Differences between Data Mining, Data Science and Data Engineering
Overview
Data mining, Data science, and Data engineering are three distinct fields within data management and analysis. While they may seem similar, they differ significantly in their approaches, goals, and outcomes. Data mining involves identifying patterns and relationships within large datasets to extract insights and inform decision-making. On the other hand, data science encompasses the entire data lifecycle, from collection to analysis to visualisation, focusing on developing models and algorithms to make sense of complex data. Finally, data engineering involves designing, building, and maintaining the infrastructure to support data-driven applications and systems. Understanding the differences between these fields is crucial for anyone who wants to make a career in any of these fields.
Data Mining
Data mining is the process of extracting valuable insights and patterns from large datasets. It involves using statistical and computational techniques to identify relationships, trends, and patterns in data that can be used to inform business decisions. Data mining is used in various industries, including finance, healthcare, retail, and marketing, to help organizations identify new opportunities and optimize their operations.
One example of data mining in action is in the healthcare industry, where it is used to analyze patient data and identify potential risk factors for certain conditions. For instance, data mining can identify patients at a higher risk of developing diabetes based on their age, weight, and other health factors. This information can then be used to develop targeted prevention and treatment strategies to reduce the risk of developing diabetes.
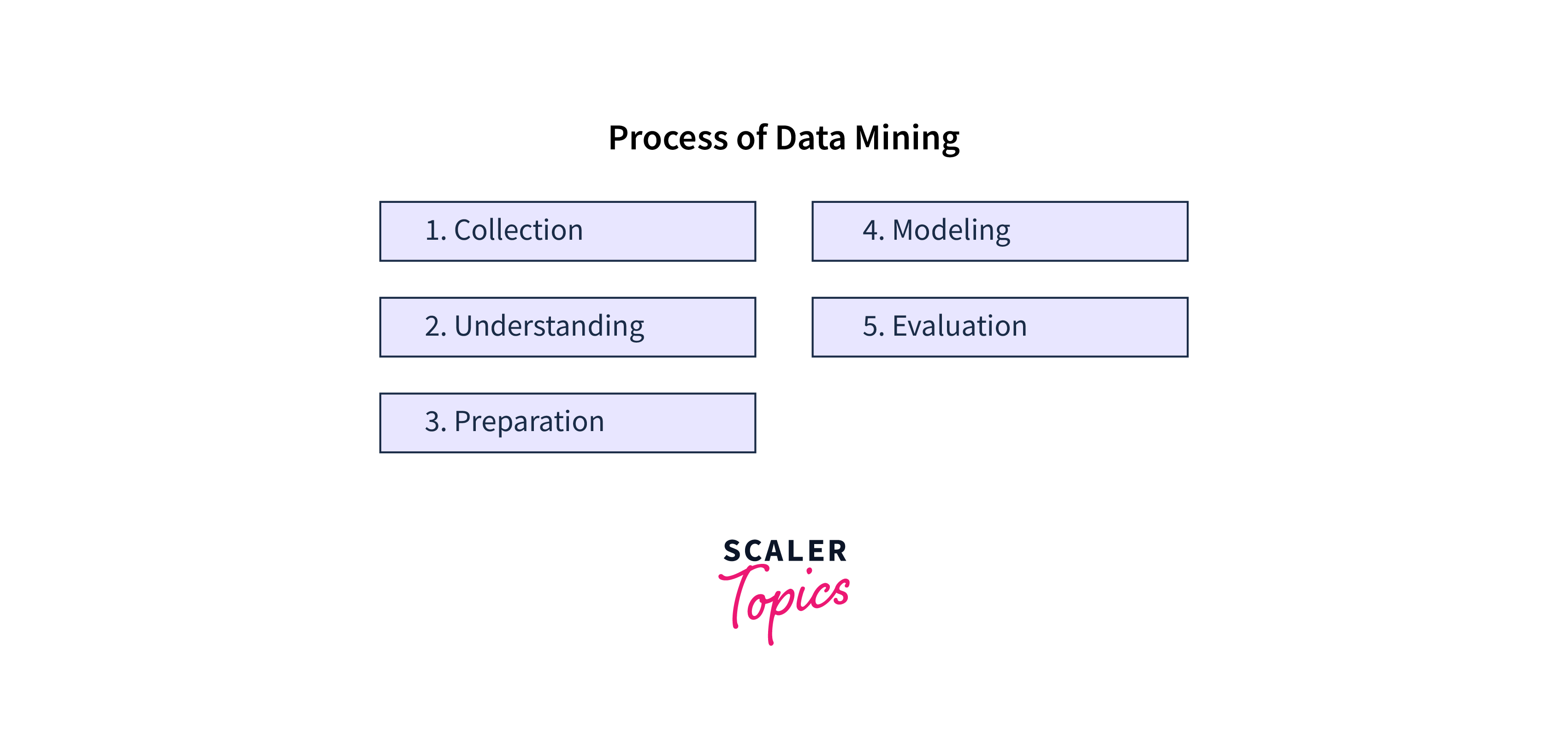
While data mining shares some similarities with other fields, such as data science and data engineering, it differs in its focus and approach. Data mining is primarily concerned with identifying patterns and relationships within data rather than with the entire data lifecycle or with the design and maintenance of data infrastructure.
