Image Caption Generator
Overview
In data mining and computer vision, one remarkable application that has gained significant attention is the image caption generator. Image caption generator combines the power of advanced machine learning techniques with computer vision algorithms to generate descriptive and meaningful captions for images. The image caption generator holds great potential in various domains, including content recommendation, accessibility for visually impaired individuals, and enhancing the user experience in image-based platforms. In this article, we will build and train our image caption generator.
What are we Building?
An image caption generator is a computational system combining computer vision and natural language processing techniques to generate descriptive captions for images automatically. By leveraging deep learning models, it analyzes visual content and produces coherent textual descriptions, enabling applications in image understanding, content indexing, and accessibility. In this project, we will train and develop our image caption generator using Convolution Neural Networks (CNNs) and Long Short Term Memory (LSTM).
Description of problem statement
In this project, we will use the Flickr 8k dataset that can be downloaded from here. It consists of 8000 images, each with five different captions. In this project, we will train our CNN+LSTM-based image caption generator on this dataset.
Pre-requisites
- Python
- Computer Vision
- Convolution Neural Networks
- Recurrent Neural Networks, LSTM
- Deep Learning
- Data Mining
- Machine Learning
- Data Cleaning and Preprocessing
How Are We Going to Build This?
- We will gather caption data and preprocess it by removing special characters, eliminating extra spaces, and filtering out single characters to ensure clean and meaningful captions.
- Then, we will tokenize captions text to convert them into numerical format.
- We will use a pre-trained CNN model (DenseNet201) to extract high-level image features, capturing the visual information necessary for generating captions.
- Then, we will develop a custom data generator that efficiently feeds the preprocessed captions and corresponding image features into the LSTM model during training, enabling effective data handling and memory management.
- Further, we will train and develop the LSTM model using the processed data, leveraging the extracted image features and tokenized captions, to learn the association between visual content and textual descriptions, ultimately enabling the generation of accurate and contextually relevant image captions.
Final Output
- The final output of this project will consist of the image and its caption predicted by our trained and developed model, as shown below.

Requirements
We will be using below libraries, tools, and modules in this project -
- Pandas
- Matplotlib
- Tensorflow
- NLTK
- Textwrap
- tqdm
- Seaborn
- Sklearn
Building the Image Caption Generator
What is CNN?
- Convolutional Neural Networks (CNNs) are a class of deep learning models specifically designed for processing structured grid-like data, such as images. CNNs excel at capturing spatial patterns and hierarchies of features in visual data.
- They comprise multiple layers, including convolutional layers that apply filters to extract local patterns, pooling layers for downsampling and reducing spatial dimensions, and fully connected layers for classification or regression tasks.
- CNNs have revolutionized computer vision tasks by achieving state-of-the-art performance in various applications, such as image recognition, object detection, and image captioning.
What is LSTM?
- Long Short-Term Memory (LSTM) is a type of recurrent neural network (RNN) architecture that addresses the limitations of traditional RNNs in capturing long-term dependencies.
- LSTMs are designed to effectively process sequential data by introducing specialized memory cells that can selectively retain or forget information over extended periods. This capability makes LSTMs particularly well-suited for tasks involving sequential or time-series data, such as natural language processing and speech recognition.
Import All The Required Packages
- Let’s start the project by importing all necessary libraries to load the dataset, perform EDA, pre-process, and build our image caption generator.
- Let’s define the path for images and captions in the Flickr 8k dataset. It is required to load images and their respective caption data, as shown below.

- As shown below, let’s define a function to load an image and display its respective caption. We will also display a few images and their captions.

