What is Binning in Data Mining?
What is Binning in Data Mining?
Binning, also known as discretization or bucketing, is a data preprocessing technique used in data mining. It involves dividing a continuous variable into a set of smaller intervals or bins and replacing the original values with the corresponding bin labels. Binning can be applied to both numerical and categorical variables, and its primary purpose is to simplify the data and make it more manageable for analysis. For instance, Binning in data mining can be used to discretize a numerical variable, such as age, into age groups (e.g., 0-18, 19-30, 31-50, and 51+), which can be useful for analysis and modeling purposes.
Binning in data mining can be useful in various scenarios, such as reducing the noise in the data, improving the accuracy of predictive models, and making the data easier to understand and interpret. In the following sections, we'll answer questions about the different types of binning techniques and how they are used in data mining.
Statistical Data Binning
- Statistical data binning in data mining is a data preprocessing technique used in statistical analysis to group continuous values into a smaller number of bins. This technique is useful for exploring the distribution of a variable and identifying patterns or trends in the data.
- Binning can also be used to discretize the variable for further analysis or modeling purposes. It can significantly improve resource utilization and model build response time without significantly losing model quality. In addition, binning can improve model quality by strengthening the relationship between attributes.
- It can also be used in multivariate analysis by binning several features simultaneously. For example, if we have a dataset of employees and their details, we can bin their ages and salaries to simplify our analysis.
Supervised Binning
- Supervised binning in data mining is a type of intelligent binning that uses important characteristics of the data to determine bin boundaries. Unlike statistical binning, supervised binning considers the joint distribution of the input variable and the target variable. The bin boundaries are determined by a single-predictor decision tree, which considers the predictive power of each bin for the target variable.
- Supervised binning in data mining can be used for both numerical and categorical attributes, and it is especially useful for identifying nonlinear relationships between the input variable and the target variable. By using supervised binning to create new features or input variables, we can improve the performance of our predictive models.
Image Data Processing
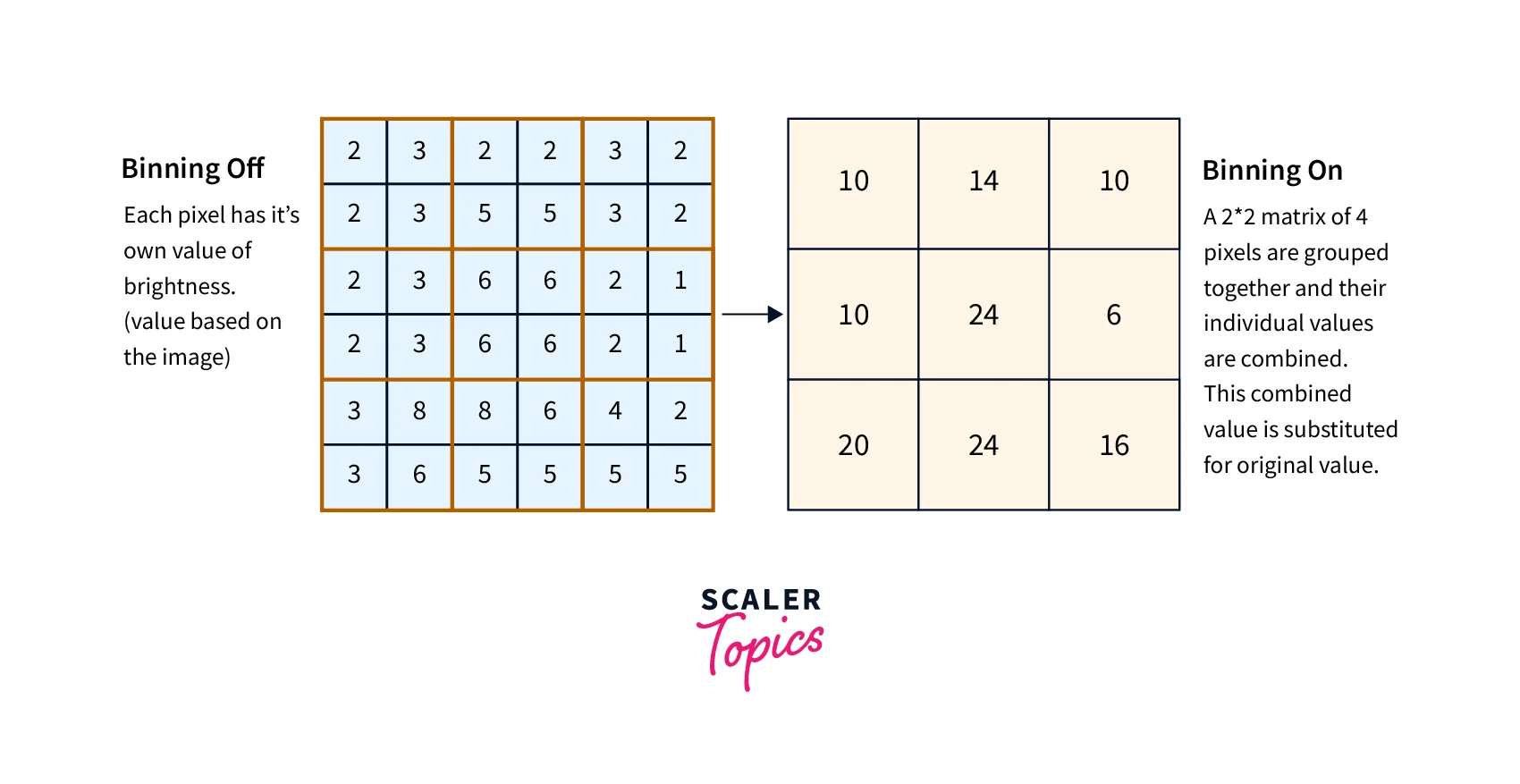
- In image data processing, binning is a technique used to reduce the size of an image by combining adjacent pixels into larger superpixels or bins. This can be useful for reducing the computational complexity of image processing algorithms and improving the image's signal-to-noise ratio.
