Big Data Orchestration Using Apache Airflow
Overview
Apache Airflow is an open-source platform for programmatically creating, scheduling, and monitoring processes. Data engineers can use it to create and orchestrate complicated data pipelines for large data processing. In addition, users may manage task dependencies, monitor progress, and automate error handling with Airflow. Airflow provides an easy-to-use interface for creating, visualizing, and editing workflows. It can be integrated with various big data technologies such as Apache Hadoop, Spark, and Hive. It allows users to organize and execute jobs and workflows effortlessly depending on variables like time, data availability, and external triggers.
Introduction
Before learning about our topic i.e. "Big data orchestration using Apache Airflow", let us understand big data processing and its needs. Big data processing involves complex workflows and multiple stages, such as data ingestion, processing, and analysis. Managing these workflows and dependencies can become a cumbersome task. This is where big data orchestration comes into play. Apache Airflow is an open-source platform that helps manage and orchestrate complex workflows in big data processing pipelines.

Airflow lets users define, schedule, and monitor workflows programmatically and efficiently. Workflows are defined using Python code, which makes it easy to modify, maintain and test them. In addition, Airflow provides a rich set of pre-built operators to interact with various data sources and sinks, including databases, cloud services, and file systems.
Airflow's user-friendly web interface allows users to monitor the status of running workflows, set up alerts, and retry failed tasks. With Airflow, users can also easily visualize dependencies among tasks, allowing for greater clarity and control over their data pipelines. Additionally, Airflow integrates well with popular big data technologies such as Apache Hadoop, Apache Spark, and Apache Kafka.
What is Big Data Orchestration?
Let us now learn about Big data orchestration before learning about: "Big data orchestration using Apache Airflow".
Big data orchestration automates, schedules, and monitors the data operations required for big data processing. It is an important part of big data management since it helps to streamline the data acquisition, processing, and distribution processes.
Big data orchestration is required because big data processing is complex and time-consuming. It necessitates integrating and orchestrating various tools and technologies for data to be processed efficiently and on time. Big data orchestration aids in the management and scheduling of these tools and technologies, ensuring that data processing operations run smoothly.
The data processing pipelines of e-commerce enterprises are a common example of big data orchestration. Data ingestion from multiple sources, including weblogs, transactional databases, and social media platforms, is the first step in the data pipelines. After that, the data is processed using various technologies such as Apache Spark, Apache Hadoop, and Apache Flink. Ultimately, the processed data is placed into a data warehouse for further analysis and reporting, such as Amazon Redshift, Google BigQuery, or Snowflake.
Big data orchestration solutions like Apache Airflow can be used in such circumstances to automate and schedule various data processing activities. Airflow's web-based user interface allows users to drag and drop workflows to create, manage, and monitor them. It also includes features like task dependencies, data lineage monitoring, and warnings to ensure data processing processes run smoothly and without problems.
What is Apache Airflow?
Let us now learn about Apache Airflow before learning about: "Big data orchestration using Apache Airflow".
Apache Airflow is an open-source platform for programmatically creating, scheduling, and monitoring processes. Airbnb created it in 2015, and the Apache Software Foundation maintains it. Airflow is flexible, scalable, and expandable, making it an ideal solution for handling complicated data pipelines.
Airflow defines workflows using Directed Acyclic Graphs (DAGs). A DAG is a set of tasks completed in the order in which they are dependent. Each job is an instance of an operator that specifies the action to be taken.
Airflow has a robust set of operators for various activities, including BashOperator for executing a shell command, PythonOperator for executing a Python function, and many more. These operators can create complicated workflows capable of performing a wide range of data-related operations such as data extraction, transformation, and loading.
One of Apache Airflow's primary features is its web-based UI, which visually represents DAGs, jobs, and their dependencies. The UI also allows users to track task progress, see logs, and manually retry or trigger activities.
Apache Airflow is highly adaptable and can add more operators, sensors, hooks, and other components. It also connects with third-party systems like databases, cloud platforms, and message queues, making it a versatile data pipeline management solution.
Installing Apache Airflow
To learn about Big data orchestration using Apache Airflow, the installation of Apache Airflow is the primary step. Let's learn about it first.
Installing Apache Airflow is a simple process that involves installing the required components and configuring the system. You should check that your system fulfills the Apache Airflow requirements before installing. These prerequisites usually include Python 3.x and other dependencies, such as the airflow module, which may be installed through pip.
