Classification in Data Mining

Overview
Classification is a technique in data mining that involves categorizing or classifying data objects into predefined classes, categories, or groups based on their features or attributes. It is a supervised learning technique that uses labelled data to build a model that can predict the class of new, unseen data. It is an important task in data mining because it enables organizations to make informed decisions based on their data. For example, a retailer may use data classification to group customers into different segments based on their purchase history and demographic data. This information can be used to target specific marketing campaigns for each segment and improve customer satisfaction.
What is Classification in Data Mining?
Classification in data mining is a technique used to assign labels or classify each instance, record, or data object in a dataset based on their features or attributes. The objective of the classification approach is to predict class labels of new, unseen data accurately. It is an important task in data mining because it enables organizations to make data-driven decisions. For example, businesses can assign or classify sentiments of customer feedback, reviews, or social media posts to understand how well their products or services are doing.
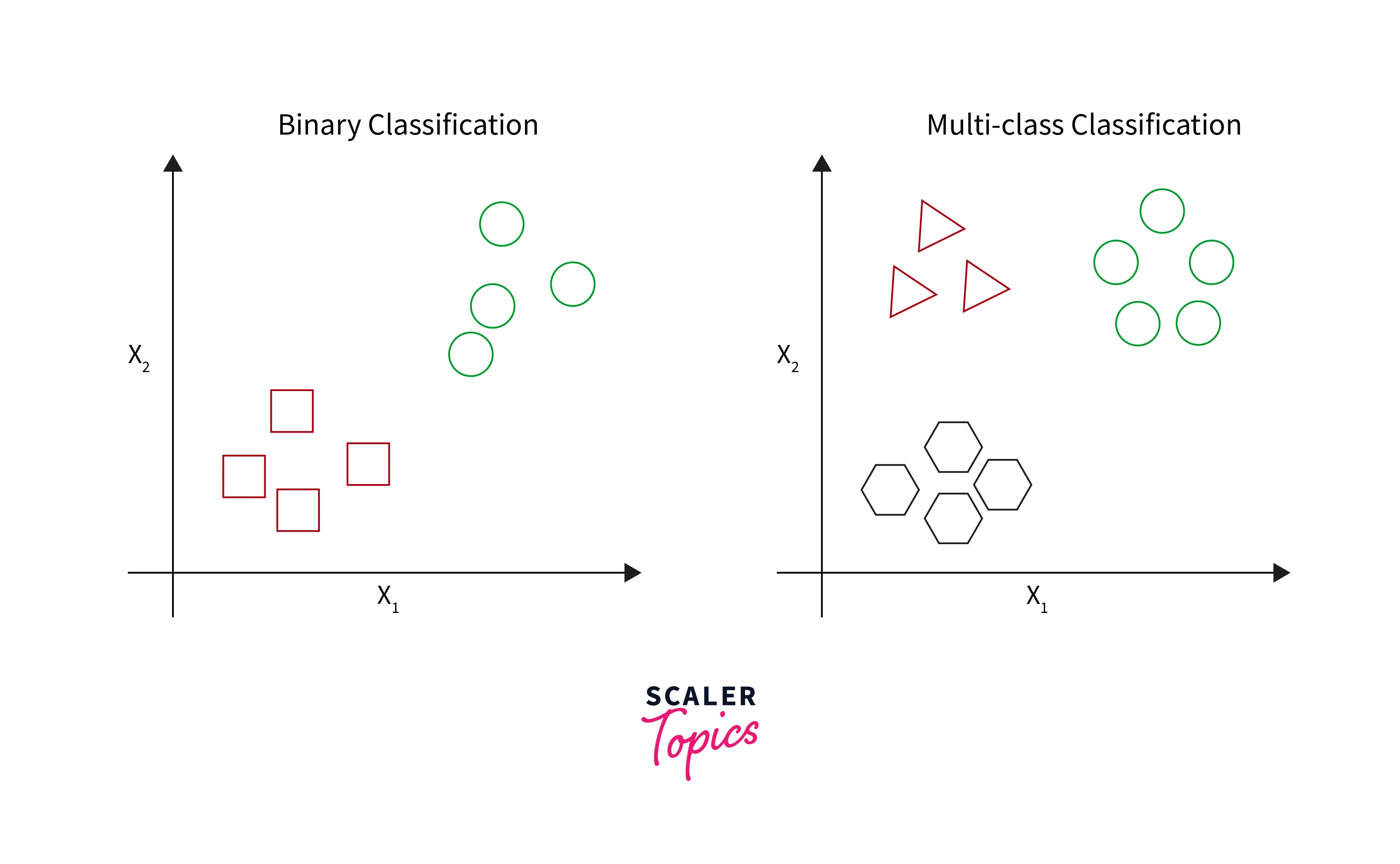
Classification techniques can be divided into categories - binary classification and multi-class classification. Binary classification assigns labels to instances into two classes, such as fraudulent or non-fraudulent. Multi-class classification assigns labels into more than two classes, such as happy, neutral, or sad.
