What is a Data Cube in Data Mining?
A data cube in data mining is a multi-dimensional array that contains pre-aggregated data for efficient analysis. It provides a way to represent data in multiple dimensions, such as time, location, and product, allowing users to view data from different angles and gain insights into patterns and trends.
For example, consider a retail business that wants to analyze its sales data. The business may create a data cube with dimensions such as year/month, product, and city/country. The cube would contain pre-aggregated data, such as total sales, average sales, and the number of units sold, for each combination of the dimensions. This would allow the business to quickly analyze sales data by year, product, and city and identify trends and opportunities for improvement. For example, a data cube shown in the below figure represents sales data in multiple dimensions, i.e., product, quarter, and country.
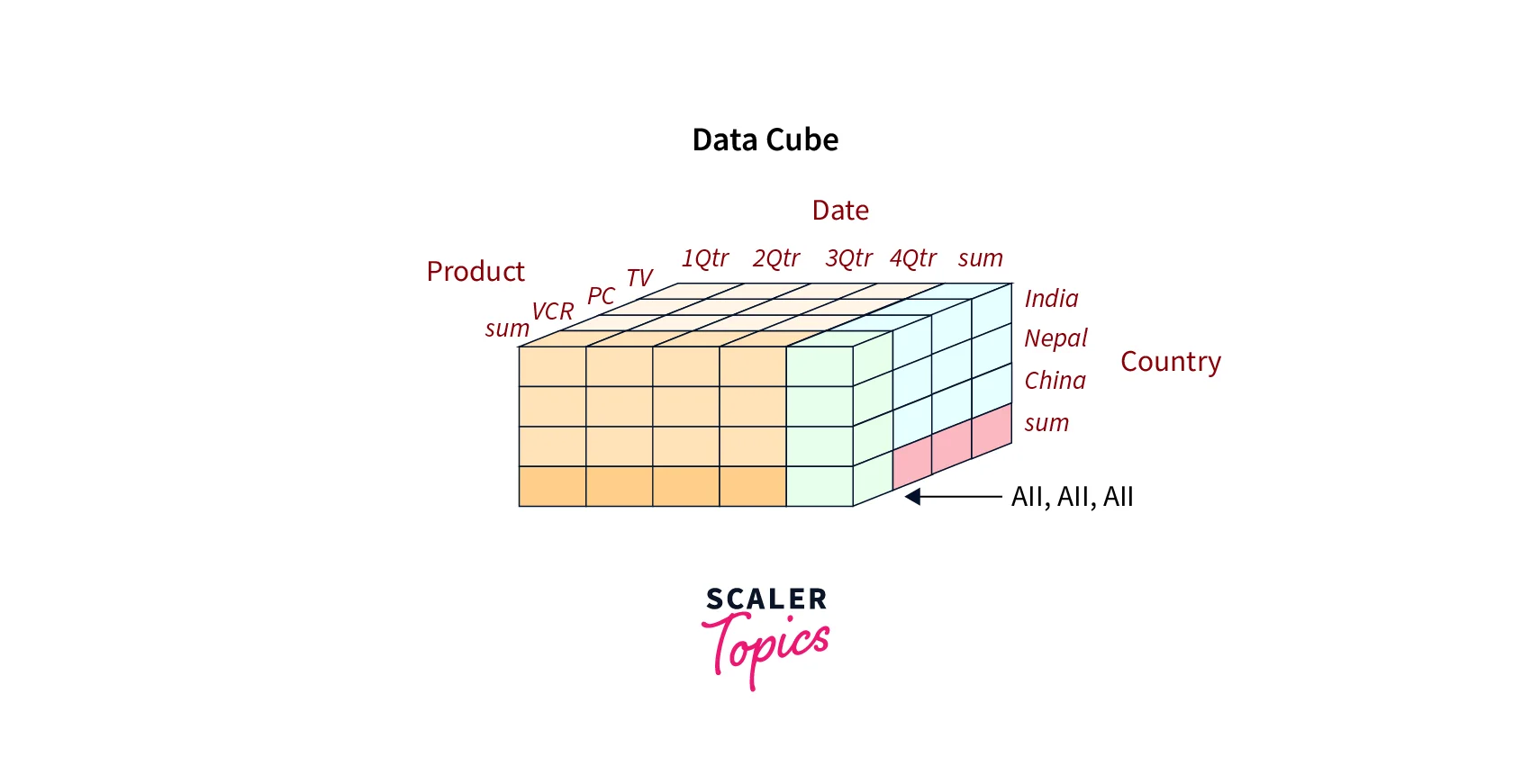
Data cube technology in data mining is commonly used in OLAP (online analytical processing) and business intelligence applications, enabling users to perform fast and efficient data analysis.
