Detecting Phishing in Data Mining
Overview
Detecting phishing in data mining refers to the application of data mining techniques and algorithms to identify and classify instances or patterns indicative of phishing attacks. Phishing is a malicious activity where attackers impersonate legitimate entities to deceive users into providing sensitive information, such as passwords, credit card details, or personal data. This project aims to detect phishing URLs using data mining techniques. Phishing attacks have become increasingly common and sophisticated, and detecting phishing URLs has become a critical task in cybersecurity. We will collect a dataset of URLs labeled as clean or phishing, preprocess the data to extract relevant features, and train the model on this data. The model will be evaluated using various metrics such as accuracy, precision, recall, and F1-score.
What are We Building?
In this project, we are building a machine learning-based system that can help in detecting phishing URLs in data mining. Phishing attacks are a common form of cyber attack in which attackers use various social engineering tactics to trick users into revealing sensitive information such as passwords, credit card numbers, and other personal information.
Description of Problem Statement
In this project, we will use a phishing URL dataset that can be downloaded from here. It consists of around 550K URLs and their respective labels. The feature Label represents whether or not the URL is a phishing URL. The project aims to develop a machine learning-based system that can detect phishing URLs by analyzing their content.
Pre-requisites
- Python
- Data Visualization
- Data Mining
- Data Cleaning and Preprocessing
- Natural Language Processing
- URL Parsing
- Machine Learning
Overview of Phishing in Data Mining
Phishing is a type of cyber attack in which attackers use social engineering tactics to trick users into revealing sensitive information such as passwords, credit card numbers, and other personal information. Phishing attacks are becoming increasingly common and sophisticated, making it crucial to have effective phishing detection mechanisms in place.
Detecting phishing in data mining is an important area of research as it can help prevent individuals and organizations from falling victim to phishing attacks. Using various data mining techniques to detect phishing attacks, it is possible to identify and block phishing emails and URLs before they reach their intended targets, reducing the risk of compromised sensitive information.
How Are We Going to Build This?
- First, we will collect data and address any missing values or outliers present in the dataset.
- Further, we preprocess URLs by extracting information such as the domain, path, and top-level domain (TLD).
- After preprocessing URLs, we compute various features, such as the length of URLs and the count of subdomains.
- Further, we tokenize the domain and path sections of the URL for further analysis.
