CQRS - Command Query Responsibility Segregation
Overview
Command and Query Responsibility Segregation Pattern, also known as CQRS Design Pattern promotes the ideology of using 2 different models to update information and read information from a data store. The application is split into 2 parts by the CQRS design pattern, i.e, the Command Side and the Query Side. The command side is responsible for handling the data modification requests like Create, Update, and Delete requests. And, the Query side is responsible for handling the data accessing requests like Reading requests.
Introduction to CQRS
In today's modern technical world, billions of people have moved to mobile banking, e-commerce, online bookings, etc. A large number of users are simultaneously reading and writing data into the data stores using these applications. It is important to synchronize the data served to the users. This requires new ways to handle the data synchronization before serving it to the users. One such approach is the CQRS Pattern.
The overall idea of the CQRS Design Pattern is that it segregates the Command operations/activities from the Query operations/activities. According to CQRS ideology, a command is any operation that writes data to a data store, whereas a query is any such operation that reads/accesses data from a data store.
When to Use CQRS Pattern
-
CQRS Design Pattern is useful where the data reading / accessing performance has become very slow due to a large number of read and write operations going on simultaneously, which can be due to a lot of load on the database, and/or the network on which the database resides.
-
CQRS Design Pattern is useful when the read and write workloads have different requirements for latency, scaling, and consistency.
-
CQRS pattern is useful when an eventually consistent system is acceptable for the read/access queries.
-
CQRS pattern is useful in the situation when reading data performance needs to be optimized separately from writing data performance, especially if the reading data queries are much more in number than the writing data queries.
-
CQRS Design pattern is useful when the system can evolve from time to time and the system might contain multiple versions of the model.
