Data Mining Techniques
Data mining, a blend of art and science, involves extracting patterns and knowledge from extensive data sets. It's not just about mining data but discovering valuable insights through sophisticated analysis and prediction techniques. Employing machine learning, statistics, and database management methods, data mining is pivotal in fields like marketing, finance, healthcare, and research. Key techniques include statistical models, machine learning methods like neural networks, and decision trees. Effective data mining is characterized by scalability, robustness, accuracy, and interpretability, enabling organizations to uncover hidden patterns and make informed decisions.
Knowledge Discovery From Data
The process of Knowledge Discovery From Data (KDD) involves several steps, which are as follows -
- Data cleaning -
The first step involves preprocessing and cleaning of data to remove noise, missing values, or inconsistencies. - Data integration -
Data from multiple sources are combined into a single dataset. - Data selection -
The relevant data is selected from the dataset for further analysis. - Data transformation -
The selected data is transformed into a format suitable for mining. - Data mining -
Data mining techniques are applied to extract useful patterns or knowledge from the data. - Pattern evaluation -
The patterns discovered by data mining are evaluated based on criteria such as their significance and usefulness. - Knowledge representation -
The results are represented in a form that is easily understandable by users. - Knowledge utilization -
The knowledge gained from the data is used for decision-making or to improve business processes.
In the next section, let’s explore the various data mining techniques used to discover patterns and relationships from a large and complex dataset.
Data Mining Techniques
Let’s explore the most commonly used data mining techniques below -
Classification
