SQL Server Clustered Indexes

Overview
The index in a Relational DBMS that sorts the data rows in the table based on the key or index is called Clustered Index. By default, the primary key acts as the clustered index. This makes the accessing of data very fast and can only be applied to files that contain ordered data with no pre-existing key.
What is Clustered Index in SQL?
The index that defines the physical order of storing the data rows in a table is known as a clustered index in SQL.
The very first place I saw the word index was probably in a book. So, let’s take the example of an index of a book. How does the index of a book help us? Of course, to get to the topic or chapter we are looking for a very fast way. All we need to do is look for the page number in the index and we can just open the page instantly.
Very similar to the index of a book, an index in DBMS is a value that makes every data row in the table unique and allows quick data access. In SQL, there are primarily two types of indexes:
- Clustered Index
- Non-clustered Index
In this article, we will be talking about the clustered index. Precisely, when we apply clustered index to our table, the data gets sorted, thereby making the data access very fast compared to the non-clustered databases.
When to Use a Clustered Index in SQL?
The two primary criteria to apply the clustered index to a file are as follows:
- The file that is stored in the secondary memory (Hard Disk Drive) should contain ordered or sequential data.
- The data should not contain any pre-existing key value.
The following diagram will clear out which indexing is to be used under which scenario.
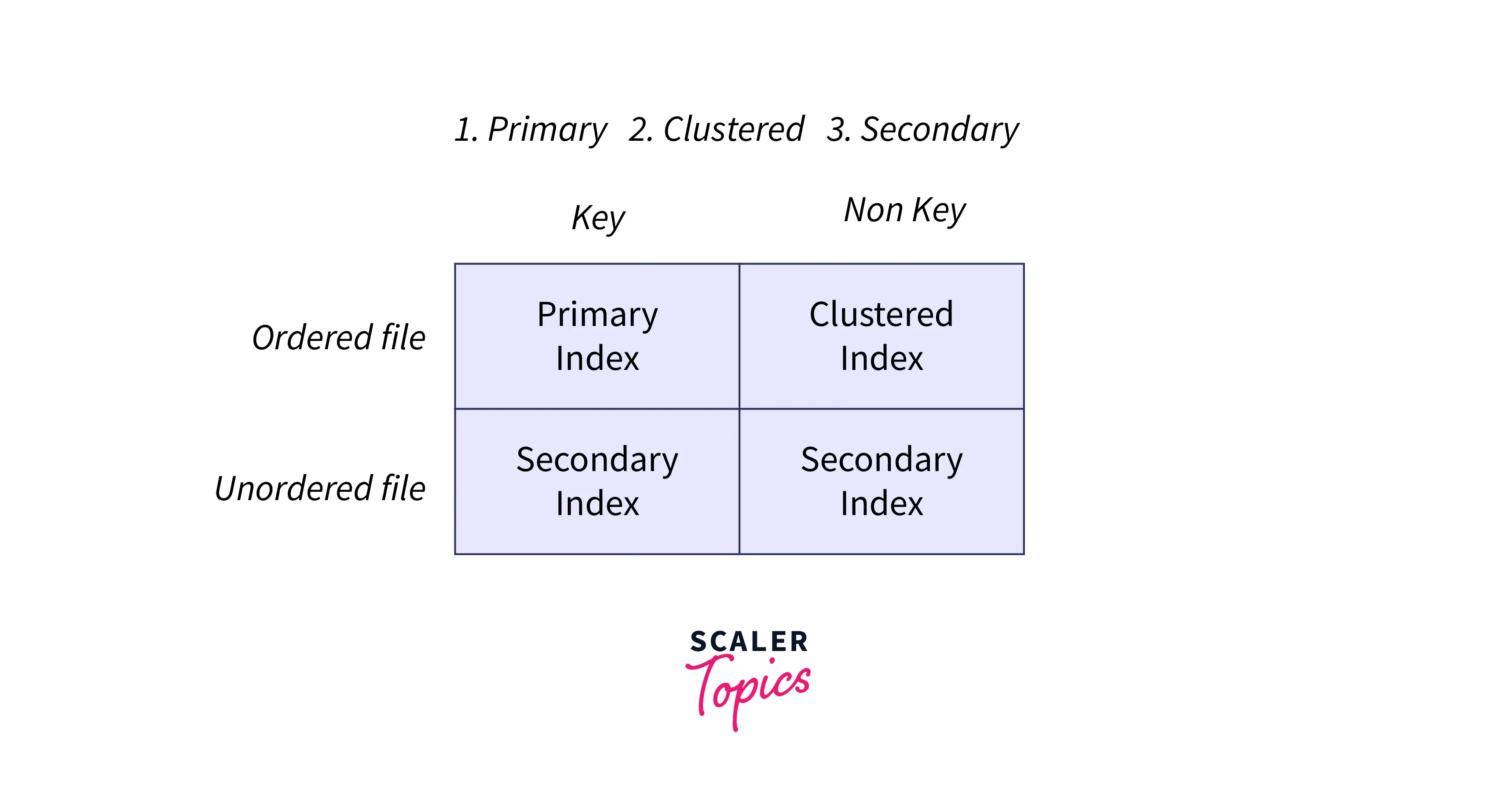
- Primary index: When the file is ordered file and has pre-existing key.
