Credit Card Fraud Detection Project in Data Mining
Overview
The Credit Card Fraud Detection Project in Data Mining involves building a system that accurately identifies and flags fraudulent credit card transactions. Credit card fraud is a common problem in the financial industry, and it can result in significant financial losses for both the card issuer and the cardholder.
What are we Building?
In the Credit Card Fraud Detection Project in Data Mining, we are building an automated system to accurately identify and flag fraudulent credit card transactions by analyzing various credit card transaction features, such as time, amount, etc. The Credit Card Fraud Detection Project in Data Mining is important for preventing financial losses and maintaining trust in the credit card industry by accurately detecting fraudulent transactions. It also contributes to the development of more secure and trustworthy financial transactions for all stakeholders.
Description of Problem Statement
In this project, we will use a credit card transaction dataset. You can download this dataset using this link. It consists of features for around 280K credit card transactions and their respective labels. The feature class represents whether the given credit card transaction is fraudulent or not. The project aims to develop an automated system to detect fraudulent transactions by analyzing various features such as transaction amount, time, etc.
Pre-requisites
- Python Programming Language
- Statistics
- Data Mining
- Machine Learning
- Data Cleaning
- Data Preprocessing
- Data Visualization
How are we Going to Build this?
- First, we will check whether the dataset contains any missing values or outliers. If these are present, will perform appropriate methods to handle outlier and missing values.
- Then, in the exploratory data analysis (EDA) stage, we will apply various visualization techniques to detect underlying patterns and trends to derive valuable insights.
- Further, we will perform training and development of multiple ML models, such as Decision Tree, Logistic Regression, etc., and compare their performance.
Requirements
We will be using below libraries, tools, and modules in this project:
- Pandas
- Matplotlib
- Seaborn
- Sklearn
Dataset Feature Descriptions
The description for each feature available in this dataset is:
- time: the time of transactions.
- V1 - V28: various attributes of credit card transactions.
- amount: amount involved in credit card transactions.
- class: whether the given credit card transaction is fraudulent (1) or not (0).
Main Challenges Involved in Credit Card Fraud
Here are some of the challenges involved in the Credit Card Fraud Detection Project:
- Enormous amount of data:
Handling and processing large amounts of data in a timely and efficient manner. - Imbalanced dataset:
Addressing the issue of imbalanced classes in the dataset, where most transactions are genuine, and a small percentage are fraudulent. - Data availability due to privacy concerns:
Obtaining access to sensitive data while respecting privacy regulations and maintaining data confidentiality. - Adaptive techniques used by scammers:
Dealing with scammers who are constantly evolving and adapting their fraudulent techniques to avoid detection by the system.
Here are a few of the ways to tackle above mentioned challenges:
- The developed ML model should not be complex and should be able to flag fraudulent transactions in real time.
- Implement techniques such as oversampling, undersampling, etc., to address the class imbalance problem.
- Use data anonymization techniques to ensure data confidentiality or reduce the dimensions of data while still maintaining the usefulness of the data.
Building the Credit Card Fraud Detection Project
The Data
-
Let’s start the project by importing all necessary libraries to load the dataset, perform EDA, and build ML models.
-
Let’s load the dataset in the pandas dataframe and explore variables and their data types.