What is OLAP?
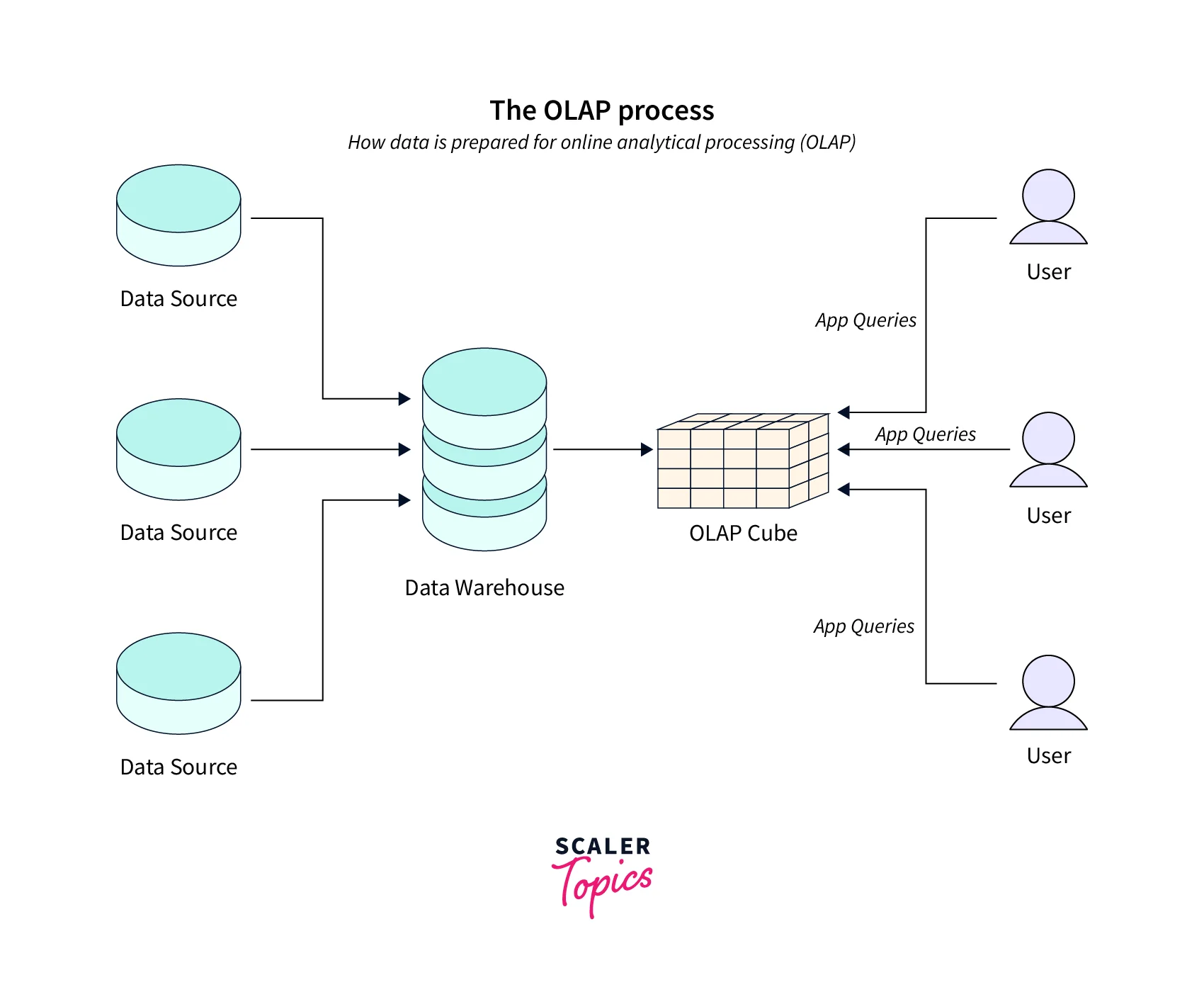
OLAP (Online Analytical Processing) is a technique used in data mining that allows users to quickly and interactively analyze large and complex datasets from multiple perspectives. OLAP is important for businesses because it enables them to analyze data in real-time and drill down into details to gain insights into business performance, identify trends, and make informed decisions. It is especially useful for decision-making and planning activities, such as budgeting, forecasting, and resource allocation.
