Introduction to Conditional GANs
Overview
Generating novel images from an image dataset has been a dream in Computer Vision. Being able to influence the generation of these images was made possible by a family of GANs named Conditional GANs. The following article explores these CGANs and shows how the DCGAN was modified to have the ability to control latent space traversal to a certain extent. We also look at the training paradigm and cover some challenges we might encounter while training a CGAN on our data.
Pre-requisites
Before reading this article, it is recommended to have a good understanding of the following concepts:
- Generative Adversarial Networks (GANs) and their basic architecture.
- The basics of deep learning and neural networks, including concepts such as activation functions, layers, and optimizers.
- Familiarity with Python and relevant libraries such as TensorFlow or PyTorch to implement GANs.
- Familiarity with the concept of supervised learning, as CGANs are a type of supervised GANs.
- Familiarity with the concept of image processing and manipulation
Introduction
CGANs are a variant of GANs that allow for greater control over the features of the generated images. They build upon the DCGAN architecture, a popular architecture for GANs, and have a similar architecture with some small differences. The main difference between a CGAN and a DCGAN is the ability CGAN to control which features are modified in the generated images. The difference is achieved by conditioning the Generator with additional information, such as labels, during training.
The added complexity allows the CGAN to generate images with specific features, such as a specific type of fruit with certain characteristics. Providing the Generator with more information can create a more diverse set of images while preserving the features we want. Additionally, the CGAN can better generalize to unseen data, which is an essential aspect of image generation tasks. Overall, CGAN architecture is an important step forward in GANs, as it allows for more control over the generation process and improves the quality of the generated images.
This article takes an in-depth look at CGANs.
What is a Conditional GAN?
