Social Media Trend Analysis in Data Mining
Overview
In the digital age, social media has become an integral part of our daily lives, transforming how we communicate, consume information, and interact with brands. Beyond its personal and social aspects, social media platforms have evolved into powerful tools for social media trend analysis. By tapping into the vast amount of user-generated content, businesses, marketers, and researchers can gain valuable insights into emerging trends, consumer preferences, and market opportunities.
What Are We Building?
- Trend analysis with social media refers to the process of examining and analyzing data from social media platforms to identify patterns, insights, and emerging trends. It systematically explores user-generated content, including posts, comments, likes, shares, hashtags, and discussions, to better understand consumer behavior, preferences, and market dynamics.
- By utilizing social media analytics tools and techniques, businesses and researchers can extract valuable information from the vast amount of data generated on platforms like Facebook, Twitter, Instagram, LinkedIn, and YouTube.
- This analysis can provide organizations with real-time visibility into emerging trends, consumer sentiment shifts, popular discussion topics, and market opportunities. It enables businesses to stay ahead of the curve, make informed decisions, and effectively tailor their strategies, products, and marketing efforts to meet evolving customer demands.
- In this project, we will perform social media trend analysis on a Twitter dataset.
Description of Problem Statement
This project will use a Twitter dataset containing tweets on the IPL during 2020-2022. This dataset can be downloaded from here. We will only use tweets on IPL 2022 for this project, but the code can be extended to any year. Also, you can generate your own dataset by using the Twitter Tweepy API.
Pre-requisites
- Python
- Data Mining
- Data Visualization
- Data Cleaning
- Exploratory Data Analysis
- Data Preprocessing
How Are We Going to Build This?
- First, we will collect the dataset containing tweets on the IPL 2022. We will clean the dataset by removing the NULL values.
- Further, we will pre-process the tweets by cleaning them, removing special characters, etc.
- Then, we will perform an extensive EDA to understand the ongoing trends, popular discussion topics, etc.
Requirements
We will be using below libraries, tools, and modules in this project -
- Pandas -
Pandas is a Python library used for data manipulation and analysis, which offers powerful data structures and functions to handle and explore structured data efficiently. - NLTK -
NLTK (Natural Language Toolkit) is a Python library used for natural language processing tasks such as tokenization, stemming, tagging, and parsing, making it easier to work with natural language data. - Seaborn -
Seaborn is a Python library used for creating visually appealing statistical graphics, making it easier for beginners to visualize and explore patterns and relationships in data. - Matplotlib -
It is used for creating visualizations and plots, making it easier to visualize and communicate data effectively. - Tweepy -
Tweepy is a Python library used for accessing and interacting with the Twitter API, making it easier for beginners to develop applications that involve fetching and posting tweets. - Textblob -
TextBlob is a Python library used for natural language processing tasks, such as sentiment analysis, part-of-speech tagging, and text classification. - re -
It is used for working with regular expressions, enabling users to search, extract, and manipulate text patterns in a flexible and powerful way.
Implementation of Trend Analysis with Social Media
Import All The Required Packages
- Let’s start the project by importing all necessary libraries to perform social media trend analysis on the Twitter dataset.
Create Dataset Using Tweepy API
- Tweepy is a popular Python library that provides an easy-to-use interface for interacting with the Twitter API. It simplifies the process of accessing and retrieving data from Twitter, including tweets, user profiles, followers, and more. Tweepy allows developers to authenticate with Twitter, perform queries, and handle rate limits, making it an essential tool for building applications that leverage Twitter's data and functionality.
- For this project, we are not using Tweepy API to generate our own dataset, but you can use the below code to create your own dataset by searching for a specific hashtag. To use this API, you will have to apply and register for the Twitter Developer Platform, create a Twitter developer app, and generate the API keys and access tokens for using it.
Data Collection
- Let’s collect the Twitter dataset containing tweets on IPL 2022 and remove any NULL values. For this project, we will only use the 100K sampled tweets from the dataset.
