What is Data Integration in Data Mining?
- Data mining is the process of discovering patterns, trends, and insights from large sets of data. It involves using statistical algorithms and machine learning techniques to analyze and extract valuable information from data. In many cases, the data needed for analysis comes from different sources and can be in different formats and structures. This is where data integration comes in.
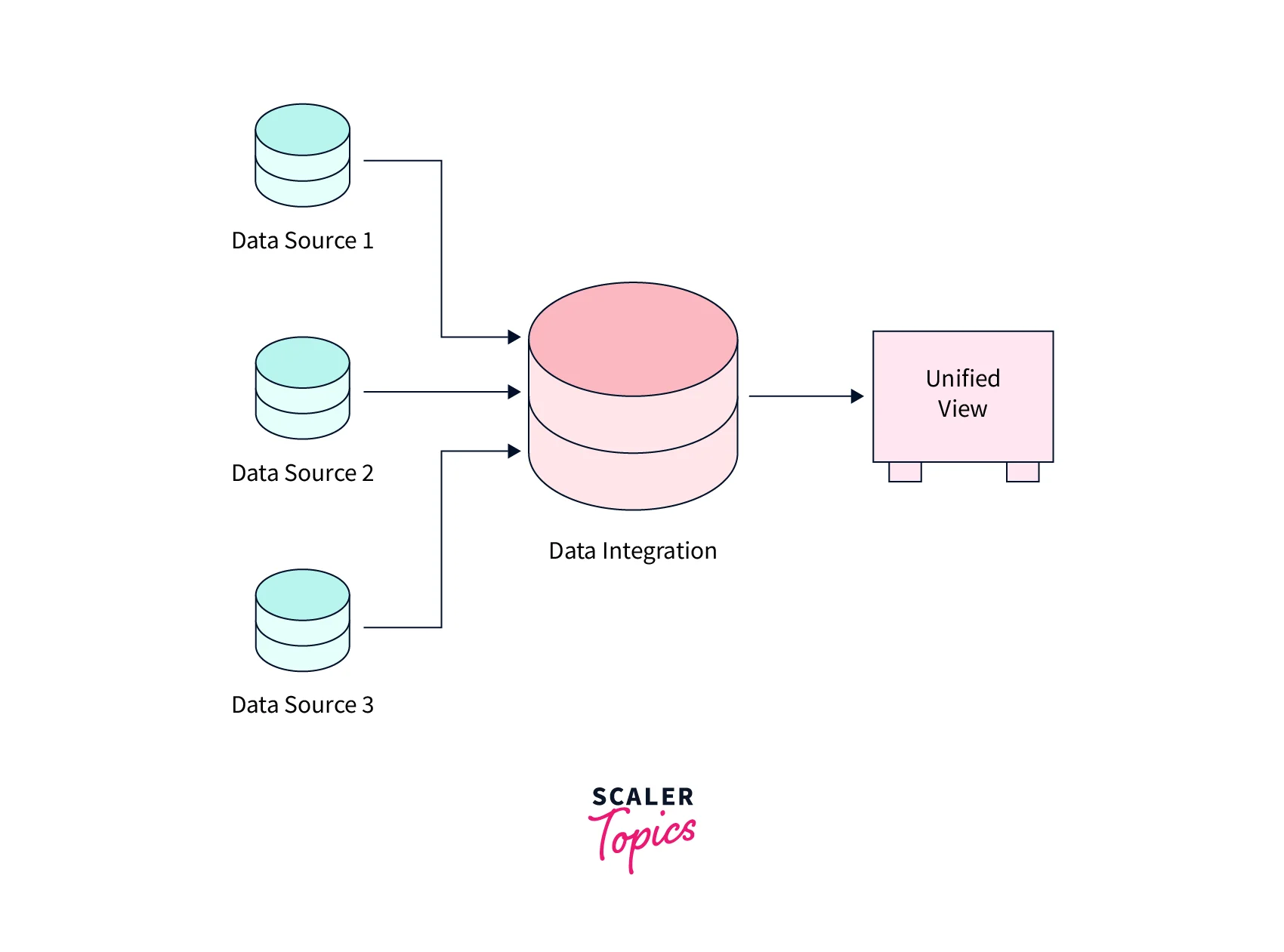
- Data integration in data mining is the process of combining data from multiple sources and consolidating it into a unified view. It is a critical aspect of data mining, which involves discovering patterns and insights from large datasets. But what is data integration, exactly? Simply put, it is the process of transforming and merging data from disparate sources so that it can be analyzed together.
- The goal of data integration in data mining is to provide a complete and accurate representation of the data for further analysis. It involves extracting data from various sources, transforming it into a common format, and loading it into a target system. Data integration can be challenging, especially when dealing with large volumes of data, complex data structures, and different data formats.
- Data integration strategy is typically described using a triple (G, S, M) approach, where G denotes the global schema, S denotes the schema of the heterogeneous data sources, and M represents the mapping between the queries of the source and global schema.
- To understand the (G, S, M) approach, Let's consider a data integration scenario that aims to combine employee data from two different HR databases, database A and database B. The global schema (G) would define the unified view of employee data, including attributes like EmployeeID, Name, Department, and Salary. In the schema of heterogeneous sources, database A (S1) might have attributes like EmpID, FullName, Dept, and Pay, while database B's schema (S2) might have attributes like ID, EmployeeName, DepartmentName, and Compensation. The mappings (M) would then define how the attributes in S1 and S2 map to the attributes in G, allowing for the integration of employee data from both systems into the global schema.
