ML Compilers in PyTorch
Overview
This article discusses Machine Learning Compilers' role in deploying ML models. Understanding how compilers work is crucial as it can help us choose the right compiler to run our ML models on a hardware device of our choice while checking the model performance to enhance the speed. In addition, compilers are used to generate a series of high- and low-level intermediate representations before generating machine code native to the hardware we want to run our models on. This article also discusses ML compilers in PyTorch.
Introduction
Machine Learning and, specifically, Deep Learning as modeling fields have shown promising and revolutionary results and are the major tech stack operating behind many intelligent applications empowering our day-to-day life.
To be able to take the trained machine learning models from our notebooks or any coding environment to our end users (essentially, in production), several bottlenecks are involved.
No matter how accurately our model performs, it will be useful only when we can efficiently serve it to our users through applications, etc.
In those terms, the model's success is defined by how optimally the models can compile and run on the hardware accelerator they are getting used by.
Let us now look at the distinction between two major ways to serve machine learning models to the end users - this will act as our motivation and foundation to learn about what compilers, which this article is about, are.
ML on the Edge - Cloud Computing vs. Edge Computing
To serve our well-performing model to the users, we could use a managed cloud service like AWS by Amazon or the google cloud platform and deploy our model on it. This way, the data from the users are sent to the model, which is deployed on the cloud and again takes care of all the expensive calculations and sends the data (predictions) back to our users as the output.
However, some downsides to deploying models on the cloud lead us to another way of deploying ML models, ML on edge or edge computing. First of all, let us look at some potential challenges faced during cloud deployment -
- The first is an obvious challenge and does not exactly source itself from cloud services. However, it is more concerned with how deep learning is growing as a field with large models containing billions of parameters being researched and released by academia. This makes inferencing from the models compute-intensive, and hence inferential process from these models takes up a lot of memory and compute on the cloud, making up for a lot of cloud expenditure on the companies' part.
- To send the data to the model on the cloud and get the predictions back, there needs to be a stable internet connection for this data transfer to occur smoothly, which is sometimes challenging for remote and underdeveloped areas.
- We see that on similar lines, network latency becomes a bottleneck when transferring data back and forth over a network.
- Sending data over the network also poses security concerns as the user data is susceptible to being intercepted. Also, data from a large user base is stored at a place that causes concern in situations of a breach.
Owing to these and other challenges, edge computing brings a large part of the computations to consumer devices (also called edge devices ) by bringing the machine learning models themselves to the consumer devices. This saves cloud costs as the model computations now do not happen on the cloud servers while also addressing other challenges.
As the interest in edge computing is growing, the hardware industry is working to bring more suitable edge devices with specialized hardware into the market capable of handling and running machine learning models.
However, a major bottleneck still exists in running ML models on specialized hardware - the compatibility and performance bottleneck. The gap between the ml models and hardware accelerators must be fulfilled, and compilers target just that. Next, we will elaborate on these bottlenecks and learn exactly what compilers are.
What are ML Compilers?
In a wider sense, compilers translate programming languages as humans write into binary code executable by computer hardware.
ML compilers bridge the ML models and the hardware accelerators or platforms used to run the models.
Let us elaborate on the state of the many ML frameworks being developed and the specialized hardware being developed to run them efficiently.
The Compatibility Bottleneck
As we just discussed, with an increased fascination towards edge computing, developments to make specialized hardware to run ML models are going on by companies. Here, it is important to note that it is not the case that models developed using any other framework can run on a hardware device. Furthermore, it is not guaranteed that the framework we are developing our models on is supported by the hardware device we want to use to optimally run our models on - for instance, until September 2020, Pytorch was not supported on TPUs. This is precisely the compatibility bottleneck.
It is important to note that supporting any arbitrary framework on any arbitrary device is challenging. It takes heavy engineering and a clear understanding of the hardware architecture to leverage it efficiently to support a particular framework.
This has double-fold implications -
- The developers working on a framework or a library tend to focus on a subset of hardware accelerators to provide support.