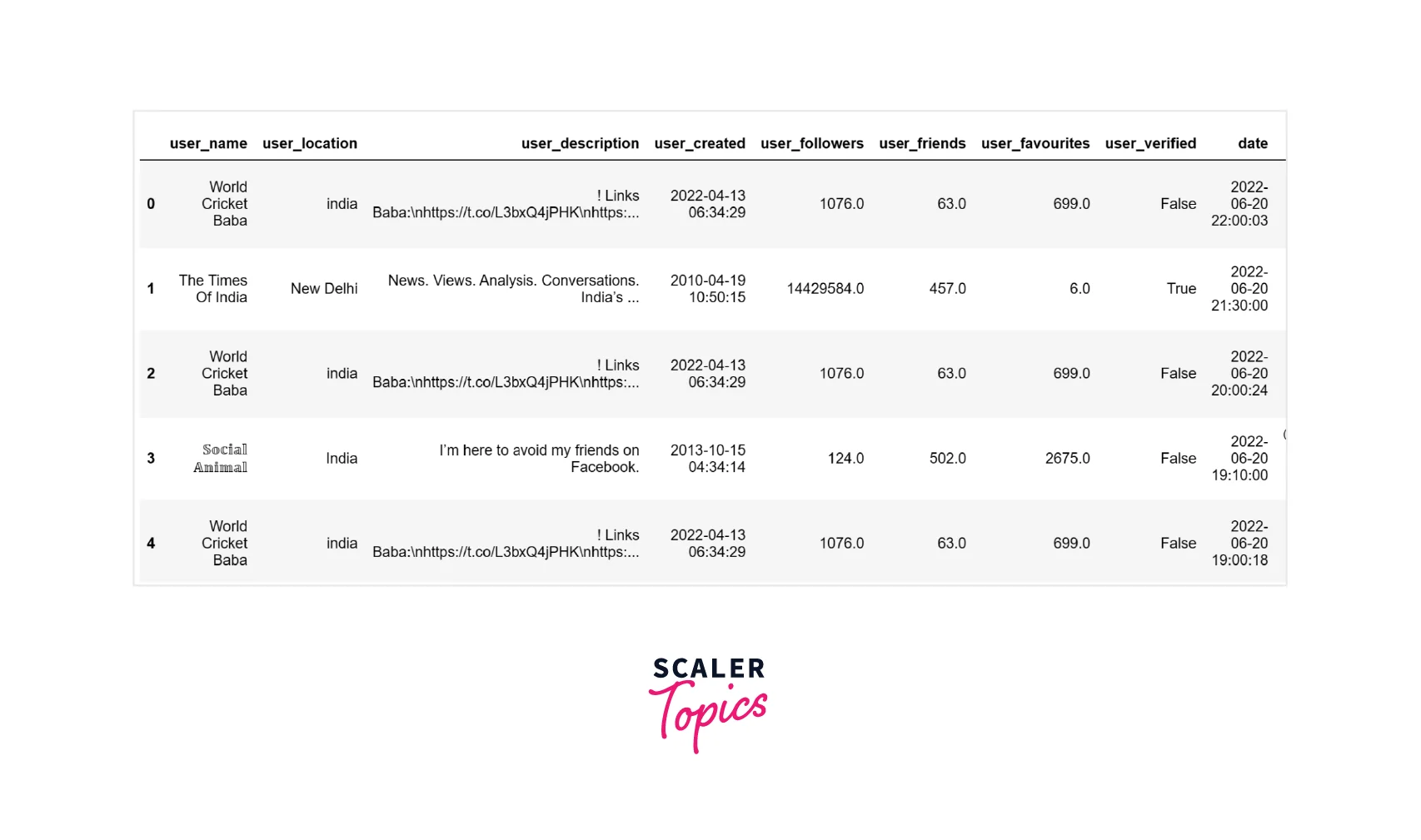
Data Pre-processing
- In this step, we pre-process the tweets by performing the following steps -
- Removing special characters
- We will not remove # and @ to identify the main keywords and account handles.
- We will lowercase the tweets.
- We will remove any short words, such as ok, oh, etc.
- We will remove stopwords and perform stemming on the tweet tokens.
Exploratory Data Analysis
- Let’s first create a WordCloud for the tweets. For this WordCloud, we will remove the hashtags and Twitter handles to derive insights into the actual tweet content.

- As you can see in the above figure, people mostly discuss players such as Virat Kohli, Butler, Williamson, Rashid Khan, etc. They are also tweeting about teams, such as Mumbai Indians, Gujarat Titans, etc. Now, we will plot a WordCloud on the location of the tweets, as shown below.

- As you can see in the above figure, people mostly tweet from major cities, such as Mumbai, New Delhi, Chennai, Kolkata, Bengaluru, Hyderabad, etc. Now, we will see how the number of tweets varies based on the date, as shown below.
