Text Mining
Overview
Text mining is a subfield of data mining that involves extracting useful information from unstructured text data. Text mining is used to analyze and mine information from text data, such as text documents, social media posts, customer reviews, etc., and extract valuable insights that can help organizations make data-driven decisions. Text mining techniques include natural language processing (NLP), sentiment analysis, topic modeling, and text classification.
What is Text Mining?
Text mining in data mining is a process of extracting useful and meaningful information or knowledge from unstructured or semi-structured text data. It involves applying various computational and statistical techniques to automatically identify hidden patterns, trends, associations, and insights from large volumes of text data.
The textual data can be in various forms, such as emails, news articles, social media posts, customer feedback, scientific papers, and more. Text mining aims to transform this unstructured data into structured information that can be further analyzed and used for various purposes. Text mining techniques typically include natural language processing, sentiment analysis, topic modeling, text classification, etc.
Using text mining, organizations can better understand their customers, competitors, and industry trends. For example, text mining can be used to analyze customer reviews and feedback to identify common issues and areas for improvement. It can also be used to monitor social media posts and news articles to track sentiment around a particular product or brand.
Difference Between Text Mining and Text Analytics
Text mining and text analytics are often used interchangeably to refer to the process of extracting insights and knowledge from unstructured or semi-structured text data. However, there are some subtle differences between the two terms.
Text mining refers to the process of automatically extracting information from text data using various computational and statistical techniques. It involves various steps such as text pre-processing, text representation, text analysis, and evaluation. On the other hand, text analytics is a broader term encompassing text mining and other related techniques such as information retrieval, natural language processing (NLP), and machine learning. Text analytics involves the analysis of text data to gain insights and knowledge that can be used for various applications.
In summary, text mining is a subset of text analytics that involves applying computational and statistical techniques to extract structured information from unstructured text data automatically. Text analytics, on the other hand, is a broader term that encompasses various techniques that can be used to analyze text data for insights and knowledge.
Process of Text mining
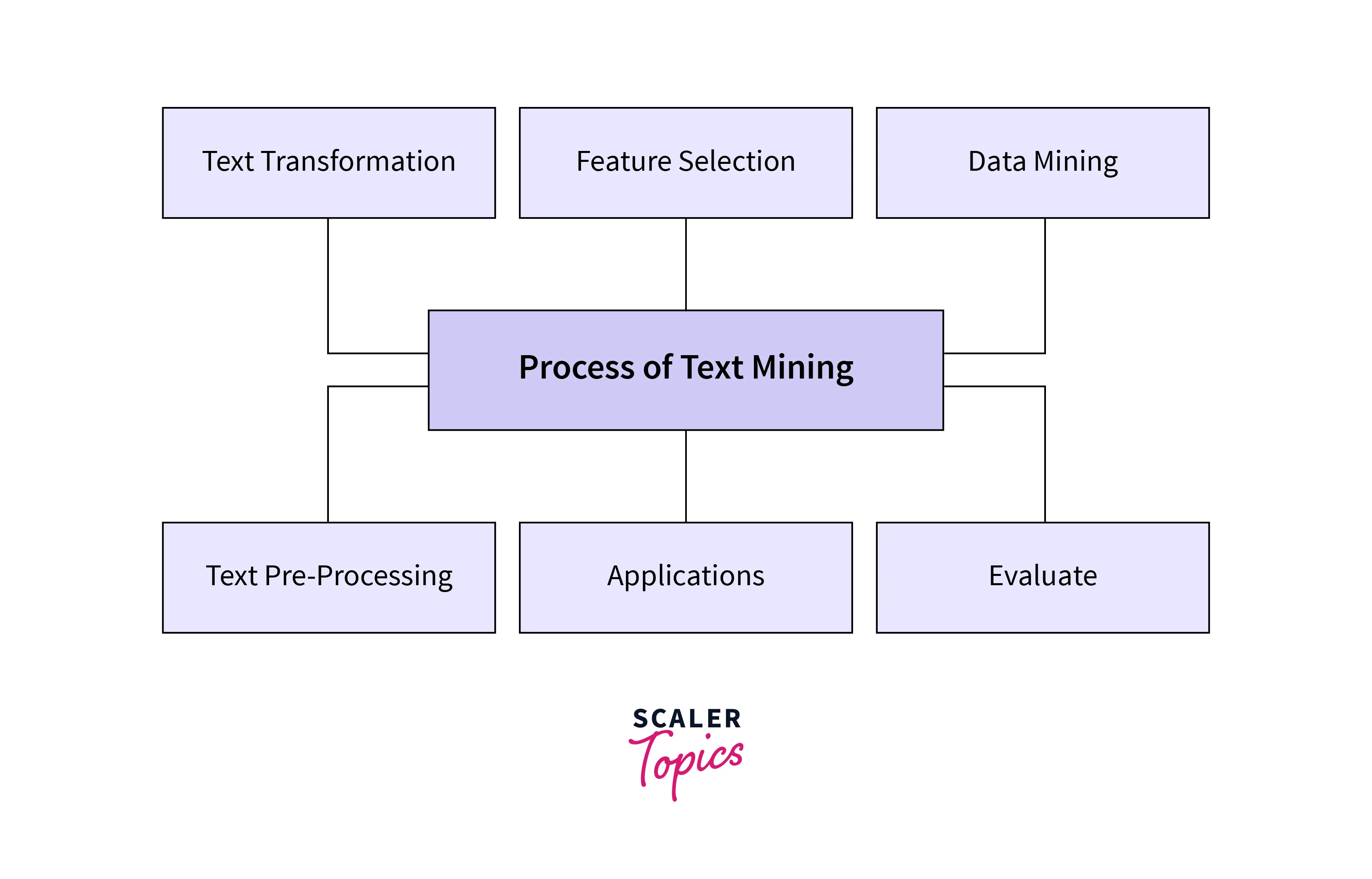
The process of text mining in data mining involves several steps, as mentioned below -
- Data Extraction - The first step in text mining is to extract the raw data from its sources, such as a document, a webpage, a social media platform, or any other source of unstructured or semi-structured text data. Data extraction involves using various techniques, such as web scraping, API calls, or manual data entry, to retrieve the relevant text data.