A Conditional GAN (CGAN) is a modification of the DCGAN architecture that allows for more control over the features of the generated images. Unlike the DCGAN, a CGAN can selectively modify certain features of the generated image by conditioning the Generator with additional information, such as labels, during training. This input allows the Generator to generate images consistent with the labels' conditioning information and specific characteristics. The differences between a CGAN and a DCGAN come from changes to the training methodology. In a CGAN, the labels guide the Generator during training to traverse the latent space, the lower-dimensional space of random noise input that the Generator uses to create images. These labels give the CGAN more control over what it generates by allowing it to traverse the latent space more precisely and be guided by the labels.
An example is choosing specific features of the face to modify.

How is CGAN Different from GAN?
There are a few significant differences between a GAN and a CGAN. This article compares the CGAN to the DCGAN, as the latter is the base for many advanced GANs. These differences are summarized in the following table.
| GAN | CGAN | |
|---|---|---|
| Generative Model | Generates new samples from a random noise input. | Generates new samples from a random noise input and a class label. |
| Discriminator | Learns to distinguish between real and generated samples. | Learns to distinguish between real and generated samples and also classify the generated samples based on the class label. |
| Generator | Learns to generate samples that can fool the discriminator. | Learns to generate samples that can fool the discriminator and also generate samples from specific class labels. |
| Loss Function | Minimizes the difference between the generated and real samples. | Minimizes the difference between the generated and real samples and also the difference between the generated class label and the input class label. |
| Applications | Image generation, text generation, etc. | Image generation with class labels, text generation with specific styles, etc. |
Architecture of CGAN
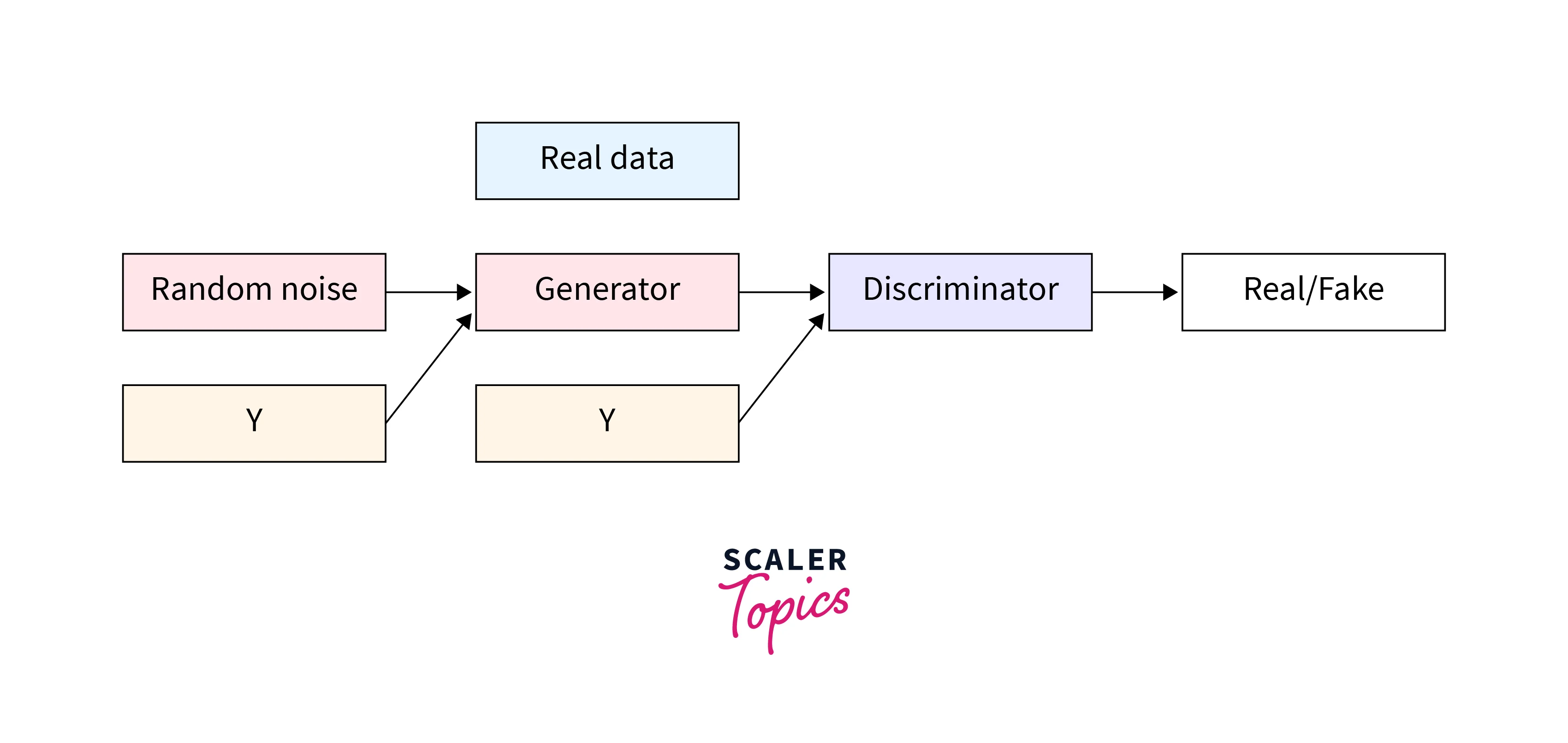
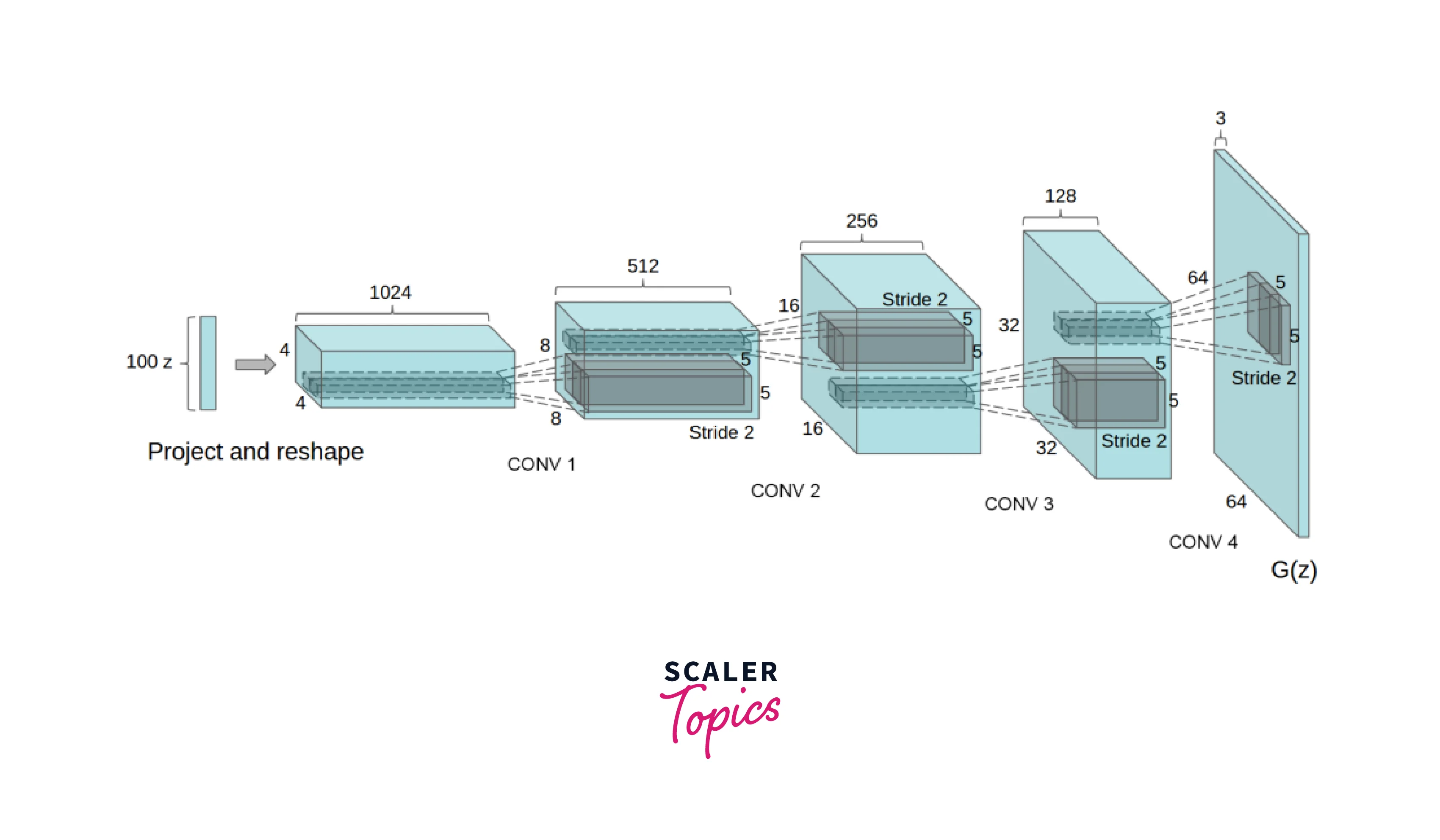
