Data Science Vs. Machine Learning Vs. Big Data
In today's digital era, Big Data, Data Science, and Machine Learning are not just buzzwords but pivotal technologies shaping our future. They're interconnected yet distinct, each playing a unique role in deciphering the vast ocean of constantly generated data. Big Data unlocks the potential of data, Data Science translates this potential into actionable insights, and Machine Learning leverages these insights to drive intelligent, data-driven decisions. This article delves into these exciting fields, highlighting their differences and synergies, and guides you in choosing the right path that aligns with your skills and career aspirations. Whether you're a data enthusiast or a professional, understanding the nuances of these domains is key to navigating the ever-evolving landscape of technology.
What Is Data Science?
In this section of the article, we shall dive deep into understanding the field of Data Science. When a large amount of data is gathered after the ETL (Extract, Transform, and Load) process, you can easily start your data analysis by building the analytical models with Data Science. This field is considered to be an interaction between Big Data and Cloud Computing where you start your analysis by nudging, gathering the data, building algorithms with this data, and finally analyzing and validating so that useful insights can be utilized by the organizations. Hidden patterns can be discovered while working with raw data, where Data Science helps understand the Big Data after the Extract, Transform, and Load process is done.
While a business problem can be used in a research project, various data points from different sources are analyzed to resolve the business problem and obtain practical solutions. To be a data scientist, one needs to have a good amalgamation of skills related to business, Data Analysis, Computer Science, and Statistics.
For a more in-depth understanding of the topic of What is Data Science, you can visit the article: What is Data Science
Skills Required For Data Science
Now that we learned what is Data Science, let us quickly go through the skills required for Data Science and for making a smooth transition into an interesting Data Science career.
- Fundamental knowledge and strong grip on programming languages like Python, SAS, R, or Scala.
- Versatility to quickly grasp and work smoothly with various formats of data like structured (text), unstructured (audio, video), and semi-structured (logs).
- Strong grasp of fundamentals for various analytical functions and tools.
- Practical application knowledge in the SQL domain.
- Beginner-level knowledge of topics like Artificial Intelligence and Machine Learning.
What Is Machine Learning?
With this section of the article, we shall dive deep into understanding the field of Machine Learning. When the Data Science model is prepared, it is important to train these models with appropriate datasets to train the ML models. This training enables the machine to capture the experience of the past like trends and patterns and output accurate future events based on the data that is fed to the model. Machine Learning is a sub-part of the Artificial Intelligence domain that enables machines/systems to learn from past experiences or trends and predict future events accurately.
Without any human intervention, machine learning helps to predict outputs by simply learning and improving the systems from the training` data by using various algorithms and training itself based on it. Various industries such as infrastructure, healthcare, finance, education, etc are unleashing the potential of Machine Learning. With few sets of instructions or observations, Machine Learning models can teach themselves about the data fed to them.
For a more in-depth understanding of the topic of What is Machine Learning, you can visit the article: What is Machine Learning
Skills Required For Machine Learning
Now that we learned what is Machine Learning, let us quickly go through the skills required in Machine Learning for making a smooth transition into the amazing field of Machine Learning.
- Fundamental knowledge and strong grip on programming languages like Python, Java, R, etc.
- Good grasp of Mathematical topics like Statistics and probability.
- Strong grasp of data modeling.
What Is Big Data?
With this section of the article, we shall dive into understanding the field of Big Data. Every like, comment, engagement, and various other activities that we are performing every day is generating a vast amount of data. Big data is a large, voluminous store of data that needs to be processed to extract relevant information that can work towards helping big organizations.
It is quite difficult to work with Big Data manually, but with proper tools specific to serving Big Data, this can prove to be a gold mine for various information that might contribute to the welfare of the organization that is using it. Extract, Transform, and Load, widely popular as the ETL process, can be defined as the data integration operation where data from various data sources is combined into a single and consistent data store. Then as per the user's requirement, transformations are performed on the data which is then loaded into a data warehouse. It is this refined and cleansed data that can be utilized by the analysts for their use cases. ETL is the key process by which you can process all sorts of structured, unstructured, or semi-structured data to further discover trends and patterns.
