Fake News Detection Project in Data Mining
Overview
Fake news detection in data mining refers to the process of identifying and categorizing news articles that contain false or misleading information. With the increasing amount of fake news circulating online, there is a growing need to develop automated methods for fake news detection.
What are we Building?
We are building a fake news detection project that can accurately identify and classify news articles that contain false or misleading information. The proliferation of fake news on social media and other online platforms has led to the spread of disinformation and propaganda, which can have serious consequences on public opinion, decision-making, and even public safety.
Description of Problem Statement
In this project, we will use a fake news detection dataset that can be downloaded from here. It consists of around 44K news articles and their respective labels. The feature class represents whether the given news article contains any fake or misleading information or not. The project aims to develop an automated system that can enable fake news detection in news articles by analyzing their content.
Pre-requisites
- Python
- Data Visualization
- Descriptive Statistics
- Data Mining
- Machine Learning
- Data Cleaning and Preprocessing
How are we Going to Build this?
- We will handle missing values or outliers, if any, present in the dataset during the data cleaning stage.
- We will preprocess cleaned data by removing special characters, removing short and stop words, and performing stemming.
- Then, we will perform exploratory data analysis (EDA) using various visualization techniques to identify underlying patterns and correlations and derive insights.
- Further, we will train and develop multiple ML models, such as Logistic Regression and Decision Tree and compare their performance.
Requirements
We will be using below libraries, tools, and modules in this project:
- Pandas
- NLTK
- Matplotlib
- Seaborn
- Sklearn
Dataset Feature Descriptions
The description of the features present in this dataset is:
- title: the title of the news article.
- text: the content of the news article.
- subject: related subject of the news article.
- date: published date of the news article.
- class: whether the given news article is real (0) or fake (1).
Building the Fake News Detection Project
Data Preprocessing
-
Let’s start the project by importing all necessary libraries to load the dataset, perform EDA, and build ML models.
-
Let’s load the fake news detection dataset in the pandas dataframe and explore variables and their data types.

-
As title, subject, and published data are not going to impact whether a given news article is fake or real or they have no impact on the efficacy of the fake news detection project, we will drop these features from our analysis. Further, we will check the description of each feature.