Steps to Build a Classification Model
There are several steps involved in building a classification model, as shown below -
- Data preparation - The first step in building a classification model is to prepare the data. This involves collecting, cleaning, and transforming the data into a suitable format for further analysis.
- Feature selection - The next step is to select the most important and relevant features that will be used to build the classification model. This can be done using various techniques, such as correlation, feature importance analysis, or domain knowledge.
- Prepare train and test data - Once the data is prepared and relevant features are selected, the dataset is divided into two parts - training and test datasets. The training set is used to build the model, while the testing set is used to evaluate the model's performance.
- Model selection - Many algorithms can be used to build a classification model, such as decision trees, logistic regression, k-nearest neighbors, and neural networks. The choice of algorithm depends on the type of data, the number of features, and the desired accuracy.
- Model training - Once the algorithm is selected, the model is trained on the training dataset. This involves adjusting the model parameters to minimize the error between the predicted and actual class labels.
- Model evaluation - The model's performance is evaluated using the test dataset. The accuracy, precision, recall, and F1 score are commonly used metrics to evaluate the model performance.
- Model tuning - If the model's performance is not satisfactory, the model can be tuned by adjusting the parameters or selecting a different algorithm. This process is repeated until the desired performance is achieved.
- Model deployment - Once the model is built and evaluated, it can be deployed in production to classify new data. The model should be monitored regularly to ensure its accuracy and effectiveness over time.
Syntaxes Used
Here are some common notations and syntax used for classification in data mining -
- X - Input data matrix or feature matrix, where each row represents an observation or data point, and each column represents a feature or attribute.
- y - Output or target variable vector, where each element represents the class label or target variable for the corresponding data point in X.
- p(y|x) - Probability of class y given input x.
- θ - Model parameters or coefficients that are learned during the training process.
- J(θ) - Cost function that measures the overall error or loss of the model on the training data and is typically a function of the model parameters θ.
Categorization of Classification in Data Mining
There are different types of classification algorithms based on their approach, complexity, and performance. Here are some common categorizations of classification in data mining -
- Decision tree-based classification - This type of classification algorithm builds a tree-like model of decisions and their possible consequences. Decision trees are easy to understand and interpret, making them a popular choice for classification problems.
- Rule-based classification - This type of classification algorithm uses a set of rules to determine the class label of an observation. The rules are typically expressed in the form of IF-THEN statements, where each statement represents a condition and a corresponding action.
- Instance-based classification - This type of classification algorithm uses a set of training instances to classify new, unseen instances. The classification is based on the similarity between the training instances' features and the new instances' features.
- Bayesian classification - This classification algorithm uses Bayes' theorem to compute the probability of each class label given the observed features. Bayesian classification is particularly useful when dealing with incomplete or uncertain data.