Classification is a supervised learning technique in data mining that assigns predefined classes to objects or instances based on their attributes or features. It involves building a model from a set of training data that consists of labeled examples, where the class label of each example is known. The model is then used to classify new, unseen data based on their attributes.
For example, consider a bank that wants to identify customers who are likely to default on their loans. The bank can use classification to build a model that predicts the default risk of a customer based on their credit score, income, and other relevant factors. The model can then be used to classify new loan applicants as low or high-risk.
Classification algorithms used in data mining include decision trees, naive Bayes, support vector machines (SVM), and logistic regression, among others. These algorithms differ in their assumptions, strengths, and weaknesses and are chosen based on the characteristics of the data and the problem being solved.
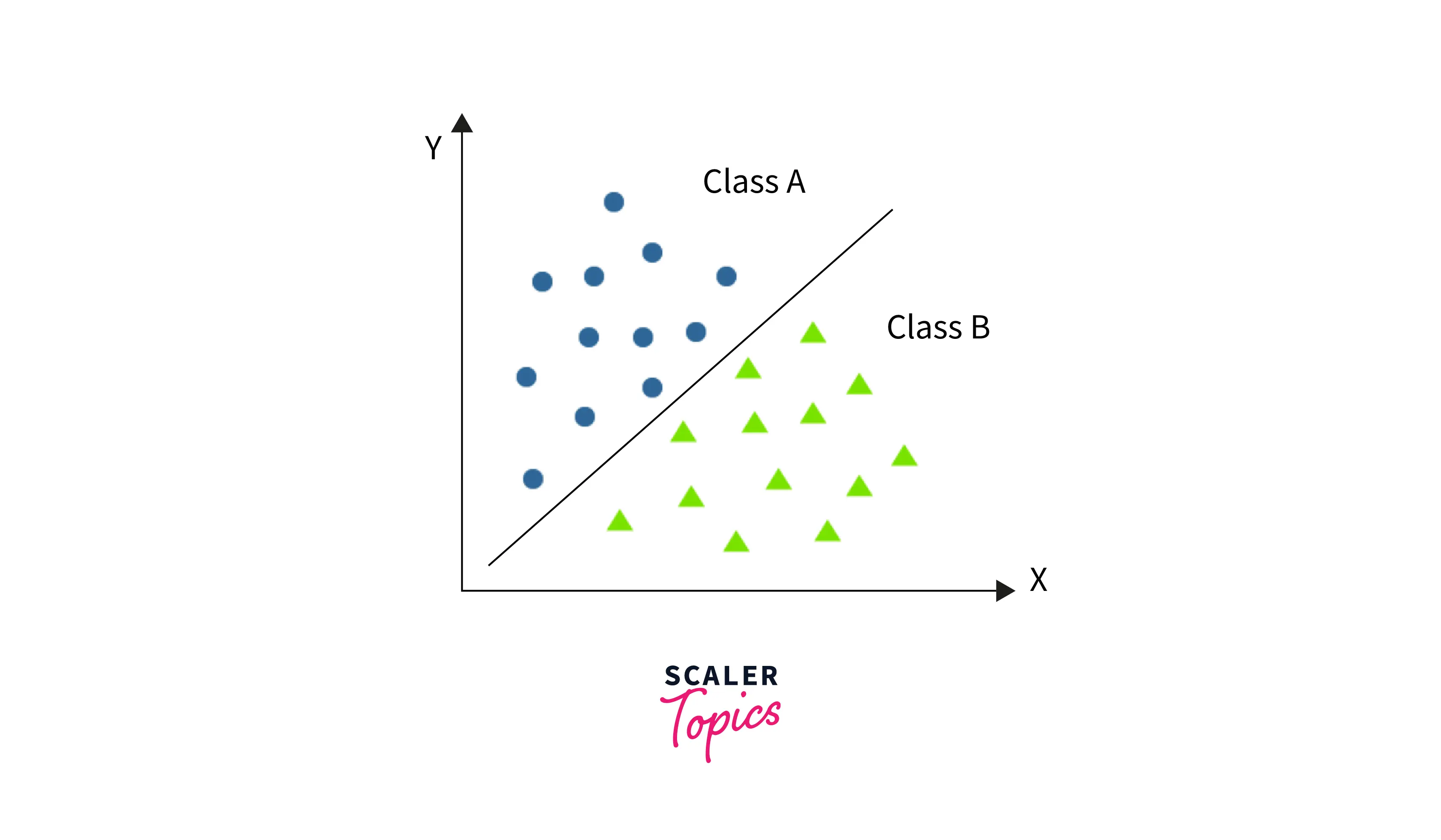
Clustering
Clustering is an unsupervised learning technique in data mining that involves grouping similar objects or instances together based on their attributes or features. Unlike classification, clustering does not involve predefined classes but rather groups objects based on their similarity. The objective of clustering is to discover inherent patterns and structures in the data that may not be immediately apparent.
For example, consider a retailer that wants to segment its customers based on their shopping behavior. The retailer can use clustering to group customers with similar purchasing patterns, such as those who buy high-end products or shop frequently. This information can be used to tailor marketing strategies and promotions to each segment.
Clustering algorithms used in data mining include k-means, hierarchical clustering, and density-based clustering, among others. These algorithms differ in their assumptions and how they define similarity or distance between objects.