-
CQRS pattern is useful when the application is complex and the business rule of the application change regularly.
Note: CQRS pattern should be avoided when the application's business logic is simple and there are just simple CRUD operations going on.
How the CQRS Pattern is Implemented
Traditional Design: According to the traditional old way, when pervasive computing was not introduced on a very large scale over the internet, only 1 database was used as the single source of truth for all read and write operations.
NOTE: Pervasive Computing also known as Ubiquitous Computing, means that the computing presence is everywhere now, making it omnipresent. It is due to the recent advancements in the field of computing due to which all devices are interconnected and continuously available to each other by leveraging the internet and wireless resources.
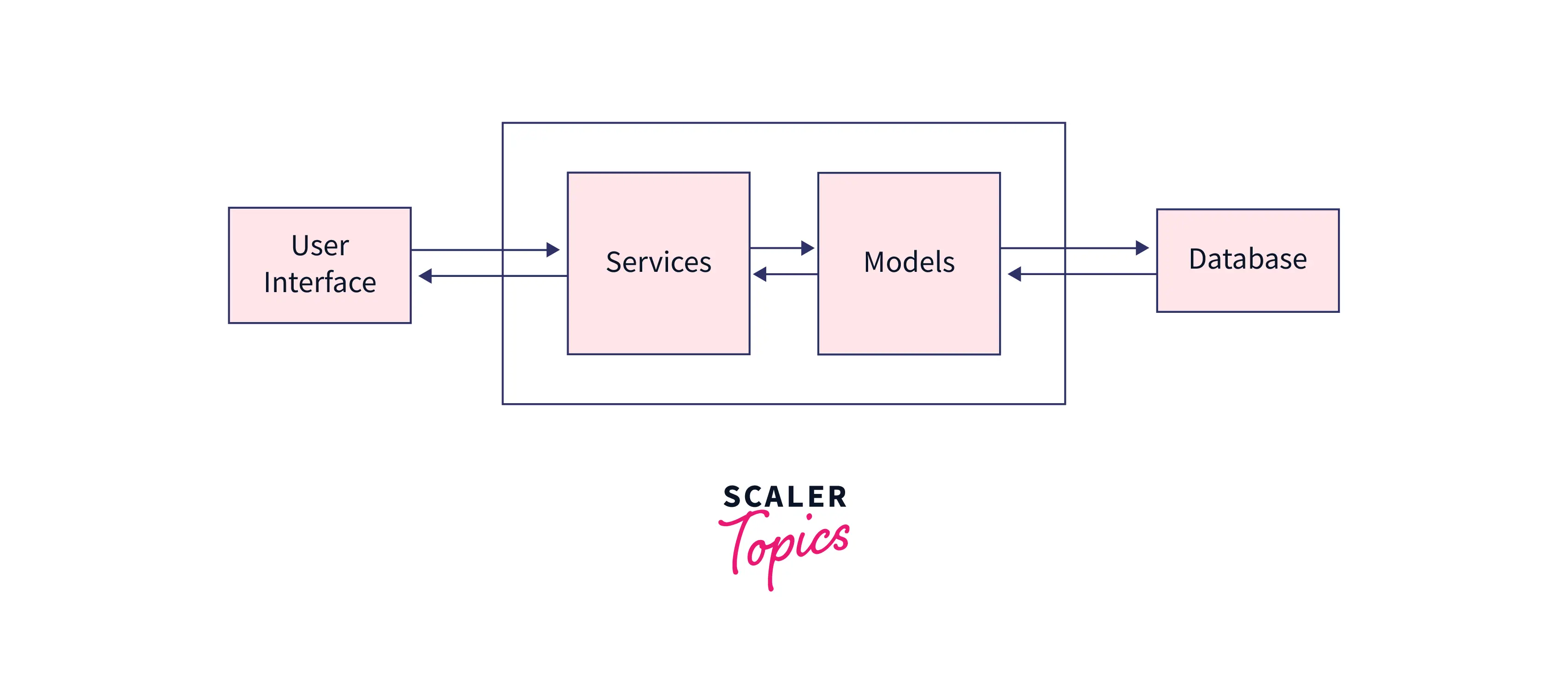
Say, the traffic load on the system has increased drastically, and the latency of the reads and writes is increasing leading to reduced performance. In this case, we can switch from a single database to a database cluster, so all the data read / access queries can be spread across the cluster to get served. But, still, there is a risk of high latency when the traffic is further increased due to the bottleneck around the access point to the cluster, because all the read and write queries will be going to the same target cluster.
CQRS Design: CQRS Design pattern brings the advantage of segregating read (as queries) and write (as commands) operational paradigms physically and logically. Logically, it separates the services and models, whereas physically it separates the actual physical databases as well.
Note: One of the major benefits that come along with distributing the read and write loads in 2 separate directions, is that now each of the read and write database technology can be chosen differently as whichever fits best to the needs. For example, a relational database like MySQL or PostgreSQL can be used for the command operations, and the query operations for web applications can be handled using a NoSQL DB like Mongo or Dynamo DB.