- Neural network-based classification - This classification algorithm uses a network of interconnected nodes or neurons to learn a mapping between the input features and the output class labels. Neural networks can handle complex and nonlinear relationships between the features and the class labels.
- Ensemble-based classification - This classification algorithm combines the predictions of multiple classifiers to improve the overall accuracy and robustness of the classification model. Ensemble methods include bagging, boosting, and stacking.
Curious to See These Concepts in Action? Our Data Science Course Provides Practical Insights. Enroll and Transform Your Knowledge into Proficiency!
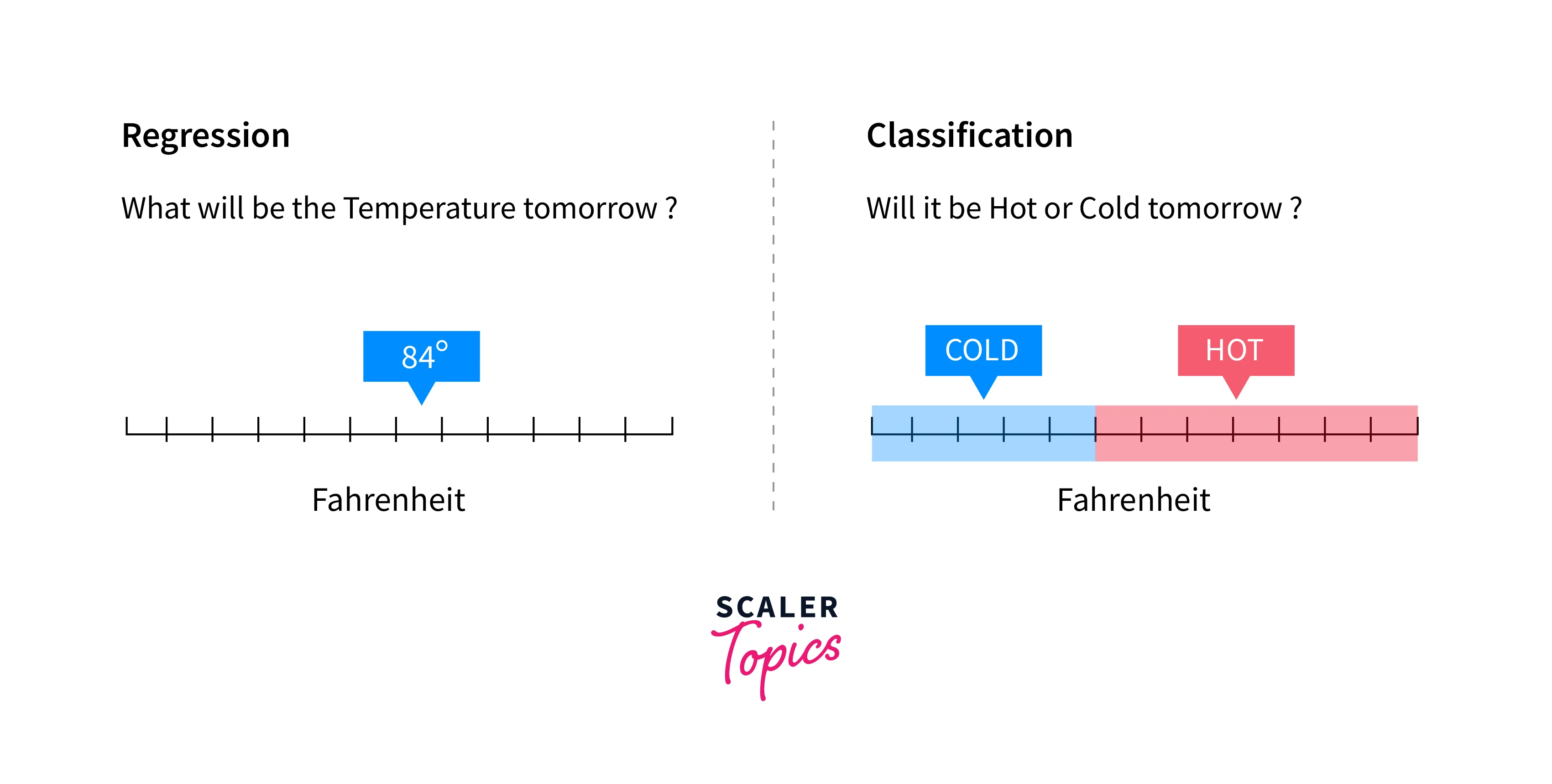
Classification Vs. Regression in Data Mining
Here are the main differences between techniques for regression and classification in the data mining process -
| Factors | Classification | Regression |
|---|---|---|
| Task/Objective | Identifying or assigning the class label of a new observation based on its features. | Estimating a continuous or discrete value for a new observation based on its features. |
| Outcome | Categorical variable, i.e., a class label or category. | Continuous or discrete variable, i.e., a numeric value. |
| Evaluation | Accuracy, precision, recall, F1 score, AUC. | Mean squared error, root mean squared error, correlation coefficient. |
| Algorithms | Decision trees, rule-based systems, neural networks, support vector machines, k-nearest neighbors. | Linear regression, logistic regression, polynomial regression, time series analysis, neural networks. |
| Examples | Spam email classification, sentiment analysis, fraud detection, etc. | Housing price prediction, stock price prediction, predicting a customer's purchase amount or sale, etc. |
Issues in Classification and Regression Techniques
Classification and regression are two important tasks in data mining. They involve predicting a new observation's class label or numeric value based on its features or attributes. Here are some issues related to regression and classification in data mining -
- Data quality - The accuracy and effectiveness of classification and regression techniques heavily depend on data quality. Noisy, incomplete, or inconsistent data can lead to poor classification or regression models.