Previously organizations were dealing with only gigabytes of data with traditional tools. But as the amount of data gathered every minute is massively increasing, Big Data holds the potential to handle petabytes and exabytes of data along with storing the voluminous data using `Cloud and Big Data frameworks like Hadoop, etc.
The five Vs of Big Data can be categorized as below:
- Volume: How big the data is?
- Variety: What are various formats of data?
- Velocity: What speed is the data generated?
- Value: What value a specific dataset is providing?
- Veracity: What is the consistency, accuracy, quality, and trustworthiness of the data?
For a more in-depth understanding of the topic of What is Big Data, you can visit the article: What is Big Data
Skills Required For Big Data
Now that we learned what is Big Data, let us quickly go through the skills that are required for Big Data and for making a smooth transition into an interesting Big Data career.
- Fundamental knowledge and strong grip on programming languages and frameworks like Python, Hadoop (MapReduce), Scala, and R.
- Versatility to quickly grasp and work smoothly with various formats of data like structured (text), unstructured (audio, video), and semi-structured (logs).
- Deep understanding of databases like NoSQL, SQL, etc.
- Practical application knowledge in the SQL domain.
- Advanced level knowledge of data warehouse concepts such as Hive, HBase, and Hadoop architecture.
- Deep understanding of topics like Cloud Computing, and Apache Kafka.
Difference Between Data Science And Machine Learning
To understand the difference between the fields of Data Science and Machine Learning, we can always go to Drew Conway's Venn Diagram. Drew Conway's Venn Diagram highlights the relation between the three sections (Hacking Skill, Maths And Statistics Knowledge, and Substantive Expertise), making it easier to understand the key similarities and differences between Data Science and Machine Learning.
As both technologies can seem to be similar, with Drew Conway's Venn Diagram, we shall broaden our knowledge to understand how different the two technologies are. Organizations like Amazon, Facebook, Netflix, etc., have started unleashing the potential of these technologies to expand and grow their businesses as they understand what skills each of these technologies demands.
In Drew Conway's Venn Diagram, we have three sections (or three circles) as can be seen from the diagram below:
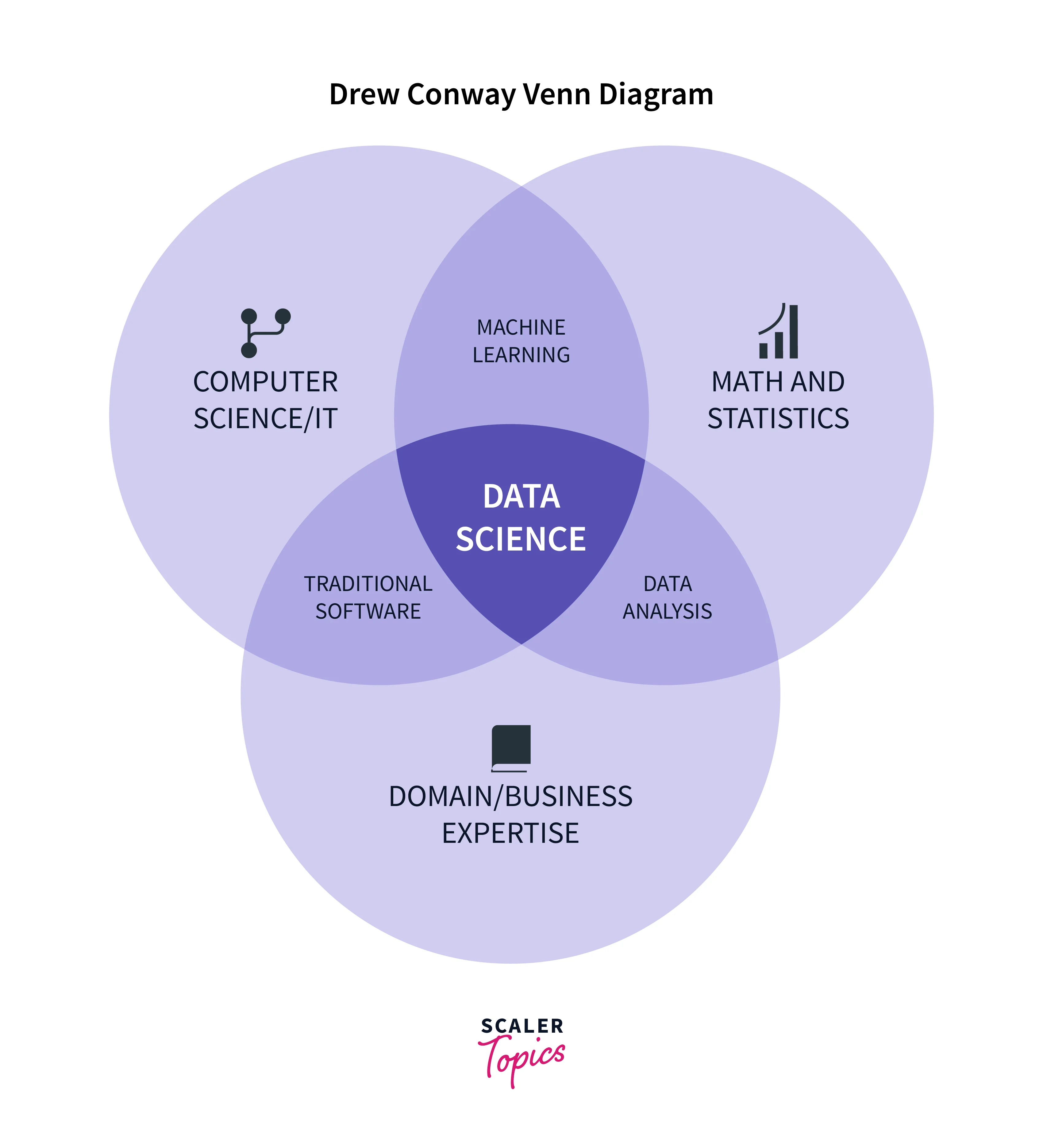
- Hacking Skill
- Maths And Statistics Knowledge
- Substantive Expertise
Let us understand each of this one by one.
Hacking Skill: Also widely popular in the field of Computer Science. It includes skills like categorizing data, learning vectorized operations, and structurally thinking in an algorithmic manner, such as how a computer would make a skilled data hacker.