- Cluster index: When the file is ordered file and has NO pre-existing key.
- Secondary index: When the file is unordered file.
The figure below shows the kind of file that is stored in secondary memory, containing ordered data and no pre-existing key. Each of the segments is called a block or page, usually, we name the blocks from the top starting from Block 0.
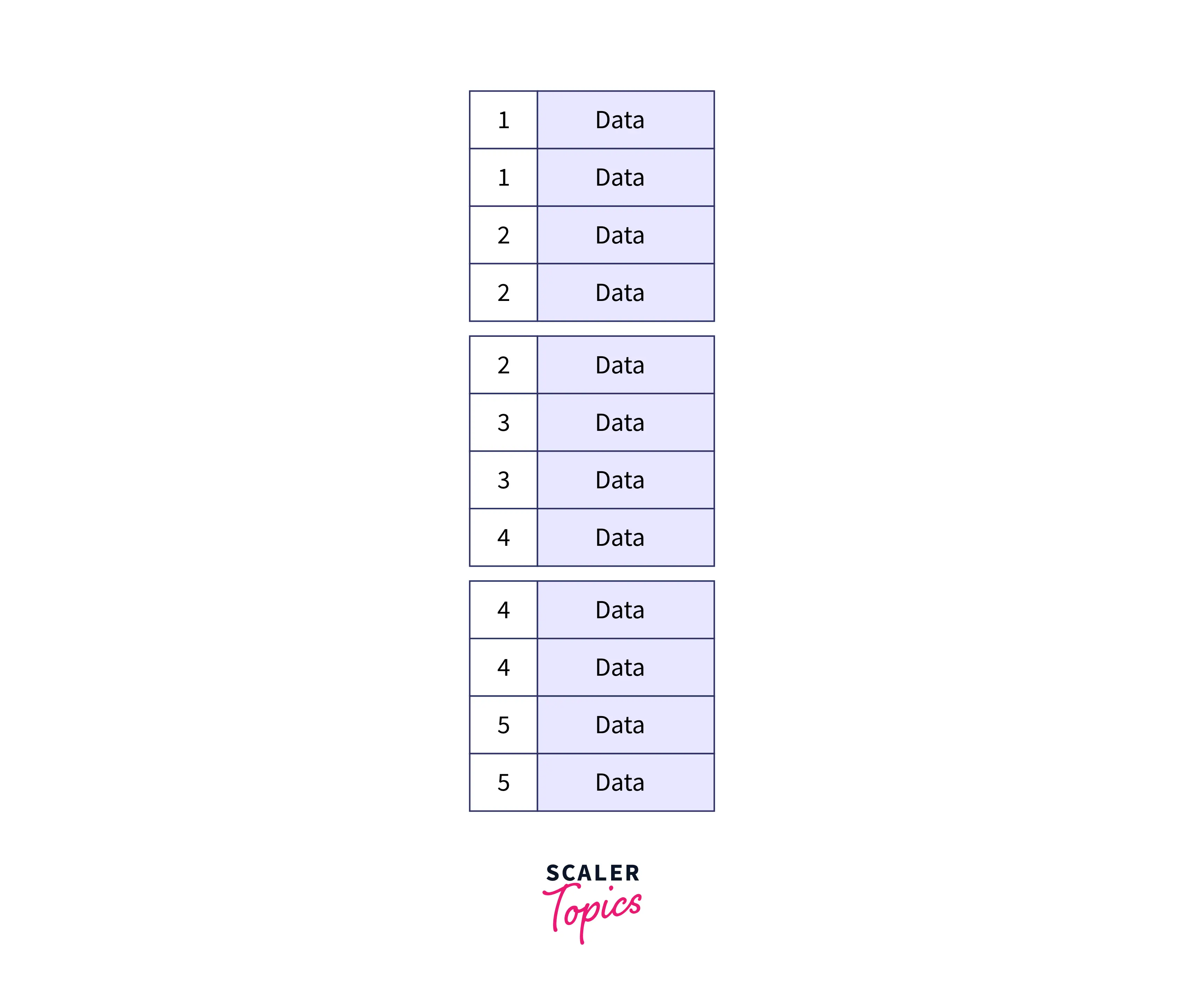
Since we are applying this to ordered files, a binary search algorithm is used to search for a particular key thereby making the process of searching very fast, in the order of O(logn), where n is the number of entries in the Index Table.
