What is Data Consistency in DBMS?

Consistency means having the property of always maintaining the same standards, opinions, and actions. In order to keep the database consistent, data written to the database must be valid according to all defined rules.
Data Consistency in DBMS is defined by a set of rules that ensure that all data points in the database system are correctly read and accepted. This is achieved by making rules. Transactions of data written to the database should only modify the affected data established by rules set by the database developer. It doesn't guarantee that the transaction is correct, it just guarantees that it doesn't violate the rules defined by the program.
Why is Data Consistency in DBMS important?
Database consistency ensures that the data in the database is correct and can be used for decision-making. Inconsistent data in the database can cause system instability and corruption. All users should enter data into the database in a way that always matches what already exists in the database. To achieve this, data fields are forced not to be used in other transactions where data is stored in an isolated manner.
Database consistency is important in DBMS to ensure accuracy, faster and more efficient data retrieval, and more database space.
What Is An Example Of Data Consistency in DBMS?
Consistency in DBMS refers to the requirement that any given database transaction change affects data only in an acceptable manner defined by the rules set by the database’s developer. For example, the column in a database may have only two values true or false. Now, if a user tries to put in any value other than these two, then the consistency rules for the database would not allow it.
Also, you may have experienced this many times that with the help of consistency rules, we can't leave a field on a web page form empty. When a person is filling out a form online and forgets to fill in one of the required spaces, a NULL value automatically goes to the database, causing the form to be rejected until the blank space has something filled in it.
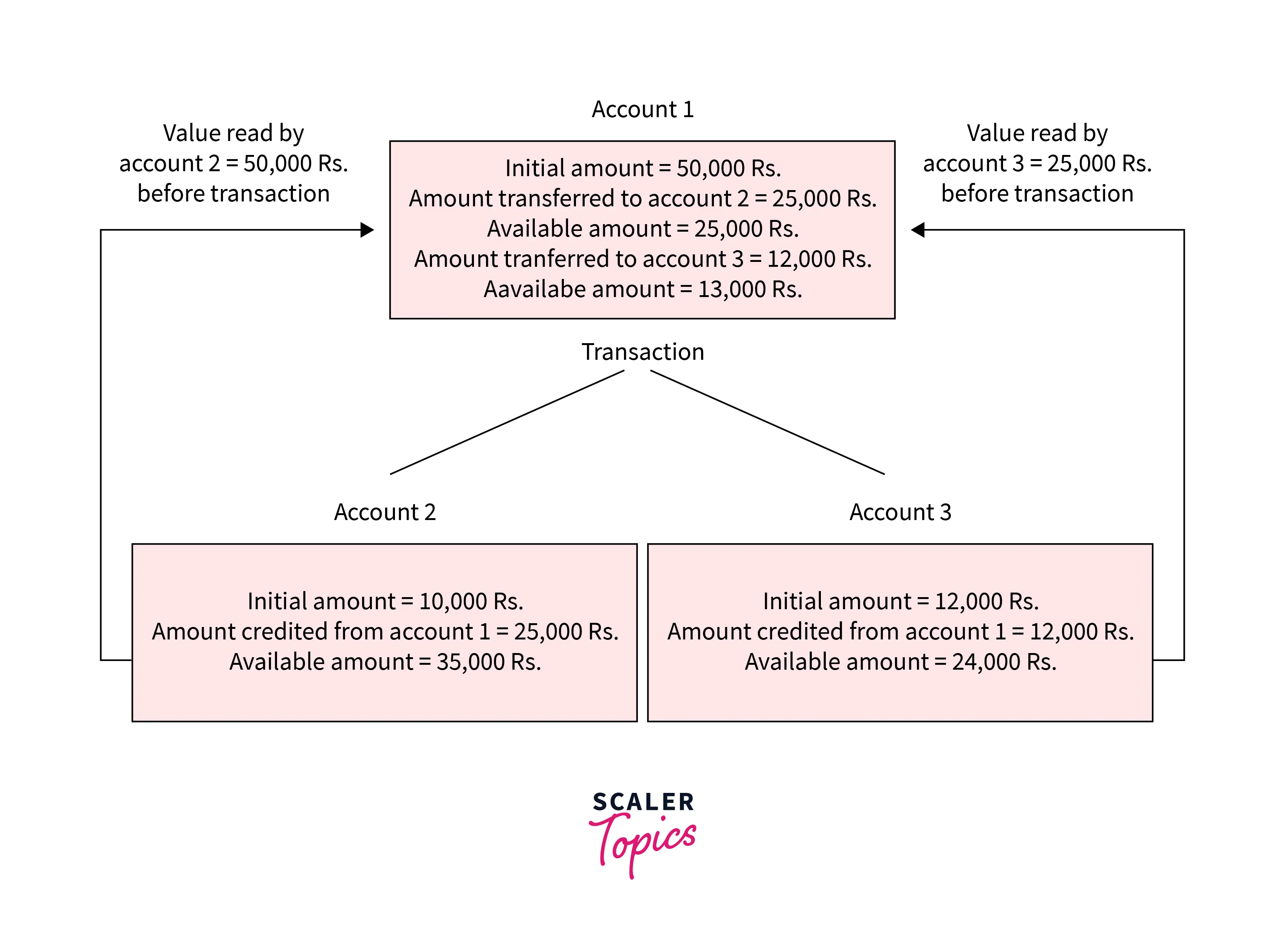
Let's try to understand this in terms of database transactions. Suppose there are three accounts, account 1, account 2, and account 3, and account 1 executes transactions against account 2 and account 3 in sequence. Two operations take place, i.e., Debit and Credit. Account 1 firstly debits 25,000 Rs to Account 2, and the amount in Account 1 is read as 50,000 Rs by Account 2 before the transaction. After the successful transaction, the available amount in 2 becomes 35,000 Rs. Now, account 1 debits 12,000 Rs to account 3, and at that time, the value read by account 3 is 25,000 Rs (this value read by account 3 is fine is correct as a debit of 25,000 Rs has been successfully done to account 2). The debit and credit operation from accounts 1 to account 3 has been done successfully.
You can see that the transaction ran successfully, and the values were read correctly. So, the data is consistent. If the value read from B and C is $300, it means that the data is inconsistent because when the debit operation executes, it will not remain consistent.