-
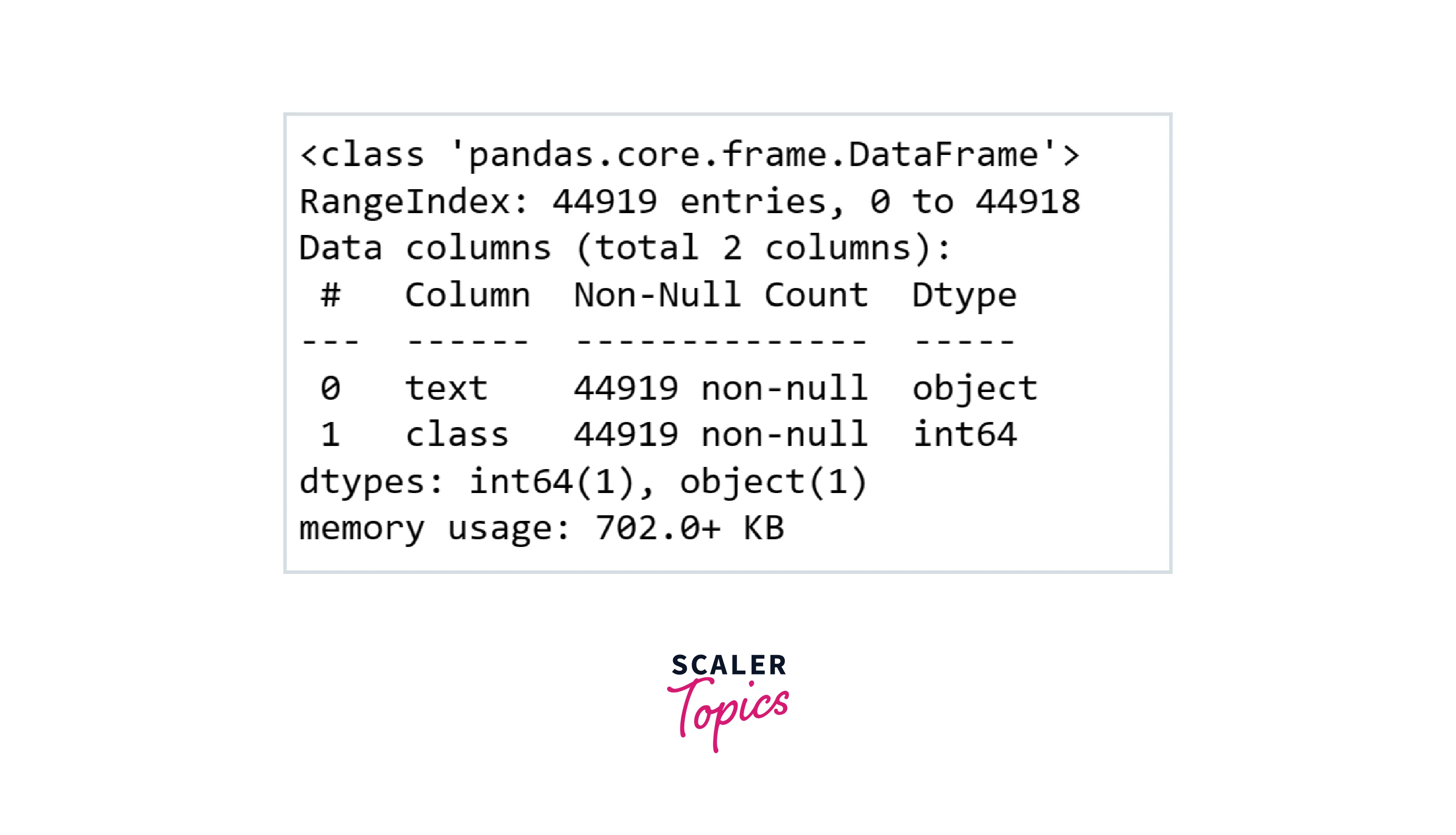
As we can see in the below figure, this dataset has 2 features and none of them contains the NULL or missing values.
Output:
-
Now, we will check the distribution of each class in our fake news detection dataset. As you can see below, both classes are more or less equally distributed (53% and 47%) in the dataset. In the next step, we will preprocess the news column to make it suitable for the ML model development.
Output:
Preprocessing and Analysis of News Column
-
In this step, we will preprocess the news column in the fake news detection. We will perform the below activities:
- Remove special characters
- Remove stop words
- Remove short words (words with length less than 3)
- Stemming
-
Now, we will create word clouds for both fake and real news articles and analyze the most frequent keywords in both sets of news articles.


-
As you can see in both the WordCloud figures, Donald Trump is present in both sets of articles. Real news articles contain keywords, such as Hillary Clinton, fact, call, report, etc. On the other hand, fake news articles contain keywords such as the white house, president, Washington, government, etc. Now, let’s train the ML model development to detect news articles containing fake and misleading news.
Converting Text into Vectors
-
Before developing the ML models, we will convert text data into vectors or numerical format. We will be using the TFIDF method to convert text into vectors or numerical format. TF-IDF stands for Term Frequency-Inverse Document Frequency, a widely used technique in natural language processing for text analysis. TF-IDF assigns weights to each word in a document based on how frequently it appears in the document and how rare it is across the entire corpus of documents. The idea behind TF-IDF is that words that frequently occur in a document but rarely in other documents are more important and indicative of the content of that document.
-
Post converting text into TFIDF vectors, we will split the dataset to create training and test datasets.
Model Training, Evaluation, and Prediction
-
First, we will train a logistic regression model and evaluate its performance. In this project, we will use precision and F1 scores to compare and evaluate the performance of the ML models.
-
As we can see in the above figure, the F1 score is 98.6% and the precision is 98.4%. It means that Logistic Regression is doing a very good job in fake news detection. Let’s train a decision tree classifier to check whether we can achieve higher accuracy or not.
-
As we can see in the above figure, for the Decision Tree Classifier, the F1 score is 99.5%, and the precision is 99.4%. It means that Decision Tree Classifier performed better in fake news detection. Let’s plot the confusion matrix for the trained Decision Tree Classifier model.