- Text Pre-processing - This step involves cleaning and transforming the raw text data into a structured format that can be analyzed. It includes tasks such as removing stop words, stemming, lemmatization, tokenization, and part-of-speech tagging.
- Text Representation - In this step, the pre-processed text data is transformed into a numerical format that can be analyzed using a wide range of machine learning algorithms. Various techniques, such as Bag of Words, TF-IDF, and word embeddings, can be used to represent text data.
- Text Analysis - This step involves applying statistical and machine learning techniques to analyze the text data. It includes tasks such as sentiment analysis, topic modeling, text classification, named entity recognition, and more.
- Evaluation - Once the text data is analyzed, it is necessary to evaluate the results to determine the effectiveness of the text mining techniques used. Evaluation metrics such as precision, recall, and F1 score are commonly used to assess the performance of text mining algorithms.
- Interpretation - This step involves interpreting the text analysis results to gain insights and knowledge that can be used for various applications. The insights gained from text mining can inform decision-making in various domains, such as marketing, finance, healthcare, and more.
Techniques of Text Mining
Text mining approaches or techniques refer to the various methods and algorithms used to extract insights and knowledge from unstructured text data. Here are some commonly used text-mining techniques -
- Natural Language Processing (NLP) - NLP is a subfield of artificial intelligence that deals with the interaction between human language and computers. NLP techniques are used to extract meaning from text data and include tasks such as sentiment analysis, named entity recognition, part-of-speech tagging, and more.
- Text Classification - Text classification involves assigning predefined categories or labels to text data based on their content. This technique is often used for topic modeling, spam detection, and sentiment analysis.
- Clustering - Clustering is a technique used to group similar documents or text data based on their content. This technique often identifies patterns or themes in large volumes of text data.
- Topic Modeling - Topic modeling is a technique used to extract the underlying themes or topics present in a large corpus of text data. This technique is often used in applications such as content recommendation and information retrieval.
- Sentiment Analysis - Sentiment analysis determines the sentiment or emotion in text data. This technique is often used in social media monitoring and customer feedback analysis applications.
- Named Entity Recognition - Named entity recognition is a technique used to identify and classify named entities in text data, such as people, organizations, and locations. This technique is often used in information extraction and entity-linking applications.
- Text Summarization - Text summarization is used in text mining to automatically generate a concise summary of a large text document or a collection of documents. The goal of text summarization is to distill the most important information from the text data while preserving the overall meaning and coherence of the original text.
