Introduction to Images in Computer Vision
Overview
Computer Vision is a rapidly evolving field that focuses on enabling machines to interpret and understand visual data from the world around them. Images play a crucial role in computer vision as they serve as the primary source of visual data. Understanding images and their properties is fundamental to building computer vision applications such as object detection, facial recognition, and image segmentation. Computer vision image is a digital representation of a visual scene that has been captured by a camera or generated by software. These images contain pixel values that represent the color and intensity of each point in the scene.

Pre-requisites
- To understand about a computer vision image, a basic understanding of linear algebra and calculus is helpful, but not mandatory.
- However, familiarity with programming languages such as Python is essential.
What is an Image?
An image is a two-dimensional representation of visual data, typically captured by a camera or generated by a computer. Computer vision image can be either grayscale or color, depending on whether they contain information about the intensity of light or the combination of different colors.
- In OpenCV, images are represented as multi-dimensional arrays of pixel values. The number of dimensions and the size of each dimension depend on the type of the image, which can be grayscale or color.
- For grayscale images, each pixel is represented by a single value that denotes the intensity or brightness of the pixel. The pixel values range from 0 to 255, where 0 represents black and 255 represents white.
- For color images, each pixel is represented by a combination of values for the three primary colors: red, green, and blue (RGB). The pixel values for each color channel range from 0 to 255, so a single pixel in an RGB image is represented by a three-dimensional vector of values (R, G, B).
- OpenCV provides a number of functions for reading, writing, manipulating, and displaying images. These functions allow for a wide range of image processing tasks, including filtering, segmentation, feature extraction, and object detection.
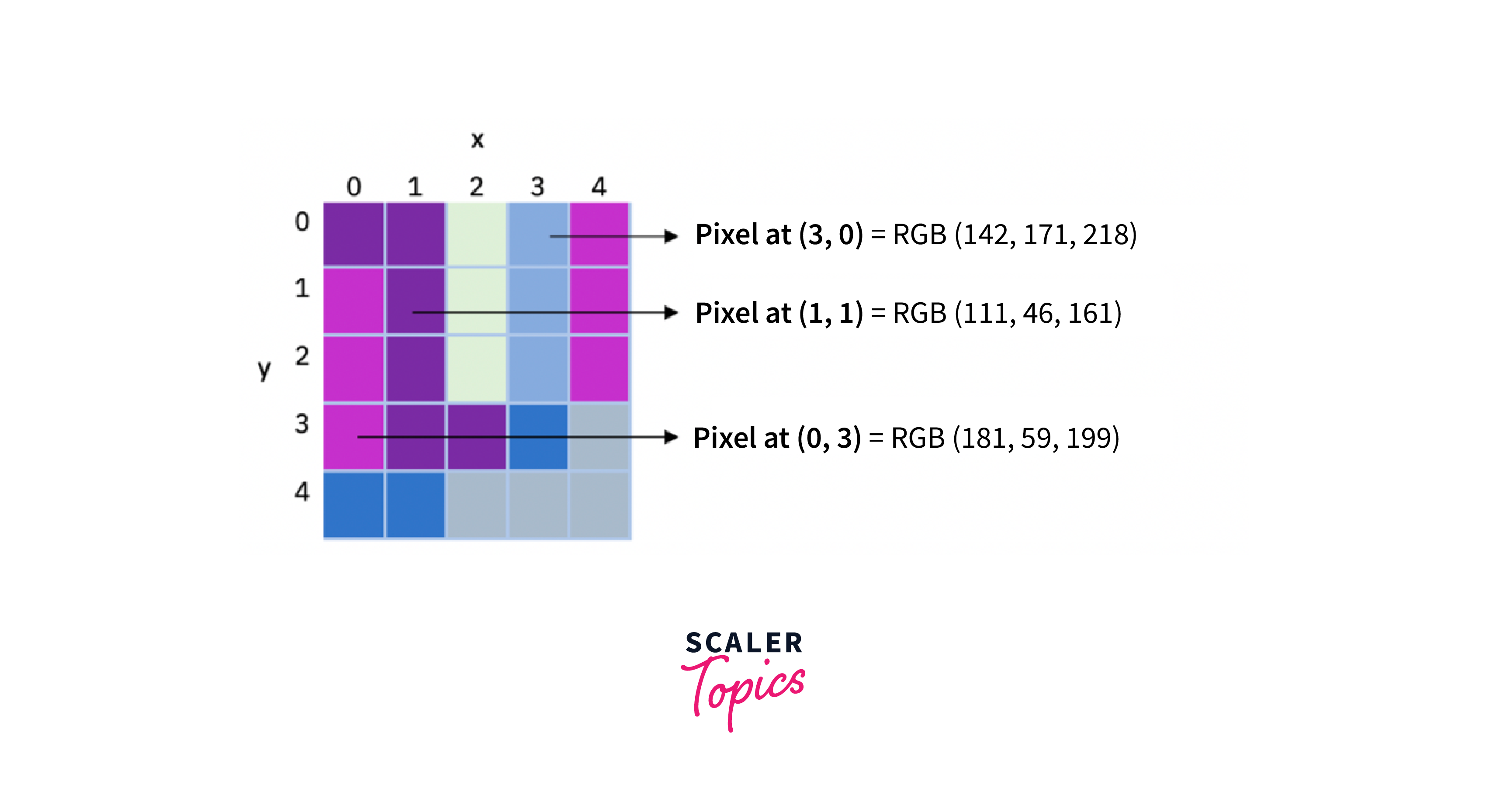
How are Images Formed?
Images are formed by capturing light reflected or emitted from objects in the world around us. When light hits an object, it is reflected back and captured by a camera, which records the intensity and color information of the light. The camera's sensor converts the light into digital data, which is stored as an image file.