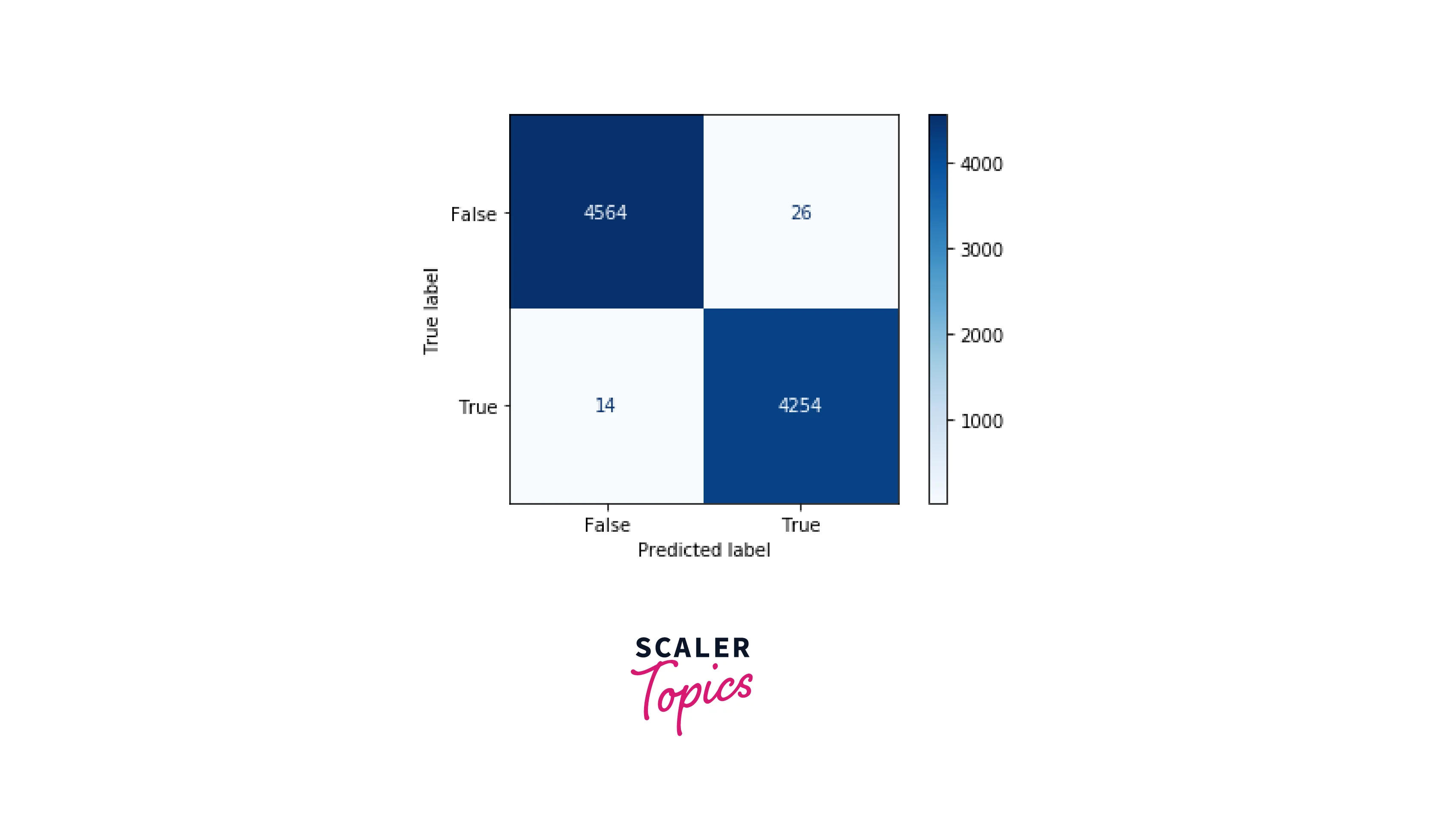
What’s Next?
- You can explore the accuracy, precision, and F1 score for the ML models with different vectorization methods, such as Bag of Words, etc.
- You can also experiment by training Random Forest and XGBoost to check whether you get any further improvement in model evaluation metrics or not.
Conclusion
- We preprocessed the dataset by removing special characters, stop words, and shorter words in the news article content. We also performed stemming on the text of the news articles.
- We examined both fake and real news articles with the help of word clouds.
- We trained and developed two ML models. We also concluded that for this problem, the Decision Tree Classifier works best.