- We train multiple machine learning models, such as Logistic Regression and Decision Tree, to develop an effective phishing detection system and compare their performance.
Requirements
We will be using below libraries, tools, and modules in this project -
- Pandas
- NLTK
- Tldextract
- Urllib
- Matplotlib
- Seaborn
- Sklearn
Implementation of Detecting Phishing in Data Mining
Data Collection
- To begin the project, we will import all the required libraries for loading the dataset, conducting exploratory data analysis (EDA), and constructing machine learning models.
- Now, we load the dataset into a Pandas data frame and examine the variables and their corresponding data types.

- As shown in the figure below, this dataset contains only 2 features (URL and Label), and none of them contain the NULL or missing values.

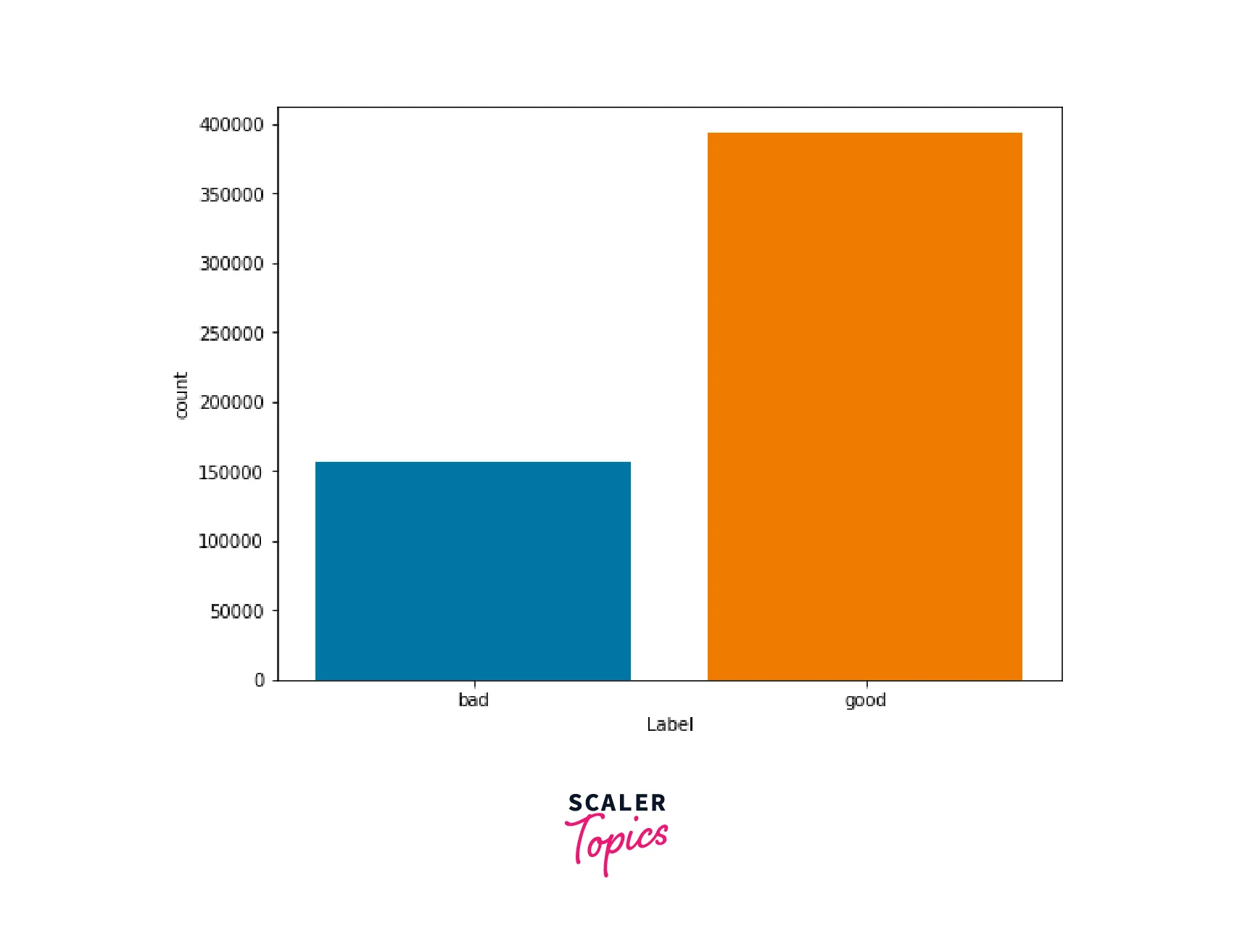
- Next, we will examine the distribution of each class in the dataset. As shown below, there is an imbalance between the two classes, with one class accounting for 72% and the other for 28% of the data. In the following step, we will preprocess the URLs for further analysis.

Data Preprocessing
- In this step, we will preprocess the given URL and extract various entities, such as scheme, network location, path, parameters, query, and fragment.
Feature Engineering
- In this step, feature engineering refers to selecting and transforming relevant information from the raw dataset of URLs to create a set of features that can be used to train a machine-learning model for detecting phishing URLs. This involves extracting characteristics such as the length of URLs, the presence of specific characters or keywords, the number of subdomains, and other relevant indicators that can distinguish between clean and phishing URLs.
- Feature engineering is a crucial step in the machine learning pipeline as it helps to create a robust and accurate model. By selecting the right features, we can improve the model's performance and increase its ability to identify phishing URLs accurately.
- Let’s create various features on the URL, its domain, and its path, as shown below -
- Now, we will create tokens from the domain and path of the given URL, as shown below. We will not consider the TLD of the domain, as it has already been computed as an additional feature.
- We will remove URL, netloc, scheme, path, query, fragment, and params features, as other features have already been engineered from these.
Model Training, Evaluation, and Prediction
- First, we will train a logistic regression model and evaluate its performance. In this project, we will use precision and recall to compare and evaluate the performance of the ML models.
- We will create a pipeline using sklearn. pipeline to prepare for training the machine learning model, taking into account the unique processing requirements for numerical, categorical, and tokenized features.
- Now, let’s define a function to display the model score, its metrics, and the confusion matrix.
- Now, let’s train a Logistic Regression ML model and check its performance.
