What are the Functionalities of Data Mining?
Overview
In today's data-driven world, extracting valuable insights from vast amounts of information has become paramount for businesses worldwide. Data mining, a powerful process, plays a pivotal role in this endeavour. In this article, we will explore the data mining functionalities, shedding light on its key processes and techniques. From predictive analysis to outlier detection, data mining encompasses a wide range of functionalities that empower organizations to uncover hidden trends, make informed decisions, and enhance their competitive edge.
Data Mining Activities
Data mining encompasses two primary categories of activities - descriptive and predictive data mining.
Descriptive Data Mining
Descriptive data mining focuses on uncovering patterns, trends, and relationships within existing data. This category of data mining doesn't aim to make predictions but rather seeks to provide valuable insights into historical or current data. Through techniques like clustering and association rule mining, descriptive data mining can help organizations understand customer behaviour, segment their market, or identify anomalies within their datasets. For instance, a retail company might use descriptive data mining to discover customer purchasing patterns, helping it optimize inventory management and marketing strategies.
Predictive Data Mining
Predictive data mining, on the other hand, goes beyond description to predict future outcomes. It leverages historical data and statistical algorithms to build models that can make predictions or classifications. Common applications include forecasting sales, detecting fraud, or predicting disease outbreaks. For instance, predictive data mining in healthcare can analyze patient records to predict disease risk factors, enabling early intervention and personalized treatment plans. The power of predictive data mining lies in its ability to harness past data to make informed decisions and drive proactive actions, ultimately improving efficiency and competitiveness.
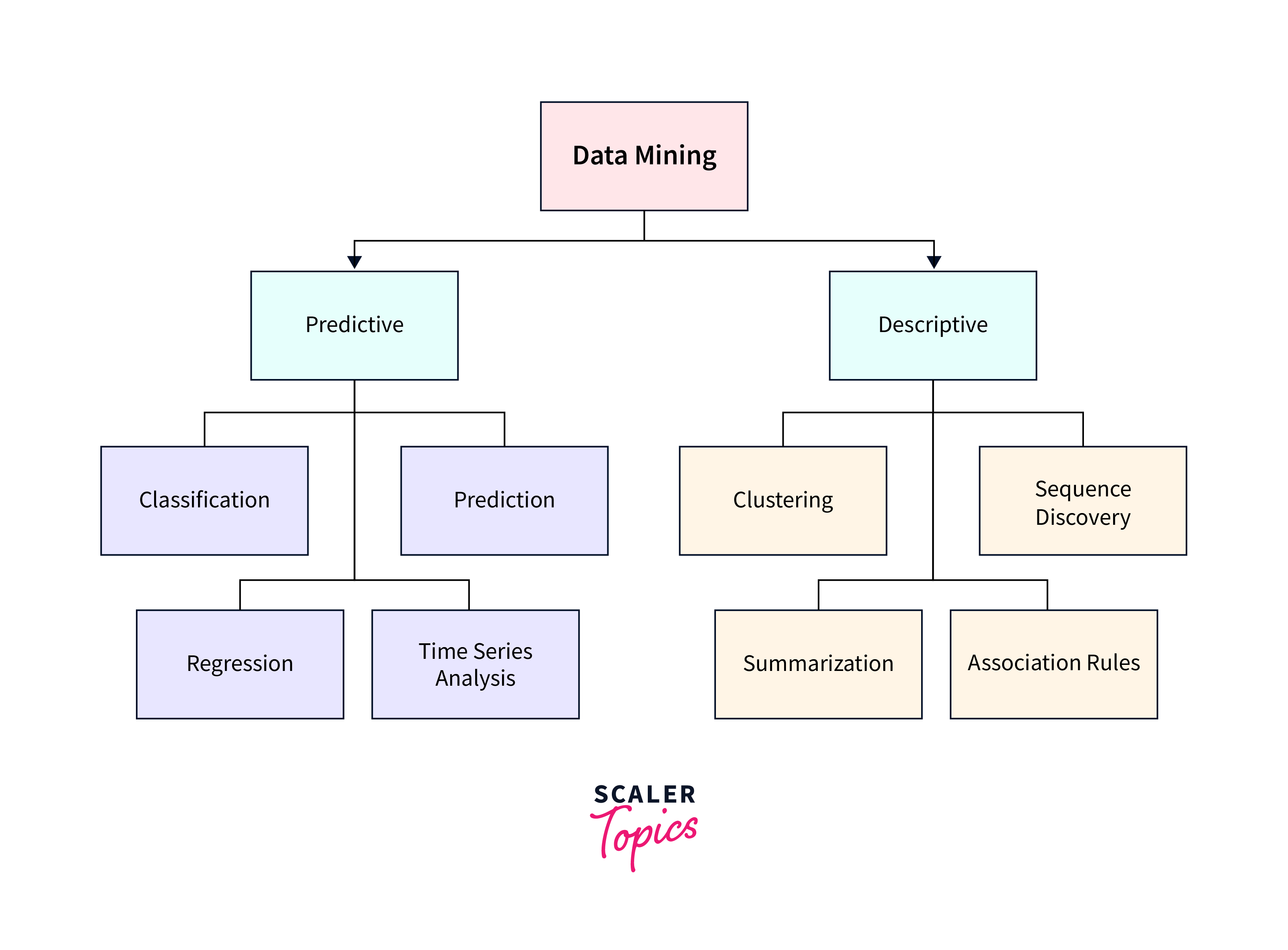
Functionalities of Data Mining
This section will explore various data mining functionalities as mentioned below.