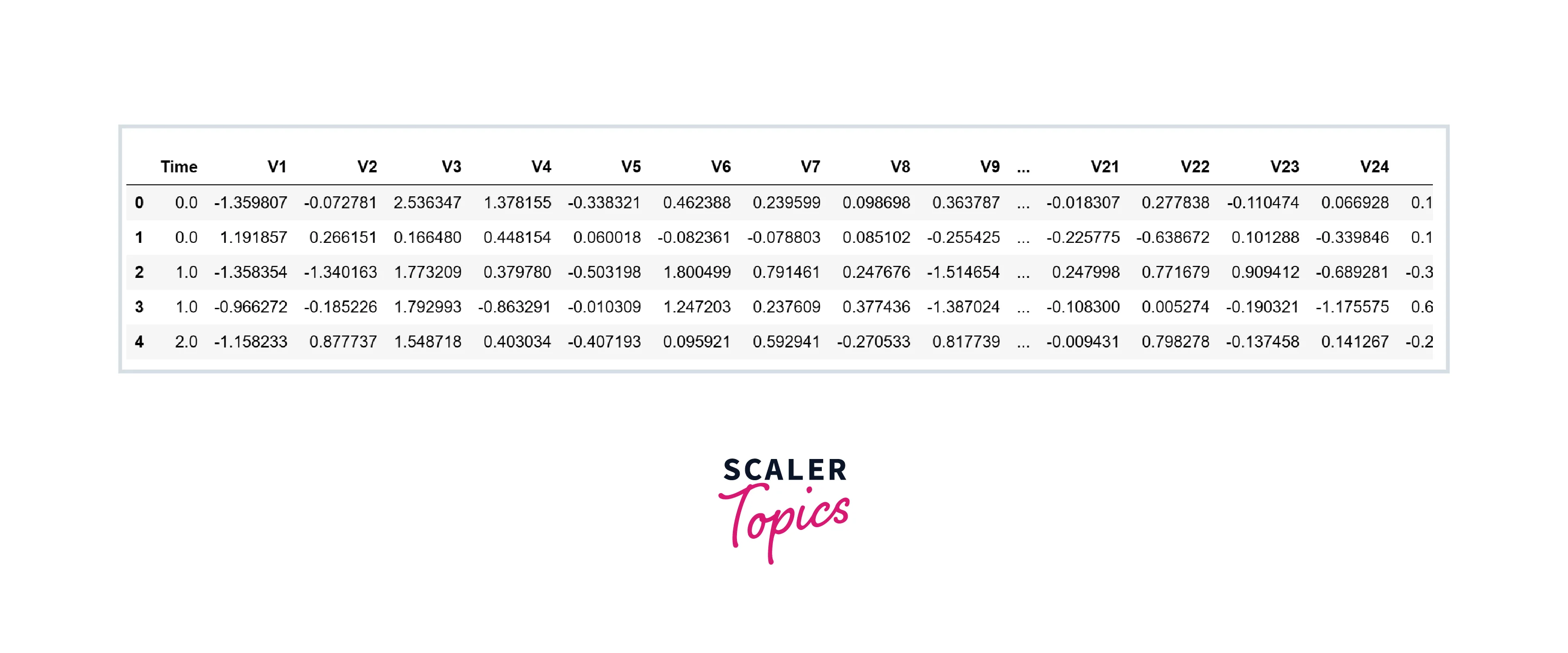
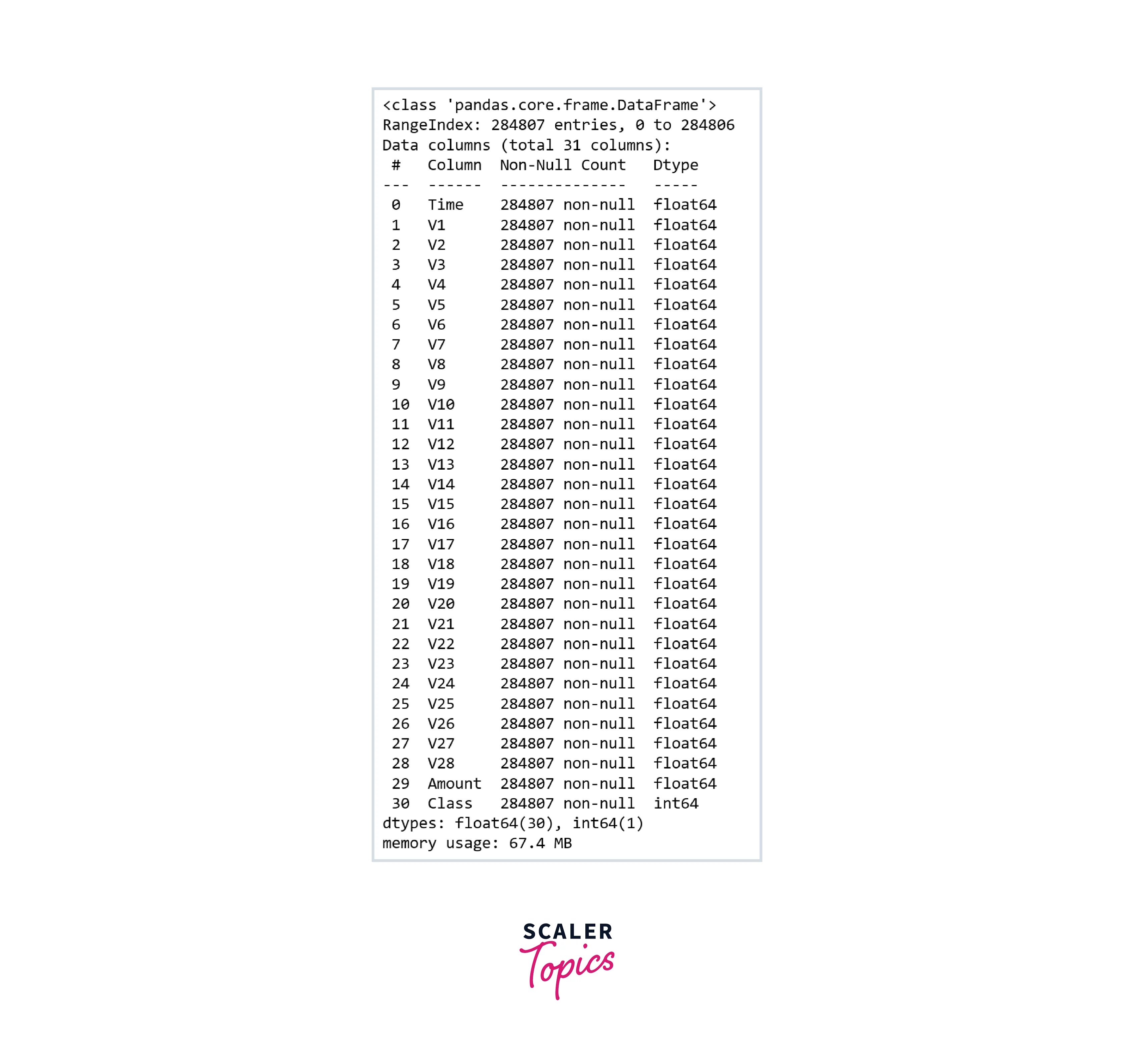
-
As we can see in the below figure, this dataset has 31 features and none of them contains the NULL or missing values.
-
Now, we will check the distribution of each class in the dataset. As you can see below, this dataset is highly imbalanced. Only 1% of records correspond to fraudulent credit card transactions, and the rest of the records are non-fraudulent.
Output:
Analyze Amount Feature of Credit Card Transactions
-
In this step, we analyze amounts of credit card transactions using a box plot. As you can see in the figure below, the amount of fraudulent transactions is generally higher than clean or non-fraudulent transactions.
