Big Data Testing - A Perfect Guide You Need to Follow
Big Data Testing is crucial for managing large data sets. It validates the functionality of Big Data applications, covering areas such as Database, Performance, and Functional Testing. This field ensures these applications effectively process data from varied sources like social media and stock exchanges, maintaining accuracy and performance.
Need for Testing Big Data
To understand the need for testing in Big Data, let us take the example of a database. Suppose we have the database of a bank. The database designers have named the following columns:
- CI (Customer ID)
- CP (Customer's Phone number)
- CL (Customer's nearest bank Pin code)
As we know, the MapReduce function works on key-value pairs; so, suppose the bank creates a key-value pair of Customer ID (CI) and Customer's Phone number (CP). If a customer mistakenly enters the letter L in place of P, then the Customer's Phone number (CP) field will be replaced by the Customer's nearest bank Pin code (CL) field. In such cases, the customer will not be able to get the OTP on their number and will not be able to use banking facilities.
So, to overcome such minor faults that may cause a major issue in the working of any application, we perform Big data testing.
What Exactly is Big Data Testing
Formally, we can define big data testing as the procedure involving the validation and examination of the functionalities of big data applications.
We can process data with the help of traditional methodologies like Relational Database Management Systems and Non-relational Database Management Systems. But these systems tend to fail or process slowly if we have tons of data. So, we use special tools and technologies to work with Big Data. Similarly, we use some specialized tools, frameworks, and technologies to test out large sets of data.
We will discuss the specialized tools and frameworks involved in big data testing later in this article.
Strategies Behind Testing Big Data
The quality assurance team handles big data testing. Since big data involves gigabytes and terabytes of data, the testers must have out-of-the-box thinking abilities and skill sets. The testing performed by the `Quality Assurance team is done around three scenarios, i.e., Batch Data Processing Test, Real-Time Data Processing Test, and Interactive Data Processing Test. Let us discuss them in detail one by one.
Batch Data Processing Test
The test procedures we run on the data when the application runs in batch processing mode are known as Batch Data Processing tests. An example of such testing can be an application that processes its data using the Batch Processing storage units such as HDFS (Hadoop Distributed File System).
Batch Processing Testing involves tests like:
- Testing the varying volume of data sets.
- Running and Testing the batch processing application against the faulty inputs.
Real-Time Data Processing Test
The data gets generated in real-time in various applications like social media. Now to test the data generated when the application is running, we use the Real-Time Data Processing Test mode.
