What is Data Cleaning in Data Mining?
What is Data Cleaning in Data Mining?
Data cleaning, also known as data cleansing, is the process of identifying and correcting or removing inaccurate, incomplete, irrelevant, or inconsistent data in a dataset. Data cleaning is a critical step in data mining as it ensures that the data is accurate, complete, and consistent, improving the quality of analysis and insights obtained from the data. Data cleaning may involve tasks such as removing duplicates, filling in missing values, handling outliers, correcting spelling errors, resolving inconsistencies in the data, etc. Data cleaning helps to minimize the impact of data errors on the results of data mining analysis.
Data Cleaning Characteristics
Some key characteristics of data cleaning are -
- Iterative process - Data cleaning in data mining is an iterative process that involves multiple iterations of identifying, assessing, and addressing data quality issues. It is often an ongoing activity throughout the data mining process, as new insights and patterns may prompt the need for further data cleaning.
- Time-consuming - Data cleaning in data mining can be a time-consuming task, especially when dealing with large and complex datasets. It requires careful examination of the data, identifying errors or inconsistencies, and implementing appropriate corrections or treatments. The time required for data cleaning can vary based on the complexity of the dataset and the extent of the data quality issues.
- Domain expertise - Data cleaning in data mining often requires domain expertise, as understanding the context and characteristics of the data is crucial for effective cleaning. Domain experts possess the necessary knowledge about the data and can make informed decisions about handling missing values, outliers, or inconsistencies based on their understanding of the subject matter.
- Impact on analysis - Data cleaning in data mining directly impacts the quality and reliability of the analysis and results obtained from data mining. Neglecting data cleaning can lead to biased or inaccurate outcomes, misleading patterns, and unreliable insights. By performing thorough data cleaning, analysts can ensure that the data used for analysis is accurate, consistent, and representative of the real-world scenario.
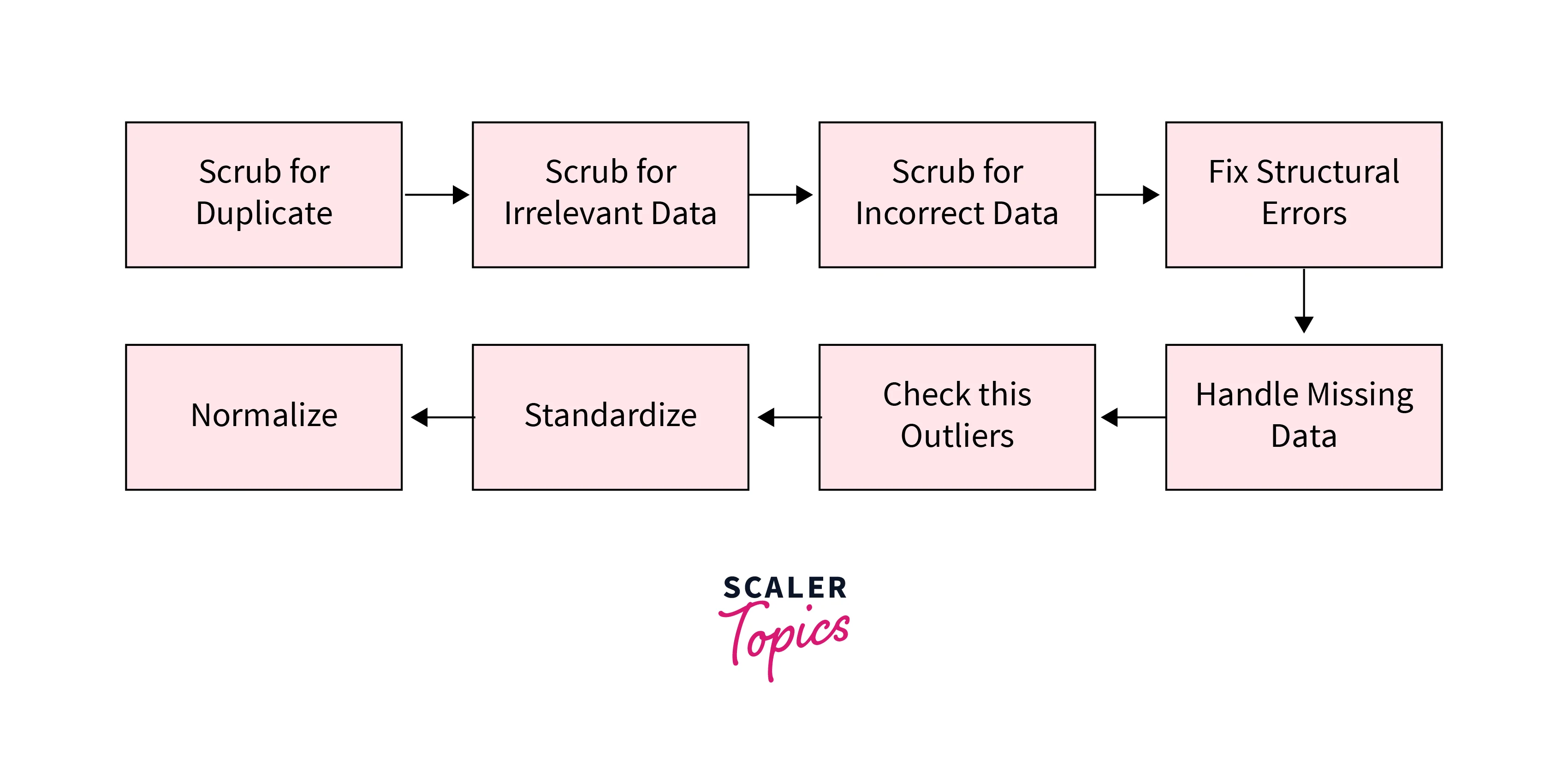
Steps of Data Cleaning
The steps involved in the process of data cleaning in data mining can vary depending on the specific dataset and the requirements of the analysis, but some common steps are -
- Data profiling - Data profiling involves examining the dataset to gain an understanding of its structure, contents, and quality. It helps identify data types, distributions, missing values, outliers, and potential issues that need to be addressed during the cleaning process.