Following the system's installation, the following step is downloading and installing Apache Airflow. This can be accomplished through pip or by obtaining the source code from the official website. Following the download, the installation configures the configuration files and runs the appropriate programs to initialize the system.
It is vital to note that Apache Airflow requires a backend database to store workflow metadata and state. This database, which might be PostgreSQL, MySQL, or SQLite, should be set up before executing Airflow.
Here are the steps to install Apache Airflow on a Linux machine using pip:
1. Install Airflow using pip:
2. Install Airflow using pip:
3. Install Airflow using pip:
4. Start the Airflow webserver and scheduler:
Note:
It is recommended to install Airflow in a virtual environment to avoid conflicts with other packages installed on your system.
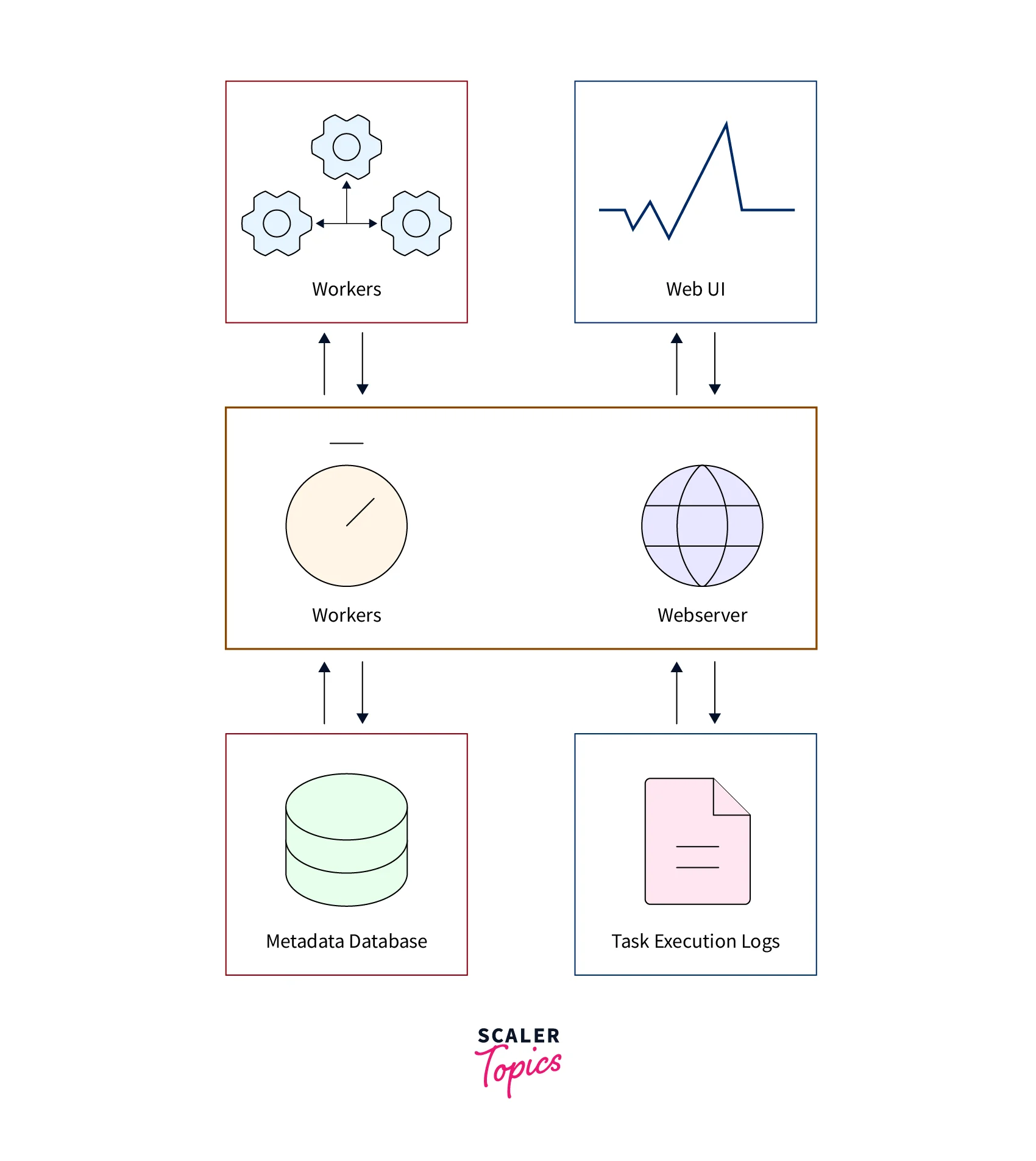
Architecture
Here is a rough diagram of the architecture of Apache Airflow:
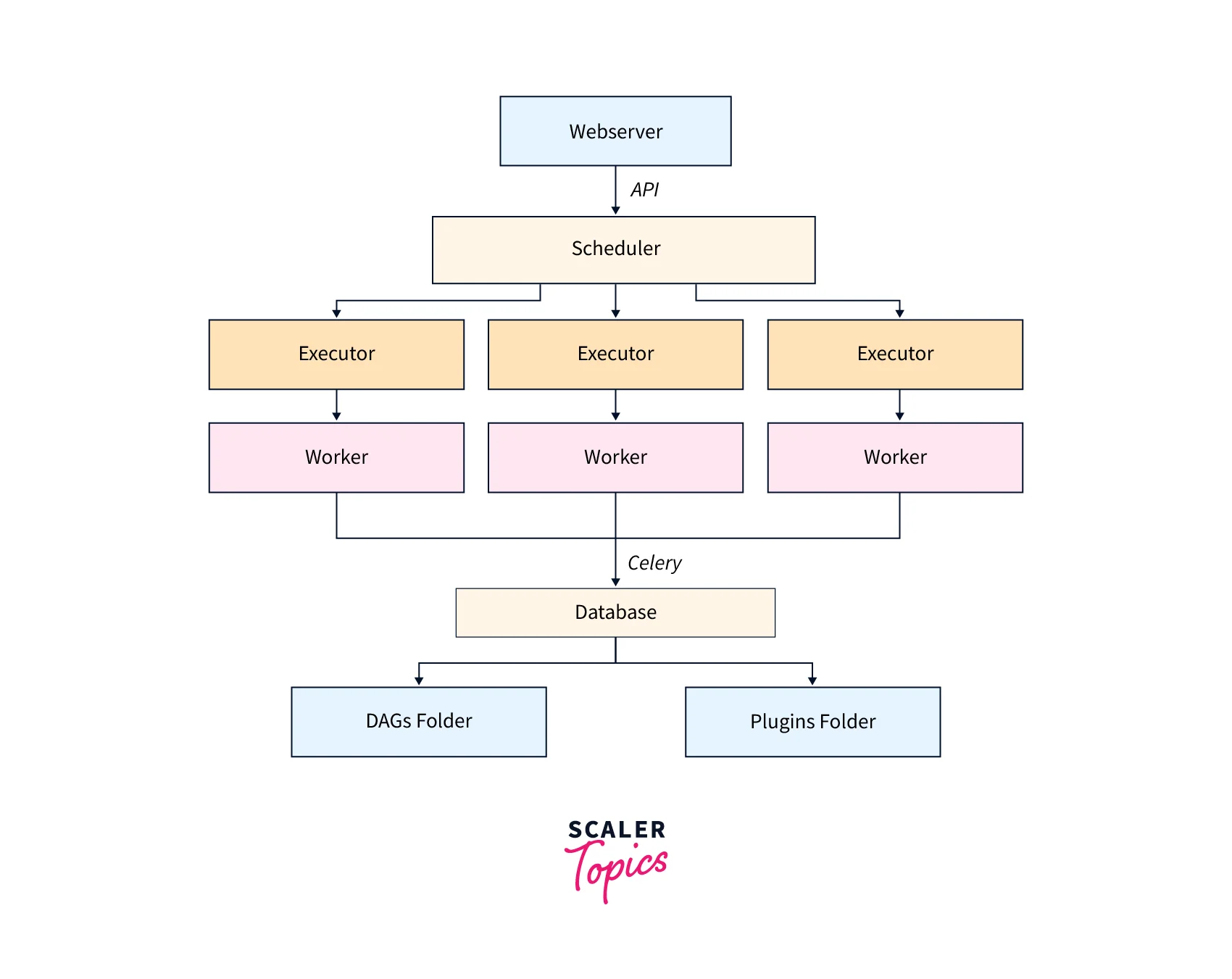 The architecture of Apache Airflow consists of five key components:
The architecture of Apache Airflow consists of five key components:
DAG and DAG Directory
The Directed Acyclic Graph (DAG) is at the heart of Airflow. The DAG is the architecture's core component. It specifies the tasks, their dependencies, and the order in which they must be completed. The DAG is represented as a Python script that includes the workflow code. A DAG's tasks are either Python functions or instances of operator classes. The tasks are grouped into a directed acyclic graph (DAG), with each node representing a task and each edge representing a task dependence.