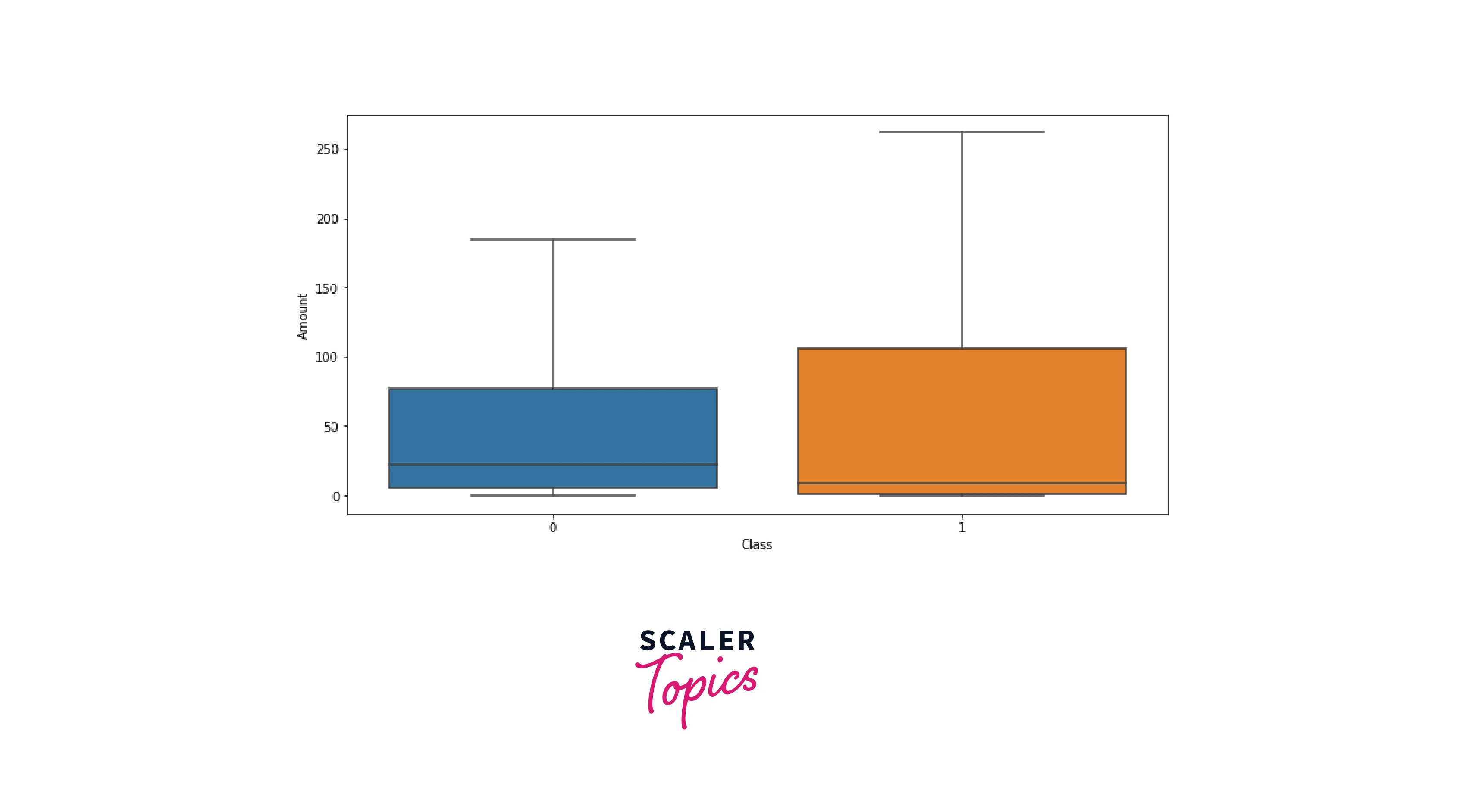
Plotting Correlation Matrix
-
In this step, we will print the correlation matrix of the dataset, as mentioned below.