Apache Spark is one of the tools used for real-time data processing applications. The prime goal of such a testing method is to test the application's stability.
Interactive Data Processing Test
In several applications, there is regular interaction with the users. So, to test out such applications and user interaction with those applications, we use the Interactive Data Processing Test mode. HiveQL is one of the most famous examples of an interactive processing tool using the Interactive Data Processing Test mode.
An example of an application that uses interactive testing in big data is a fraud detection system for a financial institution. The system analyzes large amounts of transactional data in real-time to detect fraudulent activity and prevent financial losses.
Big Data Forms
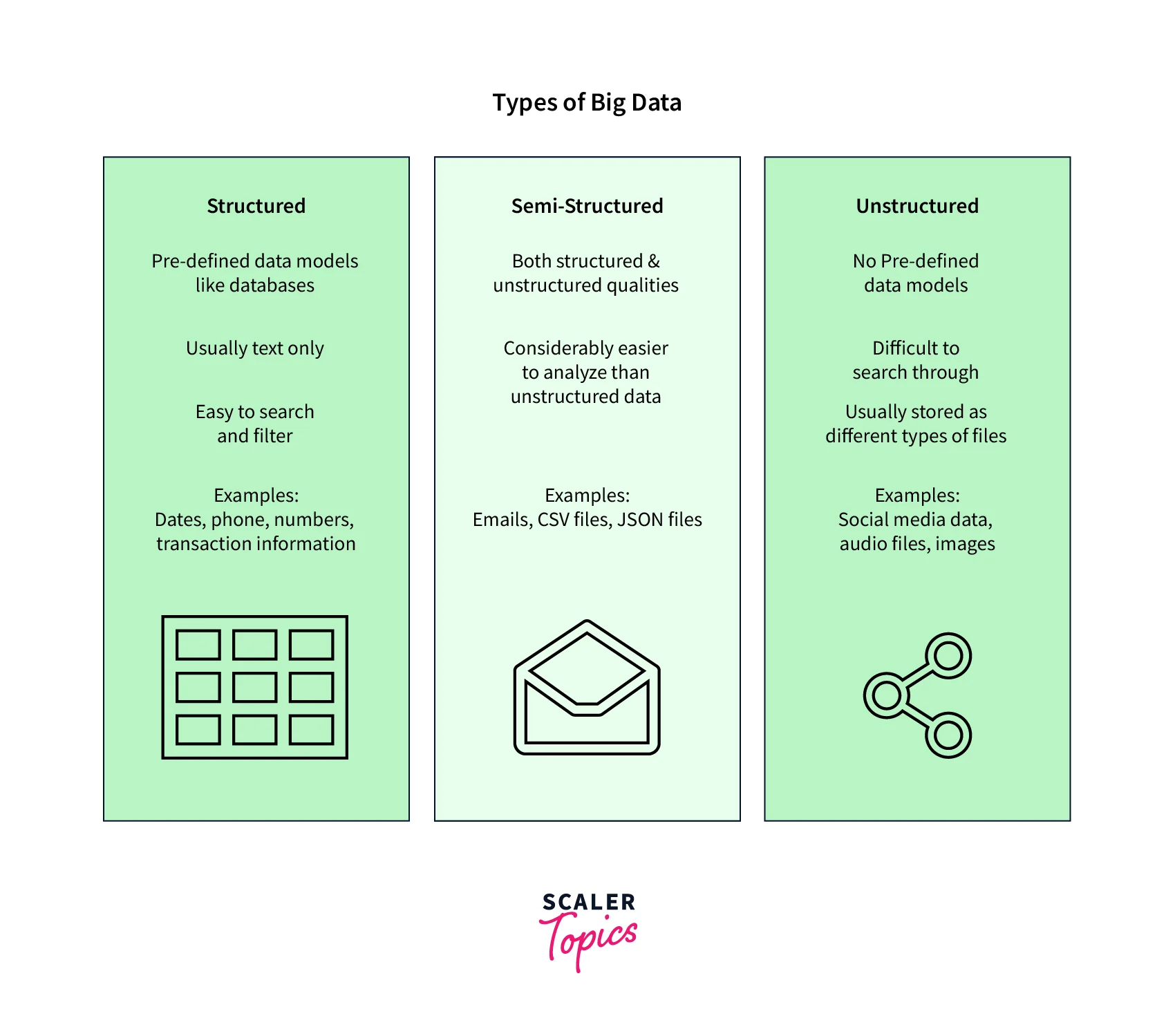
Big data is an ever-growing large set of data. We can divide big data into three categories:
Structured Data
The data that is stored in the form of tables (i.e., in the form of rows and columns) is known as structured data. Example: the data stored in Relational Database Management Systems.
Unstructured Data
Unstructured data refers to any type of data that doesn't follow a predefined data model or structure. This can include data like images, videos, social media posts, and more. Unlike structured data, unstructured data can be more difficult to analyze and make sense of, as it doesn't fit neatly into predefined categories.
Semi-Structured Data
Semi-structured data is a type of data that falls somewhere between structured and unstructured data. While it doesn't adhere to a rigid structure like traditional relational databases, it does have some level of organization and can be easily parsed and analyzed using certain techniques. Examples of semi-structured data include XML and JSON files, which are commonly used in web development and data exchange between applications. The ability to work with semi-structured data is becoming increasingly important in the age of big data, as many modern applications and services rely on this type of data.
Please refer to the chart provided below for more clarity.
Big Data Testing Environment
Testing requires a specific environment so that all the tests can be facilitated without even hampering the application. Let us take an example to understand the need for a testing environment. Suppose we have to perform the Interactive Data Processing Test on an application that still needs to be deployed and hence, no customer is using it currently. So, we simulate an environment where the application is tested to look like multiple users are using it (just like it will be used after its deployment).
Let us now look at the various requirements of the Big Data Testing Environment:
- The Hadoop cluster (or any other big data handler) and associated nodes must be responsive.
- Resources used for data processing, such as CPU, storage, etc., should be available.
- The space needed for storing, validating, and processing gigabytes and terabytes of data should be available.
Big Data Testing
So far, we have discussed a lot about Big Data testing. Please refer to the image below to see the various stages of Big data testing.