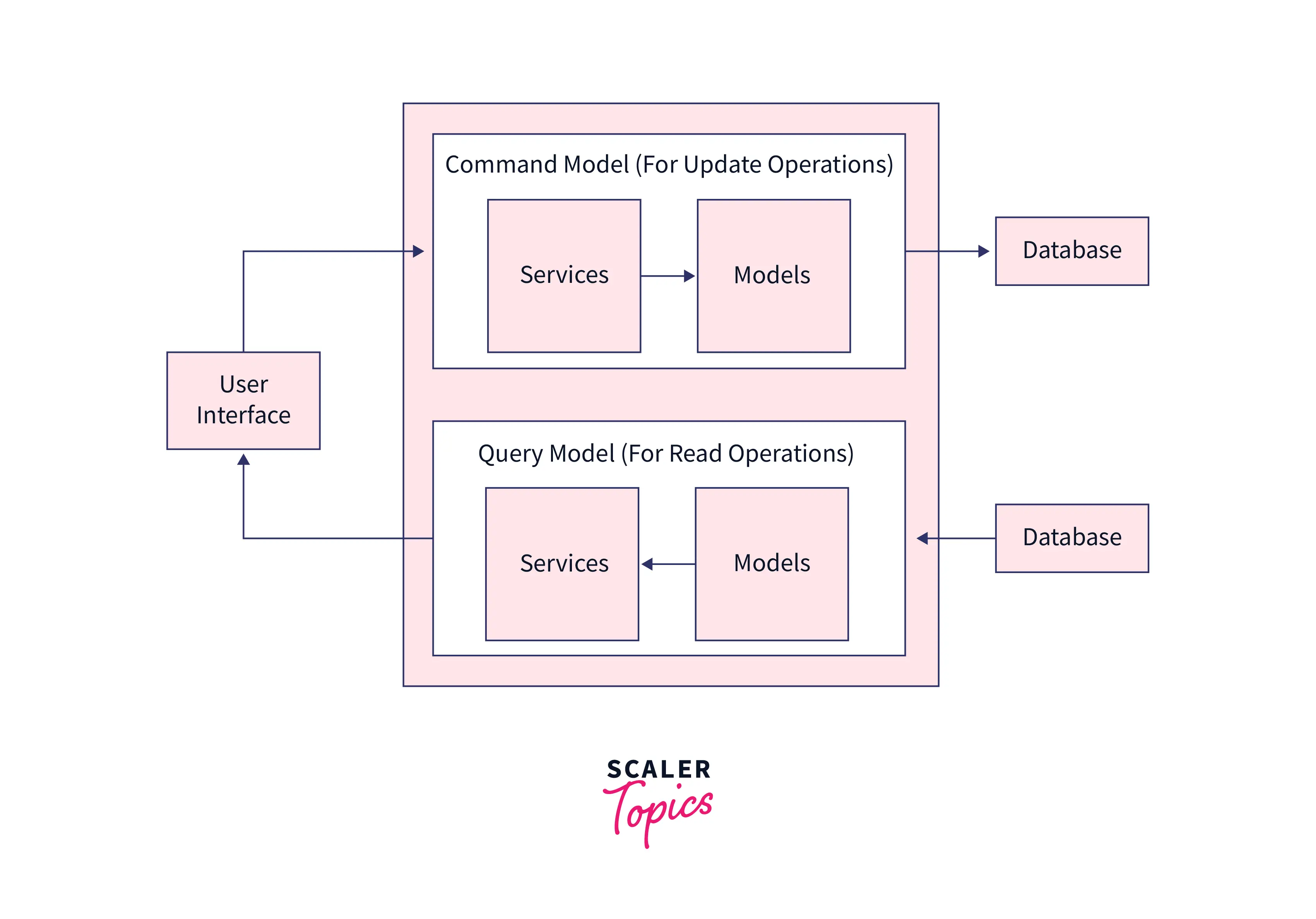
Also, one critical point to be noted is that when we use 2 different databases for commands and queries, we need to deal with the synchronization task, which in itself is a big challenge.
Example of CQRS Pattern
Say, for example, we have a House Renting Application, where any user across the web can place an advertisement for their developed House Property for Rent. Note, for simplicity as per our use case, we can consider that a house either be rented completely or not rented at all. There is no possibility to rent a particular floor or rent only some specific room(s). Every user has the option to add a new House to our application, and every user has the feature to view/get all the houses present in our application.