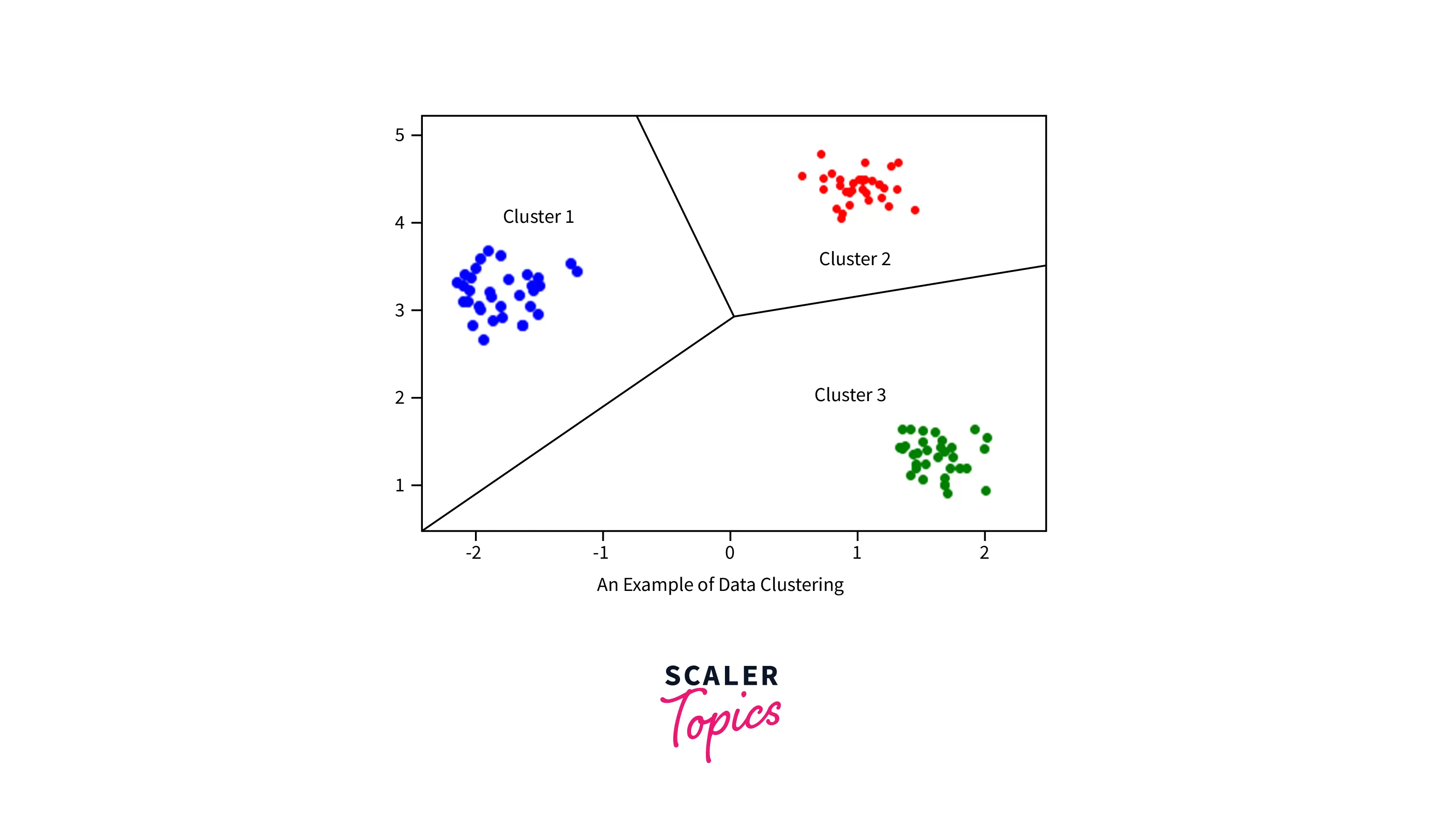
Regression
Regression is a supervised learning technique in data mining that involves building a model to predict a continuous or numerical output variable based on one or more input variables or predictors. Regression aims to establish a functional relationship between the input and output variables.
For example, consider a real estate agency that wants to predict the price of a house based on its features, such as size, location, and the number of bedrooms. The agency can use regression to build a model that predicts the price of a house based on these features. The model can then be used to estimate the price of new houses or to identify undervalued properties.
Regression algorithms used in data mining include linear regression, polynomial regression, and decision tree regression, among others. These algorithms differ in their assumptions and how they model the relationship between the input and output variables.