The overall architecture of a CGAN is similar to that of a DCGAN but with minor modifications. The Discriminator architecture in a CGAN is similar to that of a DCGAN, consisting of several convolutional layers, batch normalization layers, and Leaky ReLU activation functions. However, in a CGAN, the Discriminator receives an additional input, the conditioning information, labels, and the generated image. This extra input allows the Discriminator to consider both the image's realism and the consistency of the conditioning information when evaluating the generated image. The Generator architecture in a CGAN is similar to that of a DCGAN, consisting of several transpose convolutional layers, batch normalization layers, and ReLU activation functions. However, in a CGAN, the Generator receives an additional input, the conditioning information, and the random noise used as the latent code. This input allows the Generator to generate images consistent with the conditioning information.
The Discriminator's Network
The Discriminator in a CGAN has a similar architecture as the DCGAN, consisting of several convolutional layers, batch normalization layers, and Leaky ReLU activation functions. However, a hot-encoding layer is added to consider the current image's labels. This layer represents the conditioning information, such as the labels, in a format the network can process. This addition allows the Discriminator to consider both the image's realism and the consistency of the conditioning information when evaluating the generated image. Thus it can guide the Generator to create images with specific characteristics.
The Generator's Network
The Generator in a CGAN also has a similar architecture as the DCGAN, consisting of several transposed convolutional layers, batch normalization layers, and ReLU activation functions. However, it also has an additional layer added to take into consideration the labels. This added layer helps the Generator create images with certain characteristics and make them more consistent with the conditioning information.
Loss Functions
To train the network, we use two loss functions for the Generator and the Discriminator of the CGAN, respectively.