- And vice versa means that specialized hardware has libraries that again support a subset of ML frameworks.
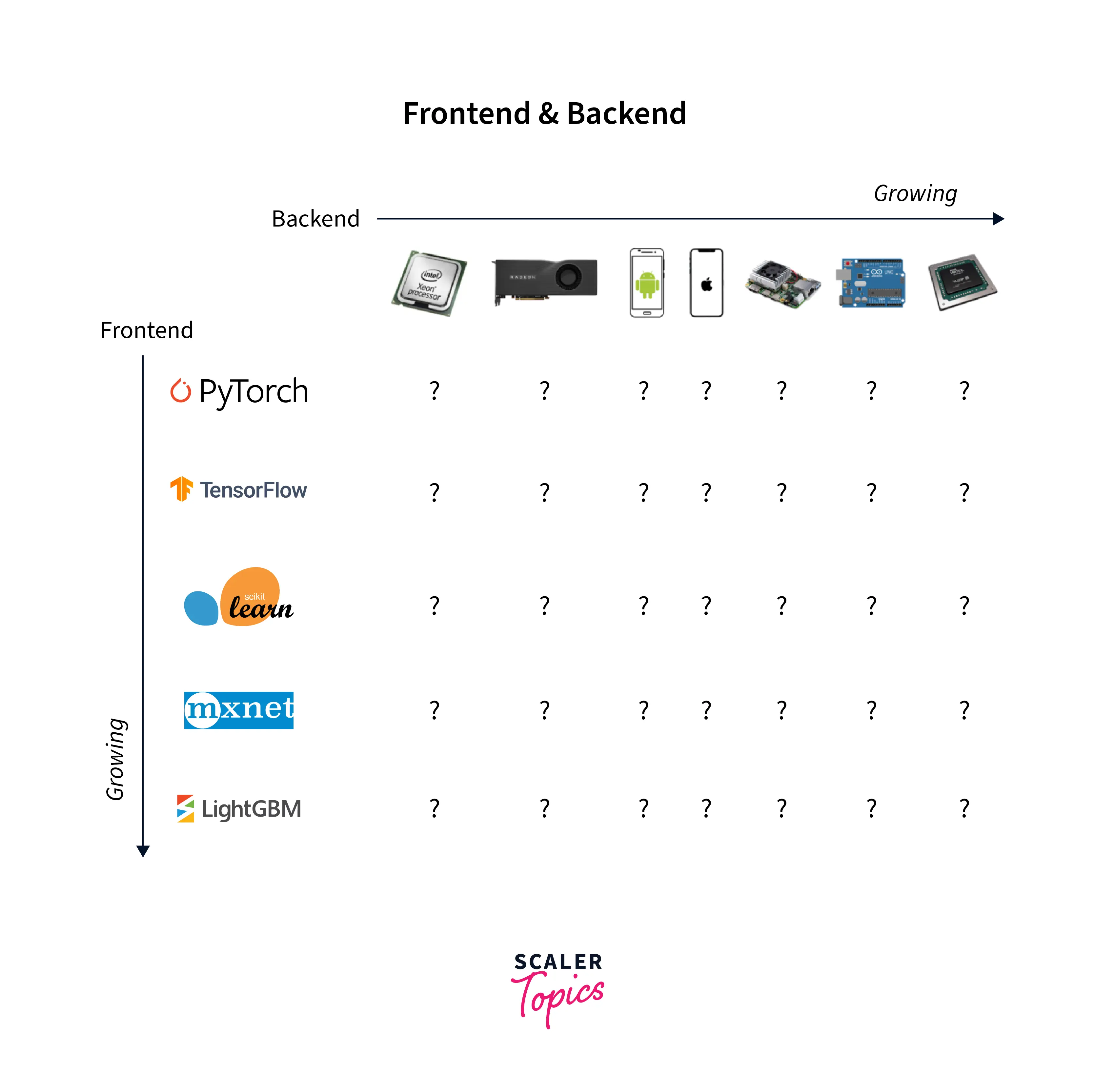
To tackle these two implications, ML compilers have something called intermediate representations or IR as their core part. Intermediate representations act as a way to connect an ML model developed in an arbitrary framework to an arbitrary hardware device which in turn allows framework developers to not worry about making their framework support every other hardware device and also allows the hardware to only focus on supporting this intermediate representation.