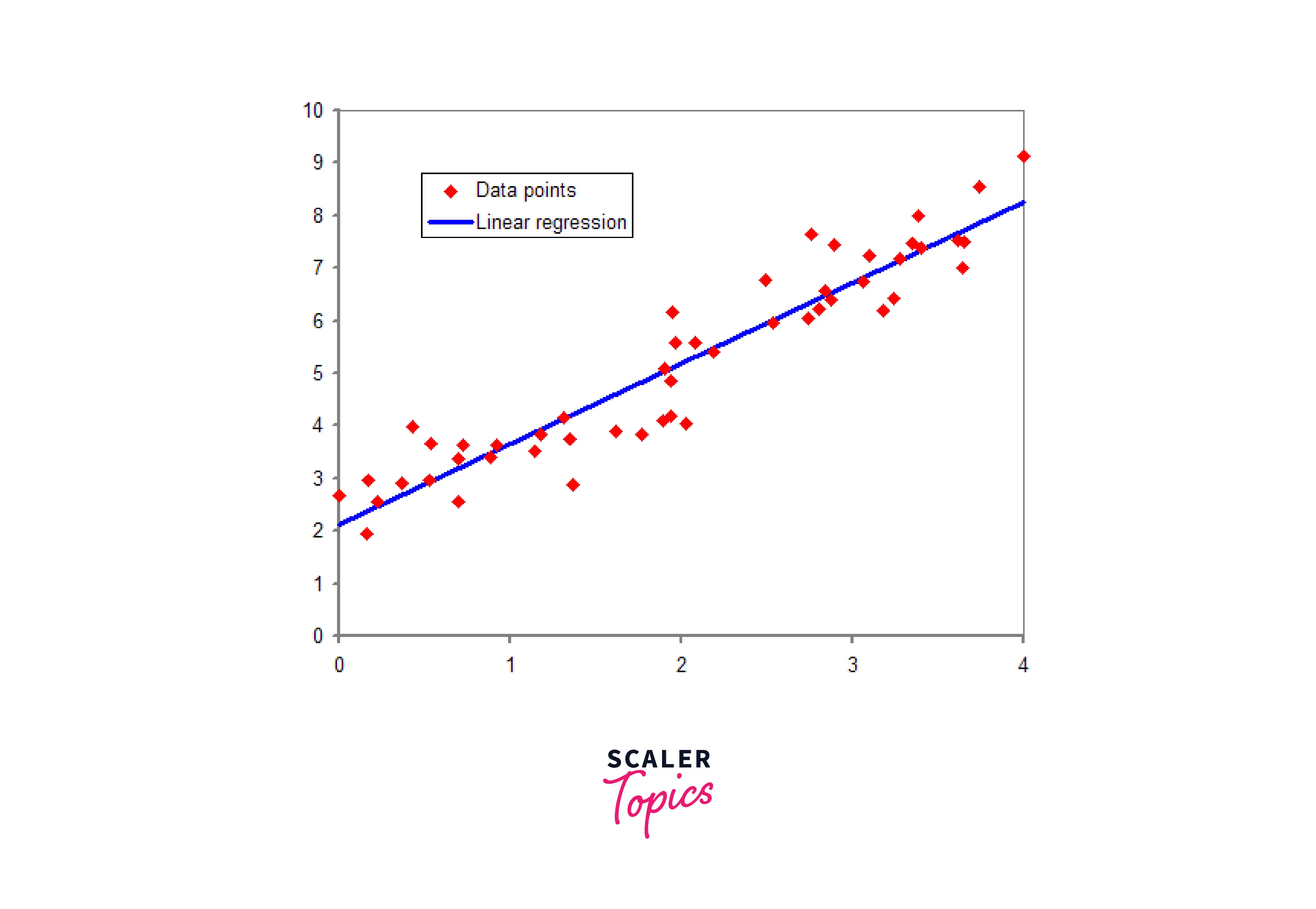
Association Rules Mining
Association rule mining is an unsupervised learning technique in data mining that involves discovering relationships or associations between variables in a dataset. It aims to find patterns of co-occurrence or correlation among variables frequently occurring together in the data.
For example, consider a retailer that wants to increase its sales by offering promotions or discounts to customers who buy certain products. The retailer can use association rule mining to identify which products are often bought together, such as bread and butter or shampoo and conditioner. This information can be used to create targeted promotions and cross-selling strategies.