Diagram of CQRS Pattern Working
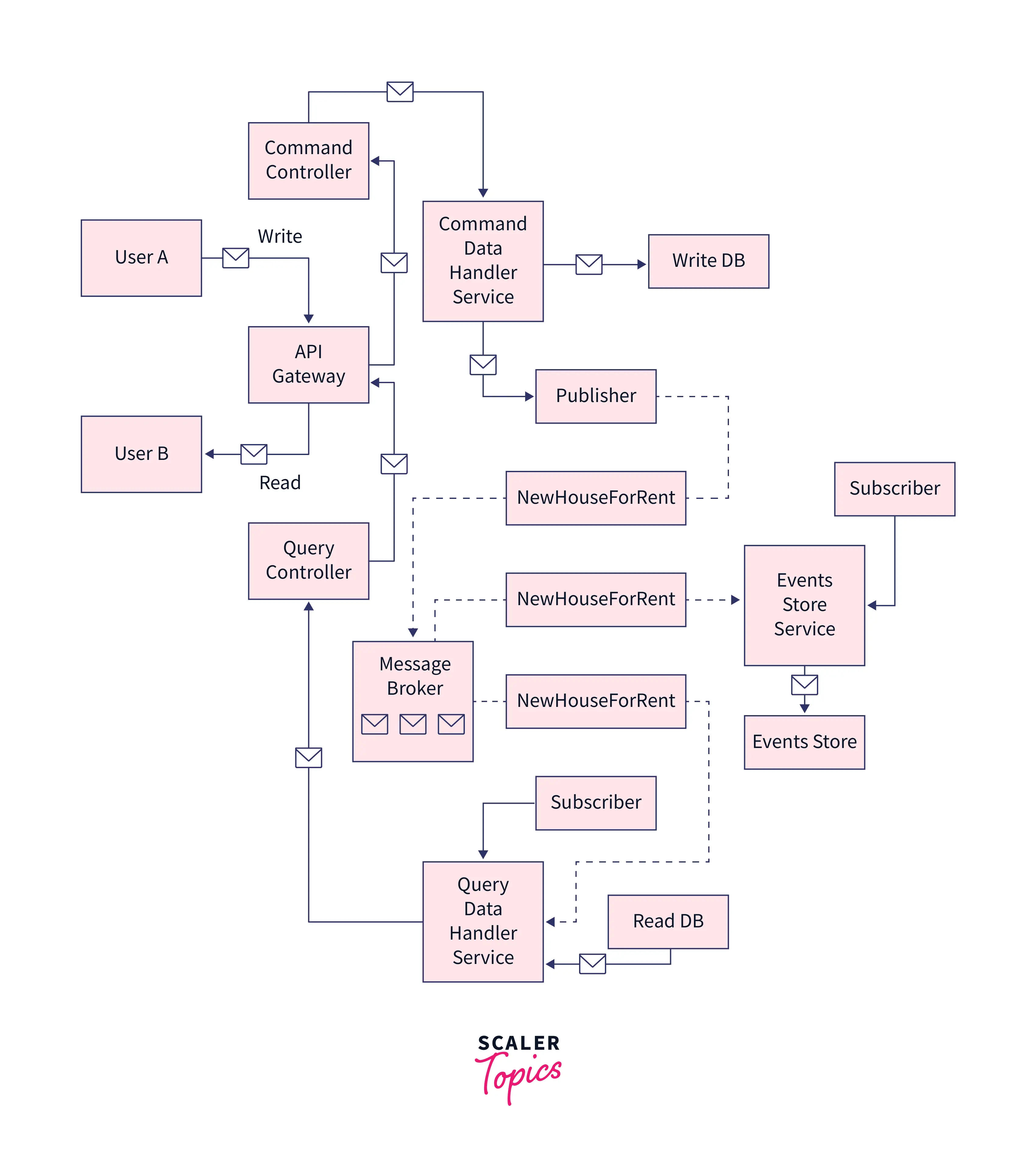
Explanation: In the above diagram, there are 2 different users A and B. User A makes a write query to add a new house to the application and User B makes a read query to view/get all the houses that are present in the application. When User A adds a new house, it gets added to the Write DB, and simultaneously, the new house information is also published to a Messaging Queue, so that it can be consumed by Query Data Handler Service, which is a Subscriber of the Queue Topic NewHouseForRent. The message after being received by the Query Service is written to the Read Database, so that the next time, this gets served to all the read requests, which in our case is User B, as of now. Also, this message has been logged to the Events Store Database using the Events Store Service which is also a Subscriber of the Queue Topic NewHouseForRent.