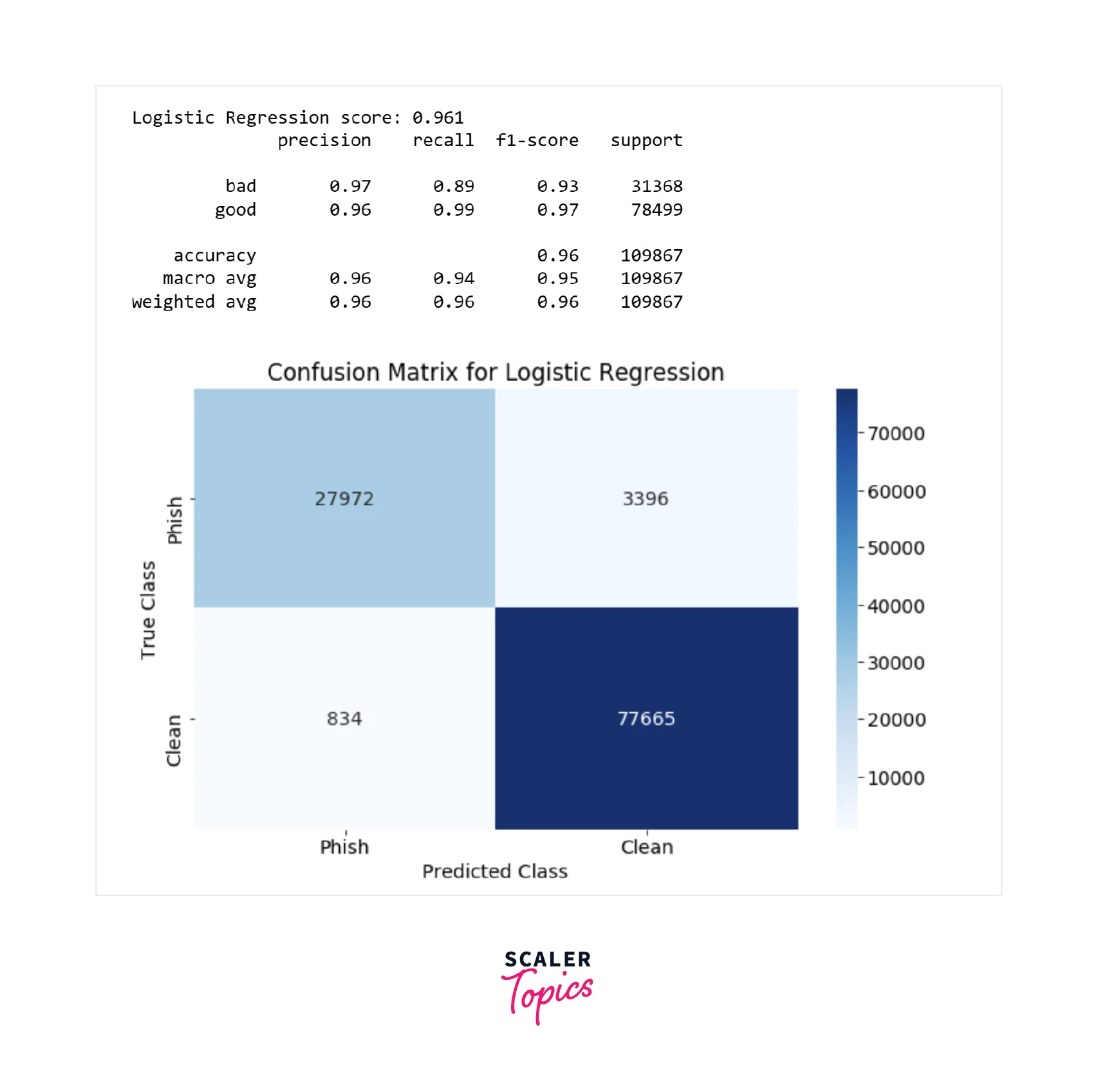
- As shown in the above figure, the precision in detecting phishing URLs with the Logistic Regression ML model is 97%, and the recall is 89%. It means that Logistic Regression is doing a very good job of detecting phishing URLs. Let’s train an SVM classifier to check whether we can achieve higher accuracy or not. We will use the linear support vector classifier for the training.