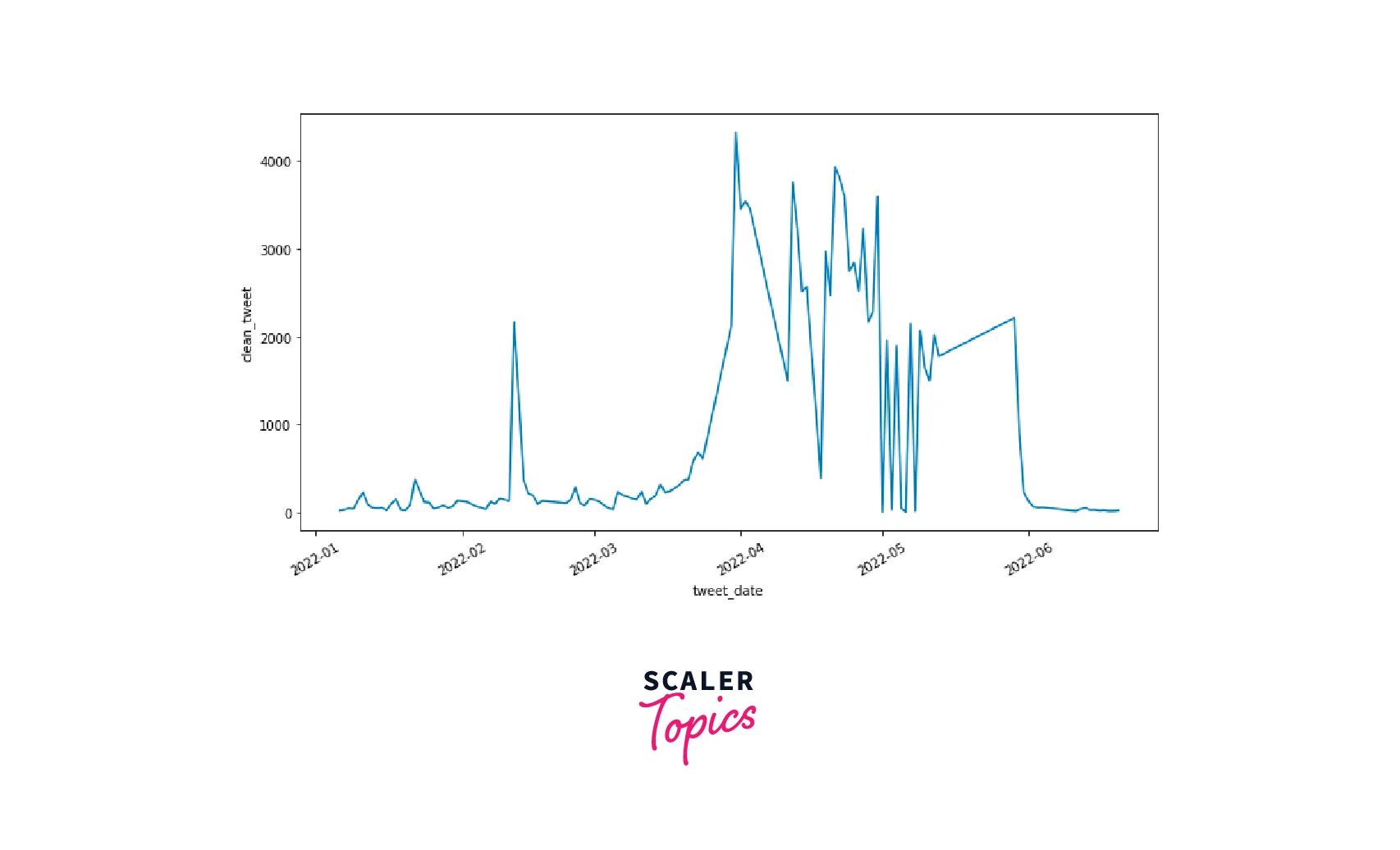
- As you can see in the above figure, most of the tweets were tweeted during the IPL season only, and there is a sharp increase during the start of the IPL and a sharp decrease after the end of the IPL. There is one more spike in the number of tweets in Feb 2022 which could be due to IPL auctions. Now, we will explore the top 10 hashtags used in the tweets, as shown below.