Data Science
Data science is a multidisciplinary field that involves collecting, analyzing, and interpreting large datasets. It encompasses a broad range of skills, including statistics, machine learning, programming, and data visualization. Data scientists use these skills to extract insights from data and develop predictive models that can be used to make informed decisions.
One example of data science in action is in the field of e-commerce, where it is used to analyze customer behaviour and make personalized product recommendations. By analyzing data such as purchase history, browsing behaviour, and demographic information, data scientists can develop algorithms that predict which products a customer is most likely to be interested in. These recommendations can then be used to improve the customer experience and increase sales.
While data science shares some similarities with data mining and data engineering, it differs in its focus on the entire data lifecycle, from collection to analysis to visualization. Data science is concerned with developing models and algorithms that can be used to make predictions and automate decision-making processes.
Data Engineering
Data engineering is the field of designing, building, and maintaining the infrastructure needed to support data-driven applications and systems. This includes data storage, processing, retrieval systems, data pipelines, and ETL (extract, transform, load) processes. Data engineers are responsible for ensuring that data is collected, stored, and processed efficiently, securely, and at scale.
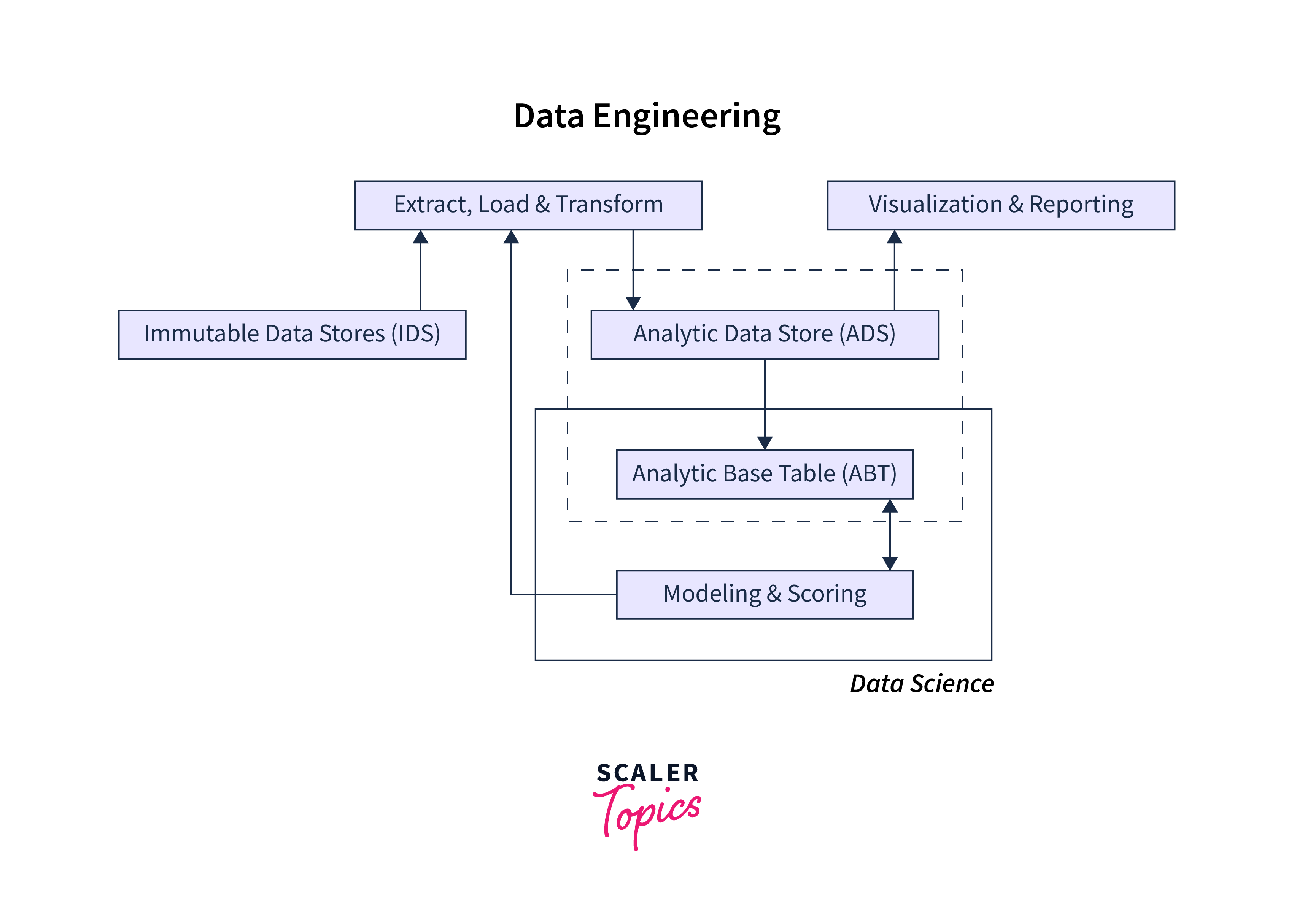
One example of data engineering in action is in the field of online advertising, where it is used to process and analyze vast amounts of data in real time. For instance, data engineers may be responsible for designing and maintaining systems that process and store ad impressions, click-through rates, and conversion data. This data can then be used to optimize ad targeting and bidding strategies in real-time, improving the effectiveness of advertising campaigns.
While data engineering shares some similarities with data mining and data science, it differs in its focus on building and maintaining the underlying infrastructure needed to support data-driven applications and systems. Data engineers often work closely with software engineers and database administrators to design and implement scalable, reliable, and secure data pipelines and storage systems. This requires a deep understanding of distributed computing systems, database design, and software engineering principles.