Consistency Levels
The consistency level defines how many replicas or nodes must respond with new valid data before it is recognized as a valid transaction. This operation can change from transaction to transaction.
For example, a programmer can specify that he needs to read newly entered data from only two nodes before checking the data for consistency. Beyond this barometer, consistent data is considered from then on. Based on the number of nodes to update, there are three levels of consistency:
- ONE: In this level, successfully writing an update to any node is sufficient, and then the system will eventually replicate it to other nodes.
- QUORUM: In this level, a majority of replicas need to acknowledge an update, and this is based on the replication factor.
- ALL: In this level, all the replicas must acknowledge an update.
Strong Consistency and Weak Consistency
Strong consistency means that all data on the primary node, replicas, and all related nodes adhere to validation rules and are always in the same state. Strong database integrity ensures that it doesn't matter which client accesses your data. Clients always see the latest updated data that conforms to the rules set in the database. With strong consistency, there is only one copy of the database, it continuously reflects each forward state transition along with the operation, giving the user a clear picture of the database. Therefore, end users are unaware of the replication of a given database in case of strong consistency.
Weak consistency does not guarantee that data is always the same on primary, replica, or node. For example, customers in India can access the data and view information that meets the validation rules, but may not be the latest updated data, resulting in integrity errors. Even if it is temporarily relevant, it most likely corresponds to the information that is no longer relevant. It is also easy to see that the data between nodes will eventually reach a consistent state after a certain amount of time.
In weak consistency, there's no guarantee that all nodes will always have the same data, and there are many different implementations. Weak consistency forces developers to adapt to the replicated nature of the data in the database, resulting in increased development complexity compared to strong consistency. Therefore, application developers must be explicitly aware of the replicated nature of data items in the database.
Isolation levels
The term isolation means separation. In DBMS, this is one of the ACID properties of databases, meaning that data that affects other data cannot occur at the same time. Consistency must be maintained for transactions where two or more transactions occur at the same time so that the changes that occur in one transaction are not visible to other transactions until the changes are committed to memory.
If two operations involving a transaction are performed concurrently in two different accounts, the values in both accounts are not affected. The value should remain persistent.
