-time fraud detection or stock market analysis. Stream processing is more interactive and allows for faster decision-making than batch processing, but it is less scalable and takes more resources.
In conclusion, batch processing is best for huge datasets, whereas stream processing is best for real-time data analysis. Companies should select the approach that best meets their objectives based on the type of data collected, processing requirements, and insights needed from the data.
What is MapReduce?
MapReduce is a programming approach and software framework for parallelizing the processing of huge datasets over numerous servers. Google introduced it in 2004, and it has since become a popular tool for big data processing. The MapReduce paradigm consists of two major processes: the Map process, which processes data in parallel across numerous servers, and the Reduce process, which aggregates the processed data and generates the final result. MapReduce is well-known for its capacity to manage enormous amounts of data and efficiently conduct complicated computations, making it a crucial tool for big data analytics.
What is Pig in Big Data?
Introduction
Pig is a high-level Hadoop platform for analyzing huge datasets. It was created at Yahoo before becoming an Apache Software Foundation project. Pig is a data flow language that provides an abstraction layer over MapReduce to simplify development. As a result, Pig allows users to build sophisticated data processing jobs with less code, making it an effective big data analytics tool.
Pig is intended to work with semi-structured data such as CSV, JSON, and XML files. It has a set of operators for performing data processing operations such as filtering, grouping, joining, and sorting. It also allows for user-defined functions and additional libraries to increase its capability.
Pig has the advantage of abstracting away the low-level intricacies of MapReduce programming, making it easier for users to build and maintain data processing tasks. Pig is also quite scalable. Thus it can handle enormous datasets in parallel across numerous nodes. Overall, Pig is a strong big data analytics tool that simplifies programming and allows users to gain important insights from their data.
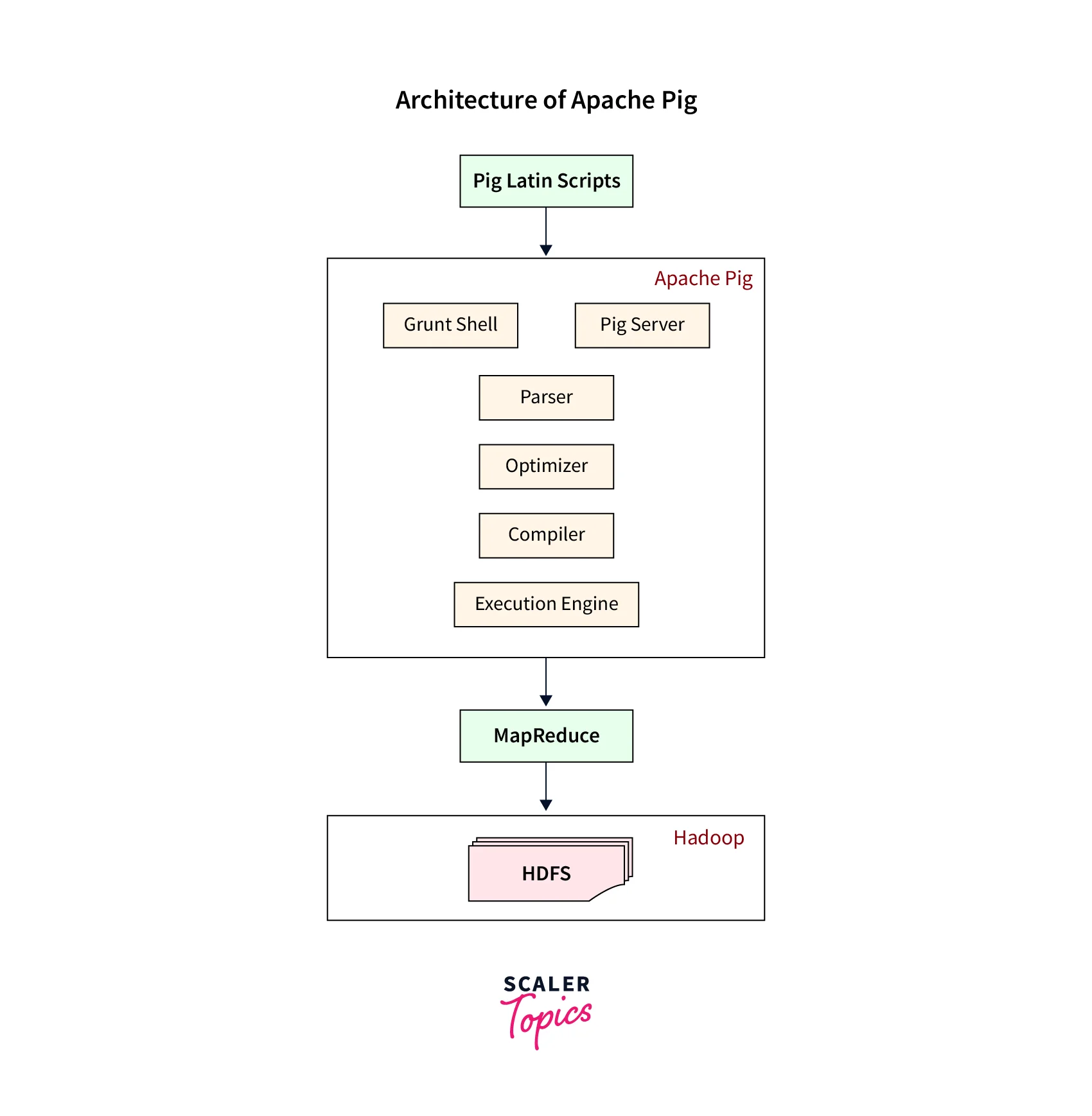
Architecture
Pig is a Hadoop framework for analyzing huge datasets developed on top of the Hadoop Distributed File System (HDFS). Pig's architecture comprises three major parts: the language interpreter, the Pig Latin language, and the execution environment.