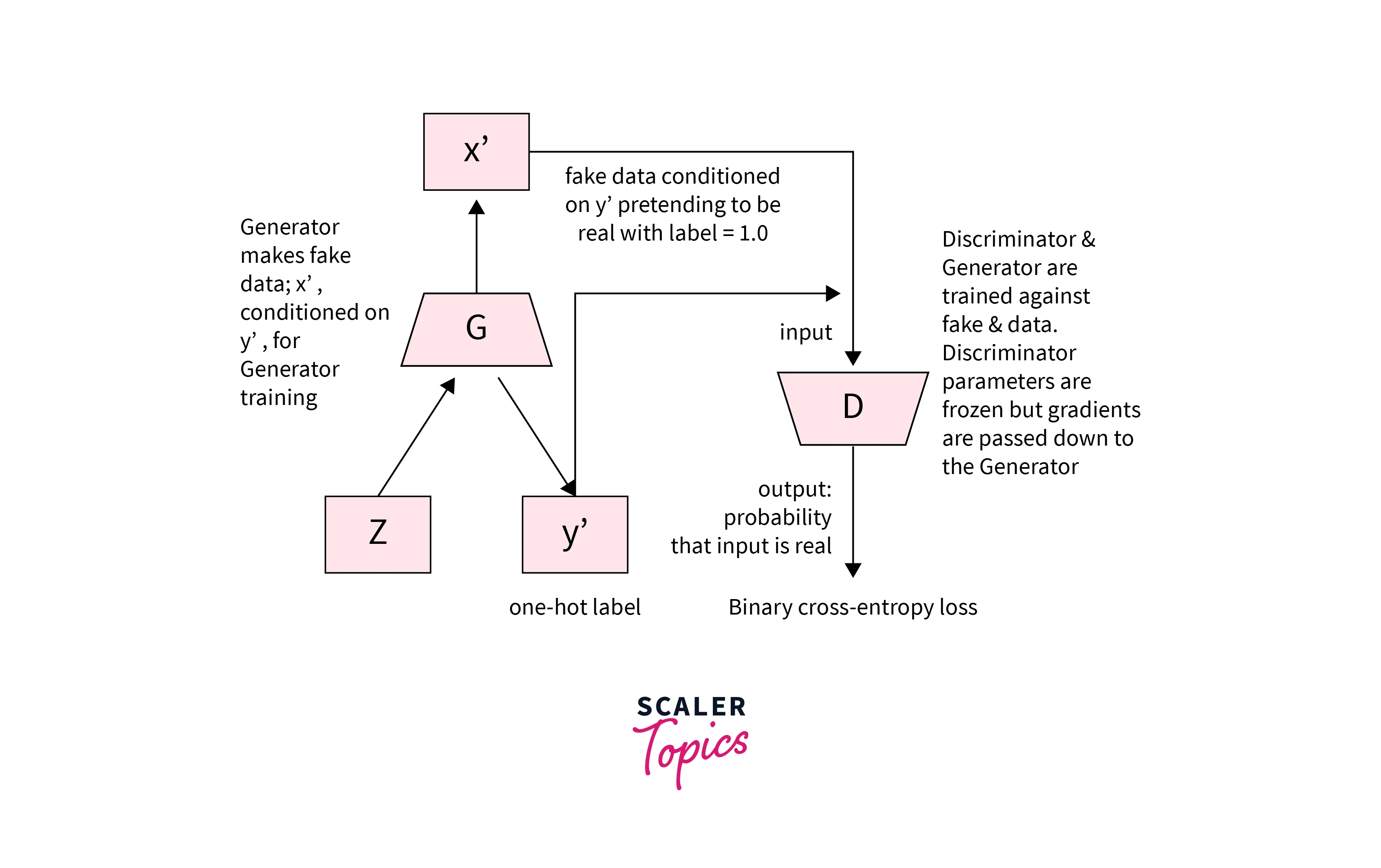
Generator Loss
Since the Generator's objective is to create better fake images gradually, it needs to minimize the difference between the predicted image and the target. The model uses one hot encoded label in this architecture to decide which features to care for. The loss function thus is the following.
The equation can be thought of as given a label, using the Generator to traverse the latent space and create an image. Then pass the created image through the Discriminator and find how well we performed.