- Handling missing data - Missing data refers to instances where values are not recorded or are incomplete. Data cleaning involves deciding how to handle missing data, including imputing missing values using statistical methods, removing instances with missing values, or using specialized techniques based on domain knowledge.
- Handling duplicates - Duplicate records occur when the dataset has identical or very similar instances. Data cleaning involves identifying and removing duplicate records to ensure data integrity and prevent bias in the analysis.
- Handling outliers - Outliers are data points that are significantly different from other data points in the dataset. Therefore, identifying and handling outliers can be important for maintaining the integrity of the analysis. Outliers can be detected using statistical methods such as Z-score or box plot analysis and removed or adjusted as necessary.
- Standardization - Standardization aims to ensure consistent and uniform representation of data attributes. It involves addressing inconsistencies in data formatting, units of measurement, or categorical values. Data cleaning includes standardizing attributes to a standard format to facilitate accurate analysis and interpretation.
- Resolving inconsistencies - Inconsistencies can arise from data entry errors, variations in naming conventions, or conflicting information. Data cleaning involves identifying and resolving such inconsistencies by cross-validating data from different sources, performing data validation checks, and leveraging domain expertise to determine the most accurate values or resolve conflicts.
- Quality assurance - Quality assurance is the final step in data cleaning. It involves performing checks to ensure the accuracy, completeness, and reliability of the cleaned dataset. This includes validating the cleaned data against predefined criteria, verifying the effectiveness of data cleaning techniques, and conducting quality control measures to ensure the data is suitable for analysis.
Benefits of Data Cleaning in Data Mining
Data cleaning plays a crucial role in data mining and has many benefits, as mentioned below -
- Improving data quality - Data cleaning in data mining enhances the quality of the dataset by addressing issues such as missing values, duplicates, outliers, and inconsistencies. By removing or resolving these data quality problems, the dataset becomes more reliable, consistent, and suitable for analysis.
- Enhancing data accuracy - Data cleaning in data mining ensures that the data used for analysis is accurate and representative of the real-world scenario. By handling missing data, correcting errors, and standardizing formats, data cleaning helps improve the accuracy of data attributes, reducing the likelihood of biased or misleading analysis.
- Increasing the reliability of analysis results - Cleaned data leads to more reliable analysis results. By eliminating errors and inconsistencies, data cleaning minimizes the impact of data quality issues on the outcomes of data mining algorithms and techniques. This increases the confidence and trustworthiness of the insights and patterns discovered through data mining.
- ML model training - Machine learning models rely heavily on high-quality training data. Data cleaning plays a crucial role in preparing the data for model training by ensuring the dataset is free from noise, outliers, and inconsistencies. Cleaned data helps improve the accuracy and effectiveness of machine learning models, leading to more reliable predictions and decision-making. For example, if missing values are not handled, many ML model algorithms will throw an error during the training phase as they can’t handle missing values inherently.
- Improving decision-making - Data cleaning in data mining is especially valuable when integrating data from multiple sources. By standardizing formats, resolving inconsistencies, and handling missing values, data cleaning facilitates the integration of diverse datasets. This enables analysts to perform comprehensive analysis and derive insights from combined data sources.
Data Cleaning Tools in Data Mining
Many data cleaning tools are available for data mining, and the choice of tool depends on the type of data being cleaned and the user's specific requirements. Some popular data cleaning tools used in data mining include -
- OpenRefine - OpenRefine is a free and open-source data cleaning tool that can be used for data exploration, cleaning, and transformation. It supports various data formats, including CSV, Excel, and JSON.
- Trifacta Wrangler - Trifacta is a data cleaning tool that uses machine learning algorithms to identify and clean data errors, inconsistencies, and missing values. It is designed for large-scale data cleaning and can handle various data formats.
- Talend - Talend is an open-source data integration and cleaning tool that can be used for data profiling, cleaning, and transformation. It supports various data formats and can be integrated with other tools and platforms.
- TIBCO Clarity - TIBCO Clarity is a data quality management tool that provides a unified view of an organization's data assets. It includes features such as data profiling, data cleaning, and data matching to ensure data quality across the organization.
- Cloudingo - Cloudingo is a data cleansing tool specifically designed for Salesforce data. It includes features like duplicate detection and merging, data standardization, and data enrichment to ensure high-quality data within Salesforce.
- IBM Infosphere Quality Stage - IBM Infosphere Quality Stage is a data quality management tool that includes features such as data profiling, data cleansing, and data matching. It also includes advanced features such as survivorship and data lineage to ensure data quality and governance across the organization.
Conclusion
- Data cleaning is a crucial process in data mining and analysis that involves identifying and correcting errors, inconsistencies, and missing values in datasets.
- Data cleaning in data mining is a crucial process that improves data quality, enhances accuracy, and increases the reliability of analysis results. It ensures that the data used for mining is accurate, consistent, and representative of the real-world context, leading to more reliable insights and decision-making.
- The characteristics of data cleaning in data mining include its iterative nature, time-consuming aspect, reliance on domain expertise, and its positive impact on the overall analysis. It involves multiple steps such as data profiling, handling missing data, duplicates, and outliers, standardization, resolving inconsistencies, and ensuring quality assurance, all of which contribute to the integrity and effectiveness of the data mining process.
- By improving data quality, organizations can reduce costs, improve efficiency, and drive business success. Therefore, data cleaning is an important step in the data analysis process.