Text Numericization
Text numericization is the process of converting text data into numerical or quantitative values that can be processed and analyzed by various statistical algorithms and ML models. Text numericization is an important step in text mining, as most machine learning algorithms require numerical data as input. Several techniques can be used for text numericization in text mining. A few of the most common approaches to performing text numericization include the following -
- Bag of Words (BoW) - The bag of words approach represents text data as a matrix of word frequencies, where each row represents a document, and each column represents a unique word in the corpus. The value in each cell represents the frequency of the word in the corresponding document.
- Term Frequency-Inverse Document Frequency (TF-IDF) - TF-IDF is a popular technique used to represent the importance of words in a document. It assigns a weight to each word based on its frequency in the document and its frequency across all documents in the corpus.
- Word Embeddings - Word embeddings are a popular technique for representing words as vectors in a high-dimensional space. The vectors are learned using neural networks and designed to capture words' semantic meaning of words. Word embeddings are often used in applications such as text classification, sentiment analysis, and information retrieval. A few of the most commonly used word embedding techniques are Word2Vec, Glove, etc.
Applications of Text Mining
Text mining in data mining has a wide range of applications across various industries and fields. Some of the common applications of text mining include the following -
- Customer feedback analysis - Text mining can be used to analyze customer feedback data from various sources such as social media, online reviews, and customer support interactions. By analyzing customer feedback, businesses can gain insights into customer needs, preferences, and sentiments toward their products or services.
- Social media analysis - Text mining can be used to analyze social media data to monitor brand reputation, track customer feedback, and understand customer behavior and sentiment towards products or services.
- Healthcare - Text mining can also be used to extract insights from medical records, clinical notes, and other healthcare data to improve patient care, identify potential drug interactions, and support clinical research.
- News analysis - Text mining can analyze a wide range of news articles to monitor ongoing trends, identify emerging issues, and understand public opinion on various topics.
- E-commerce - Text mining can analyze product reviews, customer feedback, and search queries to understand customer behavior and preferences and to improve product recommendations and marketing strategies.
- Legal analysis - Text mining can be used to analyze legal documents, case law, and other legal texts to support legal research, identify legal issues, and automate document review processes.
Advantages of Text Mining
Text mining has several advantages. A few of the most common advantages include the following -
- Enhanced customer experience - Text mining can analyze customer feedback and sentiment, providing insights into customer preferences and opinions. This can help organizations improve their products and services and enhance the customer experience.
- Competitive advantage - Text mining can provide organizations with a competitive advantage by identifying opportunities and insights.
- Improved decision-making - Text mining can uncover hidden patterns and insights within data that would be difficult to identify through manual analysis. This can help organizations to identify trends and make better-informed decisions.
- Large Volumes of Data - Text mining is highly scalable and can analyze large volumes of unstructured data, which would be impractical to analyze manually.
- Speed - Text mining can quickly identify patterns and relationships within data, allowing for faster decision-making.
- Less human errors and bias - Text mining algorithms can analyze data more objectively than humans, reducing the risk of bias and errors.
- Automation - Text mining can automate repetitive tasks such as data entry and classification, freeing time for more value-added tasks.
Disadvantages of Text Mining
Text mining in data mining also comes with several disadvantages and issues. A few of the most common issues faced with text mining include the following -
- Data quality - Text mining algorithms depend on the data quality, and unstructured data can be noisy and incomplete.
- Ambiguity and polysemy - Text data often contains words or phrases with multiple meanings, which can lead to ambiguity and polysemy. This can make it difficult for text mining algorithms to identify the intended meaning of words and phrases accurately.
- Lack of context - Text mining algorithms may not be able to capture the context or nuances of language, leading to misinterpretation of data.
- Limited domain expertise - Text mining algorithms may not have the necessary domain expertise to analyze text data in specific industries or fields accurately. This can lead to inaccurate results and a lack of valuable insights.
- Language barriers - Text mining algorithms may not be effective in analyzing data in languages other than those for which they were designed.
- Cost - Text mining software and infrastructure can be expensive, and the cost may outweigh the benefits for some organizations.
Conclusion
- Text mining in data mining is a powerful technique that enables organizations to extract valuable insights from large volumes of text data. It can automatically analyze text data, uncover hidden patterns and trends, and gain insights into customer preferences and opinions.
- Text mining in data mining has numerous applications across industries, including healthcare, finance, marketing, and social media analysis. Text mining poses several technical and practical issues, such as data quality, lack of context, cost, etc.
- While text mining poses several technical and practical issues that need to be considered, it remains an important and valuable tool for organizations seeking to gain insights from their text data.