Maths and Statistics Knowledge: Once the data is processed i.e., gathering, processing, and cleaning the data done, we could dive into learning about the appropriate mathematical and statistical methods. Knowledge about Ordinary Least Squares regression is very useful. A clear understanding of linear algebra, probability, and statistics will reward data scientists as it contributes to approximately 70% of the daily requirements.
Substantive Expertise: To help understand and wipe out any confusion, having substantive expertise is important. It helps in better understanding the data that is being checked - how the system generates the data, its processing and working, and how data products are produced along with the recommendations help the` data scientists in their work.
Now, the intersection which can be observed in Drew Conway's Venn Diagram showcases how traditional software, data science, data analysis, and machine learning gather their role.
Given below is a detailed differentiation between the fields of Data Science and Machine learning.
| Data Science | Machine Learning |
|---|---|
| In the data science domain, computer science holds importance as it helps to extract and gather meaningful data from various data sources like structured, unstructured, and semi-structured. | In the machine learning domain which is considered a subset of Artificial Intelligence, we contribute to making the computers capable enough so that they can predict results ( patterns, trends) depending upon how the models were trained with past data. |
| Considered as a multidisciplinary term. | Finds high utilization in the field of data science. |
| The data utilized in the Data Science domain may or may not be the evolved version of data via a mechanical or system process. | Technologies such as supervised learning, clustering, semi-supervised learning, regression, unsupervised learning, and reinforcement learning, etc are utilized. |
| Strong grasp of knowledge around various analytical functions along with basic capabilities of Machine Learning and Artificial Intelligence is required. | Advanced knowledge of Data Modelling is necessary. |
| Includes multiple data operations like cleaning, gathering, manipulation, analysis of data, etc. | Includes operations like preparing the data, training the model with the data, data analysis, data wrangling, etc. |
| Deals with data. | Utilises the data to train the models and predict outcomes. |
| Strong fundamental knowledge of programming languages such as Python, Scala, R, and SAS, along with practical hands-on knowledge of the SQL domain is needed. | It requires knowledge of programming languages like Java, Python,` and R as well as in-depth knowledge of mathematical concepts such as probability and statistics. |
Difference Between Machine Learning And Big Data
Given below is a detailed differentiation between the fields of Machine Learning and Big Data, where we have jotted down all the points from each domain and distinguished between the two to get a clear overview.