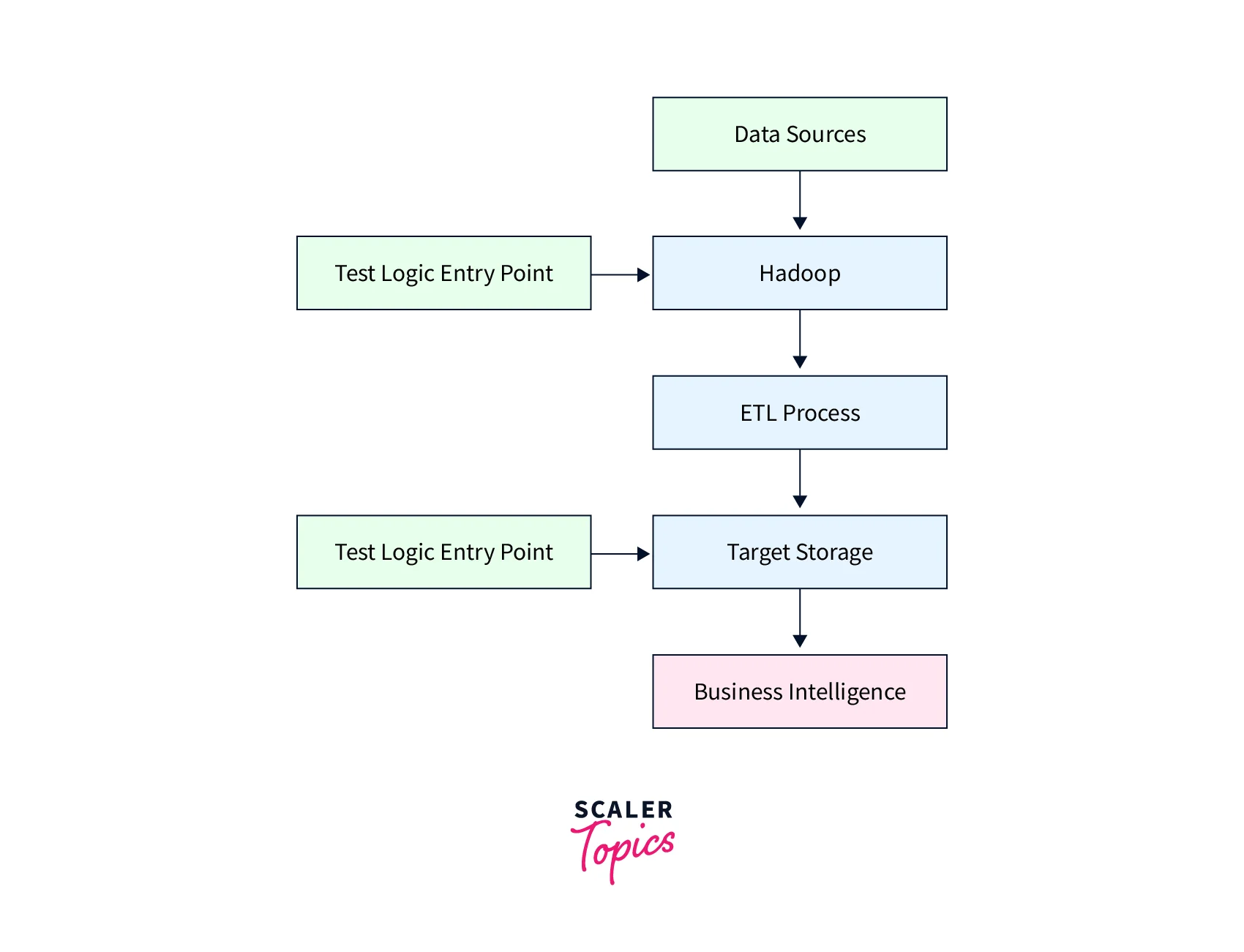
Let us now discuss the various stages involved in Big Data testing.
1. Data Ingestion
We first extract the data using the extracting tools from the source into the Big Data system. The storage of this extracted data may be done in any big data handling framework like MongoDB, HDFS, etc. After loading the source data, we filter it by checking the errors and missing values. An example of this is Talend.
2. Data Processing
In the data processing step, we generate a key-value pair out of the data by using the MapReduce technique. After generating the key-value pair, we apply the MapReduce technique on each data node and check whether the MapReduce program is working correctly or not. We also generate output from the MapReduce functions to validate whether the generated output matches the expected output. This step or process is known as data validation.
3. Validation of the Output
In the previous stage, we generated the output and compared it with the expected output, but in this stage, we migrated the generated data into the data warehouse. Apart from this, we also check the integrity of the data and the transformation logic of the data. In addition, we also verify the accuracy of the key-value pairs.