Class/Concept Descriptions
Class or concept descriptions are crucial in understanding and categorizing data in data mining. There are two key categories in this context - data characterization and data discrimination.
- Data Characterization - Data characterization summarizes a given dataset's general features and characteristics. It provides a comprehensive view of the data's distribution, central tendencies, and overall structure. This category often employs statistical measures, visualizations, and descriptive techniques to clearly and concisely represent the data's properties. For example, in financial analysis, data characterization might involve generating summary statistics and visualizations to understand the historical performance of a stock portfolio, helping investors assess risk and make informed decisions.
- Data Discrimination - Data discrimination, in contrast, is concerned with distinguishing between different classes or categories within a dataset. It aims to find features or patterns that can effectively separate one class from another. This category is commonly used in classification tasks, such as spam email detection or sentiment analysis in natural language processing. For instance, in email filtering, data discrimination techniques can analyze the content and metadata of emails to determine whether they belong to the "spam" or "not spam" category, helping users manage their inboxes effectively.
Mining Frequent Patterns
A key role of data mining involves the identification of data patterns, specifically those that occur frequently within a dataset. These frequent patterns manifest in various forms -
- Frequent Item Sets - This term pertains to sets of items that tend to co-occur regularly within the data. For instance, it might reveal that products like milk and sugar are commonly purchased together, providing insights into consumer buying habits.
- Frequent Substructures - Frequent substructures refer to diverse data structures that can be associated with item sets or subsequences. Examples include trees and graphs, which often appear in conjunction with certain patterns, unveiling deeper relationships within the data.
- Frequent Subsequences - This category involves the identification of recurring sequential patterns. For instance, it may uncover a pattern where customers frequently purchase a phone followed by a phone cover, highlighting sequences of events or actions within the data.
Association Analysis
It examines the group of items that commonly appear together within a transactional dataset. This technique is often called Market Basket Analysis due to its prevalent application in the retail industry. To establish association rules, two key parameters are employed:
- Support - This parameter identifies the frequency of occurrence of a particular item set within the database.
- Confidence - Confidence represents the conditional probability that an item will appear in a transaction, given the occurrence of another item in the same transaction.
Classification
Classification in data mining is a technique used to categorize data into predefined classes or categories based on specific attributes or characteristics. It involves the application of algorithms like decision trees, neural networks, or support vector machines to assign objects or records to distinct classes. This process is valuable for tasks such as spam email detection, sentiment analysis, and disease diagnosis, where data needs to be sorted into relevant groups to facilitate decision-making and pattern recognition.