The DAG directory is a folder that contains all of the DAG scripts. This directory is watched by Airflow's scheduler, which inspects the DAG directory regularly to identify any new or updated DAGs. After the DAGs are identified, the scheduler starts the workflows defined in the DAGs. In addition, the scheduler monitors workflow execution and updates the status of each job in the Airflow metadata database.
The DAG architecture is intended to be adaptable and extendable. It enables users to define workflows and dependencies in a modular and reusable manner. It also has a straightforward API for creating new operators, sensors, and other components.
Scheduler
The scheduler is one of the most crucial components of Apache Airflow, as it supervises workflow execution. It is responsible for scheduling workflows, monitoring their status, and initiating their execution. The scheduler operates in the background continually, looking for new tasks to execute and updating the metadata database with task progress.
To handle the execution of various sorts of jobs, the scheduler employs a plugin architecture. As a result, it can handle a wide range of tasks, including Python scripts, SQL queries, and shell commands. When an Apache Airflow workflow is submitted, the scheduler parses the DAG (Directed Acyclic Graph) definition and generates a list of jobs to be completed. Each task is given a task instance, which keeps track of its state, start time, finish time, and other information.
The scheduler maintains task dependencies and guarantees that they are completed in the correct order. It also manages task retries, failures, and timeouts. Finally, the scheduler uses the executor to launch task instances on worker nodes.
Workers
Workers in Apache Airflow are critical in carrying out the duties assigned by the scheduler.
Workers in Apache Airflow are the instances in charge of carrying out workflow tasks. They take tasks from the queue and execute them on the worker nodes that have been assigned to them. The workers use Celery, a distributed task queue, to handle task execution. Celery supports several brokers, including RabbitMQ, Redis, and Amazon SQS. The broker manages task queues and communicates between workers and the scheduler.
Apache Airflow workers run parallel to provide scalability and handle several tasks simultaneously. The number of workers can be scaled up or down based on the workload. Workers are horizontally scalable, which means they can be added or deleted based on the amount of processing power required for the workflow. Each worker can tackle numerous jobs simultaneously, increasing the workflow's efficiency.
Workers are fault-tolerant, which means they can handle the failure of a single node or numerous nodes in a cluster. When a worker node fails, the tasks allocated to that node are automatically redistributed to another available worker. This guarantees that the workflow continues uninterrupted and completes the assigned tasks.
Web Servers
The Apache Airflow architecture's front-end component is web servers. They allow users to engage with workflows, task progress, and logs. The Flask web framework is used to build the web server component, which supports basic and token-based authentication. The web server talks with the database to save and retrieve workflow metadata.
The web server also provides a REST API enabling programmatic access to Airflow features. This API can initiate processes, track task progress, and get logs.
The web server component can be horizontally scaled to manage the increasing load by installing many instances behind a load balancer. Each instance talks with the same database and can handle user requests independently under this configuration.
Apache Airflow is a powerful graphical user interface for developing, monitoring and managing complicated workflows. The web server component is essential in this process because it provides a user-friendly interface and API for engaging with workflows. Organizations can easily manage complicated workflows and optimize big data processing pipelines by leveraging Apache Airflow's scalability and flexibility.
Metadata Database
The metadata database is an important part of the Airflow design. It keeps track of all the workflows, tasks, and dependencies. Airflow employs a relational database as the metadata store, which can be any database supported by SQLAlchemy. The metadata database records the state of tasks, task dependencies, and workflow execution history.
Airflow's metadata database can store various metadata, such as task instances, DAGs (Directed Acyclic Graphs), variables, and connections. Task instances represent specific tasks in a workflow, whereas DAGs represent the workflow as a whole. Variables and connections are used to store shared data and credentials that may be used by tasks, respectively.