Challenges of CQRS
- Increases Complexity: Although the core idea of dividing the system into 2 parts of Commands and Queries is simple, for most of the systems it can add huge complexity, and especially when event sourcing comes into the picture, the complexity further increases highly.
- Conversion of an online running system to CQRS is in itself a challenge.
- Data Synchronization: When we follow the CQRS pattern to segregate read and write storages, it grants a high level of flexibility, performance, and efficiency to our system which helps us to deal with a large number of read and write requests simultaneously at a big web-scale, but the implementation of this pattern brings along with it a Data Synchronization challenge at its core. Synchronizing the reading and writing Databases is a big challenge in itself.
- Data Consistency: Since in CQRS, we separate the read and write databases to handle commands and queries differently, the read data can become outdated after some time. It will be hard to detect when some user(s) have been served outdated data. So one of the main challenges to dealing with CQRS is Eventual Data Consistency.
- Application should be able to handle failures during synchronization.
Implementation Issues and Considerations
There can be 2 ways by which we could have achieved Data Synchronization in our application.
- Update the Read Database simultaneously when a write command is executed:
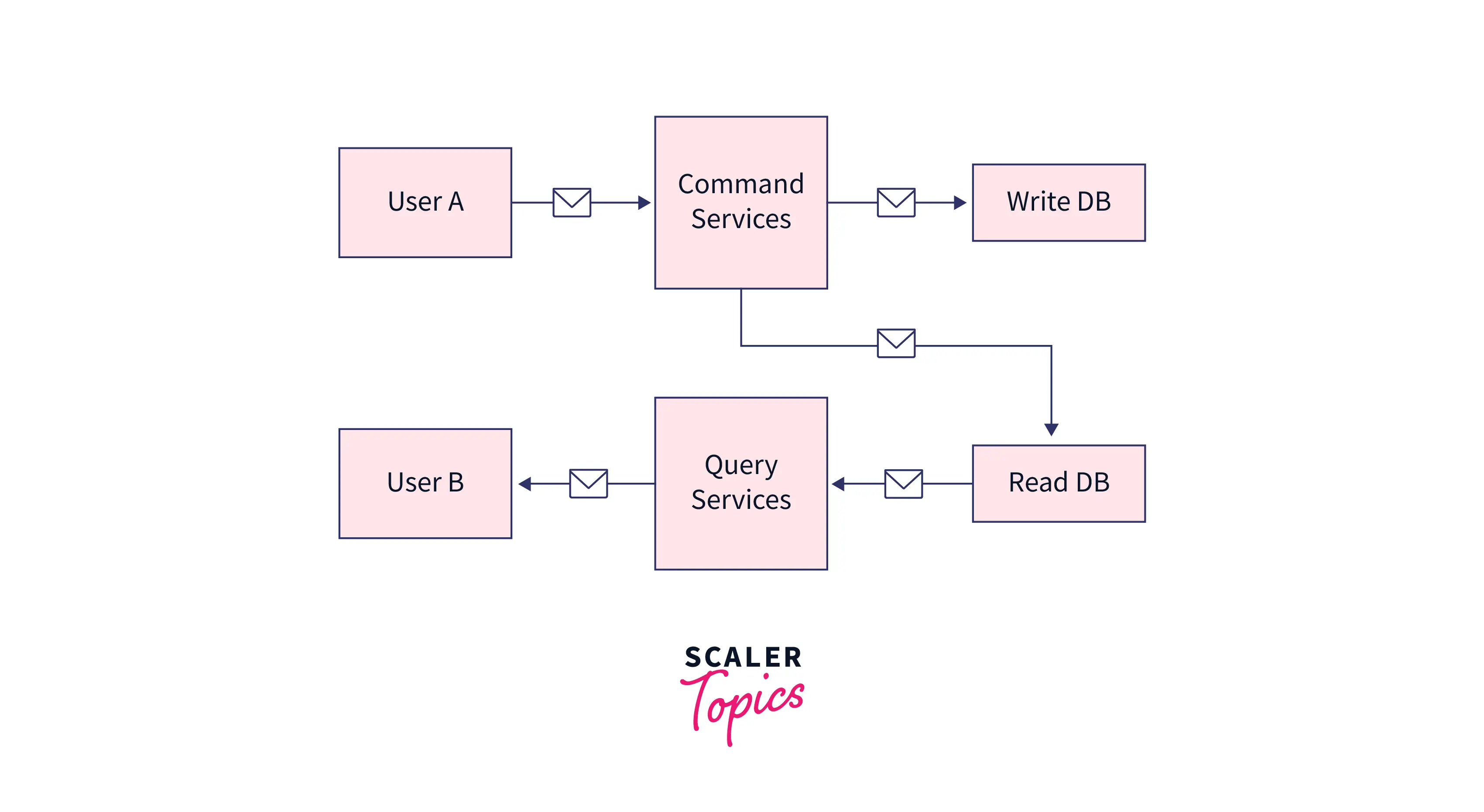
Explanation: Here, User A makes a write query. This query goes to the command service, and the command service has 2 tasks, first is to put this data in the write database, and then write this data in the read database as well. User B makes a read query, which gets served by the Read Database with the help of the Query Service.
- Update the Read Database when an event is received from an Event Bus like Kafka:
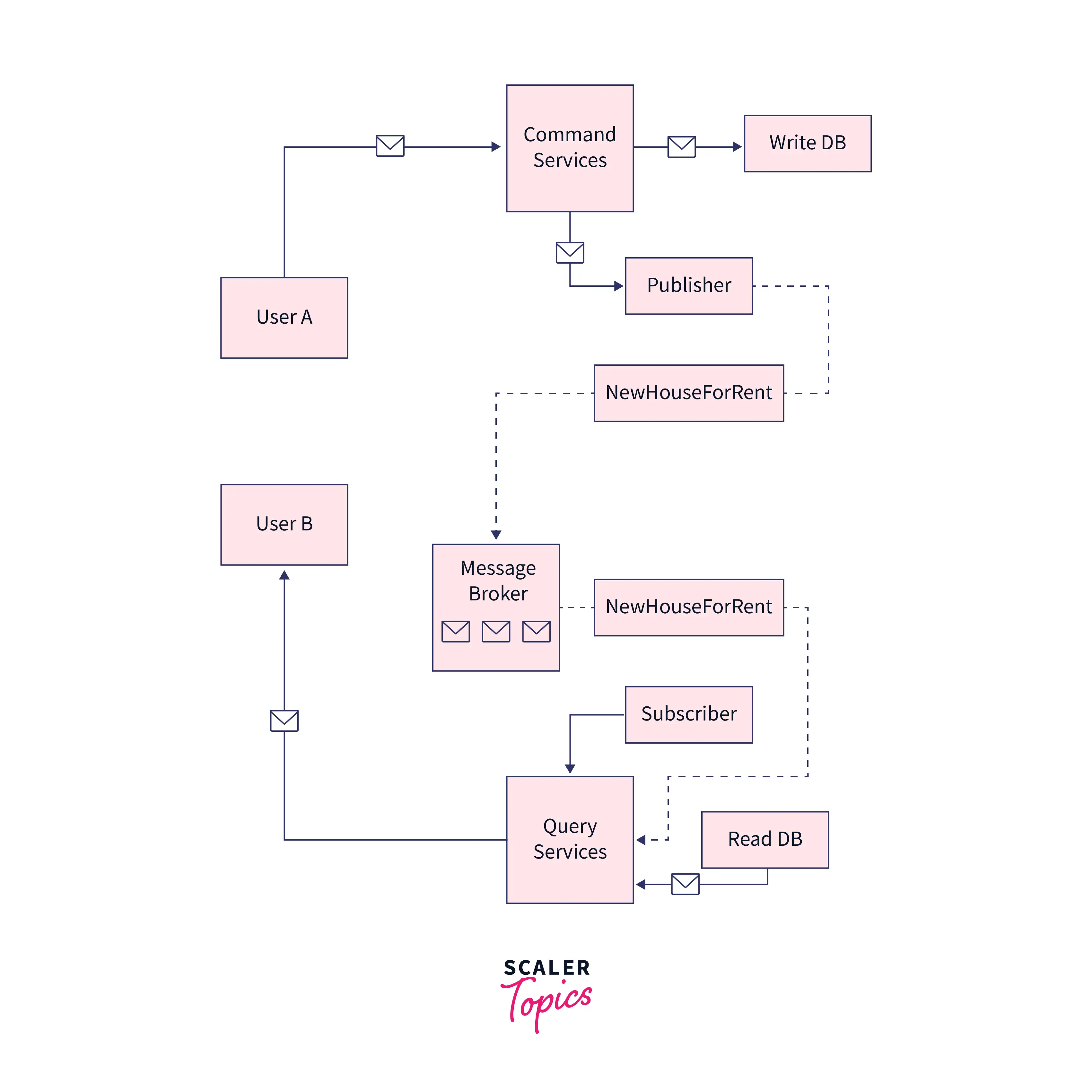
Explanation: Here, User A makes a write query to the command service. Command service has 2 tasks to fulfill, i.e, make a write to the Write Database, and also publish a message into the queue to the Topic named as NewHouseForRent, so that this message is picked by the respective subscribers, which in this case is Query Service. After getting this message, the query service makes a written request to the Read Database, so that the information gets synchronized between the Read and the Write Database. User B makes a read query to the Query Service, which gets served the synchronized Read Database.