OLAP is closely connected with data cube technology in data mining because data cubes are a popular way to represent multidimensional data for OLAP analysis. It is also called an OLAP cube. Data cube technology in data mining allows users to easily navigate through complex datasets and view data from different angles, enabling them to analyze data more efficiently and effectively.
Data Cube Classification
Data cubes in data mining can be classified into two main categories -
- Multidimensional data cube - This type of data cube in data mining is based on the concept of dimensions and measures. It represents data in multiple dimensions, such as time, product, and location, and allows users to analyze data from different perspectives. A multidimensional data cube in data mining is created by aggregating data across multiple dimensions, resulting in a cube-shaped data structure that enables users to drill down into details and gain insights into data patterns and trends.
- Relational data cube - This type of data cube in data mining is based on the relational database model and represents data in tables with rows and columns. It is created by performing aggregate functions, such as sum, count, and average, on columns of data in one or more tables. A relational data cube in data mining is often used when the data is too large to fit into memory and needs to be stored in a database. It enables users to perform complex queries and analysis on large datasets, but it may be less efficient than multidimensional data cubes for certain types of analysis.
Operations on Data Cube
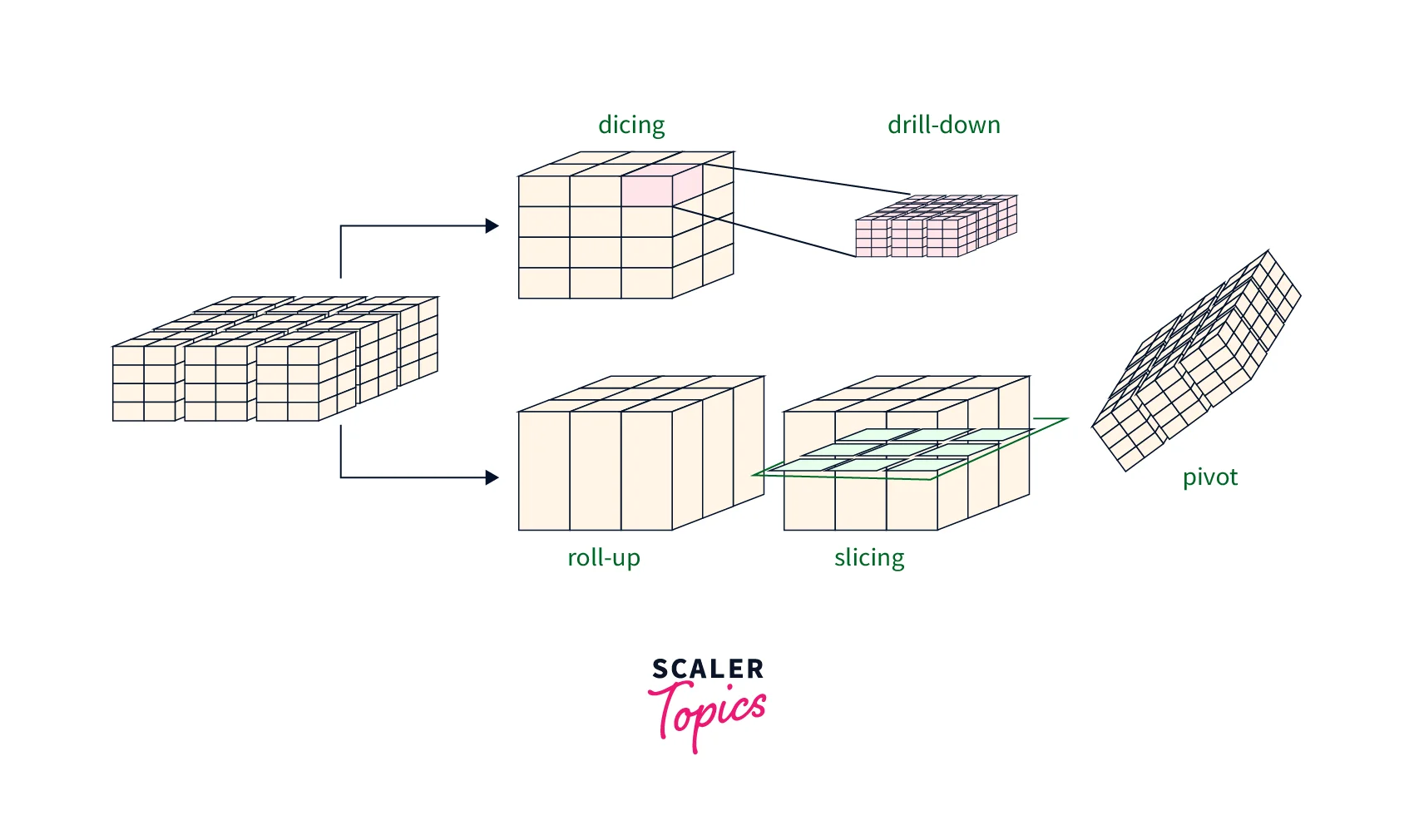
Operations on a data cube in data mining are used to analyze data from different perspectives and gain insights into data patterns and trends. The five common operations on a data cube are -
- Roll-up - This operation involves summarizing data along one or more dimensions of a data cube. It results in a data cube with a lower level of granularity. For example, we can roll up a sales data cube from monthly sales to quarterly sales, resulting in a data cube with fewer dimensions and a higher level of aggregation.