- Overfitting - Overfitting occurs when a classification or regression model is too complex and fits the training data too closely, leading to poor performance on new, unseen data. To address overfitting, various techniques such as regularization, early stopping, and cross-validation can be used.
- Bias - Bias refers to the tendency of a model to make errors in its predictions consistently. This can happen if the model is too simple or lacks enough data to learn from. It is also called the underfitting of ML models.
- Imbalanced data - In classification, imbalanced data occurs when one class label is much more prevalent than the others, leading to biased classification. To address imbalanced data, various techniques such as resampling, cost-sensitive learning, and ensemble methods can be used.
- Interpretability - Interpretability refers to the ability to understand and explain the decisions made by a classification or prediction model. Some methods, such as decision trees, linear regression, logistic regression, etc., are more interpretable than others, such as neural networks, support vector machines, etc.
Real-Life Examples
There are many real-life examples and applications of classification in data mining. Some of the most common examples of applications include -
- Email spam classification - This involves classifying emails as spam or non-spam based on their content and metadata.
- Image classification - This involves classifying images into different categories, such as animals, plants, buildings, and people.
- Medical diagnosis - This involves classifying patients into different categories based on their symptoms, medical history, and test results.
- Credit risk analysis - This involves classifying loan applications into different categories, such as low-risk, medium-risk, and high-risk, based on the applicant's credit score, income, and other factors.
- Sentiment analysis - This involves classifying text data, such as reviews or social media posts, into positive, negative, or neutral categories based on the language used.
- Customer segmentation - This involves classifying customers into different segments based on their demographic information, purchasing behavior, and other factors.
- Fraud detection - This involves classifying transactions as fraudulent or non-fraudulent based on various features such as transaction amount, location, and frequency.