Association rule mining algorithms used in data mining include Apriori, FP-Growth, and Eclat, among others. These algorithms differ in their approach to identifying frequent itemsets or sets of variables that occur together.
Outlier Detection
Outlier detection is a data mining technique that involves identifying and analyzing data points or observations significantly different from most of the data. Outliers are data points that deviate from the expected or normal behavior of the data and may indicate errors, anomalies, or rare events.
For example, consider a credit card company that wants to detect fraudulent transactions. The company can use outlier detection to identify transactions significantly different from a customer's normal spending behavior, such as unusually large purchases or transactions made in different countries. These transactions can be flagged for further investigation or declined to prevent fraud.
Outlier detection algorithms used in data mining include statistical methods, such as z-score and boxplot, and machine learning methods, such as isolation forest and LOF.
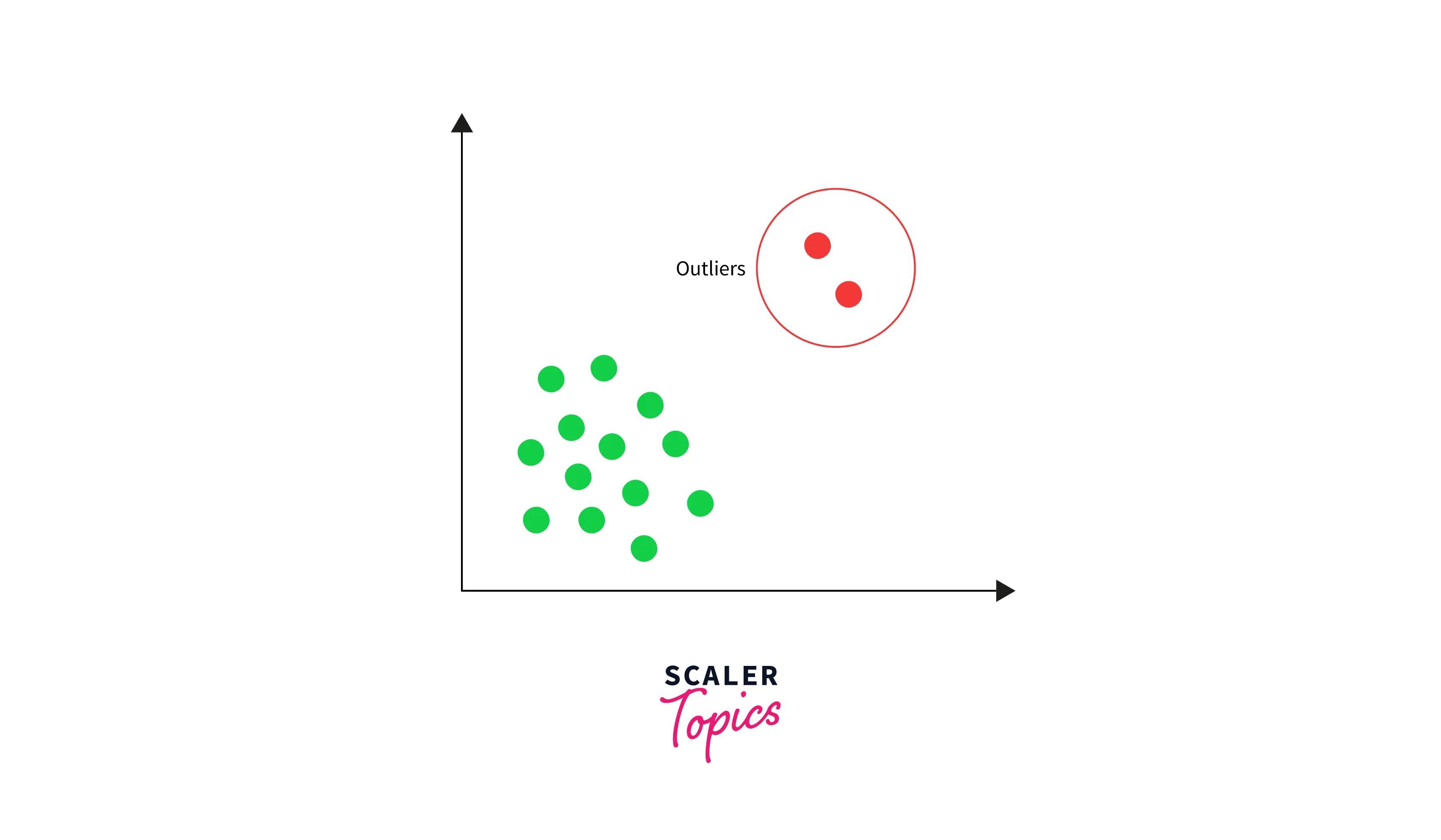
Sequential Patterns
Sequential pattern mining is a data mining technique that involves discovering patterns or sequences of events that frequently occur together in a dataset. It aims to identify temporal or time-dependent relationships between variables or events.