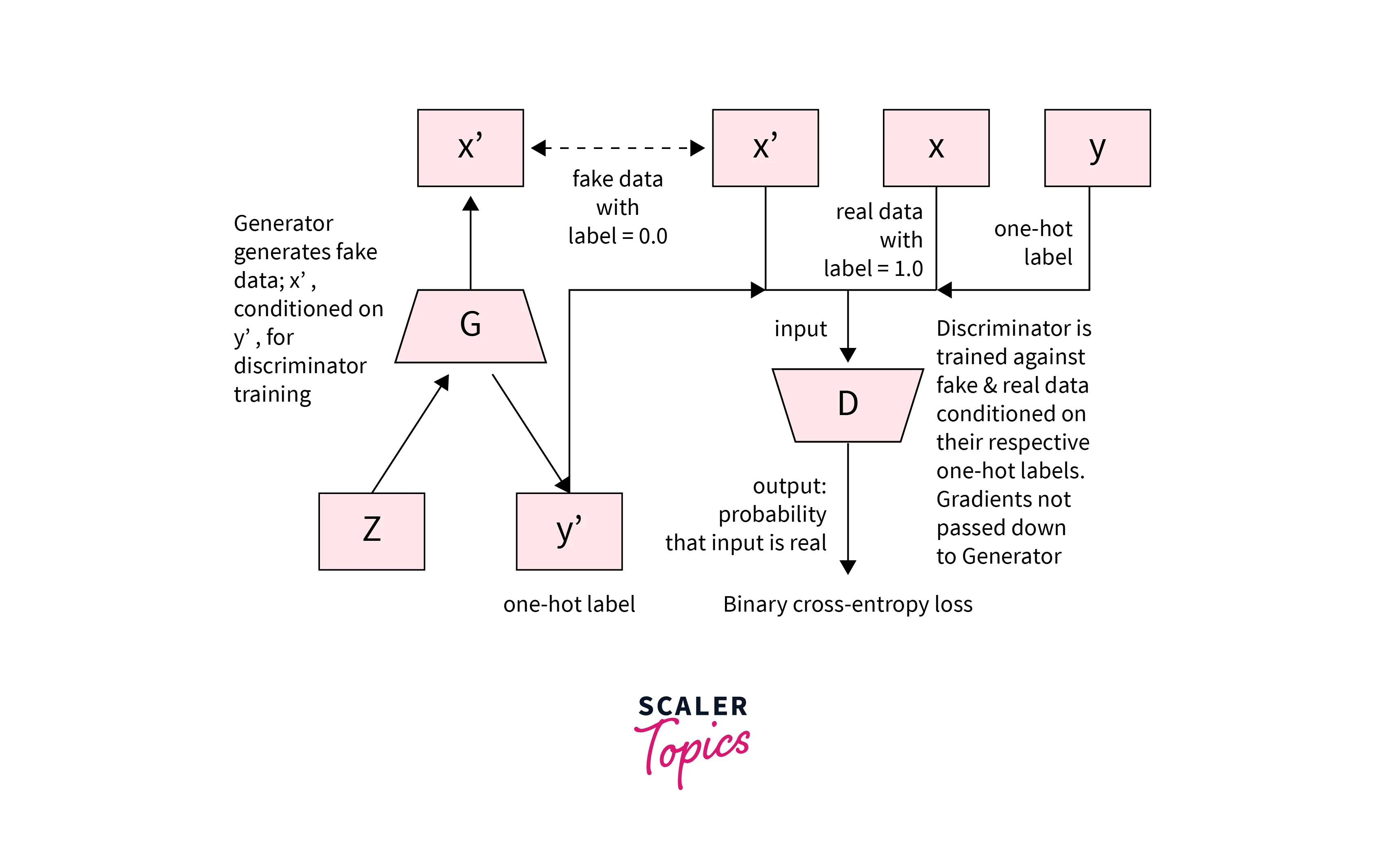
Discriminator Loss
Since the objective of the Discriminator is to label the generated images, its outputs are the probability that the image is true. The loss function is, therefore, the following. (This is a Binary Cross Entropy Loss function)
Training
Training a CGAN is similar to training any other GAN. The Discriminator and the Generator work parallel to create novel images and identify how real they look. The Generator first starts with random noise and passes it to the Discriminator. The Discriminator, in this case, is also provided with labels and returns a probability of how real it thinks the generated image is. This probability is passed to the Generator, which slowly updates its weights to generate better images. This cycle continues until the required quality of images is generated.
Training Flow
Training a CGAN is similar to training any other GAN, the main difference being the use of conditioning information to guide the network in generating specific features. We can break down the process into several steps:
- The Generator starts with a random noise, often called a latent code, as its input. This noise is passed through the generator network, which maps it to an image in the data space.