4. Categories involved in which a Big Data Application can be tested
Let us now learn the various categories involved in testing Big Data applications.
a. Unit Testing Unit testing refers to checking the smaller pieces of code. This makes the testing strategy faster. For example, in big data unit testing, we divide the large big data application into smaller segments. The testers then test these smaller segments rigorously. Finally, we perform the rigorous test to check the output or outcome with the possibilities of the expected outcome. If a segment fails, the entire codebase is sent back to the development team for improvements.
b. Functional Testing Functional testing is performed in various phases of the big data application, as we know that big data applications are meant to be used with huge data sets. These data may contain errors such as duplicate values, null values, bad data, missing values, etc. So, we perform functional testing to avoid such issues.
Depending on the type of error present in the data, we have to perform the functional testing` in big data on various phases such as:
- Data Ingestion Phase
- Data Processing Phase
- Data Storage Phase
- Data Validation Phase
- Report Generation Phase
- Data Integrity Phase
c. Non-Functional Testing The big data's velocity, volume, and variety are the three major characteristics and dimensions taken care of in the non-functional testing phase. We have five major stages involved in non-functional testing. They are:
- Data Quality Monitoring
- Infrastructure
- Data Security
- Data Performance
- Fail-over Test Mechanism
d. Performance Testing In performance testing, we test out the performance being delivered by the various components of the big data application. Performance testing can be categorized into four major types. They are:
- Data Collecting Phase
- Data Ingesting Phase
- Data Processing
- Component Peripheral testing
e. Architecture Testing The architecture testing mainly focuses on testing and establishing theApache Hadoop architecture, as we know that the performance and smoothness of the big data processing application depend upon its architecture and communication between the various components of the architecture. So, architecturetesting` plays an important role in the overall testing phase.
If we have a poorly designed architecture of the application, then it leads to problems like:
- Node Failure
- Require high maintenance
- High Data Latency
- Performance Degradation
Big Data Testing Tools
The various tools used in the Big Data testing phase are:
- Data Ingestion Process: Kafka, Sqoop, Zookeeper.
- Data Processing Process: Pig, Hive, MapReduce.
- Data Storage Process: Hadoop Distributed File System, Amazon S3.
- Data Migration Process: CloverDX, Kettle, Talend.
Challenges Faced in Testing Big Data
Let us check out the various challenges in the field of Big Data testing.
- Big Data testing isn't very easy and `requires people with great skills and mindset.
- To design the test cases, one needs to have a good scripting understanding.
- No single tool can do end-to-end testing.
- Since there is a huge amount of data to be examined, its volume is also a major challenge.
- There is a need for isolation as different application components run on different technologies.
- There is some scope for automated big data testing, but these tend to fail in many cases and require manual intervention.
- To test out critical areas and to increase performance, there is a need for a customized solution.
- Many applications use virtual machines, which tend to have some latency. So, one needs to test out the latency so that no unexpected error can occur and users can access multimedia (like images, audio, and videos) hassle-free.
Traditional Testing and Big Data Testing
Let us now see the differences between traditional testing and big data testing.
| Traditional testing | Big data testing |
|---|---|
| Traditional testing supports only structured data. | Big data testing supports all types of data (structured, unstructured, semi-structured). |
| No research and development are needed in normal or traditional testing. | There is a need for research and development as applications work on huge sets of data that can also be of varied types. |
| One with basic knowledge of operations can run tests. | It requires individuals to have qualified skill sets and problem-solving abilities. |
| The size of the data used in traditional testing is small so it can be handled quite easily. | The testing data can be quite big; hence it requires skilled people and an application-specific environment. |
| Traditional testing uses UI-based automation tools like Excel Macros. | Big data testing uses many programmed tools to work with huge datasets. |
Conclusion
- To ensure that the application's functionalities using Big Data meet the expectations, we need to use some testing techniques known as Big Data testing.
- The main aim of performing Big Data testing is to ensure the application has no errors and runs smoothly. Therefore, the prime focus of big data testing is not on testing the application's features.
- We have mainly three types of strategies in big data testing, i.e. Batch Data Processing Test mode, Real-Time Data Processing Test mode, and Interactive Data Processing Test mode.
- To design test cases, one needs to have a good scripting understanding. There are some automated big data testing tools, but these tend to fail in many cases and hence require manual interventions.
- Traditional testing supports only structured data, while big data testing supports all data types.
- Big data testing can be of five major types- Unit Testing, Functional Testing, Non-functional Testing, Performance Testing, and Architecture Testing.