- Drill-down - This operation involves increasing the level of detail in a data cube by adding more dimensions or attributes to the existing dimensions. It results in a data cube with a higher level of granularity. For example, we can drill down a sales data cube from quarterly to monthly sales by adding the month dimension to the existing time dimension.
- Slice - This operation involves selecting a subset of a data cube by fixing the values of one or more dimensions. It results in a smaller data cube with the same dimensions but fewer data points. For example, we can slice a sales data cube to analyze sales data for a particular region and time period.
- Dice - This operation involves selecting a subset of a data cube by fixing the values of one or more dimensions and selecting a range of values for another dimension. It results in a smaller data cube with fewer dimensions and data points. For example, we can dice a sales data cube to analyze sales data for a particular region, time period, and product category.
- Pivot - This operation involves changing the orientation of a data cube by rotating the dimensions and measures. It results in a data cube with a different perspective on the data. For example, we can pivot a sales data cube to analyze sales data by product category and time period instead of the time period and product category.
Start Your Data Science Journey Today! Check Out Our Best Data Science Courses and Unleash Your Analytical Potential. Enroll Today!
Advantages of Data Cube
Data cube in data mining provides several advantages -
- Multidimensional analysis - Data cube technology in data mining enables users to analyze data from multiple perspectives and dimensions, such as time, product, location, and customer, allowing for a more comprehensive data view.
- Fast query performance - Data cubes pre-aggregate data at multiple levels of granularity, making it easier and faster to query large datasets and retrieve results.
- Reduced data redundancy - Data cubes store pre-aggregated data at various levels of granularity, reducing the need to store redundant data in a database.
- Data visualization - Data cube in data mining can be visualized using charts, graphs, and other graphical representations, making it easier for users to understand and analyze complex data.
- Improved decision-making - Data cube technology in data mining allows users to drill down, roll up, slice, and dice data, enabling them to make informed decisions based on insights gained from the data.
- Scalability - Data cubes can handle large datasets and be stored in a database, making them scalable for enterprise-level data mining.
Disadvantages of Data Cube
While data cube in data mining provides several advantages, they also have some disadvantages -
- Data cube creation - Creating a data cube in data mining can be a time-consuming and complex process that requires careful consideration of the dimensions, measures, and aggregation levels.
- Data storage requirements - Data cubes can require significant storage space, especially when dealing with large datasets with many dimensions and measures.
- Limited flexibility - Data cubes are optimized for multidimensional analysis and may need to be more flexible to accommodate changes to the underlying data or analysis requirements.
- Data quality issues - Data cube technology in data mining relies on the accuracy and consistency of the underlying data, which can be challenging to achieve when dealing with complex datasets.
- Complexity - While data cubes simplify the analysis of complex data, the analysis itself can be complex, requiring knowledge of the dimensions, measures, and aggregation levels used in the data cube.
Conclusion
- A data cube technology in data mining is a multidimensional representation of data that enables users to analyze large datasets from multiple perspectives and dimensions.
- It provides several advantages in data analysis, including fast query performance, data visualization, improved decision-making, and scalability.
- However, creating a data cube in data mining can be time-consuming, and there are some disadvantages to consider, such as limited flexibility, data redundancy, and complexity of analysis.
- Overall, data cube in data mining remains a powerful tool for multidimensional analysis in data mining and business intelligence, and their benefits outweigh their limitations in most cases.