The resolution of the image is determined by the number of pixels in the image, with each pixel representing a tiny unit of the image. The higher the number of pixels, the greater the detail and resolution of the image.
In summary, understanding computer vision images and it's properties and how they are formed is essential, as it enables the development of algorithms to extract useful information from images and interpret the visual data for different applications.

Characteristics of an Image
A computer vision image has several characteristics that define its properties, including:
-
Resolution:
The resolution of an image refers to the number of pixels it contains. A higher resolution image will contain more pixels and thus more detail.
-
Color space:
Images can be represented in different color spaces, such as RGB (red, green, blue), CMYK (cyan, magenta, yellow, black), or grayscale.
-
Bit depth:
Bit depth refers to the number of bits used to represent each pixel in an image. A higher bit depth allows for more color and brightness variations in an image.
-
Noise:
Noise refers to any unwanted artifacts or variations in an image. It can be caused by factors such as sensor sensitivity, lighting conditions, or image compression.
-
Contrast:
Contrast refers to the difference in brightness between different parts of an image. High contrast images have greater differences in brightness, while low contrast images have fewer differences.
-
Edge detection:
Edge detection refers to the process of identifying boundaries between different regions in an image. Edges can be detected using various techniques, such as gradient-based methods or thresholding.
-
Texture:
Texture refers to the visual patterns and variations in an image. Texture can be analyzed using techniques such as Gabor filters or local binary patterns.
Understanding these characteristics of computer vision image is important for developing and applying computer vision algorithms and techniques to digital images.
Digital Image and Image as a Matrix
A digital image is a representation of visual data in a binary format, consisting of a matrix of numbers that represent the intensity of light or color at each pixel. Each pixel in the image is represented by a value, with grayscale images having a single value per pixel and color images having multiple values per pixel. A computer vision image is often represented as a matrix, where each element of the matrix represents the intensity of light or color at that pixel.