Why is Data Integration Important?
Data integration in data mining is important for several reasons, as mentioned below -
- Provides a Unified View of Data - Data integration in data mining enables combining data from different sources into a unified view. This allows for better decision-making by providing a complete and accurate data representation.
- Increases Data Accuracy - Integrating data from multiple sources helps to identify and eliminate inconsistencies, redundancies, and errors in the data. This improves data accuracy and reliability, making it easier to draw accurate conclusions.
- Improves Efficiency - Data integration in data mining automates combining data from multiple sources, reducing the time and effort required to access and analyze the data. This improves efficiency and reduces the costs associated with data management.
- Facilitates Data Analysis - Integrating data from multiple sources provides a broader perspective of the data. This enables more sophisticated and accurate data analysis, leading to more informed and effective decision-making.
- Enables Business Intelligence - Data integration is essential for creating a reliable and accurate data warehouse supporting business intelligence initiatives.
Approaches for Data Integration
There are mainly two kinds of approaches to data integration in data mining, as mentioned below -
Tight Coupling
- This approach involves the creation of a centralized database that integrates data from different sources. The data is loaded into the centralized database using extract, transform, and load (ETL) processes.
- In this approach, the integration is tightly coupled, meaning that the data is physically stored in the central database, and any updates or changes made to the data sources are immediately reflected in the central database.
- Tight coupling is suitable for situations where real-time access to the data is required, and data consistency is critical. However, this approach can be costly and complex, especially when dealing with large volumes of data.
Loose Coupling
- This approach involves the integration of data from different sources without physically storing it in a centralized database.
- In this approach, data is accessed from the source systems as needed and combined in real-time to provide a unified view. This approach uses middleware, such as application programming interfaces (APIs) and web services, to connect the source systems and access the data.
- Loose coupling is suitable for situations where real-time access to the data is not critical, and the data sources are highly distributed. This approach is more cost-effective and flexible than tight coupling but can be more complex to set up and maintain.
Issues in Data Integration
A few of the most common issues in data integration in data mining include -
- Data Quality - The quality of the data being integrated can be a significant issue in data integration. Data from different sources may have varying levels of accuracy, completeness, and consistency, which can lead to data quality issues in the integrated data.
- Data Semantics - Data semantics refers to the meaning and interpretation of data. Integrating data from different sources can be challenging because the same data element may have different meanings across sources. This can result in data integration issues and impact the integrated data's accuracy.
- Data Heterogeneity - Data heterogeneity refers to the differences in data formats, structures, and storage mechanisms across different data sources. Data integration can be challenging when dealing with heterogeneous data sources, as it requires data transformation and mapping to make the data compatible with the target data model.
- Complexity - Data integration can be complex, especially when dealing with large volumes of data or multiple data sources. As the complexity of data integration increases, it becomes more challenging to maintain data quality, ensure data consistency, and manage data security and privacy.
- Data Privacy and Security - Data integration can increase the risk of data privacy and security breaches. Integrating data from multiple sources can expose sensitive information and increase the risk of unauthorized access or disclosure.
- Scalability - Scalability refers to the ability of the data integration solution to handle increasing volumes of data and accommodate changes in data sources. Data integration solutions must be scalable to meet the organization's evolving needs and ensure that the integrated data remains accurate and consistent.
Transform Data into Actionable Insights! Enroll Now in Our Leading Data Science Training Course and Get Certified.
Data Integration Tools
There are mainly three types of tools for data integration in data mining, as mentioned below -
- On-Premise Data Integration Tools - On-premise data integration tools are installed and run on the organization's infrastructure. These tools offer complete control over the data integration process and are typically used by larger organizations requiring high customization and security levels. Some popular on-premise data integration tools include IBM InfoSphere DataStage, Talend, and Microsoft SQL Server Integration Services (SSIS).
- Open-Source Data Integration Tools - Open-source data integration tools are free and often community-driven solutions that allow users to modify the source code and add new features. These tools are typically less expensive than proprietary tools and can be customized to fit the organization's specific needs. Some popular open-source data integration tools include Apache NiFi, Apache Kafka, and Pentaho.
- Cloud-Based Data Integration Tools - Cloud-based data integration tools are hosted in the cloud and accessed through a web browser. These tools offer scalability, flexibility, and easy access to data from different sources. They are ideal for organizations requiring quick implementation and not wanting to invest in on-premise hardware or software. Some popular cloud-based data integration tools include Amazon Web Services (AWS) Glue, Microsoft Azure Data Factory, and Google Cloud Data Fusion. However, privacy and security are major concerns when using cloud-based data integration tools. Storing and transferring sensitive data to the cloud can expose it to potential risks, such as unauthorized access, data breaches, or data leakage. Adequate security measures, including encryption, access controls, and secure authentication, must be implemented to protect data during storage and transmission.
Conclusion
- Data integration in data mining is the process of combining data from different sources into a unified view. It is important because it allows organizations to gain insights and make informed decisions based on a complete and accurate view of their data.
- There are several approaches to data integration, including tight and loose coupling. Each approach has its benefits and challenges, and organizations must choose the approach that best suits their needs.
- However, data integration can also present challenges such as data quality, data semantics, data heterogeneity, complexity, data privacy and security, and scalability. By understanding what data integration is and its challenges, organizations can overcome these obstacles and achieve the full benefits of data mining.