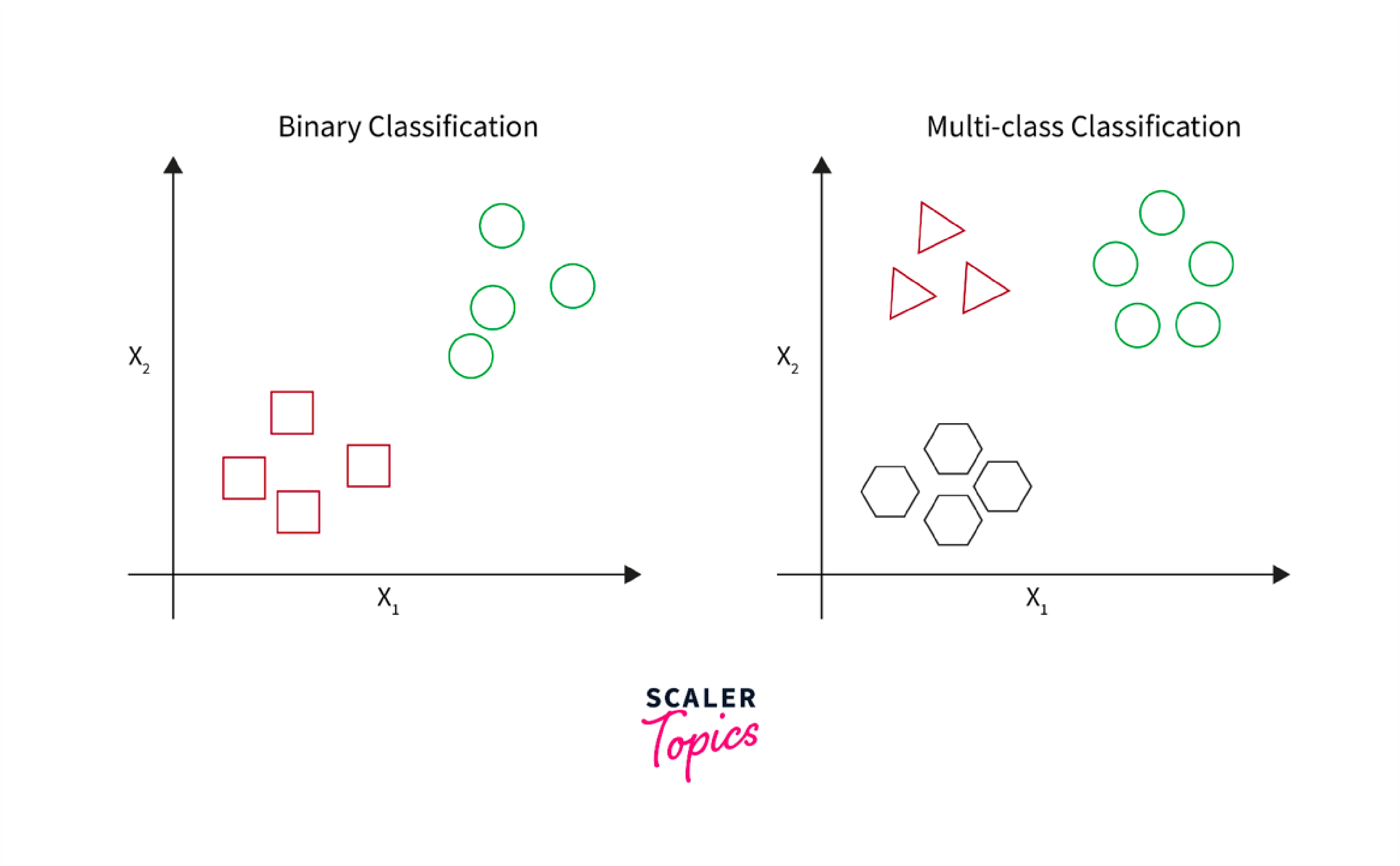
Prediction
Prediction in data mining is the process of using historical data and patterns to make informed estimates about future or missing data values. It involves the application of various algorithms and techniques to anticipate numerical values, such as sales figures, or to classify items into predefined categories. This predictive capability enables businesses and researchers to make data-driven decisions, identify trends, and enhance their understanding of complex datasets, ultimately facilitating better planning and strategy development.
- Numeric Prediction - Numeric prediction involves forecasting numerical values based on historical data, typically using techniques like linear regression. It helps businesses prepare for future events or trends impacting their operations.
- Class Prediction - Class prediction assigns missing class labels to items using a training dataset where class labels are known. It's valuable for categorizing items or objects and improving data completeness and decision-making.