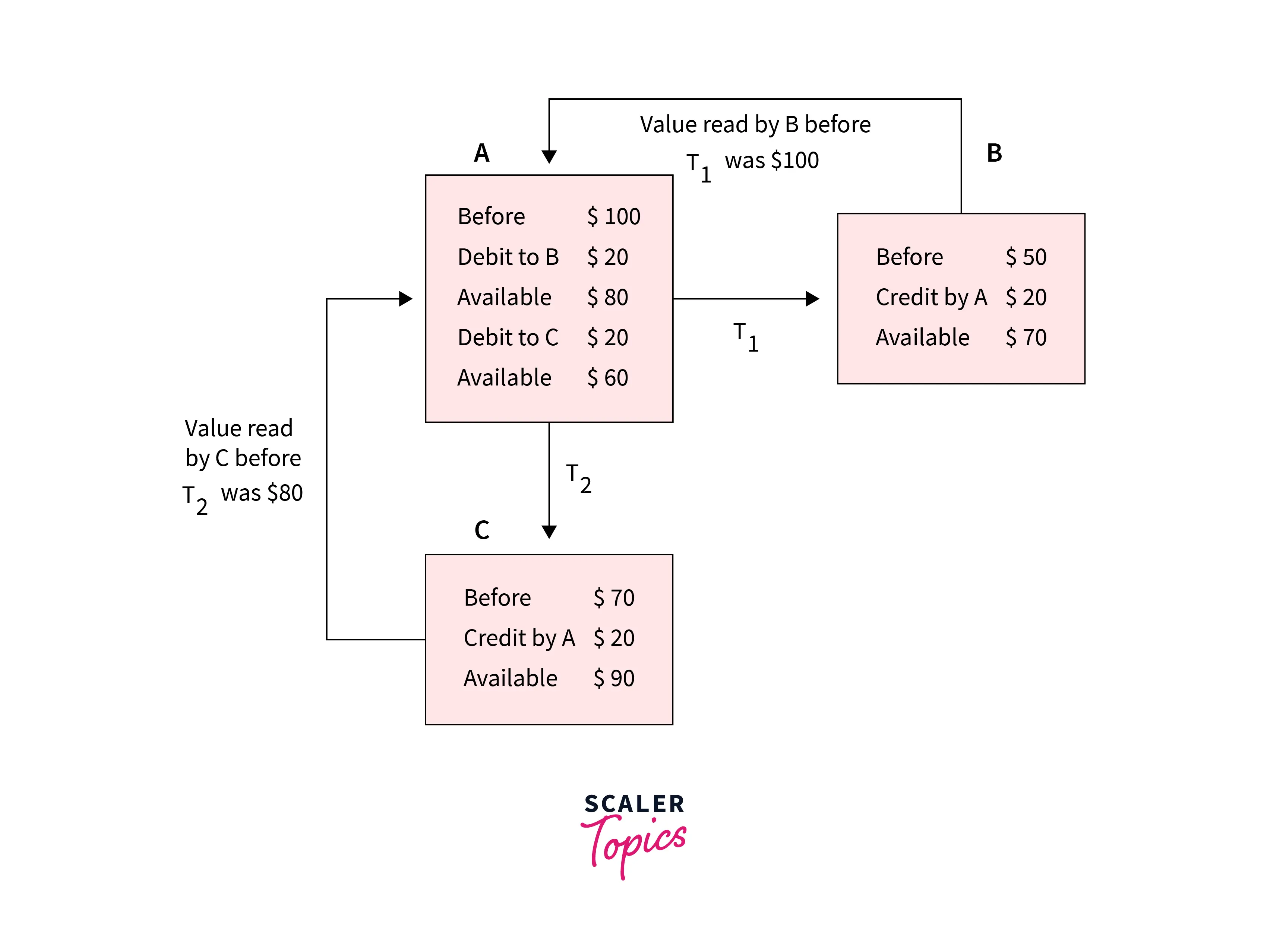
For example here, account A is making T1 and T2 transactions to accounts B and C, but both are executing independently without affecting each other. It is known as Isolation.
It is important to avoid generating extraneous data during concurrent transactions. There are four levels of inconsistency in DBMS:
-
Read Uncommitted: It is the lowest level of isolation and it stops row updates if a previous transaction provided an uncommitted update to that row.