- Binning is typically performed by dividing the image into a grid of equal-sized cells and then averaging the pixel values within each cell to obtain a new, lower-resolution image. The resulting image will have a smaller number of pixels. Still, each pixel will represent the average value of a larger area, which can help to reduce noise and improve the overall image quality.
- Let's say we have an image that is 1024 x 1024 pixels in size, and we want to reduce its size by a factor of 2. We can do this using binning by dividing the image into a grid of 512 x 512 cells, each containing 2 x 2 pixels. We can then take the average or sum of the pixel values within each cell to obtain a new, lower-resolution image that is 512 x 512 pixels in size.
What is the Purpose of Binning Data?
The purpose of binning data is to reduce the complexity of data and make it more manageable and easier to analyze. Binning in data mining can be used for both numerical and categorical data and involves grouping data into smaller, more manageable intervals or categories, or bins.
There are several reasons why binning data can be useful -
- Simplification of data - Binning reduces the complexity of data by grouping values into a smaller number of categories or intervals, which makes it easier to understand, summarize and visualize.
- Reduction of noise - In some cases, binning can help reduce noise in the data by smoothing out variations in individual data points and highlighting larger trends or patterns.
- Facilitation of data analysis - Binning can make it easier to perform statistical analysis and create visualizations, such as histograms, by reducing the number of unique values in the data.
- Improvement of model performance - Binning can also be used to create new features or input variables for predictive models. By grouping similar values, binning can strengthen the relationship between attributes and improve the performance of machine learning models.
Ready to Dive Deeper? Explore the Practical Applications of These Concepts with this Best Data Science Course and Turn Knowledge into Expertise.
Implementation of Binning Technique
There are two methods to implement binning in data mining, as shown below -
Equal Frequency Binning
This method involves dividing a continuous variable into a specified number of bins, each containing an equal number of observations. This method is useful for data with a large number of observations or when the data is skewed.
For example, our input is - , and if we want to bin this into 3 intervals, then the output will have three bins/intervals as - , , and .
Equal Width Binning
This method involves dividing a continuous variable into a specified number of bins of equal width. This method is useful for data with a normal distribution. So if there are n number of bins, then each bin will have equal width, and the range of each bin is defined as , …. where .
For example, our input is - , and if we want to bin this into 3 intervals, then our range for each bin would be, . This way, we will have ranges for 3 bins as , , and . Then the output of binning the above variable would result in - , , and .