Let us have a look at what an Index table is and how it refers to the data in the file stored in the secondary memory (Hard Disk Drive).

The left figure shows the secondary memory or the Hard Disk Drive (HDD) and the right figure shows the Index table. In the Index Table, the key column contains a single occurrence of the key of the data in the secondary index, and a pointer points to the block in the secondary memory where that same key is located. For example, the key 1 pointer points to block 0.
Note: For keys that are in two separate blocks, like key 4, there is a concept of Block Hanker which specifies that there is a continuation of the same key between two or more blocks.
Characteristics of Clustered Index in SQL
The following are the characteristics of a clustered index:
- Stores the data in sorted order: Whenever clustered index is applied to a table the data in the table gets sorted on the basis of the indices.
- The data and the index are stored together: No additional space is needed to store the index and the data separately.
- The accessing of data is very fast with a time complexity of O(logN + K) [Where N = Number of blocks in Index Table and K is the time taken for index seek]: Since binary search is applied to the sorted data thus it takes logN time to get to the required block then another linear time of K is needed for the seeking.
- Key Lookup: When the search key is not available in the table then the situation is called key lookup. This is an expensive operation for frequent queries, as this requires to search the entire table.
- Fragmentation: Fragmentation occurs when we add excess data to a page, the pages get split and they go out of order in the B-Tree. This means even if we have increasing order of keys, fragmentation can happen.
Example of Clustered Index in SQL
Let us create an EMPLOYEE table with the fields employee ID, employee name, department, and department number.
Code:
As we can see we have the empId field set as PRIMARY KEY, this is by default a clustered index so it shows properties of the clustered index like sorting the data based on the value of the key.
Let us now insert a few dummy data and display the entire table to verify if the data gets sorted in increasing order of empId.
Code:
Output:
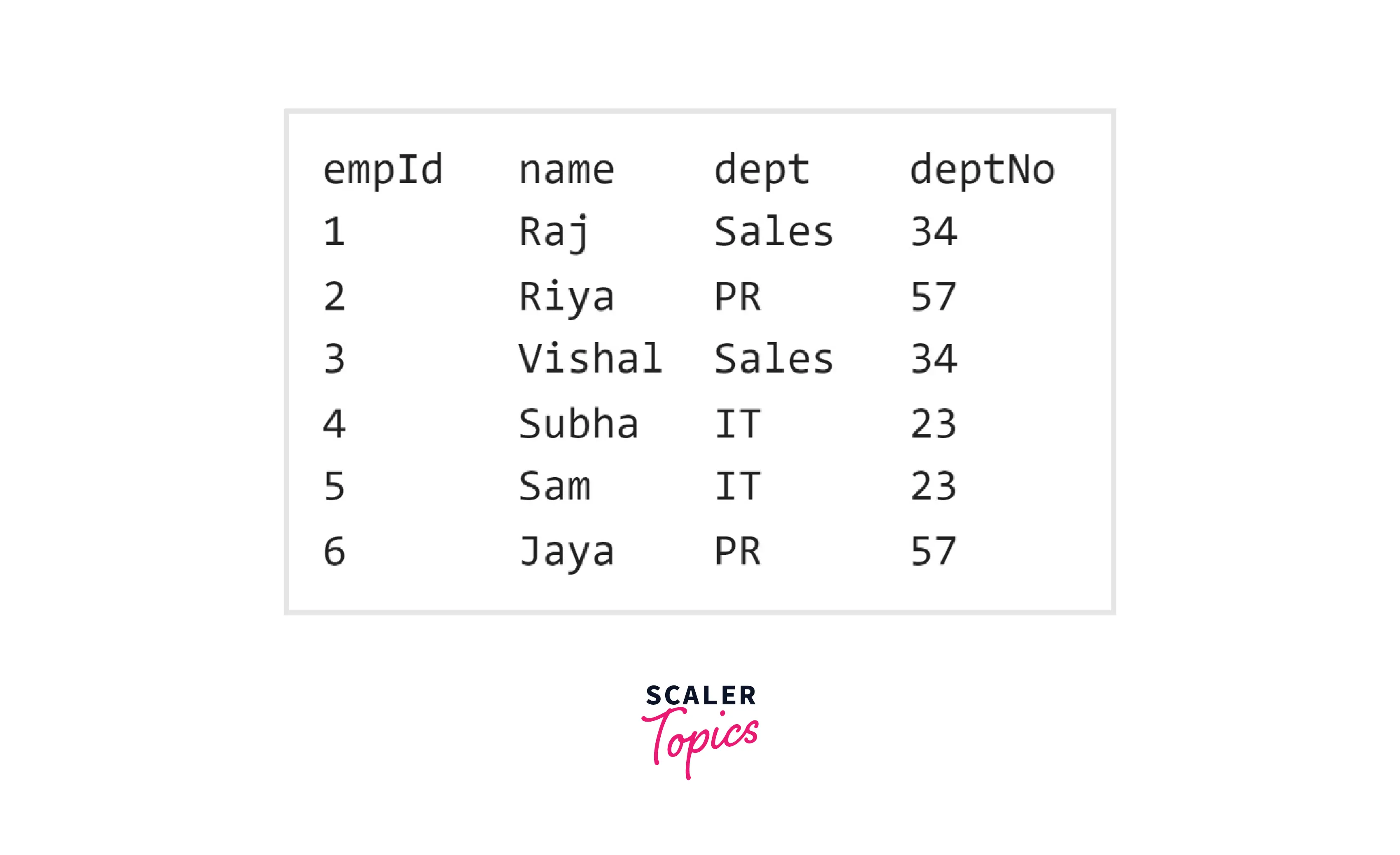
As you can see from the code, we did not enter the data in the order of ``empId, but in the output we have it sorted in ascending order of empId`.
Advantages and Disadvantages of Clustered Index in SQL
Advantages
The advantages of clustered index are as listed below:
- These are the best choice for range minimum or maximum or count type queries.
- Location mechanism is used to locate the entry index at the start of a range.
- Clustered index allows us to go to a specific point in data so that we can keep accessing the data sequentially thereafter.
- This indexing helps to minimize page transfer and maximize the cache hits.
Disadvantages
The disadvantages of clustered index are as listed below:
- Excess operations like insertion, deletion, and updates for SQL.
- Large number of insertion operations in non-sequential order
- The number of page splits increases which causes page data to increase as well as the page indices.
- Longer update time when a field in the clustered index is changed.
Clustered vs Non-clustered Index in SQL
The differences between clustered index and the non-clustered index are listed below:
| Parameters | Clustered Index | Non-clustered Index |
|---|---|---|
| Data accessing speed | Faster | Slower |
| Used for | The data is sorted and stored. | A logical order of data flow can be created and pointers are used for physical data files. |
| File size | Larger file size | Smaller file size |
| Additional disk space | No additional space required | Additional space is required to store the index separately. |
| Key type | The primary key acts as a clustered index by default. | It can be any unique constraint or even a composite key. |
| Primary feature | Performance of data retrieval is improved | This should be used only on columns that are used in joins. |
To learn more read Difference between Clustered and Non-clustered Index.
Conclusion
- The table with the clustered index gets its data sorted based on the key value of the clustered index.
- There can be only one clustered index column per table.
- Clustered index can be applied only to the files with ordered data and no pre-existing key.
- The data retrieval becomes very fast as a binary search algorithm is used to locate the index [O(logn)].