Important Point to Note: An Event Bus System should be used because an event bus like Kafka stores the events/messages, which can be sent again to the respective subscribers, in case their purpose was not fulfilled by the subscriber due to some network communication failure or any other issue.
But if we want to store all the events in a data store for a very long time so that in case of any failure of read or write databases, the same database state can be regenerated using the events stored in the data store, then we will have to use Event Sourcing.
CQRS and Event Sourcing
Event sourcing is a strategy in which we store all the events in a datastore so that in the future when read and write databases get out of sync or the data source gets destroyed, then replaying those event logs again, can help us regenerate the database(s) state.
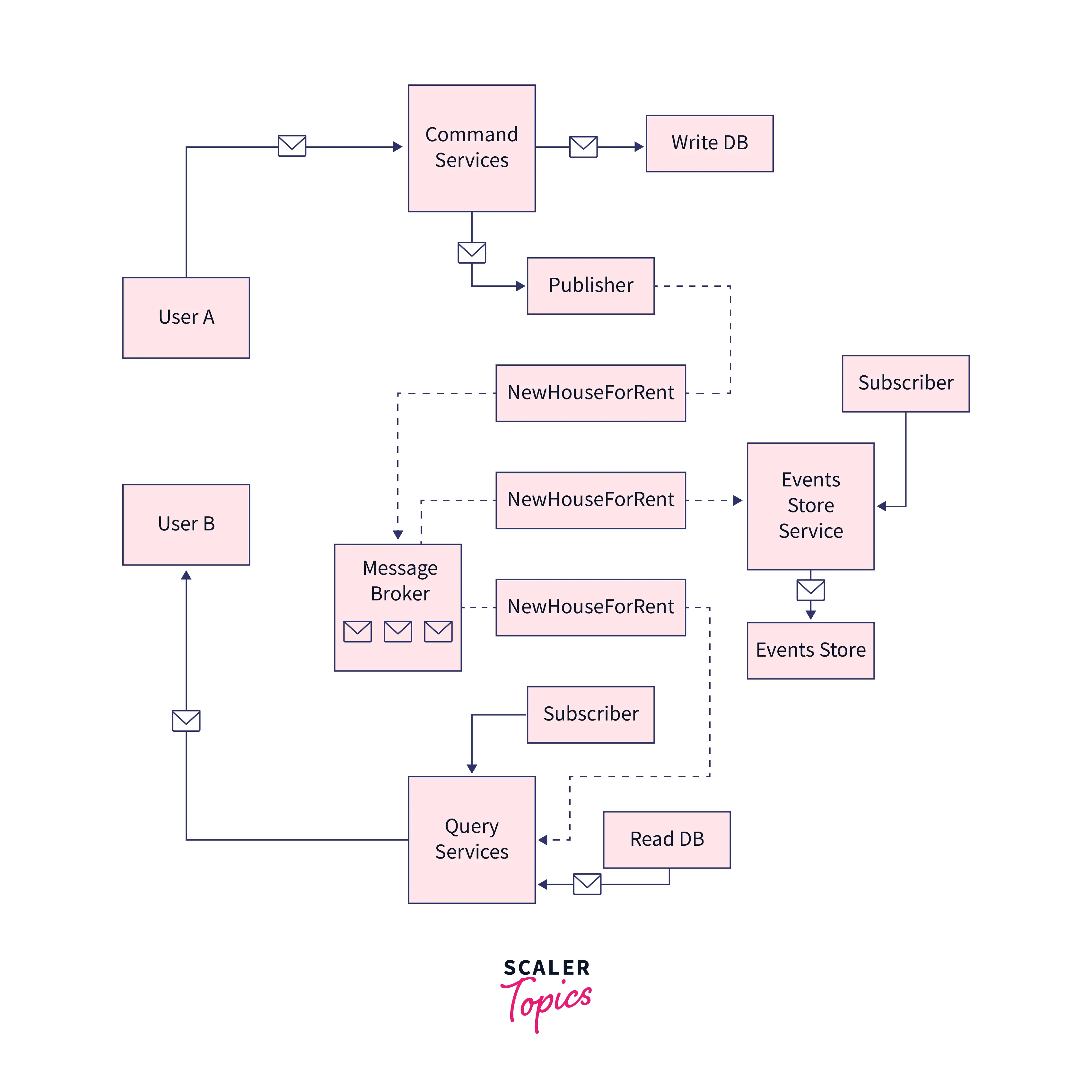
Explanation: As mentioned earlier, User A also makes a write rewritten which updates the Write Database and publishes a message in the queue on the topic NewHouseForRent, consumed by the respective subscribers, which in this case are Query Service and Events Store Service. We already know that Query Service on receiving the message makes a written request to the Read Database to synchronize it with Write Database. But the new thing that is present in this scenario is the Events Store Service which is also a Subscriber to the Topic NewHouseForRent. Events Store Service logs this message into the Events Store, a data store for all the logs. The main reason why these logs are stored is that in case the read or write database gets destroyed or corrupted in the future, then they can be rebuilt again using these logs.
What are Some Related Patterns?
- The Database Per Service Pattern creates the necessity for CQRS Design Pattern because the databases attached to different microservices need to be aligned to each other using the latest data to follow data synchronization.
- CQRS Design Pattern is often used with Event Sourcing Pattern because event sourcing can be helpful in situations where databases are destroyed or crashed or have become out of sync.
- CQRS uses Domain Event Pattern to generate its events.
Conclusion
- CQRS Design Pattern splits the application Logically as well as Physically into 2 Parts: Command Model and Query Model.
- CQRS Pattern promotes separation of concerns
- CQRS pattern works better with Event Sourcing, so that outage conditions in the future can be dealt with.
- CQRS Pattern increases the complexity of the system and has a major challenge of Eventual Consistency.
Expand your design horizons with our Instagram System Design course, enabling you to craft elegant and efficient designs.