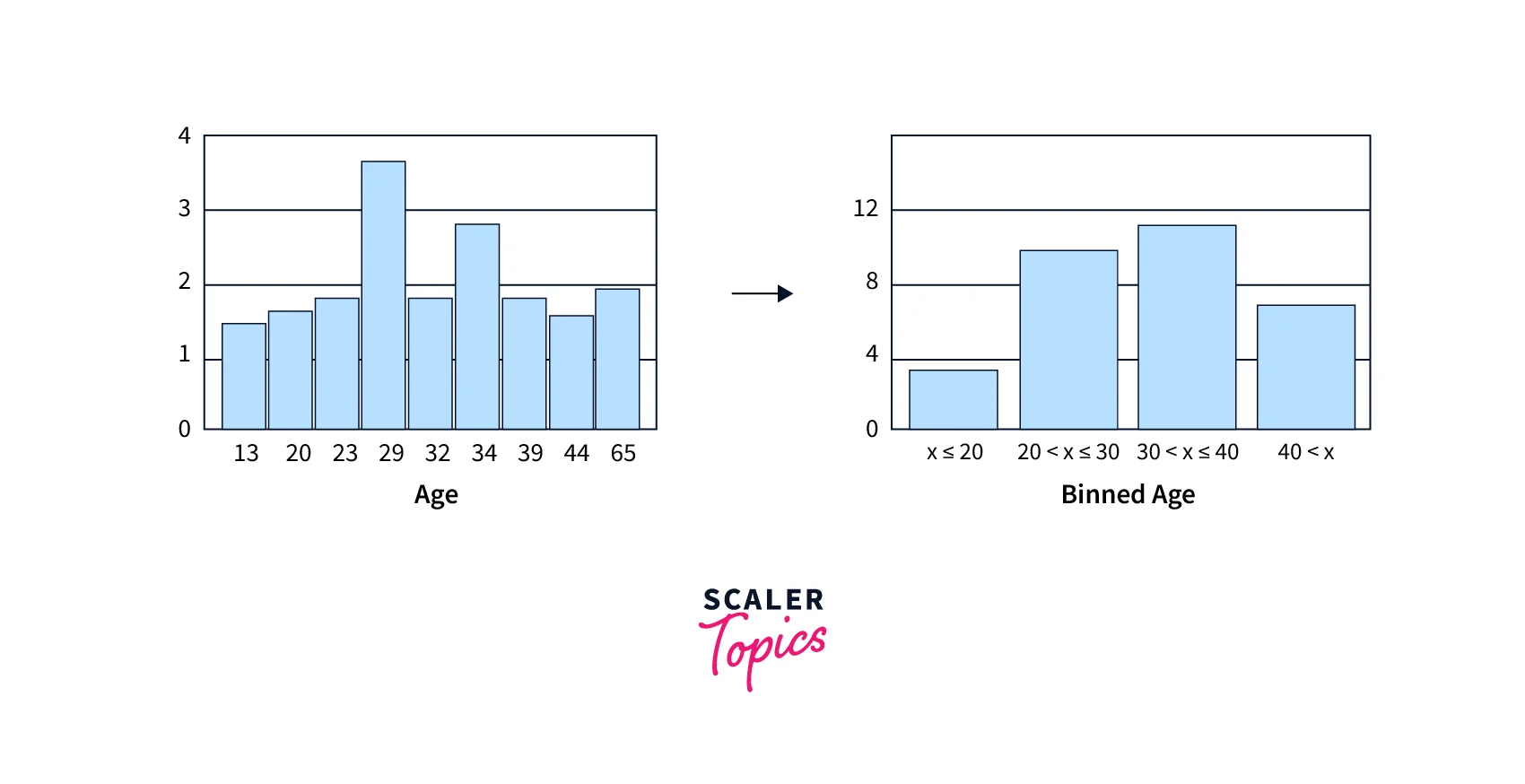
Example of Binning Continuous Data
Let’s have a look at one example of binning a continuous variable. Below is a bar chart representing the number of persons for a given age. Now if we bin the age of persons, then the data can be visualized for various age groups instead of a single age or single individuals, as shown below.