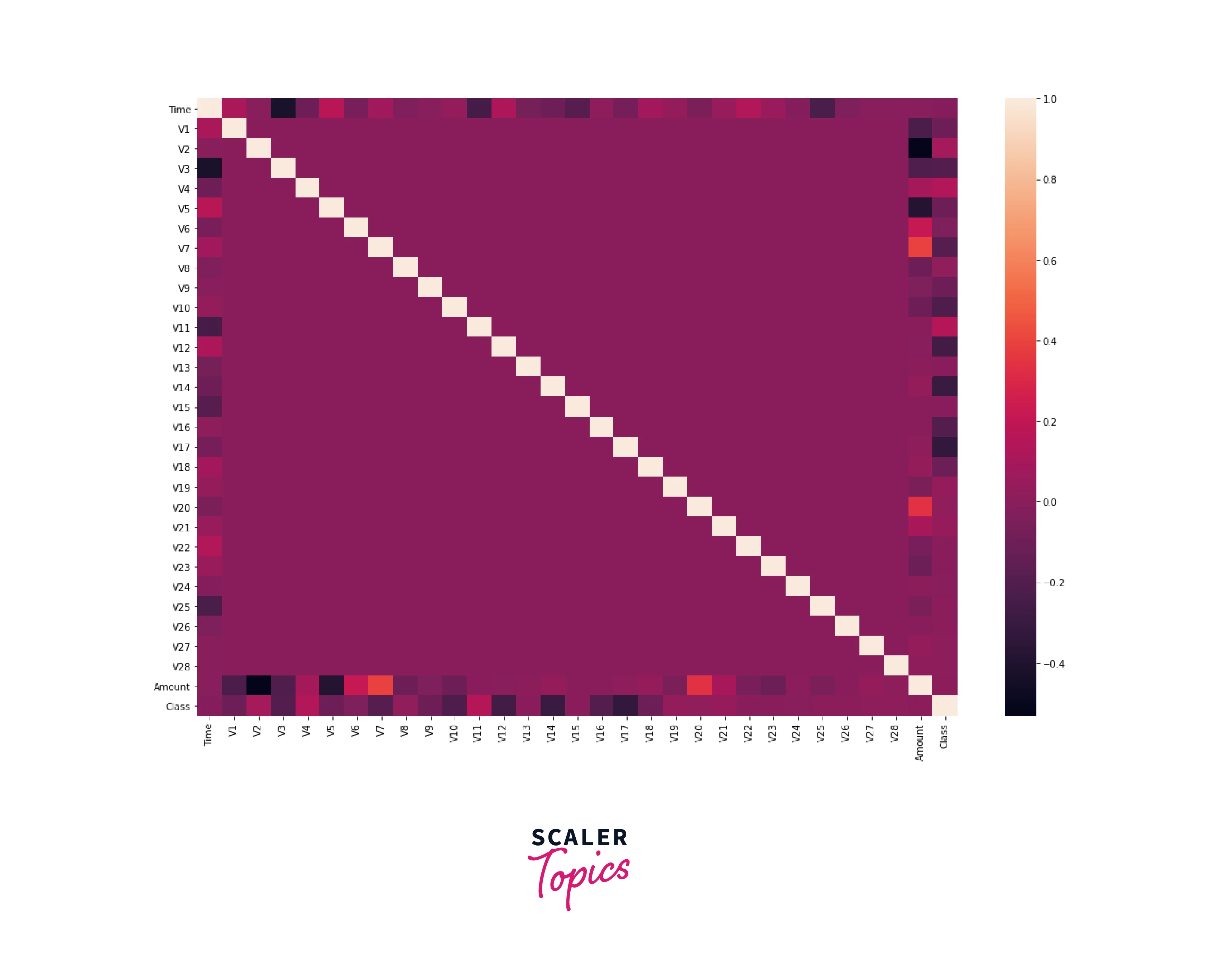
-
As you can see in the above correlation heatmap most of the features are not correlated with each other, but some features, such as V2 and V5 are negatively correlated with the amount of credit card transactions. Similarly, features V7 and V20 have a positive correlation with the amount of credit card transactions.
Train - Test Split
-
Before developing the ML models, we will split the dataset to create training and test datasets.
Using Scikit Learn to Build a Random Forest Model
-
In this step, we will train and develop a Random Forest Model to detect fraudulent credit card transactions. Random Forest is an ensemble learning algorithm in machine learning that builds multiple decision trees and combines their predictions to make more accurate and stable predictions. Each tree in the forest is built using a random subset of features and training samples to reduce overfitting. The final prediction is made by averaging or taking the majority vote of the individual tree predictions.
-
As we can see in the above figure, the F1 score is 79.7% and the precision is 84.05%. It means that Random Forest is doing a good job of detecting fraudulent credit card transactions. Let’s plot the confusion matrix for the trained Random Forest Classifier model.