Decision Tree Method
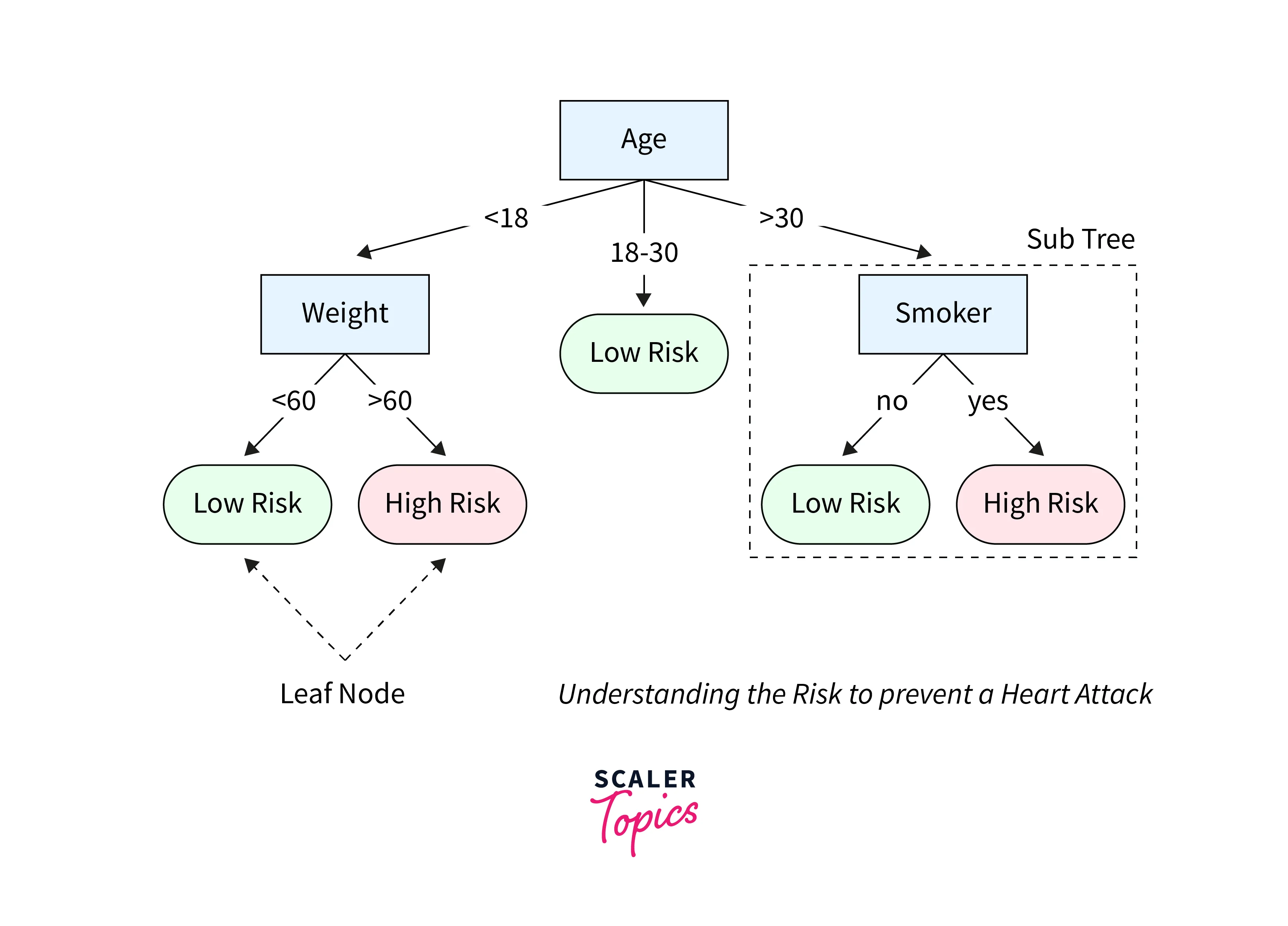
Decision tree-based classification methods are a type of machine learning technique that builds a tree-like model to classify new data points based on their features. The goal of decision tree-based classification is to create a model that accurately predicts the class label of a new observation by dividing the data into smaller and smaller subsets, each characterized by a set of features.