Airflow also supports DAG versioning, which enables improved collaboration and tracking of workflow changes over time. For example, the metadata database may hold several versions of a DAG, and the Airflow web UI makes it simple to see their differences.
Fundamentals of Airflow
This section will cover the essentials of Airflow, including DAGs, functions, operators, and execution order, along with example snippets.
Step - 1: Create DAG
We first need to import the DAG class from the airflow module to create a DAG. Here's an example:
Taking note of the example above, we've created a DAG object named my_dag. We've also set a description for the DAG, a daily schedule interval, a start date, and a catchup to False.
Step - 2: Create Functions
Next, we need to define the functions that will be executed as part of the workflow. A function represents a single unit of work in the workflow. For example, a function might download data from a database or process a large dataset.
Here's an example of a function that prints Hello World:
Step - 3: Create Operators and Attach them to Function
Operators are the building blocks of a DAG. They represent the individual tasks that need to be executed. Many types of operators are available in Airflow, including BashOperator, PythonOperator, and more.
Here's an example of a BashOperator that executes a shell command:
In the example above, we've created a BashOperator named task1. The task will execute the shell command echo "Hello World".
Step - 4: Create Execution Order of Operators
Finally, we need to define the execution order of the operators. This is done by setting the dependencies between the tasks.
In the example above, we've set the execution order of the operators. task1 is executed first, followed by task2 and task3 in parallel. Finally, task4 is executed after both task2 and task3 have been completed.
Different Ways to Define Task and DAG
There are several ways to define tasks and DAGs in Apache Airflow, including classical, context manager, and decorators.
Classical
This is the most common approach to define tasks in Airflow. Tasks are defined as Python classes, each with a run method that executes the task logically. The task parameters, such as the task ID, dependencies, and task description, are set using class-level attributes. Here's an example of a simple work specified traditionally:
Context Manager
This is a more contemporary approach to task definition in Airflow. A context manager is used to describe tasks, making the code more concise and legible. Here's a small job defined utilizing the context manager method:
Decorators
This is the shortest way to define jobs in Airflow. Python decorators are used to specifying tasks, making the code more understandable and concise. Here's an example of a straightforward task defined with the decorator method:
In the example above, we define a DAG using the @dag decorator and then define a task using the @task decorator. Finally, the my_task() function is executed when the task is run, and its output is passed to the downstream tasks.
Airflow Module Structure
Apache Airflow is organized into modules that provide various components for creating, scheduling, and managing workflows. Overall, the module structure of Apache Airflow provides a modular and extensible framework for creating, scheduling, and managing workflows. Each module provides specific functionality that can be customized or extended by the user, allowing for greater flexibility and scalability.
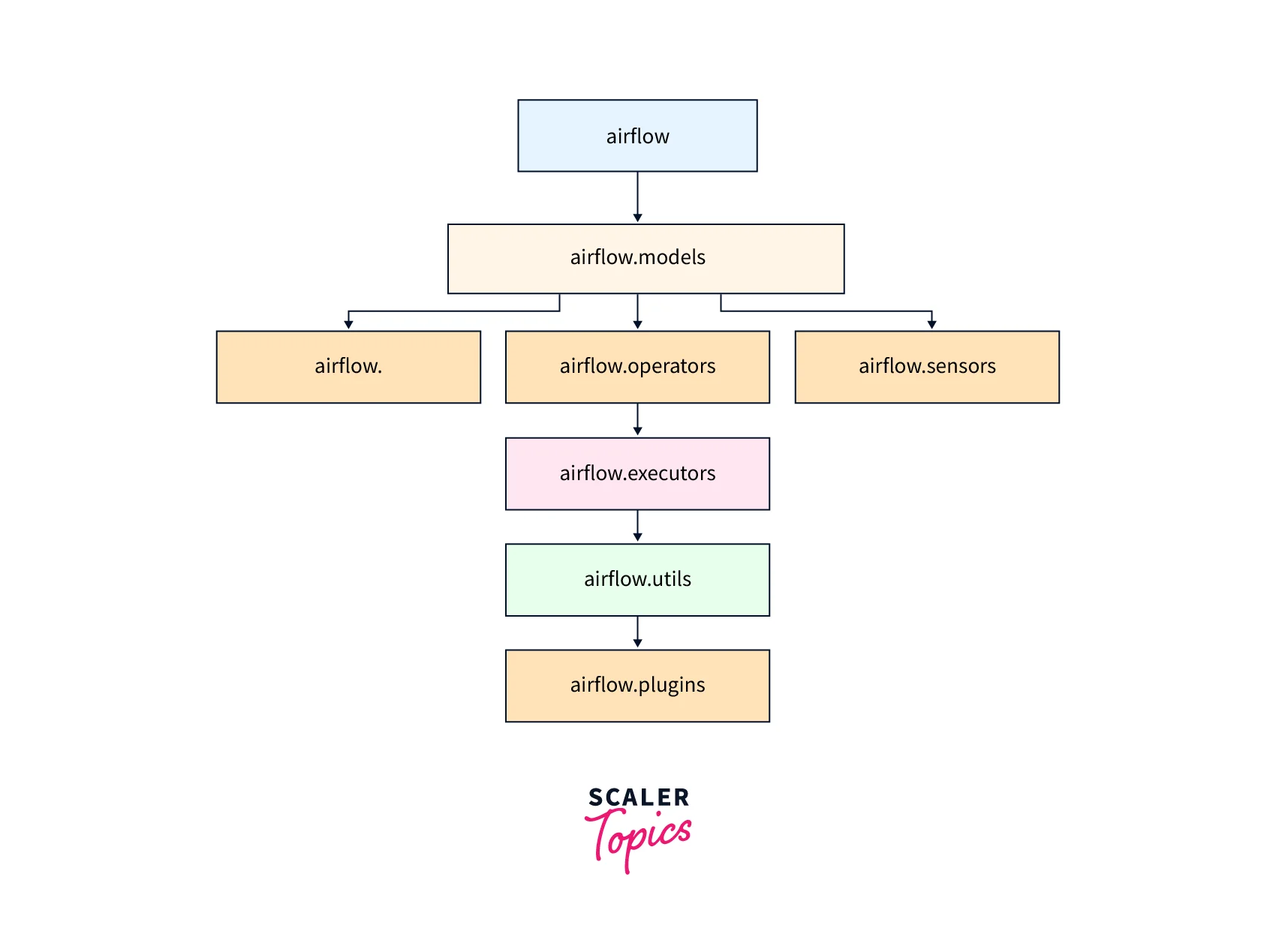
Airflow is divided into several modules, each with its specific role.
Airflow.executors
The executor's module is in charge of carrying out tasks in Airflow. It defines the fundamental Executor class and includes numerous task execution implementations, such as the LocalExecutor, which runs tasks on the local computer, and the CeleryExecutor, which executes tasks across a cluster using the Celery distributed task queue.
Airflow.operators
The operator's module comprises the elements that make up Airflow tasks. Each operator in a workflow represents a single task, such as a PythonOperator for running Python code or a BashOperator for performing shell commands. Airflow includes a wide variety of built-in operators and the ability to develop custom operators as needed.
Airflow.models
The model's module defines Airflow's data model for storing metadata about workflows and tasks. This information contains task dependencies, task status, and task execution history. In addition, the model's module has a programmatic interface for dealing with Airflow's metadata database.
Airflow.sensors
The sensors module allows you to pause a workflow until a specific condition is met. For instance, the HttpSensor can wait for a web server to respond before proceeding with a workflow. Likewise, the FileSensor can wait until a fire occurs in a directory before proceeding with a workflow.
Airflow.hooks
The hooks module allows Airflow to communicate with external systems and services. Operators utilize hooks to accomplish activities such as sending email notifications and running SQL queries. Airflow has various built-in hooks for popular services like AWS and Google Cloud, and custom hooks can be added as needed.
Here's an example of how to utilize the Airflow operators module:
In this example, we define a DAG with a single task, a PythonOperator. The PythonOperator runs the my_python_function function when executed. The DAG is scheduled to run once, on April 17, 2023.
airflow.utils:
This module contains utility functions and classes used by other Airflow modules, such as timezone conversion and logging configuration.
airflow.plugins:
This module contains the custom plugins that extend Airflow functionality, such as adding new operators or sensors.
Types of Operators
Airflow offers a choice of operators to conduct activities categorized into various sorts.