The diagram below demonstrates intermediate representation in the pipeline.
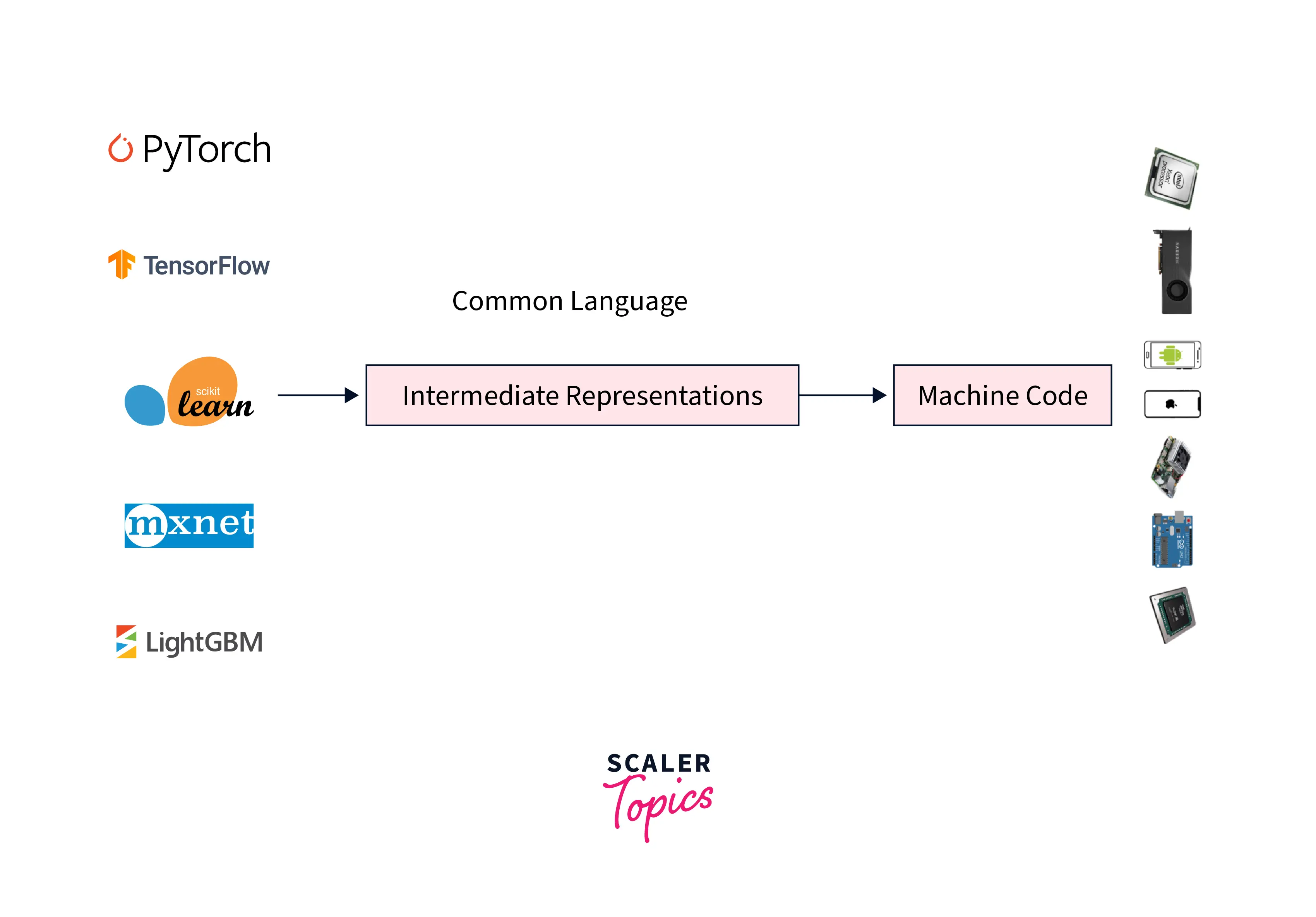
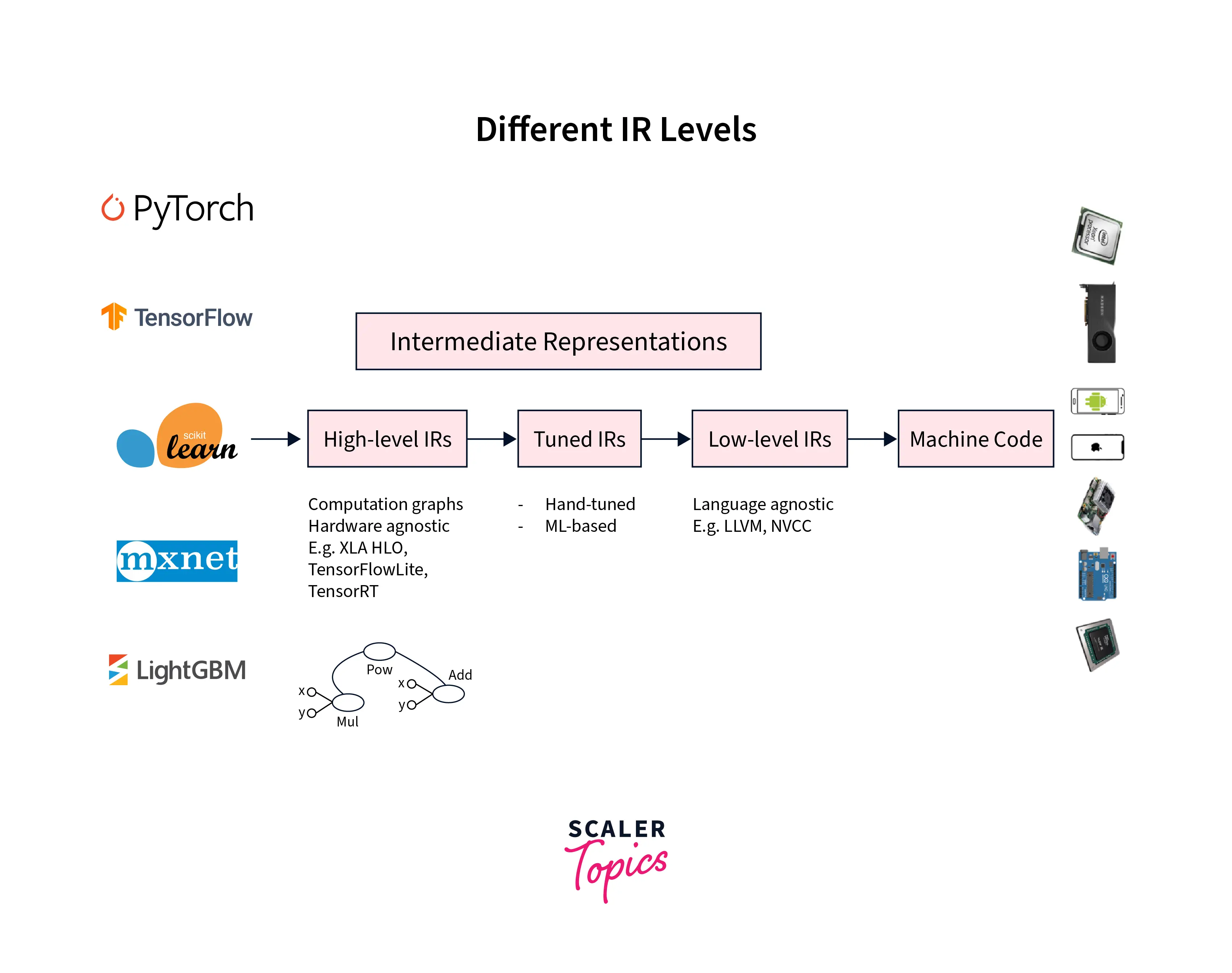
ML compilers thus work on generating a series of low and high-level intermediate representations from the code of our model written in some framework.