- The generated image and its corresponding conditioning information, such as labels, are passed to the Discriminator. The Discriminator evaluates the image based on its similarity to the real images and the consistency of the conditioning information. It returns a probability of how realistic the generated image is.
- The probability is passed back to the Generator, which uses it to update its weights to generate better images. - The weights are updated to minimize the difference between the generated and real images.
- This process is repeated for several iterations until the Generator can produce images of the desired quality. During this process, the Discriminator and Generator improve each other, with the Discriminator getting better at identifying realistic images and the Generator getting better at producing realistic images.
One important thing to note is that, during the training process, we must provide the Discriminator with real images and the conditioning information. The additional information allows the Discriminator to make informed decisions about the realism of the generated images and to detect if the conditioning information is consistent with the generated image.
Challenges with Conditional Generation
No model is perfect. CGANs have multiple issues as well. Some of these have been tackled by later research, while others are still active research areas.
Feature Correlation
Another challenge with CGANs is related to the correlation of features in the dataset, which can cause the generated images to be biased toward certain characteristics. For instance, when working with an image dataset of fruits, if the dataset contains images of mostly red apples, the output of the CGAN will also be biased toward generating red apples. Similarly, if the dataset contains mostly pears with spots, the CGAN will generate images of pears with spots.
This feature correlation can cause problems when we want to generate an image of a fruit with certain characteristics that do not align with the features of the images in the dataset. For example, if we want to generate an apple with the spots of a pear, the CGAN might modify the entire apple instead of just the spots because these features are tightly linked in the dataset. This problem can make generating images with specific characteristics difficult or even impossible.
One solution to this problem is to use larger and more diverse datasets containing various images with various features. These datasets will help reduce feature correlation and increase the range of images the CGAN can generate. Pre-processing, such as data augmentation or removing correlation between features, might also help mitigate this issue.
Z-Space Entanglement
The Z-Space is the space of all possible points where a generator could generate an image. In other words, it is the space of all possible random inputs to the Generator.
When a generator generates an image, it maps a point from the Z-space to an image in the data space. The Generator learns a mapping from the latent space to the data space to generate new images by sampling from the latent space. However, this process is only sometimes straightforward, as the latent space may need to be better structured or may not be entirely controllable.
One of the challenges of working with the latent space is that it is often high-dimensional, which makes it difficult to visualize and understand. Additionally, the space may not be smoothly connected, resulting in "entanglement", where the Generator produces unexpected results when the latent space is traversed. Entanglement occurs when interpolation between examples becomes hard to perform and can lead to difficulties in controlling the generation process, making it difficult to generate specific images.
Classifier Gradients
Another challenge with CGANs is related to the ability of the network to identify and modify specific features in the generated images. For the CGAN to make changes in a specific way, it must first be able to understand and interpret what we want it to modify. For example, in the case of generating fruits, if we want to generate an image of a fruit with a longer stem, the network must first be able to understand what a stem is and what it means for it to be longer.
This understanding can be difficult for the network because the feature we want to modify may only sometimes be clearly defined, or the network may need more information. Sometimes, the network may generate images different from what we want because it may interpret our request differently or need more information to make the desired change. Additionally, the feature we want to change might be harder to identify in the images. Hence the network might need help to learn it.
One solution to this problem is to use more explicit and detailed conditioning information, such as annotations or labels, to guide the network in identifying and modifying specific features. For example, in the case of generating fruits, we could provide the network with detailed annotation data on the fruits, including information on the size, shape, and position of the stem. However, this approach requires a large amount of labeled data, which may only sometimes be available or can be time-consuming to acquire.
Overall, being able to modify specific features in the generated images is a challenging task for CGANs and requires careful consideration of the available data and the network architecture used.
Conclusion
- In conclusion, this article discussed Conditional GANs (CGANs), a family of GANs that allow for control over the features modified in the generated image.
- The CGAN builds upon the DCGAN architecture and mainly differs in its training methodology, which allows for traversing the latent space by conditioning the Generator with labels during training.
- The article also compared CGANs to DCGANs, highlighting the key differences between the two, such as the output feature control and the semi-supervised nature of CGANs.
- It also provided an overview of CGAN architecture and the challenges one may face while training a CGAN.
- Overall, the article offers a comprehensive introduction to the concept and application of Conditional GANs, making it a valuable resource for anyone interested in this area of computer vision.