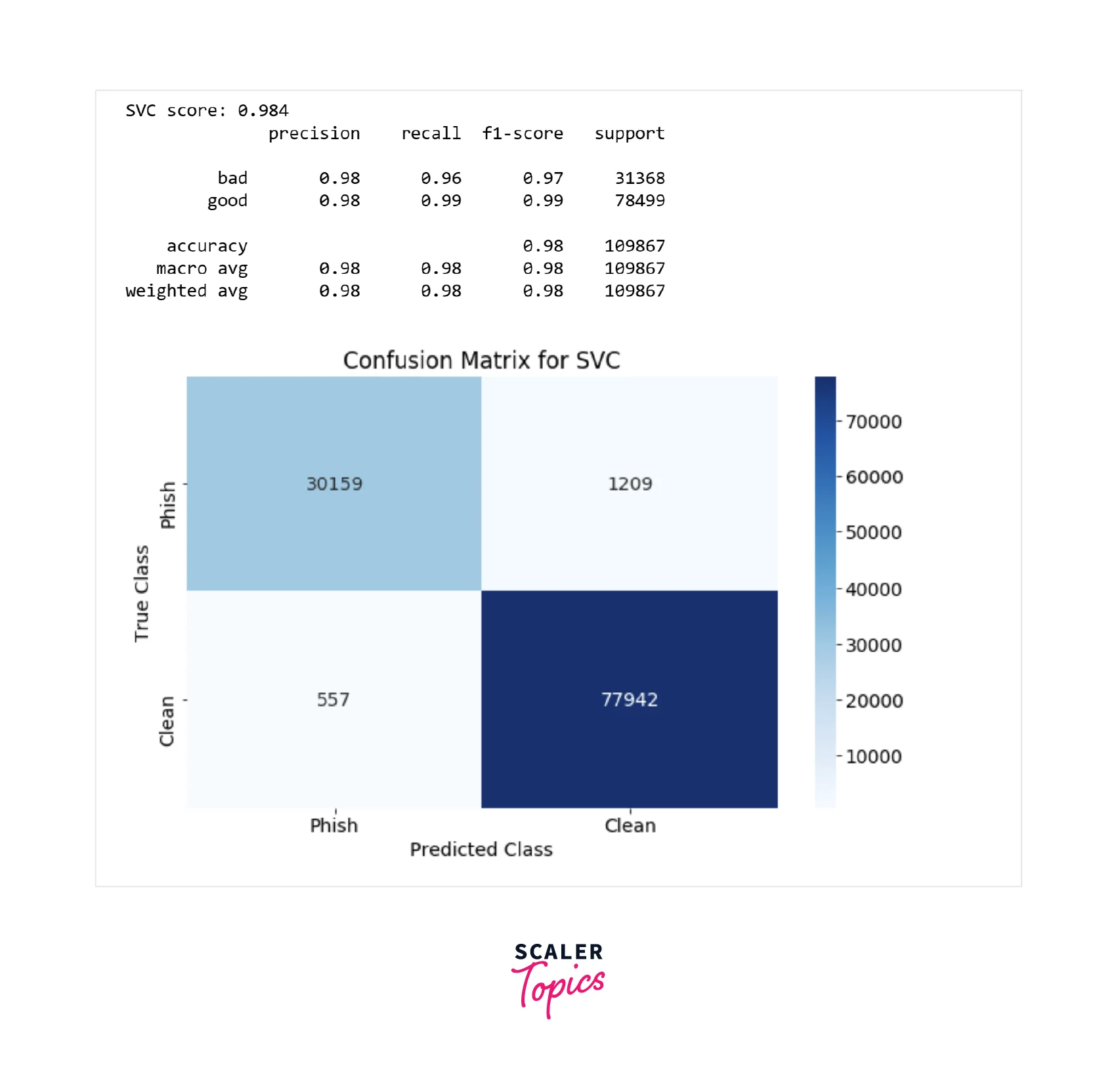
- As we can see in the above figure, for the SVM, the precision is 98% in detecting phishing URLs, and the recall is 96%. It means that SVM Classifier performed better in detecting phishing URLs.
What’s Next
- You can also experiment by training other ML models, such as Random Forest and XGBoost, to check whether you get any further improvement in model evaluation metrics or not.
Conclusion
- In the preprocessing phase, we extracted several entities from the URL and computed additional features.
- We then tokenized the domain and path sections of the URL and processed them using the TF-IDF method.
- Afterward, we trained and evaluated two machine learning models, logistic regression and SVM, to determine which performed better in detecting phishing URLs. Our results indicated that for this particular problem, the SVM model was better.