-
Read Committed: Dirty reads are not allowed at this isolation level. This means that read or write operations will be blocked if the transaction has already been updated but is still committed.
-
Repeatable Read: This isolation level prevents read rows of data from being accessed and possibly updated.
-
Serializable: Serializable is the highest isolation level that locks entire tables rather than specific rows of data.
Data Consistency Vs Data Integrity
| Data Integrity | Data Consistency |
|---|---|
| Data integrity refers to the quality of the data. This is the state of accurate and complete data. | Data consistency refers to the usefulness of the data. Data Consistency in DBMS is the state of data that is consistent across all systems. |
| Integrity ensures that the data is correct. | Consistency ensures that the data format is correct, or that the data is correct with respect to other data. |
| Data integrity mainly focuses on data quality | But in data consistency, the data may be completely consistent and at the same time it may be completely wrong. |
| For example: If you have the employees table and departments table and department_id column in both of them. There are no employees who work in departments that do not exist in the department table. This is enforced by referential integrity constraints. | For example There are no dates, numbers, or letters in the same column, but only one of them as defined by the rules of consistency. This is enforced by defining the type of column. The column ID number (3) means it does not contain any data, letters, or numbers greater than 999. |
How does the ACID Model Compare With the BASE Model?
The main difference between the ACID (Atomicity, Consistency, Isolation, Durability) model and the BASE model (Basically Available, Soft State, Eventually Consistent) is that the ACID model optimizes database consistency, while the BASE model enhances high availability.
The ACID model mainly guarantees consistency among transactions. So if you choose the BASE model, make sure that consistency is your top priority and is addressed thoroughly.
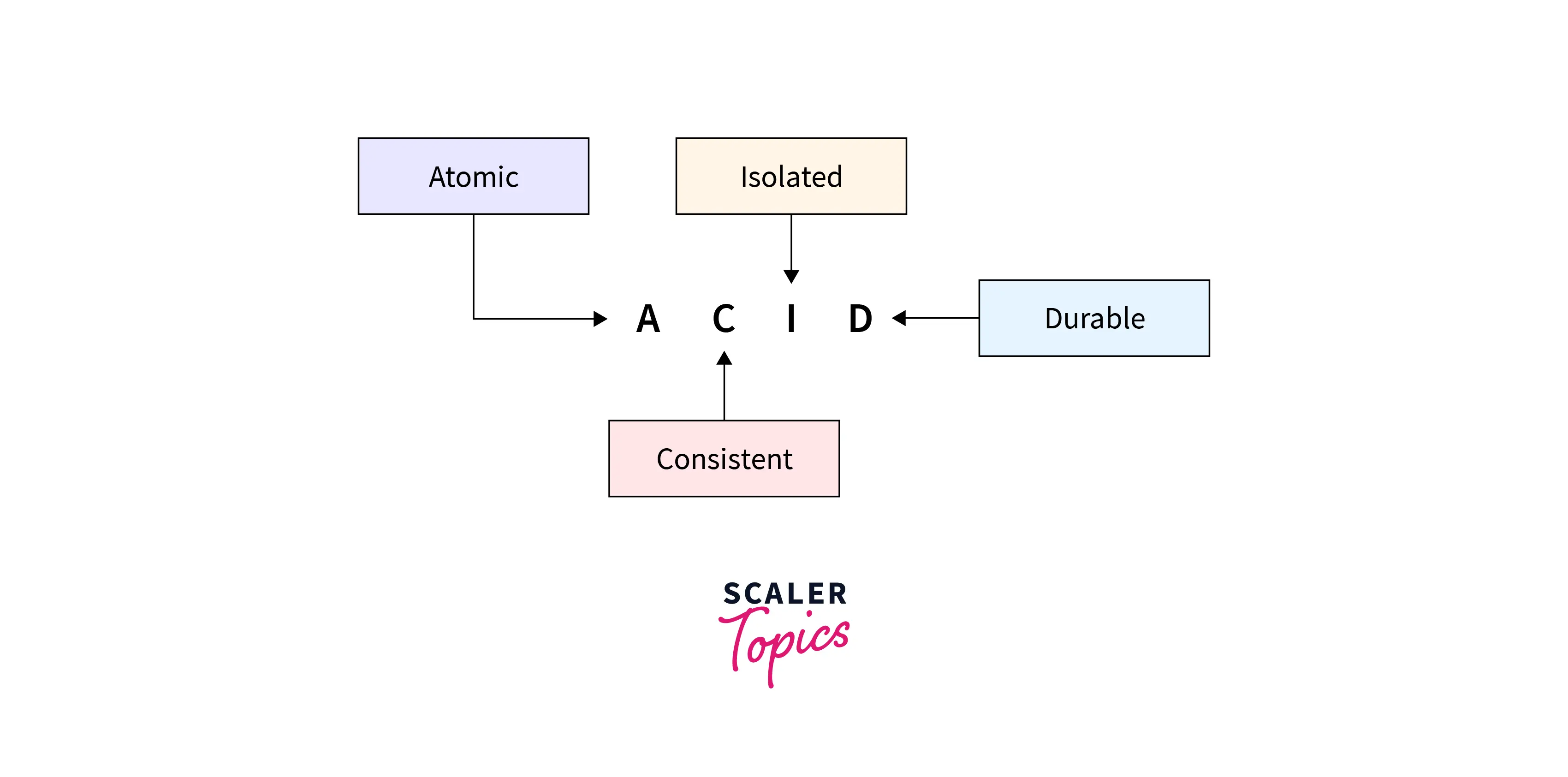
Let's see the ACID model properties in detail:
1. Atomicity:
Atomicity is the term that means that if any operation is performed then it should either get completely performed or it should not be performed at all. In terms of dbms, it refers to the fact that the whole transaction should take place at once or it doesn't happen at all. It means that the operation should not be left in the partial state. Let's understand the importance of atomicity with the help of an example:
Suppose, you have 50,000 Rs in your account (let it be account 1) and you want to transfer 25,000 Rs to someone's account (let it be account 2). In account 2, already there is a sum of 25,000 Rs present. When 25,000 Rs will be transferred from your account (account 1) to their account (account 2, the total amount will become 50,000 Rs for account 2. Now, there will be two transactions taking place at the same time. One is the deduction of 25,000 Rs from account 1 and another is the operation of getting the same amount credited to account 2.
Now, suppose the situation where the first operation of debit executes successfully, but the credit operation, however, fails. So, in this case, the amount in account 1 becomes 25,000 Rs, and the amount in account 2 remains 25,000 only as it was previously present. So, this will cause a huge issue (because of transaction not being atomic) and thus the transaction should always be atomic.
2. Consistency:
Consistency is the property that focus on maintaining the correction and integrity of data. This helps in ensuring that the value should remain preserved always. In terms of DBMS, consistency helps in making the database values consistent before and after the transaction. We have already seen the example of this in the above section to know how much data consistency is important in dbms.
3. Isolation:
This is another property of the ACID model which states that no data should affect the other one and may occur concurrently. In terms of transactions, when two or more transactions occur simultaneously, then any changes that occur in any transaction should not be visible by other transactions until the change is not committed in the memory as that will cause errors and break the database consistency. Isolation works to ensure that multiple transactions can take place at the same time without affecting each other.
4. Durability:
This is a property that ensures the permanency of something. It helps in ensuring that the data after the successful commit will remain permanent in the database. This should also cover the cases where even if the system fails or leads to a crash, the database still survives with the same values.
Therefore, all the different ACID properties of DBMS play a vital role in maintaining the consistency, durability, integrity, and availability of data in the database.