- The language interpreter is in charge of parsing and interpreting the user's Pig Latin scripts.
- Pig Latin is a data flow language including operators for performing various data processing operations such as filtering, grouping, joining, and sorting.
- The execution environment is in charge of executing Pig Latin scripts on the Hadoop cluster. It contains a set of MapReduce tasks generated by the Pig Latin script.
Pig also comes with built-in functions and the ability to add user-defined functions to enhance its capability. Pig also interfaces with third-party libraries and technologies like Apache Hive and Apache Spark, enabling more complex data processing.
Pig's architecture is intended to ease programming and enable the efficient processing of huge datasets in a distributed setting.
Hive in Big Data
Hive is a data warehouse application that analyses huge datasets stored in Hadoop. Facebook created it, and it later became an Apache Software Foundation project. Hive provides an SQL-like interface for querying Hadoop data, making it accessible to SQL-experienced users.
Hive is intended to interact with structured data stored in Hadoop, such as CSV and TSV files. It offers a set of data definition and manipulation operations such as filtering, grouping, and joining. Hive additionally allows for using user-defined functions and incorporating external libraries to increase its capability.
Hive has the advantage of abstracting away the intricacies of MapReduce programming, making it easier for users to design and maintain data processing jobs. Hive is also very scalable. Thus it can handle enormous datasets in parallel across numerous nodes.
Overall, Hive is a strong big data analytics platform that simplifies programming and lets users gain important insights from their data.
Spark in Big Data
Apache Spark is an open-source data processing engine that is quick and efficient for big data analytics. The Apache Software Foundation created it, intended to analyze massive volumes of data in parallel across a distributed cluster of machines.
Spark has Scala, Java, and Python APIs, making it accessible to developers of diverse skill levels. In addition, it supports batch and streaming data processing and has a collection of built-in operators for standard data processing operations like filtering, grouping, and aggregating.
Spark also incorporates machine learning, graph processing, and streaming data processing libraries, making it a powerful big data analytics tool. Here are the names of the tools for the three capabilities in Apache Spark:
- Machine Learning: MLlib (Machine Learning Library)
- Graph Processing: GraphX
- Streaming Data Processing: Spark Streaming
One of Spark's primary advantages is its ability to cache data in memory, which allows it to run faster than standard Hadoop MapReduce tasks. Spark also interacts with Hadoop and other big data platforms, making it simple for users to incorporate Spark into their existing data processing workflows.
Overall, Spark is a powerful big data analytics technology that allows users to quickly and efficiently process and analyze enormous amounts of data.
Conclusion
- Batch data processing is a critical approach in big data analytics for efficiently processing and analyzing massive amounts of data.
- Batch processing is the technique of processing data in fixed-sized batches, which allows enormous datasets to be handled in parallel across several nodes.
- Batch data processing has several advantages, including the ability to process huge datasets efficiently, scalability, and handling complicated data processing workflows.
- Batch processing is also extremely reliable and fault-tolerant, making it ideal for mission-critical workloads.
- Batch processing has significant drawbacks, including the inability to handle real-time data and the potential for severe latency when processing huge datasets.
- Apache Hadoop, Apache Spark, Pig, and Hive provide significant batch processing capabilities that enable enterprises to process and analyze huge amounts of data efficiently.