For example, consider an e-commerce company that wants to improve its user experience by recommending products based on the purchase behavior of its users. The company can employ sequential pattern mining to identify which products are often purchased together in a sequence, such as a user buying accessories post-purchase of a computer or smartphone. This information can be used to personalize recommendations and improve user engagement.
Sequential pattern mining algorithms used in data mining include GSP (Generalized Sequential Pattern), SPADE (Sequential PAttern Discovery using Equivalence classes), and PrefixSpan, among others.
Prediction
Prediction is a data mining technique that involves building a model to predict the value or class of a target variable based on a set of input or predictor variables. The objective of prediction is to make accurate predictions for new or unseen data based on the patterns and relationships discovered in the training data.
Prediction algorithms used in data mining include linear regression, decision trees, neural networks, support vector machines, and random forests, among others. These algorithms differ in their approach to building prediction models and are based on the data type of the variable (categorical or continuous) to be predicted. One can choose the appropriate algorithm for the prediction model based on the characteristics of the data and the problem being solved.
Advantages and Disadvantages
Data mining techniques have several advantages, which are as follows -
- Identification of patterns and trends -
Data mining techniques help identify patterns and trends in large datasets, providing valuable insights for decision-making. - Automated processing -
Data mining techniques automate the process of analyzing data, reducing the time and effort required for manual analysis. - Prediction and forecasting -
Data mining techniques can be used to build predictive models that help forecast future trends and events. - Improved decision-making -
Data mining techniques provide valuable information and insights that help make informed decisions. - Increased efficiency -
Data mining techniques help identify areas of inefficiency or waste, allowing organizations to streamline their operations and improve efficiency. - Personalization -
Data mining techniques can help personalize customer recommendations and experiences based on their preferences and behaviors.
Data mining techniques also have several disadvantages, as mentioned below -
- Privacy concerns -
Data mining techniques can be used to extract sensitive information about individuals, which can raise privacy concerns. - Reliance on data quality -
Data mining techniques rely on the quality and accuracy of the data, and inaccurate or incomplete data can lead to incorrect conclusions. - Complexity -
Data mining techniques can be complex and require specialized skills and knowledge, making it difficult for non-experts to use them effectively. - Cost -
Implementing data mining techniques can be expensive, requiring specialized hardware, software, and personnel. - Overfitting -
Data mining techniques can sometimes lead to overfitting, where the model is too closely fitted to the training data and does not generalize well to new data.
Don't just analyze data; master it. Join our free Data Science certification course and elevate your data science skills!
Conclusion
- Data mining techniques are a set of methods and tools used to extract knowledge and insights from large and complex datasets.
- These techniques can help discover patterns, relationships, and trends that may not be apparent otherwise and improve decision-making and efficiency.
- A few of the most commonly used data mining techniques include classification, regression, association rules mining, clustering, outlier detection, etc.
- Data mining techniques are widely used in various fields, including finance, healthcare, marketing, and more, and continue to evolve and improve with advances in technology and data science.