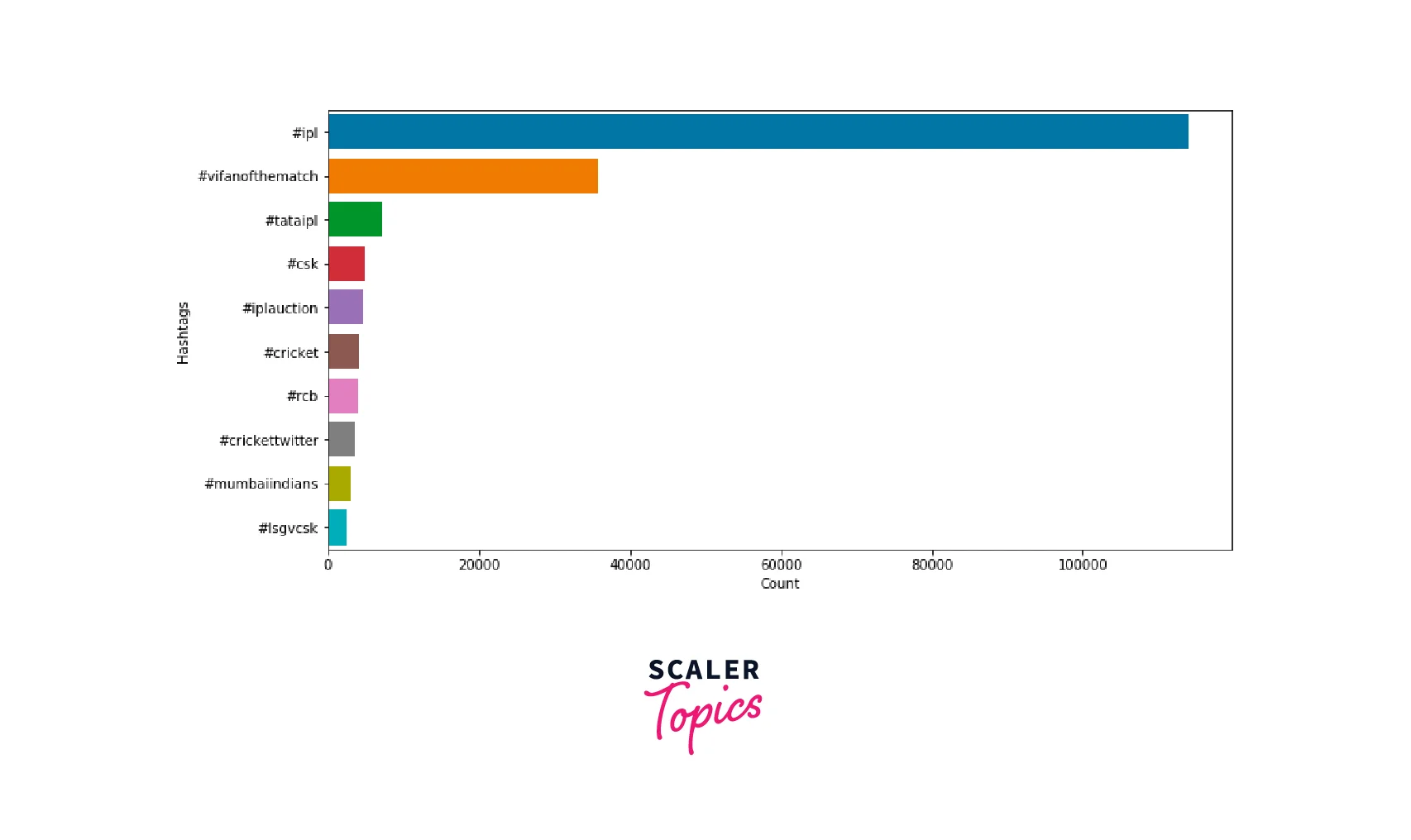
- As you can see in the above figure, people mostly discussed CSK, IPL auction, RCB, MI, and LSG vs CSK match. We ignored other hashtags as they are mostly redundant information. Next, we will explore the top 10 Twitter handles tagged in the tweets, as shown below.