Differences between Data Mining, Data Science and Data Engineering
Here is the comparison of data mining vs data science vs data engineering in the table shown below -
| Factor | Data Mining | Data Science | Data Engineering |
| Objective | Identifying patterns and relationships in data | Developing predictive models and automating decision-making processes | Designing, building, and maintaining data infrastructure |
| Techniques | Data visualization, statistical and computational techniques such as clustering, classification, and association rule mining | Machine learning, statistical modelling, programming, etc. | Database design, distributed computing, ETL, etc. |
| Focus | Informing decision-making in real-time and knowledge discovery | The entire data lifecycle from collection to analysis to visualisation | Building and maintaining the underlying infrastructure needed to support data-driven applications and systems |
| Examples | Healthcare risk assessment, fraud detection | Personalized product recommendations, predictive maintenance, customer churn analysis | Real-time data processing, data pipeline design |
| Skills Required | Statistical analysis, data visualization, programming, machine learning | Programming, statistical theory, machine learning, data visualization | Database design, distributed computing, software engineering |
Conclusion
- While data mining, data science, and data engineering share some similarities, each field has its unique focus and set of techniques.
- Data mining is focused on identifying patterns and relationships within data, while data science is focused on developing predictive models and making informed decisions using data. On the other hand, data engineering focuses on building and maintaining the infrastructure needed to support data-driven applications and systems.
- Organizations looking to leverage their data to drive business value should understand the differences between these fields and build teams with the appropriate skills and expertise.
- As data continues to play an increasingly important role in decision-making across industries, the demand for professionals with skills in data mining, data science, and data engineering is likely to continue to grow.