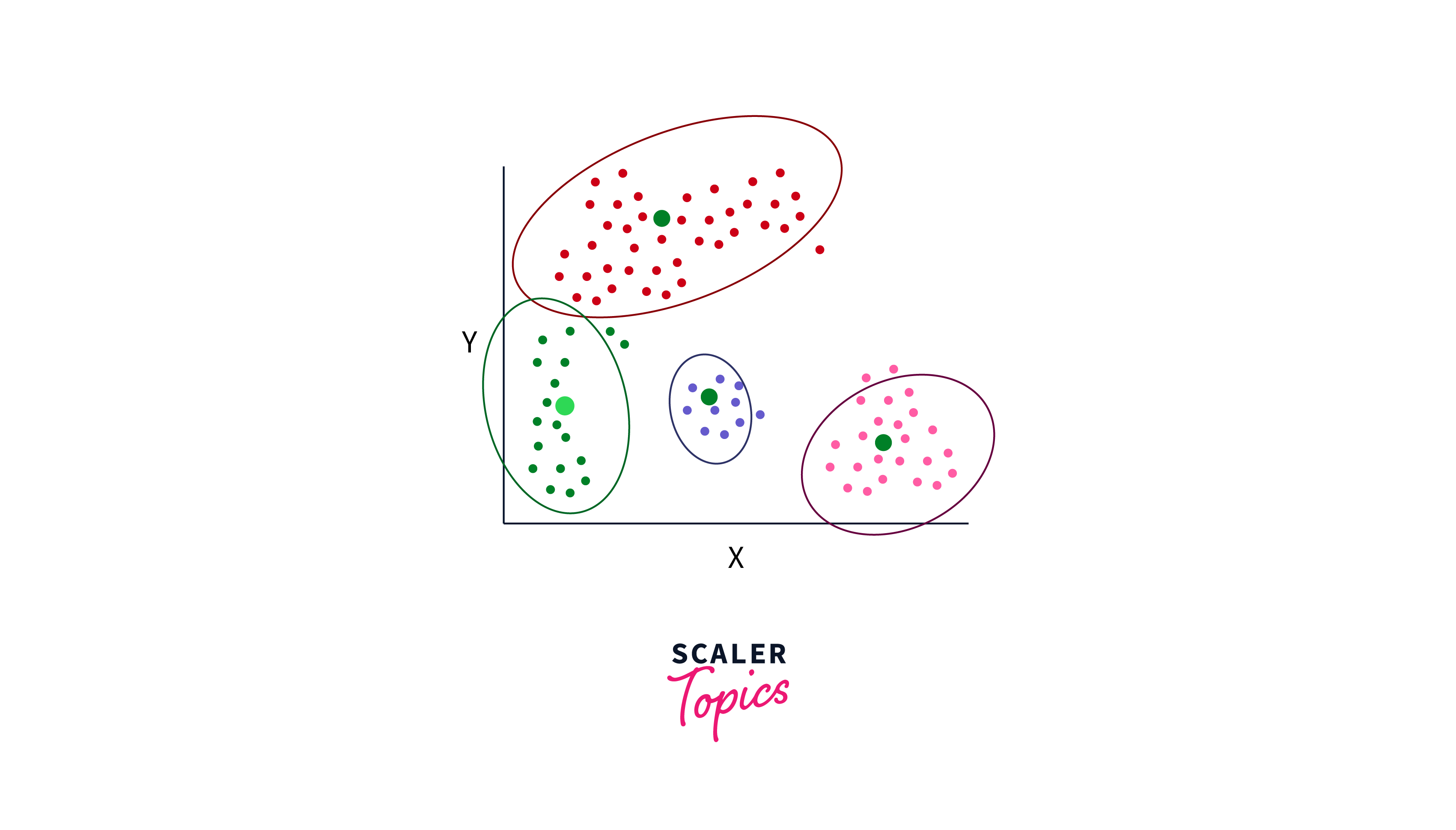
Cluster Analysis
Cluster analysis in data mining is a method used to group similar data points together based on their inherent characteristics or attributes. It aims to discover patterns and relationships within data by identifying clusters or clusters of data points that share common features. This technique has various applications, including customer segmentation, anomaly detection, and data compression, and helps uncover hidden structures within datasets, enabling more effective decision-making and data exploration.