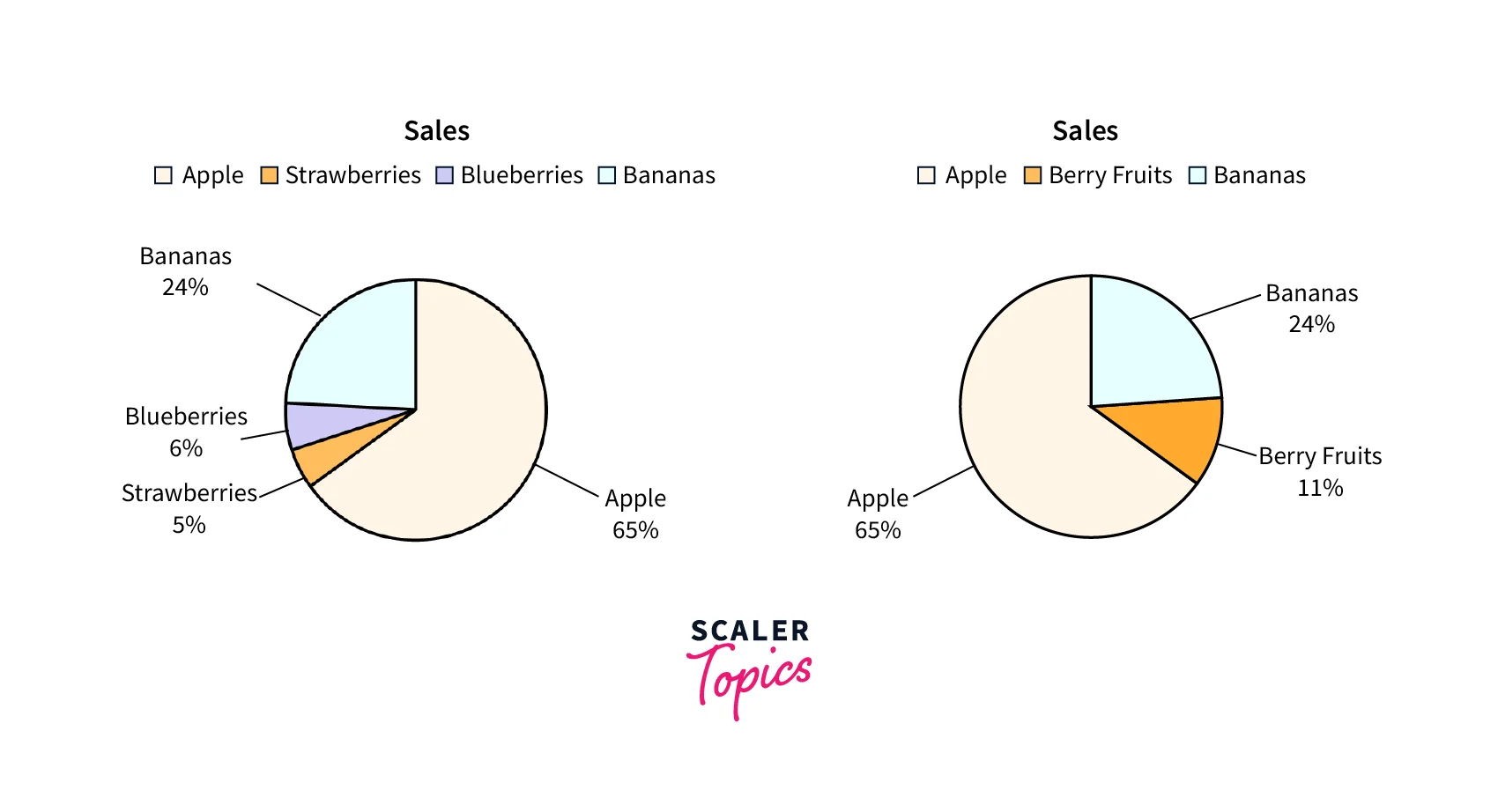
Example Of Binning Categorical Data
Let’s see an example of how categorical variables can be binned to simplify the analysis. Suppose we have a dataset showing sales distribution for each fruit, as shown below for apples, strawberries, blueberries, and bananas. We can group strawberries and blueberries into a single group - berry fruits and simplify our further analysis.
Enhance your data literacy with our free data science course. Enroll now and learn from industry experts.
Conclusion
- Binning in data mining is a data preprocessing technique that involves grouping data into smaller, more manageable categories or bins. It can be used for both numerical and categorical data and can help improve the efficiency and accuracy of data analysis.
- There are several binning methods, including equal frequency binning, equal width binning, and supervised binning. Each method has its advantages and disadvantages, and the choice of method will depend on the specific characteristics of the data being analyzed.
- Binning can be used in various applications, including data mining, image processing, and statistical analysis. By reducing the complexity of the data and focusing on broader categories, binning can help to uncover patterns and relationships that may not be immediately apparent in the raw data.