Data Pre-processing of Captions Text
- In this step, we will pre-process captions data by performing the steps shown below -
- Convert captions sentences into lowercase to ensure consistency and avoid redundancy in the data.
- Remove any special characters and numbers present in the captions text.
- Removing extra spaces and single characters in the text data
- Adding a start and an end keyword to the sentences to indicate the beginning and the ending of a caption.
- Next, we will apply a tokenizer to the captions data and split the training and test dataset for the model training and development.
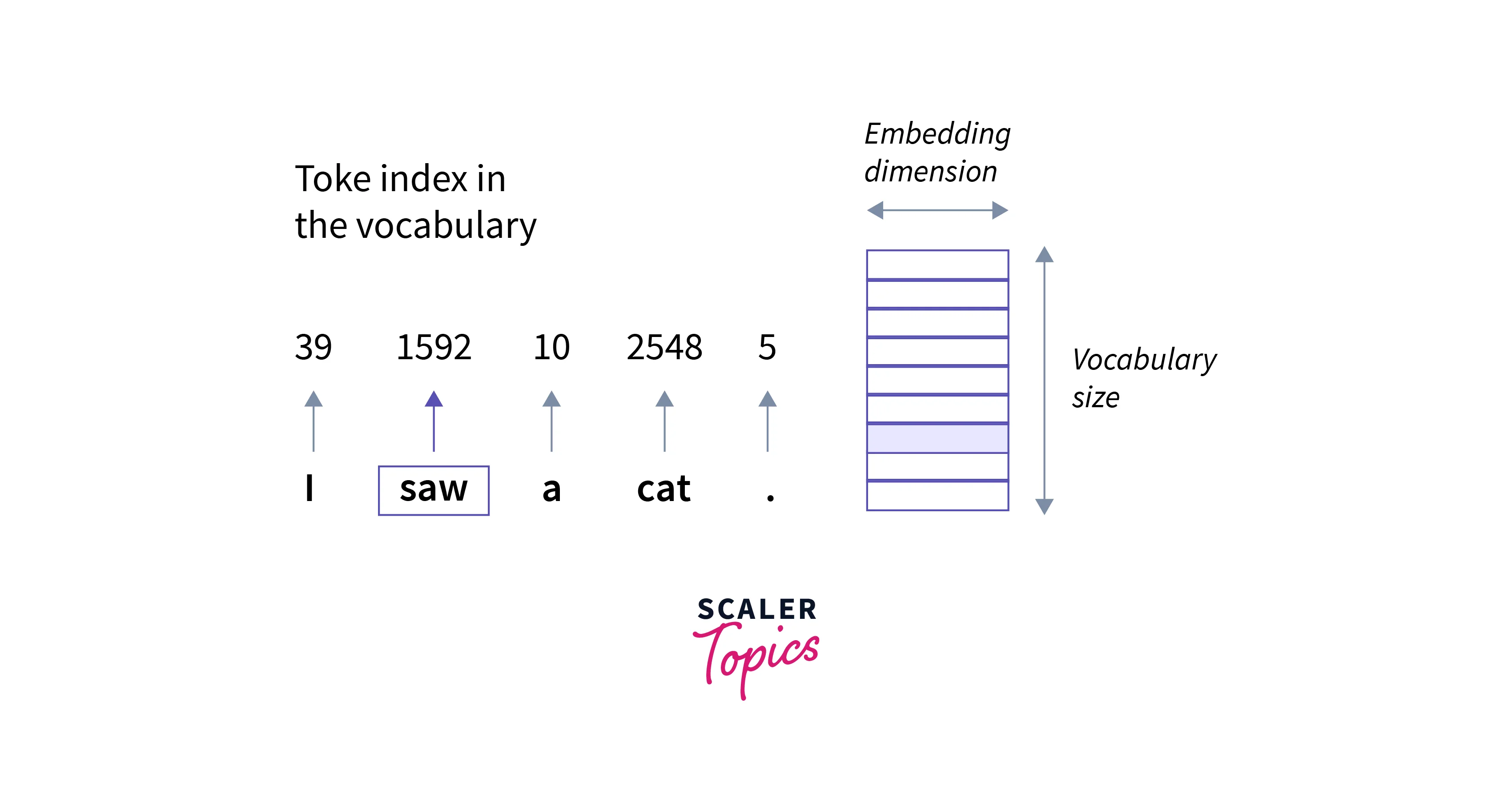
Extracting Image Feature Vector
- In this step, we will use a pre-trained CNN model - DenseNet201 for extracting image feature vectors. Any other pre-trained CNN model can also be used to extract the feature vector for input images.
- In our case, image embeddings will be of size 1920.
Create a Data Generator
- In this step, we will define a custom data generator that efficiently feeds the preprocessed captions and corresponding image features into the LSTM model during training, enabling effective data handling and memory management.
- Image caption generation is a high resource utilization task, and we can not load whole data into memory at once. Hence, we need to define a data generator to feed input images into batches for efficient memory handling.
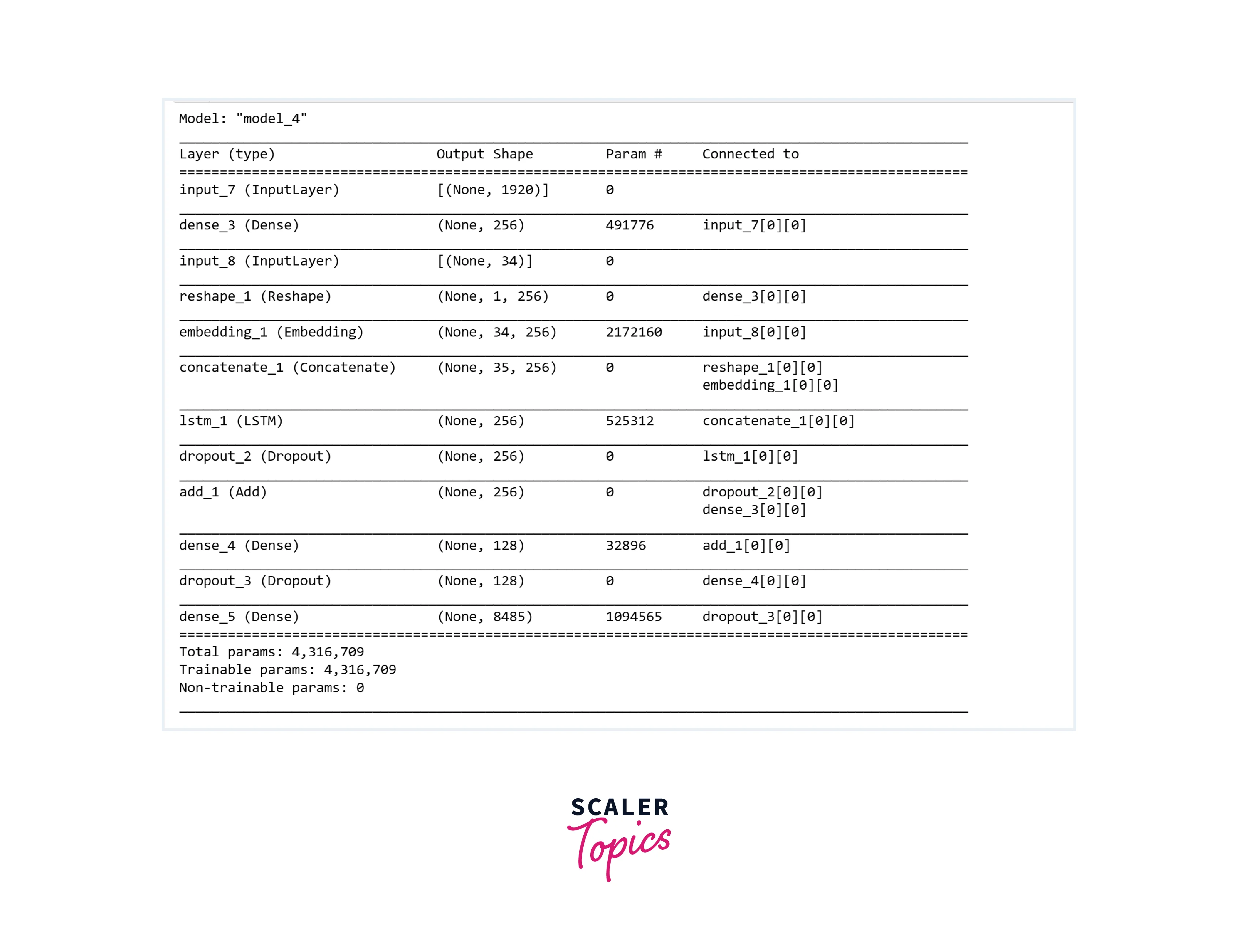
Define the CNN-LSTM Model
- In this step, we will define our CNN-LSTM model to generate image captions, as shown below.
Training the Image Caption Generator Model
- First, we will define the data generator for the training and validation dataset. We will also initialize our defined CNN-LSTM model.
- Now we will start training the CNN-LSTM model. I have kept the epoch count for this project as 5, but you can increase it to get better accuracy in the final model.

- As you can see in the above figure, with each epoch iteration, we can observe improvement in the model's accuracy. By increasing the Epoch count, we can get better accuracy in the trained model.
Image Caption Generation Using Trained Model
- In this step, we will define some utility functions to generate the captions, such as converting the model output index to words, etc. Then, we will display predicted captions for a few images.

- As you can see in the above figure, predicted captions do not fully describe the input images. It is because we trained the model for only 5 epochs. You can experiment by training the model for a higher number of epochs and can check how it improves the predicted captions.
What’s Next
- You can experiment by training the CNN-LSTM model for a higher number of epochs and can analyze whether it affects the accuracy of the predicted captions.
- You can also experiment by training the model on a larger dataset, such as Flickr 40k, etc., to generate better image captions.
Conclusion
- We gathered the dataset and preprocessed the captions by lower casing, removing special characters, and tokenizing the text.
- We extracted the image features vector by using a pre-trained model DenseNet201.
- We defined a custom data generator to feed the data to the model into fixed-sized batches efficiently.
- We trained and developed the CNN-LSTM model and observed that we need to train the model for a higher number of epochs for better captioning.