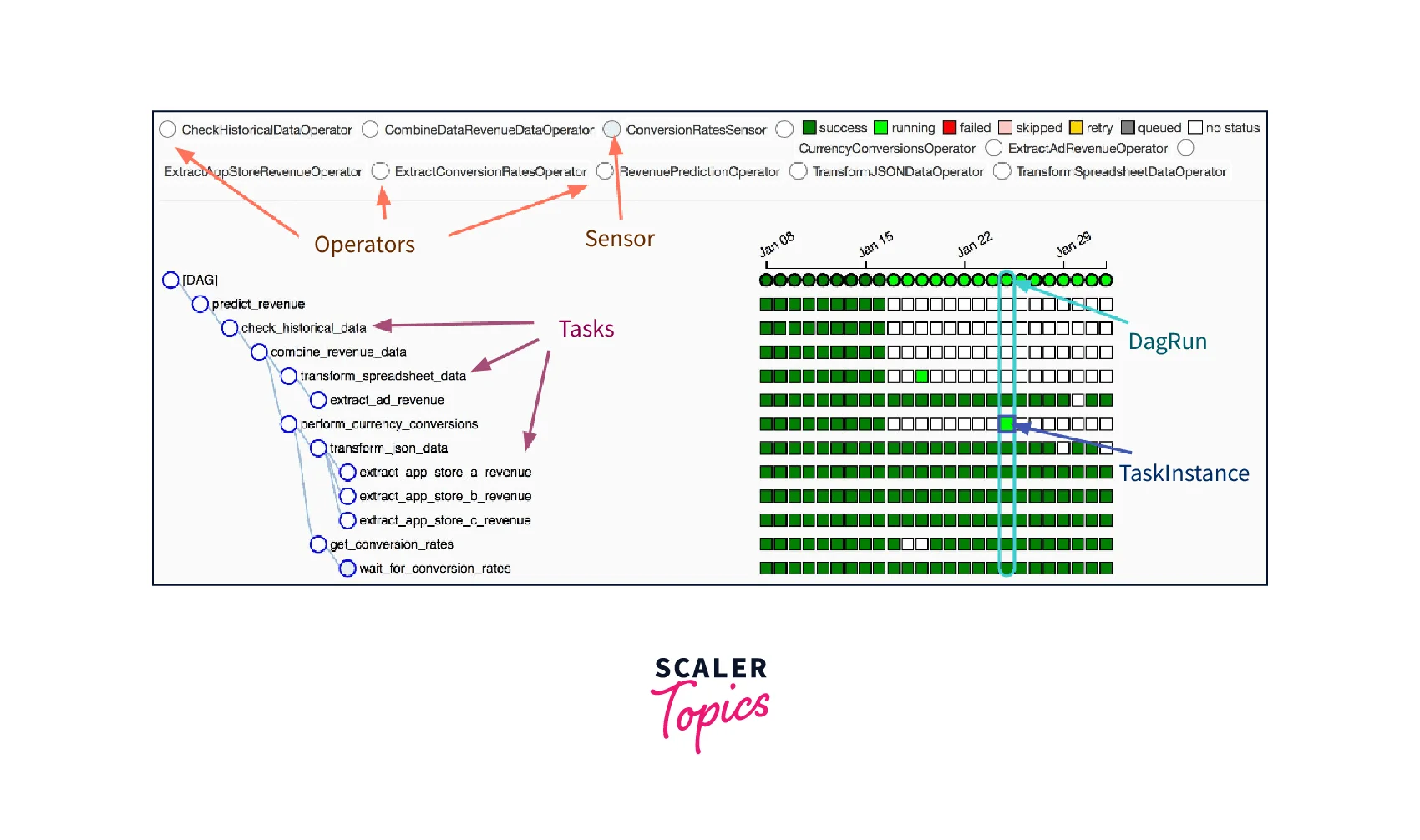
Let's take a closer look at each type of operator:
a. Operators
Operators are the DAG-building components that define the tasks to be executed. Airflow has a variety of operators, including BashOperator, PythonOperator, HiveOperator, MySqlOperator, and more. Each operator is responsible for a certain task, such as launching a Bash script, a Python function, or a Hive query.