The decision tree is built using training data, with a set of features and a known class label representing each data point. The tree is constructed by recursively splitting the data based on the most informative feature until the subsets become homogeneous concerning class labels or a stopping criterion is met. At each split, the feature that best separates the data is selected based on a criterion such as information gain or Gini index. Once the decision tree is built, it can be used to classify new data points by traversing the tree based on the values of their features until reaching a leaf node corresponding to a class label.
Some common decision tree-based classification methods include C4.5, CART, Random Forests, XGBoost, etc.
Support Vector Machines
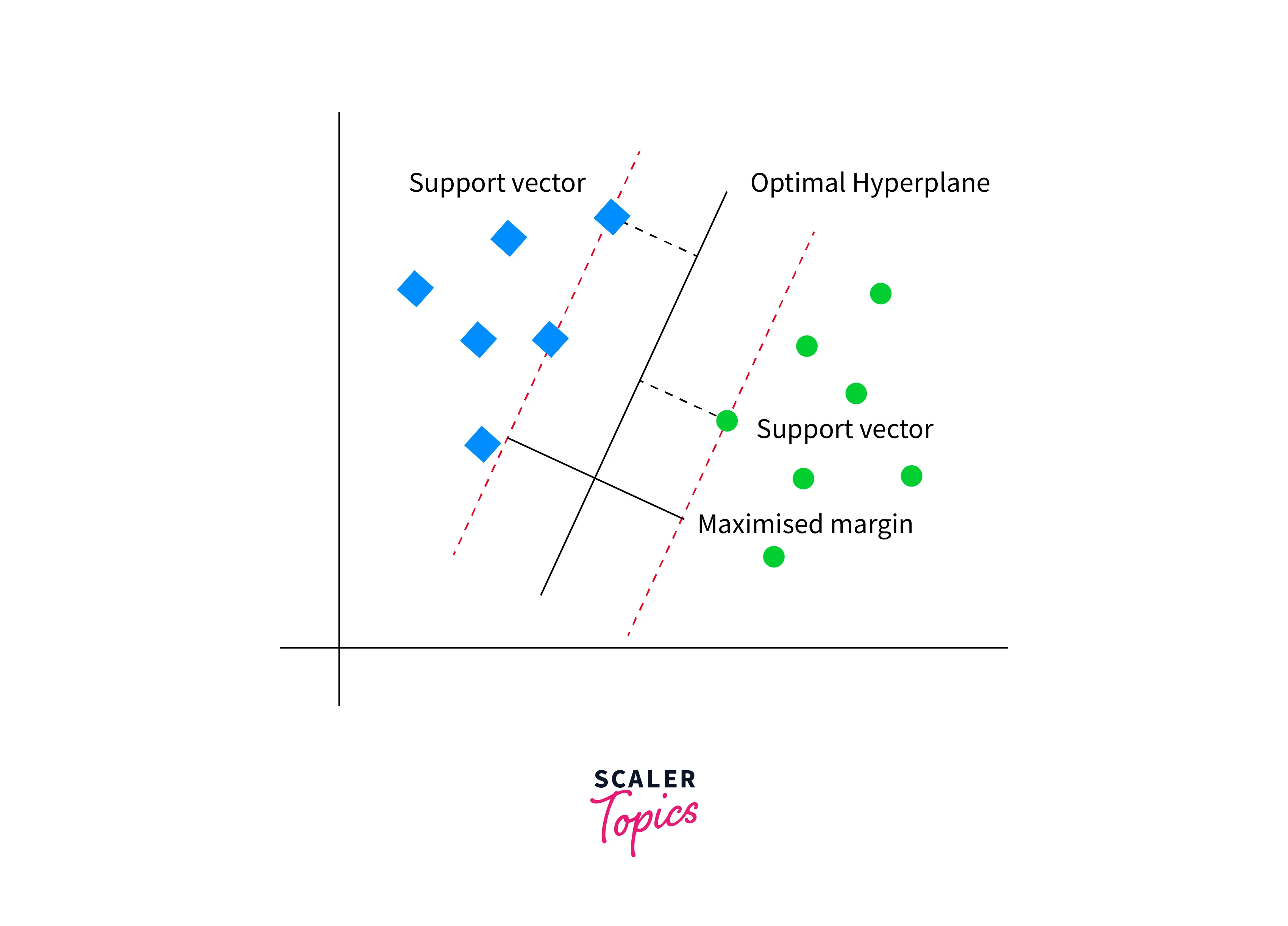
Support Vector Machine (SVM) is a powerful machine learning algorithm for classification and regression analysis. In classification, SVM seeks to identify a hyperplane in a high-dimensional space that optimally separates the data points of different classes. The hyperplane is chosen to maximize the margin between the two classes, which is defined as the distance between the closest data points of each class.