Color Image and Dimensions
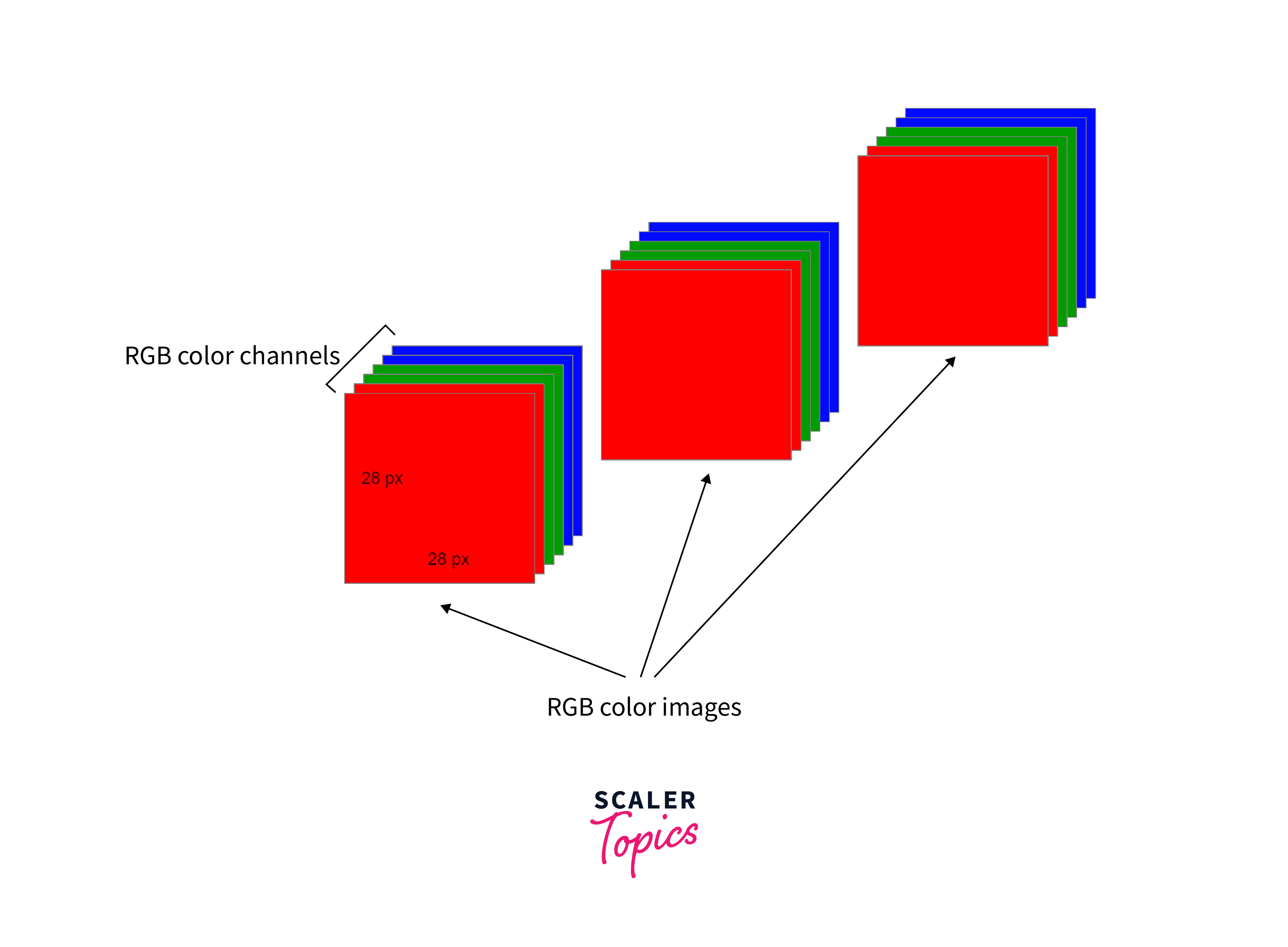
A color computer vision image consists of multiple channels of color information, such as red, green, and blue (RGB), and is represented as a 3-dimensional matrix.
- A color image in OpenCV is typically represented as a array of pixel values, where the dimensions are height, width, and channels.
- The height and width dimensions represent the size of the image in pixels, while the channels dimension represents the number of color channels used to represent each pixel.
- In OpenCV, the most common way to represent color images is using the RGB color model, which uses three color channels: red, green, and blue. Each pixel is represented by a combination of values for these three channels.