b. Sensors
Sensors are operators that wait for a specified condition before proceeding with the workflow. Airflow offers a variety of sensors, including FileSensor, HttpSensor, S3KeySensor, and others. These sensors can detect the presence of a file, the availability of a web service, a key in an S3 bucket, and so on.
c. Transfers
Transfers are an operator that transfers data between systems. Transfer operators provided by Airflow include S3ToRedshiftOperator, MySqlToHiveOperator, and others. These operators aid in the secure and efficient data transfer from one system to another.
d. Schedulers
Schedulers are in charge of scheduling tasks and executing them following their dependencies. Airflow offers a variety of schedulers, including SequentialExecutor, LocalExecutor, CeleryExecutor, and others. Each scheduler has advantages and disadvantages that can be chosen dependent on the application.
e. Executors and Types
Executors are in charge of carrying out DAG-defined tasks. Airflow provides a variety of executors, including SequentialExecutor, LocalExecutor, CeleryExecutor, and others. Each executor has their method of carrying out duties and can be chosen based on the requirements.
f. Hooks
Hooks communicate with other systems like databases, APIs, etc. For example, Airflow includes hooks such as MySqlHook, HiveHook, HttpHook, and more. These hooks aid in connecting to and operating on external systems.
g. Create a Complex DAG Workflow for the Demo
Let's develop a sample DAG workflow that receives data from a MySQL database and outputs it to a csv file to show the use of operators in Apache Airflow.
In this example, we define a DAG workflow named my_dag that runs once a day at midnight. The first task, extract_data, is a MySqlOperator that retrieves data from the my_table table in the MySQL database. The second task, write_to_csv, is a PythonOperator that writes the retrieved data to a CSV file.
The t1 >> t2 notation defines the dependency between the two tasks, indicating that the second task should only run once the first task has been completed successfully.
The Apache Airflow operator concept enables developers to design complex DAG processes that automate and streamline even the most complex data processing. In addition, the flexibility to tailor operators to specific use cases opens up new avenues for data orchestration and automation.
Advantages and Disadvantages of Using Apache Airflow
In the Big Data ecosystem, Apache Airflow is a prominent tool for orchestrating and managing complicated workflows. While it has many advantages, it also has some drawbacks. In this essay, we will look at the benefits and drawbacks of adopting Apache Airflow.
Benefits:
- Scalability:
Apache Airflow can scale from simple to complicated workflows, allowing it to handle data processing pipelines and accommodate many activities. - Flexibility:
It is adaptable enough to work with any language or tool and can be tailored to any organization's needs. - Ease of use:
Airflow's user-friendly interface makes it simple for developers to design, administer, and monitor processes. - High availability:
Airflow may be installed in a cluster for high availability, ensuring that workflows continue to run even if one or more servers fail. - Extensibility:
Airflow is an open-source platform with a thriving community of developers that create plugins and integrations to increase its features.
Disadvantages:
- Steep learning curve:
Mastering Airflow takes significant time and effort due to its complicated architecture and Python understanding. - Debugging:
Debugging workflows in Airflow can be difficult because it requires debugging numerous components, including the DAG (Directed Acyclic Graph) and individual tasks. - Resource-intensive:
Running Airflow efficiently needs substantial resources, which might be difficult for small firms with minimal resources. - No built-in data processing capabilities:
Airflow is an orchestration tool with no data processing capabilities. It must be used with other data processing tools such as Apache Spark, Hadoop, etc. - Maintenance:
Airflow necessitates regular maintenance, such as software upgrades and performance adjustments, which can be costly and time-consuming.
Conclusion
- Apache Airflow is a robust workflow management tool for big data environments. It includes several tools that allow users to schedule and monitor complex data streams quickly.
- Apache Airflow is an open-source programmatic authoring, scheduling, and monitoring framework. Airbnb invented it, and many other businesses have since adopted it.
- Apache Airflow has a robust set of operators and sensors that enable users to engage with diverse data sources and systems.
- It defines and organizes workflows using a directed acyclic graph (DAG), which provides a flexible and straightforward way to manage dependencies.
- Apache Airflow has a web-based user interface for monitoring workflow progress and viewing logs and metrics. It is compatible with many workflows, including data processing, machine learning, and ETL pipelines.
- Apache Airflow is compatible with various big data technologies and platforms, including Hadoop, Spark, and Kubernetes.
- It is extremely expandable and may be tailored to meet the specific demands of various businesses.