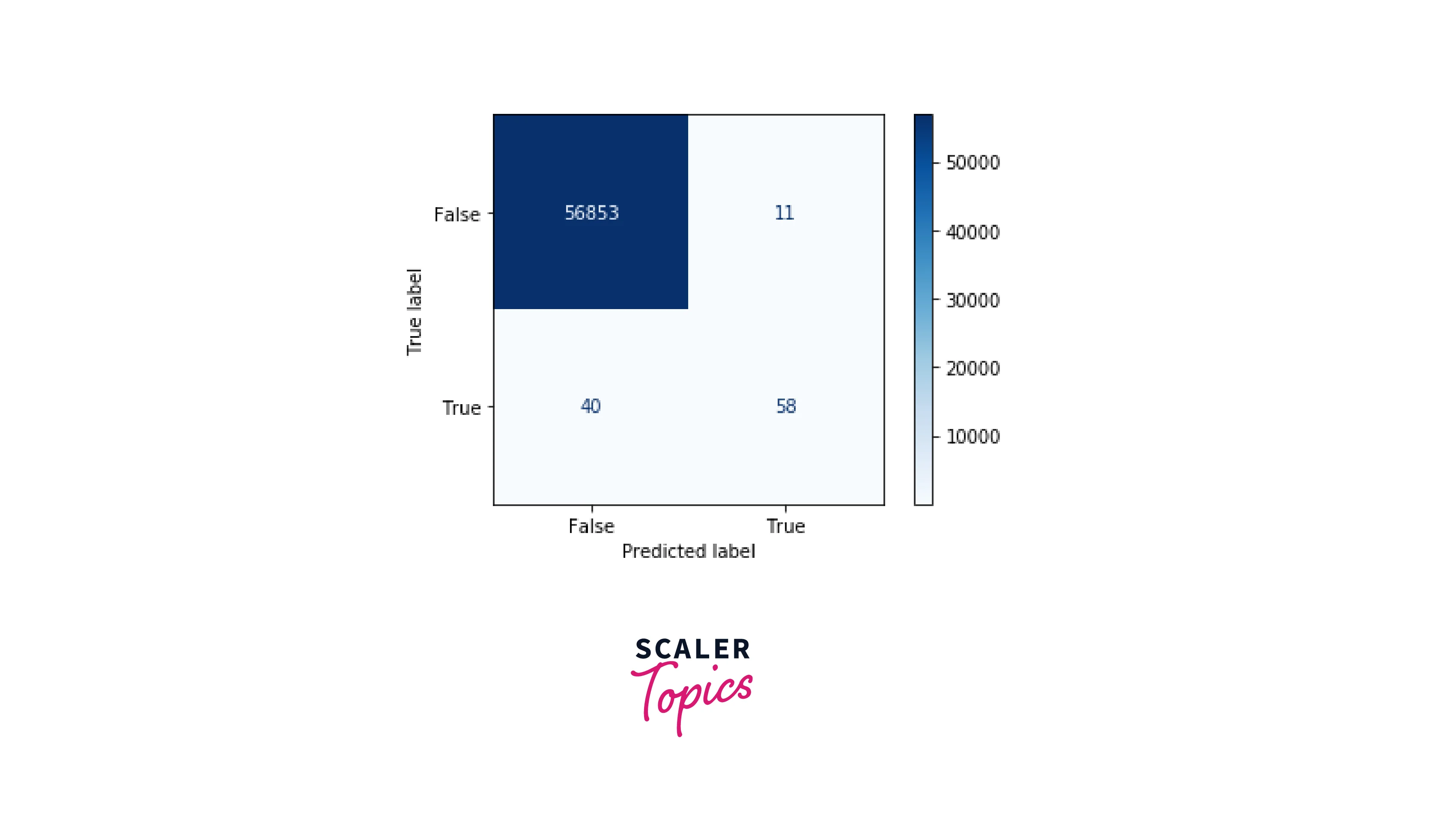
What’s Next?
- You can train different ML models, such as XGBoost, Logistic Regression, Decision Tree, etc., and explore their accuracy, precision, and F1 score for detecting fraudulent transactions.
- You can also apply methods to handle class imbalance and explore how it impacts the final accuracy of the ML models.
Conclusion
- We explored the dataset using box plots and correlation heatmap. We concluded that average amounts are higher in fraudulent credit card transactions.
- We trained and developed the Random Forest ML model with an F1 score and precision of 79.7% and 84.05%, respectively.