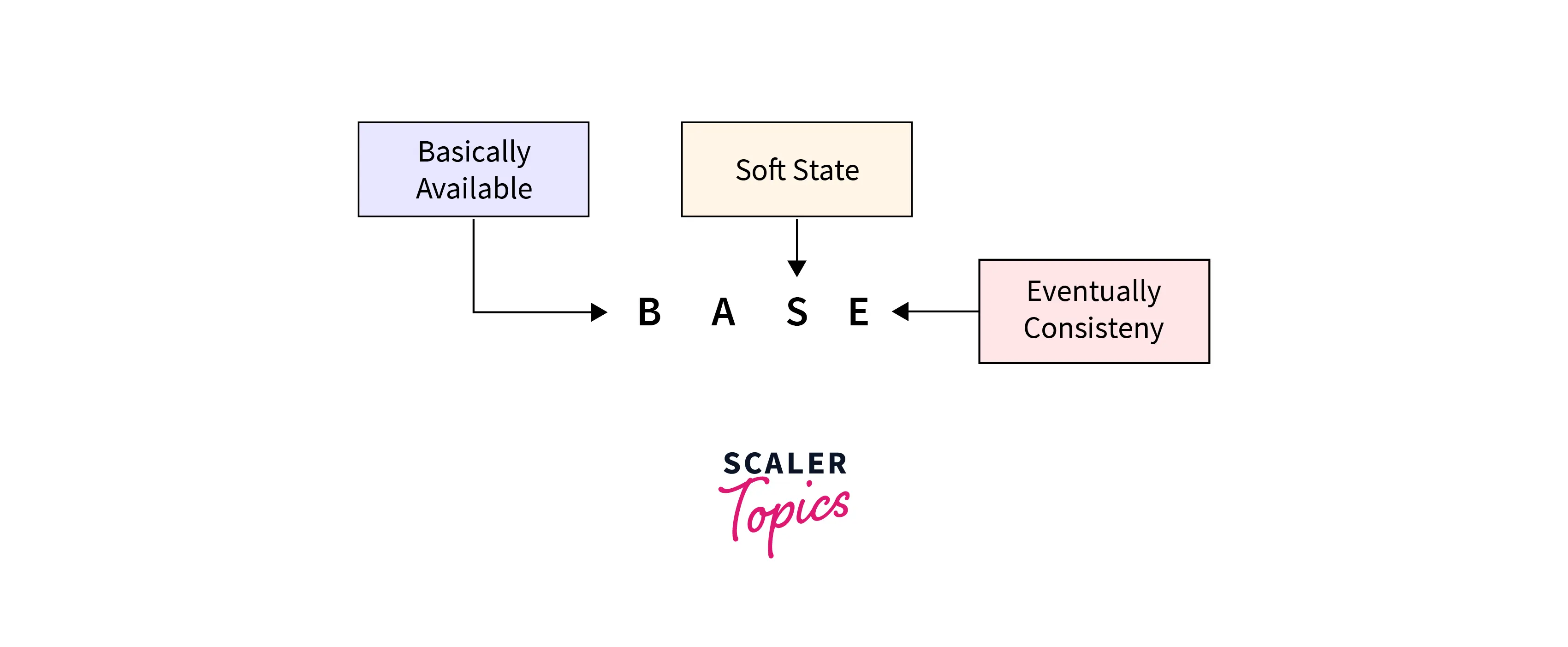
Another implication of database consistency is captured in the CAP theorem:
- Consistency: This means the same response is given to all the same and identical requests.
- Availability: This ensures that the requests receive responses even during a partial system failure.
- Partition Tolerance: In this the operations remain intact even when some nodes are unavailable.
A fundamental difference between the ACID database model and the BASE database model is how these limitations are addressed. Due to their highly structured nature, ACID-compliant databases are better suited for users who require consistency, predictability, and reliability.
The decisions regarding a particular model should be made considering all aspects of the project. Users who list growth as one of their priorities may choose the BASE model for its ease of scaling and flexibility. But the BASE model also needs developers who know how to deal with model limitations.
Learn more:
Conclusion
- Data Consistency in DBMS ensures that all data points in the database adhere to defined rules, maintaining accuracy and reliability.
- It is essential for decision-making and system stability, preventing corruption and ensuring data integrity.
- Consistency Levels define how many replicas or nodes must respond before a transaction is considered valid, with options like "ONE," "QUORUM," and "ALL."
- Understanding Strong Consistency vs. Weak Consistency is crucial, with strong consistency guaranteeing data accuracy across all nodes and weak consistency prioritizing availability over immediate consistency.
- Isolation Levels ensure transactions occur independently without affecting each other, preventing extraneous data during concurrent transactions.
- The ACID Model emphasizes consistency, while the BASE Model prioritizes availability and scalability, each with its implications and trade-offs.
- Decision-makers should consider project requirements, growth plans, and developer expertise when choosing between the ACID and BASE models.