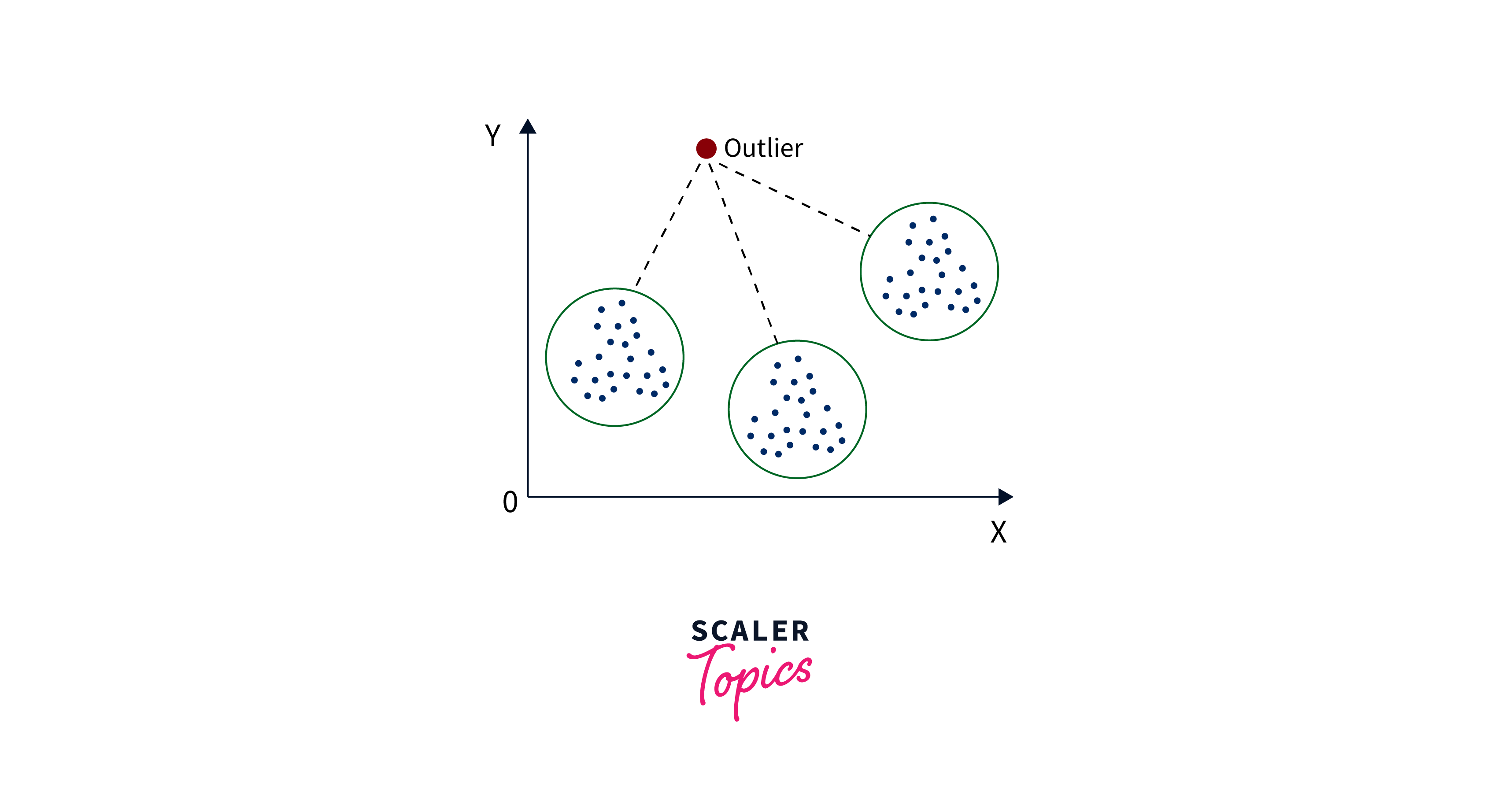
Outlier Analysis
Outlier analysis in data mining is the process of identifying and examining data points that significantly deviate from the expected or normal patterns within a dataset. These outliers, often anomalies or exceptions, may hold valuable information or indicate errors, fraud, or rare events. Outlier analysis helps detect unusual data instances that can impact data quality, decision-making, and the discovery of novel insights, making it crucial in various domains like fraud detection, quality control, and anomaly detection.
Evolution and Deviation Analysis
Evolution analysis in data mining involves tracking changes and patterns over time within a dataset. It aims to identify trends, variations, and evolving relationships in temporal data, enabling businesses to make informed decisions based on historical and current trends. Deviation analysis, on the other hand, focuses on identifying deviations or anomalies in data compared to expected or normative patterns.
Correlation Analysis
Correlation analysis in data mining involves examining the statistical relationships between two or more variables within a dataset. It quantifies the degree to which changes in one variable are associated with changes in another, providing insights into their interdependence. This analysis helps identify patterns, dependencies, and associations between variables, enabling businesses to make data-driven decisions.
Conclusion
- Data mining functionalities offer versatile tools and techniques that empower organizations to extract valuable insights from their data, enabling better decision-making, improved strategies, and enhanced competitiveness.
- In this article, we explored key data mining functionalities, including data characterization, discrimination, classification, prediction, and various types of analysis such as cluster, outlier, evolution, deviation, and correlation analysis.
- These data mining functionalities collectively underscore the significance of data mining in transforming raw data into actionable knowledge. Whether it's uncovering hidden patterns, making predictions, or identifying anomalies, data mining is an invaluable asset for harnessing the full potential of data in today's information-rich world.