To determine the hyperplane that maximizes the margin, SVM solves a constrained optimization problem that minimizes the classification error subject to the constraint that the data points lie on the right side of the hyperplane. SVM also can deal with high-dimensional data and can handle a large number of features. However, SVMs can be computationally expensive for large datasets and suffer from overfitting if not properly regularized.
Advantages and Disadvantages
The advantages of classification in data mining include -
- Automation - Classification allows for the automation of data processing, making it easier to handle large datasets and reducing the need for manual data entry.
- Predictive power - By learning patterns from historical data, classification models can predict the class of new data points with high accuracy.
- Interpretability - Some classification models, such as decision trees, can be easily interpreted, providing insights into the factors that influence the class labels.
- Scalability - Classification algorithms can scale to large datasets and high-dimensional feature spaces.
- Versatility - Classification can be applied to various problems, including image and speech recognition, fraud detection, and spam filtering.
Several disadvantages are also associated with the classification in data mining, as mentioned below -
- Data quality - The accuracy of classification models depends on the data quality used for training. Poor quality data, including missing values and outliers, can lead to inaccurate results.
- Overfitting - Classification models can be prone to overfitting, where the model learns the noise in the training data rather than the underlying patterns, leading to poor generalization performance.
- Bias - Classification models can be biased towards certain classes if the training data is imbalanced or the model is designed to optimize a specific metric.
- Interpretability - Some classification models, such as neural networks, can be difficult to interpret, making it hard to understand how the model arrives at its predictions.
- Computational complexity - Some classification algorithms, such as support vector machines and deep neural networks, can be computationally expensive and require significant training computing resources.
FAQs
Q: What is classification in data mining?
A: Classification is a fundamental task in data mining that involves predicting the class label or category of an observation or data point based on its features or attributes.
Q: What are the different kinds of classification techniques?
A: Classification techniques can be divided into two categories - binary classification and multi-class classification. Binary classification assigns labels to instances into two classes, while multi-classification assigns labels to more than two classes.
Q: How is classification different from regression?
A: Classification involves predicting or classifying the labels for a given data instance, while regression is used to predict a numeric value for a given data instance. For example, fraud detection is a classification task, while predicting house prices is a regression task.
Data science is more than just numbers; it's about understanding trends and predicting outcomes. Enroll in our free Data Science course and become a data visionary.
Conclusion
- Classification in data mining is a key technique that involves predicting the class of new data points based on historical data.
- Classification algorithms learn patterns from labeled data and use these patterns to assign new data points to specific classes. This technique has numerous applications in fields such as image and speech recognition, marketing, e-commerce, fraud detection, and spam filtering.
- There are several popular classification algorithms, such as decision trees, random forests, k-nearest neighbors, and support vector machines, each with its strengths and weaknesses.
- While classification is a powerful tool for automating data processing and making predictions, it requires careful consideration of data quality, overfitting, bias, interpretability, and computational complexity to ensure accurate and useful results.