| Big Data | Machine Learning |
|---|---|
| In the field of Big Data, the work revolves around extracting, transforming, and loading the huge volume of data as datasets, which can then be used to trace patterns and take better decisions. | In the field of Machine Learning, the work revolves around utilizing more and more data as input and teaching the machines using algorithms to help predict future patterns based on past data trends. |
| Strong grasp of technologies like Apache Hadoop, Spark, and MongoDB is required to handle all sorts of data (structured, semi-structured, and unstructured). | Strong grasp of libraries like Numpy, Scikit Learn, TensorFlow, Pandas and Keras is required to train the ML models with the data. |
| The purpose of the field of big data is to extract the data from various sources, transform it as per the requirement and load a huge volume of data which can later be utilized for creating products for the organizations. | The purpose of the field of machine learning is to get the ML models trained with the data so that they can seamlessly predict and can even estimate future outcomes. |
| Big Data is about gathering a huge amount of data and optimizing it for faster data analysis. | Machine Learning is about improving the quality of forecasting, and cognitive analysis, creating strong decision-driving capability, and improving the industries where the ML models are deployed like healthcare, speech, and text recognition, etc. |
| Requires human validation as a large volume of structured, semi-structured, and unstructured data is in the picture. | Doesn't require any human validation or intervention for training the Machine Learning algorithms. |
| Applications range from data analysis and storage in a structured form for market analysis, etc. | Applications range from the personalization of products and recommendations to spam filtering, marketing, etc. |
| With Big Data analysis, users can find patterns through classifications and sequence analysis. | With Machine Learning, users can utilize the same algorithms that data analytics utilize for automatic training with the same stored datasets. |
| Works with high-dimensionality of data, which contributes to extraction of relevant features | Works with limited dimensions of data, which makes recognizing features easier. |
Difference Between Big Data And Data Science
Given below is a detailed differentiation between the fields of Big Data vs Data science, where we have jotted down all the points from each domain and distinguished between the two to get a clear overview.
| Big Data | Data Science |
|---|---|
| In the field of Big Data, the work revolves around extracting, transforming, and loading the huge volume of data as datasets which can then be used to trace patterns and take better decisions. | In the field of Data Science, work revolves around the high volume of data, creating `analytical models, and performing data analysis. |
| Strong grasp of technologies like Apache Hadoop, Spark, and MongoDB is required to handle all sorts of data (structured, semi-structured, and unstructured). | Strong grasp of programming languages like Python, Scala, R, and SAS, along with practical hands-on knowledge of SQL domain is needed. |
| The purpose of the field of Big Data is to extract data from various sources, transform it as per the requirement and load a huge volume of data which can later be utilized for creating products for organizations. | The purpose of the field of Data Science is to build data-driven products for the benefit of organizations and their consumers. |
| Subset of Data Science, as all the data mining activities to create a streamlined data pipeline is done. | Superset of Big Data, as in this field, one needs to go through scraping, processing, visualization, statistics, and many such techniques on the data. |
| Utilized for business and customer satisfaction. | Utilized for scientific or research goals. |
| Analysis of data that is most commonly stored in a structured format, like market analysis. | Various data operations like cleaning, collection, manipulation, etc are a part of Data Science. |
| Focus is more on processing large and voluminous data. | Focus is on the science and analytics behind the data. |
| Knowledge across fields such as Hadoop, data warehouses, Kafka, and Scala is needed to understand the insights from complex data sets. | Knowledge across fields such as statistics, computer science, and applied mathematics is required. |
Conclusion
-
Machine Learning is about improving the quality of prediction and forecasting, cognitive analysis, creating strong decision-driven capability, and improving the industries where the ML models are deployed for the betterment of society like healthcare, speech and text recognition, etc.
-
The purpose of the field of Big Data is to extract the data from various sources, transform it as per the requirement and load a huge volume of data which can later be utilized for creating products for organizations.
-
The Data Science domain helps to extract and gather meaningful data from various data sources like structured, unstructured, and semi-structured.
-
In Drew Conway's Venn Diagram, we have three main parts that are hacking skills, math and statistical knowledge, and substantive expertise. It helps in creating analytical models and performing data analysis.