- Another common color model used in OpenCV is the HSV color model, which separates color information into hue, saturation, and value components. This can be useful for certain image processing tasks such as color segmentation.
- In addition to the standard color models, OpenCV also provides support for working with other color spaces, such as YUV, LAB, and XYZ. These can be useful for specific applications, such as video processing or color correction.
Get Familiar with RGB Channels
In a color image, each pixel has three values, one for each color channel. The value of each color channel ranges from 0 to 255, representing the intensity of that color at the pixel. By varying the intensity of each color channel, a wide range of colors can be represented in the computer vision image.
- Each pixel in an RGB image is represented by a combination of values for the three color channels. For example, a pixel might have values of (255, 0, 0) for red, (0, 255, 0) for green, or (0, 0, 255) for blue.
- By manipulating the values of the RGB channels, it is possible to change the colors and appearance of an image. For example, increasing the value of the red channel for all pixels will result in a redder image.
- RGB channels can also be used to extract useful information from an image. For example, in medical imaging, the green channel might be used to highlight blood vessels, while the blue channel might be used to highlight bone structures.
- In addition to RGB, there are other color models used in image processing, such as CMYK (Cyan, Magenta, Yellow, and Black) and HSL (Hue, Saturation, and Lightness). These models have different properties and are used for different applications.

Splitting and Merging Channels
In computer vision, it is often necessary to work with individual color channels of an image. RGB images can be split into separate color channels, where each channel represents the intensity of a single color at each pixel. This can be done using image processing libraries such as OpenCV and Pillow. Once the channels are separated, they can be manipulated individually or combined back into a single image by merging the channels.
Splitting a computer vision image into individual color channels is a common operation that is required for various tasks such as color-based object detection, segmentation, and image enhancement. This operation is straightforward in RGB color space, where an image is composed of three channels: red, green, and blue.
Splitting an RGB computer vision image into its color channels can be done using image processing libraries such as OpenCV and Pillow. For example, in OpenCV, the split() function** can be used to split an RGB image into its component channels:
Once the color channels are separated, they can be manipulated individually, or combined back into a single image by merging the channels. The merge() function in OpenCV can be used to merge the channels back into an RGB image:
Manipulating Color Pixels
Color pixels in a computer vision image can be manipulated by changing their intensity values. This can be done by adding or subtracting values from the pixel's color channels, which can change the overall color of the pixel. For example, to increase the intensity of the red channel in an image, the value of the red channel in each pixel can be increased.
Color pixel manipulation is changing the color of individual pixels in an image. This can be done by modifying the pixel's intensity values in its color channels. For example, to increase the intensity of the red channel in an image, the value of the red channel in each pixel can be increased. This can be done using the add() function in OpenCV:
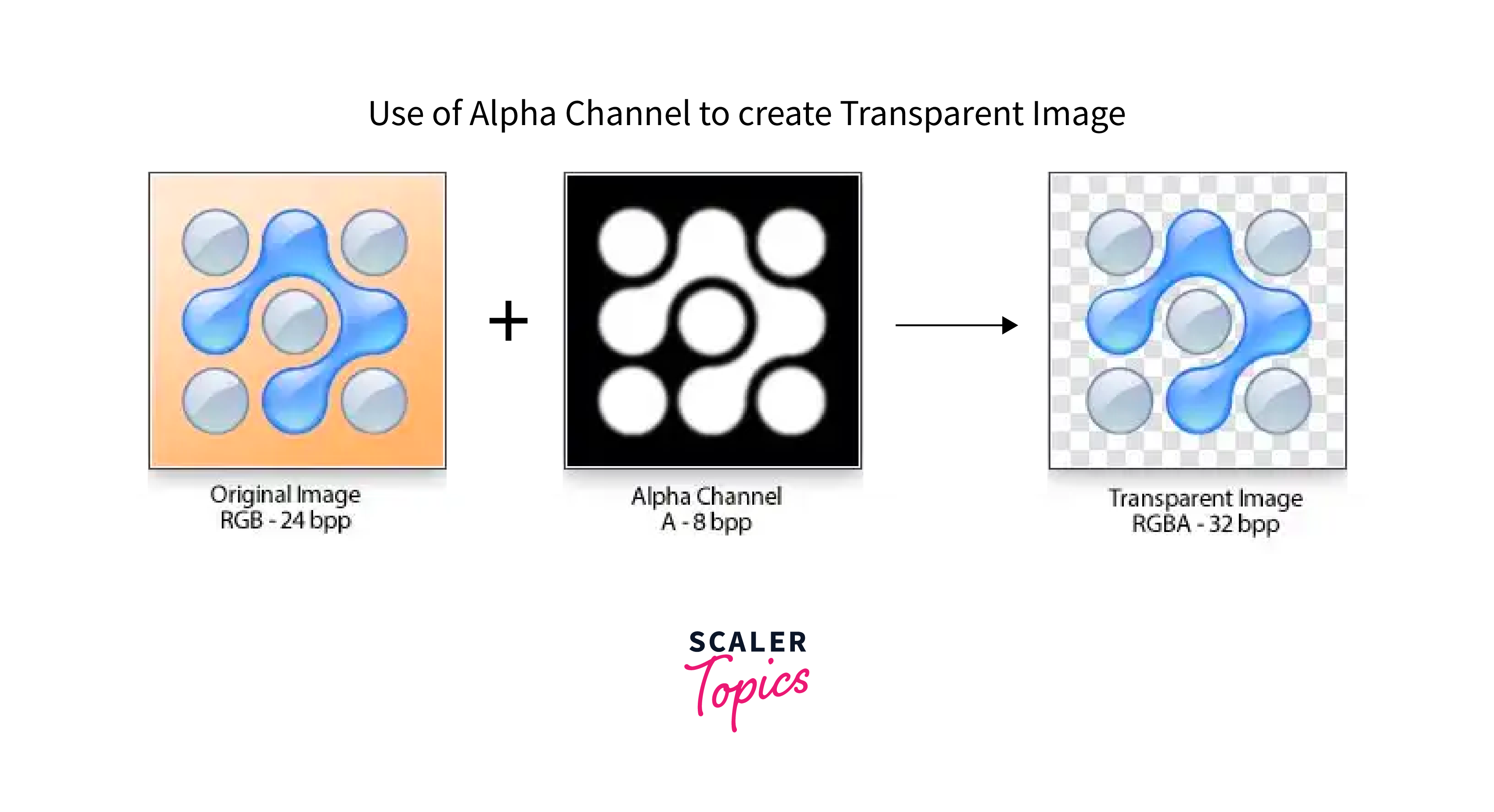
Images with Alpha Channel
Some images have an alpha channel, representing transparency information for each pixel in the image. The alpha channel value ranges from 0 to 255.
Images with alpha channels are often used in graphic design and web development to create images with transparent backgrounds. In computer vision, alpha channels can mask parts of an image or blend multiple images. Image processing libraries such as OpenCV and Pillow support working with images that have alpha channels.
Images with alpha channels have an additional channel that represents the transparency of each pixel. The alpha channel is an 8-bit channel, where a value of 0 represents a fully transparent pixel and a value of 255 represents a fully opaque pixel.
Computer vision images with alpha channels are commonly used in graphic design and web development to create images with transparent backgrounds or to overlay multiple images. In OpenCV, images with alpha channels can be loaded and processed using the IMREAD_UNCHANGED flag:
Once the alpha channel is extracted, it can mask parts of a computer vision image or blend multiple images using techniques such as alpha blending.
Conclusion
- In conclusion, computer vision images involve working with digital images, which are represented as matrices of pixel values.
- Images can be split into color channels, allowing us to work with individual colors in an image.
- Color pixels in an image can be manipulated by changing their intensity values, and images can also have an alpha channel, representing transparency information for each pixel.
- Understanding these concepts is essential for various computer vision tasks, such as object detection, segmentation, and image enhancement.
- Computer vision images are used in a variety of applications, such as self-driving cars, medical imaging, and robotics.
- With the advent of deep learning, computer vision has seen significant advancements in recent years, enabling machines to recognize and interpret images with human-like accuracy.