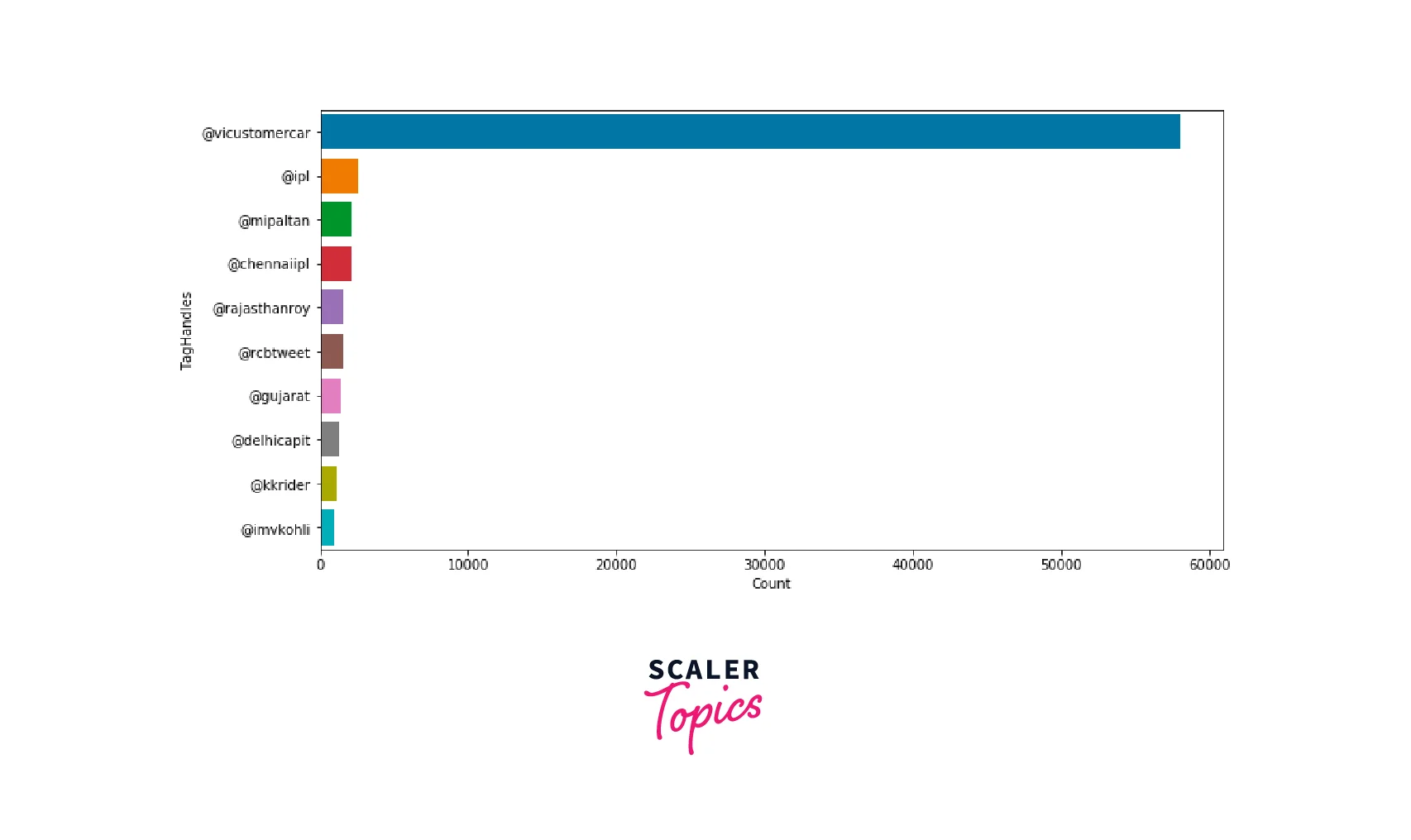
- As you can see in the above figure, people mostly tagged the Twitter handles of teams in this order, MI, CSK, RR, RCB, GT, DC, and KKR. There is also mention of Virat Kohili in the top 10 Twitter handles.
What’s Next
- You can experiment with other IPL tweets datasets to understand how the trends vary year on year.
- You can also generate your own dataset for your favorite hashtag or keyword and perform social media trend analysis on it.
- You can also perform sentiment analysis to understand the prevalent sentiment in the people.
Conclusion
- Trend analysis on tweets involves extracting insights and patterns from Twitter data to understand and identify emerging topics and popular discussions.
- In this project, we collected the IPL 2022 tweets dataset and preprocessed tweets by cleaning, lower casing, and stemming them. We also removed special characters and short words from the tweets.
- We performed social media trend analysis on this dataset using various visualization techniques, such as WordCloud, bar charts, etc.