These IRs are then used to generate something called a hardware native code to run models on specific hardware devices - codegen is the code generator that is used for this generation.
Optimizing Compilers
The machine-level code generated by codegen might be as performant as it could be depending on what hardware device it is generated for.
To develop a single ML workflow, many frameworks might interact together for data or feature transfer, etc. As a result, the flow across these frameworks might need to be optimized, leading to performance issues in production environments. Optimizing compilers hence aim to speed up or optimize our models (specifically, the computation graphs of our models) while they work to convert the model code into machine code.
What is Nvidia TensorRT?
TensorRT is an SDK developed by the NVIDIA team for high-performance deep learning inference. It includes a deep learning inference optimizer and runtime that delivers low latency and high throughput when applications use deep learning models for inferential purposes.
Models developed in almost any popular framework can be imported using the API support provided by tensorRT, which generates optimized runtime engines using the trained models that are then deployable in data centers and automotive and embedded environments.
The major features of tensorRT are as follows -
- Quantization - TensorRT quantizes models to use int8 precision format instead of operating in the floating point 32-bit format (the standard for most deep learning libraries) - this enables models to use less memory and space with faster int8—calculations with little accuracy.
- Tensor and Layer Fusion - Fusing different operations or layers into one single operation or layer optimizes GPU memory.
- TensorRT uses dynamic tensor memory and minimizes memory footprint by reusing memory for allocating tensors efficiently
- It has a scalable design to process multiple data input streams parallelly.
Convert PyTorch Model to TensorRT
This section will discuss Torch-TensorRT, an integration of tensorRT with PyTorch that leverages inference optimizations of TensorRT on NVIDIA GPUs. It provides a simple API that uses just one line of code to provide up to 6x performance speedup on NVIDIA GPUs.
Torch-TensorRT leverages TensorRT optimizations such as floating point 16 or int 8 precision instead of the standard floating point 32 precision while offering a fallback to native PyTorch when TensorRT does not support the model subgraphs.
Torch-TensorRT is an extension to TorchScript (that parses the model) that optimizes and executes subgraphs compatible with tensorRT while letting PyTorch execute the remaining graph.
The optimized graph hence obtained can be run like a torchscript module. The following three are the main steps involved in the torch-tensor rt compiler for optimizing the compatible subgraph -
- Lowering the TorchScript module - In this step, the torchscript model is lowered because common operations are represented in a form that maps directly to tensorRT. Therefore, no optimization takes place in this step.
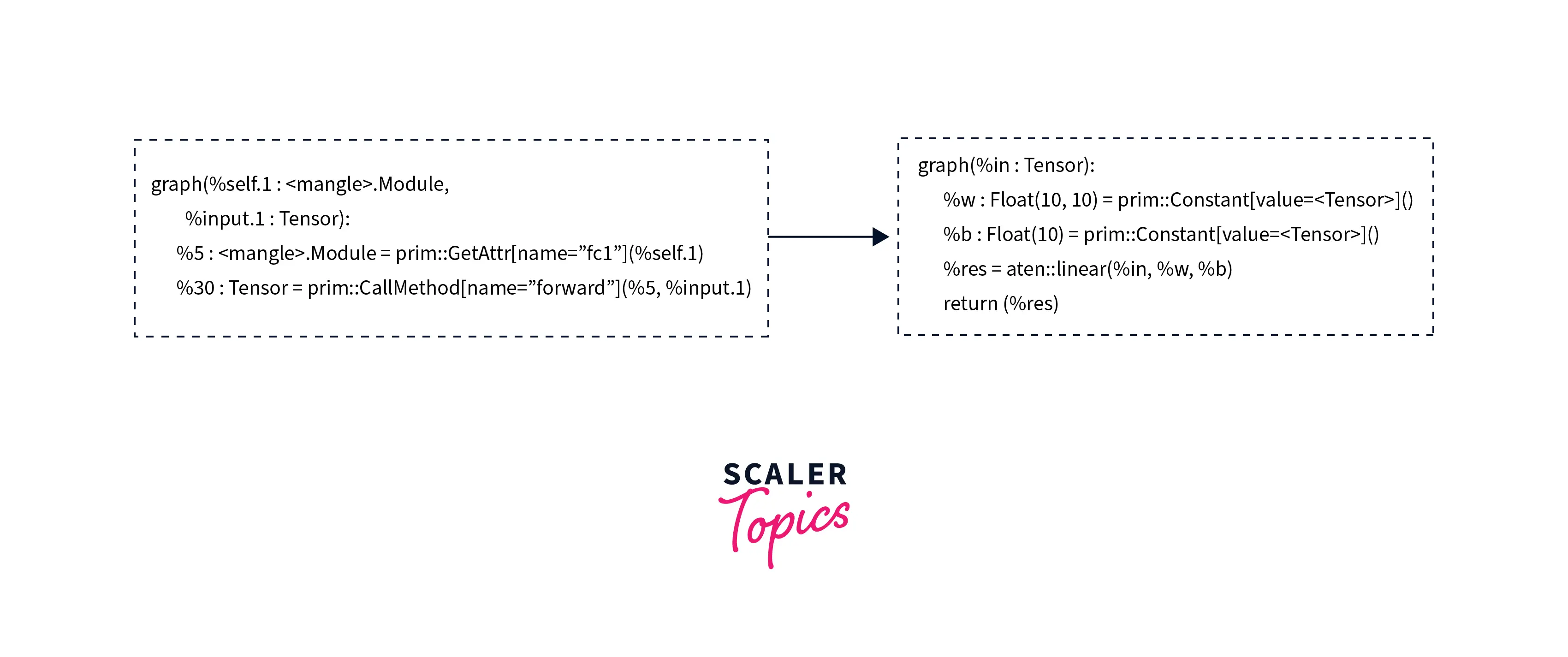
- Conversion - In this step, torch-tensor rt identifies the subgraphs compatible with tensorRT and converts them to tensorRT operations giving us a compiled torchscript module.
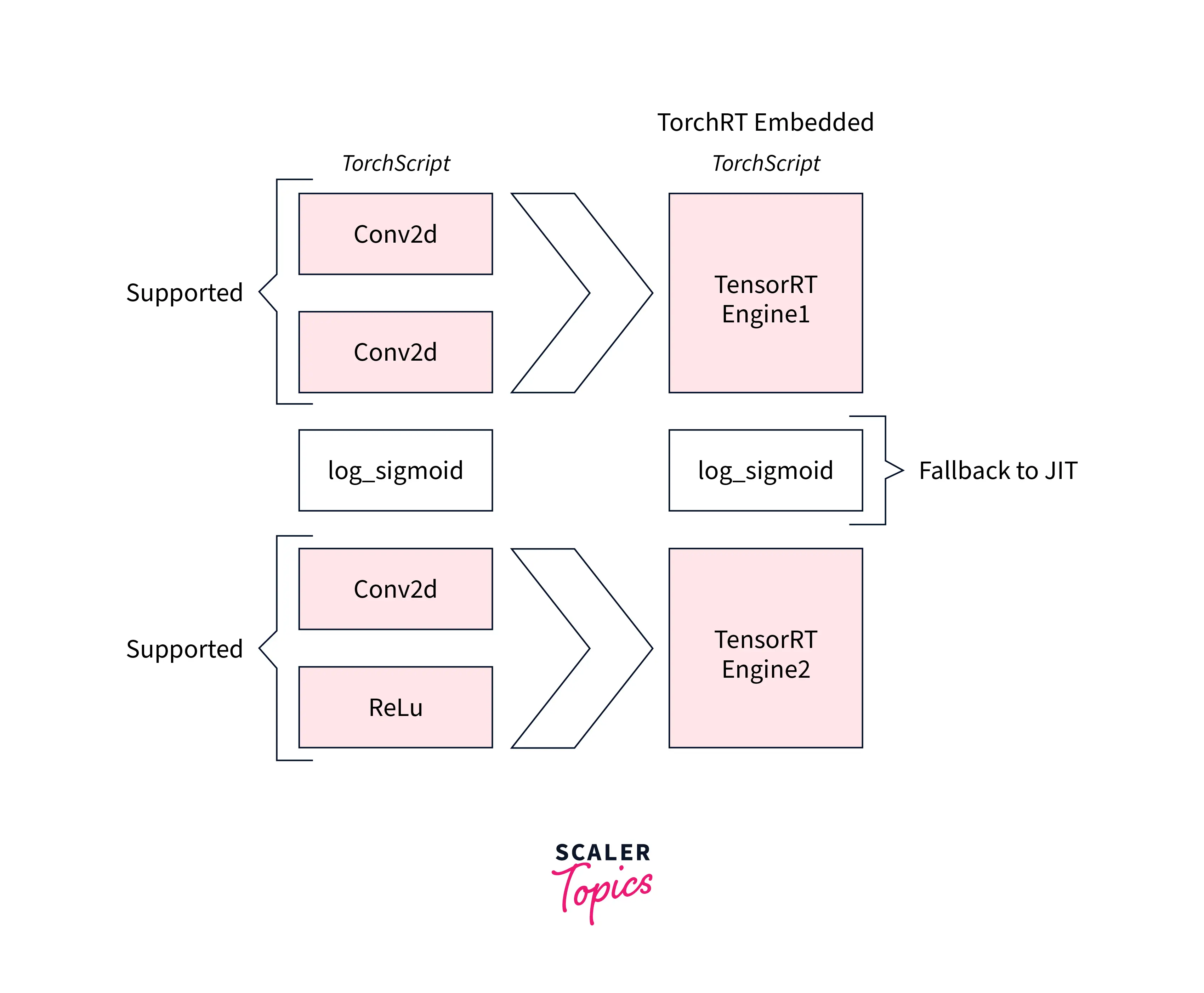
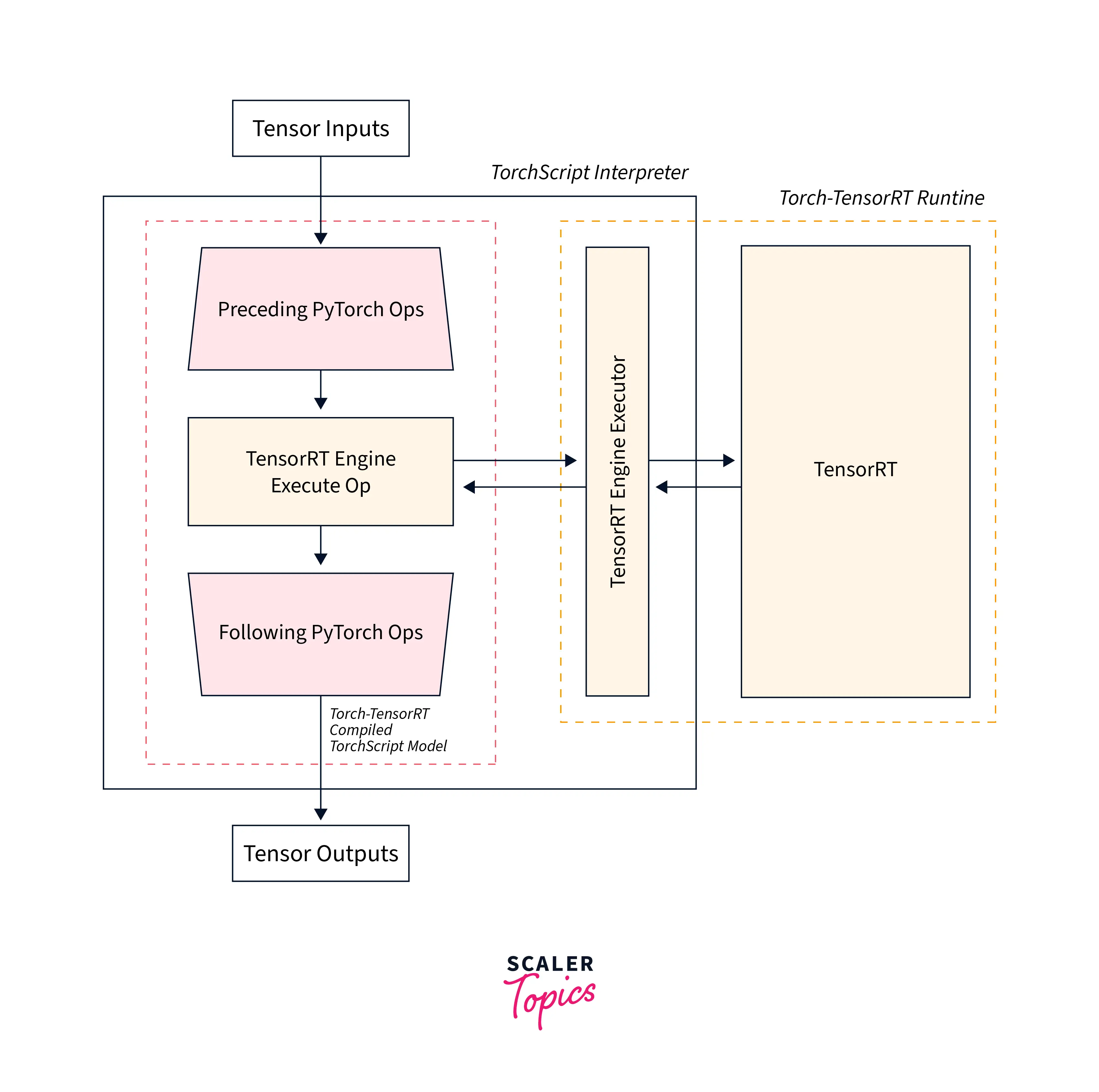
- Execution - In the execution step, the torchscript module from the previous step is executed by the torchscript interpreter passing all the inputs, and the results are returned to the interpreter.
Intro to TVM and Optimizing Models Using TVM
Apache TVM is an open-source machine learning compiler framework for hardware devices, CPUs, GPUs, and other machine learning hardware accelerators. It enables machine learning developers to optimize their models and run computations for inference efficiently on any hardware backend.
PyTorch supports an official tvm-based backend called torch_tvm. We can enable it simply by using the -
After this, PyTorch will attempt to convert all operators to known Relay operators (relay is an IR for machine learning frameworks) during its JIT compilation process.
PyTorch IR is a PyTorch-specific intermediate representation for ML models similar to Relay. PyTorch programs can be converted into the PyTorch IR via model tracing, which records the execution of a model, or by using TorchScript. In addition, the TVM backend further lowers PyTorch Intermediate representation to Relay and thus can improve performance with little user involvement.
An easy way to use an already written PyTorch model with tvm is to trace it using torch.jit.trace, like so -
Conclusion
This article introduced the reader to the role of ml compilers in developing and deploying deep learning models to serve AI-powered applications. Let us review in points that we discussed in this article -
- Firstly, we got an introduction to the bottlenecks faced while deploying ml models in production regarding compatibility with the hardware devices.
- After this, we understood what ML compilers are and how they can be used to optimize and efficiently serve ML models.
- Finally, we looked at two ml compilers in PyTorch, namely - NVIDIA's TensorRT and Apache TVM.